車輛軌跡與遙感影像多層次融合的道路交叉口識別
2021-12-09 03:13:20李雅麗向隆剛張彩麗吳華意龔健雅
測繪學報 2021年11期
李雅麗,向隆剛,張彩麗,吳華意,龔健雅
武漢大學測繪遙感信息工程國家重點實驗室,湖北 武漢 430079
道路交叉口是構成路網的基礎與核心要素,作為道路網絡的節點,起到了連接道路和承載轉向的重要作用[1]。目前,車輛軌跡與遙感影像由于其覆蓋范圍廣、更新周期短、獲取成本低,成為道路交叉口識別研究的主要數據源。一方面,軌跡數據頻率較低、噪音大,且在路網上分布不均,而遙感影像易受天氣與光照影響,且存在地物遮擋或混淆等現象[2];另一方面,道路交叉口結構復雜、形態多樣、大小不一,且相鄰交叉口可能相距較近,因此提取道路交叉口是一項非常具有挑戰性的工作[3]。為此,學者們利用易于獲得的車輛軌跡或者遙感影像,在道路交叉口識別方面開展了大量研究工作,取得了較為豐碩的研究成果。
基于車輛軌跡的道路交叉口識別一般可分為兩類:一類是基于交叉口處的幾何、拓撲特征,從軌跡中直接提取交叉口。例如,文獻[4—5]基于軌跡中的轉向點對,通過距離和角度對其聚類后提取交叉口;文獻[6]利用G統計對各軌跡相交的角度進行熱點分析,以區分交叉口與非交叉口;文獻[7]基于形狀描述訓練出交叉口分類器,以區分交叉口與非交叉口。另一類是以路網結構為導向的交叉口識別,依據交叉口是多條路段的交匯點這一特征,先識別道路,再識別交叉口[8-11]。例如,文獻[8]首先將軌跡數據柵格化為圖像,然后利用核密度估計等法探測道路區域,最后通過形態學分析獲取骨架線,再據此提取交叉口位置;文獻[12]則集成上述兩類方法的優勢,融合密度峰值聚類和形態學分析進行交叉口識別。
基于遙感影像的道路交叉口識別主要包括基于交叉口的特征提取方法和基于道路的交叉口提取方法。前者利用原始影像上交叉口的表征形式直接提取交叉口,常見方法包括基于模板匹配[13]、基于形狀約束[14]、可變模型部件模型檢測[15],以及深度神經網絡模型識別[16];后者則是在提取得的道路二值圖的基礎上進行交叉口檢測[17-19],例如,文獻[18]先使用分割算法從遙感影像中提取道路二值圖,再通過張量投票檢測出道路二值圖中的交叉點的位置作為道路交叉口。
由于單一數據的描述能力有限,上述的交叉口提取方法難以做到交叉口的全面提取。基于車輛軌跡的交叉口提取方法可以利用交叉口處軌跡特有的空間位置特征和動態連接特征,但由于車輛軌跡空間分布不均勻,無法識別軌跡稀疏區域的交叉口,且存在將大轉彎區域的道路誤識別為交叉口的情況;遙感影像覆蓋面廣,但在場景復雜或受遮擋的區域,交叉口的識別精度較低。而車輛軌跡可以彌補遙感影像中交叉口受其他地物影響的問題,遙感影像可以補充在軌跡稀疏或缺失處的交叉口信息。為了全面、精確地獲取道路交叉口,有必要綜合車輛軌跡與遙感影像各自優勢來提取交叉口。為此,本文提出了一種基于車輛軌跡和遙感數據多層次融合的道路交叉口識別方法。首先,分析道路交叉口區域區別于其他區域的顯著差異性特征,融合多元方法的交叉口提取結果,得到高質量的種子交叉口,并以此作為下一階段小樣本集的標注;然后,利用協同訓練機制開展車輛軌跡分類模型和遙感影像分類模型的多次迭代訓練,從而在種子交叉口的基礎上逐步擴充訓練集的規模,以有效提升兩分類模型的分類能力;最后,設計基于車輛軌跡分類模型和遙感影像分類模型的集成識別方法,以提升交叉口提取的整體性能。
1 研究方法
