捕獲效應下基于比特檢測的多分支樹RFID 標簽識別協議
2021-12-08 03:04:08張莉涓范明秋雷磊王勇袁代數
通信學報 2021年11期
張莉涓,范明秋,雷磊,王勇,袁代數
(1.南京航空航天大學電子信息工程學院,江蘇 南京 211106;2.西南交通大學物理科學與技術學院,四川 成都 610031;3.中興通訊股份有限公司,江蘇 南京 210012)
1 引言
射頻識別(RFID,radio frequency identification,)技術作為物聯網感知層獲取物品信息的重要關鍵技術之一,被廣泛應用于各行各業,如倉儲管理、物流追蹤、藥品監管和食品鏈監察等[1]。RFID 系統主要由一個或多個閱讀器以及大量附著在物品上的電子標簽組成,且每個標簽擁有一個全球唯一的ID 信息(即EPC(electronic product code))。閱讀器和標簽通過詢問應答方式通信,當有多個標簽同時響應閱讀器的詢問請求時,標簽信號發生碰撞,嚴重影響閱讀器的識別性能[1-4]。合理的標簽防碰撞協議可以有效提高識別性能,然而傳統研究較少考慮捕獲效應對識別過程的影響。
在被動式RFID 系統中,標簽通過電感耦合或電磁反向散射方式獲取能量并反饋響應信息。受信道衰落的影響,標簽反饋信號強度差異較大。當有多個標簽同時回復信息時,某一標簽的信號強度可能遠大于其他所有標簽的信號強度之和,此時閱讀器可以成功解碼該標簽的響應信息,該現象被稱為捕獲效應[5]。當捕獲效應發生時,原本的碰撞時隙將轉換為成功時隙,閱讀器可以成功解碼信號最強的標簽信息,而其他強度較弱的標簽信號將被覆蓋,造成標簽漏讀,嚴重影響識別過程。
傳統研究主要考慮捕獲效應下Aloha 類標簽防碰撞算法的識別性能優化問題。王陽等[6-8]提出的最大后驗概率估計(CMAP,capture-aware maximum posterior probability estimate)算法采用貝葉斯對捕獲概率和標簽數量進行估計,并以此設置動態幀時隙Aloha 算法的最優幀長。Salah 等[9]則根據丟包率和捕獲效應發生概率之間的關系獲得不同信噪比條件下的捕獲概率,并給出不同時隙長度和捕獲概率影響下的最優幀長設置表達式。Nguyen 等[10]通過估計捕獲概率和誤檢率來提高Aloha 算法的識別性能。總體來說,這類方法主要通過估計捕獲效應發生的概率,調整幀長參數,增加成功時隙的比例,但沒有考慮由捕獲效應造成的標簽漏讀問題。
近年來,捕獲效應下RFID 系統的可靠識別性能受到越來越多的關注。Wu 等[11]提出了捕獲效應下基于查詢樹(QT,query tree)協議的隱藏標簽處理方法,即通用查詢樹(GQT,general query tree)協議。該方法通過重復添加成功時隙相對應的查詢前綴,獲取隱藏標簽的信息。但由于每個成功時隙所對應的查詢前綴都執行了兩次,識別效率較低。Lai 等[12]提出了通用樹分裂(GBT,general binary tree)協議,通過閱讀器發送確認信息靜默已識別的標簽,標記相應的隱藏標簽便于下一輪識別,并通過多次執行該識別過程,解決標簽漏讀問題。采用類似的靜默和標記方法,Choi 等[13]提出了捕獲感知 CA-CRB(capture-aware couple-resolution blocking)協議識別隱藏標簽,但是重復發送完整的ID 信息對標簽進行靜默和標記,增加了較多額外開銷,識別時間長。Wu 等[14]結合Q 協議和二叉樹協議提出自適應的ABTSA(adaptive binary tree slotted Aloha)協議,通過在成功時隙中回復隨機數確認信息標記隱藏標簽以減少通信開銷,提高識別效率。
