基于支持向量機的煤矸識別研究
2021-12-24 02:12:14荊瑞俊
山西電子技術 2021年6期
李 黎,熊 英,荊瑞俊
(1.湖北工業大學,湖北 武漢 430068;2.山西農業大學,山西 晉中 030801)
0 引言
每年地下開的煤層產量占煤炭總產量的45%左右,綜采工作面在回采過程中,由于斷層或煤層厚度變化等出現矸石,是影響采煤質量重要因素[1]。頂煤放落時,依靠工人的耳聽、眼觀等方式來判斷,并以此聲音來確定是否放完頂煤。
放煤過程存在粉塵大、光線弱、空間狹窄等現象,難以準確地確定放煤狀態;環境條件的惡劣,會嚴重損害工組人員的身心健康。煤矸石的自動識別技術成為智能化采煤亟待解決的問題。
范振[2]等人考慮到采煤環境對煤與矸石表面的影響,對采集的樣本進行了細分,研究分析其圖片的灰度特征、紋理特征等信息差異性,采用支持向量機算法對樣本進行學習,構建其分類模型。薛光輝[3]等人以采煤口的煤矸石的圖像為樣本,采用裁剪、灰度變換、增強對比度等方法對原圖像進行預處理,用灰度共生矩陣表示樣本的15個紋理特征,采用隨機森林算法對煤矸石的紋理特征進行重要度排序,分析降維前后模型對煤矸石的識別效果。楊晨光[5]對不同類的煤的密度和灰分的關系進行研究分析,得出基于厚度和密度的灰度改變,采用R值法對煤矸與煤的差異識別。
上述研究主要從煤物理特性及表面圖片等對矸石進行識別,由于采煤現場的環境較為惡劣,圖像采集較為困難,通過射線技術雖能準確識別,但技術難度較大。鑒于此,本系統研究綜采面放頂煤過程煤與矸石落到支架上聲音的差異進行識別。
1 系統整體框架
本系統主要是通過放煤與放矸的聲音的不同來識別采出來的是煤還是矸,有助于后期的處理。系統的實現過程主要包含音頻信號的采集、音頻信號特征的提取、C-SVM模型構建及識別等。
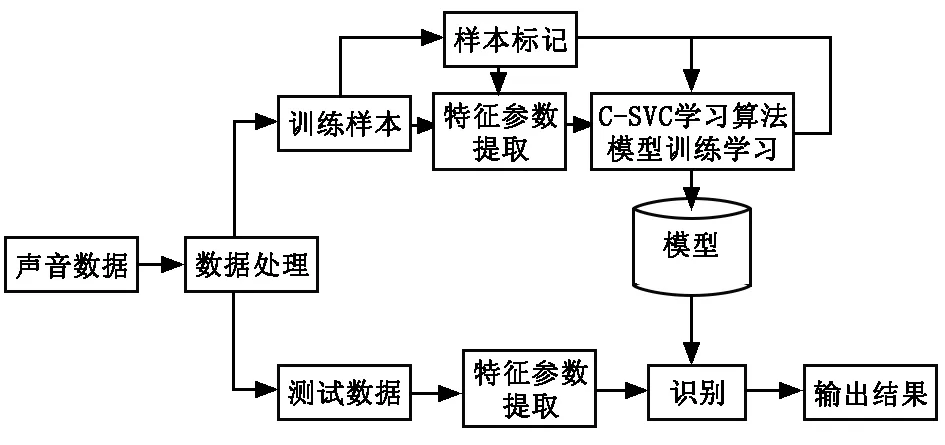
圖1 系統的整體框架
2 音頻特征提取
將原始信息的特征作為識別模型輸入。常用的特征提取算法分時域和頻域兩個方面,如時域的過零率、短時能量、自相關函數[6];頻域特征提取算法包括離散傅里葉變換、快速傅里葉變換、小波變換等。目前常用的特征提取算法采用的是梅爾倒譜系數,MFCC就是在梅爾刻度頻率上提取出來的梅爾倒譜參數。
MFCC算法實現的過程如圖2所示。預處理一般是加窗等操作、快速傅里葉變換、取模平方、Mel濾波器、對數變換、離散余弦變換等步驟。
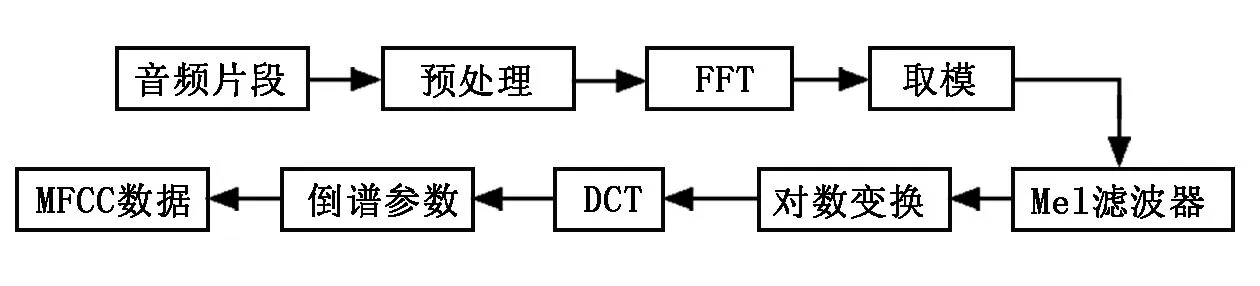
圖2 MFCC實現流程圖
對數梅爾譜圖(LogMel)更多是希望符合聲音信號的本質,擬合人耳的接收特性。
DCT是線性變換,會丟失語音信號中原本的一些高度非線性成分。當深度學習方法出來之后,由于神經網絡對高度相關的信息不敏感,MFCC不是最優選擇,經過實際驗證,其在神經網絡中的表現也明顯不如對數梅爾譜圖(LogMel)。
圖3 聲音的Fbank圖譜
系統選擇對數梅爾譜圖(LogMel)作為識別模型的輸入特征。一段放煤聲音MFCC參數與LogMel圖譜的信息量的對比圖如圖4,圖5所示。

圖4 MFCC的圖譜 圖5 LogMel特征圖譜
LogMel特征提取過程與MFCC的提取過程類似,只是把后面提取離散余弦變換(DCT)的步驟,轉而添加了取模、取對數等操作。
