基于動作周期退化相似性度量的機械軸健康指標構建與剩余壽命預測
2021-12-07 10:09:06周玉彬肖紅王濤姜文超熊夢賀忠堂
計算機應用 2021年11期
周玉彬,肖紅,王濤,姜文超,*,熊夢,賀忠堂
(1.廣東工業大學計算機學院,廣州 510006;2.廣東工業大學自動化學院,廣州 510006;3.中國科學院云計算產業技術創新與育成中心,廣東東莞 523808)
0 引言
工業機器人在大型復雜零件的加工中被廣泛應用[1],其中,六軸工業機器人在自動化生產系統中發揮著尤為重要的核心作用[2]。與此同時,六軸工業機器人精度退化和故障問題也十分嚴峻,給企業造成巨大安全生產風險和經濟損失[3]。機械軸是工業機器人運動的核心部件和支撐,跟蹤機械軸的健康狀態并預測其潛在故障,對機器人的健康管理至關重要。機械軸的故障并不是突然發生的,而是從正常運行逐漸退化到失效經歷了一段不同退化狀態的過程。為了對工業機器人機械軸進行健康管理,需要為機械軸構建合理的健康評價指標,從歷史監測數據中提取特征信息來識別和量化機械軸退化水平,進而預測其剩余壽命(Remaining Useful Life,RUL)。
目前國內外對工業設備健康指標(Health Index,HI)構建與剩余壽命(RUL)預測已經有不少研究,主要有基于模型的方法和數據驅動的方法兩大類[4]。然而,在大多數實際工業生產過程中,對復雜設備機理進行建模分析十分困難,難以保證模型的精準性。因此,在傳感器檢測大數據背景下,基于數據驅動的評價與預測方法成為主流。基于數據驅動的預測方法可以分為直接預測和間接預測兩類[4]。直接預測是指直接利用設備退化特征變量進行RUL 預測;間接預測是指利用設備退化特征變量構建健康指標(HI),再根據HI 進行RUL 預測。通常情況下,間接預測的準確性會更好,因此成為主流方法。文獻[5]使用三種不同的統計方法(奇異值分解、累計特征平均值和馬氏距離)獲取滾動軸承的振動信號并構建其健康指標。為了全面評估系統健康狀態,文獻[6]提出了基于深度置信網絡(Deep Belief Network,DBN)的無監督健康指標構建方法,通過無監督訓練深度置信網絡實現歷史數據特征提取,并利用重構誤差構建其健康指標,進而輸入隱馬爾可夫模型(Hidden Markov Model,HMM)進行剩余壽命預測。文獻[7]使用深度卷積神經網絡(Deep Convolutional Neural Network,DCNN)對軸承的深層特征進行學習,通過非線性變換將學習到的特征映射到健康指標,進而用于軸承健康管理。后來進一步提出了基于趨勢毛刺的卷積神經網絡的HI 構建方法[8],用于軸承健康管理。文獻[9]利用CNN提取信號數據中的時序局部信息,結合RNN 進行信息連接,實現軸承健康指標構建。文獻[10]提出了使用結構化域對抗神經網絡(Structured Domain Adversarial Neural Network,SDANN),基于深度遷移學習技術實現多工況下軸承故障診斷。
