多目標時間序列混合特征動態變權組合預測研究
2021-12-08 19:54:03董志學宮越胡勇甘孟壯
軟件工程 2021年12期
董志學 宮越 胡勇 甘孟壯

摘 ?要:在通過LightGBM、Prophet、HotWinters等單一預測算法,以及通過引入搜索指數等消費者行為數據作為預測變量等無法達到汽車品牌銷量預測精度的情況下,基于銷量數據特征遴選出HotWinters、Prophet、LightGBM三個預測模型,并自主構建了Musgrave方法,以此四個算法構建了組合預測模型,并結合熵值法作為權重動態變化的方法,構建了“動態變權組合預測策略”。本策略使用“單地區多品牌維度、多品牌維度、多地區多品牌維度”三種方式進行六期預測并檢驗預測效果,結果表明三種方式預測誤差中位數分別為7.50%、6.11%、9.61%,因此,本策略能夠滿足對具有復雜多變特征的數據進行預測的需要。
關鍵詞:動態變權;組合預測;Musgrave;熵值法
中圖分類號:TP311 ? ? 文獻標識碼:A
Abstract: Prediction accuracy of automobile brand sales cannot be achieved through single prediction algorithms such as LightGBM, Prophet, HotWinters, and the introduction of consumer behavior data such as search indexes as predictors. Based on the characteristics of sales data, this paper proposes to select three predicting models, LightGBM, HotWinters and Prophet, and independently build Musgrave method. With these four algorithms, a combined forecasting model is constructed, and a "dynamic variable weight combination predicting strategy" is constructed by taking the entropy method as a method of dynamic weight change. This strategy uses three methods of "single-region multi-brand dimension, multi-brand dimension, and multi-regional and multi-brand dimensions" to conduct six-period predictions and test the prediction results. Results show that the median prediction errors of the three methods are 7.50%, 6.11%, 9.61%. Therefore, this strategy can meet the needs of predicting data with complex and changeable characteristics.
Keywords: dynamic variable weight; combined prediction; Musgrave; entropy method
1 ? 引言(Introduction)