為了方便網絡運算,提取LogMel特征參數后,對其進行歸一化處理,從而得到機器學習的特征輸入。提取LogMel時分幀數選擇20 ms重疊一半,加漢明窗并使用64個分量的梅爾濾波器。經過歸一化后的LogMel譜圖分布相對均勻,使特征參數更加明顯,更有利于區分不同聲音事件。
3 SVM分類器
SVM(Support Vector Machines)是統計學理論分類算法。該算法實現樣本特征在模型復雜性與學習能力間尋求平衡點。在解決小樣本、非線性及高維等方面的效果比較明顯。
對于樣本S存在最優的分類面w·φ(x)+b=0。使用非線性函數將原來的參數空間變換到高維空間,進而建立上述超平面,w表示平面法向量,b表示截距設分離平面函數:
w·φ(x)+b=0
(1)
判別函數h(x)=w·φ(x)+b,將h(x)做歸一化處理后,使樣本滿足h(x)?1,運算轉化可得到化簡后的式子D=2/w,所以,使分類間隔最大就是相當于使w最小即可。
滿足上述條件,使分類模型對所有的樣本都有正確的效果需要滿足下式的條件。
yi(w·φ(xi)+b)-1?0i=1,2…n.
(2)
對每一個不等式約束引進拉格朗日乘子(Lagrange multiplier)αi≥0,i=1,2,…,Nαi≥0,i=1,2,…,N;構造拉格朗日函數:

(3)
將w與b消除,原始的約束最優化問題可等價于極大極小的對偶問題
(4)
而線性不可分時,需要向高維空間轉化,使其變得線性可分。此時需要松弛變量法來解決此類問題,對每個樣本引入一個松弛變量δ≥0,這樣約束條件變為:
yi(wTφ(xi)+b)≥1-δi
(5)
目標函數則變:
(6)
其中,C為懲罰因子,C越大,分錯點越少,但也不能太大,以免產生過度離合。為避免維度災難,則需要引入核函數,核函數是低維空間向高維空間映射。
4 實驗與總結
放煤放矸等數據集的構建。SONY錄音筆PCM-A10 16 GB(支持LPCM,采樣率44.1 k、96.1 kHz,分別為16位和24位;本系統采用的44.1 k,16位的PCM格式輸出模式)。數據采樣地點為陽煤集團某一礦井。處理機配置:Dell筆記本電腦,Intel I5處理器,8 G內存。根據采集上的聲音數據,請專業人士再次確定所采集的數據與標簽是否對應,并將數據裁剪成1 s時長的聲音頻段。根據確定的標簽,對1 s的聲音片段進行打標簽工作,聲音數據與標簽結果如表1所示。
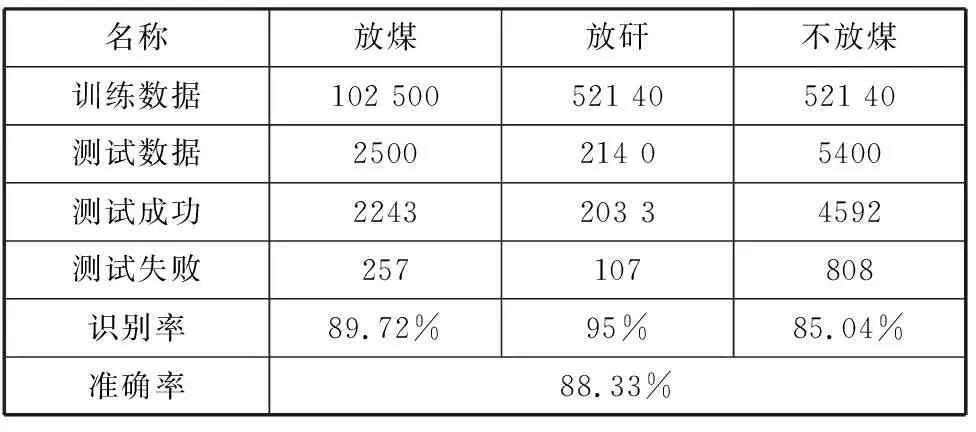
表1 實驗結果表
本實驗采用python3編程,環境為anaconda3-64位。使用了pickle、numpyscipy、python_speech_features、sklearn.metrics等庫。該實驗的訓練樣本放煤音頻數據為102 500個,放矸數據為521 40,其他為521 40,測試樣本數目分別為250 0、214 0、540 0。訓練得到模型在測試的數據集的識別率為88.33%,其中對放煤的識別率為89.72%、對放矸的識別率為95%、對不放煤的識別率為85.04%。從工業現場的情況來看,當前的識別率滿足使用的需求。該模型可以實現對放煤過程中存在矸石的準備的識別,為現場的工作提供了智能化的識別,替代傳統人耳識別的過程。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
光學精密工程(2016年6期)2016-11-07 09:07:19
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