本文提出的研究方法總體框架如圖1所示:①種子交叉口提取,利用車輛軌跡的空間分布特征和隱含的動力學特征,以及遙感影像的視覺特征,分別通過形態學法、聚類法及張量投票法[19]進行交叉口提取,融合多元方法結果獲取高置信的種子交叉口,并據此生成小樣本集;②基于協同訓練軌跡機制,分別構建車輛軌跡與遙感影像的交叉口分類器,并對兩個分類器進行初步訓練后,對無標簽數據進行概率預測,從中選擇高置信的偽標簽加入訓練集中,再次對兩分類模型進行訓練,如此迭代多次,以優化兩分類器彼此的性能;③集成兩分類模型的結果作為最終交叉口識別結果。
1.1 種子道路交叉口提取
考慮到深度學習模型的效果依賴于訓練集的規模與質量,而手動標注樣本存在人為主觀性,且耗時又煩瑣[20],本文采用多元方法集成獲取的種子交叉口作為標注。具體來說,通過分析車輛軌跡和遙感影像關于交叉口的多模特征,設計多元提取方法并進行結果融合,獲取少量高置信的種子交叉口,據此形成少量樣本集。為確保種子交叉口的正確性,在其提取過程中遵循“真交叉口可遺漏,偽交叉口不可引入”的原則。
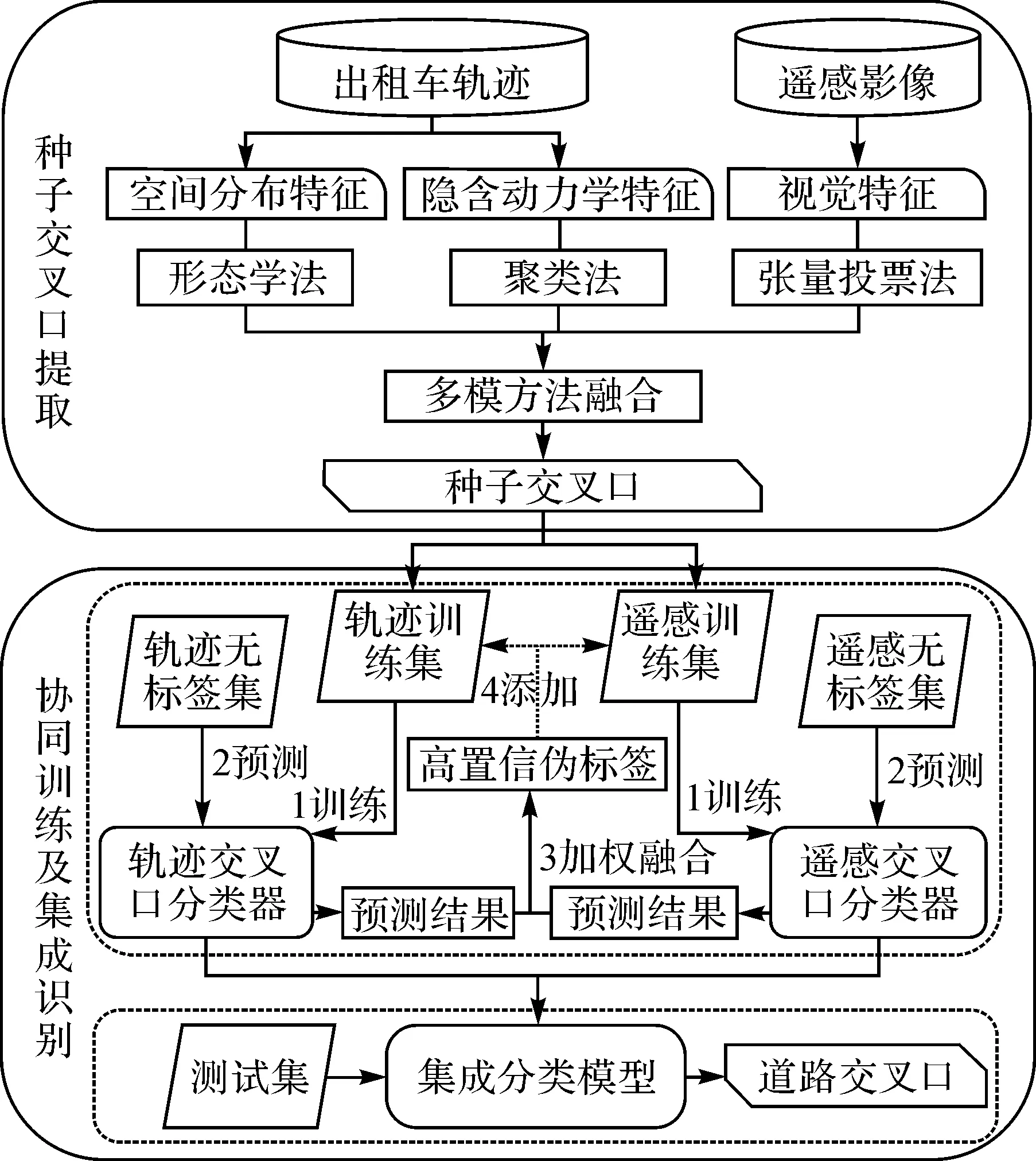
圖1 本文研究方法的總體框架Fig.1 The framework of our method
1.1.1 基于車輛軌跡的交叉口提取
車輛軌跡既包括空間分布特征,也包括隱含的動力學特征,為此,基于車輛軌跡提出兩類交叉口提取方法:①在柵格空間中,分析軌跡在路網上的靜態幾何分布,先提取道路中心線再檢測交叉口;②在矢量空間中,利用速度、方向及大轉向點對等隱含動力學特征,從軌跡的點序列中直接提取交叉口。
在柵格空間中,車輛軌跡按照某一分辨率柵格化后形成柵格特征圖。受軌跡噪音影響,直接采用形態學處理來提取道路中心線將出現大量毛刺,從而帶來大量偽交叉口。去除毛刺處理流程為:首先,利用Roberts邊緣算子提取道路邊緣,并將其從特征圖中剔除,從而獲取具有平滑邊緣的道路二值圖;然后,在其基礎上進行數學形態學開閉運算以及細化操作,用于獲取道路中心線;最后,計算中心線上各個像素的連通度,將連通度大于2的像素標記為交叉點后,通過矢量化獲取交叉口的位置。其中,連通度定義為某像素其八鄰域內像素值不為零的像素個數。
車輛在通過道路交叉口時常伴隨著顯著的方向變化,通過限制連續采樣點的方向、速度及距離可篩選出大轉向角的軌跡片段。但由于本文所采用的為出租車軌跡,其軌跡點間隔較大,計算得到的大轉向軌跡點多落在與交叉口相接的路段上,使其聚類結果不一定位于交叉口區域。針對這一問題,本文采用文獻[3]提出的反向交叉點代替大轉向對,以確保多數待聚類點位于交叉口區域,然后通過密度峰值法確定各聚類簇中交叉口點的位置。
1.1.2 基于遙感影像的交叉口提取
遙感影像中道路交叉口輪廓特征不明顯,且交叉口本身結構復雜、形態多樣,基于遙感影像直接識別較為困難。在文獻[18]的基礎上,進一步發展了兩階段式的交叉口提取方法,即首先獲取道路二值圖,然后從中檢測出交叉口。
在道路二值圖的提取過程中,考慮到深度學習是基于遙感影像進行道路提取的主流技術,且效果遠優于傳統方法。為此,選擇在Deep Globe道路識別競賽中取得第1名的D-LinkNet[21],采用其訓練好的模型提取道路二值圖;道路交叉口在地理空間中表現為點狀特征,考慮到由文獻[22]提出的張量投票算法能夠從二維或三維數據中檢測出交叉點,曲線以及曲面等幾何結構,且該算法被廣泛應用于道路交叉口提取中[18-19],故引入張量投票算法從道路二值圖中檢測交叉口,其主要步驟如下。
(1) 道路二值圖的張量表達,由于分割得到的道路二值圖中的像素點沒有方向性,因此,對所有道路像素點進行無方向性的球張量編碼,即對每個道路像素編碼為大小為2的單位矩陣。
(2) 非線性投票,對所有編碼點進行稀疏投票和稠密投票。
(3) 張量分解,兩次投票后,通過張量分解的計算式(1),獲取交叉口區域的顯著圖λ2
