基于去噪復數FastICA 和稀疏重構的相干信號欠定DOA 估計
2021-12-08 03:03:48侯進李昀喆李天宇
通信學報 2021年11期
侯進,李昀喆,李天宇
(1.西南交通大學信息科學與技術學院,四川 成都 611756;2.西南交通大學綜合交通大數據應用技術國家工程實驗室,四川 成都 611756;3.西南交通大學唐山研究生院,河北 唐山 063000)
1 引言
實際的通信環境中,多徑效應導致存在大量相干信號,使入射信號的數量超過傳感器的數量的現象普遍存在。在這樣的復雜環境中,現有的到達角(DOA,direction of arrival)估計方法將失敗。DOA估計還有一個重要的目標就是在大量噪聲的情況下,定位間隔較小的信號源。許多經典的DOA 估計技術通過利用少量源的存在來實現超分辨率。例如,Krim 等[1]研究的多重信號分類(MUSIC,multiple signal classification)算法的關鍵部分就是低維子空間的假設。因此,需要針對以上情況尋找一種新的DOA 估計方法。
目前,DOA 估計方法可分為三類:基于子空間的方法、基于獨立分量分析(ICA,independent component analysis)的方法、基于稀疏重構的方法。當傳感器和時間樣本足夠時,除MUSIC 算法,Esfandiari 等[2]和Zhuang 等[3]研究了其他基于子空間的方法,該類方法利用信號和噪聲子空間之間的正交性來估計信號源的DOA。但是,當入射信號的數量大于傳感器的數量時,這些算法因為噪聲子空間的消失都會失去最佳性能。
當入射信號的數量不大于傳感器的數量時,基于ICA的方法可以實現信號的盲分離和DOA估計,其中分離再測向有助于多信源的 DOA 估計。Zamani 等[4]和Johnson[5]通過ICA 與波束合成結合,提高算法的收斂速度,但這些方法只能解決獨立信號的DOA 估計問題。對于相干信號,基于ICA 的方法的性能將嚴重下降。基于稀疏重構的方法可以根據不同的稀疏重構算法分為三類:Trinh-Hoang等[6]探究的基于匹配追蹤(MP,matching pursuit)的方法、Malioutov 等[7]和Soubies 等[8]探究的基于lp范數的方法、Hu 等[9]和Huang 等[10]探究的基于稀疏貝葉斯學習(SBL,sparse bayesian learning)的方法。與基于子空間的方法和基于ICA 的方法相比,基于稀疏重構的方法在低信噪比(SNR,signal-to-noise ratio)、小樣本和信號相干的情況下可以獲得更好的性能。但是需要入射信號的數量小于傳感器的數量。對于欠定情況,仍然無法解決相干信號DOA 估計問題。
針對現有算法的不足,本文提出了一種基于ICA 和稀疏重構的DOA 估計方法。ICA 算法中的快速獨立主成分分析(FastICA,fast independent component analysis)算法具有收斂速度快、易使用等優點,故本文使用FastICA 算法進行信號盲分離。首先,通過FastICA 算法估計陣列流形;然后,將陣列流形中的導向矢量視為陣列輸出的單個時間樣本,并通過稀疏重構來估計分離后的獨立信源的DOA,獨立信源可能包含相干信號和非相干信號。理論分析和仿真與實測實驗結果表明,該方法可以解決欠定情況下相干信號的DOA 估計問題,并能進行多個非相干圓或非圓信號的DOA 估計。
2 系統模型
假設有M個陣元的均勻圓陣(UCA,uniform circular array),如圖1 所示。該圓形陣列接收N個入射復數獨立信源,包含NI個非相干復信號源和K組相干復信號源,則獨立信源總數為N=NI+K,這些信號源位于不同方向的陣列遠場中。其混合模型可以寫成n
