一種簡化門控結構的增強序列文本語義匹配模型研究
2022-01-04 15:05:02黃靜陳新府豪
軟件工程 2022年1期
黃靜 陳新府豪




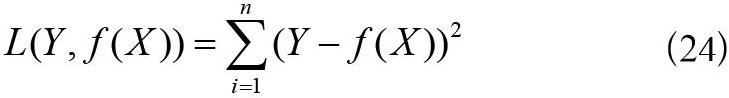
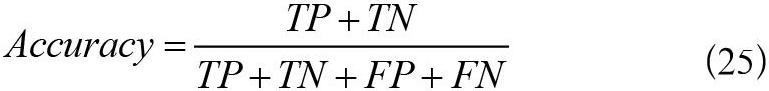
摘? 要:在自然語言處理的文本相似度匹配方面,針對長短期記憶網絡擁有多個控制門層,導致其在訓練過程中需要一定的硬件計算能力和計算時間成本,提出一種基于Bi-GRU的改進ESIM文本相似度匹配模型。該模型在雙向LSTM(BiLSTM)的ESIM模型的基礎上,通過Bi-GRU神經網絡進行數據訓練,提高模型的訓練性能。實驗表明,在公開數據集QA_corpus和LCQMC上分別進行測試,改進后的ESIM模型較之原先模型,在結果數據對比圖中,絕大部分組的損失函數數值均小于原先模型,準確率數值均大于原先模型。
關鍵詞:相似度匹配;雙向長短期記憶網絡;Bi-GRU;ESIM
中圖分類號:TP391.1? ? ?文獻標識碼:A
文章編號:2096-1472(2022)-01-50-05
Abstract: In terms of text similarity matching in natural language processing, the long and short-term memory network has multiple control gate layers, which requires a certain amount of hardware computing power and computing time cost during the training process. Aiming at these problems, this paper proposes an improved ESIM (Enhanced Sequential Inference Model) text similarity matching model based on Bi-GRU. Based on the ESIM model of bidirectional LSTM (Long Short-Term Memory), the proposed model is trained by Bi-GRU neural network to improve the training performance