基于機器學習的場外配資識別算法設計與應用
2021-12-23 12:24:44俞建群李雙宏
微型電腦應用 2021年12期
關鍵詞:特征
俞建群, 李雙宏
(東方證券股份有限公司,上海 200010)
0 引言
場外配資是指場外證券資產融資業務,其本質是一種資金借貸關系。作為一種融資手段,場外配資存在諸多風險[1]。中國證券業協會頒布的《場外證券業務備案管理辦法》中指出場外配資活動應當進行備案,最高人民法院發布《全國法院民商事審判工作會議紀要》明確場外配資合同無效,說明該業務存在違反法律與政策的風險;在場外配資過程中,股票賬戶由配資方監控,存在違約和操作風險;場外配資系統的自動平倉功能及較高的杠桿率,易引發市場下行時的系統性風險;由于配資賬戶所持股票通常波動率和周轉率較大,在加強股票流動性的同時也增大了極端事件惡化的概率,加劇股票市場的異常波動。
對此,監管部門已多次發聲表明,密切關注資本市場場外配資情況,嚴厲打擊違法違規的場外配資行為。對場外配資進行監管監控,從微觀的資本市場參與者角度來說,有利于促進投資者防范相應的投資風險,避免投資者受到非法配資公司非法經營或詐騙行為的損害;從宏觀角度來說,有利于避免場外配資業務通過盲目擴張資本市場信用交易規模,沖擊資本市場交易秩序,從而維護證券市場的穩定。
目前對于場外配資賬戶的識別與篩查,不同的監管部門均有一定的判別標準和認定規則,這些標準主要是來源于工作經驗[2]。通過對證監會向四家證券公司和三家技術支持公司作出的監管函進行梳理,可以歸納出目前場外配資的主要監管依據有軟件提供商非法經營證券業務規定、證券公司違反賬戶實名制規定和交易軟件不符合期貨公司審慎經營和風險管理要求[3]。