綜上,已有研究主要基于傳統的Aloha 或分支樹協議解決捕獲效應下的標簽識別問題,識別過程中產生了較多的空閑時隙和碰撞時隙,且對隱藏標簽的處理,增加的通信開銷較多,整體識別效率低。本文通過設計合理的標簽數量估計和高效可靠的標簽識別算法來提高捕獲效應下的標簽識別效率。
在多數RFID 系統中,標簽數量通常未知,合理的標簽數量估計可以有效提高識別效率。傳統的標簽數量估計算法采用每幀中的時隙統計信息與理論預期值之間的關系對標簽數量進行估計,時隙開銷較大。為此,Chen 等[15]提出提前中斷的估計方法,即在每幀中采用逐時隙估計的方式,提前結束幀長設置不合理的幀,減少時隙開銷。隨后Su等[16]提出設置固定檢查點和離線表格方式,進一步降低計算復雜度。由于這類算法在前期獲得的統計信息較少,估計不準確,所需時隙數較多。
在標簽識別算法中,基于比特檢測的樹分支類算法具有較高的識別效率。Jia 等[17]提出的碰撞樹(CT,collision tree)算法將發生碰撞的標簽分成不相交的2 個子集,并通過比特檢測技術獲得每個子集中標簽的最長共同前綴,從而消除空閑時隙。隨后,Landaluce 等[18]提出的碰撞窗口樹(CwT,collision window tree)協議采用啟發式方法加速識別過程。Zhang 等[19]提出的多分支樹碰撞(MCT,M-ary collision tree)協議將發生碰撞的標簽分裂成多個子集,進一步縮短識別時延。但是,這些協議并沒有考慮捕獲效應對識別過程的影響。
為了有效提高捕獲效應下標簽可靠識別的效率,本文提出基于比特檢測的多分支樹標簽識別(BMT,bit-detectingM-ary tree)協議,主要貢獻如下。
1) 提出基于比特檢測的快速標簽估計算法,初步估計待識別標簽的數量。通過將標簽的隨機選擇信息融入標簽回復信息中,提供標簽數量估計統計信息,減少估計階段的時隙開銷。
2) 提出基于比特檢測的多分支樹標簽識別協議。閱讀器利用比特檢測技術從標簽回復信息中獲取標簽的時隙選擇情況,有效消除空閑時隙,提高識別效率。并提出基于哈希靜默的方法減少對隱藏標簽處理的通信開銷。
3) 建立多分支樹概率模型分析BMT 的時隙開銷和系統效率,并通過仿真對比從多方面驗證BMT協議的有效性。
理論分析和實驗結果充分證明了BMT 協議能夠有效解決捕獲效應造成的標簽漏讀情況,且相較于已有協議,BMT 協議的識別時間縮短了至少15%。
2 系統模型
考慮一個典型的靜態RFID 系統,如圖1 所示,該系統由閱讀器、后端數據庫和大量被動式標簽組成。閱讀器和所有標簽共享無線信道,且在識別之前閱讀器沒有任何關于標簽數量和ID 的先驗信息。閱讀器和標簽之間采用詢問應答模式進行通信,標簽只有簡單的計算、存儲和通信能力,標簽之間互不通信。與大多文獻[6-14]中給定捕獲概率的固定值不同,本文定義了被動式RFID 系統中的級聯信道模型,以獲取不同信道環境影響下捕獲效應發生的概率,有效分析捕獲效應對識別算法的性能影響。
