基于交叉驗(yàn)證梯度提升決策樹的管道腐蝕速率預(yù)測(cè)
2021-12-09 01:11:54王曉娜
腐蝕與防護(hù) 2021年11期
關(guān)鍵詞:模型
顏 佳,黃 一,王曉娜
(1. 大連理工大學(xué) 船舶工程學(xué)院,大連 116024; 2. 大連理工大學(xué) 物理學(xué)院,大連 116024)
輸油管道腐蝕速率的準(zhǔn)確預(yù)測(cè)能夠?yàn)楣艿肋\(yùn)營商及時(shí)采取有效的維護(hù)措施提供依據(jù),對(duì)于保障管道安全高效運(yùn)行具有重要的意義。但是管道的腐蝕速率和腐蝕環(huán)境因素之間存在復(fù)雜的非線性關(guān)系,很難用傳統(tǒng)的數(shù)理方法建立其數(shù)學(xué)模型。近幾年來,更多的學(xué)者開始將基于數(shù)據(jù)驅(qū)動(dòng)的機(jī)器學(xué)習(xí)方法引入到腐蝕預(yù)測(cè)領(lǐng)域,取得了不錯(cuò)的預(yù)測(cè)效果。他們采用的方法主要有BP神經(jīng)網(wǎng)絡(luò)(BPNN)[1-3]和支持向量機(jī) (SVM)[4-6]等。但是這些方法也有一些缺點(diǎn):一方面,BPNN與SVM方法需要對(duì)輸入信息進(jìn)行預(yù)處理(如正則化,特征映射等)[7],增加了建模的工作量;另一方面,這些方法建立的都是單一全局模型,只能從某一方面對(duì)歷史腐蝕數(shù)據(jù)進(jìn)行學(xué)習(xí),學(xué)習(xí)不夠充分,因此其預(yù)測(cè)結(jié)果具有不穩(wěn)定性,特別是神經(jīng)網(wǎng)絡(luò)模型受權(quán)重初值的影響較大,得到的結(jié)果有時(shí)甚至很不理想。
與單一模型不同,集成學(xué)習(xí)模型能夠重復(fù)利用已有數(shù)據(jù)信息訓(xùn)練多個(gè)基學(xué)習(xí)器,并通過一定的結(jié)合策略形成一個(gè)強(qiáng)學(xué)習(xí)器進(jìn)行預(yù)測(cè)。已有的研究表明,與單一模型相比,集成模型的預(yù)測(cè)結(jié)果往往具有更高的精確性與魯棒性[8]。而梯度提升決策樹(GBDT)作為一種常見而高效的集成學(xué)習(xí)方法,近年來在價(jià)格預(yù)測(cè)[9],城市智能交通管理[10-12]和電力系統(tǒng)負(fù)荷預(yù)測(cè)[13-14]等領(lǐng)域得到了廣泛的應(yīng)用。本工作基于梯度提升決策樹算法建立管道腐蝕速率預(yù)測(cè)模型,利用k折交叉驗(yàn)證和網(wǎng)格搜索技術(shù)進(jìn)行參數(shù)尋優(yōu),實(shí)例驗(yàn)證結(jié)果表明其具有預(yù)測(cè)精度高和泛化能力強(qiáng)的優(yōu)點(diǎn),可為將來的管道腐蝕速率預(yù)測(cè)提供一種新方法。
