基于LUT的多目機場視頻實時拼接算法設計與實現
2022-01-05 14:28:38張興超陳賢富
網絡安全與數據管理 2021年12期
關鍵詞:方法
張興超,陳賢富
(中國科學技術大學 微電子學院,安徽 合肥230027)
0 引言
全景圖像拼接,指把幾幅彼此之間有重疊區域的圖像拼接成一幅視角更廣、信息更全面的圖像。而全景視頻拼接,指對多路讀入視頻的每一幀進行全景拼接,得到一個新的全景視頻。讀入視頻為實時視頻流,拼接得到實時的全景視頻流,即為實時全景視頻拼接。實時全景視頻拼接技術的應用十分廣泛,可運用于視頻監控、實時直播、視頻會議等領域。本文的研究對象為機場監控的多目實時視頻拼接。
全景實時視頻拼接可以采用硬件方法,也可采用軟件方法。硬件方法是指使用專門的拍攝設備實現全景拍攝,例如魚眼攝像機、超寬視角的廣角鏡頭等。采用硬件方法,可以滿足實時性、圖像質量等要求,但由于需要使用專門的硬件設備,成本較高。軟件方法指通過算法、程序來實現全景視頻拼接系統。采用此種方法,只要算法性能足夠優良,就可以使用常規的硬件平臺實現全景實時視頻合成的目標,而不需要依賴昂貴的硬件設備。因此,軟件方法成本相對較低。本文就是用軟件方法實現8路960×540實時視頻流的全景實時拼接。
本文采用的方法,其讀入的視頻,是機場跑道一側8臺攝像機采集的實時視頻流。8臺攝像機位于機場飛機跑道的同一側,大致覆蓋180°的視野范圍。8臺攝像機的位置是固定不變的,所以全景畫面到每一路圖像的像素映射關系也是固定的。本文采用拼接方法的總體思路如下:(1)使用現有的全景圖片拼接軟件拼接采集到的8個視頻幀,得到一幅全景圖;(2)圖像配準,即找出全景圖與8幅原圖之間的像素坐標映射關系,并將此映射關系存成查找表(Look Up Table,LUT);(3)通過LUT完成每一幀的實時拼接,包括重疊區域的融合;(4)全景視頻每一幀的顯示和存儲。實驗結果表明,本文采用的方法可實現8路視頻的實時全景拼接,并且能夠實時顯示、存儲拼接后的全景視頻。
1 相關工作
在已有相關研究中,文獻[1]提出一種基于特征的全景視圖生成算法,該算法能夠適應視差較大的情況,而無實時性要求;文獻[2]研究出一種移動設備視頻全景并行生成技術,該技術利用OpenMP并行加速,提高了視頻全景的合成速度,但所處理的是拍攝好的視頻而非實時視頻流;文獻[3]提出一種并行實現圖像配準和拼接的技術,該技術使用OpenMP多核并行加速,可實現2路320×240視頻信號的實時拼接,達到35 f/s的實時處理要求;文獻[4]研究出一種基于CUDA的全景圖生成技術;文獻[5]提出一種實時全景拼接算法,通過多數據流和GPU加速,實現了3路分辨率640×480、幀率30 f/s的視頻信號的自動配準和實時全景拼接;文獻[6]研究出一種基于GPU加速的實時4K全景視頻拼接技術,可對6路2K視頻進行實時拼接,得到4K輸出視頻。上面提到的幾種方法都使用了GPU加速,實際上均對硬件平臺有一定的要求。2020年,北方自動控制技術研究所的強勇勇等人研究出一種基于局部多層次特征的嵌入式視頻全景拼接技術[7],該技術使用查找表方法和最佳拼接線查找法,實現了2路1 000×750分辨率、30 f/s幀率視頻的實時全景拼接。