然而,以上研究主要針對軸承、齒輪箱等特定領域的特定部件健康指標構建較多,方法不具有良好的普適性,目前針對六軸工業機器人機械軸的健康預測與狀態管理研究較少[11]。不同于普通的簡單旋轉機械,工業機器人機械軸幾何形狀瞬時變換較復雜,其機械結構比較復雜,難以建立精確數學模型;所以,基于統計方法和機器學習的無模型方法成為機器人健康監測的主流選擇[12-13],包括使用主成分分析(Principal Component Analysis,PCA)[11,14]、線性判別分析(Linear Discriminant Analysis,FDA)[14]、奇異譜分析(Singular Spectrum Analysis,SSA)[15]、希爾伯特變換(Hilbert Transform,HT)[15]和小波分析[11,16]等方法,對機器人振動信號、編碼器信號、驅動電機電流、電壓、轉速信號等進行處理與分析,用于機器人故障檢測。
在實際生產中,機械軸完成一套動作(如打磨、上下料等)具有一定周期性。若忽略動作周期性,僅僅基于數據進行退化分析,會因為在動作周期不同時期的數據表現不同,進而影響機器人實際狀態退化分析的準確性。本文提出了基于動作周期退化相似性度量的六軸工業機器人健康指標構建與剩余壽命預測方法。首先,針對預處理后的機器人運行數據,使用MPdist 方法[17]關注兩條時間序列共享的相似子序列特點,計算機械軸不同退化周期的相似性距離,進而構建健康評價指標;其次,將構建的健康指標集輸入適用于時間序列分析的長短時記憶網絡進行訓練,建立健康指標與剩余壽命的映射關系;最后,混合利用MPdist 與長短時記憶(Long Short-Term Memory,LSTM)網絡模型進行機器人剩余壽命自動預測與預警。
使用某公司六軸工業機器的加速老化數據集進行實驗測試,實驗結果表明,本文方法構建HI 的單調性和趨勢性相較于其他對比方法至少高出了0.07和0.13,且RUL預測準確率更高,誤差區間更小,驗證了本文方法的可行性。
1 健康指標構建
MPdist 是一種新的距離度量方法[17-18]。MPdist 能夠比較不同長度的時間序列,且對尖峰、遺漏、基線徘徊等問題具有較強魯棒性。與傳統動態時間規整(Dynamic Time Warping,DTW)算法[19-20]、歐氏距離(Euclidean Distance,ED)算法相比,MPdist 認為兩個時間序列共享的相似子序列越多,則它們越相似,且與匹配子序列的順序無關;同時,MPdist 可以容忍兩條子序列數據點發生位置位移。
在確定工況下,工業機器人機械軸周期性執行固定的動作,不同動作周期之前會有不定時停頓,因此,周期性數據之間可能會有一定的停頓或者平移等。而現實工業過程對機械軸周期動作之間相似性的關注程度遠高于對數據點位置的關注程度。如圖1所示,對比兩條發生50個采樣點平移的序列,發現T2是序列T1向后平移50 個采樣點形成的序列。使用三種方法計算平移前的比對距離均為0,平移后的距離對比結果如表1所示。由表1可知,MP 距離比DTW 距離和歐氏距離更適合衡量動作周期循環運動的工業機器人退化評估。