θ為第n個信號的波達方向角,λ為信號的波長,r為均勻圓陣的半徑;n(t)為均值為0 的加性白高斯噪聲。
當信號為相干信號時,假設第k個入射源信號sk(t)包含Lk個相干信號,這些相干信源從θlk方向入射到陣列上,其中lk=1,2…Lk。假設在θlk中有2 個相關信號sik(t)和sjk(t),則兩信源的相關系數表示為
由Schwartz 不等式可知|μlk|≤ 1,故信號間的相關性定義為
由以上定義可知,當信源相干時,相干信源之間只相差一復常數。陣列相干信號的數據模型應調整為
若信源中存在K組相干信號,相干信源總數為,則入射信源總數即L=NI+Nk。
在實際環境中,由于相干信號存在,很可能導致入射信號的數量大于陣列傳感器的數量(即L>M)的現象。在這種情況下,現有方法無法成功估算DOA。基于子空間的方法和基于稀疏重構的方法都僅在L
通過分析可知,存在相干信號情況下的陣列數據模型只有陣列流形矩陣A不同,顯然,當獨立信源數小于陣元數,即N≤M時,可以使用ICA 方法估計A。但是由于相干信號的影響,DOA 的估計變得更加復雜,不能用傳統的方法估計DOA。針對這一問題,需要尋求一種新的DOA 估計方法。
觀察可以發現,式(2)類似于陣列數據模型。當Lk個相干信號同時入射到擁有M個陣元的陣列時,導向矢量an可以看作陣列輸出的單個時間樣本。由于陣列輸出只有一個時間樣本,基于子空間的方法和基于ICA 的方法都不能工作。近年來提出的基于稀疏重構的方法在單時間樣本條件下仍能成功地估計到達角。
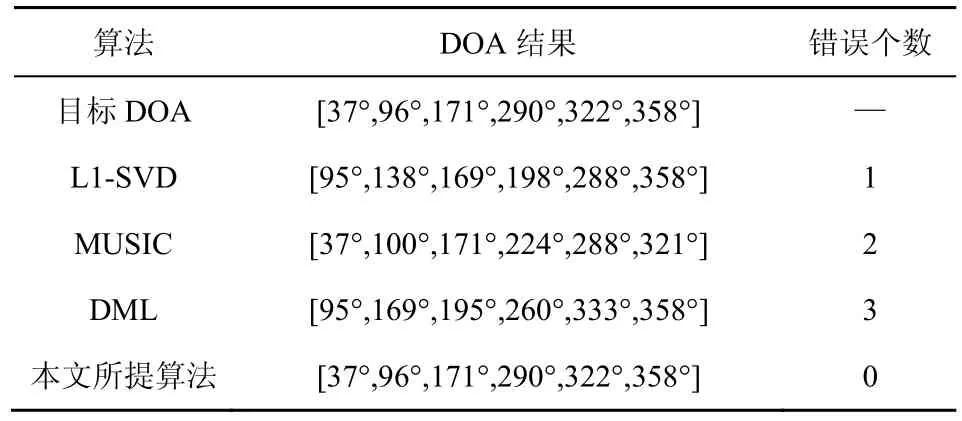
如果Lk 一般復數信號ICA 模型為 ICA 的目標是找到一個解混矩陣W,當式(4)中y的所有分量都是獨立的時,W達到其最優值。y為M個信源s的估計值,故WA=I,A=W?1,此時W?1為陣列流行矩矩陣A的估計。 真實的應用中往往存在噪聲,含噪聲復數信號ICA 模型為 一般情況下,獲取的觀測數據都具有相關性,需要對數據進行去相關處理。白化是一種常見的去相關方式,主成分分析(PCA,principal component analysis)可用于白化處理,其具有降維功能,可以去除信號噪聲的干擾。在觀測信號的維度數大于實際獨立信源的個數,即M>N時,可以經PCA 降維使觀測信號與實際信源數相等。經過白化后觀測數據的協方差是單位矩陣,各維數據不相關。故經過PCA 處理可以降低觀測數據的維度,且去除各觀測數據間的相關性,從而降低在ICA 中問題的復雜度。 使用PCA 對數據白化,首先,對觀測數據x各個分量進行中心化,即 使用中心化后的數據計算協方差矩陣,即R=E{xxH}∈CM×M,對R進行奇異值分解R=UΣVH,其中U、V分別為M×M的左、右奇異向量矩陣,且均為酉矩陣;Σ為M×M的奇異值對角矩陣。 ICA 的前提條件是獨立信源的準確估計,當非相干信源與相干信源共存時,獨立信源數N=NI+K。Bazzi等[12]提出了一種改進的MDL(MMDL,modified minimum description length)算法,在含噪聲觀測數據、快拍數較少的情況下,對信源估計的準確率優于傳統MDL。使用MMDL 方法估計出獨立信源數N,取U中前N列的向量組成UN,對數據進行PCA 降維處理,即 經過PCA 降維后,對降維數據進行白化處理,白化后的數據滿足。降維后的每一維數據是獨立的,為確保每一維數據具有單位方差,需對每一維數據除以標準差來進行縮放,則白化后的數據為 降維白化矩陣可表示為 數據經過白化處理后,在復數FastICA 算法[13]中,代價函數為 其中,G為非線性函數,常見的形式有G1(y)=y2,;y為自變量;b為任取的常數值,通常b=0.1。 