基于時序特征和集成算法的用戶購買預測①
2022-01-06 06:05:44盛鐘松朱海景
計算機系統應用 2021年10期
盛鐘松,朱海景,余 諒
(四川大學 計算機學院,成都 610041)
近年來,隨著互聯網技術的高速發展,網上購物已然成為大部分消費者購物的第一選擇,國內電商平臺的規模也越做越大,電子商務已經成為中國國民經濟的重要貢獻者.過去10年,中國網絡零售額快速增長,同比增長27.3%,高于世界平均增長速度.2019年,中國網絡零售額占比達到新高,網上零售額占總零售額的20%以上[1].如此龐大的消費群體,使得各大電商平臺積累了海量的原始數據,如何從海量的消費者數據中發現消費者購買行為背后的規律開始成為一個新的研究熱點.這對預測消費者未來的購買行為、幫助電商平臺實現高效營銷以及有效的客戶服務具有重要意義.
1 相關工作
目前,隨著數據挖掘技術和機器學習算法的逐漸成熟,各種預測算法紛紛應用在電商用戶購買預測的研究中.Liu等人[2]通過建立一個包含1000多個特征的預測模型,分別從用戶、品牌和品類等方面對數據進行特征描述,該模型證實了在預測用戶“雙十一”之后是否會再次購買商家商品的有效性,取得了不錯的效果.Lee等人[3]通過研究多個不同的電子商務網站,發現不同類型的電子商務網站中不同用戶的行為軌跡,從中發現用戶在購買前的一些行為習慣.Liu等人[4]通過使用SVM的方法對用戶網上購買做出預測,提高了電子商務的產品推薦準確率和轉化率.祝歆等人[5]通過構建Logistic回歸-支持向量機融合算法模型對網絡購買行為的預測做出研究,證明混合模型的預測效果要優于個體模型.Dong等人[6]分別基于日常場景和促銷場景下,構建基于時間演變的特征,研究用戶品牌的購買預測,發現用戶在促銷場景下的購買更多是沖動性的,而日常場景下的購買則受用戶歷史行為活動的影響.隨著神經網絡和深度學習的發展,胡曉麗等人[7]提出了一種基于CNN-LSTM的用戶購買行為預測模型,不再人工構建大量的特征,通過神經網絡的方法實現用戶和商品特征之間的交互,模型最終的F1值要比基準模型平均提高7%-11%.
用戶購買預測問題可以被描述為一個典型的分類問題,模型訓練和其它分類任務差不多,特征工程才是機器學習項目成功的關鍵,是數據科學不可分割的一部分.特征工程的工作往往比較困難,因為它屬于特定的領域,而機器學習算法在很大程度上是通用的.特征工程中存在很多的嘗試和試錯,機器學習項目的大部分工作通常都是在這方面進行的.雖然各大研究團隊已經提出了很多的分類算法,但在電子商務中預測任務的特征工程方面的文獻并不多.本文在特征工程方面花費了大量的時間,分別從用戶、商品、品類和品牌多個角度構建了大量特征.我們將描述如何從用戶行為數據中生成各種類型的特征,進行特征選擇[8,9],并通過實驗驗證了這些特征的重要性.數據挖掘技術通常是在某一數據集上訓練出一個學習器,再對測試數據做出預測,得到一個準確的結果.研究表明,個體學習器的訓練效果往往不盡人意.一般而言,為了是模型有更好的預測效果,研究人員通常會通過多次訓練來逐步擬合目標值.在數據挖掘技術中,集成學習是一種提高模型預測準確率的有效策略,集成學習通過訓練多個弱學習器,根據一定的規則對結果做出預測,從而提高整個模型的泛化能力.本文在模型搭建方面,主要選擇了集成學習模型中比較有代表性的XGBoost模型[10]和CatBoost模型[11],以及邏輯回歸模型作為基分類器,再以基分類器的輸出作為融合模型的輸入特征,從而實現用戶對商品的購買預測.選擇一個合適的融合方法可以提升由弱分類器組成的融合模型的魯棒性和泛化能力.也有部分學者在融合方法領域做出研究,Tumer等人[12]提出了一種自適應投票聚類集成算法,實驗結果證明該方法不僅適用于無噪聲環境,在有噪聲環境中也非常有效.Peng等人[13]使用投票法對訓練的基分類器融合,得出最后的預測結果,準確率要比個體分類器高出12%.