1.1 MPdist相似性度量
MPdist算法如算法1所示。
算法1 MPdist算法。
輸入 待比對的時間序列T1和T2,對比子序列長度L;
輸出 兩條時間序列的比對結果MP距離。
1)創建子序列集。以滑動窗口大小L提取時間序列T1和T2長度為L的子序列,構建子序列集。其中3 ≤L≤min length(T1,T2)。
2)建立相似性連接集。使用1NN?join函數分別尋找子序列集SubT1和SubT2中的互相最近鄰,并分別保存在相似性連接集中,同時將中每對最近鄰子序列的歐幾里得距離保存在數組。
3)計算MP距離,計算式如式(1)所示。

1.2 基于MPdist相似性的健康指標構建
由于工業機器人在完成執行程序的命令時,通常是通過機械軸的運動,循環地完成周期性動作,因此采集到的工業機器人機械軸的運行數據具有時間連續性和周期性的特點。隨著機器人運行時間不斷延長,機械軸漸漸老化,不同周期運行數據之間的相似性距離會越來越大,通過相似性距離的變化趨勢來衡量機械軸的退化趨勢是合理的。
使用MPdist 算法對數據作相似性比對,按數據采集的時間先后,標記數據文件為t1-tn,按時間先后順序,以t1時刻的數據作為基準,依次將t2至tn時刻的數據與基準數據進行相似性比對,依次得到比對距離,記為MP 距離,即得到一組基于時間的MP 距離變化數組,具體比對過程如圖2所示。此數組中的數據具有一定的單調性趨勢,并與機器人實際運行狀態的退化趨勢相符,因此,使用MP 距離來衡量機械軸的健康程度,進而構建健康指標(HI)曲線。基于MPdist 的健康指標構建方法步驟如下:
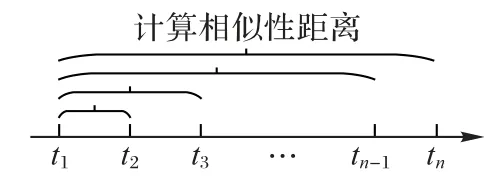
圖2 相似性比對示意圖Fig.2 Schematic diagram of similarity comparison
1)選定平穩運行時期中t1時刻的k個動作周期老化變量數據,設為比對基準時間序列T1,將退化數據集的老化過程數據的k個動作周期運行數據設為待檢測時間序列T2,設置比對子序列的時間窗口大小為l個動作周期長度L。
2)依次輸入退化數據集中標記的t2至tn時刻的數據,計算相似性比對距離,即MP距離,依次保存。
3)得到每個變量基于時間線上的MP距離變化數組。
4)對每個變量的MP距離變化數組進行差分平滑處理。
5)劃分失效數據與老化過程數據,計算健康指標值。
6)得到每個運行變量的健康指標(HI)曲線。
該方法具有以下特點:1)以動作周期為單位衡量退化程度,可以保證機械軸動作完整性信息,構建的健康指標更貼切機械軸運行特點;2)能自適應地比對動作周期數據,無需手動對齊周期的起點;3)以偏離程度來構建健康指標,屬于無監督的方式,不需要大量專家經驗和人工標簽,節省了成本。
算法評價選用健康指標評價常用的單調性、魯棒性和趨勢性作為評價指標,單調性、魯棒性和趨勢性[21]的計算分別如式(2)~(4)所示。