of the model. The improved ESIM model is tested on QA_corpus and LCQMC (Large-scale Chinese Question Matching Corpus) respectively. Test results show that compared with the original model, the loss function values of most groups are lower than the original model, and the accuracy values are higher than the original model.
Keywords: similarity matching; bidirectional LSTM; Bi-GRU; ESIM
1? ?引言(Introduction)
相似度匹配是自然語言處理領域的一個重要分支[1],是問答系統[2]、信息檢索[3]及對話系統[4]等領域的關鍵技術之一。在基于概率和統計方法方面的研究中,BERGER等[5]提出應用統計模型,將檢索詞拓展到近義詞,增大檢索范圍。郭慶琳等[6]通過適當增加詞頻改進DF算法,彌補個別有用信息的誤濾,并將特征項在特征選擇階段的權重應用到文檔集合,改進TF-IDF算法,提高其精度。石琳等[7]通過調整特征項的權重改進TF-IDF算法,優化權重計算。張奇等[8]提出三對向量分別代表TF-IDF、bi-gram、tri-gram的值,通過回歸模型計算得出相似度。
基于概率、統計方法的相似度匹配在實際運用中取得不錯的效果,但隨著深度學習在圖像、語音方面的發展,學者們開始利用深度學習模型進行自然語言處理[9]。深度學習模型特征能夠自動提取,并且相比于前者泛化性能更好。HUANG等[10]提出以輸入、表示、匹配三層為架構的DSSM模型;ZHOU等[11]提出BiLSTM雙向長短期記憶網絡模型;GERS等[12]在LSTM的基礎上,增加了窺視孔連接;CHEN等[13]提出以雙向LSTM(BiLSTM)和tree-LSTM為結構的ESIM模型,此外還有多種LSTM的變體研究。LSTM因自身存在多個控制門層,每個單元需要四個線性層,因此訓練時需要較大的存儲帶寬。
針對LSTM網絡的不足,本文采取在LSTM基礎上將忘記門和輸入門融合的GRU網絡融合ESIM模型,提出基于Bi-GRU的改進ESIM文本相似度匹配模型,在實際計算任務中相比于改進之前收斂速度加快。
