基于SuperPoint的輕量級特征點及描述子提取網絡①
2022-01-06 08:05:26李志強
計算機系統應用 2021年11期
李志強, 朱 明
(中國科學技術大學 信息科學技術學院, 合肥 230027)
圖像特征點及描述子提取是計算機視覺方向研究核心問題之一, 提取圖像特征點可以將大量的圖像信息稀疏化, 從而更好地進行信息壓縮, 而提取描述子則是對特征點周圍信息進行描述, 生成特征向量, 用以和其他區域進行區分.圖像特征點及描述子提取正被廣泛應用于圖像匹配[1], 3D重建[2]和SLAM[3]等諸多領域, 優秀的圖像特征點及描述子提取算法可以對計算機視覺的發展發揮巨大的作用.
自2012年以來, 深度學習[4]以其提取特征更豐富、魯棒性更強、精度更高和不需要手工設計特征等優點在圖像分類[5]、目標檢測[6]和圖像分割[7]等領域有了飛速發展.近些年來, 深度學習與特征點及描述子提取的結合也是該領域研究的一大熱點問題.
1 概述
目前的特征點及描述子提取算法主要有以下兩類:完全手工設計特征和通過深度學習提取特征.
完全手工設計特征指的是特征點及描述子提取的算法完全通過手工設計獲得, 圖像信息獲取完全依靠手工設計的算法獲取, 如SIFT和SURF算法.Lowe[1]提出的SIFT算法是通過構建圖像高斯金字塔進而構建DOG金字塔, 在DOG金字塔中尋找滿足條件的極值點作為特征點.SIFT算法是通過統計特征點鄰域梯度分布信息提取出特征點主方向, 將坐標軸旋轉到主方向, 計算以特征點為中心16×16窗口內像素梯度的幅度和方向, 歸一化后形成128維特征向量作為描述子.而Bay等人[8]針對SIFT算法計算量較大的缺點進行改進提出了SURF算法, 利用Hessian矩陣提取特征點, 減少了圖像下采樣的時間消耗.SURF算法通過統計特征點鄰域內的Harr小波特征獲取特征點主方向,在沿著特征點主方向的鄰域內, 提取Harr特征形成64維特征向量作為描述子.完全手工設計的特征點和描述子提取算法是通過數學公式對圖片進行進化和抽象來提取信息, 其魯棒性和泛化性較大規模數據集驅動的深度學習具有天然劣勢.
通過深度學習提取特征點或描述子的過程不依靠手工設計的算法獲得, 是通過卷積神經網絡訓練和推理獲得.由于深度學習魯棒性和泛化性較好, 因此這種方式獲得的特征點或描述子也較手工設計的方式泛化性能更好.Tian等人[9]提出的L2-Net利用卷積神經網絡在歐幾里得空間學習圖像塊描述子的特征.網絡輸入是圖像塊, 輸出是128維向量, 網絡以L2范數描述圖像特征之間的距離, 用損失函數約束匹配上的圖像塊對的描述子距離盡可能近, 不匹配上的圖像塊對的描述子距離盡可能遠.Mishchuk等人[10]提出的HardNet在L2-Net基礎上改進了損失函數.HardNet參照SIFT算法, 使用損失函數最大化最近鄰正樣本和負樣本之間的距離.Barroso-Laguna等人[11]提出的Key.Net則是將手工設計和卷積神經網絡結合形成新的多尺度特征點檢測網絡.DeTone等人[12]的SuperPoint、Ono等人[13]的LF-Net和Dusmanu等人[14]的D2-Net等均是端到端學習特征, 輸入一張圖片, 輸出特征點和描述子.其中SuperPoint提出一種自監督方式訓練網絡提取特征點和描述子.SuperPoint網絡有兩個分支分別進行特征點和描述子的提取, 共享相同的編碼器.LF-Net由兩部分組成: 全卷積網絡生成特征點和通過可微采樣器在獲取特征點附近圖像生圖像塊并將圖像塊輸入描述子提取網絡生成描述子.D2-Net與之前完全手工設計特征算法的先生成特征點再提取描述子過程和SuperPoint算法的特征點與描述子并行生成過程均不相同, D2-Net只生成描述子, 再根據當前點的描述子在最大響應通道中是否為局部最大值判斷當前的是否為特征點.