(1)
式中,Ts為棒狀張量分量;(λ1-λ2)為棒狀張量分量的顯著性特征;Tb為球狀張量分量;λ2為球狀張量分量的顯著性特征;當λ1≈λ2>0時,得到球狀張量分量的顯著性特征λ2。
(4) 交叉口點位置的提取,采用非極大值抑制法獲取λ2中各交叉口區域的中心點后,再通過矢量化獲取交叉口中心點的坐標。
1.1.3 種子交叉口提取
總的來說,上述多元交叉口提取方法分為兩類:①假設道路交匯處為交叉口,包括基于車輛軌跡通過形態學方法的交叉口提取和基于遙感影像通過張量投票方法的交叉口提取;②假設在交叉口處車輛軌跡會產生大的轉向角,如基于軌跡動態特征通過聚類生成交叉點。然而僅基于其中一類方法獲取的交叉口置信度較低,如一些空間上交疊的立交橋并不存在聯通,彎曲狀道路也存在大的轉向對。但若某區域基于上述兩類方法均被判定為交叉口,那么該區域為真交叉口的置信度將大大提升。為此,設計下述融合策略來獲取高置信的種子交叉口。
(1) 以軌跡動態特征聚類提取的交叉口位置為基準點做半徑為R的緩沖區。
(2) 統計緩沖區內基于車輛軌跡通過形態學處理和基于遙感影像通過張量投票檢測出的交叉口個數。
(3) 若緩沖區內的交叉口點個數大于0,則計算它們幾何位置中心,作為種子交叉口點位置。
(4) 若其緩沖區內交叉口點個數為0,則舍棄該基準點。
1.2 融合車輛軌跡與遙感影像的協同訓練及集成識別
訓練集規模是深度學習模型效果的重要保障,為了達到利用少量種子樣本集學習出大量樣本數據的目的,本文基于半監督學習思想,設計了協同訓練機制來擴充道路交叉口的訓練樣本數量:首先,利用少量種子樣本集分別訓練車輛軌跡和遙感影像兩種不同的分類網絡,并對無標簽數據的置信度進行評估;然后,將計算的高置信輸出加入訓練集,對兩個分類器更新訓練,經過不斷循環迭代,達到利用少量標簽道路交叉口樣本學習大量樣本數據的效果,提升了兩分類器的識別能力。
1.2.1 協同訓練與集成識別框架
協同訓練算法是一種半監督學習方法,訓練的過程中僅利用少量的帶標簽樣本以及兩個關于目標的獨立且冗余視圖,就可以將無標簽數據自動標注為訓練樣本,使得大量無標簽數據可以得到應用[23]。車輛軌跡和遙感影像提供了關于道路交叉口獨立且互補的特征圖,且在1.1節中獲取了少量樣本的標簽,在此基礎上,本文提出了車輛軌跡與遙感影像的協同訓練框架,如圖2所示。
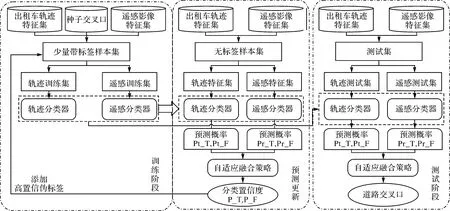
圖2 車輛軌跡與遙感影像的協同訓練框架Fig.2 Co-training framework of vehicle trajectory and remote sensing image
基于車輛軌跡數據和遙感影像的道路交叉口提取的協同訓練機制分為3個階段:訓練階段、預測更新階段和測試階段。
在訓練階段中,應用軌跡訓練集和遙感訓練集訓練兩個神經網絡。其中,考慮到道路交叉口提取是判斷某個位置點是否屬于道路交叉口,屬于二分類問題,故針對軌跡和遙感數據其特征圖的特點,設計兩個不同的深度學習網絡作為道路交叉口分類器。需要注意的是,在初始少量帶標簽樣本集的制作時,基于種子交叉口僅能獲取正樣本。為確保小樣本中的正負樣本的數量均衡,本文提出負樣本的制作方法,具體為以正樣本為位置點為基礎,考慮交叉口本身大小、相鄰交叉口之間的距離,設置與正樣本的位置點相聚一定距離的位置為非交叉口,以獲取負樣本集。
預測更新階段是利用兩個有差異的特征圖和分類器提供偽標簽數據加入訓練集,使得兩分類器可迭代優化彼此的性能,從而使訓練的兩分類器是兩類數據綜合優化的結果。具體步驟為:
(1) 基于同一位置的軌跡和遙感的無標簽樣本,應用相應的分類器分別進行預測,得到基于軌跡特征的正負樣本預測概率值分別為Pt_T、Pt_F,基于遙感特征的正負樣本預測概率值分別為Pr_T、Pr_F,根據分類器對分類精度的貢獻,對兩分類器結果進行自適應加權融合,獲取樣本為正負樣本分類置信度分別為P_T、P_F。
(2) 挑選出分類置信度不低于V的樣本,并將其打上預測的高置信偽標簽后,添加到有標簽樣本集中,同時將它們從無標簽數據集中移除,之后再對兩分類器進行訓練。
(3) 當從無標簽數據預測結果中篩選不出預測概率值大于V的樣本時,停止迭代。
在測試階段,根據待測試點的位置,基于軌跡特征和遙感影像分別生成測試集,利用優化好的車輛軌跡的交叉口分類器和遙感影像分類器分別進行分類預測。由于這兩個分類器有一定的差異,即對相同的樣本可能輸出不同的預測結果。通過自適應加權的方法融合兩個分類器的結果,可以進一步判斷差異性輸出,獲取正確的預測結果。
1.2.2 基于車輛軌跡的交叉口分類
交叉口提取實際是一個二分類問題,即判斷輸入點是否為交叉口。但城市中道路交叉口面積不等,難以在固定分辨率下,使用某一格網來捕獲交叉口,為此,本文對輸入的交叉口位置點采用多尺度信息描述,通過融合多尺度的特征獲取分類結果。又考慮到道路交叉口不是一個孤立的點,其與周圍的環境息息相關[24],將網絡的輸入設定為包含其周圍的鄰域格網信息的特征圖,所設計的車輛軌跡的交叉口分類器模型如圖3所示。
網絡包括3個支路,每個支路代表特定分辨率下的交叉口提取,分支的結構相同,均由兩個卷積核為3,步長為1,填充為0的卷積層,以及兩個全連接層組成。鑒于輸入圖像的大小過小,不對圖像進行降采樣。3個分支的特征圖通過自適應加權的方式融合后,得到作為第5個全連接層的輸入f,融合方式如下
f=w1·f(1)+w2·f(2)+w3·f(3)
(2)
式中,f(1)、f(2)及f(3)為3個分支的特征圖;w1、w2及w3為3個特征圖對應的自適應權重,初始值設置為1,自適應權重通過網絡學習獲得。
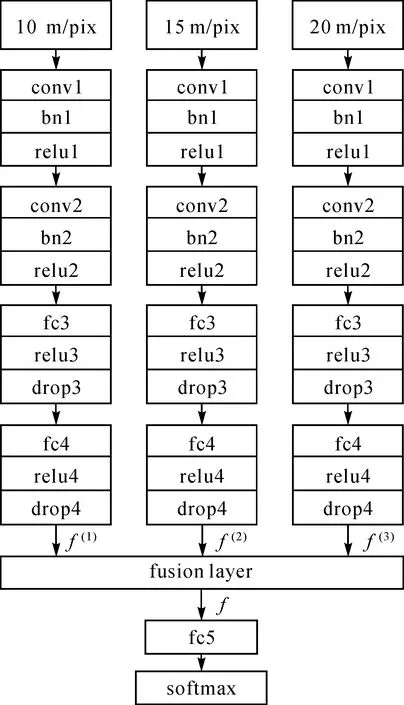
圖3 車輛軌跡的交叉口分類器模型Fig.3 Intersection classifier model of vehicle trajectory
網絡的每一支輸入均包括軌跡點柵格圖、密度圖、鄰接軌跡點轉向圖以及朝向香農熵圖。其中,軌跡點柵格圖反映道路的幾何分布的,計算方法為直接柵格化;密度圖反映由于紅綠燈道路交叉口處產生停留聚集的,計算方法為統計格網內軌跡點個數;鄰接軌跡點轉向圖表示格網是否承當轉向功能的,計算方式為統計落入格網內所有軌跡點其上一個軌跡點與下一個軌跡點的方向差值后,計算方向差值的標準差,標準差越大說明通過該格網的車輛的行為模式差異越大;朝向香農熵圖[25]代表格網內車輛朝向信息復雜程度,按照式(3)計算得到
(3)
式中,n為等間隔角度的數目;pi是屬于第i個間隔的航向角的比例。
1.2.3 基于遙感影像的交叉口分類
相對于車輛軌跡特征圖來說,遙感影像中蘊含的地物信息更為復雜,很難從較小規模的初始樣本集直接訓練出交叉口分類模型,為此,本文采用遷移學習的策略,即在基于ImageNet訓練好的VGG16網絡的基礎上,通過微調獲取遙感影像的交叉口分類模型。具體為凍結用于提取圖像特征的卷積層,對用于提取特定類別特征的全連接層進行微調。使用的遙感影像的交叉口分類器如圖4遙感影像的交叉口分類器所示。特征提取部分由13個3×3的卷積層和5個2×2的池化層組成,分類部分由3個全連接層構成,其中最后一層全連接層由VGG16原來的1000個神經元修改為2個神經元,用于輸出道路交叉口分類二分類結果。