其中:Mon(HI)是單調性指標;Num+表示HIt與HIt-1之差為正數的個數,同理可得,Num-表示HIt與HIt-1之差為負數的個數;n代表HI 的個數;Rob(HI)是魯棒性指標;HIt代表t時刻的HI 值,代表進行平滑分解后的殘差值;Tre(HI)是趨勢性指標。
2 基于MPdist-LSTM的剩余壽命預測
工業機器人機械軸退化過程是一個逐漸老化的過程,機器人的歷史運行情況變化過程會影響此時此刻的機械軸運行情況,使用LSTM 網絡可以對機器人運行數據的時間序列特征、滯后性和隨機性進行深入挖掘。LSTM網絡是一種改進的循環神經網絡(Recurrent Neural Network,RNN)[22],然而當輸入時間序列長度過長時,RNN 存在梯度消失和梯度爆炸的問題,為此,本文使用設置了“門”和“開關”實現時間記憶功能的LSTM神經網絡。LSTM的網絡結構[23]由三個“門”和記憶細胞組成,三個“門”分別為:輸入門、遺忘門、輸出門。輸入門用來控制當前時刻神經單元的輸入信息,遺忘門用來保留上一時刻神經單元中存儲的歷史狀態信息,輸出門用來控制當前時刻神經單元的輸出信息。
傳統的利用長短時記憶網絡的剩余壽命預測方法通常是直接將數據輸入模型進行模型訓練,預測剩余壽命。為了利用MPdsit相似性度量方法對數據進行退化特征提取并構建健康指標,本文將得到的健康指標用來訓練LSTM 網絡模型后得到訓練好的MPdist-LSTM模型(如算法2所示),在此基礎上進行機械軸健康狀態識別與剩余壽命計算,具體框架如圖3所示。使用MPdist-LSTM 模型進行壽命預測主要分為兩步:基于歷史老化數據集的訓練階段和基于在線監測數據的預測階段,流程如圖4所示。
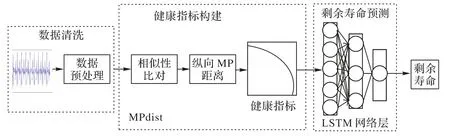
圖3 基于MPdist-LSTM的剩余壽命預測框架Fig.3 Framework of remaining useful life prediction based on MPdist-LSTM
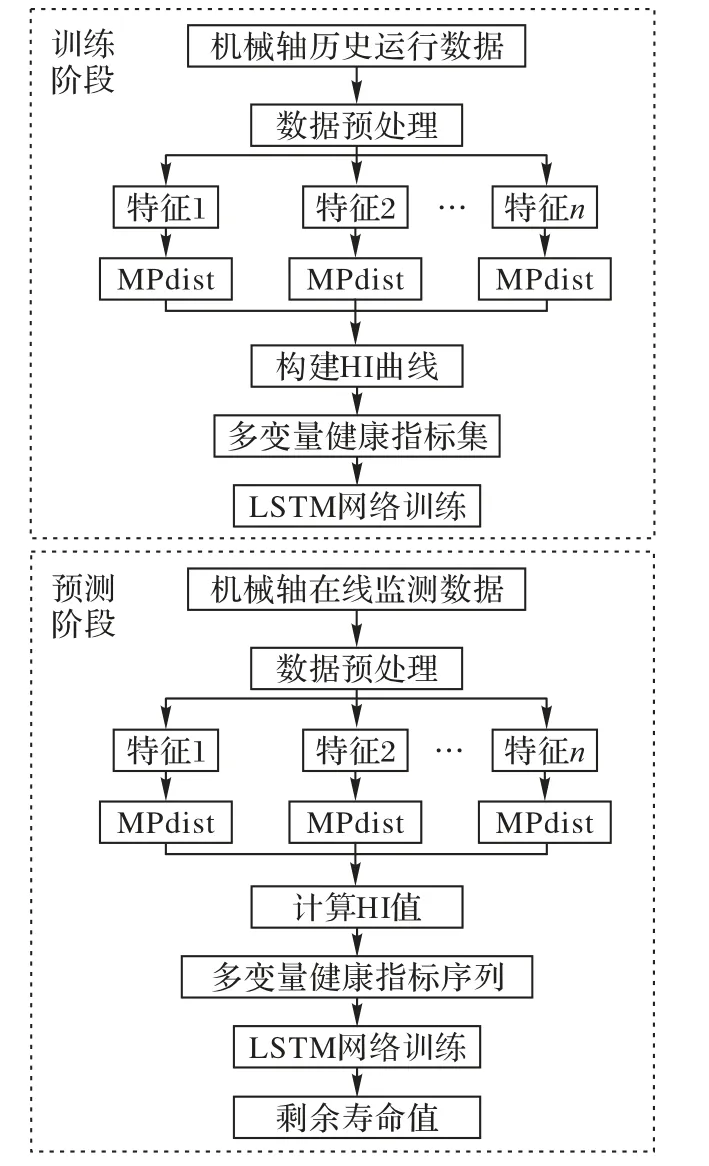
圖4 健康指標構建與剩余壽命預測流程Fig.4 Flow chart of health index construction and remaining useful life prediction
算法2 MPdist-LSTM模型。
a)訓練階段。


算法評價選用三種評價回歸模型預測效果優劣程度的統計量作為模型性能評價指標[24],分別為平均絕對誤差(Mean Absolute Error,MAE)、均方根誤差(Root Mean Square Error,RMSE)和決定系數(R-Square,R2)。MAE 表示所有真實值與預測值之間偏差的平均絕對值,RMSE 表示真實值與預測值誤差平方的均值,MAE 和RMSE 越小,模型的預測誤差越小,預測精度越高;反之亦然。R2表示衡量模型預測未知樣本的效果,當R2數值越接近1,模型的擬合效果越好,預測精度更高;反之亦然。本文使用RUL 預測誤差區間(Error Range,ER)、早預測(Early Prediction,EP)和晚預測(Late Prediction,LP)作為評價指標來進一步評估RUL 的預測結果。早預測和晚預測的定義如圖5所示。預測誤差如式(5)所示:

圖5 早預測和晚預測示意圖Fig.5 Schematic diagram of early prediction and late prediction
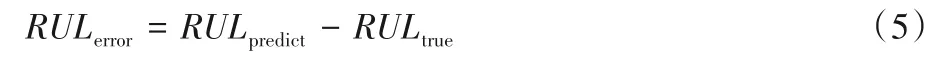
當RULerror≥0 時,記為晚預測;RULerror<0 時,記為早預測。
在實際應用場景下,早預測和晚預測影響程度不同,在一定程度上,早預測可以為機械軸提供預警,而晚預測可能帶來一定的損失,相較于晚預測,更偏好于早預測。
3 實驗與結果分析
3.1 數據采集
根據工業機器人的設計,驅動器會提供電流和電壓等信號,而這些信號與電機輸出的扭矩和轉速關系密切;同時有些驅動器也提供編碼器信號,而此信號常用于機器人位置反饋。當齒輪斷裂、連接裝置脫落和反饋裝置異常等機器人故障發生時,會在驅動器電流、電壓和編碼器等信號中有所反映。
實驗采用某公司六軸工業機器人進行加速老化實驗,建立加速老化實驗數據集。實驗的工業機器人如圖6 所示,該型號機器人本體重量輕,內部運動慣量小,采用高速電機結合內旋轉功能實現快速沖壓,常用于上下料、搬運、打磨等實際應用場景。實驗設置3 臺機器人,負載為6 kg,運行速度達到100%,執行老化實驗跑機程序,連續跑機一個月,采集機器人多個運行變量數據,所有數據變量符號定義如表2 所示。包括9 個變量,采樣頻率為4 ms。為減少數據冗余,每隔4 h 抽取一次數據作為實驗數據,數據包含每臺機器人500 多萬條數據,900 多個動作周期。數據分析工具采用pycharm 和jupyter book。

表2 變量名說明Tab.2 Description of variable name

圖6 某公司六軸工業機器人Fig.6 Six-axis industrial robot of a company
3.2 健康指標構建測試分析
首先對采集到的9 個變量數據進行分析,根據專家經驗和統計分析,先篩選掉指令位置(pcmd)、指令力矩(tcmd)、指令加速度(acmd)這三個具有周期不變性的變量;然后使用PCA 方法進行特征降維并結合Pearson 相關系數,篩選出反饋力矩(tfb)、反饋速度(vfb)和位置誤差(pe)這三個能反映出老化趨勢的變量作為老化特征變量。根據MPdist算法輸入參數特點,輸入兩條待比對的時間序列T1和T2以及比對的子序列長度L。
由于MPdist算法可以容忍兩條時間序列的起點為隨機起點,所以輸入數據無需周期對齊。為探索最佳時間序列T1和T2與L之間的長度關系,以1 號機器人2 軸的反饋力矩為例,分別比對了T1和T2與L為不同比率,計算MP 距離的單調性、魯棒性和趨勢性,結果如表3所示。