1 梯度提升決策樹模型
1.1 提升算法
集成學(xué)習(xí)方法通過結(jié)合某種學(xué)習(xí)算法構(gòu)建多個(gè)基學(xué)習(xí)器,提高單個(gè)學(xué)習(xí)器的泛化能力與魯棒性[15]。提升算法是集成學(xué)習(xí)方法中非常重要的一類,它通常涉及兩個(gè)部分——前向分步算法和加法模型[16]。
前向分步算法是指在訓(xùn)練過程中,下一輪迭代產(chǎn)生的基學(xué)習(xí)器是在上一輪的基礎(chǔ)上訓(xùn)練得來的,每增加一個(gè)基學(xué)習(xí)器即是對(duì)上一個(gè)模型的修正,因此該模型可以用式(1)表示。
Fm(x)=Fm-1(x)+γmhm(x)
(1)
式中:Fm為第m次迭代后得到的集成模型;hm(x)為第m個(gè)基學(xué)習(xí)器;γm為第m個(gè)基學(xué)習(xí)器在集成模型中的權(quán)重。
加法模型是指迭代完成后得到的強(qiáng)學(xué)習(xí)器可表示為多個(gè)基學(xué)習(xí)器線性相加的形式,如式(2)所示。
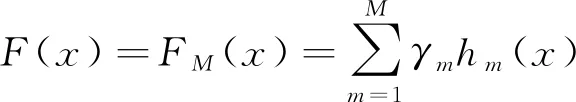
(2)
式中:FM(x)為最終的集成模型;M為基學(xué)習(xí)器的個(gè)數(shù)。
1.2 梯度提升決策樹(GBDT)
GBDT是FRIEDMAN[17]基于提升算法框架提出的一種新的機(jī)器學(xué)習(xí)方法,同時(shí)也是對(duì)傳統(tǒng)提升算法的一種改進(jìn)。其基本思想是把損失函數(shù)的負(fù)梯度在當(dāng)前模型下的值作為模型預(yù)測(cè)結(jié)果的近似殘差,并把該值作為下一個(gè)模型的訓(xùn)練目標(biāo),通過迭代過程逐步減小預(yù)測(cè)偏差[10,18],提高預(yù)測(cè)精度。GBDT使用決策樹模型作為基學(xué)習(xí)器。決策樹模型是基于單特征比較構(gòu)建的,不對(duì)數(shù)據(jù)進(jìn)行預(yù)處理也可以很好地?cái)M合數(shù)據(jù)。GBDT將提升算法和決策樹模型兩者的優(yōu)點(diǎn)結(jié)合起來,因此被認(rèn)為是機(jī)器學(xué)習(xí)中功能最強(qiáng)大的算法之一。
