基于IIGA-BP神經網絡的鋼材銷售預測模型①
2022-01-06 06:05:08陳永當曹坤煜
計算機系統應用 2021年10期
關鍵詞:模型
陳永當,曹坤煜
1(西安工程大學 機電工程學院,西安 710600)
2(西安市現代智能紡織裝備重點實驗室,西安 710600)
隨著企業市場化進程的不斷推進,企業間的競爭壓力及銷售市場的不穩定程度與日俱增.如何合理、準確預測產品的市場需求,已成為現代企業控制產能,有效規避經營風險,實現精準營銷的重要舉措[1].因此銷售預測是現代企業經營管理中不可或缺的環節,預測的準確性也直接關系到企業生產經營的成敗.為準確預測企業在未來時間內的銷售量,國內外學者再度掀起了對預測模型的研究.
近年來,國內外學者針對預測模型進行了大量研究,并相繼提出了神經網絡、極限學習、機器學習、時間序列模型等銷售預測方法[2-4].神經網絡因其具有強大的自適應學習能力和較好的非線性擬合能力,而被廣泛應用于銷售預測模型的構建[5].其中,最具代表性的BP神經網絡(BP Neural Network,BPNN)因其完備的理論體系已逐漸成為學者們關注的重點.如:吳正佳等[6]針對備貨型企業的銷售情況,利用BPNN強大的學習和存貯信息的能力,建立了基于BPNN的銷售預測模型.Qin等[7]通過選取網絡類型在制定網絡參數優化機制的基礎上,提出了BPNN銷售預測模型.高文等[8]采用logsig激勵函數,在對影響因素數據收集與降維處理的基礎上,建立了基于BPNN的預測模型.Bibaudalves等[9]以數據的季節性與價值性為導向,提出了一種采用月平均值具有最佳結構的神經網絡銷售預測模型.但由于易陷入局部極值和對初始網絡權重敏感性強等問題是BPNN難以避免的不足,對此,學者們提出了許多優化BPNN的有效方法.如:查劉根等[10]利用免疫算法優化BPNN的初始權值和閾值,提出了基于免疫遺傳算法的BPNN預測方法.鄭建剛等[11]提出了一種改進的免疫遺傳算法,擴大了BPNN模型中權值的搜索空間,提高了BPNN的學習效率和精度.Cheng等[12]提出了一種基于自適應免疫遺傳算法優化BPNN的網絡流量預測新方法.朱玉等[13]提出一種基于IGA的BP網絡應用于煤與瓦斯的突出強度預測.Yang等[14]采用免疫遺傳算法優化BPNN的權值,建立了用電量增長率的神經網絡預測模型.張浩等[15]提出了一種自適應免疫遺傳算法優化的BP神經網絡用于糧食產量預測研究.Wang[16]運用免疫遺傳算法優化神經網絡,進行電力負荷預測.Yun等[17]提出了一種基于父輩免疫遺傳算法的碳釬維性能預測神經網絡模型.王華強等[18]將用免疫遺傳算法全局尋優和BP網絡局部尋優相結合提出了IGA-BP網絡模型并應用于高爐鐵水硅含量的預測.Huang[19]將免疫遺傳算法與小波神經網絡相結合,實現了對離心式壓縮機性能的預測.付傳秀等[20]將免疫遺傳算法與BP神經網絡相融合,對中國區域經濟協調發展水平進行預測.這些采用免疫遺傳算法優化BPNN的研究,在一定程度上解決了BPNN的不足,但由于免疫遺傳算法自身存在著早熟收斂和種群質量低下等問題.因此只有在進一步改進優化的基礎上才能更好的解決BPNN的預測問題.
綜上所述,BPNN雖然在銷售預測方面取得較好的效果.但由于傳統BPNN利用梯度下降原理對網絡參數進行調節,存在收斂速度慢、易陷入局部最優的缺點,且該算法初始權值和閾值的隨機選取致使神經元缺乏調節能力,基于此本文提出了改進免疫遺傳算法與傳統BP神經網絡模型于一體的有效的神經網絡銷售預測模型.利用改進的免疫遺傳算法(Improved Immune Genetic Algorithm,IIGA)中特有的種群初始化方式、抗體濃度調節機制及交叉算子、變異算子自適應調節策略解決免疫遺傳算法(Immune Genetic Algorithm,IGA)的早熟收斂問題,進而初始化BPNN各連接層的權值和閾值,改善網絡參數隨機性導致BP神經網絡輸出不穩定和易陷入局部極值的缺點,從而提高算法的收斂速度和模型的預測精度.
1 改進免疫遺傳算法優化BP神經網絡設計
1.1 BP神經網絡
BP神經網絡是含有一個或多個隱含層的多層前饋神經網絡,其較強的非線性擬合能力是解決不確定性問題的數學模型.它采用逆向傳播算法基于梯度下降原理以監督學習的方式實現模式識別和函數逼近功能,是目前應用最為廣泛的神經網絡[21].最為典型的3層神經網絡結構,可以實現任何函數輸入到輸出分布式并行信息處理的高度非線性映射,通過數據信息的正向傳遞和誤差的反向傳播按一定的規則不斷調整權值閾值,修正網絡誤差,直至輸出誤差或訓練次數滿足預定條件,如圖1.該網絡結構具有一個隱含層,輸入節點數為xm,輸出節點數為yn;wij、wjk分別為各連接層間的權值向量;θj、?k分別為隱含層與輸出層的閾值向量.