此外,傳統的場外配資識別系統大多采用規則驅動的方法,根據設定的規則特征進行篩選,比如賬戶總資產規模、賬戶成交量、交易頻次等,規則的制定較為主觀,需要不斷進行規則的調整或增加。而隨著政策性或市場環境的變化,之前的監管規則可能失效,出現誤報或漏報,并且賬戶的行為模式也在不斷發生變化,被動地制定規則存在滯后性與局限性,無法動態靈活地根據行情變化及實際交易行為進行及時的場外配資監控。
針對場外配資監控系統現狀,本文創新性地采用人工智能的手段,通過機器學習算法進行市場交易行為分析,從而準確靈活地識別出賬戶是否為配資賬戶。本文提出了基于改進的XGBoost場外配資監控算法,并結合場外配資識別的業務需求,在現有的規則篩選方法基礎上,設計合理的業務特征,通過特征工程及重要性分析構建特征指標體系。根據場外配資行為特性對XGBoost模型進行改進,更好地用于配資賬戶的識別。在效果評價方面,結合實際賬戶分布及識別需求,選取召回率作為關鍵評價指標。實驗結果顯示,本文所提出的場外配資監控算法得到了更高的準確率,具有更優的識別效果,并且通過市場交易行為分析能夠更加靈活快速地適應市場環境變化,從而更好地用于證券市場的場外配資監控。
1 基于改進的XGBoost的場外配資監控
1.1 場外配資流程
場外配資是一種金融融資手段,逐漸形成了較明確的業務流程。首先,用戶向配資公司繳納服務費、手續費等,并繳納賬戶初始資金(保證金)。其次,配資公司提供無限制配資、按月配資、按周配資、按天配資等業務,用戶選擇配資模式和配資比例后,配資公司向用戶提供合同規定賬戶金額的賬戶,之后用戶即可進行買入或賣出操作。為了確保出借資金的安全,配資公司實時監控客戶賬戶資金情況,設置平倉線和預警線。每日清算階段,配資公司會判斷用戶的賬戶資金是否達到相應的臨界線。如果未觸及臨界線,用戶可正常交易;若低于補充保證金臨界線,則提醒用戶補充保證金;若低于強制平倉臨界線,用戶需補充保證金才可進行后續操作,若不補充,則配資公司會對賬戶強制平倉,平倉后進行保證金結算,用戶退出配資系統。具體配資流程圖如圖1所示。