假設(shè)已知的數(shù)據(jù)集為:
T={(x(i),y(i))|i=1,2,…N}?Rn×R
(3)
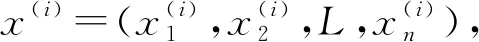
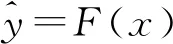
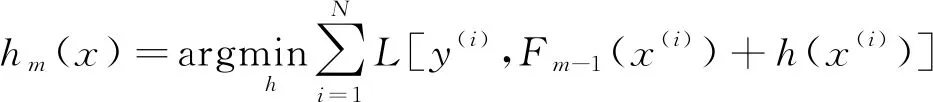
(4)
但是,在每一步迭代過程中,對(duì)于任意損失函數(shù)L[y,F(x)],依據(jù)式(4)求出最優(yōu)的函數(shù)解h(x)在計(jì)算上是十分困難的。因此,一般采用啟發(fā)式算法,通過不斷地迭代來逐步逼近精確解。根據(jù)這個(gè)思想,GBDT使用最速下降法來求解該最小化問題。假設(shè)選取的損失函數(shù)在當(dāng)前集成模型Fm-1上可微,則最速下降方向是損失函數(shù)在Fm-1處的負(fù)梯度方向,即令:
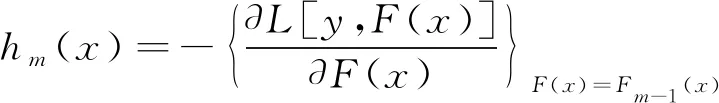
(5)
則更新模型為:
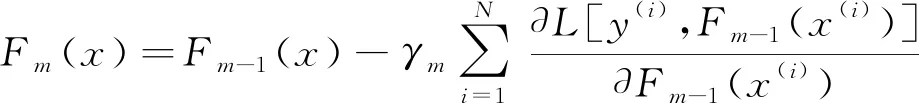
(6)
其中,步長γm可以通過一維線搜索求得,即:
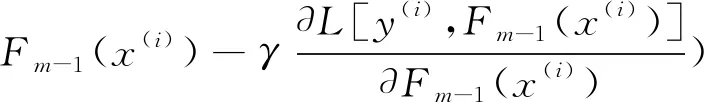
(7)
為了防止過擬合,F(xiàn)RIEDMAN等[17]提出了一種簡單的正則化方法,通過學(xué)習(xí)率v來控制每個(gè)基學(xué)習(xí)器對(duì)集成模型的貢獻(xiàn)程度,最終的模型則可以表示為:
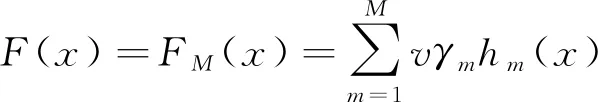
(8)
1.3 參數(shù)選擇與交叉驗(yàn)證
由式(8)可以看出,GBDT的預(yù)測(cè)精度和泛化能力主要取決于集成模型中決策樹的數(shù)量M,學(xué)習(xí)率v以及每個(gè)決策樹模型hm(x)的復(fù)雜度(以最大葉子節(jié)點(diǎn)數(shù)J表示)。一般而言,較小的學(xué)習(xí)率意味著需要更多的決策樹模型才能達(dá)到要求的預(yù)測(cè)精度,而生成過多的決策樹會(huì)消耗大量的計(jì)算資源[20]。研究表明,將學(xué)習(xí)率v設(shè)置為一個(gè)較小的值(v≤0.1),能夠避免因過快逼近造成的過擬合問題,從而減小測(cè)試誤差[21]。單棵決策樹的葉子節(jié)點(diǎn)數(shù)越多,本身學(xué)習(xí)能力就越強(qiáng),集成模型中需要的決策樹就越少,但這不利于發(fā)揮集成算法的優(yōu)勢(shì)。HASTIE等[21]認(rèn)為在GBDT中,當(dāng)4≤J≤8時(shí),模型效果表現(xiàn)最佳。