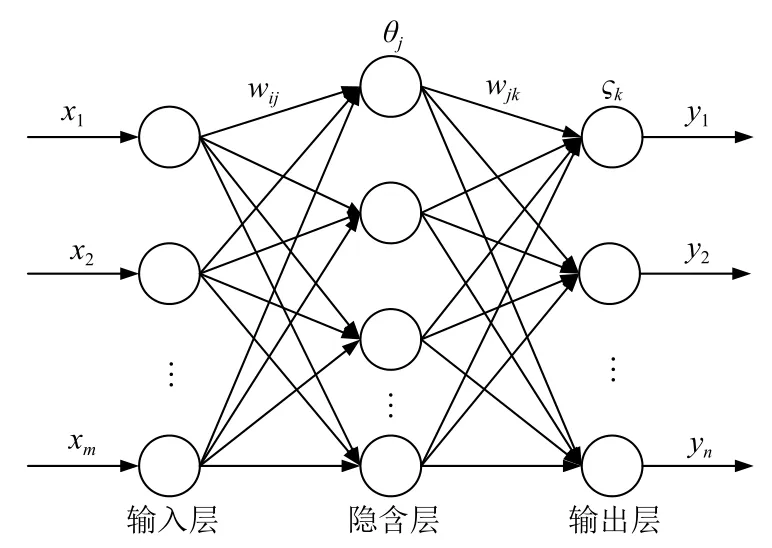
圖1 BP神經網絡結構圖
1.2 改進免疫遺傳算法優化BP神經網絡原理
免疫遺傳算法是一種模擬生物免疫原理和遺傳進化過程的新型進化優化算法,是具有免疫功能的遺傳算法.通過在免疫算子中加入遺傳算子,兼顧搜索速度與搜索能力的同時,又避免了遺傳算法的退化現象及早熟收斂問題.它將需要優化的參數編碼形成串聯群體,通過免疫遺傳進化操作,將種群進化到更好的搜索空間,使種群中的個體達到最優[22].免疫遺傳算法較為突出的尋優能力和種群多樣性保持機制,正好彌補BP神經網絡的不足,但標準免疫遺傳算法在處理復雜優化問題上仍存在收斂速度慢和局部極值問題.因此,考慮改進免疫遺傳算法對BP神經網絡進行優化.
本文采用改進免疫遺傳算法從以下3個方面優化BP神經網絡:
(1)確定網絡拓撲結構
(2)優化BP神經網絡初始權值和閾值
以種群中最優抗體的適應度為導向利用免疫遺傳算法尋優,得到全局適應度最高的一組網絡參數即為初始權值和閾值.
(3)仿真預測
將得到的初始權值和閾值,回代BP網絡在訓練期間再次局部尋優,獲得最優權值閾值,進而實現最佳預測輸出.
1.3 改進免疫遺傳算法優化BP神經網絡過程
先對免疫遺傳算法的種群初始化方式、抗體濃度的調節機制及交叉算子、變異算子的自適應調節策略進行改進.用改進的免疫遺傳算法以種群中最優抗體的適應度值為導向進行全局尋優,定位最優解的參數空間,再用BP算法的局部尋優能力通過Bayesian函數對網絡權值和閾值進行精調,使網絡輸出值逐步逼近期望值,最后經過反歸一化得到預測值.采用改進免疫遺傳算法優化BP神經網絡算法流程,如圖2.
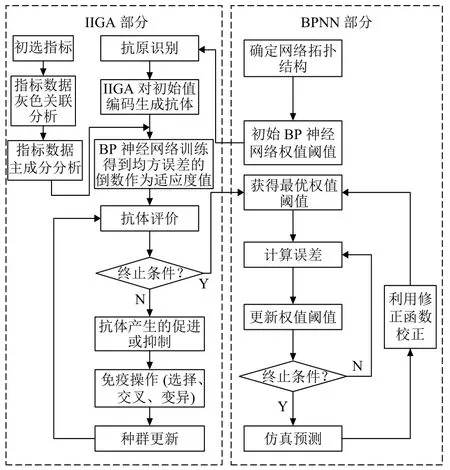
圖2 改進免疫遺傳算法優化BP神經網絡算法流程圖
具體步驟如下:
(1)確定網絡拓撲結構
(2)抗原識別
抗原對應問題的目標函數即網絡預測的均方誤差最小.
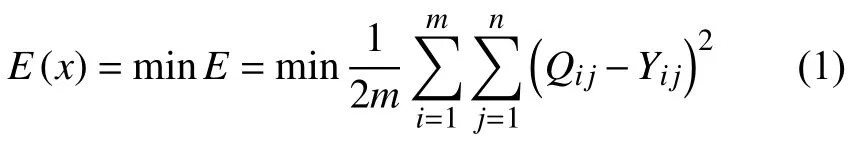
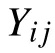
(3)產生初始抗體
為避免初始權值閾值隨機化,計算效率較低的弊端,在保證種群多樣性的同時加快算法收斂速度.本文先采用Nguyen-Widrow方法[23]產生70%初始種群;剩余30%,采用多次進化隨機生成的方法,在每次生成的抗體群中只保留部分適應度較高的抗體,并將抗體群中適應度較弱的抗體,在下次進化過程中進行替代,以此為循環,直至達到隨機生成的種群規模.