大數據驅動的深度學習能夠比完全手工設計的算法提取更深層次的圖像特征, 魯棒性和泛化能力更強.而端到端學習特征的網絡減少了工程的復雜度也減少了誤差的累計.在端到端提取特征點和描述子網絡中SuperPoint是其中效果較好的網絡, SuperPoint網絡輸出的特征點和描述子精度較高, 網絡結構較其他網絡更為簡單, 因此本文選擇在SuperPoint網絡上進行進一步優化.SuperPoint網絡雖然網絡結構較為簡單, 但是對于計算能力較低的設備, 如嵌入式設備, SuperPoint網絡參數量和運算量仍較大, 不能實現實時運行, 因此本文在SuperPoint網絡基礎上進行優化, 構造效果接近SuperPoint網絡, 但參數量和運算量更低的輕量型網絡, 實現在計算能力較低的設備上實時運行的目標.
2 輕量級特征點及描述子提取網絡實現
為了實現SuperPoint網絡的輕量化, 本文首先更改SuperPoint網絡的卷積方式、卷積層數和下采樣方式, 將普通卷積改成深度可分離卷積[15]并且減少了網絡層數, 然后對網絡進行進一步剪枝, 進一步減少網絡參數和運算量.
2.1 基于深度可分離卷積的SuperPoint網絡
SuperPoint是端到端的特征點及描述子提取網絡,網絡結構是類似語義分割網絡的編碼器-解碼器結構,輸入一張完整的圖片, 經過共享的編碼器提取圖像深層特征, 再分別經過特征點和描述子兩個解碼器, 分別輸出特征點和描述子, 與完全手工設計算法的先檢測特征點, 再計算描述子不同, 特征點和描述子并行生成.SuperPoint網絡結構如表1所示, 表中每一行為一個卷積通道, 第一個數字是輸入通道, 中間兩個數字是卷積核大小, 最后一個數字是卷積核數目, “+池化”是指在卷積后進行最大池化操作.共享編碼器結構類似與VGG網絡[16]的卷積結構, 前6層每經過兩次3×3卷積后緊跟著進行2×2最大池化, 共享編碼器經過卷積池化等操作后, 進行了圖片降維, 提取了深層特征, 減少了后續的計算量.經過特征點解碼器和描述子解碼器輸出的特征圖大小為原圖的大小的1/8, 為了輸出了原圖一樣大小的特征圖, 特征點解碼器輸出的特征圖進行8倍的子像素卷積, 描述子解碼器輸出特征圖進行8倍上采樣.

表1 SuperPoint網絡結構
SuperPoint網絡是使用自監督方式進行訓練, 訓練過程如下所示: (1)構建包含基礎圖形的虛擬圖片, 如線、多邊形和立方體等組成的圖片.已知虛擬圖片的角點, 訓練編碼器和特征點解碼器提取特征點.(2)使用訓練好的編碼器和特征點解碼器輸出真實圖片及其N個經過隨機單應性變換圖片的特征點, 將N個經過隨機單應性變換圖片的特征點通過逆向單應性變換還原到原圖上, 與原圖的特征點合并為增強的特征點數據集.(3)將真實圖片及其經過單應性變換后的圖片輸入SuperPoint網絡中, 根據特征點的位置和特征點的對應關系訓練網絡生成特征點及描述子.
本文使用的損失函數與SuperPoint網絡的損失函數保持一致.損失函數由特征點損失和描述子損失兩部分組成, 如式(1)所示:
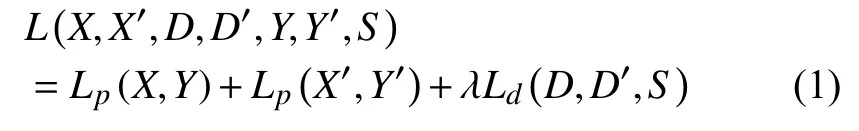
其中,X,D分別為原圖輸入網絡后輸出的特征點特征圖和描述子特征圖,Y為原圖特征點的的標簽值,X',D'和Y'對應輸入圖片為原圖經過單應性變換后的圖片, 其余含義與X,D和Y相同,S由式(5)說明.Lp和Ld分別表示特征點損失和描述子損失, 超參數λ用來平衡特征點檢測損失和描述子損失.Lp具體公式如下所示:
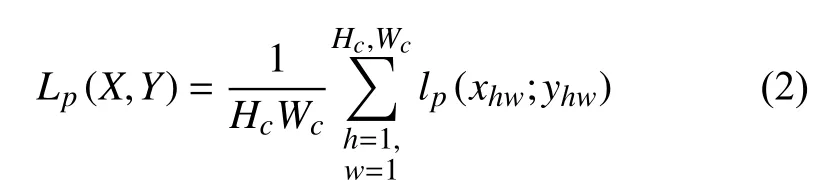
其中,Hc,Wc分別表示特征點特征圖的高和寬.xhw,yhw分別表示X,Y在(h,w)處的值.lp具體公式如下所示:
其中,xhwk表示為xhw在第k個通道的值.lp使得xhw在標簽值y對應的通道上盡可能大.
