多模型融合的客服工單文本分類方法的研究與實(shí)現(xiàn)
2021-12-10 06:10:56張亮代曉菊鄭榮賀同澤
電信科學(xué) 2021年11期
張亮,代曉菊,鄭榮,賀同澤
多模型融合的客服工單文本分類方法的研究與實(shí)現(xiàn)
張亮1,代曉菊1,鄭榮1,賀同澤2
(1. 上海理想信息產(chǎn)業(yè)(集團(tuán))有限公司,上海 201315;2. 北京郵電大學(xué),北京 100876)
電信呼叫中心客服在人工進(jìn)行工單分類時(shí)存在歸檔耗時(shí)長、效率低、準(zhǔn)確率難以保障的問題,但此場(chǎng)景下類別數(shù)量多,且類別間具有層級(jí)關(guān)聯(lián),導(dǎo)致傳統(tǒng)文本分類方法準(zhǔn)確率較低。針對(duì)此問題,提出了一種基于多模型融合的文本分類方法,根據(jù)不同層級(jí)的數(shù)據(jù)特點(diǎn)使用不同模型進(jìn)行分類,考慮了類別的層級(jí)關(guān)聯(lián)以提升準(zhǔn)確率,并驗(yàn)證了此方法的有效性,可以優(yōu)化客服生產(chǎn)系統(tǒng)運(yùn)營流程,加快現(xiàn)場(chǎng)人工客服響應(yīng)能效,提升客服熱線整體運(yùn)營效率,實(shí)現(xiàn)人工智能注智生產(chǎn)。
文本分類;客服工單;多模型融合;運(yùn)營效率
1 引言
目前國內(nèi)傳統(tǒng)的呼叫中心,主要通過人工客服和自助語音助手兩種方式,全天候提供咨詢、訂購辦理、投訴建議等熱線服務(wù)。目前自助語音助手只能幫助用戶進(jìn)行簡單的查詢和訂購操作,而面對(duì)復(fù)雜業(yè)務(wù)訴求,諸多用戶還是會(huì)選擇人工客服來處理訴求。人工客服不但要記住客戶訴求,還要在相關(guān)業(yè)務(wù)運(yùn)營系統(tǒng)進(jìn)行分類歸檔,勢(shì)必會(huì)耗費(fèi)大量時(shí)間,完全采用人工的方式進(jìn)行管理越來越不能滿足實(shí)際的需求,并且伴隨用戶需求劇增和變化,對(duì)呼叫中心的接通率提出更高和更全面的要求,勢(shì)必需要融入各種新技術(shù)來使之適應(yīng)需求。
以電信客服呼叫中心為例,目前日均呼入量為25 000通,而接通率為92%,電話訴求日均受理量已達(dá)到20 000多件,每位人工客服日均受理80通電話或錄音。每通電話平均處理時(shí)長為5.75 min,其中通話平均時(shí)長為3.25 min,案頭歸檔平均處理時(shí)長為2.5 min。平臺(tái)完全依賴人工、服務(wù)能力趨于飽和,人工客服工作強(qiáng)度大,服務(wù)效率難以提升,最終導(dǎo)致接通率難以保證。人工客服在受理訴求時(shí),需要耗費(fèi)大量時(shí)間去理解分析、手工整理用戶訴求內(nèi)容,并且工單業(yè)務(wù)分類體系復(fù)雜(多層級(jí)、多類別)、操作流程煩瑣,十分依賴于人工客服的知識(shí)儲(chǔ)備和經(jīng)驗(yàn)?zāi)芰Γ窃斐呻娦趴头艚兄行倪\(yùn)營效率產(chǎn)生瓶頸的主要原因。
為進(jìn)一步提升呼叫中心服務(wù)渠道“對(duì)內(nèi)智能輔助、對(duì)外智能服務(wù)”的能力,通過引入人工智能技術(shù)——中文文本自動(dòng)分類,實(shí)現(xiàn)用戶訴求的快速記錄及工單準(zhǔn)確分類歸檔。
本文針對(duì)電信客服呼叫中心人工客服在實(shí)際運(yùn)營系統(tǒng)的重點(diǎn)、難點(diǎn)問題,結(jié)合并使用了目前若干前沿的中文本分類技術(shù)和算法,提出了一個(gè)多模型融合的客服工單文本分類方法,解決人工客服進(jìn)行工單分類歸檔耗時(shí)長和準(zhǔn)確率低的問題,為呼叫中心提供了一種自動(dòng)快捷、高效準(zhǔn)確的面向分類結(jié)構(gòu)復(fù)雜的工單文本分類系統(tǒng),優(yōu)化客服生產(chǎn)系統(tǒng)運(yùn)營流程,加快現(xiàn)場(chǎng)人工客服響應(yīng)能效,提升客服熱線整體運(yùn)營效率。
目前隨著機(jī)器學(xué)習(xí)、深度學(xué)習(xí)算法研究的逐漸深入,文本分類的方式、方法得到不斷改進(jìn)、優(yōu)化,特別是在中文文本分類領(lǐng)域的研究成果日新月異,但很多研究的前沿技術(shù)都聚焦在較少類別的分類體系任務(wù)上,對(duì)超多類別且成層級(jí)體系的文本分類問題研究較少。多層級(jí)分類體系的特點(diǎn)在于不同層級(jí)的數(shù)據(jù)具有不同的規(guī)模,且層級(jí)間存在一定聯(lián)系。然而,現(xiàn)有方法通常著重于挖掘?qū)蛹?jí)間關(guān)聯(lián),對(duì)每個(gè)層級(jí)使用相同的模型,卻忽略了每個(gè)層級(jí)的數(shù)據(jù)特點(diǎn)不同,單一模型并不適用于全部層級(jí)。因此,本文將基于電信客服領(lǐng)域工單文本,設(shè)計(jì)了多模型融合算法(multi model fusion algorithm,MMF),根據(jù)各層級(jí)的數(shù)據(jù)特點(diǎn)選擇合適的模型,實(shí)現(xiàn)工單自動(dòng)多級(jí)分類,以及提高分類準(zhǔn)確度作為主要研究方向。