系統的通信鏈路包括前向信道和反向信道2 個部分,閱讀器通過前向信道發送查詢命令并提供連續載波信號,標簽通過反向散射方式從閱讀器的載波信號中獲取能量,并反饋回復信息[20-21]。閱讀器收到的標簽回復信號功率需綜合考慮級聯信道中前向和反向鏈路損耗。令Ptx為閱讀器的發射功率,標簽接收到閱讀器信號的功率Pr,T為[20-21]
其中,ρL為閱讀器與標簽天線匹配的極化損耗因子(PLF,polarization loss factor),GR和GT分別為閱讀器和標簽的天線增益,L(df)為閱讀器與標簽相距df時前向信道的大尺度路徑損耗,|hf|為前向信道的小尺度衰落隨機系數。標簽通過反向散射方式獲取能量并回復,故閱讀器收到某一標簽的回復信號功率Pr,R為[20-21]
其中,τ為歸一化系數,表示由編碼和調制方法所導致的閱讀器接收功率差異;μT為標簽芯片與天線間的功率傳輸效率;上標和下標中的f 和b分別表示前向和反向鏈路,下標中的R 和T 分別表示閱讀器和標簽;Γ為標簽反射系數差值。考慮自由空間路徑損耗模型可得L(d)=[λ/(4πd)]2,鏈路衰落系數|h|可由Rician 分布或Rayleigh 分布模型獲得。
根據功率模型,定義RFID 系統中的標簽捕獲效應如下:當有k個標簽同時發送信號時,如果某一標簽的信號強度遠大于其他所有標簽的信號強度之和,捕獲效應發生,即
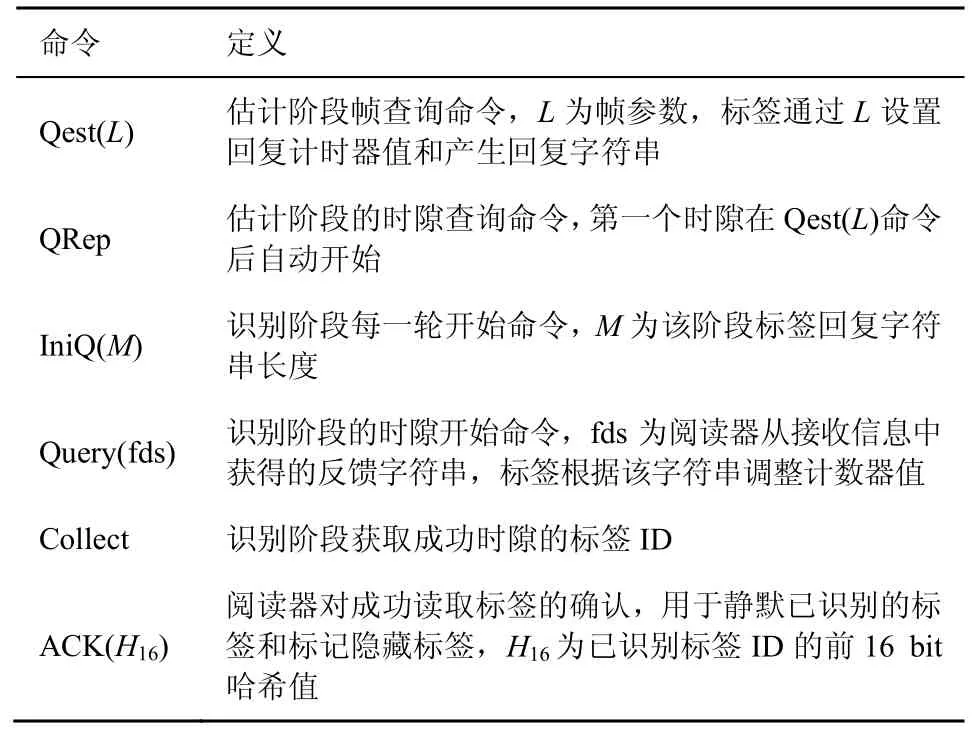
其中,Z為功率比門限(PRT,power ratio threshold)[5],是閱讀器成功接收信號所需要的最小載波干擾比,其值與調制方式和編解碼方法有關,對于一般的窄帶系統,1 由式(1)~式(4)可得,當有k個標簽同時發送信息時捕獲效應發生的概率qk。采用文獻[20-21]中的射頻參數設置,圖2 給出了當閱讀器的讀取范圍為3 m 時,不同參數條件下2 個標簽同時發送信息的捕獲概率。從圖2 中可以看出,當Kf=Kb=?∞時,傳輸鏈路中缺乏可視通路,捕獲效應發生概率較高;當Kf=Kb=10 dB 時,傳輸鏈路處于強可視環境,此時發生捕獲效應的概率有所降低。 此外,從圖2 還可以看到,隨著功率比門限的增加捕獲概率下降顯著,因此本文主要分析功率比門限對捕獲概率和識別算法的影響。考慮典型室內RFID 應用場景,圖3 給出了當Rician 分布參數Kf=Kb=10 dB 時,捕獲概率的理論值和指數擬合情況。 通過曲線擬合,可得捕獲概率的近似表達式為qk=eaz+b,各參數如表1 所示。 表1 捕獲概率擬合曲線參數 本文提出的BMT 協議包括2 個階段:基于比特檢測的標簽數量快速估計和多分支樹可靠識別。在估計階段,閱讀器采用少量時隙對標簽進行初步估計和預分組,該階段采用幀時隙方式將時間分為幀,每一幀包括多個時隙。閱讀器在每一幀開始時廣播Qest(L)命令,告知所有標簽當前幀參數L,該幀中的第一個時隙在該命令之后自動開始,其余時隙由閱讀器的QRep 命令開啟。在識別階段,閱讀器構造多分支樹結構提高識別效率,該階段通過逐時隙的方式進行識別,閱讀器在每個時隙開始時廣播Query(fds)命令通過fds 字符串反饋所有標簽的時隙選擇情況。表2 給出了BMT 協議用到的命令和定義。 表2 命令和定義 在BMT 識別過程中,標簽將其時隙選擇信息融入回復信息中,閱讀器通過比特檢測技術從碰撞信息中獲悉標簽選擇情況,以此對標簽進行估計和識別。比特檢測技術被廣泛應用于RFID 標簽防碰撞協議設計[17-19,22-26],閱讀器通過比特檢測技術可以有效定位碰撞時隙中發生碰撞的比特位置。 