結合Bi?2DPCA與CNN的美式手語識別
2021-12-20 12:35:46楊明羽葉春明
計算機工程 2021年12期
楊明羽,葉春明
(上海理工大學 管理學院,上海 200093)
0 概述
手語通過擺出不同的手臂與手的姿勢,輔以表情及其他肢體動作傳達信息,是聾啞人重要的溝通語言,也是幫助他們融入社會的重要工具[1]。美式手語(American Sign Language,ASL)是適用于美國、加拿大等地區的手語語言[2-3]。在ASL 中,包含靜態手勢和動態手勢,以J 和Z 表示動態手勢,其余字母表示靜態手勢。但由于人類的手非常靈活,可以擺出很多形狀,因此增加了手勢識別的難度。
近年來,許多學者在ASL 圖片的識別問題上,使用流行的神經網絡進行研究。ASHA 等[4]提出一種通過提取靜態ASL 圖片的特征直方圖、統計量度等進行神經網絡訓練的識別算法,最高識別率為98.17%。QUTAISHAT 等[5]通過使用霍夫變換和神經網絡開發了ASL 語言翻譯及標志系統,識別準確度率為92.3%。ADITHYA 等[6]通過使用卷積神經網絡(Convolutional Neural Network,CNN)[7]對ASL 數據集進行訓練預測,準確率達到94.7%。但在使用神經網絡訓練時,往往需要花費大量的時間在訓練模型上[8]。特別是近年來CNN的網絡層數不斷加深[9]和可訓練參數驟增,更凸顯了模型訓練時間過長的問題。因此,一些學者提出了將主成分分析(Principal Component Analysis,PCA)與神經網絡相結合的觀點。吳偉[10]提出PCA 與CNN 相結合識別ASL 圖片的方法,通過在CNN 前插入PCA 層進行特征降維,大幅提升了訓練速度,且識別率達到94.45%。鐘健等[11]提出一種PCA 與自組織神經網絡SOM 相結合的識別方法,使用SOM 作為分類器進行圖片分類,同樣顯著提高了識別速度,且識別率穩定在90%左右。上述方法使用的PCA 均在一維數據中使用,針對圖片等二維數據,學者們又發展了二維主成分分析(Two-Dimensional PCA,2DPCA)[12]和雙向二維主成分分析(Bidirectional 2DPCA,Bi-2DPCA)[13]方法。相比于一維的PCA,改進后的2DPCA 和Bi-2DPCA 對圖像的降維效果更好,提升速度的效果更明顯。
在基于神經網絡的各種模型中,超參數的選擇對模型的性能影響很大,不恰當的超參數或將直接影響模型的應用效果。近幾年在ImageNet比賽中獲得成功的GoogleNet、ResNet-52 和DenseNet 都需要對超參數進行精細地調整,這3 個模型分別有78、150、376 個超參數[14],若手動調參則會浪費非常多的時間。因此,在優化超參數時可使用粒子群優化(Particle Swarm Optimization,PSO)算法[15]、遺傳算法(Genetic Algorithm,GA)[16]、貝葉斯優化(Bayesian Optimization,BO)算法[17-19]等自動調參算法。
為提高ASL 圖片識別準確性同時加快模型訓練速度,本文提出基于Bi-2DPCA 與CNN 的美式手語識別算法。利用Bi-2DPCA 對原始圖片進行降維預處理,在此基礎上提取特征矩陣,并將降維后的數據輸入CNN 網絡進行模型訓練。同時,使用貝葉斯優化方法,通過設計超參數的選取及其范圍優化CNN的超參數。
1 相關知識
1.1 卷積神經網絡
卷積神經網絡(CNN)用于處理空間上有關聯的數據[20],其使用多個較小的卷積核(filter),有規律地掃描數據。CNN 的網絡連接是稀疏連接,卷積核使用的是共享參數,這極大地減少了網絡可訓練參數的數量,加快了網絡訓練速度。CNN 的基本結構由輸入層、卷積層、激活層、池化層、丟棄層(Dropout)、全連接層和輸出層構成。在卷積層后加入批歸一化層(Batch Normalization,BN)可以進一步增強網絡的性能和泛化能力[21-22]。
卷積層中有多個卷積核,對于前一網絡層傳入的圖像或特征圖,在其每一圖層都有一個卷積核進行掃描。卷積核計算公式為:

BN 層對一批數據進行標準化,使數據符合以0為均值、以1 為標準差的分布,計算公式為:


池化層向下采樣可增加感受野,緩解過擬合。目前,常用的池化方法有最大值池化和均值池化。
Dropout 層在訓練時舍棄一定比例的神經元,這使得網絡的訓練參數變少,增加了網絡的泛化能力,減少了某些神經元的依賴性。當網絡中存在BN 層時,Dropout 的比例可適當減少。
CNN 使用Adam 優化器對Softmax 的交叉熵函數進行優化。Adam 定義了一階動量mt和二階動量Vt,分別為當前t次迭代時梯度gt的一次函數與二次函數,β1與β2為超參數,設置為0.9 與0.999。一階和二階動量表達式分別如式(4)和式(5)所示:
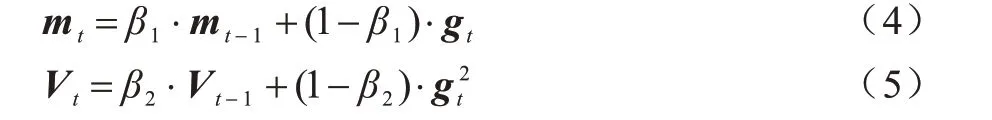
1.2 Bi-2DPCA 算法
PCA 算法核心思想是將樣本投影到一個超平面上,并使所有樣本的投影盡可能分開,即最大化投影點的方差。2DPCA 針對圖片等二維矩陣,不需要將圖片數據打平為一維數據,極大地減少了維度[12]。
利用2DPCA 算法對圖片Xi(m行n列)進行特征提取,其中投影基W(n行k列)的列寬遠小于圖片矩陣,由此可得到最后的投影矩陣為:

最后的投影矩陣Y為m行k列,實現了圖片在列維度的降維。其中,W矩陣為原數據中心化后的協方差矩陣前k個特征值組成的特征向量。協方差矩陣Gt表示為:
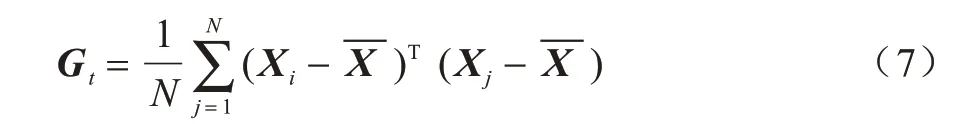
其中:N為樣本總數為樣本均值。計算Gt矩陣的特征值和特征向量,取前k個特征值組成的特征向量構成W矩陣,即可計算最后的投影矩陣Y。
由于2DPCA 只對列維度進行降維,整體維度仍比較大,因此出現了改進算法Bi-2DPCA,其將2DPCA 處理后的數據Y(m行k列)繼續投影到某組基C上,得到最終的投影矩陣U,表示為:

其中,C為由新樣本構造的協方差矩陣前j個特征值組成的特征向量。表示為:
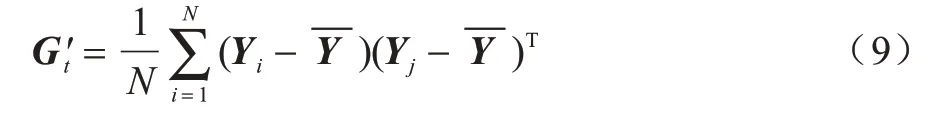
最后得到行變換C與列變換W,將行列變換合并。對于圖片Xi,降維后的特征矩陣A的維度為j行k列,其中j和k遠小于原始圖片的m和n,則行列變換矩陣公式為:

若對特征矩陣進行復原顯示,則可得到:

在Bi-2DPCA 算法中也存在2 個超參數,即列降維選取的k取值與行降維選取的j取值,其經驗選取為特征值貢獻率為0.9~0.99 的特征數[12]。
1.3 貝葉斯優化
貝葉斯優化(BO)算法基于順序模型,其目標函數不需要具有可導、連續等數學性質,并且如果是昂貴的黑盒函數,也可以在比較少的迭代次數內計算得到最佳的取值[17]。
在BO 算法中,最重要的2 個部分是概率代理模型和采集函數。概率代理模型用于替代評估代價高昂的目標函數,常用的代理模型有貝塔-伯努利(Beta-Bernoulli)模型、線性模型、高斯過程(Gaussian Processes,GP)模型等。GP模型具有較好的靈活性、可拓展性和可分析性,是BO 中應用最廣泛的概率代理模型。該模型由均值函數和協方差函數構成,如式(12)所示:

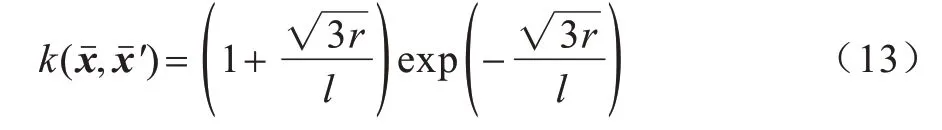
其中:r為l為尺度參數。
采集函數從搜索域X中選擇評估點,將其映射到實數空間α:X→R。該函數由已觀測數據集D1:t的后驗分布組成,通過最大化該函數尋找下一個評估點xt+1,如式(14)所示:

該過程基于提升的策略EI(Expected Improvement),采集函數為:
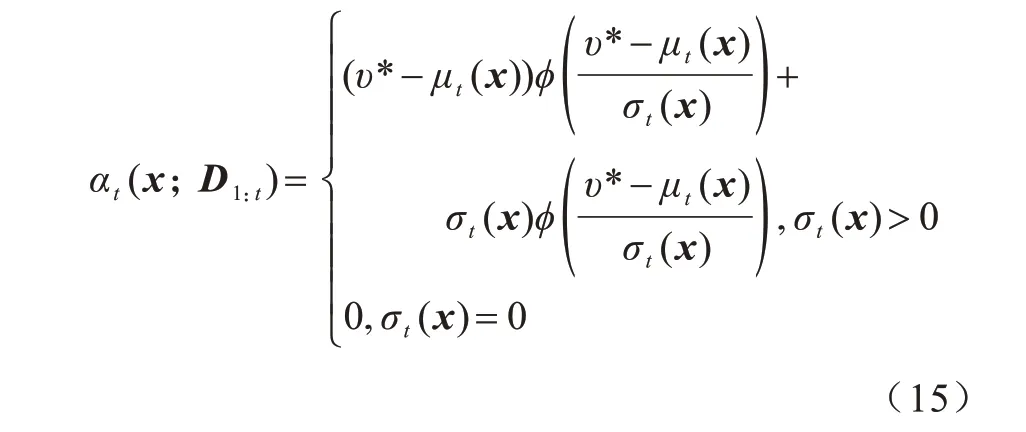
其中:υ*為當前最優函數值;φ(·)為標準正態分布密度函數;μt(x)為均值;σt(x)為標準差。
2 B2DPCA-CNN 算法
本文提出Bi-2DPCA-CNN 算法,算法流程如圖1所示。