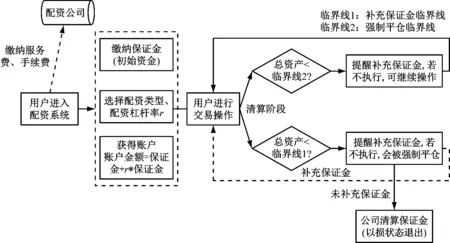
圖1 配資流程圖
例如,某用戶初始資金為100萬元,按照5倍杠桿進行配資,則可操作資金為600萬元。按照合同規定,警戒線(補充保證金臨界線)為杠桿操盤資金+本金×50%,即550×(500+100×50%),平倉線為杠桿操盤資金+本金×30%,即530×(500+100×30%)。某天清算后,用戶總資產為525萬元,則用戶至少補充5萬元的保證金才可進行第二日的交易操作。若不補充保證金,則公司進行強制平倉后用戶實得金額約為25萬元,虧損約75萬元。
在深入了解場外配資賬戶交易行為的基礎上,我們構建了與場外配資識別強相關的特征指標體系,并以市場交易行為分析為基礎進行場外配資監控算法設計。
1.2 場外配資監控算法流程
場外配資監控系統的流程如圖2所示。
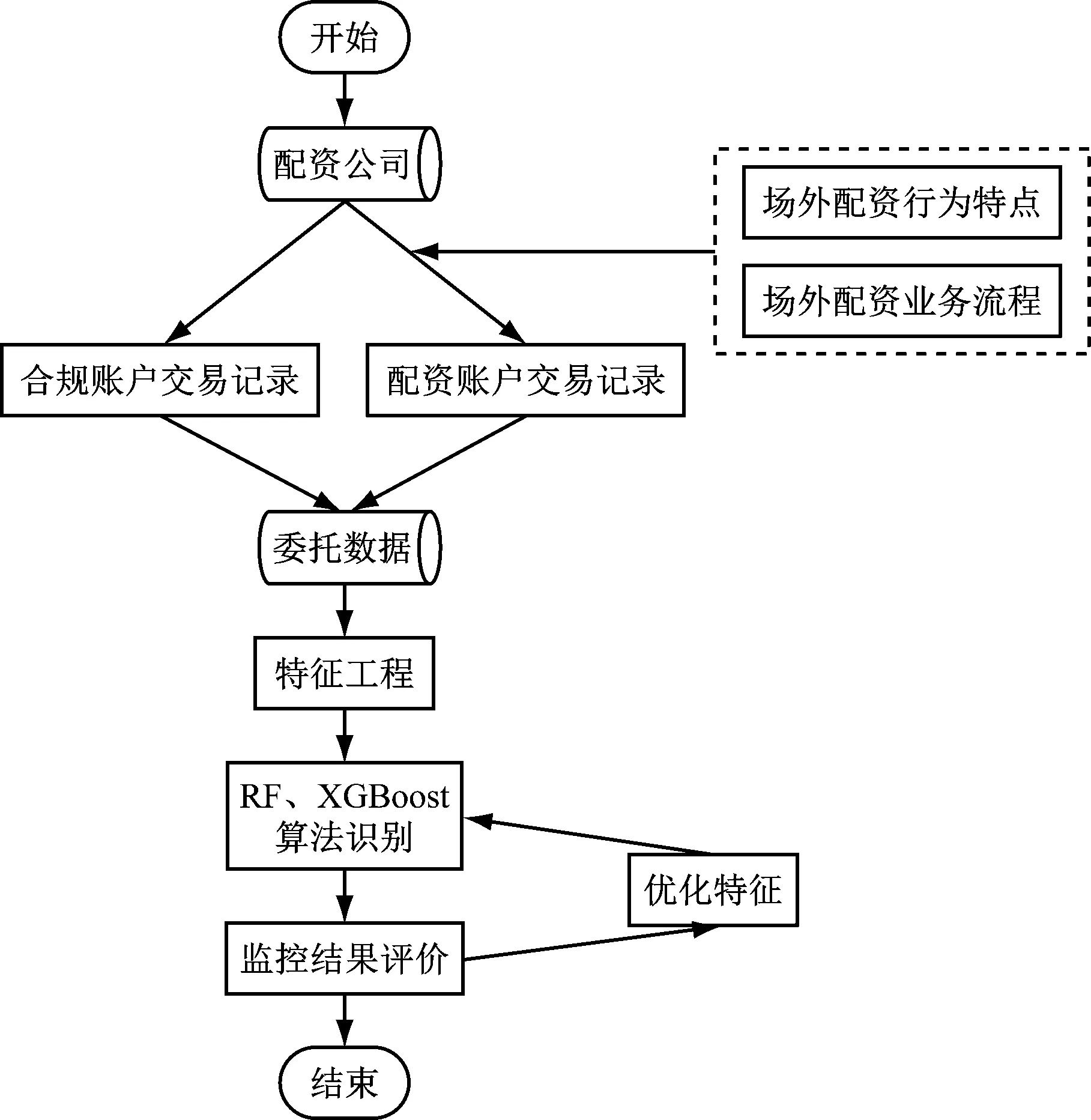
圖2 場外配資賬戶識別流程
首先,結合實際場外配資背景,使用歷史行情數據生成配資和合規交易數據,導入委托交易數據庫。隨后,進行特征設計,抽取出具有場外配資行為特性的特征。最后,設計機器學習模型進行訓練預測,本文選取了兩種集成算法,隨機森林和XGBoost,相對于單一的弱學習器,集成算法的學習器更精確,魯棒性更好,并且結合業務實際,從3個角度對XGBoost模型進行了改進優化。
由于賬戶交易數據涉及客戶隱私,在數據獲取途徑上,采用了數據生成的方法,即根據歷史行情數據并結合場外配資交易的行為特征,構建了賬戶生成算法模型,生成相應的交易數據。
1.3 配資賬戶的實現和交易數據的生成
根據配資流程,定義配資賬戶類,并按照不同的交易策略生成配資賬戶的交易數據。配資賬戶類的說明如表1所示。