由表3可知,當T1和T2與L的比率為5∶1時,MP距離曲線單調性和魯棒性最好,且隨著比率的增加,算法復雜度更高,而MP 距離曲線的單調性和魯棒性沒有明顯變得更好的趨勢。因此,實驗選擇MPdist算法的輸入參數設置:對比序列T1和T2為5 個動作周期數據,子序列長度L為一個動作周期長度。依次將各個老化變量的退化數據與正常數據輸入MPdist算法進行相似性度量,計算得到MP 距離。以反饋力矩(tfb)為例,參數設置示意圖如圖7所示。
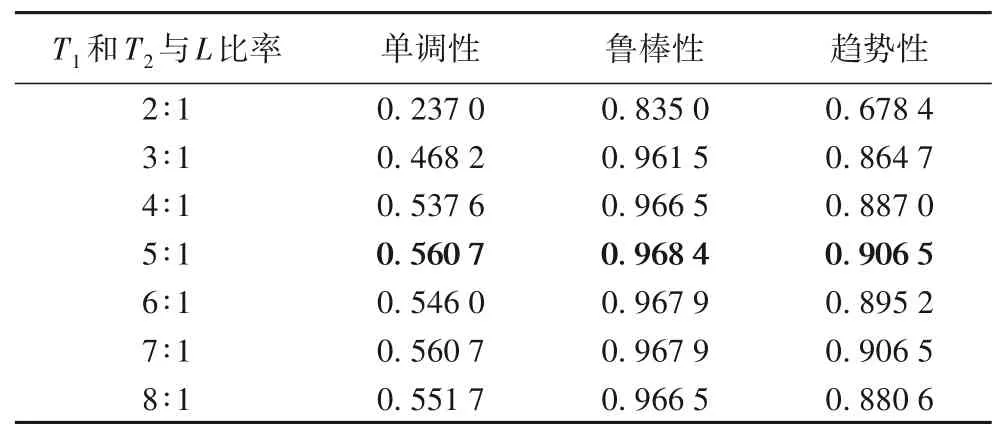
表3 不同比率的MP距離曲線評價結果對比Tab.3 Comparison of evaluation results of MP distance curves with different ratios

圖7 反饋力矩的MPdist相似性度量示意圖Fig.7 Schematic diagram of MPdist similarity measurement of feedback torque
以1 號機器人4 軸反饋力矩(tfb)、反饋速度(vfb)和位置誤差(pe)為例,使用MPdist 算法依次計算各變量的MP 距離,為減少隨機波動性對數據的影響,對曲線進行差分平滑法構建出平滑后的MP 距離曲線。平滑后的反饋力矩(tfb)、反饋速度(vfb)和位置誤差(pe)的MP距離曲線如圖8所示。
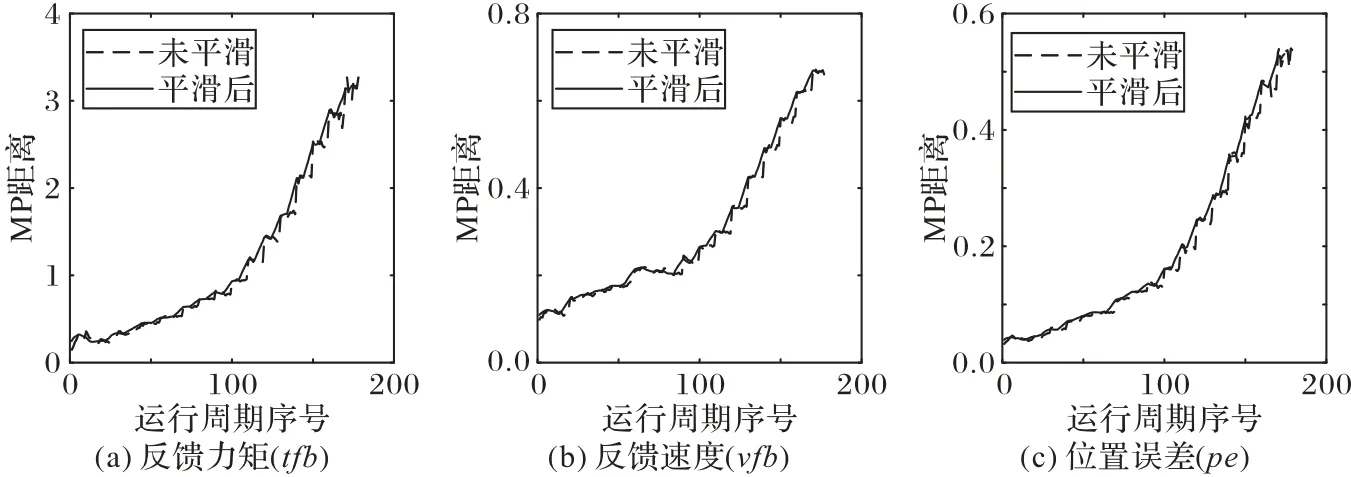
圖8 平滑后多變量MP距離曲線Fig.8 Smoothed multivariable MP distance curve
實驗將比對距離的后5%的數據視為機械軸已完全老化的數據,定義為失效數據,經過老化過程數據特征與失效數據特征作差可以得到健康指標值,計算方法如式(6)所示。

其中:ft為實時數據的MP 距離;ffault為失效數據的MP 距離;T為數據點MP距離的個數;HIt為第t點的健康指標值。
以4 軸的反饋力矩(tfb)為例,通過以上步驟計算出三臺機器人的反饋力矩HI數據曲線如圖9所示。
由圖9 可知,三臺機器人退化趨勢有明顯的差異,1 號機器人4軸的HI曲線下降得最快,表明1號機器人4軸退化相對快;2 號和3 號機器人4 軸的HI 曲線較1 號機器人下降較緩慢,表明2 號和3 號機器人4 軸退化相對較緩慢,實驗數據與實際相符。圖9 結果表明,本文構建的健康指標可以較好地反映出機械軸真實的退化趨勢。
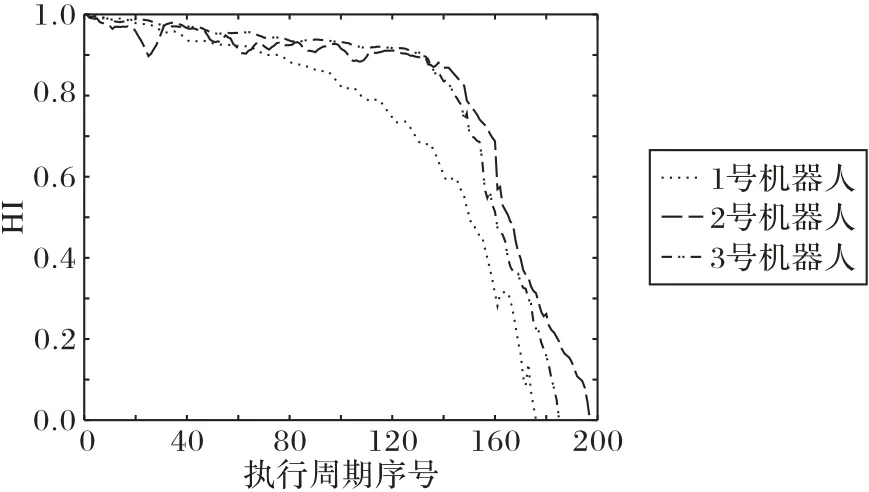
圖9 三臺機器人4軸反饋力矩的HI曲線Fig.9 HI curves of four-axis feedback torque for three robots