2 文本分類算法
中文文本自動(dòng)分類是計(jì)算機(jī)對(duì)中文自然語言按照一定的分類體系或標(biāo)準(zhǔn)進(jìn)行自動(dòng)化歸類、標(biāo)記的過程,根據(jù)一個(gè)已標(biāo)注的文檔集合,訓(xùn)練學(xué)習(xí)得到文檔特征和文檔標(biāo)簽類別之間的關(guān)系模型,然后利用這種關(guān)系模型對(duì)新的文檔進(jìn)行類標(biāo)簽進(jìn)行判斷、預(yù)測(cè)。現(xiàn)針對(duì)本文實(shí)驗(yàn)過程中使用的算法如XGBoost、TextCNN、HFT-CNN、BERT做具體介紹。
2.1 XGBoost算法
極度梯度提升(extreme gradient boosting,XGBoost)算法,是一種boosted tree的可擴(kuò)展機(jī)器學(xué)習(xí)算法,經(jīng)常被用在一些大型文本類比賽中,效果顯著。它是目前最快最好的開源boosted tree工具包,能夠高效、靈活和便利地進(jìn)行大規(guī)模并行boosted tree算法操作。XGBoost 所應(yīng)用的算法就是全梯度下降樹(gradient boosting decision tree,GBDT)的改進(jìn),既可以用于分類也可以用于回歸問題。XGBoost算法的實(shí)現(xiàn)流程如下。
輸入 訓(xùn)練樣本={(1,1), (2,2),…, (,)},最大迭代次數(shù),損失函數(shù),正則化系數(shù)、;
輸出 強(qiáng)學(xué)習(xí)器();
迭代輪數(shù):=1,2,…,;
步驟1 計(jì)算第個(gè)樣本(=1,2,…,)在當(dāng)前輪損失函數(shù),計(jì)算所有樣本的一階導(dǎo)數(shù)和二階導(dǎo)數(shù)。
步驟2 基于當(dāng)前節(jié)點(diǎn)嘗試分裂決策樹,默認(rèn)分?jǐn)?shù)值為0,和為當(dāng)前需要分裂的節(jié)點(diǎn)的一階二階導(dǎo)數(shù)之和。
步驟3 基于最大值對(duì)應(yīng)的劃分特征和特征值分裂子數(shù)。
步驟4 如果最大值為0,則當(dāng)前決策樹建立完畢,計(jì)算所有葉子區(qū)域的權(quán)重,得到弱學(xué)習(xí)器,更新強(qiáng)學(xué)習(xí)器,并進(jìn)入下一輪弱學(xué)習(xí)器的迭代。如果最大值不為0,則從步驟2繼續(xù)嘗試分裂決策樹。
XGBoost廣泛應(yīng)用最重要的原因是具有可擴(kuò)展性。從工業(yè)界應(yīng)用的落地情況來看,XGBoost的分布式版本具有廣泛的可移植性,支持在MPI、YARN等多個(gè)平臺(tái)上運(yùn)行,同時(shí)得益于XGBoost保留了單機(jī)并行版本的各種優(yōu)化,使得工業(yè)界數(shù)據(jù)規(guī)模的問題可以得到很好的解決。
2.2 TextCNN算法
TextCNN算法模型結(jié)構(gòu)是CNN結(jié)構(gòu)的一個(gè)變體,如圖1所示。

圖1 TextCNN算法結(jié)構(gòu)模型




其中,表示一個(gè)非線性函數(shù),表示權(quán)重,表示偏移量。
然后對(duì)每一個(gè)特征向量進(jìn)行最大化池化操作并拼接各個(gè)池化值,最終得到句子的特征表示,將這個(gè)句子向量輸入分類器進(jìn)行分類,至此完成整個(gè)流程。
針對(duì)文本淺層特征的抽取TextCNN能力很強(qiáng),在短文本搜索、對(duì)話等領(lǐng)域?qū)W⒂谝鈭D分類時(shí)效果很好,并且速度快,應(yīng)用較為廣泛。由于TextCNN主要靠濾波器窗口抽取特征,針對(duì)長文本領(lǐng)域中的長距離建模方面能力受限,且對(duì)語序不敏感,因此應(yīng)用不是特別突出。
2.3 HFT-CNN算法
HFT-CNN模型類似于TextCNN,使用的是fastText進(jìn)行詞向量計(jì)算,輸入是由詞向量拼接而成的短文本句子序列,接著使用卷積核為的卷積層提取句子特征,然后添加池化層,將這些池化層的結(jié)果拼接然后經(jīng)過全連接層和Dropout(降低過擬合的可能性進(jìn)而提高模型的泛化能力)得到上層標(biāo)簽[A,B,...]的概率,損失函數(shù)采用交叉熵。