Bingham 等[13-14]提出復數FastICA 算法的圓性信號學習規則為 Novey 等[15]提出復數FastICA 算法的非圓信號學習規則為 要進行N個信源的估計,需進行N次迭代計算,最終解混矩陣WH=[w1,w2,…,wN]∈CN×N,在完成所有迭代后,對W進行對稱正交變換,去除W間的相關性,避免wn收斂到相同極值,即。 除噪復數FastICA算法具體步驟如算法1所示。 算法1除噪復數FastICA 算法 當SNR 較大的情況下,噪聲對信號的影響可以忽略,使用上文中的除噪算法,在計算時只選取信號子空間,使用PCA 進行降維直接去除噪聲的影響。當信噪比SNR 較小時,需要考慮到噪聲對信號的影響。 使用式(6)對觀測數據進行中心化,并計算協方差矩陣R=E{xxH}∈CM×M。對協方差矩陣進行奇異值分解,即 奇異值對角矩陣Σ理論上應滿足如下關系:。 奇異值前N個對應信號子空間,后M?N個對應噪聲方差δ2。但在實際計算時,這些奇異值往往不是相同的值,故無法直接得到噪聲方差δ2。 若已知獨立信源數N,通過噪聲子空間特性,可近似估計噪聲方差 則N個信源組成的信號子空間奇異值矩陣為 依據白化原則,對觀測數據進行降維和去相關線性變換,因為去噪白化操作后的數據不再滿足協方差矩陣為單位矩陣,用“近白化”代替白化,則近白化矩陣為 其中,UN為矩陣U的前N列。 近白化后的觀測矩陣為 經過去噪變換后,近白化后的數據協方差矩陣不再是正交矩陣,結合式(14)推導及,可得 Bingham等[13]和Novey等[15]在對式(12)和式(13)的推導中均使用了近似關系E{uuHf(u)}≈E{uuH}E{f(u)},其中,u為白化處理后的數據E{uuH}=I,故 依據式(20)推導結果,在去噪情況下式(22)應為 根據以上推導,去噪復數FastICA 算法的學習規則為 信源s的估計表示為 去噪復數FastICA算法具體步驟如算法2所示。 算法2去噪復數FastICA 算法 上述2 種去噪算法中,算法1 直接使用PCA去除噪聲部分,針對信號強度相當、信噪比高、噪聲影響小的情況,利用白化處理把觀測信號全部投影到信號子空間,在復數FastICA 中也沒有考慮噪聲的影響。算法2 適用于存在微弱信號或噪聲過強等強干擾的情況,根據噪聲高斯、獨立性,對噪聲進行了估計,在白化處理中,在信號子空間中減去噪聲方差,濾除信號子空間中噪聲的干擾,并在復數FastICA 算法的迭代中,考慮了噪聲的影響對學習規則進行改進,使盲分離算法更適用于存在噪聲的情況和微弱信號的提取。 從ICA 的角度來看,接收到的陣列數據是由不同方向接收到的獨立信號混合而成的。混合矩陣為A,可以用復數FastICA 估計分離矩陣,則A可以用分離矩陣來估計。 對A中的每一列進行稀疏重構,稀疏重構是由觀測向量重構稀疏信號的過程。只要滿足信號稀疏或可壓縮條件,就可用一個觀測矩陣對矩陣進行稀疏表示,稀疏表示后的信號越稀疏則重建后的精度就越高,所包含的信源DOA 信息越全面。對于稀疏表示的信號,通過求解一個優化問題就能近似地重構信號。觀測信號中信源具有稀疏性,且每次都對A中一列即單個獨立信源進行重構,稀疏重構理論正是運用信號在觀測空間上的稀疏特性來實現對入射信號角度估計的。 經過以上2 種算法分析計算,假設已經使用算法 2 估計去噪白化處理后的陣列流行矩陣,其中#表示矩陣的偽逆。雖然ICA不能識別出矩陣A的導向向量順序,但在本文所提DOA 估計方法中并不會產生影響。假設an是的第n列即第n個信源的導向向量。