2 用戶基于目標品類下商品的購買預測模型
2.1 問題場景描述
用戶購買預測是電子商務推薦系統的一個主要分支[14],目的是預測用戶在未來的某段時間內是否會購買某種商品.電商平臺往往擁有海量的用戶歷史消費數據和商品數據,通過數據挖掘的方法從海量數據中發現用戶潛在的興趣愛好,預測出用戶未來的購買意向,將很大的提高平臺的交易成功率.圖1表示的是京東商城3月份不同評論數商品的用戶購買數統計,圖中可以看出大部分用戶更加傾向于購買評論數多的商品,用戶可以從多條評論中了解商品的好壞,說明用戶的購買意向可能和商品評論數有一定的正相關性.同時也可以從用戶的一些歷史操作行為(如關注、加入購物車等)去分析出用戶的潛在消費習慣.因此,通過以上分析,可以從已有的用戶數據和商品數據中構建出相關特征,構建訓練集和測試集,再對用戶在未來5天內基于目標品類下的商品做出購買預測.
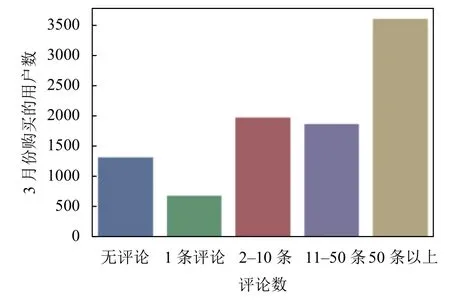
圖1 3月份用戶購買數和商品評論數的關系
2.2 特征工程
原始數據通常具有很大的噪聲,存在各種缺失值和異常值,并且用戶信息和商品信息相對比較獨立,數據交互比較分散,能用于預測的特征比較少.因此,首先必須要對原始數據做一定的去噪處理和數據探索性分析,發現數據的分布規律以及數據屬性之間相似性,再通過特征工程從原始特征中提取出一組有對任務預測有促進作用的特征,對機器學習預測模型往往能起到決定性的作用.
本文基于對統計分析知識和電商業務的掌握和了解,主要從5個方面來構建新的特征,用于模型的訓練.圖2是基于原始數據的特征交互圖.
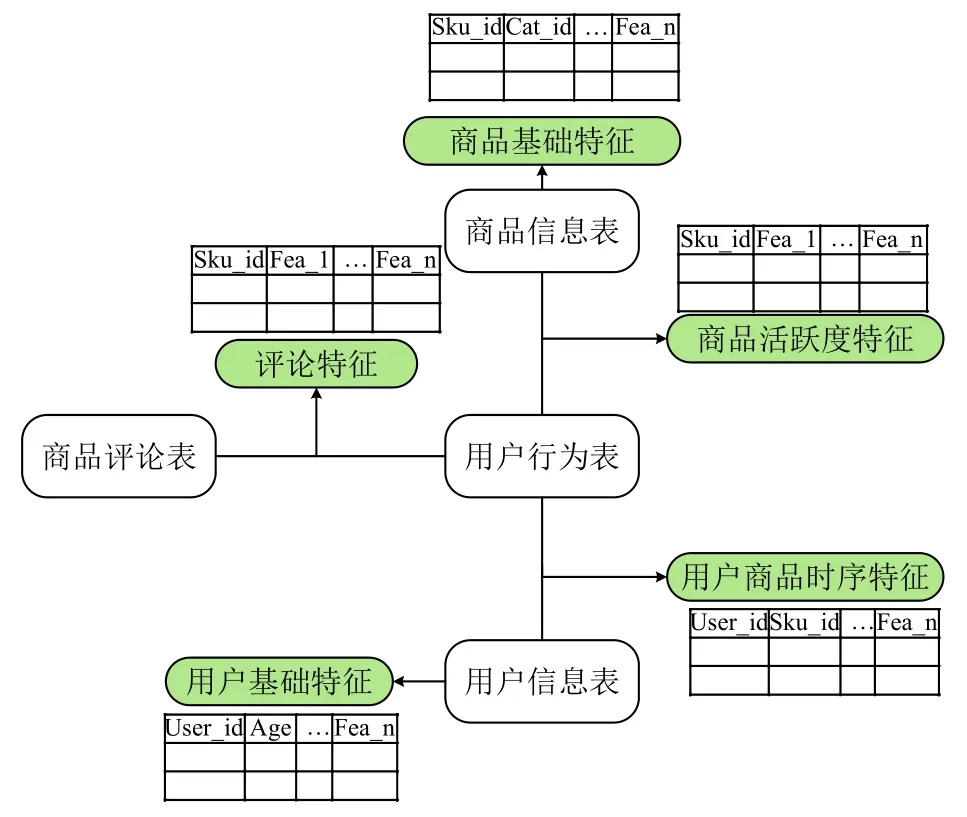
圖2 特征交互圖
構建的主要5類特征如下:
1)用戶基礎特征
描述用戶個人信息,主要包含用戶年齡、用戶等級(會員等級)、用戶性別等; 分析發現用戶的年齡和性別可能會影響用戶對目標商品的購買.例如,某種商品的用戶年齡段在30-40歲左右,20歲的用戶的購買意愿可能較低.除此之外,用戶的會員等級也反映著用戶的一些購買習慣,高等級會員可能更偏向于消費一些奢侈用品.
