基于可拆分倒排索引的可搜索加密方案
2021-12-07 10:09:38孫曉玲楊光沈焱萍楊秋格陳濤
計算機應用 2021年11期
孫曉玲,楊光,沈焱萍,楊秋格,陳濤
(防災科技學院信息工程學院,河北三河 065201)
0 引言
隨著云計算技術[1-2]的快速發展以及大數據時代的到來,越來越多的用戶選擇將數據存儲到云服務器,以節省自身的開銷,實現便捷的多點訪問。
為了保護數據安全,數據擁有者通常將數據加密后存儲在云端。用戶對數據進行檢索和更新時,需要將所有密文數據從云端下載到本地,再進行解密、檢索和更新,隨著數據資源的激增,這種方案是無法滿足時效要求的。因此,如何在用戶提交檢索請求時,實現云端對密文數據的檢索是云數據安全存儲的重要需求。為了解決這一問題,提出了可搜索加密的概念。具體地,數據擁有者對文件進行加密,并提取文件中的關鍵詞加密以建立安全索引,將密文和索引外包給服務器,當用戶需要訪問含有某個關鍵詞的文件時,計算該關鍵詞的搜索憑證發送給云服務器,云服務器根據搜索憑證查詢索引,獲得文件標識符,將對應文件的密文返回給用戶。
可搜索加密思想最早由文獻[3]提出。第一個實際的對稱可搜索加密方案由文獻[4]提出。文獻[5]提出了一個基于前向索引(Forward Index)的對稱可搜索加密方案,采用為每個文件建立一個布隆過濾器(Bloom filter)的方法來建立索引。文獻[6-7]均采用建立前向索引的方法構建可搜索加密方案。與前向索引結構相對應的是倒排索引(Inverted Index)結構,該索引結構由文獻[8]提出。文獻[9]設計了一個完全支持動態操作的基于倒排索引的對稱可搜索加密方案。文獻[10]在文獻[9]的基礎上使用紅黑樹提出了一個支持并行和動態操作的對稱可搜索加密方案。文獻[11-13]分別提出了不同的動態可搜索加密方案,都是對文件和關鍵詞配對進行處理,文獻[14]中提出了一種在云端創建搜索索引的方案,該方案首先由用戶創建一個存儲了文件-關鍵詞映射的文件索引和一個用于存儲關鍵詞-文件映射的空的搜索索引,并提交給云端,云端在用戶提交檢索憑證時查詢文件索引獲取檢索結果,并將檢索結果添加到搜索索引中,搜索索引只存儲了已被搜索過的關鍵詞及其所在文件集合,該方案將搜索索引的構建時間分攤到了每次檢索過程中,同時提高了檢索效率,節省了存儲空間,但動態更新的效率不高。文獻[15]在文獻[14]的基礎上由云端增加了一個刪除索引,用以存儲已被搜索過的文件-關鍵詞映射,在刪除文件時,可迅速查找出被刪除文件在搜索索引中的位置,極大提高了搜索索引的更新效率。近年來,研究學者設計了許多不同功能的可搜索加密算法,比如:支持模糊搜索[16],支持多關鍵詞搜索[17],支持近似搜索[18],支持搜索結果排序[19-20],支持分塊處理[21-22]。
現有方案對可搜索加密技術在安全、效率、功能、存儲空間和動態更新等方面進行了不同程度的取舍,以適應不同應用環境的需求。隨著大數據技術的發展,海量密文存儲場景增加,如何有效利用云端資源、快速地批量更新數據,成為了新的應用需求。
本文采用了文獻[14]中的方案,用戶在本地創建文件索引,由云端在搜索過程中構建搜索索引,充分利用了云端資源,將搜索索引的存儲空間和計算時間分散到了每次搜索過程中,且對于已搜索過的關鍵詞,該方案實現了近似最優的線性搜索時間。文獻[14-15]方案中索引的存儲采用的是哈希鏈表的形式,索引的更新是單個節點的增加和刪除,要逐個進行,故文件的添加和刪除只能單個進行。本文采用了keyvalue 集合形式的存儲結構,可對索引進行合并和拆分,能夠快速實現文件的批量添加和刪除。本文方案可兼容分布式系統架構,應用于海量數據處理場合。
1 問題描述
1.1 方案對比
稱文件中的不重復關鍵詞為唯一關鍵詞,設n為唯一關鍵詞的總數,m為所有關鍵詞的總數,|F|為文件的總數,IDw為包含w的文件標識符集合,r為一次查詢中平均返回文件記錄總數,表1給出了本文方案與其他方案的各方面性能比較。