算法的目標就是通過估計的導向向量an,求得其中非相干信源的到達角度nθ或相干組信號到達角度θ1,θ2,…,θlk。 為將導向向量an作為稀疏表示問題,引入一個包括所有可能入射信號DOA 的過完備字典D,假設Θ=[α1,…,αQ]是所有可能的DOA 組成的抽樣網絡。矩陣Θ中的列表示潛在入射信號DOA 對應的導向矢量,D=[d(α1),d(α2),…,d(αQ)], D是已知的,并且與信號源的實際位置無關。的空間過完備表示為 其中,為小噪聲部分,v=[v1,v2,…,vQ]。如果α q=θlk,則v q=μlk;否則vq=0。將DOA 估計問題轉化成v的稀疏譜問題,v中包含入射信號的真實DOA 處主峰。可以解決式(27)的逆問題,通過L1 范數的方法將其正則化,使其有利于信號稀疏。最小化v的空間譜,則代價函數為 由于目標函數的數據是復數值,因此,無論是線性規劃還是二次規劃都不適用于其優化。此時,可以采用二階錐規劃(SOCP,second order cone programming)[16],把復數凸優化問題轉化成SOCP問題,使在內點方法(IPM,interior point method)框架下實現高效的全局收斂算法。 把L1 范數形式轉化為SOCP 形式。根據Lobo等[17]對SOCP 的推導與分析。把式(28)轉換成SOCP形式,使用輔助向量e和f把目標函數進行線性表示,將非線性部分代入約束條件,則優化目標可轉換成如下形式 故SOCP 最終優化問題表示為 式(30)中重要的部分是正則化參數β的選擇,其平衡了實際問題中數據的擬合和稀疏性。Malioutov 等[6]所提的L1-SVD 算法中已經給出關于β的選擇方法。β參數的選擇是稀疏重構的關鍵,在文獻[6]中β的選擇與信噪比有關,需要根據噪聲的大小分情況多次計算,特別是在信噪比較小的情況下,參數選擇過程較復雜。但在本文中,陣列流行矩陣A的估計經過去噪處理,其中噪聲已進行濾除,存在較小的噪聲。此時,只需保證β盡可能小,且滿足,β選擇一個較小的固定值進行計算,即可進行信號稀疏。 本節算法具體步驟如算法3 所示。 算法3基于復數FastICA 與稀疏重構的DOA估計 基于ICA 的算法最多能處理M個獨立信源。在單個時間樣本的情況下,稀疏重構算法最多能處理個入射源信號[18],因此本文所提算法最多能夠處理個入射信號。實際上,如果源信號的幅值滿足隨機分布,那么稀疏重構算法能夠處理s的入射信號數可以達到M?1個。因此,本文所提算法最多能夠處理M(M?1)個入射信號。例如,當陣列傳感器數量為3 時,該方法可最多可以處理6 個入射信號,其中3 組相干信號,每組相干信號包含2 個相干信號。 在復數FastICA 算法之前,使用PCA 預處理方式。對于陣列流行矩陣A而言,若信源數與陣元數相等,A需要估計M2個元素,經過白化后A的待估計個數降為M(M?1)/2,且A的估計為,白化矩陣經過PCA降維處理為M×N,故W只需估計N2個元素,即A只需估計N2,大幅減少了FastICA 計算量,提高了算法的運算效率。 為驗證ICA 算法的分離效果,仿真實驗使用Amari 指數[19]對除噪FastICA 算法和去噪FastICA算法的分離信號性能進行評估。Amari 指數的定義為 其中,N代表信源數;P=WHCwhiteA=FA,即分離矩陣與混合矩陣A的積。IA∈[0,1],10logΙA的值代表分離效果,值越小分離的效果越好,若10logIA 為驗證本文所提2 種去噪算法在不同信噪比下的分離效果,使用非線性復數FastICA 算法[15]進行對比實驗。