為進一步驗證所構建健康指標的有效性,利用常用的單調性、魯棒性和趨勢性作為構建的健康指標的評價指標,并將常用的時間序列相似性比對方法與基于MPdist的方法進行比較,結果如表4所示。由表4可知,基于MPdist、DTW、ED 和時域特征值(Time Domain Eigenvalue,TDE)四種方法構建的健康指標魯棒性相差較小,但基于MPdist方法構建的HI單調性和趨勢性最好,分別為0.5607和0.9065,相較于其他方法分別至少提高了0.07 和0.13;基于DTW 方法構建的HI 曲線魯棒性最好,但單調性和趨勢性不足;基于ED 構建的HI曲線單調性、魯棒性和趨勢性都不足。
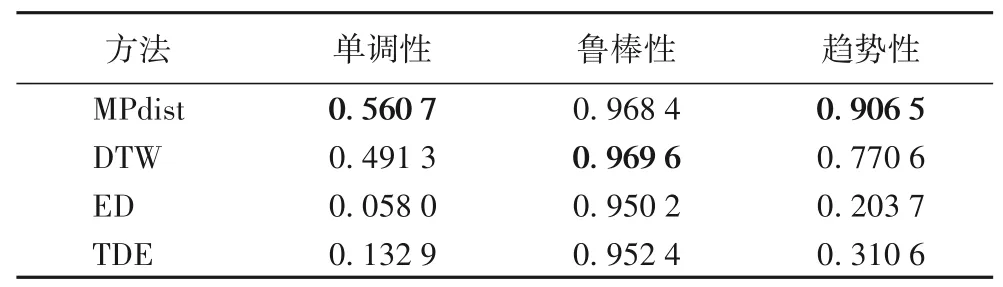
表4 健康指標評價Tab.4 Health index evaluation
機器人的機械軸執行動作具有一定的執行周期,每個執行周期執行時間有差異,且周期之間有停頓,而這樣的數據特點更符合MPdist方法共享更多相似子序列的序列更相似的特點,基于MPdist方法構建的健康指標的評測效果更好。
3.3 剩余壽命預測實驗分析
經過專家評估和經驗[25-26],以及實驗分析結果可知,在進行剩余壽命標注時,將機械軸的退化分為兩個階段,如圖10所示。機械軸運行數據訓練集中的前30%變化平緩,退化趨勢不明顯,將其設置為平穩運行狀態,剩余壽命為1。隨著老化實驗的進行,機械軸逐漸發生退化,進入退化階段,后70%的數據設置為退化狀態,隨著真實運行時間的推移,剩余壽命從1到0依次減少,直至完全失效為0。
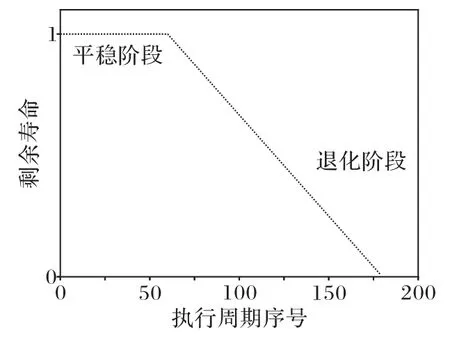
圖10 剩余壽命標注示意圖Fig.10 Schematic diagram of remaining useful life marking
基于構建好的反饋力矩(tfb)、反饋速度(vfb)和位置誤差(pe)將健康指標(HI)輸入LSTM網絡模型中進行訓練,數據集中的樣本以0.6∶0.2∶0.2 劃分訓練集、測試集與驗證集,經過調優實驗后,選擇預測模型的網絡結構由兩層LSTM 結合兩層全連接層組成。其中,兩層LSTM 網絡的隱藏神經元個數分別為128 和64,迭代次數(epochs)為200,學習率為0.01;兩層全連接層的神經元個數分別為32 和1,使用激活函數為ReLU(Rectified Linear Unit),神經網絡層的輸入輸出結構如圖11所示。

圖11 神經網絡輸入輸出結構Fig.11 Structure of input and output of neural network
LSTM 時間步長的調整過程如表5所示,時間步從3~6,預測效果逐漸變好;從6~20,預測效果逐漸變差。因此,LSTM預測模型的參數選擇時效果最好的時間步長為6,迭代次數為400。為了驗證基于MP 距離構建健康指標的有效性,將驗證集中的34 個測試樣本輸入訓練好的模型進行剩余壽命預測,比較MP 距離、DTW 距離、時域特征值結合LSTM 網絡、MPdist 結合RNN 以及LSTM 等方法進行剩余壽命預測的效果,基于MAE、RMSE和R2三種回歸預測評價指標和基于RUL預測誤差區間、早預測和晚預測等評價指標的評價結果如表6所示。