圖1 Bi-2DPCA-CNN 算法流程Fig.1 Procedure of Bi-2DPCA-CNN algorithm
2.1 數據預處理
本文使用的ASL 數據集來源于Kaggle,為24 分類樣本,對應A~Z(除去J、Z)的24 個英文字母,每一類有3 000 張圖片,共72 000 張圖片。每個字母對應的照片集都在光照、姿勢、位置等方面有所不同,可以較好地模擬真實識別場景。圖2 展示了ASL 數據集部分圖片及其字母表示。

圖2 ASL 數據集部分圖片及其字母表示Fig.2 Some pictures of ASL dataset and their letter representations
圖2 中每張圖片的原始尺寸大小為200 像素×200 像素,在進行特征估計并排序后,前30 位特征柱狀圖如圖3 所示。可以看出,排名高的特征值遠大于其他特征值。
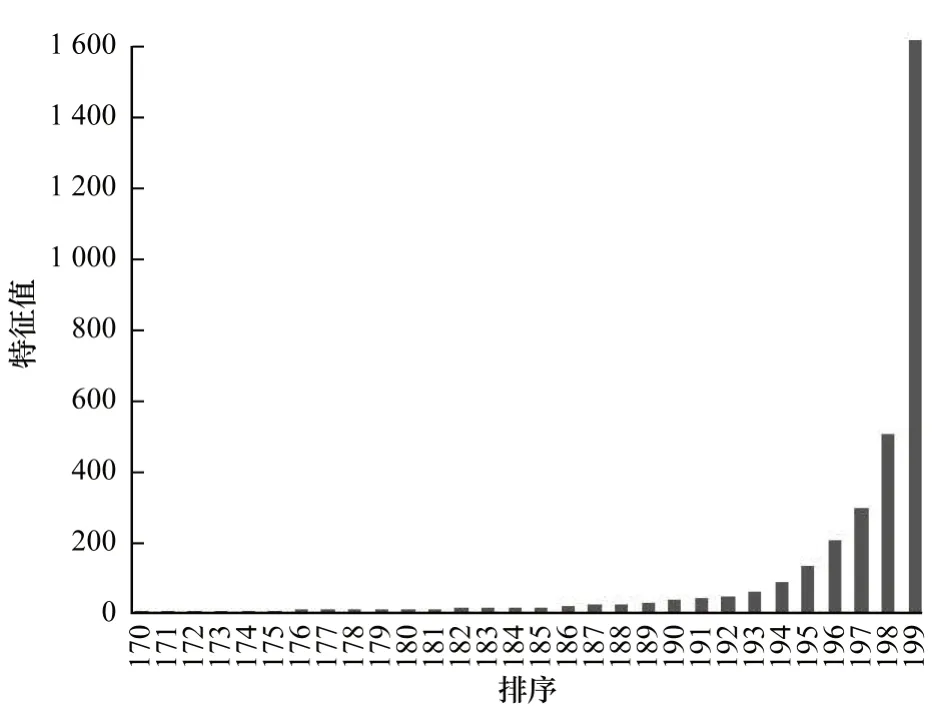
圖3 前30 個特征柱狀圖Fig.3 Top 30 feature histograms
若對圖像進行復原,則可以直觀地看出降維后的效果,圖4~圖6分別為原始灰度圖與降維到100、50、25維度復原圖像的對比圖。可以看出降維到25 的復原圖像仍然可以還原手勢的形狀,所以,Bi-2DPCA 降維參數選擇為25,即200 像素×200 像素的原圖降維成25 像素×25 像素的尺寸。

圖4 100 維度原圖與復原圖對比Fig.4 Comparison of 100-dimensional original image and restored image

圖5 50 維度原圖與復原圖對比Fig.5 Comparison of 50-dimensional original image and restored image