Nguyen-Widrow方法:

式中,w為權值矩陣,θ為閾值矩陣;s、r分別為網絡隱含層節點數與輸入指標的維數;rand(s,r)為s行r列的均勻分布的隨機數矩陣;I(s,l)為s行r列的全1矩陣;normr(J)為J矩陣的標準化歸一矩陣.
(4)抗體編碼
本文采用實數編碼方式對神經網絡初始連接權值及閾值編碼,得到隨機分布的基因碼串,每一個基因碼串,對應一組權值閾值.
抗體編碼長度為:

式中,n、m、l分別為輸入層、隱含層及輸出層節點數.
(5)親和度計算
① 抗體與抗原之間的親和度
抗體與抗原間的親和度大小是決定抗體優劣的評判標準,以訓練數據均方誤差的倒數作為免疫遺傳算法的原始親和度函數即適應度函數.
適應度函數為:

為了防止進化初期,初始抗體群中的特殊抗體誤導種群的發展方向.本文采用線性調整策略,對適應度函數進行調整[24].
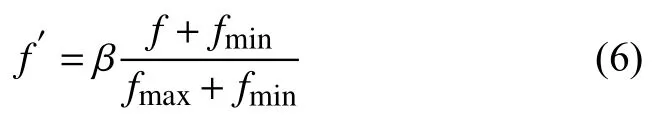
式中,fmax、fmin分別為當代種群中最大與最小的適應度值;f為當前抗體的適應度值;f′為修正后抗體適應度值; β為調節系數.
② 抗體與抗體之間的親和度
本文采用歐幾里得距離作為衡量抗體間相似度的重要指標.抗體v={v1,v2,···,vn}與抗體r={r1,r2,···,rn}之間的歐氏距離[25]為:
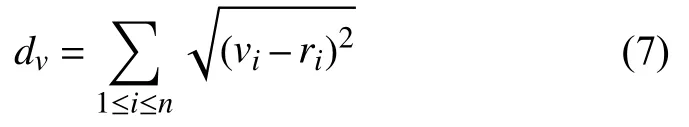
親和度為:

抗體濃度為:
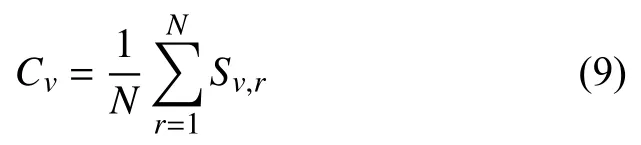

(6)基于濃度的種群調節
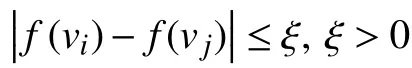
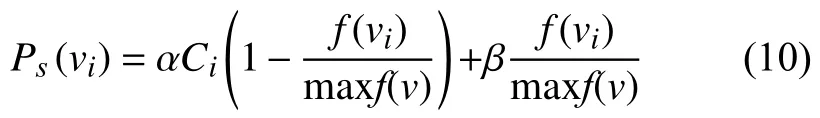
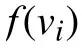
(7)免疫操作
① 克隆選擇
按照精英保留與輪盤賭相結合的策略進行克隆選擇操作.在每次更新記憶庫時,先將適應度較高的抗體進行保存,再按照式(10)計算出選擇概率大小將種群中優秀的抗體存入記憶庫.
② 自適應交叉與變異
為了使算法的交叉與變異概率能夠根據種群中抗體適應度高低和算法進化代數進行自適應調整,則需對交叉和變異概率進行參數設計.
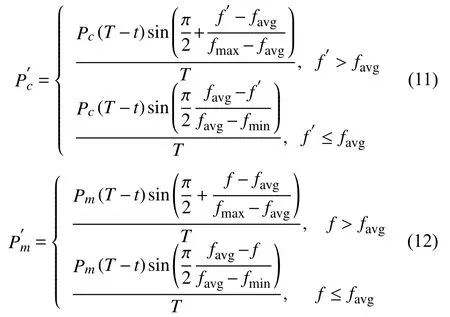
式中,f′為待交叉抗體的最大適應度值; fmax為當前種群的最大適應度值; favg為當前種群的平均適應度值;fmin為當前種群的最小適應度值; f為待變異抗體的適應度值; t為算法當前的進化代數; T為算法的總進化代數; Pc、Pm分別為交叉與變異概率的初始值.
(8)網絡初始權值和閾值的確定
以種群中最優抗體的適應度為導向循環進行評價、選擇、交叉、變異等操作,直到達到設定的進化代數,選擇適應度最高的一組網絡參數即為初始權值和閾值.
(9)仿真預測
取得初始權值、閾值后,利用BP算法進行學習,不斷調整,直至滿足既定的網絡誤差或達到最大進化代數,得到最優權值和閾值,并實現預測輸出.