2)商品基礎特征
用于描述商品的基本信息,包含商品的品牌、品類等特征.同一個商品可能屬于不同的品牌,有些用戶由于自己的興趣愛好可能只會選擇其中的一個品牌,或者從不同的角度去考慮這多個品牌,再做出選擇.
3)用戶-商品的時序行為特征
表示用戶在某段時間內對商品和品類的行為特征統計,一定程度上反映了用戶近期是否會對商品進行購買.時間窗口可以選擇距離用戶是否購買商品的預測日的前7天、15天和1個月這3個時間段,對每個用戶,統計出其在某個時間窗口內對商品或者品類的行為(點擊,加入購物車,購買和關注)次數,再計算出用戶基于特定行為的購買轉化率,作為預測模型的特征.假設用戶ui在時間窗口T內的點擊次數為Ni,購買次數為Mi,則用戶ui基于時間窗口T的點擊購買轉化率為Ni/Mi.
4)商品(品類或者品牌)活躍度特征
描述商品、品類或品牌在某段時間內的受歡迎程度,商品越受歡迎,表示用戶越可能購買該產品或品類下的商品.基于3)中設定的時間窗口,對每一個商品(品類或品牌),統計出其在某個時間窗口內關注(購買、加入購物車)過該商品(品類或品牌)的不同用戶的數量,該值越大,表明商品的客戶群大,被大量不同用戶喜歡,用戶購買它的概率也越大.此外統計購買商品的不同年齡段用戶的總數,用以區分商品在不同年齡段的用戶群體的受歡迎程度.同時,我們發現一些品牌具有特定的目標用戶,這將影響不同用戶的購買,本文通過計算購買過某品牌的用戶的平均年齡和平均性別,以代表在此期間訪問過該品牌的所有用戶的這些特征.
5)評論特征
描述用戶對購買商品的評價,商品的評價是用戶在購買商品前的一個參照依據.包含商品在某個時間點的累積評論數、商品的差評率、以及有無差評等特征.對商品差評率進行分箱處理,把連續型特征轉化為類別特征.
表1是特征工程構建的用戶購買行為預測特征.