HFT-CNN針對(duì)下層標(biāo)簽的預(yù)測(cè)是基于在上層標(biāo)簽的預(yù)測(cè)模型中已經(jīng)學(xué)到了通用特征,但更深層的網(wǎng)絡(luò)需要去學(xué)習(xí)原始數(shù)據(jù)集中比較詳細(xì)的信息。因此模型中對(duì)詞嵌入和卷積層參數(shù)保持不變,在這個(gè)基礎(chǔ)上進(jìn)行微調(diào)學(xué)習(xí),這一步標(biāo)簽也由[A,B]變?yōu)閇A1,A2,B1,B2]。采用了兩種得分方式來對(duì)最終文本分類的結(jié)果進(jìn)行判斷:布爾評(píng)分函數(shù)(boolean scoring function,BSF)和乘法評(píng)分函數(shù)(multiplicative scoring function,MSF)。這兩種得分方法都是設(shè)置一個(gè)閾值,預(yù)測(cè)文本在某個(gè)分類標(biāo)簽的得分超過閾值則認(rèn)為是該分類標(biāo)簽。區(qū)別在于BSF只有在文本被分到一級(jí)分類標(biāo)簽時(shí)才會(huì)認(rèn)為分類的二級(jí)分類標(biāo)簽是正確的,MSF則沒有此限制。對(duì)標(biāo)簽的分類,模型是先學(xué)習(xí)比較通用的特征知識(shí),然后再進(jìn)行細(xì)分。
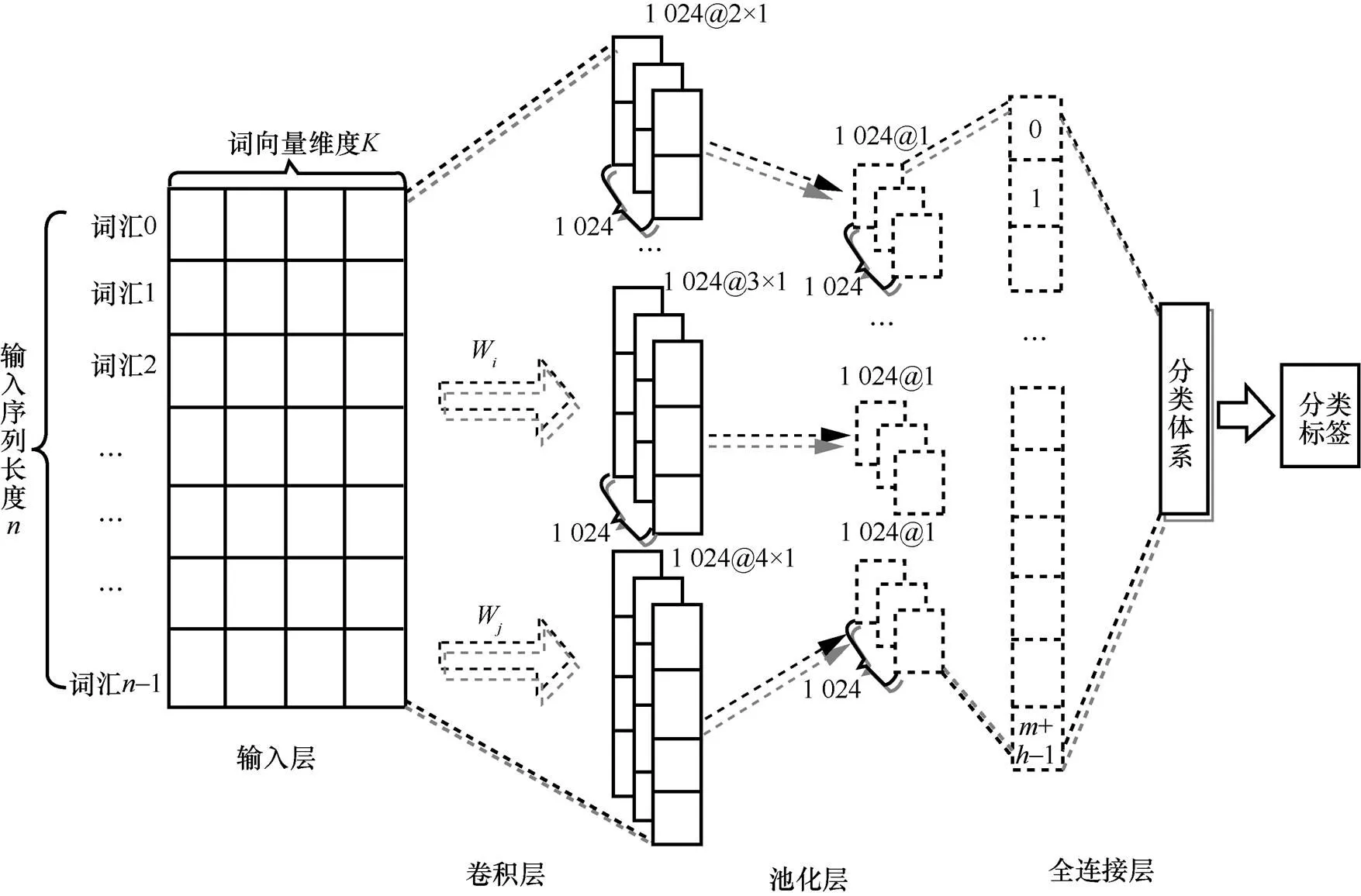
圖2 TextCNN算法流程
HFT-CNN模型標(biāo)簽層級(jí)化微調(diào)思路值得深入研究,但是也存在一些問題:一方面是關(guān)于差異性特征抽取問題;另一方面,按照遍歷遞進(jìn)思路,多元標(biāo)簽數(shù)量多,層級(jí)也比較高,則模型會(huì)變得異常復(fù)雜,訓(xùn)練的速度很慢。這也是工業(yè)界未能廣泛應(yīng)用的重要原因。
2.4 BERT算法
BERT(bidirectional encoder representation from transformers)算法模型是一種基于雙向Transformer構(gòu)建的語言模型。語言模型(language model)是指找到一串字或詞序列的概率分布,可以表示一個(gè)句子或序列出現(xiàn)的概率,通過概率模型表示文本語義,從而可以量化地衡量一段文本存在的可能性,也就是這個(gè)句子或序列的邏輯是否通順。對(duì)于一段長度為的文本序列,序列里每個(gè)單字或詞都有上文預(yù)測(cè)該單字或詞的過程,所有單字或詞的概率乘積可以用來評(píng)估文本存在的可能性。Transformer是首個(gè)完全依靠自注意力機(jī)制來計(jì)算其輸入和輸出表示,而不使用序列對(duì)齊的循環(huán)或卷積的神經(jīng)網(wǎng)絡(luò)轉(zhuǎn)換模型,旨在解決序列到序列的關(guān)聯(lián)任務(wù),同時(shí)能夠輕松處理長時(shí)序依賴。此處“轉(zhuǎn)換”是指將輸入序列轉(zhuǎn)換成輸出序列。Transformer創(chuàng)建的核心理念是通過注意力和重復(fù)機(jī)制,徹底處理輸入和輸出之間的依賴關(guān)系。BERT的模型架構(gòu)是一個(gè)多層雙向Transformer編碼器,且BERT模型中與Transformer相關(guān)的實(shí)現(xiàn)和原Tranformer結(jié)構(gòu)幾乎一樣。BERT的設(shè)計(jì)不同于單向語言模型(ELMo、GPT)來學(xué)習(xí)通用語言表征,它是受到完型填空任務(wù)的啟發(fā),通過在所有網(wǎng)絡(luò)層中對(duì)單個(gè)字或詞的左右上下文進(jìn)行聯(lián)合調(diào)節(jié),將來自未標(biāo)記文本的深層雙向表示進(jìn)行預(yù)先訓(xùn)練,減輕單向語言模型的約束問題。

圖3 BERT算法的預(yù)訓(xùn)練和微調(diào)
使用BERT主要有兩個(gè)步驟:預(yù)訓(xùn)練和微調(diào),如圖3所示。在預(yù)訓(xùn)練期間,BERT模型的主要作用是在不同任務(wù)的未標(biāo)記數(shù)據(jù)上進(jìn)行訓(xùn)練學(xué)習(xí);而微調(diào)的時(shí)候,BERT模型是用預(yù)訓(xùn)練好的參數(shù)進(jìn)行初始化,基于下游任務(wù)的已有標(biāo)簽的數(shù)據(jù)來訓(xùn)練學(xué)習(xí)的。盡管最初的時(shí)候都是用預(yù)訓(xùn)練好的BERT模型參數(shù),但每個(gè)下游任務(wù)有自己的微調(diào)模型。模型將預(yù)訓(xùn)練模型和下游任務(wù)模型結(jié)合在一起,下游任務(wù)中仍然使用BERT模型,而且支持文本分類任務(wù),在做文本分類任務(wù)時(shí)不需要對(duì)模型做修改。將BERT在大量的領(lǐng)域相關(guān)數(shù)據(jù)上繼續(xù)訓(xùn)練,使得BERT更好地適應(yīng)于相關(guān)領(lǐng)域的文本分布表示,最終在該領(lǐng)域的下游任務(wù)上取得進(jìn)一步的提升。
很多實(shí)驗(yàn)證明BERT適合處理句子對(duì)匹配類的任務(wù),在GLUE(general language understanding evaluation)這種綜合的NLP數(shù)據(jù)集下,對(duì)幾乎所有類型的NLP任務(wù)(除了生成模型外),BERT預(yù)訓(xùn)練都有明顯促進(jìn)作用。但是,GLUE的各種任務(wù)有一定比例的數(shù)據(jù)集規(guī)模偏小,領(lǐng)域也還是相對(duì)有限,例如在書面文本領(lǐng)域表現(xiàn)較好,而對(duì)于口語文本領(lǐng)域的表現(xiàn)就相對(duì)較差。隨著BERT本身能力的各種增強(qiáng),絕大多數(shù)NLP子領(lǐng)域都會(huì)被統(tǒng)一到BERT兩階段+Transformer特征抽取器的方案框架上,預(yù)訓(xùn)練技術(shù)對(duì)于很多應(yīng)用領(lǐng)域的確產(chǎn)生了很大的促進(jìn)作用。