2 鋼材銷售預測模型的建立
2.1 鋼材銷售主要影響因素識別
鋼材的銷售狀況受各種復雜因素的影響,以某鋼鐵企業的歷史銷售數據為例,從影響鋼材銷售量的眾多因素中選取國內生產總值(X1)、鋼材出口量(x2)、鋼材進口量(X3)、房地產開發投資(X4)、金屬切削機床產量(X5)、拖拉機產量(X6)、全社會固定資產投資(X7)、車輛產量(x8)、全國建筑業總產值(x9)作為初選指標.9個影響因素數據選自1994-2018年《中國統計年鑒》[26],如表1.
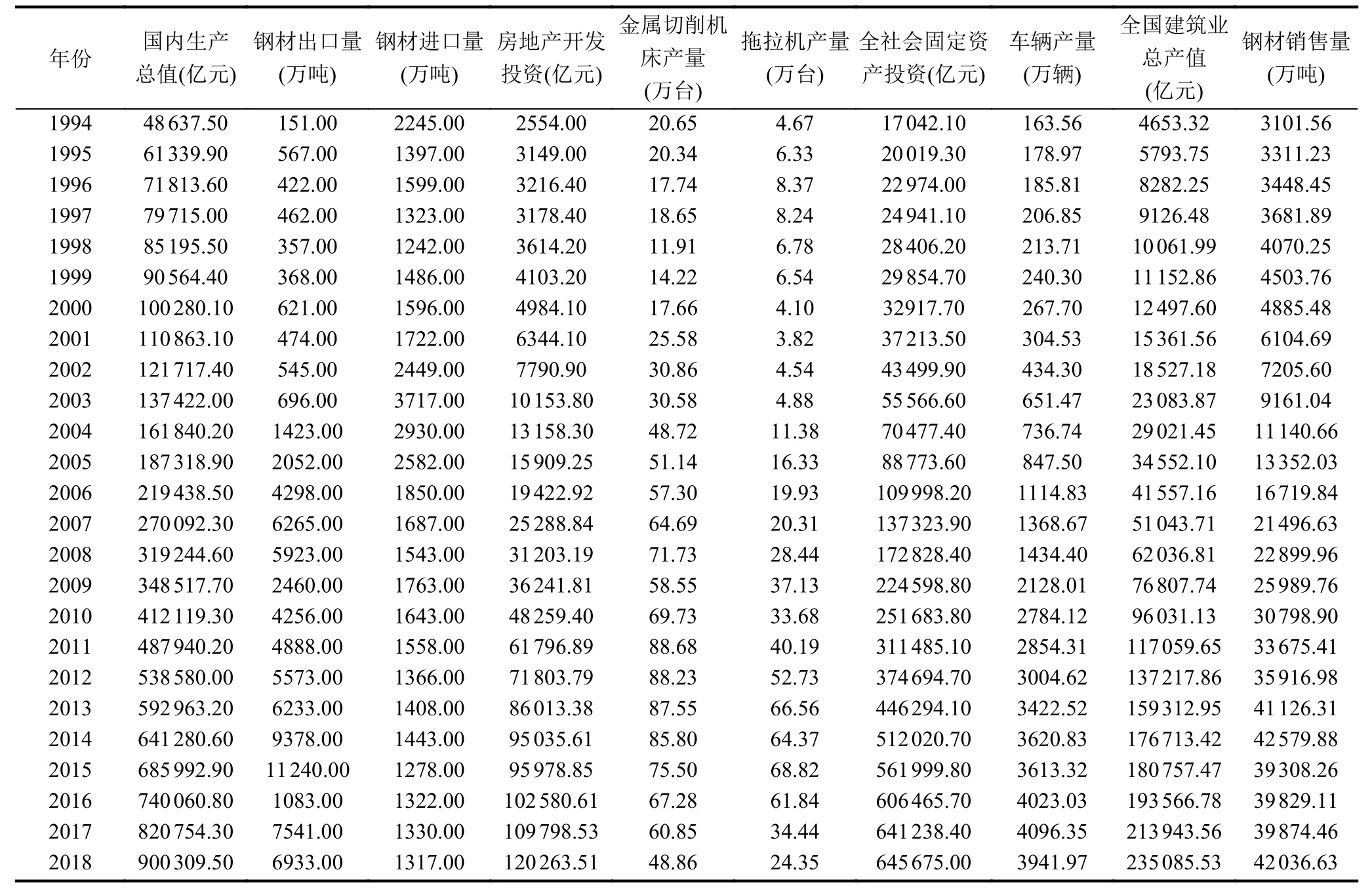
表1 某鋼鐵企業鋼材銷售量及影響因素數據
2.2 灰色關聯分析
灰色關聯分析是一種通過權衡同一坐標系中各因素序列曲線的相似程度,來判斷系統中因素間的關聯性.它對樣本容量以及樣本間規律性無特別要求,具有計算量小,精度高的特點,是研究少樣本、貧信息分析和預測領域的新方法[27].本文主要采用灰色因素關聯分析法對鋼材銷售量的主要影響因素進行識別,找出各輸入因素與輸出量之間的關聯程度,從而提取出影響輸出指標的主控因素.
具體步驟如下:
(1)確定參考序列和比較序列
根據研究需要,以表1中1994-2018年的鋼材銷量作為因變量Y,并記參考序列為Y={y(k)|k=1,2,···,n};鋼材銷售的9個影響因素分別作為自變量組,9組比較序列為xi={xi(k)|k=1,2,···,n},i=1,2,···,m.