表1 配資賬戶類屬性和方法
生成交易數據的偽代碼如表2所示。數據具有隨機性。

表2 交易數據生成偽代碼
通過不斷重復上述操作,最終得到的交易數據集中共有188個正常賬戶,56個配資賬戶,共158 370條交易記錄。配資賬戶占比小的原因是在真實情況中,配資賬戶占比較小,這樣設置類別比例更符合實際。
1.4 特征工程
針對數據庫中的交易操作記錄,首先進行交易數據的特征工程。結合場外配資的業務特點,抽取了交易頻率、總成交量等9個特征,具體說明如表3所示。
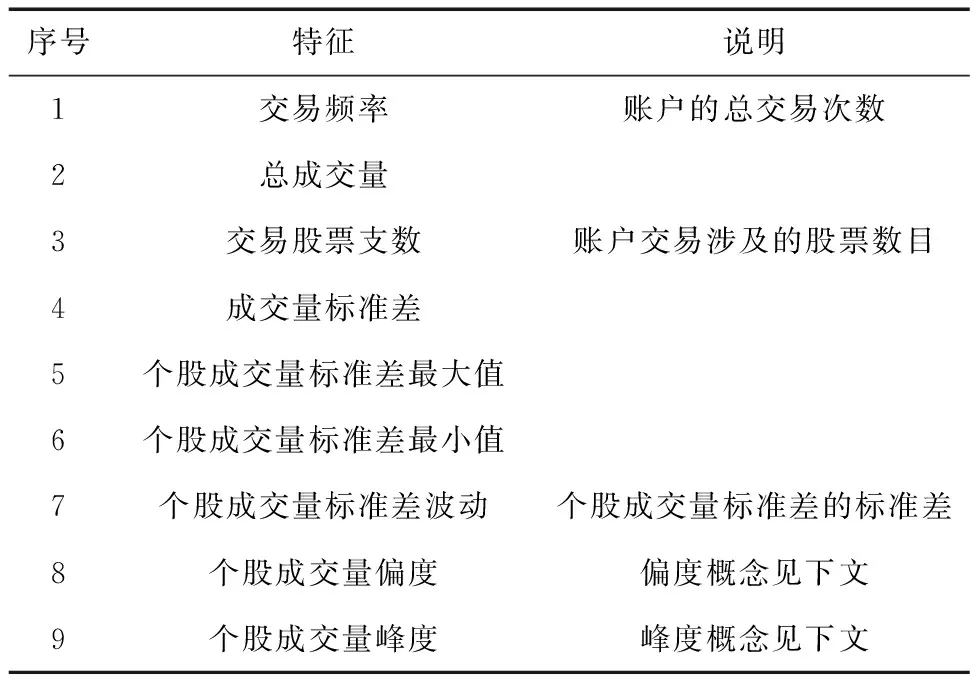
表3 特征設計
偏度(skewness)是統計數據分布偏斜方向和程度的度量,是統計數據分布非對稱程度的數字特征。其表征概率分布密度曲線相對于平均值不對稱程度的特征數。直觀看來就是密度函數曲線尾部的相對長度。偏度是樣本的三階標準化矩,其計算式為式(1)。
(1)
其中,k2、k3分別表示二階和三階中心距。在一般情形下,當統計數據為右偏分布時,Skew>0,且Skew值越大,右偏程度越高;當統計數據為左偏分布時,Skew<0,且Skew值越小,左偏程度越高。當統計數據為對稱分布時,顯然有Skew=0。
峰度(kurtosis)表征概率密度分布曲線在平均值處峰值高低的特征數。直觀看來,峰度反映了峰部的尖度。如果峰度大于3,峰的形狀比較尖,比正態分布峰要陡峭。反之亦然。峰度的計算式為式(2)。
(2)
其中,μ4表示四階中心距,減3是為了方便和正態分布進行對比。在實際計算中,常用的是樣本峰度的計算式,其表達式為式(3)。
(3)
1.5 交易賬戶類型識別
1.5.1 基于隨機森林的特征重要性分析