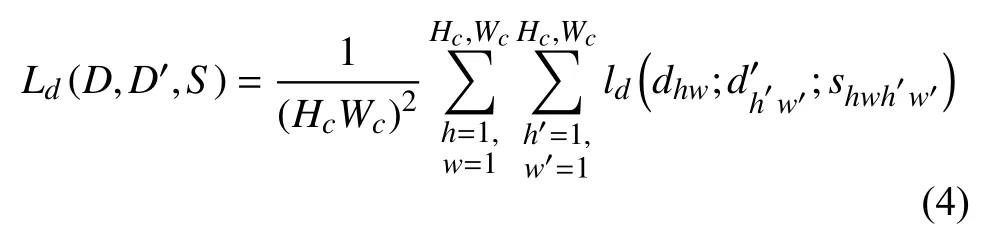
其中,dhw,dh′w′分別表示D,D′在 (h,w), (h′,w′)處的值.由于共享編碼器經過8倍下采樣, 因此輸出的描述子特征圖中的點對應輸入圖片中一個8×8像素點的圖片單元.shwh′w′用來判斷dhw對應輸入圖片單元的中心位置經過與原圖一致的單應性變換后, 是否在d′h′w′對應輸入圖片單元的中心位置的鄰域內,shwh′w′是用來判斷dhw,d′h′w′在原圖中對應位置是否相近.shwh′w′=1 表示在原圖中對應位置相近, 為正向對應, 反之為反向對應.shwh′w′和ld具體公式如下所示:
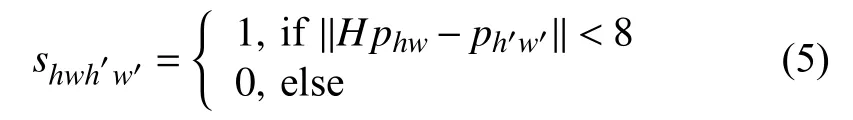
其中,phw,ph′w′分別表示dhw,d′h′w′對應的輸入圖片單元的位置中心.Hphw是對phw, 進行與原圖相同的單應性變換.
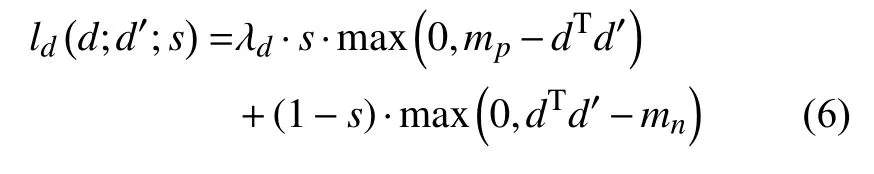
其中, 超參數λd用來平衡描述子內部正向對應損失和負向對應損失值, 超參數mp為正向對應閾值,mn為負向對應閾值.