(2)數據的無量綱化
為避免數量級差別過大而導致預測誤差較大的情況,在對數據計算前需要進行無量綱化處理.本文采用均值轉換法,以消除不同數據間的量綱差異.計算公式為:
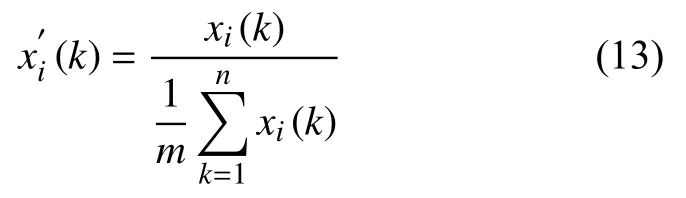
(3)計算各因素與鋼材銷售量的關系系數

式中,Δi(k)=|y(k)?xi(k)|; ρ為分辨系數,一般取0-1.
(4)計算各因素與鋼材銷售量的關聯度
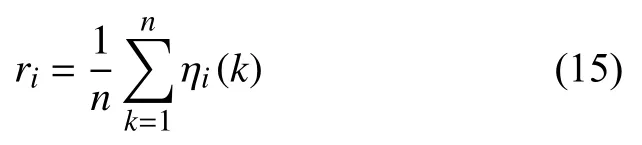
將上述過程基于Matlab 2018a平臺編寫計算程序,分辨系數 ρ設定為0.5,則灰色關聯分析結果,如表2.

表2 各影響因素與鋼材銷售量灰色關聯度表
2.3 主成分分析
由表1可知原數據為多維數據,由于數據間的耦合性導致并不是所有的數據都對鋼材的銷售量有很高的貢獻率.如果直接將使用灰色關聯分析選定的指標作為預測模型的輸入節點,由于實驗數據的復雜和冗余,網絡的性能及模型的預測精度勢必會受到影響[28].為此本文選用主成分分析法對灰色關聯分析選定的指標進行降維處理,確定輸入指標,以減小變量間的耦合關系,保留對預測結果有價值的數據.
具體步驟如下:
(1)建立相關矩陣R
假設輸入原始數據集為X,每個樣本對應P個影響因素,即X=(X1,X2,···,XP).則相關系數矩陣為:

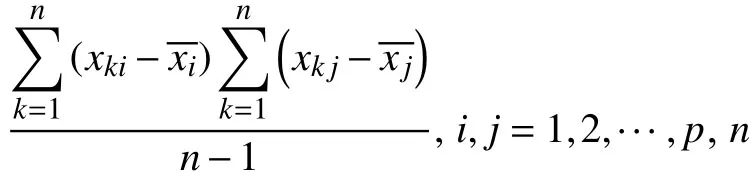
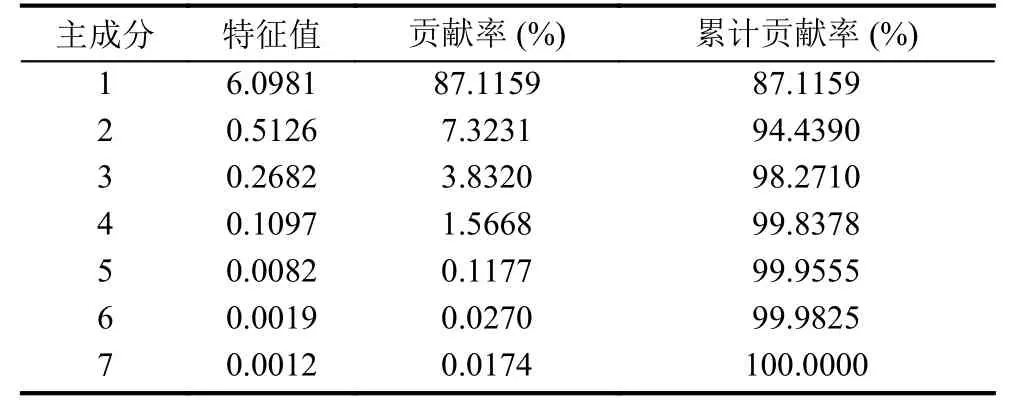
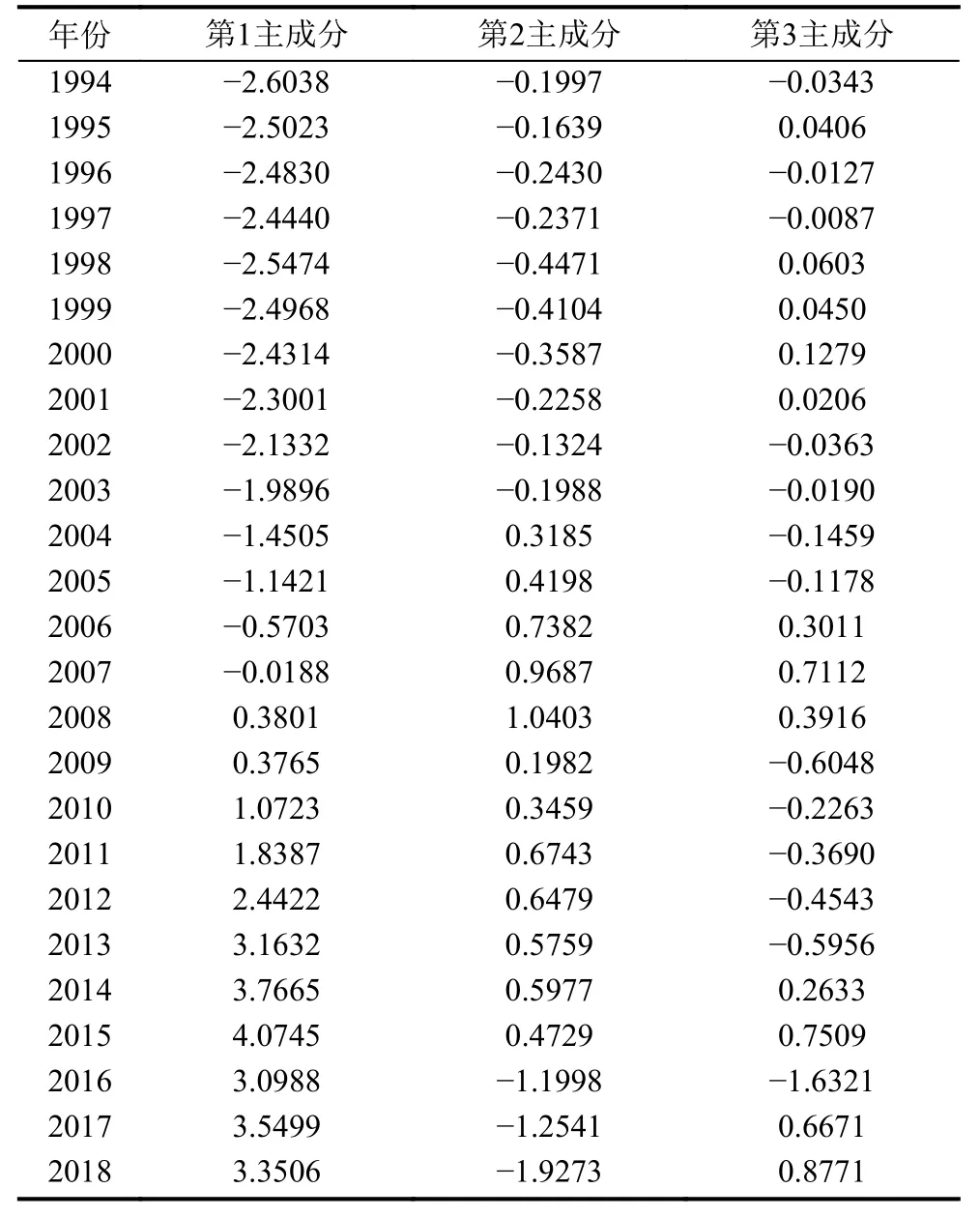
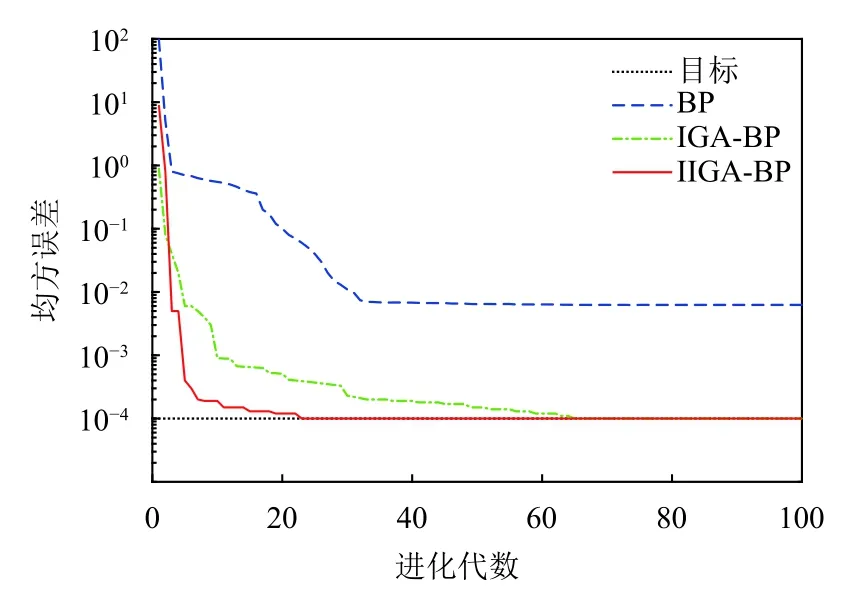
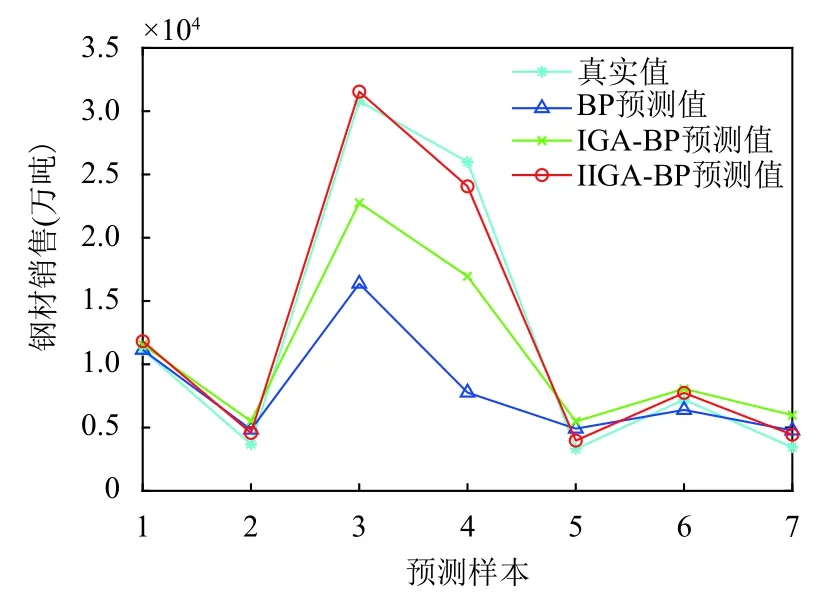
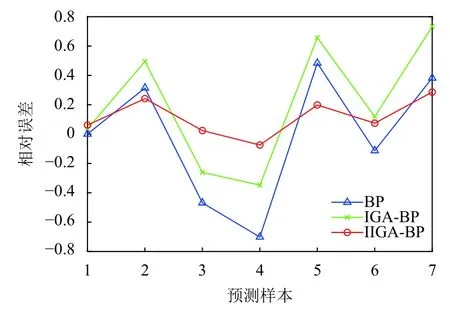