圖6 25 維度原圖與復原圖對比Fig.6 Comparison of 25-dimensional original image and restored image
2.2 CNN 網絡及參數設計
如圖7 所示,本文設計包含多個卷積層和池化層的卷積神經網絡。加入BN 層進行數據批標準化,并在Dropout 層進行丟棄處理,避免過擬合,最后接入全連接層和Softmax 分類器進行分類。
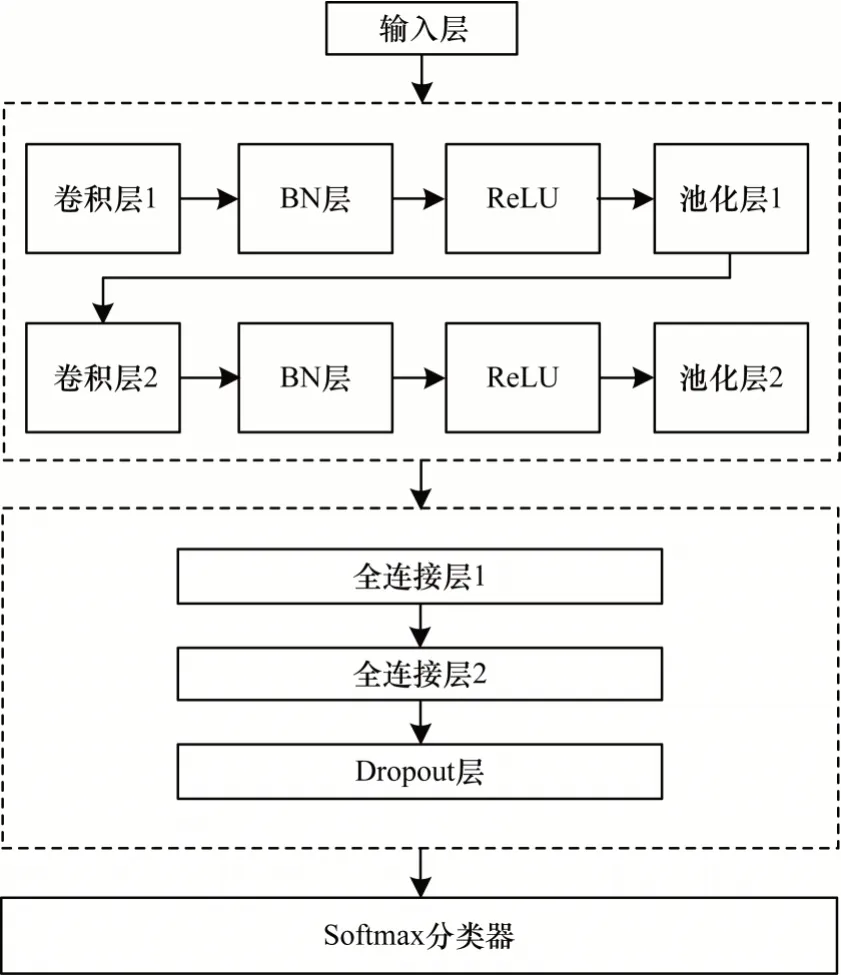
圖7 包含多個卷積層和池化層的CNN 結構Fig.7 Structure of CNN with multiple convolution layers and pooling layers
卷積層、池化層和Dropout 層參數項如下,參數范圍如表1 所示。