作為我國最重要的產業部門之一,汽車產業無論橫向還是縱向都跨越多個行業部門,同時又與百姓生活關聯緊密,對汽車市場銷量態勢進行準確預測有助于從國家層面洞察各個汽車品牌的經營態勢,也有利于從消費者方面了解不同價值等級消費者選擇不同汽車品類過程中體現出來的消費結構和能力的變遷。然而,汽車銷量數據除了具有周期性(如車型換代)、季節性(如金九銀十)、節假日(如春節)等特征,還容易受政府調控(如限行限號、車險費率改革)、車企不定期促銷、優惠措施(如購置稅減半)等行為的影響,同時又具有隨機性特征,而現在新興的直播購車等互聯網形式的營銷活動又進一步增加了預測的復雜性。
為提升預測精度,有關學者分別從應用并改進人工智能算法[1]、引入搜索指數等消費者行為數據作為變量[2]等方面進行預測研究。雖然此類方法能夠在特點品牌[3]、特定時段[4]產生較高的預測精度,但更多實踐表明,使用ARIMA、X-11、HotWinters等時間序列預測方法難以覆蓋全部的數據特征,預測結果容易出現“有時準”但難以做到“實時準”,而當今流行的Prophet、LightGBM等機器學習算法具有難以將數據全部特征提取完全的弊端。所以,在單一靜態預測無法滿足需要的前提下,動態組合預測成為一種改善單項模型預測性能的有效策略。
本文基于相關學者的研究成果,在組合預測的基礎上引入動態變權的策略,以廣東地區30大品牌銷量數據為基礎,在數據特征識別、預測模型動態選擇依據、各算法價值權重的自動調整方面進行預測研究。同時,為進一步驗證動態變權組合預測策略的有效性,將預測對象從廣東地區30大汽車品牌擴展到全國42 個地區的30大汽車品牌以及全國30大汽車品牌進行擴展預測,以期達到能夠真正指導實踐的目的。
2 ? 模型設計(Model design)
2.1 ? 組合預測模型的原型
組合預測最早可追溯到1969 年BATES和GRANGER[5]提出的將單個預測組合成復合預測的原理,組合模型憑借可以有效去除滯后變量和非平穩性對預測的干擾[6]、在單項預測結果存在有偏性的情況下通過組合能產生具有無偏性的預測結果[7]等優勢得到了研究學者的廣泛應用,尤其是機器學習預測算法的引入,對通過識別長時間序列數據自身具有的規律性特征進而提升預測精度具有顯著效果。組合預測模型如下:
假設選取種預測模型(,),每個模型在預測過程中均能夠依據誤差產生依據時間序列而變動的權重,則變權重組合預測模型可表示為:
式中,為隨機噪音。
2.2 ? 單項預測模型的選擇
預測模型種類繁多且各有優劣勢,從統計學層面來看,可分為回歸問題和分類問題兩大類。而在機器學習層面,可分為線性模型、樹型模型和神經網絡模型,例如,謝如賢等[8](1992)使用ARMA、季節變量回歸模型、指數自回歸模型組成變權重組合模型對社會商品零售總額進行了預測,將平均誤差(ME)降到了0.10;王永剛等[9](2013)以灰色Verhulst模型、Brown指數平滑模型及非線性冪函數回歸模型為單項模型,構建航空運輸事故征候的最優變權組合預測模型,組合預測模型的平均絕對百分比誤差(MAPE)為0.02323;朱周帆等[10](2020)將SVM、RF、XGBoost與ARIMA模型相組合應用于汽車市場預測,平均絕對百分比誤差(MAPE)為0.0297。通過對現有研究成果的歸納總結,本文選擇的納入組合模型的預測算法需要重點考慮能夠處理季節性、趨勢性、節假日等特征的模型,因此,初選模型包括ARIMA、HotWinters、Prophet、LightGBM、XGBoost、GM(1,1)。
2.3 ? 權重設計與動態計算
預測效果的評估方法有絕對偏差、均方誤差、均方根誤差、平均絕對相對誤差、平均絕對誤差等,而權重的確定方法有等權重法、最小方差法、誤差倒數法、優勢矩陣法、權重收縮法等。在預測效果評價方面,本文選擇絕對偏差法
()作為評價準則;在權重方法選擇方面,考慮到預測數據收到季節性、節假日等因素的影響,各預測算法對預測對象的預測結果存在動態誤差[11],權重同樣需要考慮實時、動態的特征,所以本文使用熵值法[12]計算組合預測模型的參數。熵值法的基本原理是:假設有 個評價對象(各預測算法),有 個評價指標(各品牌預測誤差),視計算結果情況將其歸一化后轉變為標準化數據,則其第 個指標的熵的計算公式為:
式中,為權數,為第項指標下第年占該指標的比重。將式(2)代入式(1)即得到基于熵值法的組合預測模型。
3 ? 實例研究(Case study)
3.1 ? 數據特征認知
本文研究使用的銷量數據以月為單位,數據對象是汽車30大品牌的新車銷量數據,數據范圍包括全國銷售數據和42 個主要地區的銷售數據,選擇2017 年1 月至2020 年9 月作為測試集,選擇2020 年10 月至2021 年3 月數據作為驗證集。因此,從數據的時間跨度來看,數據內涵既包括各品牌的銷售行為等微觀特征,又包括各地區經濟發展、市場推廣等宏觀特征,這無疑都加大了預測難度。
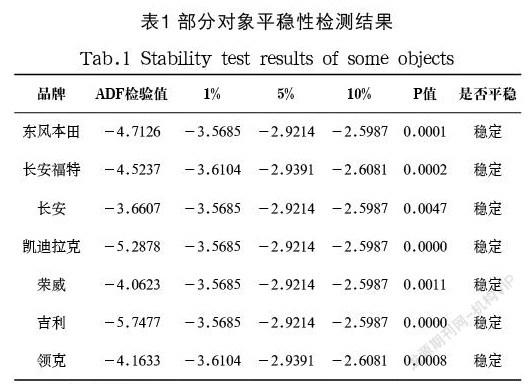
(1)平穩性檢驗
為進一步確定數據集的特征,本文使用ADF進行平穩性檢驗。平穩性是選擇預測模型的先決條件,對于平穩型數據可使用AR、MA、ARMA等方式直接建模,而對于非平穩型數據則需要通過取對數、差分等方法處理后使用ARIMA進行建模。對平穩性的檢驗分為依據時序圖和自相關圖進行判斷的圖檢驗法以及構造檢驗統計量的假設檢驗法,前者主要依據研究者的經驗以主觀方式判斷,后者可通過單位根檢驗法進行客觀判別,因此,本文采取ADF方法進行檢驗。從如表1所示的檢測結果表可以看出,30大品牌中不平穩對象占大多數,僅有7 個品牌(東風本田、長安福特、長安、凱迪拉克、榮威、吉利、領克)在數據期內平穩,因此,在模型選擇中,ARMA、ARIMA應包含在選擇對象之內。
(2)季節性判定
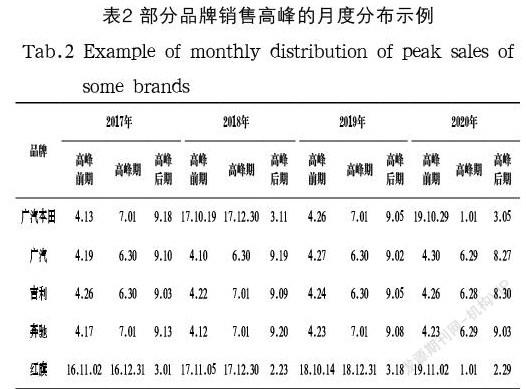
長期趨勢、循環波動、季節性變化、隨機波動是數據序列波動的四大類因素,因此,對季節性因素進行識別是提升預測精度的一個有效手段。本文使用圓形分布法結合集中度進行是否存在季節性以及集中月份的識別,該方法通過三角函數變換使得原始數據成為線性數據,進而識別季節分布特征。圓形分布法先將12 個月變換成360 度,1 年按365.2563 天計算,1 天相當于0.9856 度(360/365.2563),以1 月1 日零時為起點,以每個月月中值作為組中值折算為度,如:1 月份31 天,組中值為15.5 天,轉換角度為15.2769 度;2 月份28 天,組中值為45(31+28/2) 天,轉換角度為44.3524 度;其他以此類推。通過公式計算圓形分布的值、平均角和角標準差。由平均角和角標準差推算該對象的集中時間和增長高峰期,由于圓形分布法對數據格式的要求必須是整年數據,因此,選取2017 年、2018 年、2019 年、2020 年作為研究數據,并選取0.5作為標準差系數,經計算可得廣東地區2017—2020年度30大品牌銷售高峰的月度,如表2所示。
通過以上計算結果可以看出,各個品牌在研究期間內的季節性呈現出多樣化的特征,各品牌差異化程度較高,例如廣汽本田的銷售高峰期分別是6 月底7 月初和12 月底1 月初,紅旗品牌的銷售高峰期則是12 月底1 月初,而奔馳品牌的銷售高峰期則是6 月底7 月初。同時可以看出,廣汽、吉利品牌的銷售高峰近4 年均在6 月底7 月初。由此可見,各個品牌的季節性規律并不統一,基于此種數據特征,特將HotWinters、Prophet、LightGBM列入選擇范圍。
3.2 ? 單項模型選擇
通過對每個算法的預測進行實驗,根據預測誤差進一步淘汰了中位數誤差較大的ARIMA、GM(1,1)、XGBoost模型,最終選取了HotWinters、Prophet、LightGBM三個模型,考慮到能夠滿足數據特征的預測算法相對較少,本文結合數據特征,基于Musgrave和Henderson系數單獨設計了算法進行預測(下文簡稱Musgrave方法)。