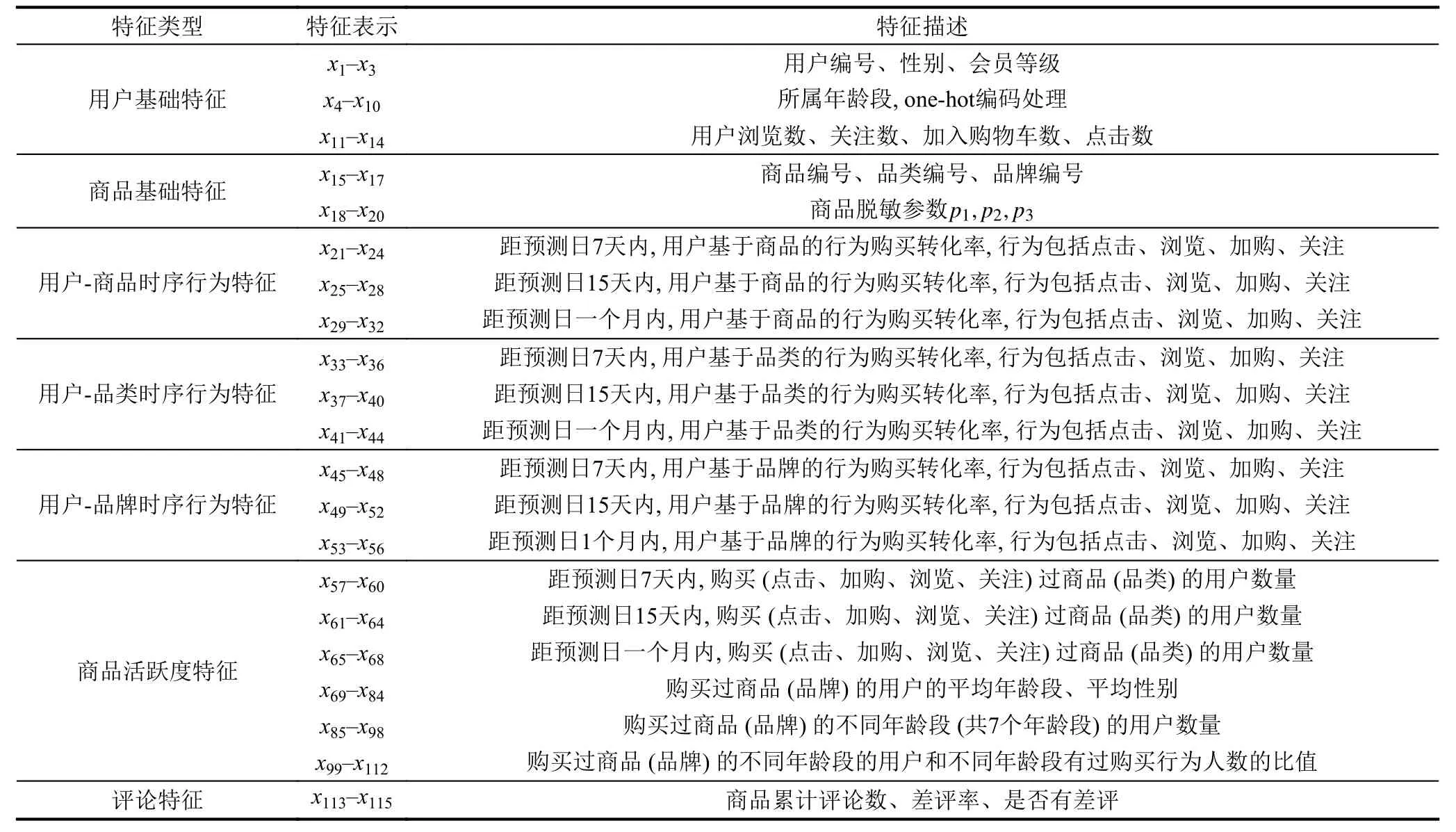
表1 構建的特征表示和特征表述
2.3 集成學習算法模型
圖3所示是本文預測模型的整體結構圖,表1中基于原始數據生成的新特征作為基預測模型的輸入,基預測模型采用XGBoost、CatBoost和邏輯回歸,對于XGBoost模型,選取表1中特征的兩個不同的特征子集分別訓練XGBoost模型,得到兩個不同的XGBoost模型,基預測模型的訓練采用10折分層交叉驗證的方法,把數據分成5份,即train1-train10,單個模型的每次都把9份分好的數據集作為訓練,1份用于評估模型的性能,重復10次以上操作,確保每份數據都預測一遍,對測試數據test而言,10個模型分別對其做出預測,最終對結果取均值.個體模型的訓練過程采用網格搜索的方法選取最佳參數.