2? ?相關模型介紹(Introduction to relevant models)
2.1? ?Word2vec模型
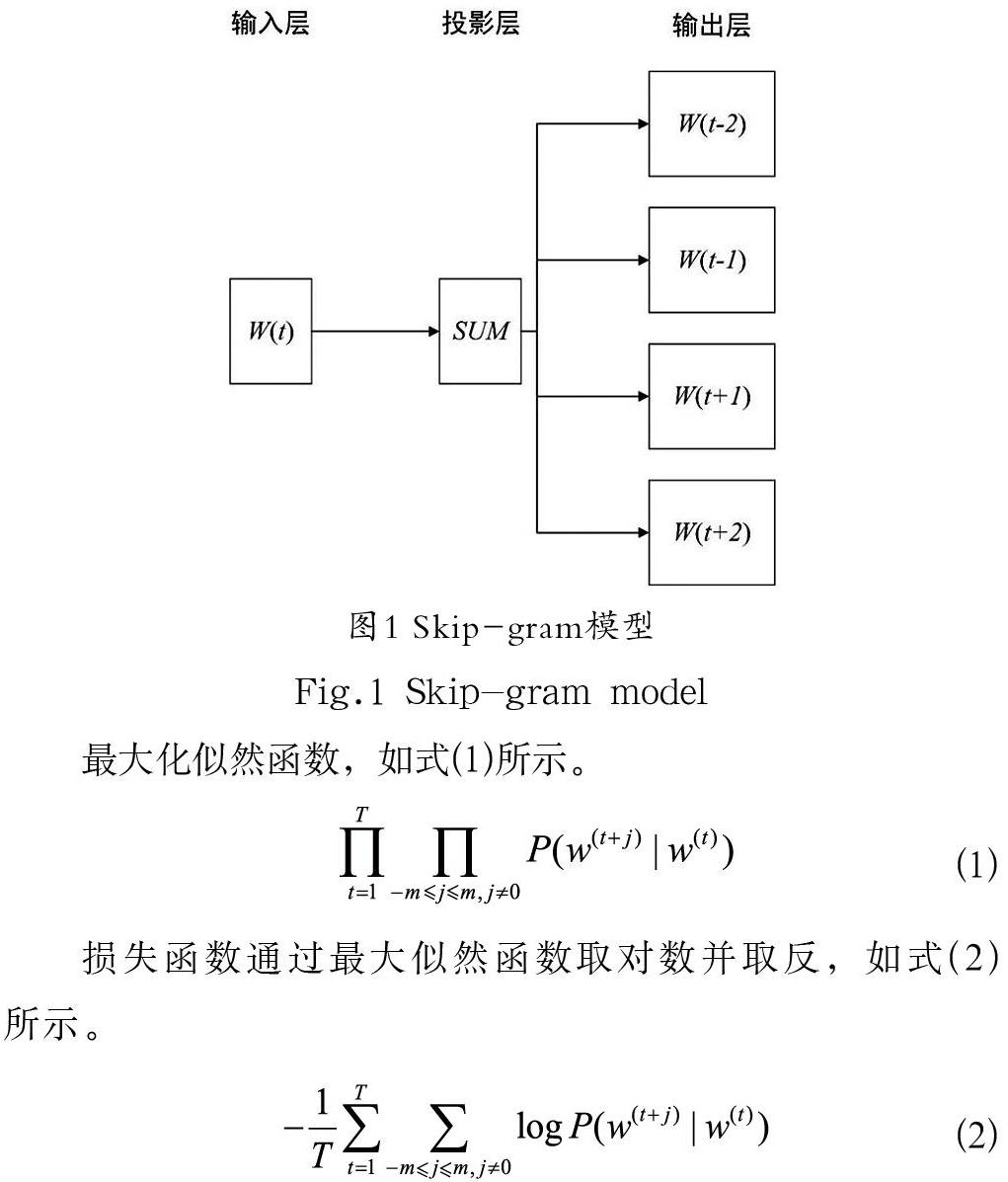
Word2vec模型是2013 年Goolge開源的一款詞嵌入模型,用于將文本內容生成詞向量,投影到向量空間以便后續做向量運算,其中包括連續詞袋CBOW和跳字Skip-gram兩種模型。
本文使用Skip-gram模型,通過詞本身來預測其上下文。該模型結構分為三層,分別為輸入層、投影層、輸出層,具體如圖1所示。
最大化似然函數,如式(1)所示。
損失函數通過最大似然函數取對數并取反,如式(2)所示。
在式(2)中,m表示窗口大小并大于零,T表示訓練文本大小。Skip-gram模型計算條件概率即根據給定詞推測其上下文詞匯的概率,如式(3)所示。
2.2? ?LSTM模型
RNN屬于時間序列網絡,能存儲歷史信息,但在序列過長的情況下會產生梯度消失的問題[14]。LSTM作為RNN的特殊形態,用于處理該問題。LSTM的網絡結構包含三個門層,分別是用于保留或刪除上一時刻狀態的忘記門層、用于決定保存輸入當前時刻的輸入門層,以及用于控制當前時刻輸出的輸出門層。具體的模型結構如圖2所示。
忘記門公式如式(4)所示。
忘記門通過sigmoid激活函數實現,當其值為1時,表示保留信息;當其值為0時,表示舍棄信息。
輸入門公式如式(5)—式(7)所示。
輸入門也可成為更新門,用于更新當前網絡單元的狀態,通過sigmoid、tanh激活函數協同調節網絡,來決定更新哪些信息。
輸出門公式如式(8)、式(9)所示。
輸入門和單元狀態共同決定輸出,即LSTM的最終輸出[15]。
2.3? ?GRU模型
GRU(Gated Recurrent Unit)模型是LSTM模型的一種特殊類型,其結構是在LSTM的基礎上,將忘記門和輸入門融合并混合單元狀態和隱藏狀態,得到只含更新門和重置門的結構模型。更新門控制上一時刻狀態信息流入當前時刻的程度,重置門是控制上一時刻狀態信息寫入當前時刻的閥門。具體的結構模型如圖3所示。
更新門公式如式(10)所示。
重置門公式如式(11)所示。
GRU模型的單元輸出公式如式(12)、式(13)所示。
由于GRU相比于LSTM的結構更加簡化,因此在循環神經網絡的長依賴問題方面展現出更好的性能。
2.4? ?ESIM模型