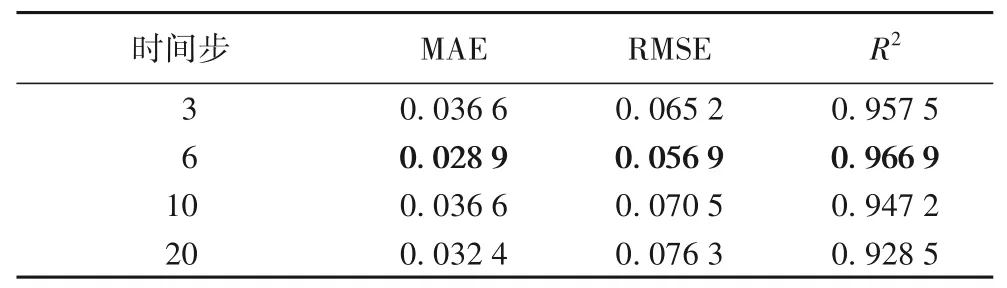
表5 LSTM網絡時間步調整評價Tab.5 Evaluation of LSTM network time step adjustment
由表6 給出的34 個測試樣本的預測評價結果可知,使用基于動作周期退化相似性構建健康指標之后的預測結果明顯優于未考慮動作周期退化、直接使用原始數據輸入LSTM 網絡的預測結果。基于MP 距離健康指標的剩余壽命預測模型的MAE 為0.0289,RMSE 為0.0569,R2為0.9669,RUL 預測的誤差區間為[-8,12],其中早預測個數為19,晚預測個數為13,均優于基于DTW 距離和基于時域特征值健康指標的預測模型,在實際工況下,為了避免故障的發生,更偏好于早預測。與MPdsit-RNN 預測結果相比,MPdist-LSTM 預測的各項評價指標也更優,基于MPdist-LSTM 的剩余壽命預測結果可視化如圖12所示。因此,本文構建的MPdist-LSTM框架是有效的,基于MP 距離構建的健康指標可以有效衡量機械軸的退化水平和預測機械軸的剩余壽命。
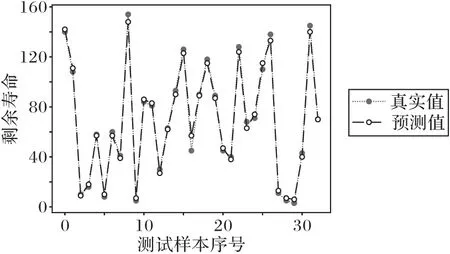
圖12 MPdist-LSTM預測結果Fig.12 Prediction results of MPdist-LSTM

表6 剩余壽命預測評價Tab.6 Evaluation of remaining useful life prediction
4 結語
針對工業機器人機械軸健康管理方面存在的低效、低精度問題,本文提出了基于動作周期退化相似性度量的機械軸健康指標構建方法,先使用MPdist 方法計算不同退化時期動作周期之間的偏離程度衡量退化水平,再結合LSTM 網絡進行剩余壽命預測。在某公司六軸工業機器人加速老化實驗數據集上進行的實驗結果表明,本文方法能準確地構建健康指標并有效地預測剩余壽命。本文主要是在單一工況下進行探索,未考慮變工況情況,未來將繼續探索變工況條件下機械軸的退化狀況,研究新的面向工藝的工業機器人預測與健康管理方法。
猜你喜歡
電腦報(2020年35期)2020-09-17 13:25:53
當代工人(2020年8期)2020-05-25 09:07:38
電腦報(2019年40期)2019-09-10 07:22:44
兒童故事畫報(2019年5期)2019-05-26 14:26:14
小溪流(畫刊)(2017年12期)2018-01-10 16:07:29
科技知識動漫(2016年8期)2016-07-29 20:40:09
Coco薇(2016年2期)2016-03-22 02:42:52
兒童故事畫報·發現號趣味百科(2015年12期)2016-01-25 00:41:49
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