本工作通過k折交叉驗(yàn)證來尋找模型的最優(yōu)超參數(shù)組合,降低模型潛在的過擬合風(fēng)險(xiǎn)。運(yùn)行k折交叉驗(yàn)證時(shí),首先將樣本集隨機(jī)劃分為k份,每份的樣本數(shù)量大體相等。然后依次選取第i份數(shù)據(jù)作為測(cè)試集,其余k-1份數(shù)據(jù)作為訓(xùn)練集對(duì)模型進(jìn)行訓(xùn)練,最終得到k個(gè)模型,把k個(gè)模型在各自測(cè)試集上預(yù)測(cè)效果的平均值作為判斷該超參數(shù)取值下模型性能的依據(jù)[22]。
k折交叉驗(yàn)證使用無重復(fù)抽樣技術(shù),使得每一個(gè)樣本都有一次機(jī)會(huì)作為測(cè)試樣本,提高了數(shù)據(jù)的利用率,是模型性能評(píng)估的有效方法[23]。k折交叉驗(yàn)證選擇最優(yōu)超參數(shù)建立梯度提升決策樹模型的流程圖如圖1所示,其中超參數(shù)集Pi={Mi,vi,Ji}。
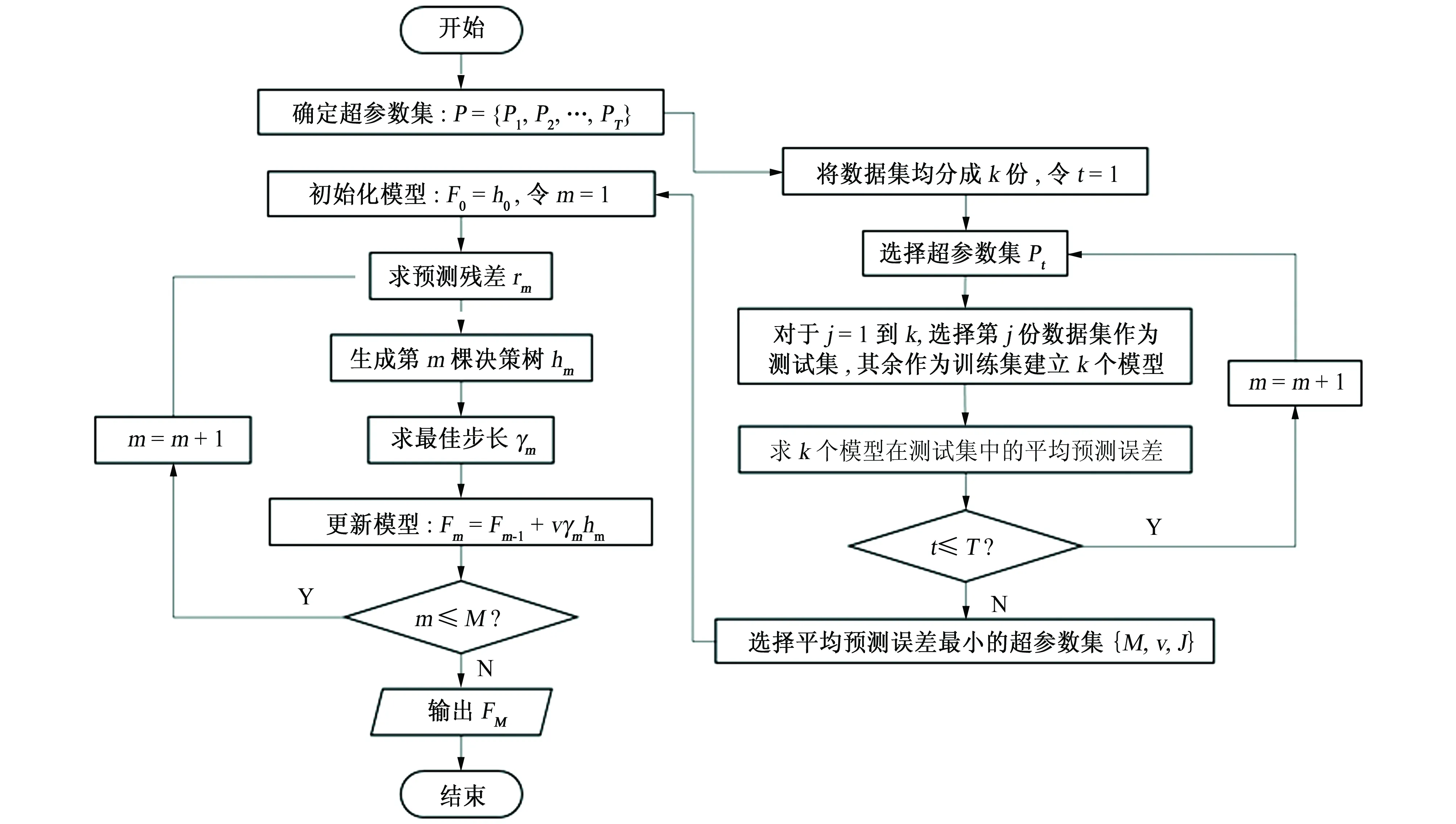
圖1 k折交叉驗(yàn)證選擇最優(yōu)超參數(shù)建立梯度提升決策樹模型的流程圖Fig. 1 Flow chart of selecting optimal hyper-parameters to establish gradient boosting decision tree model through k-fold cross validation
2 GBDT在管道腐蝕速率預(yù)測(cè)中的應(yīng)用
2.1 數(shù)據(jù)來源
某輸油管道材料為20號(hào)鋼,使用壓力為1.0~5.0 MPa,輸送介質(zhì)為產(chǎn)地不同的原油。影響該管道內(nèi)腐蝕速率的主要環(huán)境因素為硫含量,酸值,溫度,流速和壓力,通過正交試驗(yàn)方法實(shí)測(cè)得到的腐蝕速率如表1所示[5]。將環(huán)境因素作為模型輸入,腐蝕速率實(shí)測(cè)值作為期望輸出,建立梯度提升決策樹預(yù)測(cè)模型。
2.2 建立模型
為了測(cè)試模型的泛化能力,首先將所有的樣本按照4∶1的比例隨機(jī)劃分為訓(xùn)練集和測(cè)試集。在建模時(shí),選取決策樹數(shù)量M的集合為{50,100,150,200,250},學(xué)習(xí)率v的集合為{0.001,0.005,0.01,0.025,0.05,0.075}以及每棵決策樹最大葉子節(jié)點(diǎn)數(shù)J的集合為{4,5,6,7,8},利用網(wǎng)格搜索技術(shù)遍歷所有可能的參數(shù)組合,根據(jù)最小均方誤差準(zhǔn)則,對(duì)于訓(xùn)練集中的數(shù)據(jù)采用5折交叉驗(yàn)證方法確定模型的最優(yōu)參數(shù)。