在國外,2007年,Brown等人在尺度不變特征轉換(Scale-Invariant Feature Transform,SIFT)算法提出之后[8],研究出一種基于SIFT算法的全景圖片合成算法[9],該算法用于全景圖片拼接,對實時性無要求;2013年,Termoe等人研究出一種基于多模塊化編程的全景視頻處理技術[10],該技術使用GPU加速,可完成4路1 280×960分辨率、30 f/s視頻信號的實時合成;2020年,Meng等人研究出一種基于非對稱雙向光流的高質量全景圖拼接技術[11],該技術采用了魚眼攝像機采集輸入圖像信號,遠景與近景拍攝的圖像信號皆能處理。
本文提出的全景視頻實時拼接方法,讀入視頻為8路960×540分辨率、25 f/s幀率的實時視頻流,采用SIFT算法進行特征點匹配以實現圖像配準,采用LUT方法和OpenMP加速以實現實時拼接。相鄰兩路圖像間的過渡區域融合,本文使用線性融合法。輸出的全景視頻分辨率為3 636×932,幀率為25 f/s。平均每一幀視頻的讀取、拼接、顯示、存儲整個過程的耗時小于40 ms,基本滿足實時性要求。本文所使用的方法,可在使用常規硬件平臺(不需要使用專門的拍攝設備,亦不需要使用GPU加速)的條件下完成8路960×540分辨率、25 f/s視頻流的實時拼接。
2 算法設計
2.1 圖像配準
如前所述,實現視頻實時拼接,首先要完成圖像配準。圖像配準,指找出全景圖與原圖之間的像素坐標映射關系。本次實驗中,8臺攝像機的位置全程都是固定不變的,因此圖像配準過程只需要做一次,并且可以離線完成,對時間復雜度不作要求,配準結果足夠準確即可。完成配準過程之后,就可以利用找出的映射關系,實現視頻的實時拼接。
圖像配準分為以下步驟:特征點匹配、計算單應矩陣(原圖到全景圖的像素坐標變換矩陣)、構建LUT表。下面分別對這三個步驟進行闡述。
2.1.1 特征點匹配
要找出全景圖和原圖間的像素映射關系,首先需要在全景圖和原圖中找出足夠數量的特征點,并找出特征點之間的匹配關系。通過特征點匹配對,可以計算每幅原圖到全景圖的像素坐標變換矩陣(即8個單應矩陣),從而得到8幅原圖中所有像素點與全景圖中像素點的映射關系。
常用的特征點匹配算法有尺度不變特征變換(Scale-Invariant Feature Transform,SIFT)算法[8,12]、加速穩健特征(Speeded Up Robust Features,SURF)算法[13]和Oriented FAST and Rotated BRIEF(ORB)算法[14]。其中,SIFT算法時間復雜度最高,但可以找出最多的特征點匹配對,匹配結果最準確;SURF算法是SIFT算法的改良加強版,時間復雜度低于SIFT算法,但找出的特征點匹配對數量少于SIFT算法;ORB算法原理較簡單,速度較快,但能找到的匹配點數量較SIFT、SURF少。