為進一步提高性能,本文使用集成技術對上述個體預測模型的結果做一定的處理,即采用加權平均的方法得出最終的預測結果,融合模型定義如下:
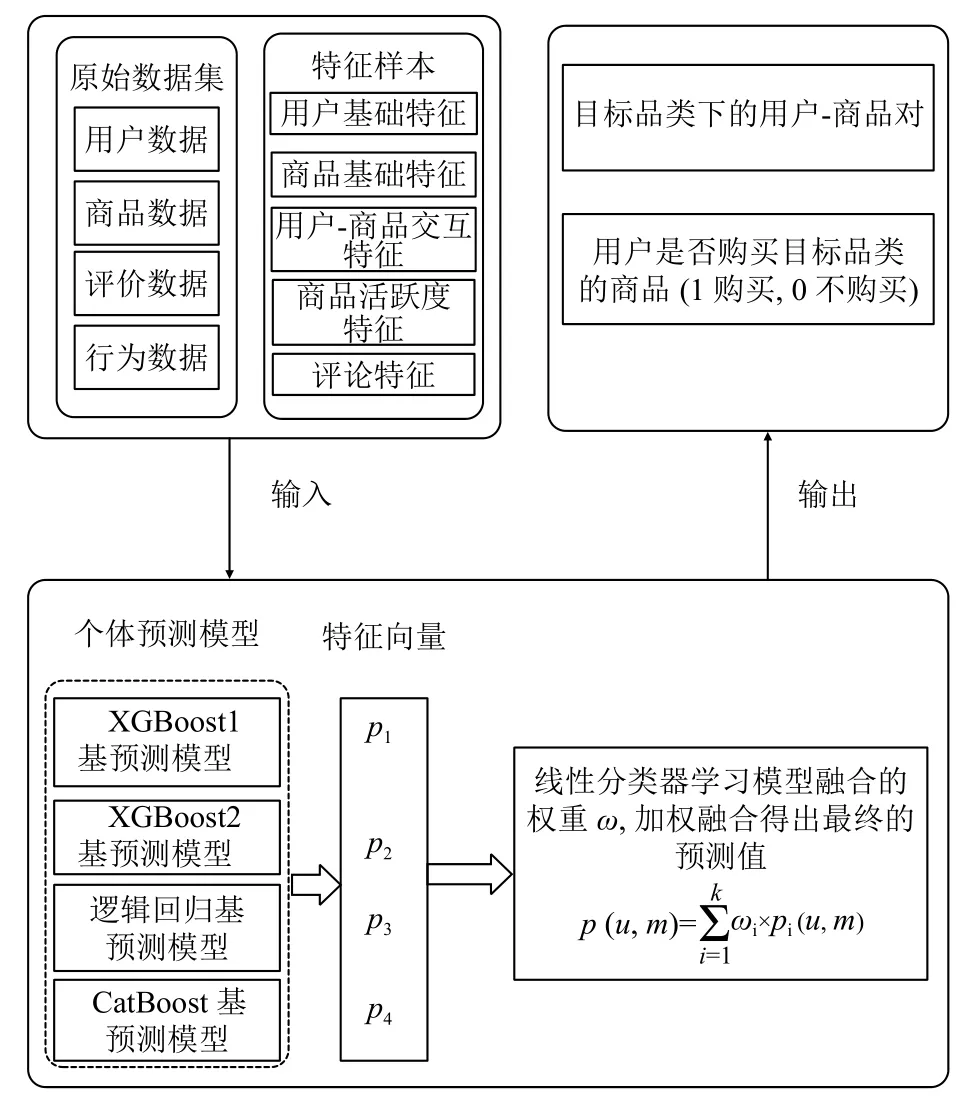
圖3 融合模型整體框架
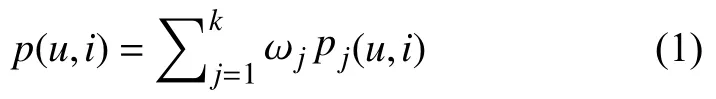
其中,u表示用戶,i表示商品,p(u,i)表示用戶u在未來5天內購買商品i的最終概率,j表示基預測模型的個數,pj表示第j個基預測模型的預測結果,ωj指的是分配給第j個基預測模型的權重.對于權重ω,采用構建線性分類器的方法學習權重,給每一對用戶-商品對(u,i)生成一個k維特征向量,第j維表示第j個基預測模型生成的概率pj(u,i),該k維特征向量作為線性模型的輸入,學習出最終融合模型的權重.