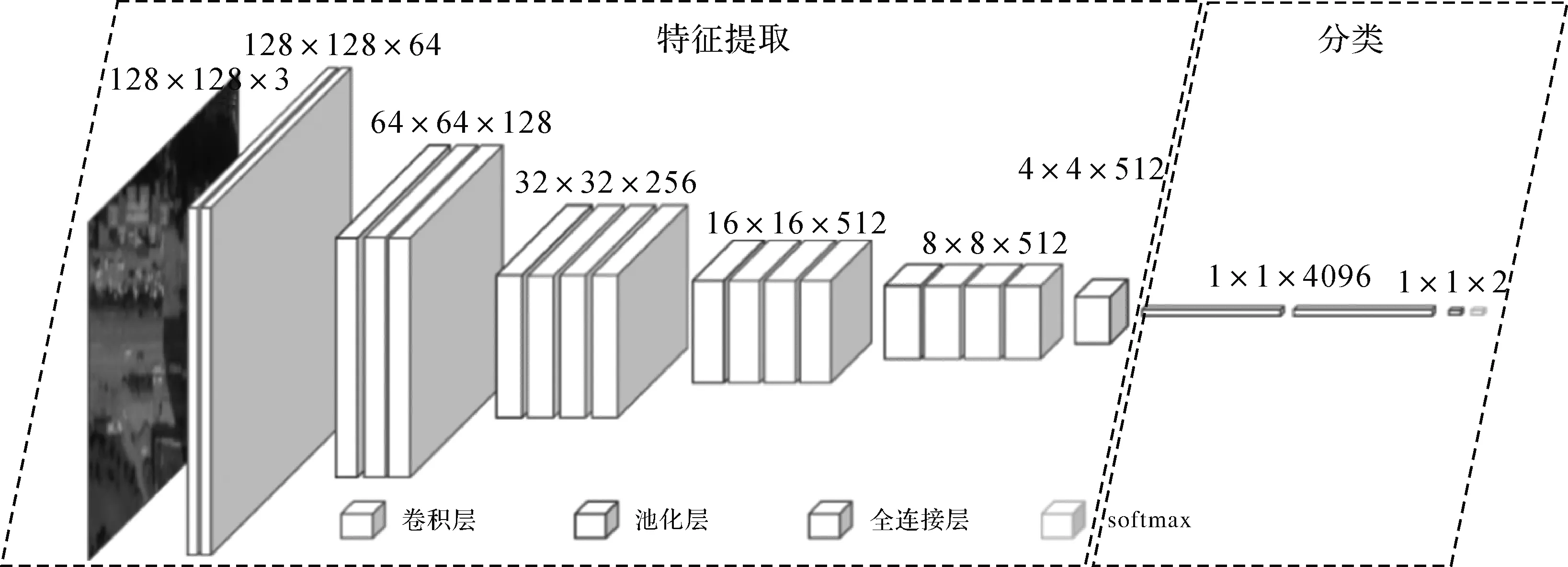
圖4 遙感影像的交叉口分類器Fig.4 Intersection classifier of remote sensing image
1.2.4 自適應加權的分類模型集成
由于車輛軌跡和遙感影像對道路交叉口的描述角度不同,且兩分類器所應用的深度神經網絡結構不同,這就造成在使用兩分類器對同一樣本進行預測時,可能會出現不一致的結果。為了獲取唯一的高置信預測結果,本文結合兩個分類器預測結果的差異性對樣本置信度的影響,根據自適應加權融合策略[26]融合兩分類器的預測結果,從而集成兩分類器優勢,提升預測結果的置信度。其中,權重值按照分類器的類別精度的貢獻確定,自適應加權融合的計算如下
P(k)=w(k)·Pt(k)+(1-w(k))·Pr(k)
(4)
式中,P(k)是第k個類別的融合預測值;k共計兩類,交叉口和非交叉口;Pt(k)和Pr(k)分別是軌跡分類器和遙感分類器輸出的第k個類別的預測值;w(k)是軌跡分類器輸出的第k個類別的權重,其大小依賴于軌跡分類器對圖像屬于第k個類別的分類精度的貢獻,該權重的計算共分為兩步:
(1) 根據式(5)計算兩個分類器關于類別k的歸一化似然值wt(k)和wr(k)
(5)
式中,M是測試樣本總個數;2為總的類別數;Pt(m,k)和Pr(m,k)是兩分類器將第m個樣本預測為類別k的概率值;分子表示類別k的總的平均似然;分母是類別k的平均似然。
(2) 根據式(6)輸出最終的權重值w(k)
(6)
2 試驗與分析
2.1 試驗數據與環境設置
本文所采用的軌跡試驗數據為武漢市區出租車一周的軌跡數據,軌跡點數據量約為1.96 GB。車輛軌跡數據集包含7個字段,具體為:車輛的編號、時間、經度、緯度、瞬時速度、瞬時方向角和狀態。由于軌跡數據來源于出租車,其軌跡點大多落于主要道路,支路上的軌跡點覆蓋度較低或沒有軌跡點,如圖5(a)紅色框所示。本文所采用的遙感影像從谷歌地球獲取,其空間分辨率約為0.5 m。為方便計算,將遙感影像降采樣到空間分辨率1 m,坐標系統轉換至WGS-84坐標系,使其與軌跡數據保持一致。研究區域的遙感影像中包含多類型,不同大小的道路交叉口,且一些交叉口存在被樹木的遮擋的情況,如圖5(b)藍色框所示。
在應用本文提出的交叉口提取方法進行試驗的過程中,涉及參數值包括:①種子交叉口提取階段,軌跡形態學法中的柵格化圖像的空間分辨率為5 m,選用較低分辨率便于提取軌跡稀疏區域的交叉口;車輛軌跡聚類法中,在計算轉向對時,篩選出的轉向對需滿足軌跡點速度小于30 km/h,相鄰軌跡點距離小于200 m及時間間隔小于20 s。在進行轉向對的反向點聚類時,聚類距離為70 m;遙感影像張量投票法中,非極大值抑制的閾值為70 m;多模方法融合中,融合半徑R為50 m。②協同訓練階段,軌跡分類器輸入的多尺度空間分辨率分別為10 m、15 m及20 m,輸入的特征圖大小為7×7,在各尺度下對應實際區域為70 m×70 m、105 m×105 m、140 m×140 m;遙感影像分類器輸入的影像分辨率1 m,影像大小為128×128。在迭代訓練過程中,將分類置信度不低于V的分類結果選作偽標簽,通過試驗發現V取值為95%時,效果最好。
在協同訓練試驗中,操作系統為Ubuntu18.04,顯卡為2塊GeForce GTX 1080Ti,開發工具為Python,框架為Pytorch。車輛軌跡的交叉口分類器的優化器為SGD,迭代批量大小為256,初始學習率為0.1;遙感影像的交叉口分類器的優化器為Adam,迭代批量大小為64,動量參數為0.9,初始學習率為0.01。epoch統一設置為50,兩個分類器均采用交叉熵損失函數。協同訓練中當選擇不出偽標簽時停止迭代,共迭代20次。基于種子交叉口生成的帶標簽小樣本集數量為389,其中正負樣本比例1∶3,無標簽樣本集數量為3162,測試集數量為573。