由于本次實驗對圖像配準的時間復雜度不作要求,且需要配準結果盡可能準確,本文采用SIFT算法進行特征點匹配。首先,獲取8路視頻的各一幀,并使用Panorama Studio軟件對這8個圖片進行拼接,得到一幅全景圖片。然后,使用SIFT算法分別找出8幅原圖和全景圖片之間的特征點匹配對。Panorama Studio軟 件 拼 接8幅960×540圖 片 需2~3 s的時間。SIFT算法使用OpenCV中的庫函數實現。圖1為Panorama Studio得到的全景圖與原圖1之間的特征點匹配示意圖。為確保特征點匹配的準確程度,在與原圖1進行特征點匹配時,全景圖只保留了原圖1大致對應的區域(圖1中左側畫面即為保留的全景圖區域,右側畫面為原圖1)。8幅原圖都采用此種方法完成特征點匹配。
2.1.2 計算單應矩陣
單應矩陣即像素坐標映射矩陣,其描述兩圖像之間的像素坐標映射變換。平面的單應性被定義為從一個平面到另一個平面的投影映射。描述這樣變換關系的矩陣,就叫單應矩陣。它是一個3×3浮點數矩陣。8臺攝像機分別位于不同位置,攝像頭的角度各不相同,因此8幅原圖到全景圖的映射變換屬于透視變換。
令原圖中一像素點的坐標為(x,y),變換到全景圖后坐標為(x′,y′),單應矩陣為:

則(x,y)與(x′,y′)的變換關系為:

可以發現,單應矩陣H乘以任意非0值,最終得到的變換后坐標值都是不變的。因此可令h33恒為1,僅需計算另8個元素的值,即可得到有效的單應矩陣。
理論上,只需要知道4個不共線的原圖點坐標以及它們各自變換后的坐標,即可算出一組單應矩陣元素的值。然而本文需要找出的是整幅原圖變換到全景圖的單應矩陣,要求計算出的單應矩陣適用于原圖中所有的像素點,因此,只用4個匹配點對計算單應矩陣,并不能夠得出適用于整幅原圖的單應矩陣。所以,計算單應矩陣,本文采用隨機抽樣一致算法(RANdom SAmple Consensus,RANSAC)[15],用OpenCV中的findHomography()函數實現。
2.1.3 構 造LUT表
如果拼接每一幀都對8幅原圖(視頻幀)中的像素點和單應矩陣作相乘運算,則時間開銷較大,無法滿足實時性要求。故本文采用LUT表方法實現實時拼接。具體方法如下:首先構造一個二維矩陣(稱之為矩陣M),其行列數與全景圖相同,矩陣中的元素為像素點的地址信息;然后,通過單應矩陣進行逆變換運算,得到全景圖上每個點對應于原圖中的點;之后,將此原圖點的地址存放在矩陣M的相應位置。比如,如果總合成圖中第1行第1列的點對應于第1幅原圖的第2行第3列點,那么就將第1幅原圖第2行第3列這個點的地址存放在矩陣M的 第1行 第1列。
通過單應矩陣進行矩陣逆變換運算的原理如 下:如2.1.2節 所 述,變 換 之 后 的 點 坐 標 可以用變換前的原坐標與單應矩陣中的元素表示出來,那么,變換前的原坐標也能夠用單應矩陣中的元素和變換后坐標表示。由式(2)~式(4)可得:
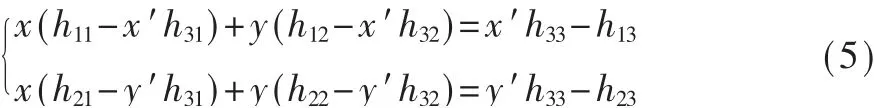

在得到8幅原圖映射到全景圖的單應矩陣之后,首先用合成圖中所有點同原圖1的單應矩陣進行逆運算。如果合成圖中的某一個點是從原圖1變換得到的,那么它逆變換得到的橫坐標值x取值必然大于0小于原圖1的寬,縱坐標y取值大于0小于原圖1的高。逆變換后x,y的取值不在此范圍內的點就不是原圖1變換得到的。然后再把原圖1中點的地址填在矩陣M的相應位置。
完成原圖1單應矩陣逆變換、找出由原圖1變換得到的區域之后,依此類推,按順序分別找出原圖2~8變換到合成圖的區域,并將原圖中相應點的地址填在矩陣M的相應位置。