針對本文研究的數據特征,本文使用Musgrave非對稱濾子和Henderson濾子思想構建基于數據對稱分布特征的預測[13]。在X-11中,使用Henderson移動平均可以從季節調整后序列中提取趨勢這一成分,在應用項中心化移動平均時,由于結構限制,得不到序列最初項和最后項的平滑估計值,這容易給預測帶來困擾,因為通常序列中最重要的點就是最末的那個點,因此在實際應用中需要采用非中心化移動平均來估計這些值。Musgrave的思路就是構建這樣的非對稱移動平均,能使得未來對估計值做出的修正達到最小。其基本原理是:
3.3 ? 組合預測策略
(1)算法匹配策略
通過前期預測實驗發現,不同的算法對同一品牌的預測能力、同一算法對不同品牌的預測能力均存在顯著差異,在實際工作中預測中位數誤差在6%以內具有較高的使用價值,因此本文將誤差6%作為評價算法優劣的邊界,而預測中位數誤差在6%—10%具有一般的使用價值,因此,本文分別以6%、10%作為各算法匹配的閾值,具體匹配策略如下:
第一,對于在期預測累計雙誤差(均值和中位數)均低于6%的算法直接用于預測第期;如果對于多個算法都在6%以內的,則根據此算法在該品牌的預測誤差權重,使用動態變權組合預測策略計算期綜合預測值。
第二,對某品牌的中位數誤差為的品牌的算法,使用組合算法進行預測,其中:①如果某個機構的某個品牌上有多個算法,中位數誤差均在,則根據權重進行“動態組合預測”。②如果某個機構的某個品牌上只有一個算法,中位數誤差均在,則使用該算法進行預測。
第三,對于某品牌的中位數大于0.1,選取各算法預測中位數誤差較低的算法進行預測。
(2)預測維度選取策略
動態變權組合預測策略能否在實踐中發揮關鍵作用取決于兩個因素,其一是在滿足數據特征多樣性前提下帶來的預測結果的準確性;其二是在一套匹配策略下能夠滿足不同類別預測場景的多樣性。因此,本文并未從單一汽車品牌銷量開始預測,而是考慮到以應用為核心目標,在明確數據時間的前提下從不同的維度采取如下策略:第一,在單地區多品牌維度方面,選取廣東地區30大汽車品牌進行預測;第二,在多品牌維度方面,選取30大汽車品牌各自的全國銷量進行預測;第三,在多地區多品牌維度方面,選取全國42 個主要地區的30大汽車品牌銷量進行預測。之所以從這三個維度進行預測研究,其核心目的是在預測精度的前提下評估動態變權組合策略在多場景下的綜合適用性,而本文的效果評估也從這三個維度展開。
3.4 ? 預測效果評估
模型評估標準是對預測效果的直接決定影響因素,本文在評估方法方面考慮到預測對象數量較多,因此選擇“誤差中位數”作為標準。而在實踐中,決策者經常需要對一段時間的銷量進行跨期預測,因此本文選擇2020 年10 月起至2021 年3 月累計6 個月銷量進行預測測試,而各算法在這6 期的表現也將作為最終效果評價的標準。基于前述的假設,現將動態變權組合預測模型的預測效果總結和分析如下:
(1)以廣東為例的單地區多品牌維度預測效果評價
在實踐中,對單地區的汽車品牌銷量進行預測可以有效指導分/子公司層面的經營行為,本文通過使用動態變權組合預測策略對廣東地區30大品牌2020 年10 月至2021 年3 月銷量進行預測,從動態變權組合預測策略所體現的誤差中位數可以看出,動態變權組合預測模型的誤差中位數為7.50%,明顯低于其他單一預測模型,如表3所示。
(2)以全國為預測對象的多品牌維度預測效果評價
為進一步驗證動態變權組合預測模型對宏觀方面的適用性,本文繼續對“全國30大品牌”進行預測,經過對預測結果統計分析發現,預測誤差中位數為6.11%,依然低于其他預測模型,如表4所示。
(3)在多地區為預測對象的多品牌維度預測效果評價
為進一步體現動態變權組合預測的能力,本文將預測對象進一步拓展到“42地區30大品牌”。經統計分析發現,動態變權組合預測模型誤差中位數為9.61%,預測效果依然比較優秀,但相比于前兩類預測對象,誤差中位數明顯增加不少,如表5所示。對原始數據的研究表明,這主要是由于預測對象和數據維度增加了數據復雜度,進而加大了預測難度。