隨機森林(Random Forest,RF)[4],指的是利用多棵樹對樣本進行訓練并預測的一種分類器。該分類器最早由Leo Breiman和Adele Cutler提出,由多棵CART(Classification And Regression Tree)構成,每棵樹所使用的訓練集是從總的訓練集中有放回采樣出來的,這意味著,總訓練集中的部分樣本可能多次出現在一棵樹的訓練集中,也可能從未出現在任意樹的訓練集中。在訓練每棵樹的節點時,使用的特征是從所有特征中按照一定比例隨機地無放回抽取的。
經特征工程處理后的交易記錄數據集,共有9個特征和1個類別。這里采用隨機森林進行了特征重要性分析,進一步優化特征指標體系,并驗證了所構建特征對于場外配資賬戶識別的效果。接下來,基于隨機森林分類器進行了建模識別。由于樣本存在比例不協調的問題,因此對模型的相關參數進行了設定,使模型能夠更好地處理實際情況下的樣本分布不平衡問題。
1.5.2 基于改進的XGBoost的場外配資監控算法
考慮到隨機森林弱化預測偏差的局限性,本文進一步使用了XGBoost算法對配資賬戶進行識別。XGBoost是經過優化的分布式梯度提升庫,優點在于在高效、靈活且可移植[5]。它是在Gradient Boosting框架下實現的一類集成樹的機器學習算法。XGBoost基于并行樹增強(GBDT,Gradient Boosting Decision Tree)的算法邏輯,可以快速準確地解決許多數據科學問題。與隨機森林相比,XGBoost是一種提升算法,不僅學習效果較好,而且速度也很快,并且相較于隨機森林更加關注分類錯誤的樣本。
在算法效果分析評估過程中,結合場外配資行為特性,除準確性指標外,本文采用召回率(Recall)作為關鍵度量指標。召回率的實際意義為真實的配資賬戶最終被算法正確識別出來的比例,在實際業務場景中,往往更希望盡可能全面地識別出配資賬戶,保證不遺漏,因此使用召回率更符合實際場外配資監控場景。
