人工智能算法在5G套餐潛在用戶識別中的應用
2022-01-19 06:30:56董瑩瑩李坤樹李子旋
江蘇通信 2021年6期
董瑩瑩 葛 陽 李坤樹 李子旋
中國聯合網絡通信有限公司網絡AI中心
0 引言
隨著5G網絡正式在中國商用,大量的5G終端涌進市場,5G終端占有量日益增長,但其中相當一部分5G終端仍然使用的是非5G套餐,精準預測5G套餐潛在用戶對5G業務發展具有重要意義。
本文基于O域信令數據、B域用戶出賬數據、用戶MR位置數據等,先識別出全網的5G終端,然后對半年內5G終端非5G套餐更換為5G套餐的用戶進行大數據分析,從用戶活躍時長、通話能力、消費能力、終端偏好、網絡滿意度等方面做特征工程,然后搭建LightGBM分類預測模型,精準預測5G套餐潛在用戶更換套餐的概率,將高概率更換套餐的用戶清單支撐市場部門進行精準營銷,助力5G業務發展。
1 5G終端概況
1.1 5G終端識別
不同網絡類型的網絡DPI信令數據采集接口不同,在具體的終端識別過程中,可以通過用戶終端話單的最高接入網類型接口來判斷用戶終端類型。2/3/4/5G接入網接口范圍可以通過《中國聯通移動網絡DPI信令采集設備技術規范》進行查看,DPI采集系統在網絡中的位置示意圖如圖1所示。
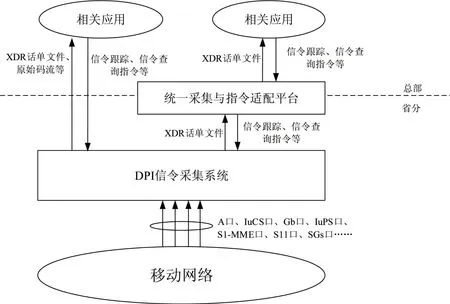
圖1 DPI采集系統在網絡中的位置示意圖
本文首先在4/5G信令數據中,識別出最高接入網類型為5G的終端,并結合存量的5G終端庫,不斷補充與修正5G終端配置庫;然后基于已識別的5G終端篩選出未開通5G套餐的用戶,作為本文的數據采樣基礎。
1.2 5G終端分析
目前運營商各種類型終端的占比如圖2所示。
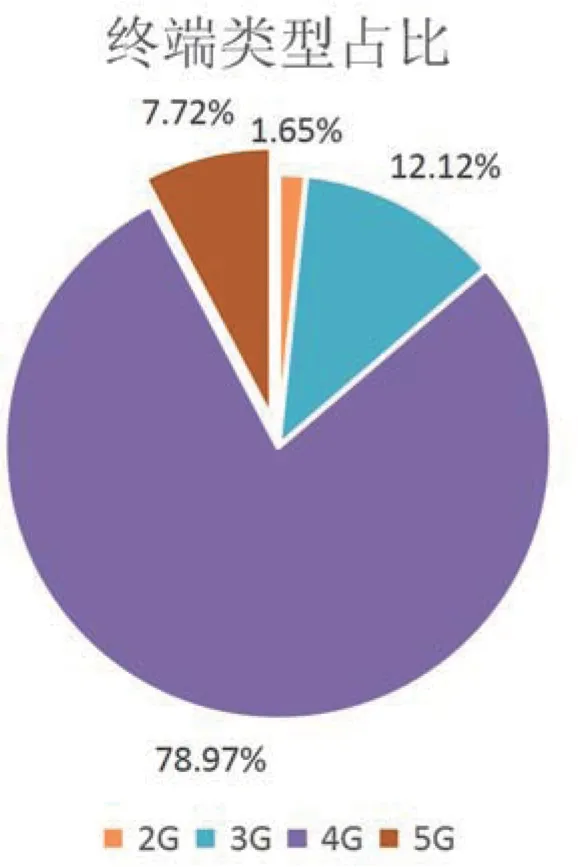
圖2 運營商中各網絡類型終端占比