比特檢測技術可以通過曼徹斯特編碼實現,該編碼采用電平的跳變來表示“0”或“1”,即每個碼元均用兩個不同相位的電平信號表示[1]。如圖4所示,采用電平下降沿表示“0”,上升沿表示“1”。當有多個標簽同時回復信息時,閱讀器可以定位到發生碰撞的比特位置[17-19,22-26]。圖4 中標簽A、B和C 分別回復字符串“10110010”“10100110”和“10000011”,通過曼徹斯特解碼規則閱讀器得到的字符串為“10XX0X1X”,其中“X”代表無效碼元。閱讀器可以有效解碼全“0”和全“1”位的信息,但當有標簽同時回復“0”和“1”時,閱讀器判斷該位置為碰撞位。 本文利用比特檢測技術,設計標簽回復信息和閱讀器讀取策略,有效提高識別效率。需要注意的是,比特檢測技術主要用于碰撞時隙中碰撞信息位的獲取,當某一時隙發生捕獲效應后,該時隙變為成功時隙,閱讀器可以成功解碼接收到的信號,此時不會檢測到碰撞位信息。 鑒于傳統的估計方法所需時隙數較多、效率低,本文采用比特檢測技術從標簽回復信息中獲取標簽數量估計所需統計信息,減少通信開銷。該過程采用幀時隙方式,閱讀器在每一幀中估計標簽數量和調整下一幀的幀參數,通過多個幀的調整和估計提高估計準確度。 在每一幀開始時,閱讀器廣播Qest(L)命令,其中初始幀的幀參數為L0。標簽收到該查詢命令后,產生1~L的隨機數RN,然后設置時隙計數器tc和回復字符串str,其中,str 為B比特長字符串,且第 [(RN?1)modB]+1 位為“1”,其余位為“0”。其中,mod 為求模運算,為向上取整運算,B為標簽在每個時隙中的回復信息長度,如圖5(a) 中B=6。若tc=0,標簽在當前時隙回復字符串str;否則,標簽在收到閱讀器的Qrep 命令時設置tc=tc?1。 閱讀器接收標簽回復信息并記錄估計統計參數c0,直到當前幀中所有個時隙都執行完成。由于每個標簽的回復信息中只有一位值為“1”,其他位都是“0”。結合比特檢測技術,當閱讀器檢測到當前位為“0”時,表明沒有標簽選擇當前位置。通過統計解碼信息中“0”比特的數量,并將其與理論值相比,可得標簽數量的初步估計。如果閱讀器沒有收到任何標簽回復信息,如圖5(a)中“時隙3”所示,該時隙為空閑時隙,閱讀器設置c0=c0+B。如果閱讀器收到標簽的回復信息,則統計接收信息中“0”比特的數量,并設置c0=c0+。如圖5(a)中“時隙1”為碰撞時隙,閱讀器通過比特檢測技術得到解碼信息“0XX00X”,其中“X”為碰撞位,此時c0=c0+3;“時隙2”為成功時隙,閱讀器接收信息為“000001”,故c0=c0+5。此外,圖5 中t1和t2分別為閱讀器和標簽發送信息的傳輸時間,t3為空閑時隙中閱讀器的等待時間。相較于傳統標簽數量估計算法在每個時隙只能獲取單一的標簽選擇信息,本文算法在每個時隙可以獲得較多標簽選擇信息,時隙利用率高。 在每幀結束時,閱讀器根據c0值估計標簽數量。每一幀中標簽隨機選擇RN 值,與傳統標簽估計算法[6-10]類似,假定每個標簽設置L比特中某位置為“1”的事件相互獨立。則沒有標簽選擇某一特定位置(即閱讀器檢測到比特“0”)的概率為P0=(1?1/L)n。實際統計中P0=c0/L,由此可得標簽數量的估計值為 閱讀器計算估計結果?與幀參數L的偏差|,并以此判斷是否結束估計階段。若未結束,閱讀器調整下一幀的幀參數為當前估計值。 