表1 參數范圍Table 1 Range of parameters
1)卷積層1:卷積核的大小為dim1,數量為num_conv1。
2)池化層1 :池化大小為pool。
3)卷積層2:卷積核的大小為dim2,數量為num_conv2。
4)池化層2:池化大小為pool。
5)Dropout 層:丟棄率為drop。
6)學習率:設置為優化參數lr。
3 實驗與結果分析
3.1 實驗設置與評價指標
本文實驗使用Windows10 系統,編程語言為Python,實驗平臺使用TensorFlow2.1 版本,采用GPU加速,處理器為Inter i7-8750H 處理器,顯卡為NVIDIA GTX1060,6 GB 顯存。實驗使用的樣本為72 000 張圖片,其中60 000張作為訓練集,12 000張作為測試集集,模型迭代50 次,保存模型每次迭代的準確率與損失。評價指標選取準確率、訓練時間、測試時間和F1 值。
3.2 Bi-2DPCA 優化驗證
分別使用以下模型對ASL 數據集識別并進行實驗分析,驗證Bi-2DPCA 對CNN 整體性能的提升:1)文獻[10]中的PCA-CNN 模型(下文簡稱a-CNN模型);2)文獻[6]中的CNN 模型(下文簡稱b-CNN無改進模型);3)文獻[6]中加入Bi-2DPCA 的CNN模型(下文簡稱b-CNN-2DPCA 模型);4)本文設計的CNN 網絡無改進模型(下文簡稱CNN 無改進模型);5)本文設計的Bi-2DPCA-CNN 模型。
5 種模型的實驗評價指標如表2 所示。可以看出:a-CNN 模型雖然使用PCA 算法,但未使用Bi-2DPCA,仍需要花費大量時間將圖片變為一維向量進行樣本矩陣的降維,且計算的協方差矩陣維度較大,無法準確地進行特征向量估計,影響了準確率與F1 值,其準確率和F1 值分別為95.82%、95.67%,測試時間為158 s;b-CNN-2DPCA 模型使用3 輪卷積池化結構,由于存在較多的可訓練參數,訓練時間較長,在進行Bi-2DPCA改進后,準確率為98.32%,提升了0.28%,F1值為98.17%,提升了0.54%,訓練時間縮減了91.5%,測試時間從244 s減少到96 s;本文提出的Bi-2DPCA-CNN 模型相比于CNN無改進模型,準確率為98.28%,降低了0.03%,F1值為98.26%,提升了0.02%,訓練時間從3 707.3 s 縮短到358.2 s,縮減了90.3%,測試時間從232 s 減少到90 s,縮減了61.2%。圖8 為Bi-2DPCA-CNN 模型的準確率與損失曲線。
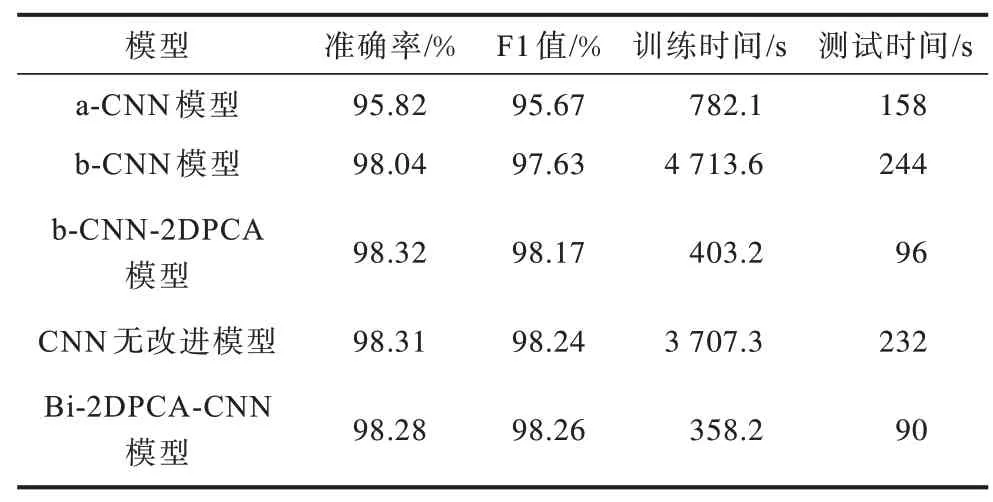
表2 不同模型的評價指標Table 2 Evaluation indicators of different methods
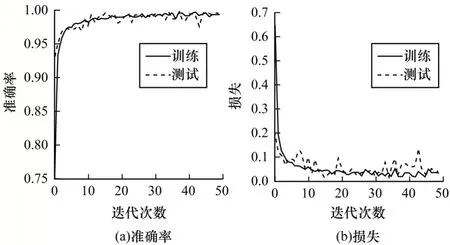
圖8 Bi-2DPCA-CNN 模型的準確率與損失曲線Fig.8 Accuracy and loss cruves of Bi-2DPCA-CNN model
3.3 貝葉斯優化驗證
在Bi-2DPCA-CNN 的基礎上繼續使用貝葉斯算法優化網絡存在的超參數。在上文2.2 節中,設計了7 組變量并分別設定了范圍,本文使用貝葉斯優化算法,將7 組變量作為算法的輸入、將Bi-2DPCA-CNN的準確率作為輸出進行自動調參迭代。在進行5 次初始化尋優和10 次自動尋優后,得出模型最優參數。貝葉斯優化后的模型最優參數如表3 所示。