ESIM模型的英文全稱為Enhancing Sequential Inference Model,是一種為自然語言推斷而生的加強版LSTM[16]。其工作原理為:通過給定的前提推導出假設,再由損失函數判斷和的關聯程度,當此模型進行文本相似度匹配時,損失函數的工作從判斷推理與假設之間的關聯轉向判斷兩序列是否同義。
ESIM模型有雙向LSTM(BiLSTM)和tree-LSTM兩種結構,分為四層,分別是輸入編碼層(Input Encoding)、局部推理模型層(Local Inference Modeling)、推理合成層(Inference Composition)、池化層(Pooling)。本文為了高效簡潔,選擇BiLSTM結構進行研究,具體的結構模型如圖4所示。
輸入編碼層的輸入結構為已訓練完成的詞向量或添加詞嵌入層,再將輸入通過雙向LSTM(BiLSTM)網絡對輸入值進行編碼,即特征提取。輸出結果為和,如式(14)、式(15)所示,其中和即為前提和假設。
(2)Local Inference Modeling
局部推理模型層是將特征值做差異性處理,引入注意力機制,上一層的輸出和的注意力權重矩陣計算公式如式(16)所示。
再根據注意力權重計算a和b權重加權后的值,計算公式如式(17)、式(18)所示。
此處的計算方法是與做加權。同理,的計算方法也是與做加權。
得到計算出的編碼值和加權編碼值后,再對其做差異性計算,通過將編碼值和加權編碼值進行相減、相乘再拼接,結果向量如式(19)、式(20)所示。
(3)Inference Composition
推理合成層用于捕獲和的局部推理信息及其上下文信息,再進行推理組合操作,將值送入池化層,對其進行最大池化和平均池化的操作并拼接得到固定長度的向量,最后將值送入全連接層與softmax輸出層。計算公式如式(21)—式(23)所示。
3? ?實驗(Experiment)
本次實驗使用TensorFlow為深度學習框架,通過jieba分詞分解文本,并以Word2vec將詞轉換為詞向量,利用Bi-GRU網絡搭建ESIM模型,最后分別在兩個公開數據集上進行模型的訓練學習,檢測改進后的ESIM模型相比于改進前的ESIM模型的損失函數,以及準確率伴隨不斷迭代的收斂性能。
3.1? ?實驗環境
本文訓練模型所處的實驗環境和硬件相關的配置如表1所示。
3.2? ?實驗數據集