表1 不同方案的性能比較Tab.1 Performance comparison of different schemes
1.2 系統模型
云環境下密文檢索系統模型如圖1 所示,包括三個主體:數據擁有者、用戶和云服務器。

圖1 云環境下密文檢索系統模型Fig.1 Ciphertext retrieval system model in cloud environment
數據擁有者是擁有原始數據的企業或組織,要將文件集合F=(f1,f2,…,fn)存儲在云服務器,為了保障數據的安全,先使用對稱加密算法對文件進行加密,得到密文集合C=(c1,c2,…,cn),同時,對每個文件提取唯一關鍵詞構成唯一關鍵詞集合(1 ≤i≤n),對文件的唯一關鍵詞用偽隨機函數進行變換,構造key-value 形式的文件索引If,key 值為文件標識符id(f),value 為集合形式存儲的唯一關鍵詞密文,同時生成一個空的key-value 形式的搜索索引Iw,key值為由被搜索關鍵詞生成的搜索憑證,value 為集合形式存儲的包含該關鍵詞的文件的標識符,數據擁有者將密文集合C、文件索引If、空的搜索索引Iw一起提交給云服務器。當用戶想要獲取某些文件時,需利用關鍵詞對文件進行搜索,用戶從數據擁有者獲取陷門密鑰,由關鍵詞生成搜索憑證,將搜索憑證提交給云服務器。云服務器首先查找搜索索引Iw中是否有該關鍵詞的key值,有則直接返回對應的value值,若沒有,則根據搜索憑證對文件索引If進行搜索,記錄包含該關鍵詞的文檔編號集合,并在搜索索引Iw中添加該項記錄,最后返回搜索結果中的文件密文給用戶。
1.3 變量和定義
文中所用到的變量和相應定義如表2所示。

表2 所用到的變量和相應定義Tab.2 Used variables and corresponding definitions
定義1基于可拆分倒排索引的可搜索加密方案由一個五元組SIISE構成,SIISE=(Keygen,Indexgen,Search,Add,Delete),具體如下。
1)SIISE.Keygen。用戶端根據安全參數λ生成密鑰集K,分別為對稱加密和解密、帶密鑰的偽隨機算法提供不同密鑰。
2)SIISE.Indexgen。用戶端根據文件集合F和密鑰集K,生成文件索引If、空的搜索索引Iw、空的搜索歷史集合σ和加密后的密文集合C,將If、Iw和C提交給云端。
3)SIISE.Search。用戶端根據檢索關鍵詞w和密鑰集K,生成檢索憑證提交云端,并更新搜索歷史σ,云端檢索得到包含此關鍵詞的文件標識符集合IDw,同時更新搜索索引Iw。其中,未被檢索過的關鍵詞先通過搜索文件索引If獲得檢索結果并將結果添加到Iw中,已搜索過的關鍵詞可直接檢索搜索索引Iw。云端返回密文集合Cw,用戶解密得到文件集合Fw。
4)SIISE.Add。用戶端根據要添加的文件集合Fa、唯一關鍵詞集合Wa、搜索歷史σ和密鑰集K,生成文件索引Ifa、搜索索引Iwa和密文集合Ca,將Ifa、Iwa、Ca提交給云端。云端將已有的If、Iw分別與Ifa、Iwa合并,將Ca添加到密文集合中。
5)SIISE.Delete。用戶端根據要刪除的文件集合Fd、唯一關鍵詞集合Wd、搜索歷史σ和密鑰集K,生成索引Iwa,將Iwa和要刪除的文件標識符集合IDS提交給云端。云端從If中刪除由IDS中的標識符作為key 值的記錄,從Iw中拆除Iwa,從密文集合中刪除IDS中標識符對應的密文。
稱可搜索加密方案SIISE是有效的,如果對任意λ∈N,由算法Keygen生成的密鑰集K,文件集合F,對稱加密所得密文集合C,以及所有基于索引I所進行的添加、刪除等操作,任一搜索操作返回的結果都是正確的。
理想情況下,可搜索加密方案應避免云端獲取有關文件和搜索內容的相關信息,但如此高安全性的實現是以存儲消耗和搜索效率為代價的,可以允許泄露少量信息來構建更加有效的方案。采用文獻[10]中給出的方法,使用泄露函數(leakage function)來驗證方案的安全性。
定義2SIISE=(Keygen,Indexgen,Search,Add,Delete)是一個安全的動態可搜索加密方案。進行以下實驗,假設A是一個有狀態攻擊者、S為有狀態模擬器,LSearch,LAdd為泄露函數,有:

稱SIISE對自適應動態選擇關鍵詞攻擊是(LSearch,LAdd)安全的,如果對任意概率多項式算法A,存在概率多項式時間模擬器S,使得A的優勢|Pr=1]|對于λ是可忽略不計的。
2 倒排索引的構建
本文方案的核心設計是建立可拆分倒排索引,云端可獨立合并和拆分索引,實現文件的批量增加和刪除。采用keyvalue形式存儲索引,key為索引鍵值,value為集合形式的結果集,假設有表T,key 值為k,value 值為v,可表示為T[k]=v。實現的時候可直接采用哈希表結構,也可使用非關系型數據庫,與分布式系統結合,用于大規模數據場合,可獲得更高的檢索效率,更靈活的增量添加和刪除,且云端可在不依賴客戶端的前提下實現對索引的更新。
2.1 索引的構建
本文方案中,用到了兩個索引If和Iw,采用key-value 集合形式存儲。客戶端首先生成一個文件索引If,用以存儲文件標識符與其唯一關鍵詞的映射,如圖2 所示,key 為文件標識符id(f),value 為該文件的唯一關鍵詞密文集合cˉ=,H為偽隨機函數;云端在檢索過程中構建搜索索引Iw,如圖3所示,key為由關鍵詞w生成的搜索憑證τw=G(w),G為隨機函數,value 為包含該關鍵詞的文件標識符集合IDw={id(f1),id(f2),…},m為文件集合F的唯一關鍵詞個數。

圖2 文件索引If示意圖Fig.2 Schematic diagram of file index If
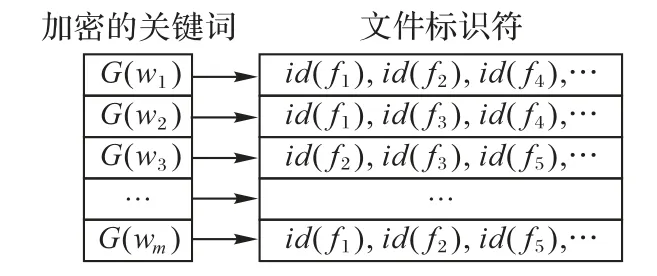
圖3 搜索索引Iw示意圖Fig.3 Schematic diagram of search index Iw
用戶檢索時,假設被檢索關鍵詞為w,根據陷門密鑰生成搜索憑證τw,提交給云端,若w不在搜索歷史中,則云端依次搜索If中的每個關鍵詞密文進行匹配,將含有關鍵詞w的文件標識符添加到Iw[τw]中,以創建表Iw的一條記錄;否則,已搜索過的關鍵詞可直接查詢索引Iw獲取搜索結果。
2.2 索引的動態更新
目前常用的索引構建方法主要有倒排索引、樹形索引和前向索引(布魯姆過濾器索引)。大部分方案中的索引構建都采用類似鏈表結構,節點之間存在依賴關系,索引執行添加和刪除操作時,只能單個節點操作,因此無法實現批量添加和刪除。
本文方案中的索引采用key-value 集合形式存儲,可實現一次性合并與刪除,適用于批量增加和刪除文件。
批量添加文件時,在本地生成添加文件集合Fa的文件索引Ifa和添加索引Iwa,這里Iwa中的key 值只需包含那些屬于Wa且已被搜索過的關鍵詞,因為云端現有的Iw中只有已被搜索過的關鍵詞記錄,只需將這些關鍵詞對應的新增文件標識符添加到Iw中相應的value 集合中即可,同時將Ifa整個合并到云端已有的If中。
批量刪除文件時,只需用相同的方法生成要刪除文件集合Fd的刪除索引Iwd,云端直接將要刪除文件的記錄從If中刪除,將Iwd中關鍵詞對應的刪除文件標識符從Iw中對應的value集合中一次性刪除。
3 方案描述
假設對稱加密方案SKE=(Gen,Enc,Dec)是抗不可區分選擇明文攻擊的,選取一個偽隨機數生成器V:{0,1}λ→{0,1}*,一個偽隨機函數G:{0,1}λ×{0,1}*→{0,1}λ,一個隨機函數H:{0,1}λ×{0,1}*→{0,1}λ,構建的方案SIISE=(Keygen,Indexgen,Search,Add,Delete)描述如下。
算法1SIISE.Keygen。