3 多模型融合算法分類方法
3.1 基本思路
由于單級(jí)的文本分類系統(tǒng)在分類類別特別多時(shí),受到類別空間大、數(shù)據(jù)稀疏性的影響,準(zhǔn)確率較低,因此現(xiàn)有的針對(duì)超多類別的文本分類系統(tǒng)多為基于分級(jí)結(jié)構(gòu)的方法。然而,現(xiàn)有的基于分級(jí)結(jié)構(gòu)的方法多為每級(jí)使用相同的機(jī)器學(xué)習(xí)模型或深度學(xué)習(xí)模型,但忽略了不同的層級(jí)上的數(shù)據(jù)特點(diǎn)不同,適合的模型也不同,導(dǎo)致部分層級(jí)準(zhǔn)確率較低。為了驗(yàn)證這一觀點(diǎn),本文使用TextCNN在四級(jí)分級(jí)結(jié)構(gòu)的每一層直接進(jìn)行分類,結(jié)果見表1。第一級(jí)和第二級(jí)的類別個(gè)數(shù)相對(duì)較少,且每一類別的數(shù)據(jù)量也較為充足,TextCNN在這兩級(jí)的也有著較高的準(zhǔn)確率。而第三級(jí)的類別個(gè)數(shù)則多至上百個(gè),每個(gè)類別的數(shù)據(jù)量有明顯的降低,在第四級(jí)這種現(xiàn)象進(jìn)一步加劇,導(dǎo)致TextCNN模型的準(zhǔn)確率很低。因此本文提出了基于分級(jí)結(jié)構(gòu)的多模型融合算法,結(jié)構(gòu)如圖4所示,提升分類準(zhǔn)確率。
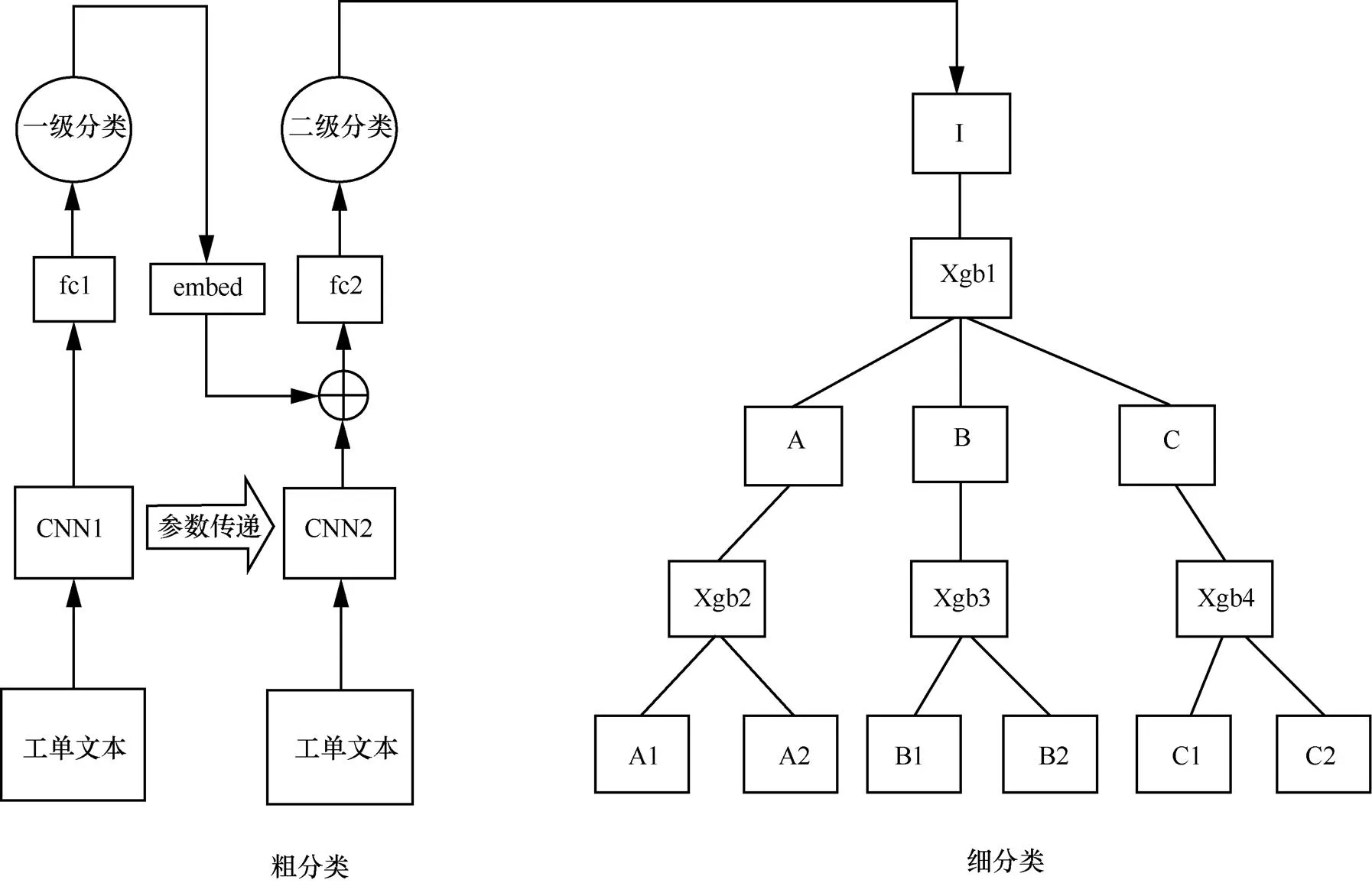
圖4 MMF模型整體結(jié)構(gòu)

表1 各級(jí)分類數(shù)據(jù)及直接使用TextCNN分類準(zhǔn)確率情況
為了充分利用標(biāo)簽的分級(jí)特性,解決深度模型在靠后層級(jí)上分類準(zhǔn)確率下降的問題,將分類模塊設(shè)計(jì)為兩個(gè)子模塊,分別為粗分類模塊和細(xì)分類模塊,分類流程如圖5所示。粗分類模塊的目的是將文本分類到非最后一層的某一層葉節(jié)點(diǎn)類別上,由于數(shù)據(jù)量充足且類別空間較小,可以采用深度學(xué)習(xí)模型進(jìn)行分類,本文采用TextCNN作為分類器。細(xì)分類模塊則是將粗分類得到的結(jié)果繼續(xù)沿著分級(jí)結(jié)構(gòu)向下分類,直至分類到最后一層類別節(jié)點(diǎn)上,由于分類空間變大,數(shù)據(jù)更加稀疏,所以本文采用針對(duì)每一個(gè)類別訓(xùn)練分類器的方式,并使用對(duì)數(shù)據(jù)量要求較低的XGBoost作為分類器。

圖5 分類流程
3.2 基于TextCNN的粗分類
粗分類模塊流程如圖6所示,以粗分類級(jí)數(shù)為2級(jí)為例。在粗分類模塊中,將文本分類到較高層的類別,由于分類空間相對(duì)最后一集較小,所以很多深度學(xué)習(xí)方法都可以使用,選擇了經(jīng)典的TextCNN模型。

圖6 粗分類模塊流程
然而,接近百種類別的類別空間仍然會(huì)導(dǎo)致模型受到數(shù)據(jù)稀疏性的影響,對(duì)于TextCNN這種含有大量的參數(shù)的模型而言,在小數(shù)據(jù)集上訓(xùn)練會(huì)極大地影響泛化能力,通常會(huì)導(dǎo)致過度擬合,為緩解這種影響,本文采用微調(diào)的技術(shù)訓(xùn)練模型。微調(diào)的動(dòng)機(jī)是觀察到TextCNN上層可以捕捉到對(duì)許多任務(wù)都有效的通用的特性,TextCNN后面的層則逐漸變得更與任務(wù)相關(guān)聯(lián),以捕捉到原始數(shù)據(jù)集中包含的細(xì)節(jié)。這個(gè)動(dòng)機(jī)與將類別標(biāo)簽做分級(jí)的動(dòng)機(jī)是相同的,因?yàn)楸疚氖紫葘⒉煌念悇e在層次結(jié)構(gòu)的上層進(jìn)行相對(duì)粗粒度的區(qū)分,然后在底層進(jìn)行更加細(xì)粒度的區(qū)分,也就是說,上層的標(biāo)簽更加具有泛化性。因此在層級(jí)之間對(duì)TextCNN做微調(diào),可以充分利用類別標(biāo)簽的層級(jí)結(jié)構(gòu)。具體的方法是,將第一層TextCNN模型的上層參數(shù),包括詞向量、卷積層、池化層傳遞到第二層的TextCNN模型,然后對(duì)下層參數(shù),即全連接層使用訓(xùn)練數(shù)據(jù)微調(diào),以此類推。