本文訓練模型時使用的公開數據集分別是QA_corpus和LCQMC。其中,公開數據集QA_corpus的訓練數據為100,000 條,驗證數據為10,000 條,測試數據為10,000 條,并有人工標注標簽1和0,表示語義相似與否。LCQMC是哈爾濱工業大學在自然語言處理國際頂會COLING2018上構建的語義匹配數據集,其中訓練數據為238,876 條,驗證數據為8,802 條,測試數據為12,500 條,并有人工標注標簽1和0,表示語義相似與否。
3.3? ?參數設置
本文模型的實現主要基于Python和TensorFlow。其中,模型訓練的相關參數分別如下:詞向量的維度設為100 維,嵌入隱層單元數設為512 維,上下文隱層單元數設為256 維,學習率設為0.001,每個批次的訓練數據數設為1,024,訓練的總輪次數設為50 次。
為了在訓練過程中避免過擬合現象的產生,設置Dropout參數[17]。本文將Dropout值的大小設為0.7,該參數的含義是指在向前傳播過程中,以一定的概率讓某神經元的激活值停止工作,進而使網絡變得稀疏,模型的泛化能力更強,從而減少局部特性的依賴和不同特征之間的協同效應[18]。
3.4? ?實驗結果及分析
將本文提出的改進Bi-GRU-ESIM模型和原始ESIM模型進行訓練效果對比,以相同的參數及超參數設置在兩個公開數據集上訓練,完成兩組對比實驗。將損失函數和準確率作為衡量模型訓練的性能,同時記錄且對比評估50 次總訓練輪數的完成時間。
本文采用平方損失函數作為描述性能的標準之一,如式(24)所示。先進行反向傳播,將數據值代入損失函數,通過梯度下降更新網絡中的參數,再讓正向傳播過程中的損失函數不斷減小[19],隨著訓練次數的增加,損失函數數值由大變小趨于穩定,代表訓練完成。
準確率(Accuracy)隨著迭代次數的增加呈現由小到大的變化,并趨于最終穩定,定義如式(25)所示。
在公開數據集QA_corpus上訓練,總數據量為100,000 條,每批次訓練數為1,024 條,訓練總輪數為50 次。在訓練過程中打印出每一批次的損失函數和準確率,得到4,851 組迭代數據,將改進前后的實驗結果繪圖對比,分析模型的學習效果。由于數據密集,并且損失函數和準確率收斂最終趨于平穩之后的數據接近重合,因此截取前250 組收斂速率明顯的數據對比以便更加直觀。損失函數對比如圖5所示,準確率對比如圖6所示。
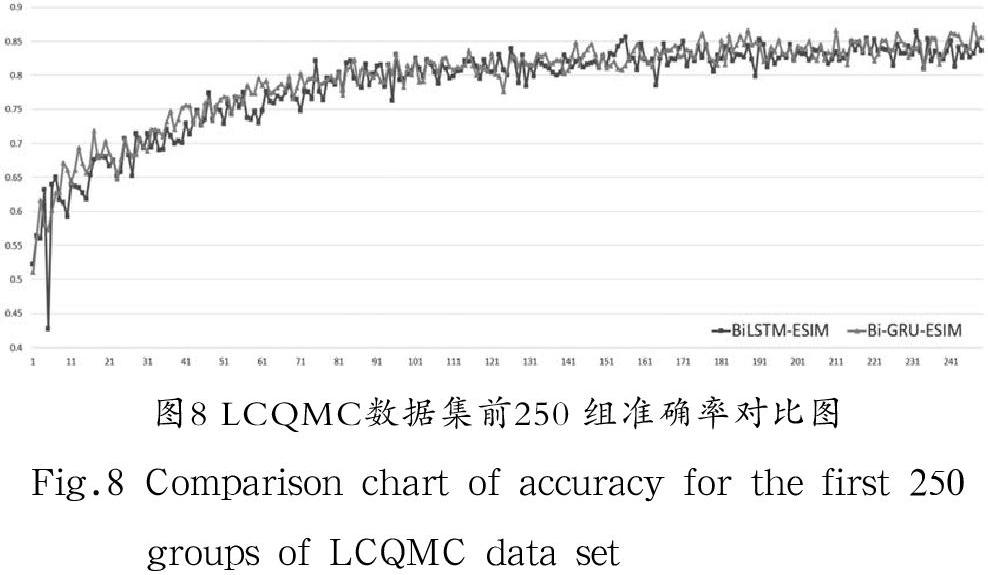
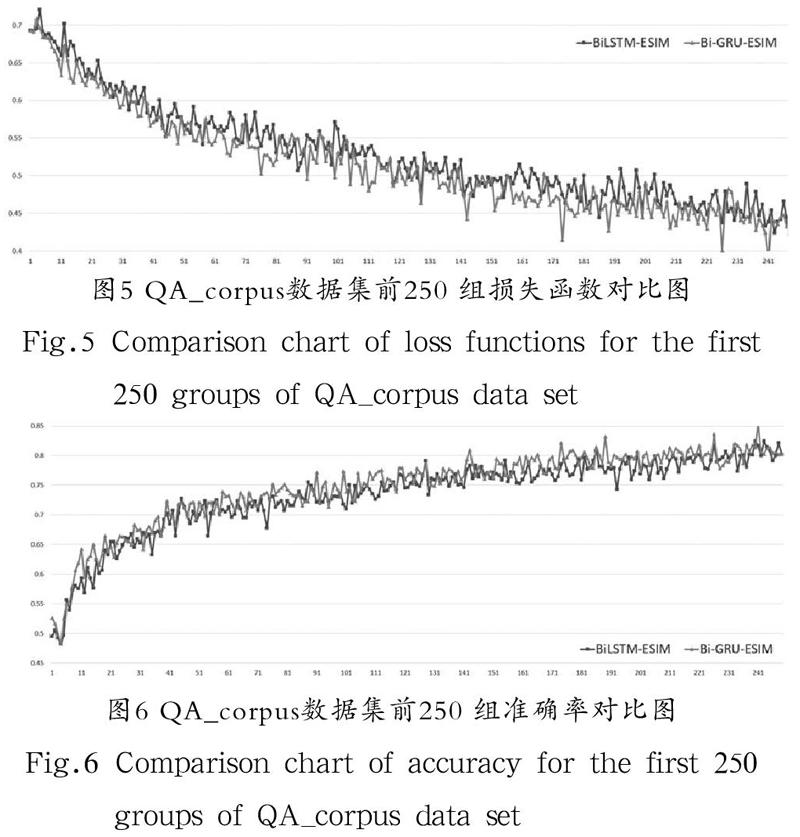