2.2 試驗結果分析
2.2.1 種子交叉口提取結果
依據車輛軌跡的幾何形態信息及其所蘊含的轉向語義信息,計算基于軌跡點柵格圖獲取的道路交叉口點和轉向對的反向交叉點的聚類中心如圖6。其中,圖6(a)為軌跡點柵格原始圖,含有大量噪音,經過邊緣算子圖6(b)處理后得到邊緣光滑且消除了細小道路的圖6(c),圖6(d)是基于圖6(c)通過形態學算子處理得到的灰色道路中心線和白色道路交叉點,為了方便示意,對其進行3個像素膨脹,通過該方法正確提取出了位于主干道交叉口,但數量較少,遺漏了連接支路的交叉口。圖6(g)中黃色點是基于車輛軌跡計算出的轉向對的反向交叉點。可以看出其探測出的交叉口位置較多,但也將一些彎曲道路誤識別為了交叉口,同時由于一些交叉口位于場所內部,雖然在遙感影像中可以明顯辨識,但由于沒有軌跡點而未能識別。圖6(e)為通過現有道路提取模型D-LinkNet獲得的道路二值圖,可以看出由于模型的遷移能力不足,提取的道路較為細碎。通過腐蝕算子、張量分解和非極大值抑制處理道路二值圖后得到的道路交叉點如圖6(f)所示,可以看出其可以提取社區內部的交叉口,但受圖譜異物的影響,將其他地物誤識別為交叉口。圖6(h)是融合多元方法后獲取的種子交叉口的示意圖,將上述方法中基于先道路后交叉口獲取的交叉口取并集后,再與基于語義信息直接獲取的交叉口取交集,得到兩者的交集的所有幾何中心位置,生成少量種子交叉口。
2.2.2 協同訓練結果
基于協同訓練的方法,經過多次迭代訓練,擴充樣本集后得到模型的預測結果如圖7所示。其中圖7(a)為基于車輛軌跡模型的交叉口提取結果,圖7(b)為基于遙感影像的交叉口提取結果。由圖7中藍色框可以看出,在樹木遮擋但有軌跡點覆蓋的場景下,基于軌跡分類器能夠有效提取交叉口,但此時遙感影像分類器的提取能力較弱。由圖7中紅色框可以看出,基于遙感影像分類器可以提取缺少軌跡覆蓋但空間特征明顯的交叉口,但軌跡分類器無法識別此類交叉口。可見兩種分類器在道路交叉口提取能力上各具優勢且可以互補,但需要注意的是兩類分類器中仍存在一些偽交叉口,因此,為進一步獲取全面、精確的交叉口,需要通過有效的融合方法集成兩分類器的互補優勢,同時注意剔除偽交叉口。
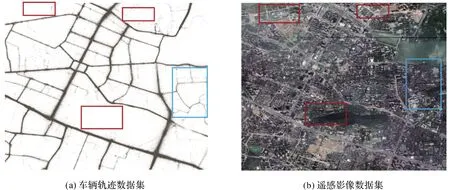
圖5 研究區域數據集Fig.5 Study area data set

圖6 多元方法融合提取種子交叉口Fig.6 Extraction of seeds from intersection by multi method fusion
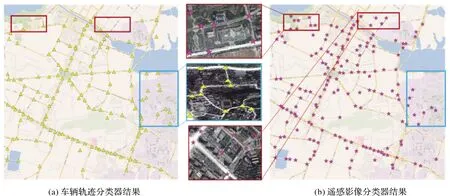
圖7 協同訓練模型結果Fig.7 The results of co-training model
2.2.3 分類模型集成提取結果
圖8(a)是基于自適應加權融合策略融合兩分類器結果所提取的最終道路交叉口結果圖,其中藍色點為正確提取的交叉口;紅色點的位置是通過目視解譯為道路交叉口,但沒有提取到的交叉口;綠色點表示誤提取的交叉口。在本文方法中,車輛軌跡可以彌補遙感影像中交叉口被其他地物遮擋的問題,遙感影像可以補充車輛軌跡稀疏區域的交叉口信息,從而實現兩者優勢互補。例如,圖8(b)表明本文方法可以提取遙感圖像上被樹木遮擋的交叉口。圖8(c)表明缺乏軌跡覆蓋但遙感影像空間特征明顯的交叉口可以被有效提取。圖8(d)表明本文方法可以剔除大轉彎處的偽交叉口。