考慮到前面幾級(jí)的類別標(biāo)簽數(shù)量較少,且具有較強(qiáng)正交性,即類別之間區(qū)分較為明顯,對(duì)后續(xù)的分類有更強(qiáng)的影響。如果第一級(jí)模型將文本分類為交通類,那第二級(jí)的模型應(yīng)該更關(guān)注在交通類的子類別中進(jìn)行細(xì)分,又因?yàn)槟P驮谇懊鎺准?jí)分類準(zhǔn)確率較高,所以本文采取在后續(xù)層級(jí)的分類中引入上一級(jí)模型向量的方式來輔助當(dāng)前層級(jí)模型的學(xué)習(xí)。圖6中,將第一級(jí)TextCNN模型的最后一層向量與第二級(jí)TextCNN模型的最后一層向量做拼接后,經(jīng)過全連接層輸出分類類別。如果粗分類包括多于兩級(jí)的話,則對(duì)其他級(jí)也做如上操作。
3.3 基于XGBoost的細(xì)分類
經(jīng)過粗分類后,每個(gè)樣本被分類到了中間層的某個(gè)類別上。這時(shí),如果繼續(xù)用粗分類的框架繼續(xù)分類,則會(huì)面臨分類空間巨大,數(shù)據(jù)非常稀疏的情況,深度學(xué)習(xí)方法由于需要足夠數(shù)據(jù)量支撐,不再適用,即使通過微調(diào)的方式緩解,模型的準(zhǔn)確度依然不高。為解決這個(gè)問題,本文采用針對(duì)每個(gè)類別單獨(dú)訓(xùn)練模型的方式,而不是使用一個(gè)模型分類所有類別。這樣做的優(yōu)勢(shì)在于每個(gè)模型的分類空間變小,分類難度降低。但同時(shí),考慮到每個(gè)模型對(duì)應(yīng)的訓(xùn)練數(shù)據(jù)也變少了,使用對(duì)訓(xùn)練數(shù)據(jù)量要求較小的XGBoost算法。相比于深度學(xué)習(xí)算法,XGBoost有較強(qiáng)的非線性擬合能力,在訓(xùn)練數(shù)據(jù)較少時(shí)仍有比較好的記憶性,且只占用CPU資源,可以同時(shí)進(jìn)行多個(gè)模型的訓(xùn)練和預(yù)測(cè)。
XGBoost算法需要人為構(gòu)造特征作為輸入。通過觀察數(shù)據(jù)發(fā)現(xiàn),多數(shù)類別是具有較為明顯的關(guān)鍵詞的,所以首先將文本數(shù)據(jù)集分詞并且除去停用詞以后,進(jìn)行文本特征詞的提取。在文本的特征詞提取中,關(guān)注的是某個(gè)詞與類別是否存在比較強(qiáng)的相關(guān)性。如果是,那么這個(gè)詞就具有表征此類文章的能力,則可以作為此類文本的特征詞。為了表示某個(gè)詞與某個(gè)類別的相關(guān)性,本文使用CHI檢驗(yàn)方法提取特征詞。通過給每一類文本選出150維的特征并去重,可以獲得1 000維左右的特征,接著為每個(gè)文本構(gòu)造向量空間模型,即使用詞頻-逆文件頻率(TF-IDF)的方法計(jì)算各特征的權(quán)重得到表示該文本的特征向量,就將原本的單個(gè)文本轉(zhuǎn)化成了1 000維特征向量,對(duì)應(yīng)一個(gè)分類類別號(hào)這種可以方便使用XGBoost算法分類的數(shù)據(jù)。
在某一層進(jìn)行分類后,每條樣本都會(huì)得到對(duì)應(yīng)分類類別的概率分布,常用的是類別選擇方式是貪心搜索,即將概率最高的類別當(dāng)作此條樣本在這一層的類別,下一層在這個(gè)類別的基礎(chǔ)上繼續(xù)分類,但由于在下一級(jí)是針對(duì)每個(gè)類別的子類別進(jìn)行細(xì)分,層級(jí)之間具有強(qiáng)依賴關(guān)系,這種貪心搜索的方式只能保證局部最優(yōu)而不能保證全局最優(yōu),如果在上一級(jí)分錯(cuò),那下一級(jí)的分類結(jié)果也一定是錯(cuò)的。為了緩解這個(gè)問題,本文采用束搜索的方式,通過挑選概率最高的兩個(gè)類別,然后在下一層用這兩個(gè)類別對(duì)應(yīng)的子模型進(jìn)行分類,每個(gè)子模型同樣保留概率最高的兩個(gè)類別,當(dāng)分類到最后一層時(shí),每個(gè)分類類別都對(duì)應(yīng)著一條路徑,將這個(gè)路徑上對(duì)應(yīng)的概率相乘,將乘積最大對(duì)應(yīng)的類別作為最終的分類結(jié)果。如圖7所示,加粗的路徑為按照上述邏輯選出來的路徑。
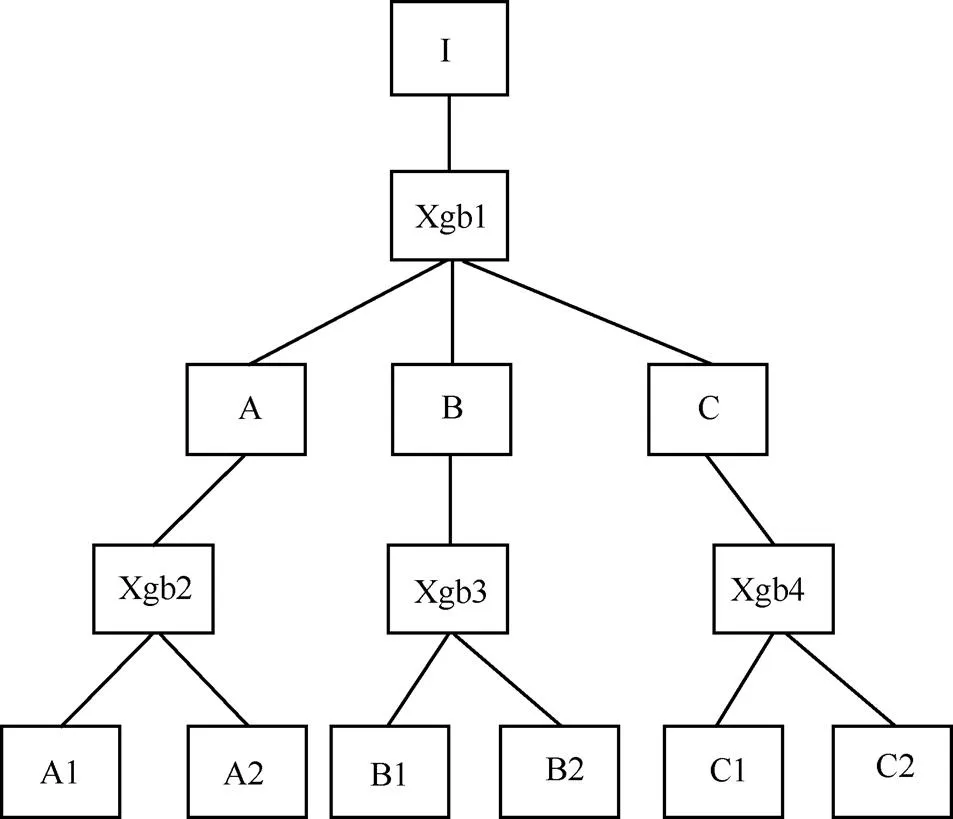
圖7 細(xì)分類模塊流程
4 實(shí)驗(yàn)結(jié)果及分析
4.1 實(shí)驗(yàn)數(shù)據(jù)
為了驗(yàn)證基于分級(jí)結(jié)構(gòu)的多模型融合工單分類方法的可行性和優(yōu)勢(shì),本文將其與現(xiàn)有的文本分類模型進(jìn)行驗(yàn)證和比對(duì)。實(shí)現(xiàn)了基于分級(jí)結(jié)構(gòu)的多模型融合工單分類方法包括文本預(yù)處理模塊和分類模塊,分類模塊又可以分為基于TextCNN的粗分類和基于XGBoost的細(xì)分類兩個(gè)子模塊。文本樣本輸入系統(tǒng)后,首先進(jìn)行文本預(yù)處理,處理為適合下游模型輸入的數(shù)據(jù)格式,常用手段包括過濾非中文信息、模板提取和文本分詞等。然后輸入分類模塊開始進(jìn)行分類,得到分類結(jié)果。