在公開數據集LCQMC上訓練,總數據量為238,876 條,每批次訓練數為1,024 條,訓練總輪數為50 次。在訓練過程中通過程序打印出每一批次各個迭代步驟的損失函數和準確率,得到11,651 組迭代數據,將改進前與改進后的數據繪制成折線圖對比,分析訓練效果。由于數據密集,并且損失函數和準確率收斂最終趨于平穩之后的數據接近重合,因此截取前250 組收斂速率明顯的數據對比以便更加直觀。損失函數對比如圖7所示,準確率對比如圖8所示。
改進前后兩模型分別在兩個數據集上完成訓練所需的時間如表2所示。
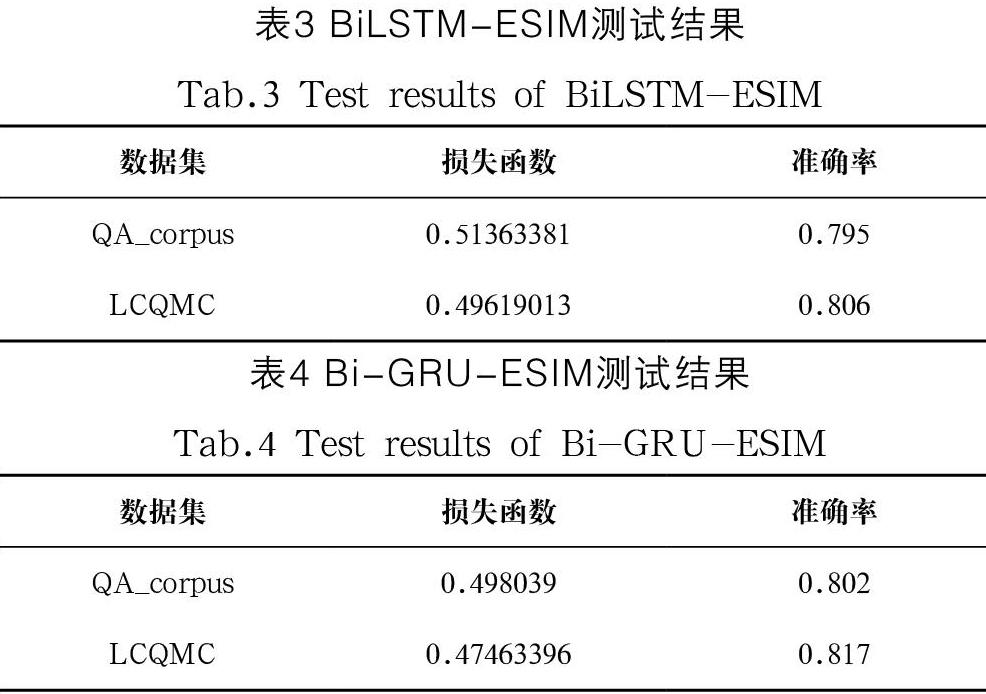
改進前后兩模型分別在QA_corpus和LCQMC提供的測試數據上測試得到的損失函數和準確率如表3、表4所示。
本文的實驗結果分析如下:
(1)由圖5和圖6中的數據對比可以得出,隨著訓練的不斷迭代,Bi-GRU-ESIM模型的損失函數的下降收斂和準確率上升收斂速度在相同迭代步數下要比BiLSTM-ESIM模型更快。
(2)由圖5和圖7相比,圖6和圖8相比,LCQMC數據集數據量是QA_corpus數據集數據量的2.4 倍,可以得出在訓練數據量較少的情況下,Bi-GRU-ESIM模型訓練的收斂速度比BiLSTM-ESIM模型更快。
(3)由表3和表4可以得出,改進后的Bi-GRU-ESIM模型較之改進前的模型在準確率測試方面較為相近。但在結合表2分析下得出,Bi-GRU-ESIM模型與BiLSTM-ESIM模型達到相同的準確度性能時,改進后的模型完成訓練所需要的總時間比改進前的模型完成訓練需要的總時間要少。
4? ?結論(Conclusion)
本文提出的基于Bi-GRU的改進ESIM文本相似度匹配模型與基于BiLSTM-ESIM的模型相比,在訓練的收斂速度上有所提升,并且在訓練數據較少的情況下,因Bi-GRU-ESIM模型的門層較少,所以訓練的收斂速度更快。雖然ESIM模型在改進前后的測試效果接近,但在模型訓練的時間上,Bi-GRU-ESIM模型所需要的學習時間更少,這就意味著與改進前的ESIM模型相比,改進后的ESIM模型達到相近的效果所需要的硬件資源和計算成本更少,因此改進后模型的學習性能有所提高,具有一定的實用價值和現實意義。
由于此次改進只針對優化學習速率,對于提高模型準確度方面實際效果差別不大,因此在提高模型學習性能的基礎上優化模型的準確率將是下一步研究的重點和方向。
參考文獻(References)
[1] 周艷平,朱小虎.基于正負樣本和Bi-LSTM的文本相似度匹配模型[J].計算機系統應用,2021,30(04):175-180.