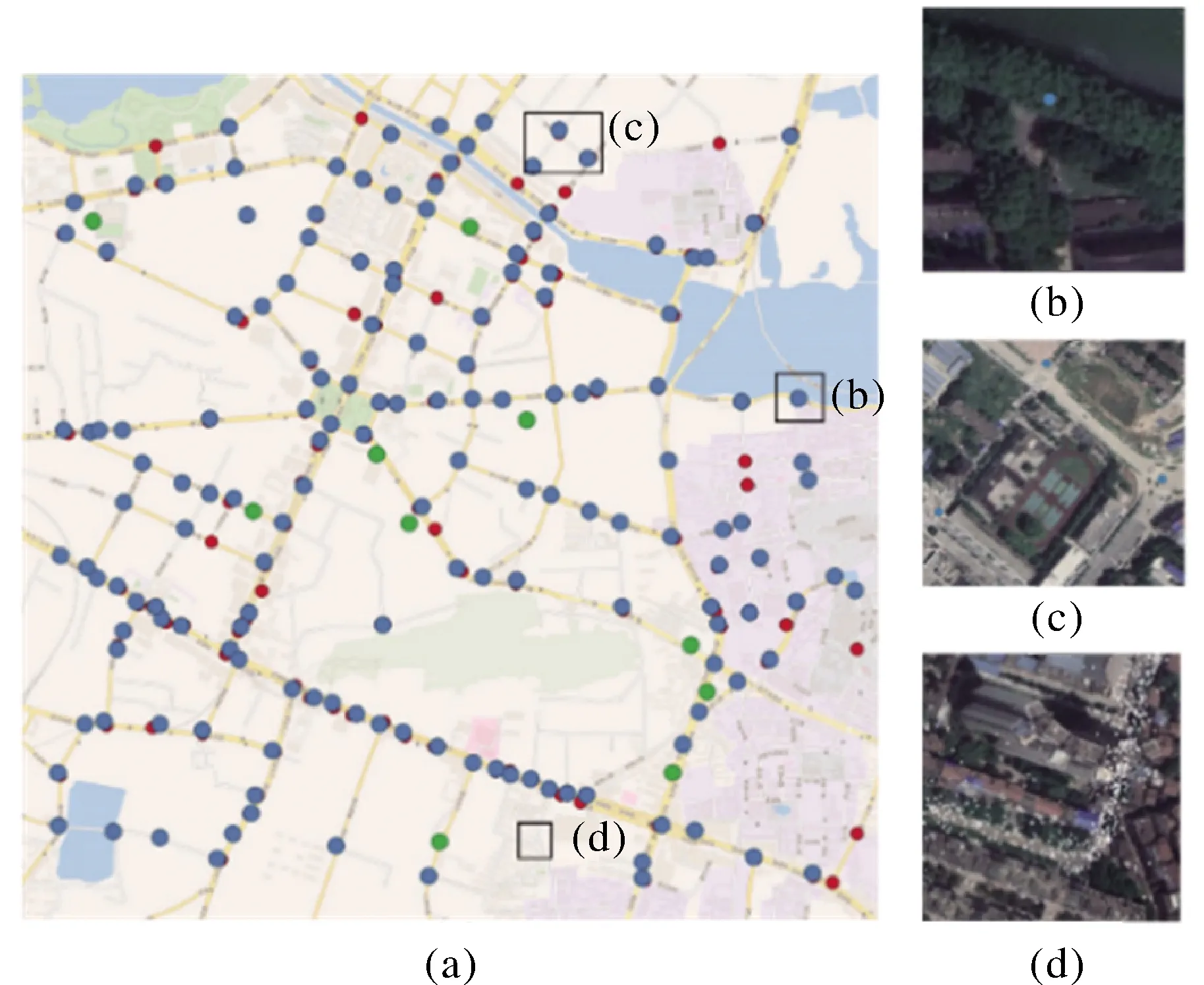
圖8 本文方法的交叉口提取結果Fig.8 Intersection extraction results of our method
為進一步說明本文提出的方法能夠適應于不同情景下的道路交叉口提取,圖9展示了部分典型交叉口的提取細節,不難看出本文方法在道路交叉口提取方面的特點:①可以識別形態迥異、大小不一的多類型交叉口,且不受交叉口之間的距離影響,如圖9(a)所示;②可以識別的道路的分岔點與聚合點,如圖9(b)所示,這對于輔助車輛導航有重要的幫助;③能夠識別大型興趣點的出入口(圖9(c)),如學校和醫院的進出點。
圖10是應用本文方法未能正確提取的道路交叉口。其中,圖10(a)是由于遙感影像中存在與交叉口光譜特征相似的地物,將道路與施工地的連接部分誤識別為交叉口;圖10(b)是由于軌跡噪音點的影響,將一處居民地錯誤識別為交叉口;圖10(c)是遺漏識別的交叉口,該交叉口未能有效提取的原因是:該場景下軌跡點稀疏,同時遙感影像上的交叉口被樹木遮擋使其視覺特征不明顯。

圖9 典型交叉口提取結果Fig.9 Typical intersection extraction results

圖10 未能正確提取的交叉口Fig.10 Intersections not extracted correctly
2.3 精度對比
試驗綜合準確率、召回率及F來衡量模型的預測性能,計算公式為
(7)
(8)
(9)
式中,TP為預測正確的道路交叉口數量;FP為預測錯誤的交叉口數量;FN為未提取出的道路交叉口數量。由于本文提取的為道路交叉口點,而道路交叉口本身具有一定的大小,且位于不同等級道路上的交叉口大小也不同,難以使用固定閾值的緩沖區對交叉口提取效果進行評價,故在定量評價時采用多級緩沖區方法,即根據交叉口所在的道路等級設置其緩沖區范圍。通過對武漢市不同等級道路和交叉口的統計,將交叉口緩沖區分為3級,具體為,將位于主干道和快速路的交叉口緩沖區閾值設置為50 m,將位于次干道的緩沖區閾值設置為40 m,其余支路上的交叉口緩沖區閾值設置為30 m。
針對車輛軌跡數據,本文選用文獻[12]提出的集成形態學方法和聚類方法提取交叉口進行對比,針對遙感影像,采用張量投票方法[18]進行對比。圖11展示了上述幾種方法的提取結果。圖11(a)是將真值按照其所在的道路等級分級,共分為3級,顏色越深級別越高。圖11(b)表明本文方法的交叉口提取數量最接近真值的個數,且不存在明顯的交叉口提取困難的區域。由圖11(c)可以看出集成方法提取的交叉口主要位于測試區域的中部,邊緣區域的交叉口提取個數較少,這是因為測試區域邊緣的軌跡稀疏或是缺乏,受軌跡覆蓋度的限制,該方法無法提取此類區域的交叉口。圖11(d)表明張量投票方法的交叉口提取個數較少,這說明基于遙感影像可以有效提取位于道路特征明顯區域的交叉口,但難以識別被遮擋區域以及與周圍背景區分不明顯區域的交叉口。總的來說,基于單源數據的交叉口提取方法難以突破其數據本身的限制。
表1是以真值所在的道路等級做多級閾值緩沖區后,將本文方法與對比方法的測試區域178個交叉口提取效果進行檢驗。其中最高值用加粗黑體表示, 次高值用下劃線表示。由表1可以看出,本文提出的基于多層次融合的方法,在道路交叉口提取效果上,優于集成方法和張量投票方法。基于單一數據源的集成方法和張量投票的僅提取了少量正確的交叉口,且錯誤提取數量相對較高,使得其召回率和F值均處于小于0.6的區間。本文方法充分利用車輛軌跡和遙感影像各自的優勢,交叉口提取的數量和質量大幅提升,其準確率、召回率和F值分別為0.934 1、0.876 4及0.904 3。