實(shí)驗(yàn)驗(yàn)證數(shù)據(jù)集為客服中心某套餐業(yè)務(wù)2018年、2019年的工單數(shù)據(jù)。數(shù)據(jù)集包含80 482條樣本,將其劃分為訓(xùn)練集和測(cè)試集,訓(xùn)練樣本72 000條,測(cè)試樣本8 482條,數(shù)據(jù)集的標(biāo)簽體系分為四級(jí),每級(jí)的類別數(shù)和數(shù)據(jù)情況見表1。
數(shù)據(jù)預(yù)處理基于 Python3/SKLearn 實(shí)現(xiàn);模型訓(xùn)練和驗(yàn)證,基于 Python3/TensorFlow1.14 實(shí)現(xiàn)。
4.2 實(shí)驗(yàn)環(huán)境
實(shí)驗(yàn)環(huán)境硬件采用的是P40顯卡(運(yùn)行內(nèi)存24 GB),軟件開發(fā)環(huán)境為:CUDA(10.1)、cuDNN(7.4)、Anaconda(4.10.1)、Python(3.6)、 Tensoflow-gpu(1.14)、Scikit-learn(0.23.2)。
4.3 評(píng)估方法
實(shí)驗(yàn)分別驗(yàn)證了TextCNN、分級(jí)TextCNN、BERT、分級(jí)BERT、XGBoost、分級(jí)XGBoost、HFT-CNN和本文提出的MMF共8種模型在數(shù)據(jù)集上的準(zhǔn)確率(所有預(yù)測(cè)四級(jí)分類全部正確的樣本/總樣本)。對(duì)于TextCNN模型,設(shè)置其卷積核窗口大小為(2,3,4),步長為1;對(duì)于BERT模型,使用與論文中相同的超參數(shù)設(shè)置。對(duì)于XGBoost模型,由于數(shù)據(jù)量較少容易導(dǎo)致過擬合,對(duì)其進(jìn)行了較為細(xì)致的調(diào)參,設(shè)置樹模型最大深度為5,樹的個(gè)數(shù)為100,特征子采樣比率為0.7,L1正則化參數(shù)為0.5,L2正則化參數(shù)為1,學(xué)習(xí)率為0.05。
4.4 實(shí)驗(yàn)結(jié)果和分析
4.4.1 實(shí)驗(yàn)結(jié)果對(duì)比
模型實(shí)驗(yàn)對(duì)比結(jié)果見表2,通過對(duì)比可以看出,直接用單一模型分類所有類別的TextCNN、BERT和XGBoost方法準(zhǔn)確率較低,BERT相比于TextCNN的提升也十分有限。而基于分級(jí)的方法,分級(jí)TextCNN、分級(jí)BERT、分級(jí)XGBoost、HFT-CNN和本文提出的方法則明顯優(yōu)于非分級(jí)方法,說明在類別空間非常大的時(shí)候,利用標(biāo)簽的分級(jí)體系進(jìn)行分類是非常有必要的。其中,分級(jí)BERT和HFT-CNN比分級(jí)XGBoost方法的準(zhǔn)確率更高,說明進(jìn)行級(jí)別之間的參數(shù)共享是可以進(jìn)一步緩解數(shù)據(jù)稀疏性的。

表2 模型試驗(yàn)對(duì)比結(jié)果
本文提出的MMF明顯超過了其他對(duì)比方法,相比分級(jí)BERT方法高出3.8%,相比HFT-CNN方法高出3.9%,相比分級(jí)XGBoost方法高出5.1%,相比分級(jí)CNN高出6.3%。主要原因在于使用了粗分類和細(xì)分類的分類架構(gòu),前者利用數(shù)據(jù)量較為充足的優(yōu)勢(shì),使用分級(jí)的TextCNN模型進(jìn)行分類,并且為了充分利用層級(jí)結(jié)構(gòu),本文使用了層級(jí)之間TextCNN模型的參數(shù)共享。后者采用對(duì)每個(gè)子類別單獨(dú)分類的方法,用訓(xùn)練更多模型換取更高的精度,同時(shí)使用對(duì)數(shù)據(jù)量要求較小的XGBoost方法作為分類器,減輕過擬合的風(fēng)險(xiǎn)。在粗分類的時(shí)候,同時(shí)還將第一級(jí)模型的最后一層的向量加入到后續(xù)層級(jí)的模型中,使得后續(xù)層級(jí)分類時(shí)更關(guān)注在其父類類別上。此外,細(xì)分類時(shí)本文采用束搜索的方式來獲得全局最優(yōu)的分類效果。
本文在粗分類里將第一級(jí)模型的最后一層的向量加入后續(xù)層級(jí)的模型中,提高粗分類的分類精度,在細(xì)分類中采用束搜索的方式來獲得全局最優(yōu)的分類效果,為了驗(yàn)證這兩個(gè)操作的有效性,本文分別針對(duì)這兩個(gè)操作進(jìn)行消融實(shí)驗(yàn),實(shí)驗(yàn)結(jié)果如圖8所示,模型嵌入(model embedding,ME)和束搜索(beam search,BS)分別代表著模型分別將這兩個(gè)操作去掉的實(shí)驗(yàn)結(jié)果,可以看到,粗分類中將第一級(jí)模型向量加入后續(xù)模型可以帶來1.48%的收益,這說明第一層模型的分類效果對(duì)后續(xù)模型有著較大的影響,通過讓后續(xù)模型關(guān)注在父類類別的子類別上,可以有效縮小分類空間,提升粗分類精度。此外,細(xì)分類中的束搜索可以帶來0.93%的收益,這說明與貪婪搜索相比,束搜索通過擴(kuò)大搜索空間,可有效減輕單個(gè)模型精度不足導(dǎo)致的錯(cuò)分情況。

圖8 模型向量和束搜索的有效性驗(yàn)證
4.4.2 分級(jí)方法性能比較