[2] 侯瑩,陳文勝,王丹寧,等.智能問答技術在網絡運維服務中的研究[J].軟件工程,2020,23(09):9-12.
[3] 張超,陳利,李瓊.一種PST_LDA中文文本相似度計算方法[J].計算機應用研究,2016,33(02):375-377,383.
[4] 劉征宏,謝慶生,李少波,等.基于潛在語義分析和感性工學的用戶需求匹配[J].浙江大學學報(工學版),2016,50(02):224-233.
[5] BERGER A, LAFFERTY J. Information retrieval as statistical translation[J]. ACM SIGIR Forum, 2017, 51(2):219-226.
[6] 郭慶琳,李艷梅,唐琦.基于VSM的文本相似度計算的研究[J].計算機應用研究,2008(11):3256-3258.
[7] 石琳,徐瑞龍.基于Word2vec和改進TF-IDF算法的深度學習模型研究[J].計算機與數字工程,2021,49(05):966-970.
[8] 張奇,黃萱菁,吳立德.一種新的句子相似度度量及其在文本自動摘要中的應用[J].中文信息學報,2005(02):93-99.
[9] 王寒茹,張仰森.文本相似度計算研究進展綜述[J].北京信息科技大學學報(自然科學版),2019,34(01):68-74.
[10] HUANG P S, HE X, GAO J, et al. Learning deep structured semantic models for web search using clickthrough data[C]// QI H, ARUN I, WOLFGANG N, et al. Proceedings of the 22nd ACM International Conference on Conference on Information & Knowledge Management. New York, United States: ACM, 2013:2333-2338.
[11] ZHOU P, SHI W, TIAN J, et al. Attention-Based bidirectional long short-term memory networks for relation classification[C]// ERK K, SMITH N A. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). Berlin, Germany: The Association for Computer Linguistics, 2016: 207-212.
[12] GERS F A, SCHMIDHUBER J. Recurrent nets that time and count[C]//LEWIS R D, KENNEDY J, ANDRUSKIEWICZ M, et al. EEE-INNS-ENNS International Joint Conference on Neural Networks. Como, Italy: IEEE, 2000:189-194.
[13] CHEN Q, ZHU X, LING Z, et al. Enhanced LSTM for natural language inference[C]// MOHIT B, HENG J. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. Vancouver, Canada: Association for Computational Linguistics, 2017:1657-1668.
[14] YOUSFI S, BERRANI S, GARCIA C. Contribution of recurrent connectionist language model in improving LSTM-based Arabic text recognition in videos[J]. Pattern Recognition, 2017, 41(5):245-254.
[15] 陶永才,吳文樂,海朝陽,等.一種結合LSTM和集成算法的文本校對模型[J].小型微型計算機系統,2020,41(05):967-971.
[16] 馬宇生.基于深度文本匹配模型的智能問答系統問題相似度研究[D].上海:上海師范大學,2020.
[17] 黃建強,趙梗明,賈世林.基于biLSTM的新型文本相似度計算模型[J].計算機與數字工程,2020,48(09):2207-2211,2278.
[18] SRIVASTAVA N, HINTON G, KRIZHEVSKY A, et al. Dropout: A simple way to prevent neural networks from overfitting[J]. The Journal of Machine Learning Research, 2014, 15(1):1929-1958.
[19] 盧超.基于深度學習的句子相似度計算方法研究[D].太原:中北大學,2019.
作者簡介:
黃? ? ? 靜(1965-),女,博士,教授.研究領域:通信工程,大數據,深度學習.
陳新府豪(1996-),男,碩士生.研究領域:嵌入式與物聯網,智能信息處理.