為了降低運算量和參數量, 本文將SuperPoint網絡中除共享編碼器第一層以外的其余卷積更換成深度可分離卷積.深度可分離卷積將傳統的卷積方式分成逐層卷積和逐點卷積兩部分, 如圖1所示, 左側為逐層卷積過程, 右側為逐點卷積過程.假設輸入特征圖大小為H×W, 通道數是Cin, 逐層卷積是對每一個通道使用S×S大小的1個通道的卷積核進行卷積, 逐層卷積對通道內的特征信息進行處理.逐點卷積是使用1×1大小的卷積核進行傳統方式卷積, 處理通道間的特征信息.假設輸入特征圖大小為H×W, 通道數是Cin, 卷積核大小是S×S, 卷積核數目是Cout, 對傳統卷積來說參數量為Cin×S×S×Cout, 運算量為H×W×Cin×S×S×Cout, 對逐層卷積來說, 參數量為Cin×S×S×1, 為傳統卷積的 1/Cout,運算量為H×W×Cin×S×S×1, 為傳統卷積的 1/Cout.對逐點卷積來說, 參數量為Cin×1×1×Cout, 為傳統卷積的1/S2, 運算量為H×W×Cin×1×1×Cout, 為傳統卷積的 1/S2.因此深度可分離卷積的參數量和運算量均為傳統卷積的1/Cout+1/S2.通常來說, 卷積核大小S為3, 卷積核數目Cout遠遠大于9, 因此深度可分離卷積的參數量和運算量大概是傳統卷積的1/9.深度可分離卷積既處理了通道內的特征信息也處理了通道間的特征信息, 可以替代傳統卷積進行, 減少了網絡的參數量和運算量.

圖1 深度可分離卷積的卷積和剪枝過程
為了進一步減少網絡參數量和運算量, 本文將原始共享編碼器的卷積層數和下采樣方式進行更改.具體操作如下所示: (1)原始編碼器的8層卷積改成6卷積; (2)將卷積+最大池化的下采樣方式更改為步長為2卷積, 這樣卷積的運算量變為原來的1/2, 并且省去了最大池化的計算; (3)為了彌補這些操作帶來的特征信息損失, 本文將共享編碼器的輸出維度設置成256維.
2.2 網絡剪枝
為了進一步對網絡結構進行優化, 本文進一步對網絡進行剪枝, 尋找更優的網絡結構.Liu等人[17]提出的通道剪枝算法是一種效果較好的算法, 該算法對VGG參數量壓縮20倍, 運算量壓縮5倍, 而沒有影響精度.但是算法是根據傳統卷積設計的, 本文將其進行改進應用于深度可分離卷積中, 壓縮本文的網絡.
Liu等人的通道剪枝算法是通過批歸一化中γ參數衡量通道的重要程度, 刪除低于某個閾值的通道,進而刪除與之關聯的卷積核, 重新訓練進行微調, 完成剪枝過程.批歸一化的過程如式(7)所示, 其中xi是批歸一化的輸入的一個通道的特征,yi是批歸一化的輸出的一個通道的特征, μB和 σB分別為批特征的均值和方差, γ和 β 為批歸一化中的參數.對于某個通道而言, 若其批歸一化中的參數 γ較小, 其歸一化輸出值也較小, 可認為該通道不重要, 則可以刪除生成這個通道的卷積核與下一層卷積核中對應的該通道的通道.具體衡量標準是將網絡中所有的批歸一化參數 γ進行升序排序, 根據需要將前面一定比例較小的 γ對應通道進行刪除.中間層的卷積核剪枝應該包括兩部分:(1)輸入通道的刪除導致卷積核中對應通道的刪除;(2)輸出通道的刪除導致對應卷積核的刪除.卷積核剪枝意味著尋找到一個較優的網絡結構, 再進行訓練進行微調提升其精度.
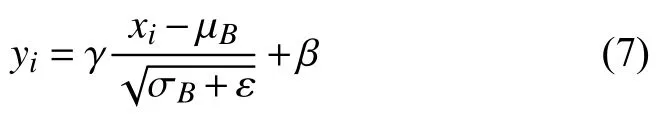
Liu等人的通道剪枝算法是刪除所有批歸一化中γ中較小的值對應的通道.在深度可分離卷積中, 逐層卷積后續操作也是批歸一化, 但是逐層卷積的輸入輸出通道數應該相同, 因此深度可分離卷積中只能通過逐點卷積中的批歸一化衡量通道重要程度.逐層卷積剪枝是通過輸入通道的刪除而進行剪枝, 具體流程參見算法1.

算法1.深度可分離網絡剪枝算法images/BZ_317_1898_3031_1923_3064.png1) 將所有非逐層卷積后的批歸一化參數 進行升序排序, 刪除前a%對應的通道;

2) 如圖1所示, 圖中白色部分代表特征圖和核卷積核被刪除.輸入通道的刪除導致逐層卷積核中對應通道的刪除以及逐點卷積核中對應通道的刪除;3) 輸出通道的刪除導致逐點卷積中對應卷積核的刪除;4) 對剪枝后的網絡重新訓練進行微調.