模型融合采用線性分類器方法學習融合模型的權重,其目的是為了進一步降低基預測模型的預測誤差,提高模型整體的預測準確率.融合模型并沒有采用基于樹模型的分類器或者其它復雜分類器,主要考慮最終預測模型的泛化能力.相比于簡單的線性分類而言,采用復雜模型來實現模型融合的方法更加容易造成過擬合的現象,并且考慮到模型性能的問題,復雜模型的訓練時間也相對要長.在融合模型權重取值方面,通過人工賦值的方法具有很大的隨機性,可能多次嘗試也不一定會有一個良好的結果,隨著基預測模型的數量增多,融合模型權重的選擇會更加多樣和復雜; 而通過采用線性分類器的方法來學習權重,把不同類型的基預測模型的輸出作為線性分類器的輸入,任務的真實值作為輸出,通過梯度下降的方法,最終學習出融合模型的權重,從理論上講,更加科學和有效.
算法的詳細流程如算法1.

3 實驗與分析
3.1 實驗數據
本次實驗的數據集來自京東平臺舉辦的算法大賽“高潛用戶購買意向預測”,包含用戶信息表、商品信息表、商品評價數據表和用戶行為數據表,表2-表5描述了各表格的字段信息.數據集總共包含105 231個用戶,28 710種商品以及442種品牌.用戶行為數據包含2016-02-01到2016-04-15這段時間內用戶對商品的各種行為動作,預測任務是用戶在未來5天內對目標品類cate=8下的商品的購買意向預測.劃分數據集:用2016-02-01到2016-02-29的數據來預測2016-03-01到2016-03-05的購買意向,用2016-02-15到2016-03-14的數據來預測2016-03-15到2016-03-19的購買意向,將這兩部分作為訓練集; 用2016-03-13到2016-04-10的數據預測2016-04-11到2016-04-15的購買意向,該部分數據作為驗證集.

表2 用戶表

表3 商品表

表4 評論數據表

表5 行為數據表
3.2 評估指標
本文采用京東算法比賽給出的F1值作為預測模型的評估指標,F1的定義由式(2)所示,P表示準確率,R表示召回率,準確率表示預測正確的樣本數占總數的比例,召回率表示預測正確的樣本數占總的正確樣本數的比例,該值能綜合考慮準確率和召回率來評估分類模型的性能.

3.3 實驗結果分析
為了比較融合模型和基分類器的預測效果,本文另外訓練了LightGBM[15]和隨機森林兩種算法模型.獲取每個基分類器和融合模型的預測結果,每種算法運行5次,取5次的平均值作為最終比較的參考標準.對比結果如圖4所示,圖中展示了用于融合的4個基分類模型、融合模型以及另外訓練的LightGBM模型和隨機森林的F1評分對比,可以看出個體模型中,CatBoost的效果最佳,F1評分為0.735,要優于其它個體預測模型,表現最差的個體模型為隨機森林.與個體模型相比,本文采用的融合模型的F1評分為0.757,要明顯優于其它個體模型,證明了本文設計的融合模型的有效性.