為了減少時隙開銷,該階段的結束條件由時隙開銷和估計偏差之間的關系決定。圖6 給出了當標簽數量從100 變化到1 000 時估計階段的時隙開銷。從圖6 中可以看到,隨著標簽數量和估計偏差的增加,估計階段的時隙開銷相應增加。當估計誤差低于0.1 時,時隙開銷的增加幅度變大,特別是當ε=0.01 時,時隙開銷較大。為平衡時隙開銷和估計準確度,設置估計階段的結束條件為ε<10%。注意,該階段主要給出標簽數量的初步估計,為了降低算法復雜度,由捕獲效應造成的估計偏差不作考慮。標簽估計過程的偽代碼如算法1 所示。 算法1基于比特檢測的標簽數量快速估計 閱讀器端: 標簽端: 該階段采用多分支樹方法對標簽進行識別,由于傳統多分支樹結構隨分支數量的增加碰撞時隙數逐漸減少,而空閑時隙數急劇增加,整體識別效率低。本文通過比特檢測技術將標簽時隙選擇信息融入回復信息中,通過反饋調整的方式消除多分支樹結構中的空閑時隙,提高識別效率。 識別過程中,標簽根據閱讀器的Query(fds)命令調整時隙計數器tc。估計階段結束時,閱讀器根據最后一幀所有時隙中收到的標簽回復信息構建L比特長反饋字符串fds,在fds 中用“1”表示有標簽選擇的位置(包括閱讀器接收信息中所有碰撞位和“1”比特位),“0”表示沒有標簽選擇該位置。如圖5(b)中,假設估計階段最后一幀中標簽A~H選擇的RN 分別為3,2,2,8,3,8,5,9,閱讀器獲得的fds=011010011。標簽收到該反饋信息后更新其tc 值,即標簽統計fds 中第RN 位之前的“0”比特數量b0,并設置時隙計數器值tc=RN?b0?1。圖5(b)中,標簽設置tc(A)=1,tc(B)=0,tc(C)=0,tc(D)=3,tc(E)=1,tc(F)=3,tc(G)=2,tc(H)=4。 若tc=0,標簽產生新的隨機數RN(RN∈[1,M])和Mbit 全零字符串str,并將第RN 位設為“1”。該標簽在當前時隙回復字符串str,其他標簽等待閱讀器的查詢命令。圖5(b)“時隙1”中標簽B 和C的計數器值為0,于是在該時隙進行回復,回復字符串分別為“010000”和“000100”。閱讀器收到標簽回復信息后,若當前時隙為沖突時隙,則根據解碼信息重新構建新的反饋字符串。圖5(b)“時隙1”中閱讀器接收到標簽B 和C 的回復信息后,構建反饋字符串fds=010100。圖5(b)“時隙2”中標簽收到閱讀器的Query(fds)命令后,按如下方式調整計數器值, 1) 若tc=0,標簽統計fds 中第RN 位之前的“0”比特數量b0,并設置時隙計數器值tc=RN?b0?1。 2) 若tc>0,標簽統計fds 中所有“1”比特數量b1,并設置時隙計數器值tc=tc+b1?1。 若當前時隙為成功時隙,閱讀器接著發送Collect 命令獲取相應標簽的ID 信息。如圖5(b)“時隙2”中在收到Collect 命令時,只有標簽B 的時隙計數器值為0,此時標簽B 回復其ID 信息,使閱讀器可以成功識別該標簽。 由于識別過程中可能發生捕獲效應,閱讀器無法判斷成功時隙中有一個標簽回復還是有捕獲效應發生。為了解決由捕獲效應造成的隱藏標簽問題,閱讀器在成功獲取標簽ID 后廣播ACK(H16)信息,其中H16為已識別標簽ID 的前16 bit 哈希值。收到該確認消息后,標簽進行如下調整。 1) 若tc=0,對比其H16值是否與接收到的哈希值相等,若相等該標簽轉為靜默狀態,否則標記自己為隱藏標簽,并等待下一輪識別。 