對于重疊區域則采取以下方式處理:再構建7個二維矩陣(稱之為m1~m7),分別對應7個重疊區域。按上文所述方法,原圖2中點的地址填充到矩陣M中后,會覆蓋原圖1重疊區域部分點的地址。所以將原圖1重疊區域點的地址信息從矩陣M中復制到矩陣m1中,再把原圖2的像素地址填在矩陣M中。對其他6個重疊區域,采用同樣的方法處理。LUT表示意圖如圖2所示。

圖2 LUT表示意圖
2.2 實時拼接
2.2.1 基于LUT表的圖像拼接
非重疊區域只需要通過LUT表(即矩陣M),按照地址映射關系,把原圖(即讀入的每一幀圖像)中像素點的值復制到全景圖對應位置即可。
重疊區域采用線性融合方法。如前所述,對于每一個重疊區域,左側原圖的像素地址信息存放在矩陣mi(i=1,2,…,7)中,右側原圖像素地址信息存放在矩陣M中。所以,使用左圖像素權重線性遞減、右圖像素權重線性遞增的方法,對重疊區域進行融合,得到重疊區域的像素值。
2.2.2 使用OpenMP多核并行方法對拼接過程進行加速
直接使用上文所述基于LUT表的圖像拼接法,拼接一幀圖像花費的時間就達到了40 ms以上,并不能滿足8路960×540分辨率25 f/s視頻信號的實時拼接。而多核CPU目前已廣泛使用,所以本文采用OpenMP多核并行,對拼接每一幀圖像的過程進行加速,以滿足實時性要求。
2.3 全景視頻的實時顯示與存儲
實時全景視頻的顯示和存儲的時間代價較小,使用OpenCV庫函數即可。其具體耗時將在后面的實驗結果部分展示。
3 實驗結果分析
本次實驗的輸入信號為索尼SNC網絡攝像機采集的8路960×540實時視頻流,主機處理器為因特爾Core i5-8500六核處理器,軟件環境為Windows10+Microsoft Visual Studio2013+OpenCV2.4.11,編程語言為C++。讀入500幀數據進行拼接、存儲和顯示,并記錄每一幀的讀取、拼接、顯示、存儲耗時和平均每一幀的各個步驟耗時。表1展示了平均每一幀的讀取、拼接、顯示、存儲每個步驟的耗時,以及處理一幀圖像總耗時的平均值。
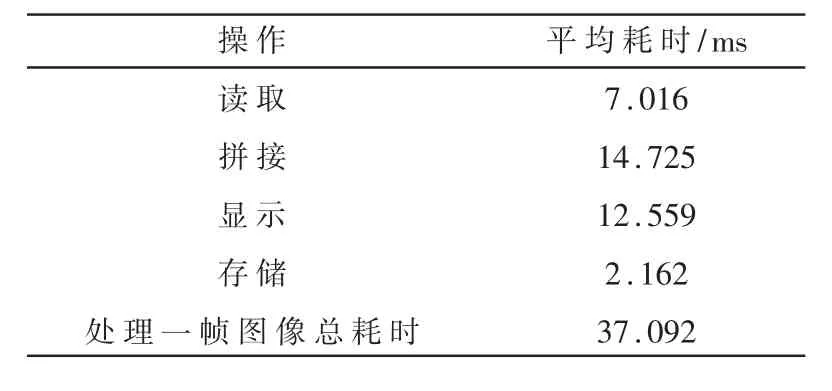
表1 程序運行時間
平均每一幀的拼接時間為14.725 ms,總處理時間只需37.092 ms,基本滿足實時性要求。
拼接得到的全景畫面(分辨率3 636×932)如圖3所示。畫面無明顯的畸變和拼縫痕跡,也未出現明顯的鬼影。

圖3 使用本文方法拼接得到的全景畫面
4 結論
本文研究了一種基于LUT查找表技術的多目全景視頻實時拼接技術。采用先離線匹配再構建LUT表的方法,解決攝像機位置固定不變情況下的視頻全景實時拼接問題;但直接采用LUT法拼接8路960×540視頻,仍然無法滿足實時性要求,因此采用了OpenMP多核并行加速。實驗結果表明,本文采用方法基本滿足實時性要求,且畫面無明顯畸變。而如何實現更高幀率和分辨率視頻信號的實時拼接,如何實現圖像自動配準,以及多路視頻信號色差的處理等問題,還有待進一步研究。
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