4 安全性分析
方案中的查詢和更新操作會泄露特定信息給服務端。與文獻[14-15]相同,采用文獻[5]中提出的安全標準和文獻[10]中提出的泄露函數來證明可搜索加密方案的安全性。下面用兩個泄露函數LSearch、LAdd具體給出泄露的信息內容。


5 性能測試
5.1 存儲空間復雜度
方案中使用了兩個索引If、Iw。If中存儲了文件標識符與文件唯一關鍵詞密文集合的映射,假設m為If中所有關鍵詞的總量,則If的空間復雜度為O(m)。Iw中存儲了關鍵詞的搜索憑證與文件標識符集合的映射,Iw的空間復雜度為
5.2 搜索時間復雜度
假設m為If中所有關鍵詞的總量,n為If中唯一關鍵詞總量。本文方案中,第一次搜索某個關鍵詞時,其搜索時間是與m線性相關的,當所有關鍵詞都被搜索過后,即Iw中有n個輸入,搜索時間達到近似最優。此時,進行一次查詢操作,平均返回m/n個文件。故在搜索時間達到最優值后,搜索時間復雜度為O(m/n)。
5.3 搜索時間測試
本文方案的測試中,所用環境為AMD 銳龍52400G 整合Radeon Vega Graphics 3.60 GHz,32 GB內存,64位Windows 10操作系統,開發環境為Python 3.7,IDE 為Pycahrm。使用Enron Email 20150507 測試數據集,此數據集包含517401 個郵件,共1.32 GB。
初始搜索時,需要遍歷If中幾乎所有的節點,耗時較長,隨著搜索次數的增加,Iw中記錄條數增多,搜索歷史中的關鍵詞可直接返回結果,平均耗時逐漸降低。以5000次搜索為遞增單位,給出搜索次數與搜索歷史關鍵詞數及新增關鍵詞數的統計情況,如圖4 所示,同時給出對應的平均搜索時間變化情況,如圖5所示。
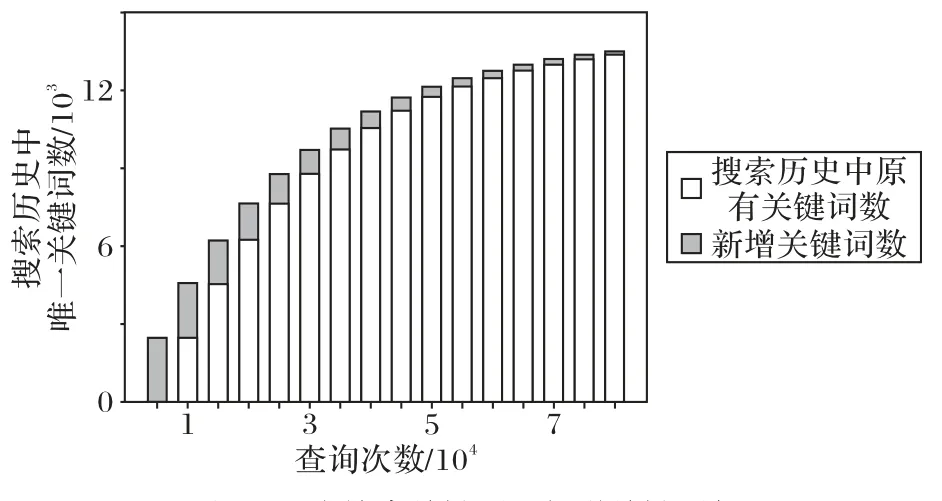
圖4 歷史搜索關鍵詞及新增關鍵詞與總搜索次數關系Fig.4 Relationship between historical search keywords,new keywords and total search times