2) 若tc>0,設置tc=tc?1,等待閱讀器的查詢命令。 閱讀器重復后續時隙的識別過程,直到沒有標簽回復。采用閱讀器回復ACK(H16)命令靜默已識別標簽和標記隱藏標簽,可有效減少傳統方法中需要傳輸完整ID 信息的時間開銷。 閱讀器在重復多輪該識別過程,讀取所有標簽的ID 信息。注意在后續每輪開始時閱讀器廣播第一個Query(fds)命令中fds 為空串,所有未被識別的標簽收到該命令后設置tc=0,產生并回復字符串str。如果閱讀器沒有收到任何標簽回復,則表明所有標簽都被識別,便結束整個識別過程,該過程偽代碼如算法2 所示。可以看到,標簽在回復信息時需要產生特定的回復字符串,相較于傳統算法中直接產生隨機字符串,本算法會增加少量的計算開銷。其次,在哈希靜默過程中,標簽需要進行哈希運算,但該過程只在已識別標簽和隱藏標簽中產生,故增加的計算開銷在可接受范圍內。 算法2基于比特檢測的多分支樹可靠識別 閱讀器端: 標簽端: 本文提出的BMT 協議主要包括2 個階段,標簽數量估計和標簽識別。標簽數量估計階段需要的時隙數較少,其時間開銷占比將通過仿真結果給出,本節主要對標簽識別階段的時隙開銷進行分析。對于捕獲效應造成的隱藏標簽,BMT 采用靜默已識別標簽的同時對其進行標記,以及多輪識別的方式保證可靠性。每一輪的識別過程基本相同,通過分析一輪中所需時隙數和識別標簽數量之間的關系,可得所提協議的系統效率為 其中,n為標簽數量,Thide(n)為單輪識別過程中由于捕獲效應被隱藏的標簽數量,S(n)為單輪識別過程所需總時隙數。 在識別階段,閱讀器首先根據估計結果對標簽進行初步分組,令L1為標簽初始分組數。依據相關文獻[19,24,27]假定標簽選擇時隙服從均勻分布,n個標簽中有k個標簽被分配到L1個組中某一組的概率Pk可以由二項分布公式得到,即 在初始分組后,每一個發生碰撞的小組按照M分支的方式持續分裂。整個過程可以表示為如圖7所示的多分支樹結構,其中第一層的時隙數為初始分組數L1,第一層中每個碰撞時隙都將延伸為一棵M分支樹。 在BMT 中,標簽通過閱讀器的反饋信息調整其時隙計數器值,及時消除即將產生的空閑時隙。故在單輪識別中所需時隙數即圖7 中所有成功時隙和碰撞時隙數之和,即 其中,等號右邊第一項為成功時隙數,第二項為由捕獲效應產生的成功時隙數,第三項為碰撞時隙數,SA(k)為由初始分組中發生碰撞的時隙衍生出的多分支樹所包含時隙數。采用遞歸方法可以得到SA(k)的表達式為 其中,等號右邊第一項為該層中原本的成功時隙數,第二項為由捕獲效應產生的成功時隙數,第三項為碰撞時隙數,每個碰撞時隙又將衍生出一個M分支的子樹。由式(7)~式(9)可得每一輪中識別階段所需時隙數。 接下來,分析單輪識別過程中的隱藏標簽數。當k個標簽同時回復發生捕獲效應時,有k?1 個標簽被隱藏和標記,并進入下一輪的識別過程。結合捕獲效應概率模型,可得每一輪中被隱藏的標簽數量Thide(n)為 其中,等號右邊第一項為該層中發生捕獲效應時被隱藏的標簽數量,第二項為由該層碰撞時隙衍生出的M分支樹中的隱藏標簽數。采用類似方法可得 由此可得單輪識別過程中被隱藏的標簽數量。綜上,將式(8)和式(10)代入式(6)中可得識別階段的系統效率。 仿真環境包括一個閱讀器和多個被動式標簽,且每個標簽都有唯一的128 bit ID。