為了提高識別的召回率,本文對所使用的XGBoost算法進行了以下改進。
1)加入新特征
在原有特征的基礎上,新加入了總交易金額。其結果為每個賬戶的每條交易信息中價格與交易量乘積的求和。對于某個賬戶,設Pi為其第i條交易記錄中的交易價格;Vi為其第i條交易記錄中的交易量,則總交易金額TOTAL_ACCOUNT定義為式(4)。
(4)
2)對部分原特征對數變換
由于某些特征的分布圖中呈現三峰或多峰現象,本問題為二分類問題,最理想的狀況為雙峰分布,因此對于部分特征進行了對數特征變換。
3)自定義測評函數
在XGBoost模型中,自定義測評函數。由于本問題更關注召回率這一指標,因此將測評函數定義為1-召回率,即若測評函數越小,說明召回率越高,越符合實際要求。
2 實驗結果分析
2.1 特征重要性分析
采用隨機森林模型進行特征重要性分析與初步識別算法構建。考慮到樣本存在比例不協調的問題,因此對模型的相關參數進行了設定。模型參數如下:n_estimators=200,max_depth=5,verbose=True,class_weight={"SMF":56,"NORMAL":188}。
特征重要度占比和排序如圖3所示。
從圖3可以看出,交易頻率(TRA_FRE)重要性最高,其次是交易總量(TRA_VOL),個股交易量偏度(VOL_SKEW)等。結合特征重要度的實際意義,上述的特征排名能夠較好地反映出場外配資行為的特點。交易頻率反映出場外配資賬戶交易頻繁的特點;交易總量特征說明與正常賬戶相比,交易總量存在顯著性差異;個股交易偏度則說明場外配資賬戶的歷史交易主體交易量變動范圍大,交易行為具有不一致性的特點。
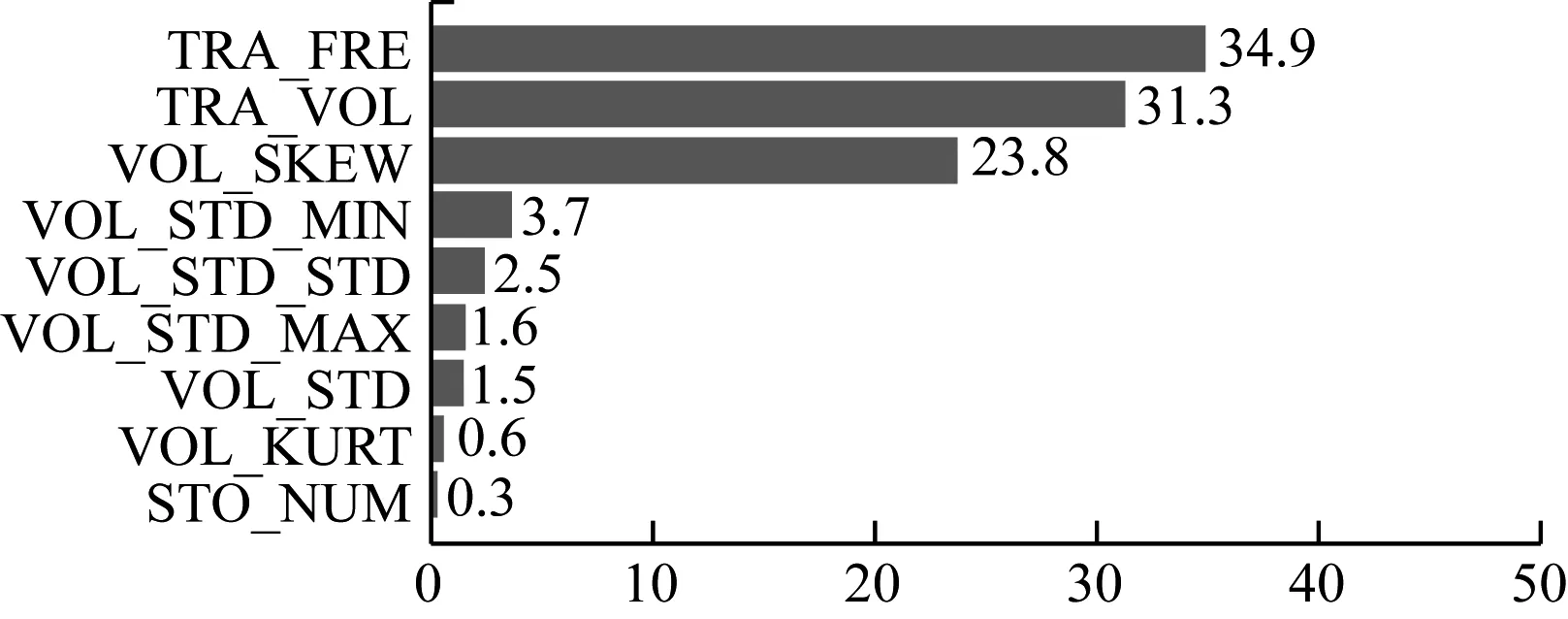
圖3 特征重要度占比排序