在交叉驗(yàn)證時(shí),由于模型從未使用過測(cè)試集中的樣本,因此模型在測(cè)試集上的預(yù)測(cè)性能能夠反映其真實(shí)的泛化能力。為了進(jìn)行對(duì)比分析,使用BP神經(jīng)網(wǎng)絡(luò)(BPNN)和支持向量機(jī)(SVM)方法在同一數(shù)據(jù)集上進(jìn)行建模。

表1 某輸油管道實(shí)測(cè)腐蝕速率Tab. 1 Measured corrosion rates of an oil pipeline
2.3 預(yù)測(cè)精度評(píng)估指標(biāo)
為了評(píng)估模型的整體性能,選擇均方誤差EMSE,平均絕對(duì)百分誤差EMAPE和決定系數(shù)R2等3個(gè)指標(biāo)來衡量模型的預(yù)測(cè)精度,計(jì)算公式分別如式(9)~(11)所示。其中,均方誤差能很好地反映預(yù)測(cè)誤差的實(shí)際情況,平均絕對(duì)百分誤差是衡量模型相對(duì)誤差最重要的指標(biāo),決定系數(shù)是回歸預(yù)測(cè)擬合優(yōu)度的度量。
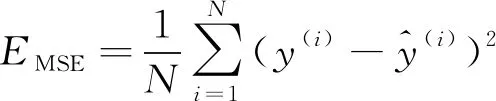
(9)
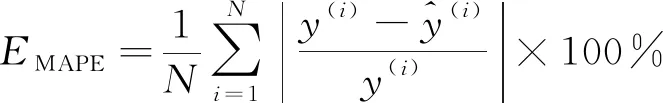
(10)
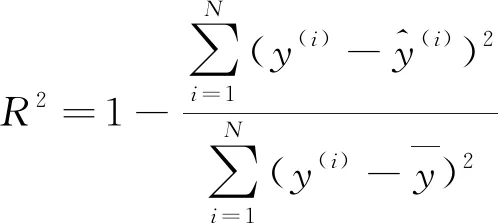
(11)

3 結(jié)果與分析
3.1 模型預(yù)測(cè)結(jié)果比較
在建模中,通過隨機(jī)劃分將序號(hào)為25,2,24,4和20的樣本劃入測(cè)試集,其余樣本作為訓(xùn)練集。通過網(wǎng)格搜索和交叉驗(yàn)證得到GBDT模型的最優(yōu)參數(shù)M=100,v=0.075,J=4。GBDT、BPNN和SVM三種模型在訓(xùn)練集與測(cè)試集上的預(yù)測(cè)值和相對(duì)誤差如表2所示,預(yù)測(cè)值的殘差如圖2所示。
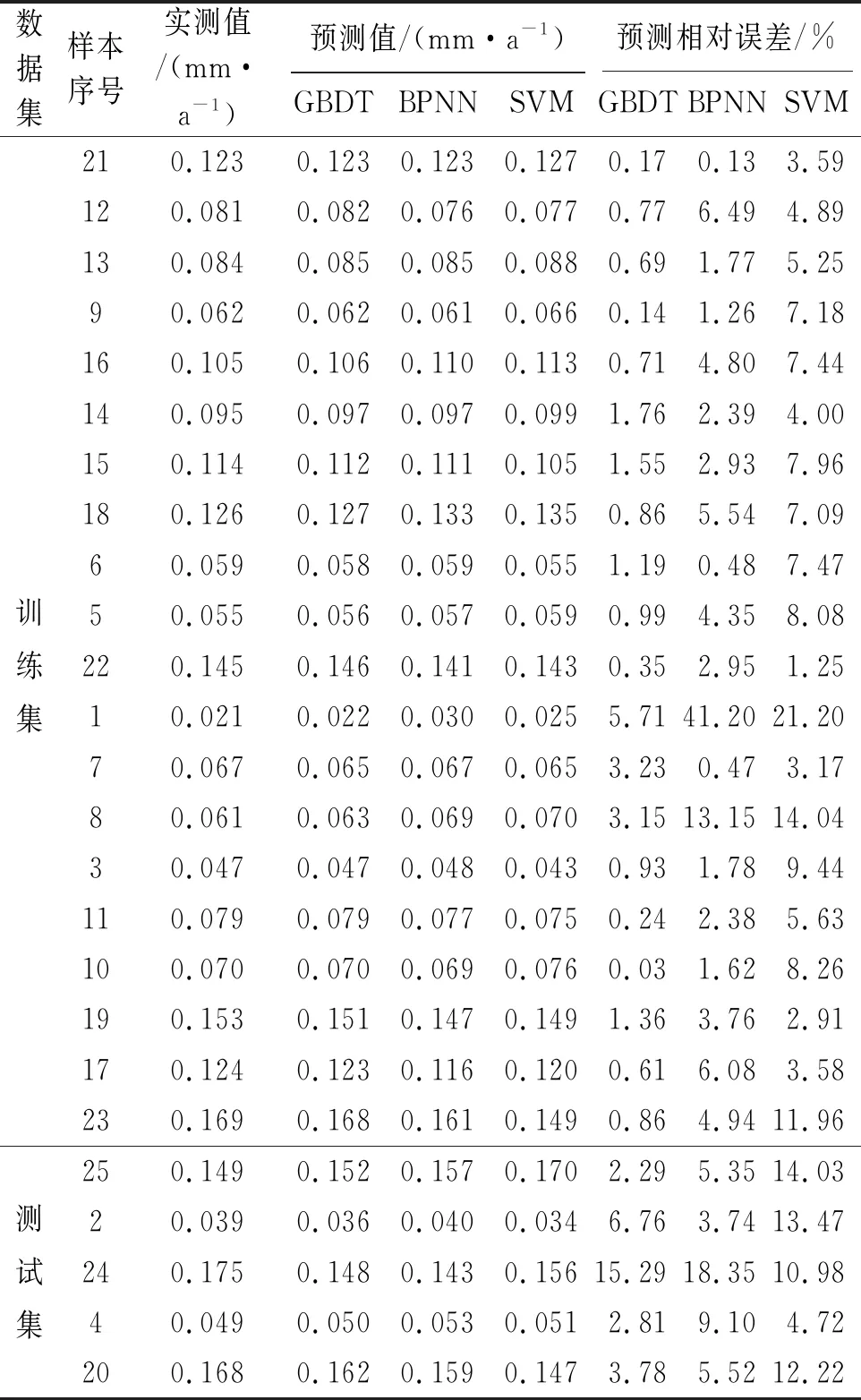
表2 三種模型腐蝕速率的預(yù)測(cè)值和相對(duì)誤差Tab. 2 Predicted corrosion rates and relative errors of three models