為了更好地體現(xiàn)本文提出的分類框架的優(yōu)越性,本文將每一級(jí)的準(zhǔn)確率指標(biāo)與同為分級(jí)方法的分級(jí)TextCNN、分級(jí)BERT、分級(jí)XGBoost、HFT-CNN進(jìn)行比較,其結(jié)果如圖9所示。與分級(jí)BERT、分級(jí)XGBoost方法相比,本文提出的方法在前兩級(jí)的分類效果上有明顯提升,原因在于模型的粗分類模塊是用的分級(jí)TextCNN,準(zhǔn)確率要好于分級(jí)XGBoost算法;在后兩級(jí)上,本模型的表現(xiàn)也好于另外3種分級(jí)的方法(分級(jí)TextCNN、分級(jí)BERT、分級(jí)XGBoost),這說明了針對(duì)每個(gè)子類單獨(dú)訓(xùn)練XGBoost模型可以有效緩解分類空間大的問題,并且使用XGBoost作為分類器有效防止了數(shù)據(jù)量少帶來的過擬合問題。
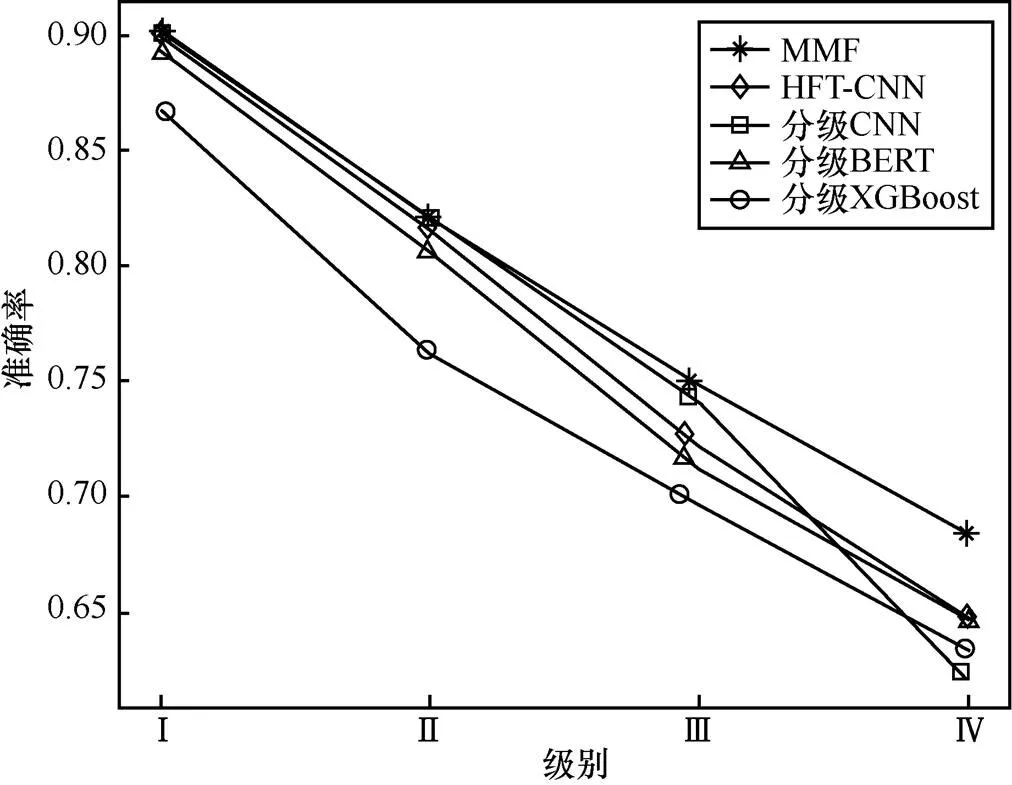
圖9 分級(jí)方法性能比較
5 結(jié)束語
文本分類一直有著廣泛的應(yīng)用需求,然而現(xiàn)有的方法在針對(duì)分類類別數(shù)目較少的情況時(shí)性能較好,當(dāng)分類空間增大時(shí),算法的準(zhǔn)確性會(huì)降低。
由于文本的多層級(jí)的特殊性,即使每層的分類器準(zhǔn)確率超過90%,受到多層級(jí)分類器累積的影響,最終準(zhǔn)確率值并未達(dá)到一個(gè)較高的水平。后續(xù)建議在提高語音轉(zhuǎn)文本準(zhǔn)確率的同時(shí),加強(qiáng)數(shù)據(jù)預(yù)處理操作(包括停用詞、同義詞、糾錯(cuò)等方式)提高輸入數(shù)據(jù)的質(zhì)量,同時(shí)希望能結(jié)合領(lǐng)域?qū)<抑R(shí),重新梳理工單本身的分類結(jié)構(gòu)體系,保證工單類別盡可能精確、獨(dú)立。
本文在分析了現(xiàn)有方法劣勢(shì)的基礎(chǔ)上,提出了一個(gè)基于分級(jí)結(jié)構(gòu)的多模型融合的工單分類方法,包括粗分類和細(xì)分類兩個(gè)子分類模塊,前者使用層級(jí)TextCNN獲得粗粒度的分類,后者通過對(duì)每個(gè)子類別學(xué)習(xí)多個(gè)樹分類器,進(jìn)行更精細(xì)的分類。通過在實(shí)際生產(chǎn)數(shù)據(jù)集上的實(shí)驗(yàn)驗(yàn)證可發(fā)現(xiàn),本文提出的分類框架可有效提升分類效果。
[1] KIM Y. Convolutional neural networks for sentence classification[C]//Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). USA: Association for Computational Linguistics, 2014.
[2] MA M B, HUANG L, ZHOU B W, et al. Dependency-based convolutional neural networks for sentence embedding[C]//Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 2: Short Papers). USA: Association for Computational Linguistics, 2015.
[3] Devlin J, Chang M W, Lee K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[EB]. 2018.
[4] ZHAO Z W, WU Y Z. Attention-based convolutional neural networks for sentence classification[C]//Interspeech 2016. [S.l:s.n.], 2016.
[5] SHIMURA K, LI J Y, FUKUMOTO F. HFT-CNN: learning hierarchical category structure for multi-label short text categorization[C]//Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. USA: Association for Computational Linguistics, 2018.
[6] CHEN T Q, GUESTRIN C. XGBoost: a scalable tree boosting system[C]//Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM Press, 2016: 785-794.
[7] ZHANG Z Y, HAN X, LIU Z Y, et al. ERNIE: enhanced language representation with informative entities[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. USA: Association for Computational Linguistics, 2019.