本文中a設置為20, 剪枝前共享編碼器的輸出通道為[64, 64, 128, 128, 256], 特征點解碼器輸出通道為[256, 65], 描述子解碼器輸出通道為[256, 256], 剪枝后共享編碼器的輸出通道變為[35, 47, 94, 86, 147], 特征點解碼器輸出通道變為[256, 65], 描述子解碼器輸出通道變為[256, 256].可以發現, 共享編碼器相對于解碼器結構更為復雜, 存在較多冗余信息, 被刪除較多.
3 實驗分析
本文實驗過程中使用操作系統為Ubuntu 18.04, 深度學習框架為PyTorch 1.3.在測試FPS時使用的硬件環境為NVIDIA Jetson TX2開發板和AMD Ryzen 5 4600U CPU, 其他情況下硬件環境為Intel Core i7-7800X CPU+ NVIDIA GeForce GTX 1080 Ti GPU.本文實驗過程中超參數設置與SuperPoint網絡保持一致,損失函數中λ=0.000 1,λd=250, 正向對應閾值mp=1, 負向對應閾值mn=0.2.訓練過程中批處理大小為32, 使用ADAM優化器,lr=0.001,β=(0.9, 0.999).
本文分析了改進后的網絡和SuperPoint網絡在參數量、運算量以及HPatches數據集[18]評估效果對比.
3.1 參數量、運算量和FPS對比
參數量和運算量對比如表2所示, SuperPoint+2.1代表使用2.1節中的優化方法, 即將傳統卷積改成深度可分離卷積, 改變卷積層數和下采樣方式, SuperPoint+2.1+2.2代表在2.1節優化方法的基礎上使用2.2節的優化方法, 即進一步進行網絡剪枝.浮點運算數代表運行網絡所需要的浮點運算次數用來表示網絡計算量.實驗結果表明, 使用2.1的優化方式后, 參數量被壓縮為原始網絡的22%, 運算量被壓縮為原始網絡的8%.使用本文最終的優化方法(2.1+2.2節優化方式)后, 參數量被壓縮為原始網絡的15%, 運算量被壓縮為原始網絡的5%, 大大降低了網絡參數量和運算量.
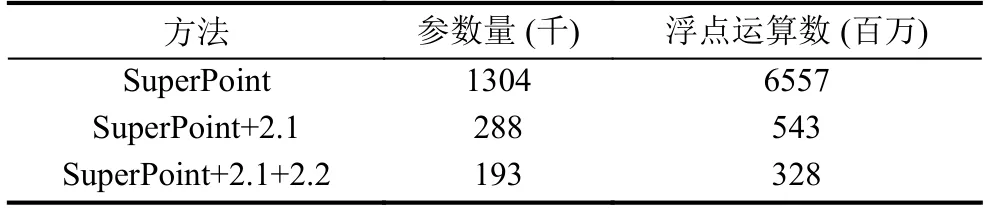
表2 參數量與運算量對比
FPS表示網絡每秒鐘處理圖片幀數, 反應網絡運行速度.FPS對比如圖表3所示, 480×640_tx2表示實驗硬件環境為嵌入式NVIDIA Jetson TX2開發板, 使用其配置GPU進行推理, 圖片分辨率為480×640.240×320_cpu和480×640_cpu則表示實驗硬件環境均為筆記本小新PRO13 2020, 使用其配置的CPU AMD Ryzen 5 4600U進行推理, 圖片分辨率分別為240×320和480×640.可以看出本文優化后網絡的FPS在3次對比中分別提升5.07, 7.19和7.68倍, 均值為6.65倍,FPS 提升較大.在 480×640_tx2和 240×320_cpu條件下, 本文網絡近似實現了實時運行的目標.

表3 FPS對比
3.2 Hatches數據集評估效果對比
本文參照發布SuperPoint論文中的評估方式, 在Hatches數據集進行評估, Hatches數據集是2017年發布的特征點及描述子評估數據集.Hatches數據集內部包含屬于116的696張照片, 其中57個場景屬于大幅度的光照變化, 59個場景屬于大幅度的視角變化.本文接下來分別對比SuperPoint和本文方法在特征點檢測和特征點匹配效果的對比, 對比實現過程中網絡使用的超參數設置均相同.