進行仿真實驗,經過500 次蒙特卡羅實驗,在九陣元均勻圓陣,3 個非相干入射信號[30°,260°,120°],中心頻率為500 MHz,快拍數L=500,陣元半徑為0.58 m,對3 個信號進行盲分離,分離效果如圖2 所示。 從圖2 可以看出,當信噪比為[?20 dB,20 dB]時,3 種FastICA 算法均能達到較好的分離效果。當信噪比為[?20 dB,?8 dB]時,去噪復數FastICA 算法優于除噪復數FastICA 算法,平均要好約?1 dB。當信噪比大于?5 dB 時,2 種去噪算法的性能趨于一致。非線性復數FastICA 算法的性能由于沒有去噪降維處理,性能整體弱于2 種去噪算法,平均差約?4 dB。 對算法收斂性進行分析,SNR=?5 dB,經過500 次蒙特卡羅實驗,在門限設置為10?12、最大迭代500 次情況下,收斂次數對比如表1 所示。非線性FastICA 算法迭代次數平均為68 次,遠高于所提的2 種去噪算法。除噪復數FastICA 算法與去噪復數FastICA 算法均表現出良好的算法性能,在迭代15 次以內就取得良好的收斂性。 表1 3 種FastICA 算法收斂次數對比 通過非線性FastICA 算法與2 種去噪FastICA算法的分離效果和收斂性能分析實驗,可以看出去噪確實提高了對盲信號的分離性能,特別是算法的收斂速度得到明顯提高,分離效果也得以提高。去噪復數 FastICA 算法整體表現優于除噪復數FastICA 算法。 為驗證 DOA 估計算法的有效性,使用L1-SVD[6]、MUSIC[1]算法和極大似然估計(DML,deterministic maximum likelihood)[1]與本文所提算法進行對比,分別進行實測數據實驗、相干信號欠定仿真實驗、非相干信號超定仿真實驗、低信噪比和信源小間隔實驗等,對算法的性能進行分析驗證。 使用九陣元圓陣接收機,接收機陣元半徑為0.58 m,中心頻率為600 MHz,快拍數為8 192。采集實際數據,其中包含一個非相干信號103°及一組相干信號[256°,320°],根據MMDL 判斷獨立信源數N為2。 表2 給出了真實采集數據的情況下,子空間經典算法、L1-SVD 與本文所提算法的DOA 估計結果。因為有相干信號與非相干信號同時存在,在沒有進行解相干的情況,直接判斷信源個數,故觀測信號中只包含2 個獨立信源數,MUSIC 算法和DML 算法都依賴于信源數的準確性,故只能測出2 個信源的DOA。L1-SVD 法和本文所提算法在只提供獨立信源數的情況下,仍然可以得到3 個信源的DOA,在本次實驗中,L1-SVD算法對其中一個信源320°的結果存在1°偏差,本文所提算法的測向結果較為準確。 表2 實測3 個信源數據在不同算法下DOA 估計結果 3 種算法在包含相干與非相干實測信號空間譜圖如圖3 所示。從圖3 可以看出,3 種算法均在3 個目標信源DOA 處產生譜峰。但是在只有2 個獨立信源的前提下,MUSIC 只能得到2 個信源DOA 結果。 表3 是實測6 個信源數據的DOA 結果,使用MMDL 估計信源數N為6。在實際應用中,DML 對多信號的測向效果較差,MUSIC 及L1-SVD 算法存在不同程度的錯誤,本文所提算法仍保持良好的性能,對于多信號測向表現出較強的分辨力和穩定性。 表3 實測6 個信源數據不同算法DOA 結果 為驗證算法對相干信號欠定情況,本文對M(M?1)個相干信源的分辨性能進行了仿真實驗,在陣元數為3 的均勻圓陣,信號的中心頻率為500 MHz,陣元半徑為0.58 m,快拍數L=200,信噪比為10 dB,生成3 組相干信號。通過去噪復數FastICA 算法估計出陣列流行矩陣。對的每一列數據采用L1 范數稀疏重構算法,得到三組相干信號空間譜。