從表2和圖2中可以直觀地看出,SVM模型的預(yù)測(cè)效果較差:一方面其預(yù)測(cè)值的相對(duì)誤差和殘差大都高于BPNN模型與GBDT模型的相對(duì)誤差和殘差;另一方面該模型在測(cè)試集上的預(yù)測(cè)殘差遠(yuǎn)大于在訓(xùn)練集上的預(yù)測(cè)殘差,出現(xiàn)了“過擬合”現(xiàn)象。這說明SVM模型的泛化能力比GBDT模型要差一些。對(duì)于腐蝕速率最小的第1個(gè)樣本,三種模型預(yù)測(cè)值的相對(duì)誤差都很大,說明模型對(duì)于數(shù)據(jù)集中最值的預(yù)測(cè)能力都有待提高。但三種模型預(yù)測(cè)值的絕對(duì)誤差仍在可接受的范圍內(nèi),且相比于BPNN模型與SVM模型,GBDT模型的預(yù)測(cè)精度有了很大的提高,預(yù)測(cè)相對(duì)誤差僅為5.71%。
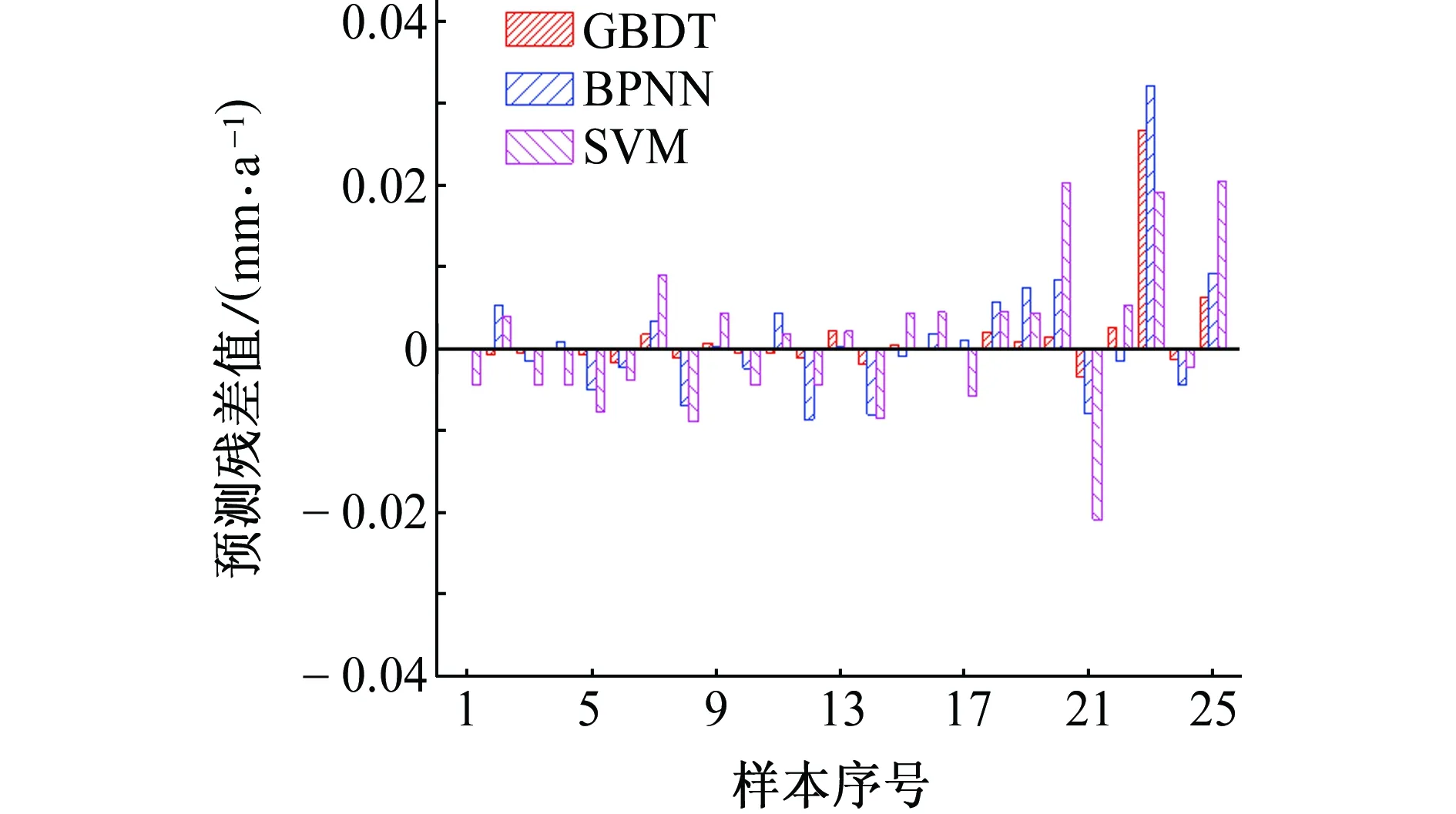
圖2 三種模型預(yù)測(cè)值的殘差Fig. 2 Residual errors of predicted values by three models
為了量化模型的整體預(yù)測(cè)性能,利用式(9)~(11)計(jì)算得到模型預(yù)測(cè)精度指標(biāo)如表3所示。

表3 GBDT、BPNN與SVM模型預(yù)測(cè)精度指標(biāo)Tab. 3 Prediction accuracy indexes of GBDT,BPNN and SVM models
從表3中可以看出,BPNN和SVM模型預(yù)測(cè)結(jié)果的平均絕對(duì)百分誤差分別為6.03%和7.99%,而GBDT模型只有2.25%,且該模型的均方誤差值小;GBDT模型的決定系數(shù)比BPNN和SVM模型的決定系數(shù)更接近于1,說明GBDT模型的整體預(yù)測(cè)效果最好。
為了消除單個(gè)數(shù)據(jù)可能帶來的隨機(jī)性誤差,對(duì)預(yù)測(cè)值與實(shí)測(cè)值進(jìn)行線性擬合分析,結(jié)果如圖3所示。
從圖3中可以看出,三個(gè)模型的預(yù)測(cè)結(jié)果都落在理想擬合直線附近。但是相比較而言,BPNN和SVM模型的預(yù)測(cè)結(jié)果的實(shí)際擬合直線離理想擬合直線更遠(yuǎn)一些。此外,對(duì)于最大腐蝕速率樣本點(diǎn),三種模型的預(yù)測(cè)結(jié)果都明顯地偏離了理想擬合直線,而該樣本點(diǎn)恰好在測(cè)試集中,說明三種模型的外推能力都比較弱。