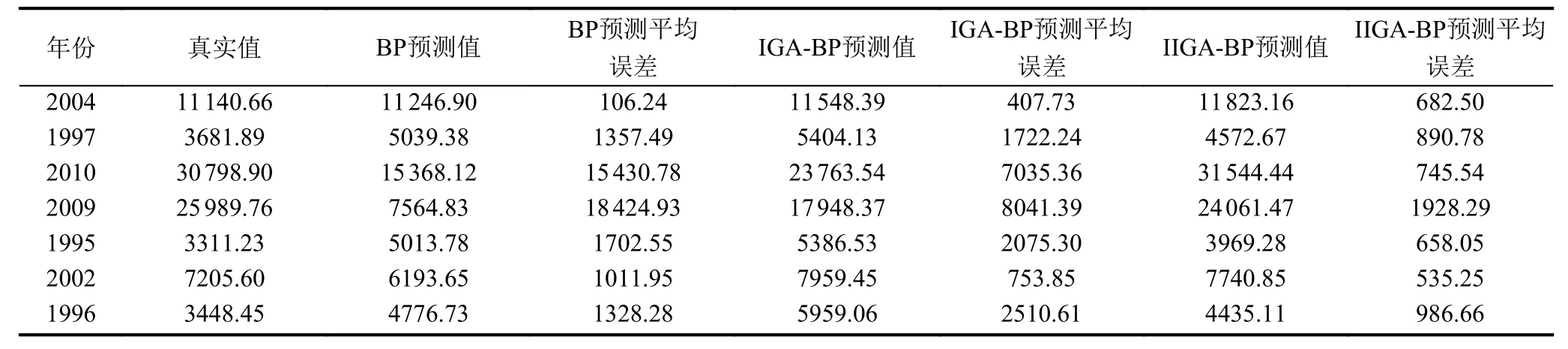
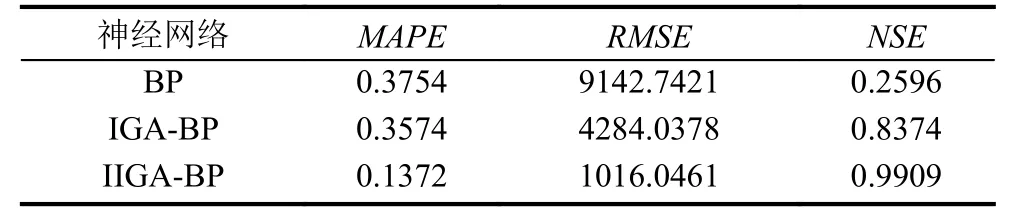
(3)確定主成分個數m(m 一般來說當累計貢獻率達到75%-95%時,對應的前m個主成分就能夠包含原始數據集的絕大多數的信息.方差貢獻率和累計方差貢獻率為: (4)計算主成分得分 式中,fbv=αv1xb1+αv2xb2+···+αvpxbp,b=1,2,···,n,v=1,2,···,m. 將上述過程基于Matlab 2018a平臺編寫計算程序,使用princomp函數,得出各指標因素的貢獻率,如表3. 表3 影響因素的特征值及其方差貢獻率 由表3可知,前3個主成分已包含了全部影響因素95%以上的信息.故選取前3個主成分代替原灰色關聯分析選定的因素作為最終的輸入指標.各主成分的得分值,如表4. 表4 主成分得分表 為全面驗證算法性能,以某鋼鐵企業鋼材銷售量數據集為例進行驗證.將主成分分析得到3個主成分的得分作為新樣本,在已有鋼材銷售量統計的25條數據中,隨機抽取18條作為仿真訓練集,剩余7條作為仿真驗證集,用于驗證誤差.算法程序是在Matlab 2018a的基礎上實現,在處理器為Intel(R)Core(TM)i5-5200U CPU,RAM為4 GB,運行環境為Windows 10(64位)的個人計算機上進行仿真測試.BP神經網絡隱含層傳遞函數采用tansig函數; 輸出層傳遞函數采用purlin函數; 訓練函數采用trainlm函數; 激活函數采用Sigmoid函數. 隱含層節點數的確定,通常先用經驗公式來計算節點范圍,再進行BP神經網絡試算,確定準確的節點數. 式中,q、m、n分別為隱含層、輸入層及輸出層的節點個數; a為調節因子一般取1-10.通過不斷增加隱含層節點數,以網絡輸出誤差最小為標準,獲取最佳隱含層節點數.