本文使用可重復率和定位誤差來判斷特征點檢測效果.可重復率指是: 在視角或者光照變化的兩張圖片中, 同時出現的特征點對占總的特征點數的比率.定位誤差指的是: 同時出現的特征點對的像素點距離的均值.本文中同時出現的特征點對指的是在相同視角下特征點間距離小于3個像素點, 視角不同的特征點對需對其中一張照片經過逆向變換, 從而到相同視角.SuperPoint和SuperPoint+2.1的對比顯示: 經過將傳統卷積改成深度可分離卷積、改變卷積層數和改變下采樣方式后, 雖然使得網絡模型變得更簡單, 但是可重復率上表現更好, 增加了1.12%, 定位誤差也僅僅增加0.11.SuperPoint+2.1和SuperPoint+2.1+2.2的對比顯示: 進行網絡剪枝后, 可重復率降低0.32%, 定位誤差降低0.02, 網絡剪枝帶來的特征點檢測效果損失可以忽略不記.表4證明, 本文的優化方法(SuperPoint+2.1+2.2)在大幅度降低運算量和參數量的情況下, 并沒有導致特征點檢測效果大幅度下降, 甚至可重復率表現上更優.

表4 特征點檢測效果對比
要實現特征點匹配效果對比, 首先要通過特征點和描述子獲得兩幅輸入圖片的單應性變化矩陣.獲取單應矩陣的過程如下所示: 首先圖片1和圖片1經過單應性變換產生的圖片2分別送入網絡中生成特征點和描述子, 描述子通過暴力方式進行最近鄰匹配進行配對, 配對的特征點和描述子調用OpenCV中find-Homography()函數, 方法選擇RANSAC算法, 生成兩個圖片之間的估計的單應性變換矩陣.表5中單應估計準確率指的是: 圖片1經過真實的單應變換矩陣的圖片邊界角點和經過圖2流程產生的估計的單應變換矩陣的圖片邊界角點的距離在一定的容忍距離差e下的數目占總的數量比例, 單應估計準確率可以反映圖片間特征點匹配效果.表5中對比SuperPoint和SuperPoint+2.1, 可以發現: 本文使用的方法, 在e=1時下降0.03, 在e=3時下降0.02, 在e=5時下降0.02, 僅用輕微的降幅, 在可以接受范圍內.SuperPoint+2.1和SuperPoint+2.1+2.2的對比表明: 剪枝算法幾乎沒有降低單應估計準確率, 僅在e=1時下降0.02.表5證明,本文使用的方法并沒有導致的特征點匹配效果大幅降低, 匹配精度仍然較高.

表5 單應估計準確率對比
圖2展示的為原始SuperPoint網絡、使用2.1節優化后的網絡和最終優化后的網絡的在同一幅圖片上特征點檢測和匹配的效果圖對比圖, 紅色點為檢測到的特征點, 綠色線為匹配特征點.對比3幅圖片可以發現3個網絡檢測到的特征點數和匹配的特征點數都比較相近, 說明本文最終優化后的網絡在參數量壓縮為原來的15%, 運算量運算量壓縮為原來的5%和FPS提升6.64倍的同時, 特征點檢測和匹配的效果幾乎沒有降低.

圖2 特征點檢測與特征點匹配效果圖
4 結論與展望
本文針對SuperPoint網絡的參數量和運算量較大,在嵌入式設備上不能實現實時運算的缺點, 對其網絡結構進行精簡和優化.首先, 本文將深度可分離卷積應用于SuperPoint網絡中并且改變了網絡的層數和下采樣方式.然后本文將Liu的通道剪枝算法進行改進, 使其可以應用于深度可分離卷積中.實驗結果表明, 最終優化后的網絡網絡參數量被壓縮為原始網絡的15%,運算量被壓縮為原始網絡的5%, 運行的FPS較原始網絡提升6.64倍, 在計算資源有限的嵌入式和CPU上也能近似實現實時運行, 網絡特征點檢測和匹配效果較原始網絡僅有輕微幅度下降.
下一步的研究工作在于將本文的網絡與SLAM等算法進行結合, 用本文提出的特征點和描述子提取算法代替傳統的特征點和描述子提取算法, 構建一個更魯棒的SLAM算法.
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年6期)2019-01-08 02:43:04
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