2.2 場外配資賬戶識別
將數據集按比例劃分為測試集和訓練集。在測試集中,正常用戶(NORMAL)和配資賬戶(SMF)的比例為4:1以上,目的盡可能反映配資賬戶與合規賬戶分布不均衡的實際情況,同時保證實驗驗證結果的可靠性。
首先,采用基于隨機森林的場外配資識別模型進行訓練和預測。通過調整訓練集中樣本比例,繪制出不同的訓練集、測試集所對應的預測準確性和召回率結果,如圖4所示。
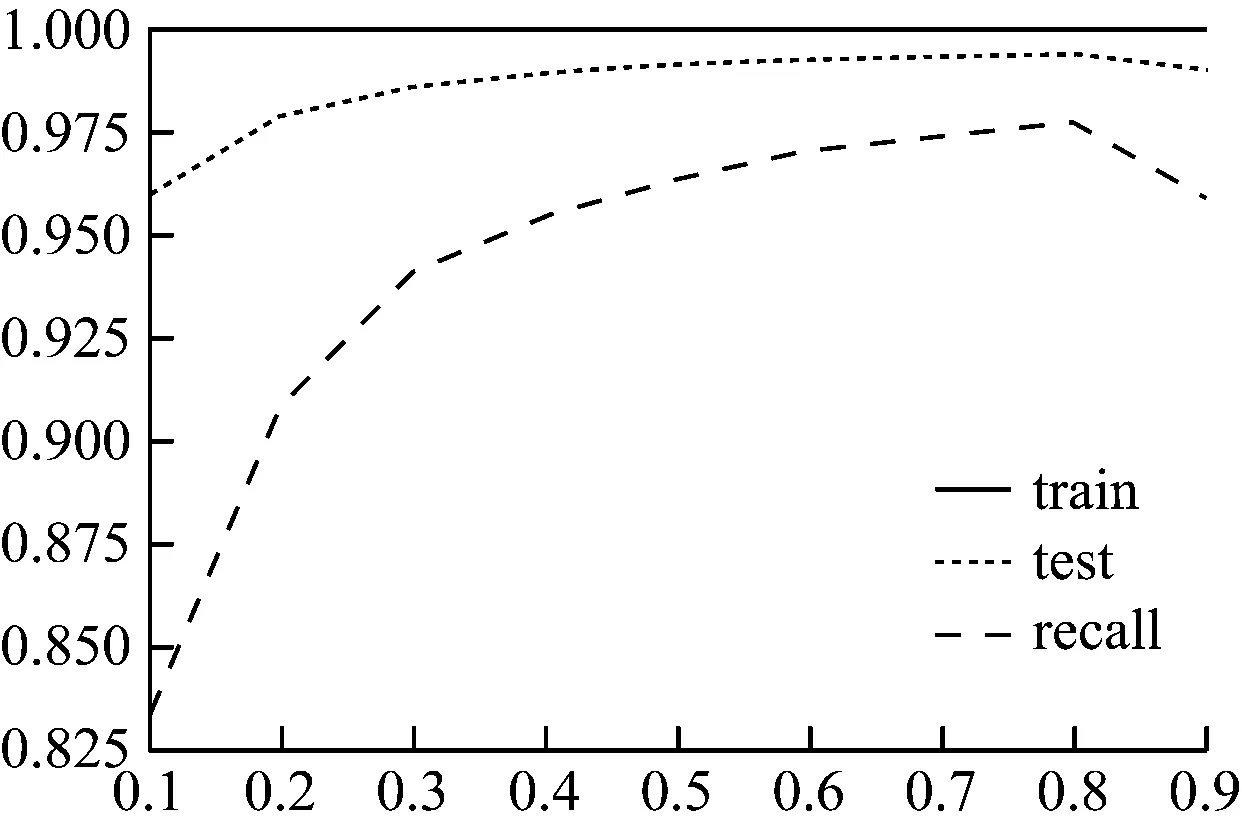
圖4 不同比例的測試集指標圖
由圖4可以看出,最終經過訓練所得到的模型在測試集上的準確性達到95%以上,召回率為96%。對比預測結果和真實值,發現預測錯誤的賬戶數為1,且為配資賬戶。召回率Recall=27/28=96%。召回率是評價模型較好的指標,因為它代表了模型從真實的配資樣本中識別出配資賬戶的比例。當測試集比例為0.8時,模型識別效果最好。
本文進一步使用改進的XGBoost算法對配資賬戶進行識別,并選取了Binary:logistic作為算法的目標函數。詳細的參數設置如表4所示。
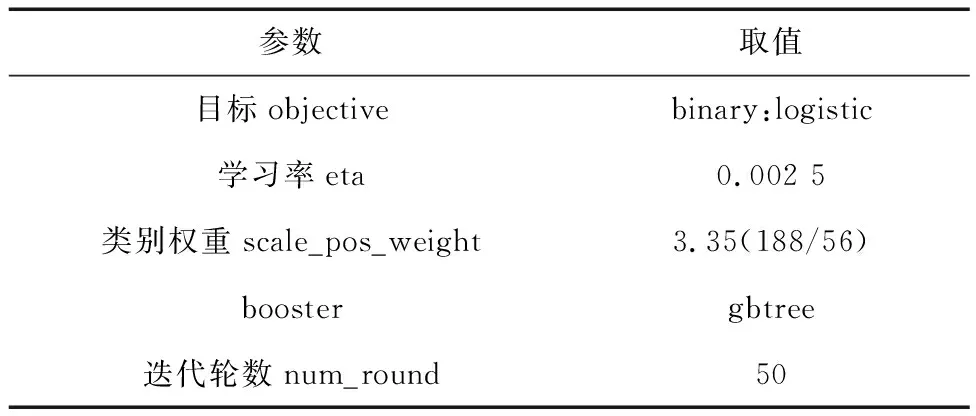
表4 Binnary:logistic關鍵參數
將XGBoost與隨機森林的預測結果匯總,在不同的測試集樣本比例下,預測召回率如圖5所示。
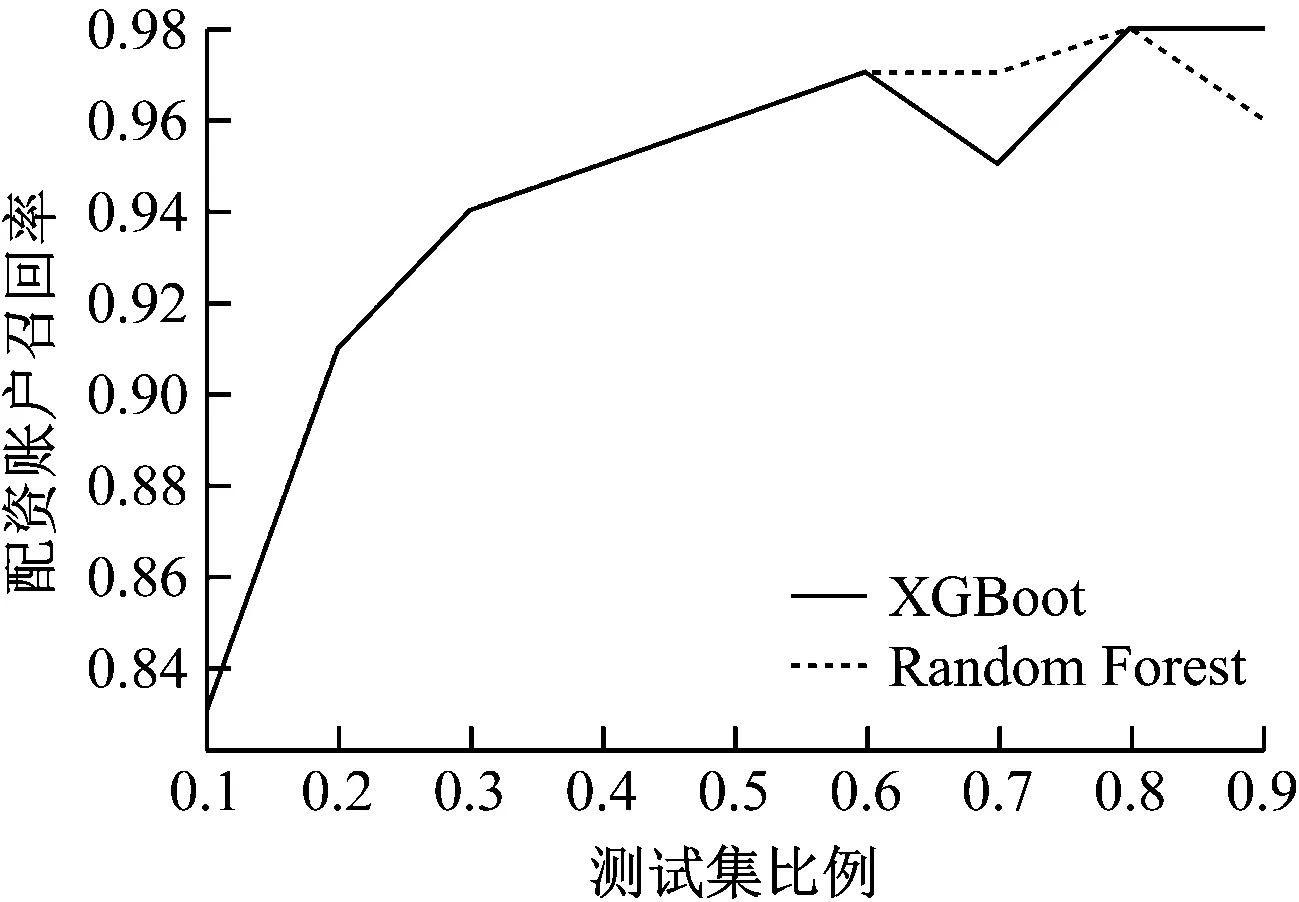
圖5 數據折線圖
從圖5可以看出,在測試集中樣本分布比例達到90%時,改進的XGBoost算法相比隨機森林能夠得到更高的召回率,召回率達98%。在小樣本訓練集上,XGBoost的識別效率較高,說明本文改進的算法具有魯棒性。在實際業務中,配資賬戶在總賬戶中的比例非常小,改進的XGBoost算法能夠更好地適應實際的賬戶數據分布情況,因此改進的XGBoost更加適用于真實的場外配資監控場景。