經過反復調整,當隱含層節點數為10時,輸出誤差最小,網絡拓撲結構為8-10-1. 實驗參數設置,如表5、表6. 表5 BP神經網絡參數設置 表6 免疫遺傳算法參數設置 IGA模型與IIGA模型的適應度函數進化曲線,如圖3. 由圖3可知,改進的免疫遺傳算法模型進化54代以后,優化結果的適應度函數值逐漸趨于穩定,約為2.2961,表明每個個體都在最優解附近.免疫遺傳算法模型適應度函數值從76代之后逐漸穩定在1.7294左右,且進化后期曲線有振蕩現象發生.表明改進的免疫遺傳算法模型在優化網絡參數的效果上要好于經典的免疫遺傳算法模型. 圖3 適應度函數進化曲線圖 目標誤差為10-4時,BP、IGA-BP、IIGA-BP三種網絡模型訓練誤差曲線,如圖4. 由圖4可知,IIGA-BP算法,訓練前期收斂速率最快,曲線最陡峭,在第5代左右擺脫局部最優解后,又快速進入穩定狀態,這與本文的交叉算子、變異算子的自適應設計有關.而且,IIGA-BP神經網絡經過23次進化后達到目標誤差,IGA-BP神經網絡經過65次進化后達到目標誤差,而BP神經網絡經過100次進化后訓練誤差收斂于6.253×10-3陷入局部最優且無法逃逸.可見,采用改進免疫遺傳算法優化的BP神經網絡,在提高網絡的收斂速度,降低BP網絡陷入局部極值的可能上具有很強的優越性. 圖4 3種網絡模型訓練誤差曲線圖 為進一步比較3種模型的性能差異,驗證預測模型的準確性、適用性,對BP、IGA-BP、IIGA-BP神經網絡進行仿真實驗,獨立運行20次得到如圖5、圖6的仿真結果. 圖5 3種網絡模型預測輸出對比圖 圖6 3種網絡模型預測相對誤差對比圖 由圖5、圖6可知,BP神經網絡模型和IGABP神經網絡模型預測離散度和誤差波動幅度都較大;IIGA-BP神經網絡模型預測離散度較小,誤差基本保持在[-0.25,0.25]之間,預測效果更穩定,預測精度大幅度提高. 