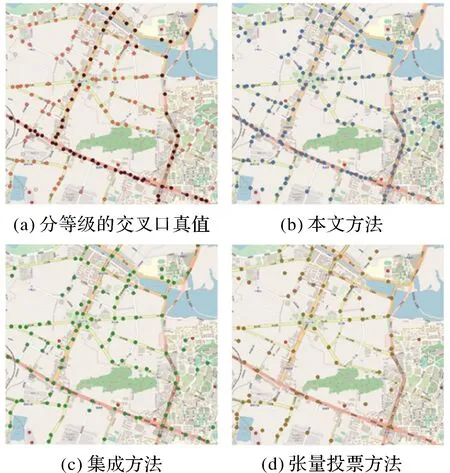
圖11 對比方法的結果Fig.11 The extraction result of comparison methods

表1 測試區域交叉口提取效果對比
2.4 討 論
基于真值的多級緩沖區,對本文在各階段通過多元方法提取的交叉口結果進行了對比(表2)。多元方法包括:①種子交叉口提取過程中,所涉及的形態學方法、聚類方法和張量投票方法,以及種子交叉口融合提取方法;②在協同訓練過程中的訓練階段,基于小樣本集訓練獲取的兩分類模型,以及在其測試階段,基于擴充后的訓練集得到的兩分類模型;③集成識別過程中,本文提出的集成模型。
由表2可以看出,在種子交叉口提取階段,種子交叉口可以融合形態學方法、聚類方法和張量投票的優勢提取少量但準確的種子交叉口。在協同訓練階段,通過協同訓練逐步擴充訓練樣本集的協同訓練融合模型,其各項評價指標,均高于通過監督訓練基于小樣本集的融合模型,這說明加入無標簽樣本后,可有效提升模型的分類能力。基于車輛軌跡數據和遙感影像數據的協同訓練模型的各項指標表現均衡,但指標值均低于本文方法,這也說明了協同訓練的前提下,融合模型的效果要高于僅基于車輛軌跡的模型或僅基于遙感影像的模型。本文方法在各項指標表現優異,召回率和F值均為最高值,但準確率低于僅可以提取少量交叉口的形態學方法和種子交叉口提取。綜上,本文提出的方法能夠有效集成車輛軌跡數據和遙感影像數據的優勢,提取覆蓋全面且質量高的道路交叉口。
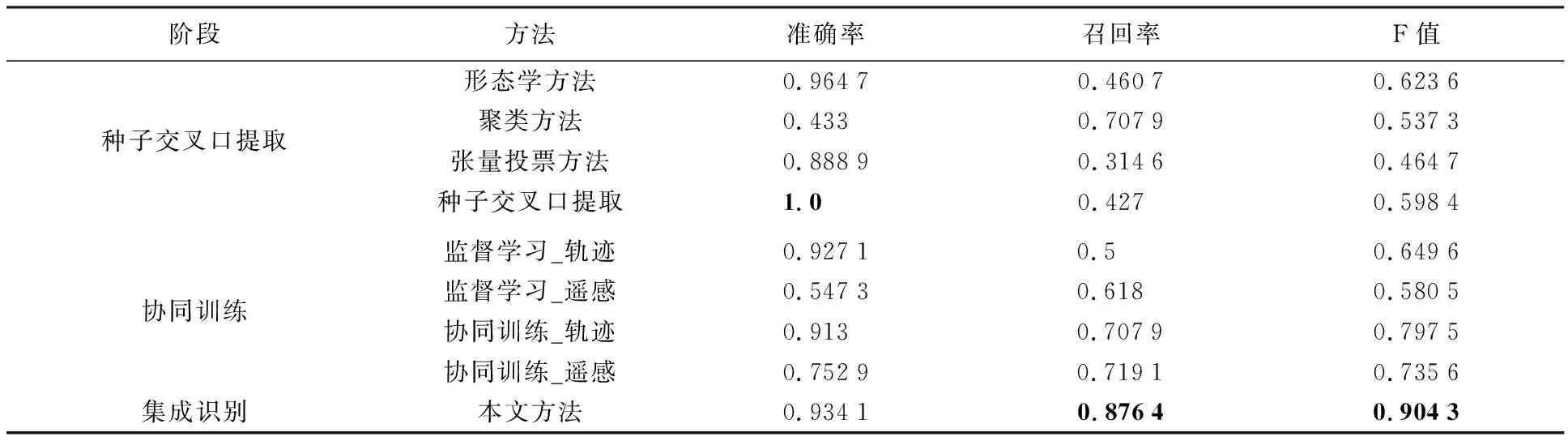
表2 各階段的交叉口提取結果對比
為了進一步說明本文方法的穩定性,圖12展示了在真值不同的緩沖區閾值下,基于綜合評價指標F值對兩個對比方法以及各階段交叉口提取方法的檢驗結果。由圖12可以看出在不同閾值的緩沖區下,本文提出的交叉口提取方法的F值均遠遠高于其他對比方法。
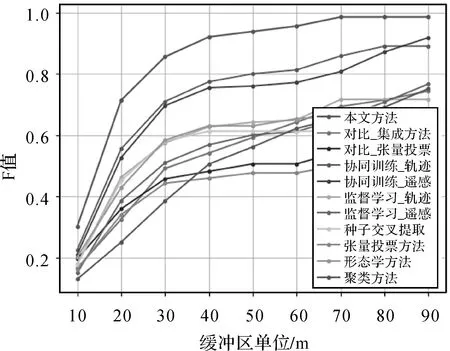
圖12 各類方法的F值對比Fig.12 F-score comparison of various methods
3 結 論
考慮到道路交叉口不僅反映在車輛軌跡的靜態分布特征和動態轉向特征中,還呈現在遙感影像的紋理特征上,本文提出了一種車輛軌跡與遙感影像多層次融合的道路交叉口識別方法,彌補了單一數據源在道路交叉口提取上的不足。基于武漢市數據的試驗表明,本文方法在種子交叉口生成、協同訓練以及集成識別多個階段融合車輛軌跡與遙感影像的交叉口描述特征,可以提取形態迥異、大小不等的道路交叉口,識別精確度超過93%,召回率達到87%。
本文方法充分利用車輛軌跡和遙感影像關于交叉口的互補性描述特征,不僅可以有效解決被遮擋區域和軌跡稀疏區域的交叉口提取問題,還能夠提取輔路與主路交匯點,以及興趣點的出入口。此外,所提出的半監督式交叉口提取技術,無須人工標注樣本,具有較高的穩健性與可擴展性。需要指出的是,本文主要針對簡單交叉口的提取問題開展研究,后續將對立交橋等復雜交叉口進行研究。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
兒童故事畫報(2019年5期)2019-05-26 14:26:14
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
意林原創版(2016年10期)2016-11-25 10:28:30
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