3 總結
場外配資是一種高風險的金融融資行為,其監管是否有效關系到證券市場的穩定和發展。本文創新性地提出了基于改進的XGBoost的場外配資監控算法。對于場外配資賬戶的識別,首先對不同賬戶的歷史交易信息通過特征工程進行了特征指標體系構建,構建了10個關鍵特征。針對新特征,首先使用了隨機森林算法進行特征重要性分析與解釋驗證,并初步進行識別建模預測,結果顯示,該模型下的查全率(Recall)平均達到90%以上。然后,使用了XGBoost這一更加關注分類錯誤樣本的梯度提升集成樹算法,并結合實際數據特征,對測評函數、特征等進行了改進,進一步提升算法效果。最后,將改進的XGBoost與隨機森林模型進行了實驗分析比較,結果顯示,改進后的XGBoost算法相對于隨機森林,其在評價指標上表現更優,說明對場外配資的監控效果表現優異。本文通過機器學習算法對場外配資賬戶進行識別,構建場外配資監控系統,能夠有效落實監管要求,清查場外配資,有助于維持股市的健康有序發展,引領正確的價值投資理念。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化(高中版.高考數學)(2022年3期)2022-04-26 14:04:16
數學年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學學報(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數學(2019年8期)2019-11-25 01:38:14
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