為了更直觀地顯示3種模型的預測精度,采用平均絕對百分比誤差(MAPE)、均方根誤差(RMSE)和納什效率系數(NSE),進一步評價3種網絡模型的誤差指標. 3種模型的預測值與真實值對比如表7所示.3種網絡模型預測精度對比,如表8. 表7 3種網絡模型預測值與真實值對比(萬噸) 由表8可知,IIGA-BP神經網絡模型的MAPE為0.1372相對于BP神經網絡模型預測精度提高了23.82%,也優于IGA-BP神經網絡模型的預測精度.與另兩種模型相比IIGA-BP神經網絡模型的RMSE值最小,模型的誤差小,泛化能力強.IIGA-BP神經網絡模型的NSE為0.9909相比其它兩種模型,本模型具有更好的非線性擬合能力,預測的穩定性更高. 表8 3種網絡模型預測精度對比 本文針對BP神經網絡在銷售預測中的不足.提出了一種改進免疫遺傳算法優化BP神經網絡的銷售預測模型.改進的免疫遺傳算法提出了新的種群初始化方式、抗體濃度的調節機制及交叉算子、變異算子自適應策略的設計方法,保證了種群多樣性,提高了算法的收斂能力和尋優能力.利用改進的免疫遺傳算法擴大BP網絡的權值搜索空間,獲得最優權值和閾值,改善了BP網絡易陷入局部極值的缺點.最后通過構建IIGA神經網絡鋼材銷售預測模型并與BP、IGA-BP神經網絡預測模型進行橫向測評,實驗表明改進免疫遺傳算法優化后的BP神經網絡具有較強的擬合能力和泛化能力,在提高模型預測精度和收斂速度的同時,也簡化了網絡結構,降低了進化代數,預測輸出的穩定性較好.但由于網絡的訓練數據較少,網絡訓練不完善,導致模型預測精度不是太高.如需深入研究,可進一步擴大訓練數據集,加強模型的學習效果,提高預測精度.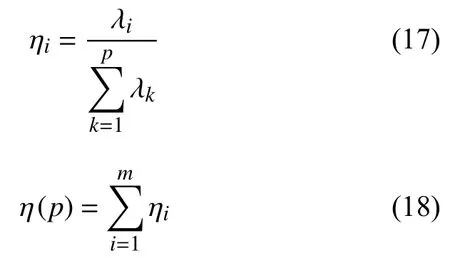

3 仿真實驗
3.1 實驗環境及參數設置



3.2 網絡性能分析

3.3 算法模型預測精度分析

4 結論
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