閱讀器和標簽之間的數據傳輸率為160 kbit/s;表2 中的每個命令都用4 bit 表示;幀參數L,反饋字符串fds 以及哈希確認消息H16的長度都為16 bit;t1=t2=25 μs,t3=12.5 μs。采用MATLAB 2018a 進行仿真,且每個仿真結果都是500 次仿真的平均值。 在仿真分析中,首先對BMT 協議估計階段的時間開銷和總識別時間進行對比分析,其次給出功率門限比對BMT 協議識別性能的影響,最后分別對BMT 識別所有標簽所需的碰撞時隙數和空閑時隙數以及平均識別時間進行分析。與捕獲效應下標簽識別最相關的同類協議進行比較,包括CMAP[8]、GQT[12]、GBT[13]和ASTSA[20]。其中,CMAP 是對捕獲概率進行估計并優化動態幀時隙Aloha 識別過程的最優協議;GQT、GBT 和ASTSA 是考慮捕獲效應下標簽可靠識別的代表性協議。由于CMAP 只考慮單輪識別的情況,為了仿真對比的公平性,考慮將ASTSA 中的靜默標記方法應用到CMAP 中,實現可靠識別。考慮識別性能在標簽數量變化情況下的穩定性,本文給出Z=5 dB,標簽數量從100 變化到1 000 時各協議的仿真結果。 表3 給出了Z分別為3 dB 和5 dB 時BMT 協議在估計階段和整個識別過程的時間開銷對比情況。 表3 BMT 協議估計階段的時間占比 表3 中估計時間和總時間隨標簽數量的增加而增加,而估計階段的時間占比隨標簽數量的增加而減少。在BMT 識別過程中,標簽估計階段的時間開銷非常少,且時間占比不超過6%。隨著標簽數量的增加,識別階段的時間開銷增加較多,而估計階段增加的時間相對較少。因此隨著標簽數量的增加,估計階段的時間占比有所下降。此外,隨著Z的增加,估計階段的時間占比隨之降低。這主要是因為發生捕獲效應的概率隨Z的增加而降低,Z越大,發生捕獲效應的情況越少;Z越小,捕獲效應發生的情況越多,所以估計時間略長。 由系統模型分析可知,捕獲效應發生的概率隨Z值的增加而降低。考慮該門限值對算法識別性能的整體影響,圖8 給出了BMT 協議識別500 個標簽所需各類時隙數的變化情況。從圖8 中可以看到,隨著Z值增大,發生捕獲效應的時隙數逐漸減少,這與圖3 中捕獲效應發生概率的變化趨勢一致。其次,隨捕獲效應時隙數的減少,由碰撞時隙轉化為成功時隙的數量隨之減少,使碰撞時隙數相應增加。最后,由圖8 可知隨功率比門限的增大,識別所有標簽所需總時隙數有增加趨勢。 當Z=5 dB 時,各協議碰撞時隙數隨標簽數量變化的仿真結果如圖9 所示。 由圖9 可知,碰撞時隙數隨標簽數量的增加呈線性增長,且本文提出的BMT 協議產生的碰撞時隙數最少,其次是CMAP 和ABTSA,而GBT 和GQT 產生的碰撞時隙數較多。相較于CMAP,BMT的碰撞時隙數減少了約40%。GBT 和GQT 通過傳統的二叉樹對標簽進行分組,分裂速度較慢,且前期識別過程大部分為碰撞時隙,因此產生的碰撞時隙數最多。ABTSA 采用樹時隙Aloha 的方式將標簽分成多個組,適當減少了前期識別過程中的碰撞時隙數。但由于初始幀長與標簽數量的不匹配,ABTSA 產生的碰撞時隙數仍然較多。CMAP 通過對標簽數量和捕獲概率進行估計,并以此調整幀長,產生的碰撞時隙數相對較少。BMT 通過多分支樹的方式對標簽進行分組識別,減少標簽發生碰撞的概率,進一步減少碰撞時隙數。 各協議的空閑時隙數對比結果如圖10 所示。