表3 Bi-2DPCA-CNN 模型最優參數Table 3 Optimal parameters of Bi-2DPCA-CNN model
使用貝葉斯優化后的最優模型與未使用貝葉斯優化的模型評價指標如表4 所示。可以看出:經過貝葉斯優化后的模型性能更好,準確率為99.15%,提升了0.87%,F1 值為99.02%,提升了0.76%;對比文獻[6]未經貝葉斯優化的模型,準確率提升了1.11%,F1 值提升了1.39%。
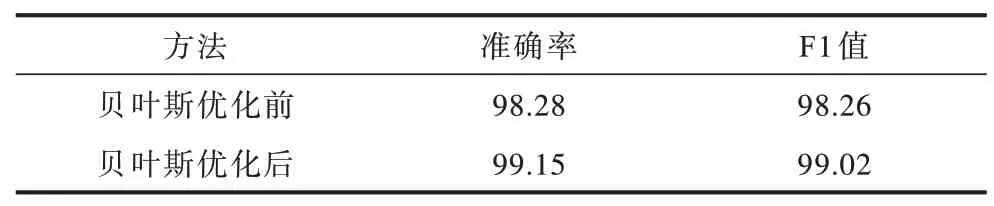
表4 貝葉斯優化前后Bi-2DPCA-CNN 性能對比Table 4 Performance comparison of Bi-2DPCA-CNN before and after Bayesian optimization %
圖9 為貝葉斯優化后Bi-2DPCA-CNN 模型的準確率與損失曲線。可以看出:該模型使用Bi-2DPCA 算法對數據進行預處理,在保留原圖特征的同時降低了尺寸大小,顯著減少了運行時間。在使用貝葉斯優化后,準確率與F1 值都有所提升。同時,2D2DPCA 算法與其他模型結合也有較好的結果,能夠有效減少訓練時間。

圖9 貝葉斯優化后Bi-2DPCA-CNN 的準確率與損失曲線Fig.9 Accuracy and loss cruves of Bi-2DPCA-CNN after Bayesian optimization
4 結束語
針對現有算法識別ASL 數據集訓練模型速度慢和識別準確率低的問題,本文提出Bi-2DPCA-CNN算法。在圖片預處理階段使用Bi-2DPCA 算法對原始圖片特征提取降維,保留原圖重要特征并減小圖片尺寸。在此基礎上,設計多層卷積、池化結構的卷積神經網絡進行特征圖的識別分類,并加入批歸一化層與丟棄層防止過擬合。同時,使用貝葉斯優化方法對卷積神經網絡中的超參數進行優化,以實現模型的最優化。在對24 分類ASL 圖片進行識別時,該算法在準確率、訓練時間、F1 值方面較文獻[6,10]方法均具有優勢,驗證了算法的有效性,并且2DPCA 算法得到了特征值矩陣,對不同識別任務可獲得基于當前數據集的特征值,在其他圖像識別問題上也有可拓展性。本文工作僅針對ASL 數據集英文靜態字母,并未對動態字母及其他手語動作進行識別,下一步研究將聚焦于動態手勢識別,包括單張圖片出現多個動態手勢的復雜情況,以及手勢遮擋等問題。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