以上各方面的對(duì)比分析表明,對(duì)于管道腐蝕速率預(yù)測(cè),本工作提出的GBDT模型能夠更好地?cái)M合實(shí)測(cè)數(shù)據(jù),其綜合性能要優(yōu)于BPNN與SVN模型。
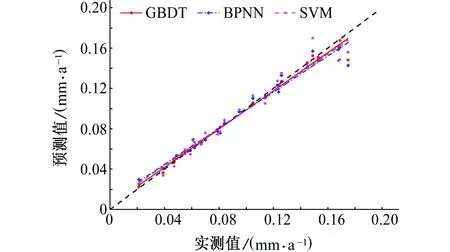
圖3 預(yù)測(cè)值與實(shí)測(cè)值之間的線性擬合Fig. 3 Linear fitting between predicted values and measured values
3.2 對(duì)GBDT模型的進(jìn)一步分析
由式(8)可以看出,GBDT模型的預(yù)測(cè)精度受到模型中決策樹數(shù)量M的影響。圖4顯示了當(dāng)學(xué)習(xí)率v=0.075,最大葉子節(jié)點(diǎn)數(shù)J=4時(shí),包含不同決策樹數(shù)量的GBDT模型預(yù)測(cè)值與實(shí)測(cè)值的對(duì)比結(jié)果。從圖4中可以看出,隨著M的增加,模型預(yù)測(cè)值與實(shí)測(cè)值之間的偏差越來越小,說明增加決策樹能夠提高模型的預(yù)測(cè)性能。但是當(dāng)決策樹達(dá)到一定數(shù)量后,再增加其數(shù)量對(duì)模型預(yù)測(cè)能力的提升作用不大。為了進(jìn)一步驗(yàn)證這一觀點(diǎn),繪制模型預(yù)測(cè)值的平均相對(duì)誤差與決策樹數(shù)量的關(guān)系圖,如圖5所示。
從圖5中可以看出,當(dāng)決策樹數(shù)量小于70時(shí),GBDT模型在訓(xùn)練集和測(cè)試集上的平均相對(duì)誤差隨決策樹數(shù)量的增加都迅速減小,這與BüHLMANN等[24]的分析結(jié)果一致,即隨著決策樹數(shù)量的增長,集成模型的預(yù)測(cè)偏差呈指數(shù)型衰減。當(dāng)決策樹數(shù)量大于70時(shí),GBDT模型在訓(xùn)練集上的平均相對(duì)誤差繼續(xù)減小,但減小速率變慢,而在測(cè)試集上的平均相對(duì)誤差略微上升,說明此時(shí)模型開始出現(xiàn)“過擬合”現(xiàn)象。在這種情況下,可使模型訓(xùn)練提前停止,在不降低模型的整體性能的情況下縮短訓(xùn)練時(shí)間。

(a) M=1 (b) M=2 (c) M=5
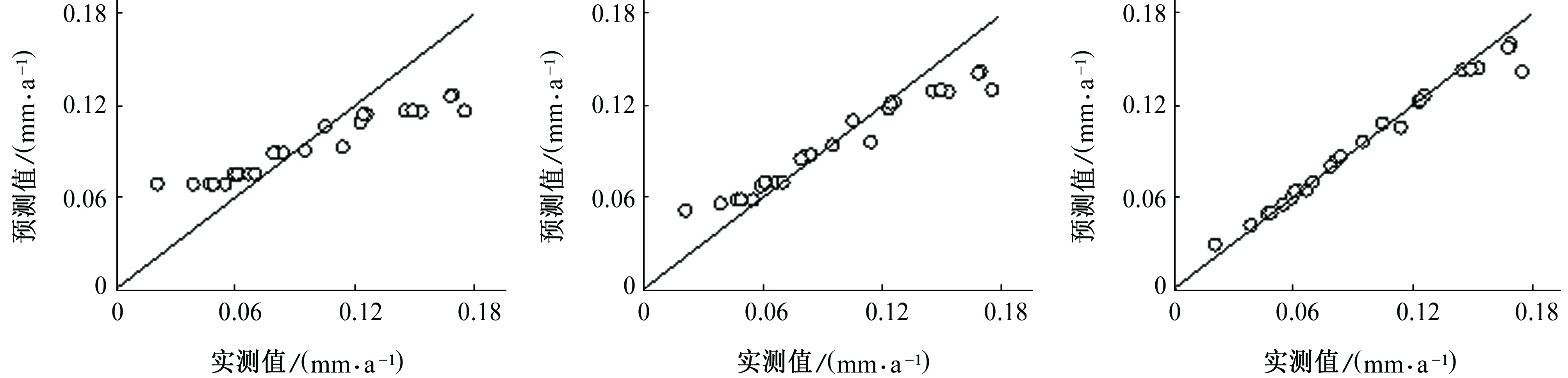
(d) M=10 (e) M=20 (f) M=50
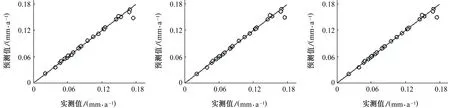