圖10 中,CMAP 產生的空閑時隙最多,GQT、ABTSA 和GBT 依次減少,BMT 協議幾乎不產生空閑時隙。BMT 協議只有在估計階段才產生空閑時隙,在識別階段不產生空閑時隙。在估計階段,如果沒有標簽選擇當前時隙所對應的比特位,該時隙為空閑時隙。由表3 可知,估計階段的時間占比非常小,因此該階段產生的空閑時隙數也相對較少。在識別階段,標簽將時隙選擇信息融入標簽回復信息中,閱讀器通過反饋檢測到的標簽時隙選擇信息,使標簽重新調整時隙計數器,消除空閑時隙。因此,BMT 產生的空閑時隙非常少。 GBT 根據標簽的時隙計數器進行分組,產生的空閑時隙比其他協議少。ABTSA 根據估計結果動態調整幀長,產生的空閑時隙比GBT 略多。GQT受標簽ID 分布影響較大,因此當ID 長度較長,標簽數量相對較少時產生的空閑時隙較多。CMAP 考慮到空閑時隙比碰撞時隙和成功時隙的時間短,通過增大幀長設置減少碰撞時隙數,使空閑時隙數急劇增加,因此CMAP 產生的空閑時隙數較其他協議更多。 最后,圖11 給出了各個協議平均識別一個標簽所需時間。從圖11 中可以看到,本文提出的BMT協議平均識別一個標簽所需時間最少,約為1.1 ms,ABTSA 其次,CMAP、GBT 和GQT 所需時間依次增加。由圖9 和圖10 可知,BMT 產生的碰撞和空閑時隙比其他相關協議都少,故平均識別時間最短。ABTSA 雖然比CMAP 產生的碰撞時隙多,但其產生的空閑時隙較CMAP 少得多,因此平均識別時間比CMAP 短。GBT 和GQT 產生了過多碰撞時隙,識別時間最長。相較于ABTSA、CMAP、GBT和GQT,BMT 的識別時間分別縮短了約15%、37%、50%和63%。 本文提出了基于比特檢測的多分支樹標簽識別BMT 協議,該協議通過比特檢測標簽估計策略和多分支樹標簽識別算法對捕獲效應下的RFID 標簽進行高效可靠的識別,有效減少了標簽估計和識別過程所需時隙數,縮短了識別時延。此外,本文還提出基于哈希靜默的方法來減少靜默已識別標簽和標記隱藏標簽的通信開銷,進一步提高識別效率。理論分析和仿真對比表明,所提協議能有效提高識別效率,且相較于已有協議,所提協議將識別時間縮短了至少15%。在后續工作中,筆者將深入研究靜默已識別標簽和標記隱藏標簽的有效方法,進一步提高識別效率。
3 算法設計
3.1 比特檢測技術
3.2 基于比特檢測的標簽數量快速估計
3.3 基于比特檢測的多分支樹可靠識別
4 性能分析
5 仿真分析
5.1 估計階段的時間開銷

5.2 捕獲效應對識別性能的影響
5.3 碰撞時隙數
5.4 空閑時隙數
5.5 平均識別時間
6 結束語
猜你喜歡
核科學與工程(2021年4期)2022-01-12 06:30:26
今日農業(2020年19期)2020-12-14 14:16:52
小學生必讀(中年級版)(2020年9期)2020-12-04 02:07:22
中華手工(2017年2期)2017-06-06 23:00:31
中學物理·高中(2016年12期)2017-04-22 11:53:03
小櫻桃·童年閱讀(2014年11期)2014-12-01 22:21:30
中外會展(2014年4期)2014-11-27 07:46:46
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
祝您健康(1987年2期)1987-12-30 09:52:28