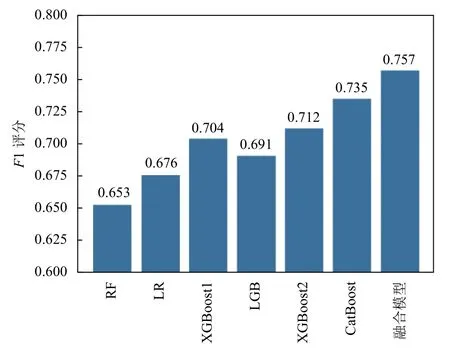
圖4 各模型F1評分對比
基預測模型中,CatBoost和XGBoost模型的預測表現最佳,考慮到兩種模型都是基于boosting的集成算法,由多個回歸樹組合而成.其中,每一個回歸樹的訓練過程都是去擬合上一次迭代的負梯度方向的值,從而最小化損失函數.同時模型能很好的處理輸入特征中的類別特征,并且在訓練過程中能自動生成組合特征并且進行特征選擇,因此選擇CatBoost和XGBoost模型作為融合模型的基預測模型,可以很好的實現用戶購買預測任務.同時,融合模型的好壞往往取決于基預測模型之間的差異性,所以本文把邏輯回歸模型作為一個基預測模型,主要考慮該模型從不同于樹模型的角度去訓練數據,邏輯回歸可以看成對不同的特征賦予不一樣的特征權重,最終學習出一個函數來預測購買的概率.因此本文設計的融合模型可以從不同的角度考慮,得出用戶的購買概率,并且還具有更強的泛化能力和魯棒性.
圖5是基預測模型XGBoost2輸出的特征重要性排名(提取排名前20的特征),其中對模型訓練最有利的前3個特征分別為7天內用戶對品類的加入購物車行為的購買轉化率、7天內用戶對品類的關注購買轉化率和品類在15天內被關注的用戶數,說明了用戶在距離購買預測日的時間間隔越近做出的行為,對用戶最后做出購買選擇的影響越大,其中加入購物車和關注行為最能夠反映用戶對該品類的喜愛程度,并且品類在15天內被關注的用戶數在一定程度上反映了該品類近期的受歡迎程度,該特征重要性排名第三也符合實際生活中,用戶購買商品前會考慮商品品類的受歡迎度再做出選擇.
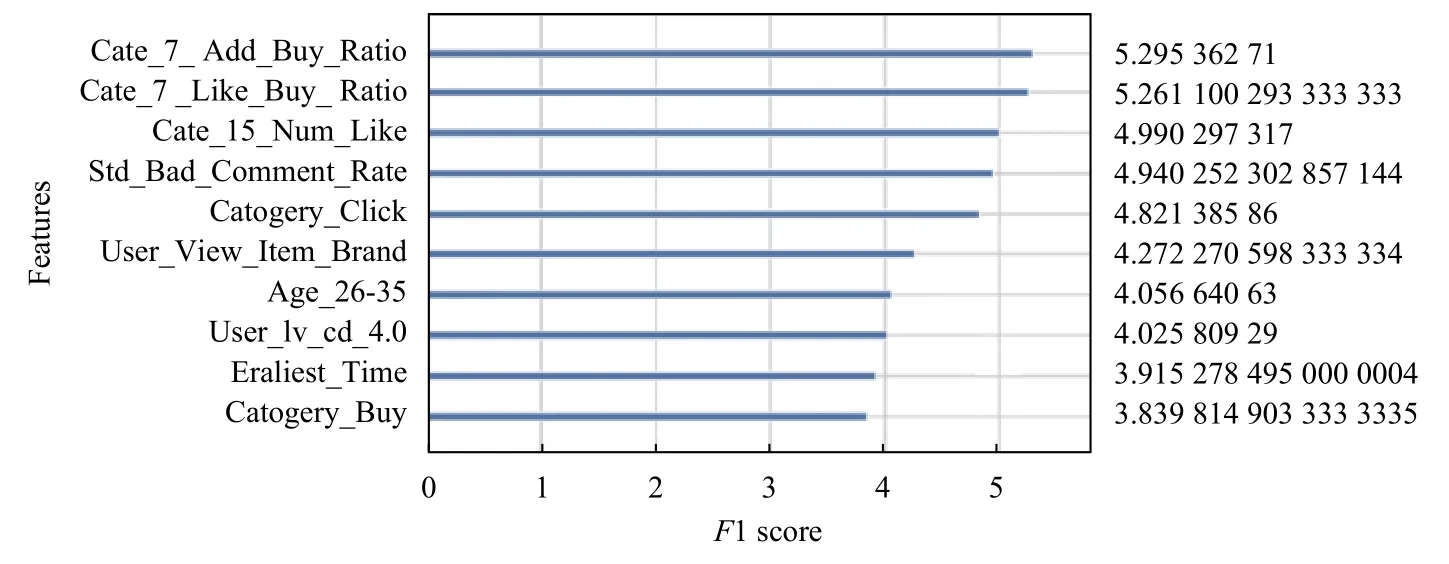
圖5 XGBoost2特征重要性排名
圖6可以看出,融合模型的預測效果總體上要優于其它模型,且5次實驗的結果相對比較穩定.基于個體模型而言,CatBoost和XGBoost這兩個模型的F1評分相對較高,但是缺乏穩定性,隨著實驗次數的增加,模型預測效果波動較大.模型融合的出發點就是最大化個體模型預測的優點,忽略個體模型中的缺點.通過在同一測試集上的實驗結果對比,發現本文設計的融合模型,可以很好地提高任務的預測準確性,同時也解決了個體模型預測不穩定的問題.