圖5 平均每次搜索耗時與總搜索次數關系Fig.5 Relationship between average time cost in each search and total search times
5.4 動態更新時間測試
本文方案相較文獻[14]方案和文獻[15]方案的最大改進是采用key-value 結構構建索引,索引可一次性批量添加和刪除value 值,可高效實現文件的批量增刪,下面對索引添加和刪除操作進行對比測試。
對于索引If,本文方案與文獻[14]方案、文獻[15]方案這兩種方案相比,增加和刪除文件的區別在于一條記錄的增刪和多條記錄增刪,時間差別在于n次操作和單次操作的區別。
對于索引Iw,文獻[14]方案、文獻[15]方案中添加文件操作是相同的,每添加一個文件f,對f中已在搜索歷史中的每一個關鍵詞w,將id(f)添加到Iw[τw]中,添加多個文件時要逐個添加。本文方案中,對于要批量添加的文件集合,構造Iwa,將Iwa[τw]一次性添加到Iw[τw]中,圖6給出了兩種方案(本文方案和文獻[14-15]方案)的Iw添加文件耗時對比。
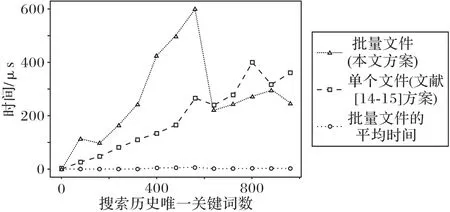
圖6 Iw添加文件在本文方案與文獻[14-15]方案的耗時對比Fig.6 Time consumption comparison of adding files in Iw between proposed scheme and scheme in literature[14-15]
文獻[14]方案每刪除一個文件,要遍歷Iw中每一項,并逐個查找Iw[τw]處列表的每個節點,直到找到所刪除文件的標識符或者到達末尾節點,若要批量刪除文件,也需要逐個刪除。本文方案中,對于要批量刪除的文件集合,構造Iwd,將Iwd[τw]一次性從Iw[τw]中刪除,圖7給出了本文方案與文獻[14]方案的刪除文件耗時對比。
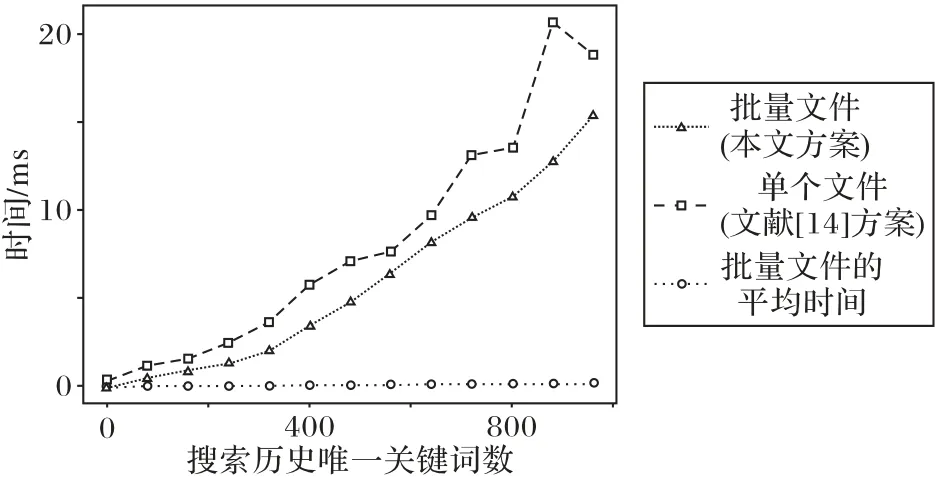
圖7 Iw刪除文件在本文方案與文獻[14]方案的耗時對比Fig.7 Time consumption comparison of deleting files in Iw between proposed scheme and scheme in literature[14]
文獻[15]方案每刪除一個文件,先查找刪除索引以確定該文件中有哪些關鍵詞已被搜索過,然后直接查找已搜索關鍵詞在搜索索引中的記錄,依次查找鏈表節點直到找到文件的標識符并將其刪除。圖8 給出了本文方案與文獻[15]方案的刪除文件耗時對比。

圖8 Iw刪除文件在本文方案與文獻[15]方案的耗時對比Fig.8 Time consumption comparison of deleting files in Iw between proposed scheme and scheme in literature[15]
6 結語
在文獻[14]方案的基礎上,基于key-value 結構構建倒排索引,本文提出了一種可對索引進行批量更新的可搜索加密方案,適用于批量數據的添加和刪除。本文索引的可合并與可拆分特性,支持云端獨立對索引進行操作,而不依賴于客戶端的狀態,可進一步應用于分布式系統,更加高效地實現海量數據處理。本文方案還可用于其他功能下的搜索方案,如多關鍵字查詢、模糊查詢等。