欠定情況下基于子空間的MUSIC 等方法失效,因此,實驗對比了L1-SVD 與本文所提算法性能,如圖4 所示。 L1-SVD 算法只生成了5 個譜峰,在[21°,220°]目標角度正確出現譜峰,由于[82°,92°]和[150°,153°]兩兩之間角度間隔較小,此算法只在兩組信源中間位置產生峰值,在360°處產生一錯誤峰值,L1-SVD法在本實驗中表現較差。本文所提算法在三組相干信源的真實DOA 處均出現峰值,每組相干信號的真實DOA 處分別產生2 個峰值。 下面的仿真實驗驗證了本文所提算法對最大數量非相干信源分辨性能。在六陣元均勻圓陣,信號的中心頻率為500 MHz,陣元半徑為0.58 m,快拍數L=200,信噪比為?5 dB,生成6 個非相干信源[30°,60°,120°,150°,180°,210°]。當信源數與陣元數一致時,基于子空間的MUSIC 算法將失效,因此,實驗對比了L1-SVD 與本文所提算法的性能,如圖5 所示。 從圖5 可以看出,2 種算法均可測出6 個信源的DOA,但L1-SVD 算法在最后一個信源,即210°處有少許偏差,本文所提算法對6 個信號均能準確定位。 本文所提算法有一個重要的特性就是可以分辨間隔較小的信源,且對噪聲有良好的穩健性。將這2個性能結合在一起進行分析。對于超分辨方法來說,分辨率取決于信噪比,如超分辨率方法MUSIC[1]在高信噪比時顯示出良好的分辨率,但一旦噪聲變得顯著,它們的分辨率開始下降。DML[1]在初始化良好的情況下性能較好,但在低信噪比下存在類似的穩健性問題。由于去噪復數FastICA 和稀疏重構算法的結合使用,本文所提算法可以承受更高水平的噪聲。 在九陣元均勻圓陣,3 個入射信號分別為15°、20°、25°,快拍數L=200,信噪比為?10 dB,中心頻率為500 MHz,陣元半徑為0.58 m 條件下,MUSIC、L1-SVD 和本文所提算法進行低信噪比、小間隔仿真實驗,結果如 圖6~圖8 所示。 從圖6 和圖7 可以看出,在低信噪比、小間隔情況下,MUSIC 和L1-SVD 算法都只能得到2 個信源對應的角度,無法得到正確DOA。從圖8 可以看出,本文所提算法分別得到3 個信源對應的正確DOA,對噪聲穩健性強,且可定位小間隔的信源。 本文提出了一種基于去噪復數FastICA 和稀疏重構的DOA 估計方法,與傳統DOA 方法相比,該方法可以解決入射信號總數欠定情況下,相干信號的DOA 估計問題。當陣列傳感器數量為M時,本文所提算法最多可以處理M(M?1)個入射信號。該算法也同樣適用于陣元數與信源數相等,即M=N情況下非相干信源的DOA 估計,以及非相干與相干信號共存的DOA 估計;而且,在低噪聲、小信源間隔的情況下仍表現出良好的分辨率。經過理論分析、實際數據實驗和仿真實驗均可證明該算法的有效性。3 復數FastICA 算法
3.1 除噪復數FastICA 算法
3.2 去噪復數FastICA 算法
4 基于稀疏重構的DOA 估計
5 性能分析
6 實驗仿真分析


7 結束語
猜你喜歡
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
中國生殖健康(2019年3期)2019-02-01 06:12:26
Coco薇(2016年2期)2016-03-22 02:42:52
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
海軍航空大學學報(2015年3期)2015-11-11 17:20:00
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