(g) M=100 (f) M=150 (i) M=200圖4 包含不同決策樹數(shù)量的GBDT模型的預(yù)測(cè)結(jié)果Fig. 4 Prediction results of GBDT model with different number of decision trees

圖5 GBDT模型平均相對(duì)誤差與決策樹的數(shù)量之間的關(guān)系Fig. 5 Relationship between average relative error and number of decision trees for GBDT model
4 結(jié)論
(1) 實(shí)例驗(yàn)證結(jié)果表明,對(duì)于管道腐蝕速率預(yù)測(cè),梯度提升決策樹模型能夠取得很高的預(yù)測(cè)精度,其預(yù)測(cè)結(jié)果可為了解管道運(yùn)行狀況及采取適時(shí)的維護(hù)措施提供參考依據(jù)。
(2) 與廣泛應(yīng)用的BPNN和SVM預(yù)測(cè)模型對(duì)比可以發(fā)現(xiàn),基于集成思想的梯度提升決策樹模型不僅能很好地?cái)M合已知數(shù)據(jù),而且對(duì)未知數(shù)據(jù)具有很強(qiáng)的泛化能力,因此具有更大的實(shí)用價(jià)值。
(3)在梯度提升決策樹模型構(gòu)建過程中,隨著決策樹數(shù)量的增加,模型預(yù)測(cè)偏差的減小程度會(huì)迅速降低,因此選擇恰當(dāng)?shù)臎Q策樹數(shù)量,對(duì)于縮短模型的訓(xùn)練時(shí)間和防止“過擬合”現(xiàn)象至關(guān)重要。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡(luò)安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導(dǎo)航定位學(xué)報(bào)(2022年4期)2022-08-15 08:27:00
中學(xué)生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀(jì)智能(數(shù)學(xué)備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學(xué)院學(xué)報(bào)(2021年2期)2021-07-19 08:35:14
新世紀(jì)智能(數(shù)學(xué)備考)(2020年9期)2021-01-04 00:25:14
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