4 ? 結論(Conclusion)
本文提出了一種動態變權組合的預測策略,綜合來看,本策略除了能夠顯著提升預測效果外,更能擴大實踐中的預測業務場景,可以進一步增強為決策者提供輔助決策的能力。本文雖有創新,但也存在以下不足,綜合總結如下:
(1)預測對象數據特征的變化是決定動態變權的依據。實踐表明,對預測對象數據特征的認知至關重要,引起數據特征變化的因素多種多樣,既有行業因素,又有企業因素,還有國家和地區的政策因素,而這些都需要進行通盤考慮。更重要的是,針對每個因素導致的誤差都要找到相應的預測解決方案,最終形成與預測算法、權重算法并重的數據認知算法模塊。
(2)如何將權重實現智能計算需要進一步研究。本文在預測算法中使用了基于權重的動態匹配策略,因為權重在不同時間同樣是一個變化的隨機變量,所以在確定權重方法時,有必要實時考慮它的不確定性,除了本文使用的熵值法,權重的計算依然有綜合評價法、Topsis法、方差倒數法等多種方法,如何通過方差、變異系數等更詳細地評估各算法在預測過程中的穩定性,對權重的計算采用動態匹配模式非常值得進一步研究。
參考文獻(References)
[1] 劉吉華,張夢迪,彭紅霞,等.基于卷積神經網絡的汽車銷量預測模型[J].計算機科學,2021,48(6A):178-189.
[2] 王煉,寧一鑒,賈建民.基于網絡搜索的銷量與市場份額預測:來自中國汽車市場的證據[J].管理工程學報,2015,29(4):56-64.
[3] 劉吉華,張夢迪.基于百度指數的大眾汽車銷量預測研究[J].統計與管理,2020,35(279):25-33.
[4] 王守中,崔東佳,彭賡.基于Web搜索數據的寶馬汽車銷量預測研究[J].經濟師,2013(12):24-26,28.
[5] BATES J M, GRANGER C. The combination of forecasts[J]. Journal of the Operational Research Society, 1969, 20(4):451-468.
[6] HOLDEN K, PEEL D A. An empirical investigation of combinations of economic forecasts[J]. Journal of Forecasting, 2010, 5(4):15-18.
[7] COULSON N E, ROBINS R P. Forecast combination in a dynamic setting [J]. Journal of Forecasting, 2010, 12(1):63-67.
[8] 謝如賢,成盛超,吳健中.變權重組合預測模型的建立與應用[J].預測,1992,11(4):64-67.
[9] 王永剛,鄭紅運.基于最優變權組合模型的航空運輸事故征候預測[J].中國安全科學學報,2013,23(4):26-31.
[10] 朱周帆,郝鴻,張立文.基于機器學習與時間序列組合模型的中國汽車市場預測[J].統計與決策,2020,36(548):179-182.
[11] 凌立文,張大斌.組合預測模型構建方法及其應用研究綜述[J].統計與決策,2019(01):20-25.
[12] 狄淼,王明剛.基于熵權組合模型的風電功率預測[J].科學技術與工程,2012,20(29):7713-7718.
[13] 中國人民銀行調查統計司.時間序列X-12-ARIMA季節調整——原理與方法[M].北京:中國金融出版社,2006:76-85.
作者簡介:
董志學(1980-),男,博士,算法工程師.研究領域:統計學,數學.
宮 ? 越(1987-),女,碩士,算法工程師.研究領域:數據挖掘.
胡 ? 勇(1973-),男,碩士,算法工程師.研究領域:機器學習.
甘孟壯(1986-),男,碩士,軟件工程師.研究領域:自然語言處理,機器學習.