[8] KALCHBRENNER N, GREFENSTETTE E, BLUNSOM P. A convolutional neural network for modelling sentences[C]// Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). USA: Association for Computational Linguistics, 2014.
[9] YIN W P, SCHüTZE H. Multichannel variable-size convolution for sentence classification[C]//Proceedings of the Nineteenth Conference on Computational Natural Language Learning. USA: Association for Computational Linguistics, 2015.
Research and implementation of text classification method for customer service orders based on multi-model fusion
ZHANG Liang1, DAI Xiaoju1, ZHENG Rong1, He Tongze2
1. Shanghai Ideal Information Industry (Group) Co., Ltd., Shanghai 201315, China 2. Beijing University of Posts and Telecommunications, Beijing 100876, China
Due to the large amount of order categories and their hierarchical associations, traditional manual order classification method of customer service in telecom call center has the problems of long archiving time, low efficiency and unsustainable accuracy. To solve this problem, a novel text classification algorithm based on multi-model fusion was proposed, which intelligently classify orders with multiple models based on data characteristics and their hierarchical associations, the effectiveness of this method was verified. The current manual operation process was optimized and operation efficiency was enhanced, which support the intelligent transformation and upgradation of existing customer service system.
text classification, customer service order, multi-model fusion, operational efficiency
TP391.1
A
10.11959/j.issn.1000?0801.2021236

張亮(1991?),男,上海理想信息產(chǎn)業(yè)(集團(tuán))有限公司軟件產(chǎn)品研發(fā)工程師,主要研究方向?yàn)槿斯ぶ悄芗夹g(shù)、自然語言處理、大數(shù)據(jù)挖掘與分析。
代曉菊(1990?),女,上海理想信息產(chǎn)業(yè)(集團(tuán))有限公司軟件產(chǎn)品研發(fā)工程師,主要研究方向?yàn)槿斯ぶ悄芗夹g(shù)、自然語言處理、大數(shù)據(jù)挖掘與分析。

鄭榮(1981?),男,上海理想信息產(chǎn)業(yè)(集團(tuán))有限公司軟件產(chǎn)品研發(fā)高級(jí)工程師,主要研究方向?yàn)槿斯ぶ悄芗夹g(shù)、自然語言處理、大數(shù)據(jù)挖掘與分析。
賀同澤(1996?),男,北京郵電大學(xué)碩士生,主要研究方向?yàn)橥扑]系統(tǒng)、自然語言處理、大數(shù)據(jù)挖掘與分析。
Shanghai Internet Big Data Engineering Technology Research Center (No.15DZ2250700)
2021?03?22;
2021?10?14
上海互聯(lián)網(wǎng)大數(shù)據(jù)工程技術(shù)研究中心資助項(xiàng)目(No.15DZ2250700)
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