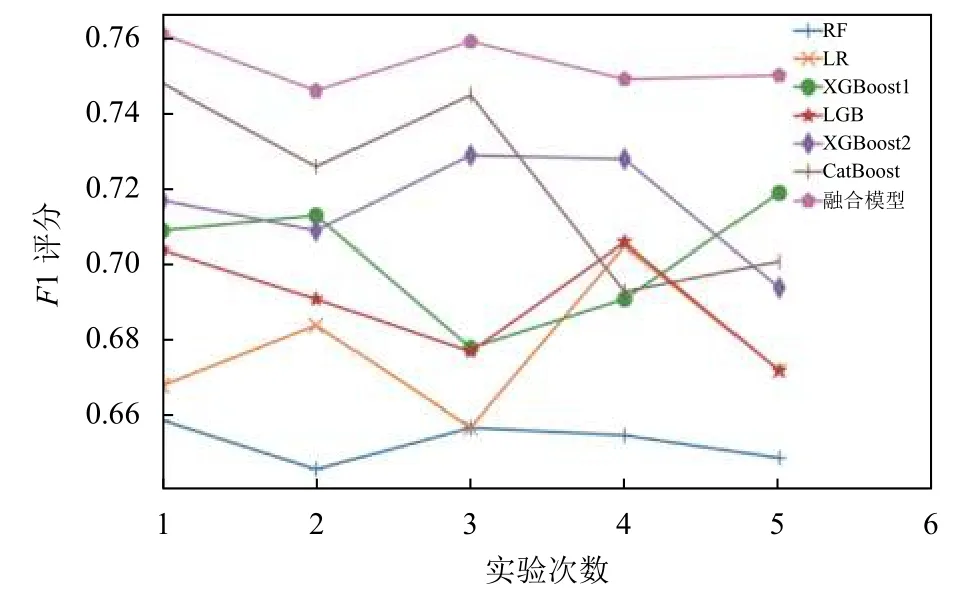
圖6 各模型多次實驗的結果比較
4 總結與展望
本文主要通過生成時間演變特征和設計融合模型進行用戶對商品的購買預測.在特征工程方面,生成了大量的特征來捕捉用戶的偏好和行為,包括商品、品類和品牌的特征以及它們之間的交互,實驗表明在用戶和商品的基本屬性穩定的情況下,用戶的時序行為特征能夠更好的反映用戶的購買意圖,說明了特征工程工作一定程度上提升了模型預測的精度; 在模型的構建方面,本文設計一個基于XGBoost、CatBoost和邏輯回歸的兩層融合模型,第一層通過選取不同的特征子集對個體學習器進行訓練,第二層融合模型通過線性分類器的方法學習出融合模型的權重,再做出最后的預測.從結果看出,本文設計的融合模型的效果要優于其它常用的方法.在未來的學習中,希望能夠從原始數據中挖掘出更多用戶潛在的行為特征,來提高模型的預測效果,同時希望能夠在基預測模型中引入深度學習領域相關算法,通過自動學習特征,對用戶購買做出預測.
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