從圖2中可以發現,目前運營商提供服務的終端中絕大部分依然是4G終端。5G終端的占比甚至不到10%,依然有很大提高的空間。除此之外,圖3展示了2021年4月至2021年5月5G終端變化和5G終端非5G套餐用戶數占比的變化。
從圖3中可以發現,5G終端數量在不斷增長。然而,有大量的5G終端用戶并沒有在運營商開通5G套餐,這體現出5G套餐的用戶滲透率較低。為了提升用戶的使用體驗和運營商的盈利能力,在5G終端非5G套餐用戶中篩選出潛在的5G套餐用戶將成為運營商需要迫切建立的能力之一。為此,本文將人工智能算法引入5G潛在用過戶的識別過程。
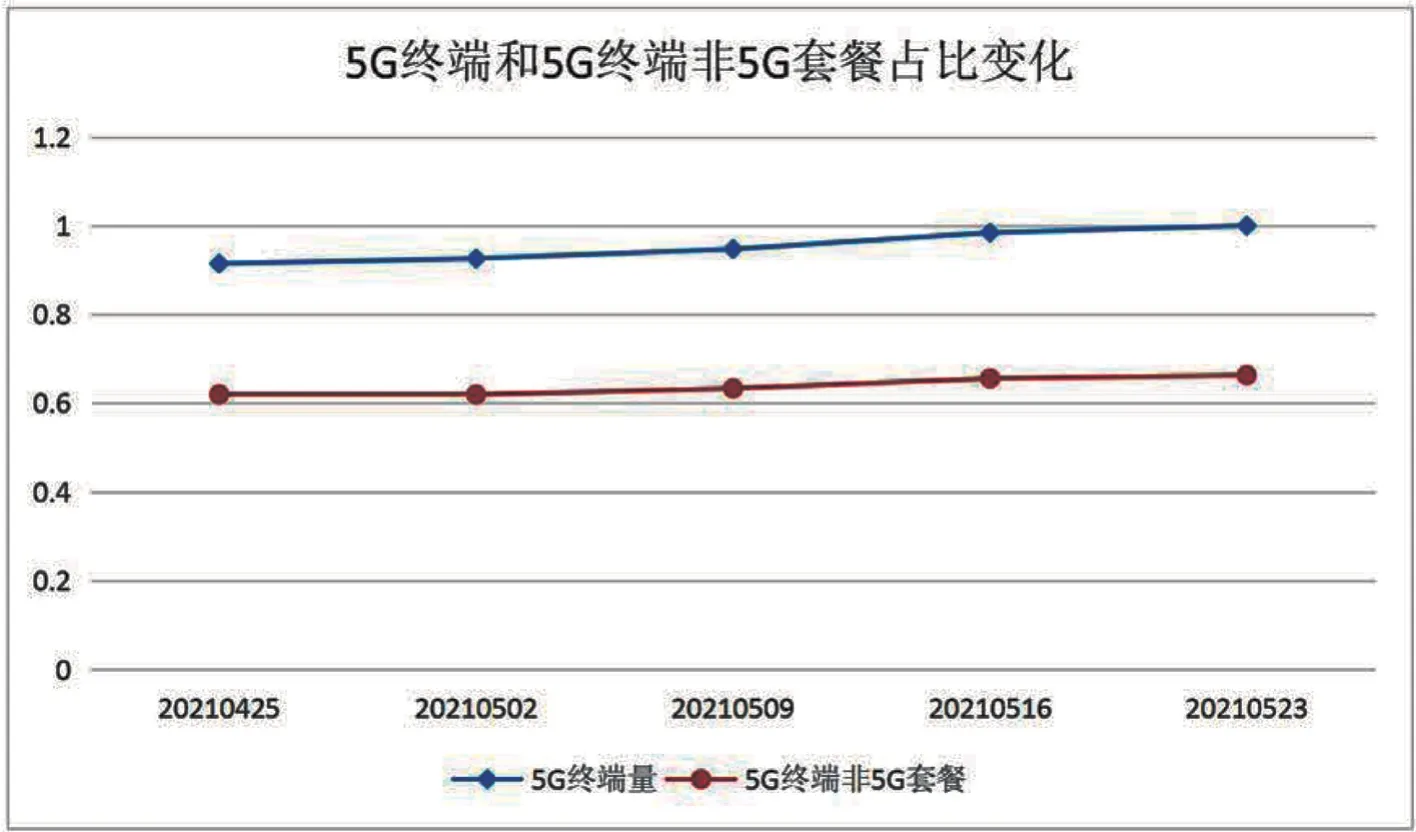
圖3 5G終端和5G終端非5G套餐用戶數占比
2 5G套餐潛在用戶識別建模
2.1 數據集生成
2.1.1 獲取數據
信令數據存儲在分布式hadoop集群上,首先在hive數據庫篩選近6個月的數據(5G終端非5G套餐用戶)作為模型的采樣數據。選取的特征主要包含用戶的網絡粘性(在網時長、離網時長等),終端屬性(終端廠商、終端型號、上市日期、終端制式、價位等),通訊能力(主叫時長、主叫次數、被叫時長、被叫次數等),漫游屬性(國漫次數、省漫次數等),位置信息(早忙時常小區、晚忙時常駐小區等),消費能力(出賬、ARPU、流量、業務訂購等),基本屬性(號碼、套餐、年齡、性別、網齡、發展渠道、用戶群等),基于以上用戶屬性信息數據,通過初步的數據清洗、特征工程得到初步的樣本數據,共計90+字段屬性。
2.1.2 篩選正反例
在上述樣本數據中,篩選本年內已經更換為5G套餐的用戶作為模型的正例樣本數據,設置標簽label=1。其余未更換5G套餐的用戶作為模型反例,設置標簽label=0。這樣,正反例的選取工作就完成了。
2.1.3 生成訓練集與測試集
對于均衡樣本來說,可以從全量數據集中按照比例隨機抽取樣本,將數據集切分成訓練集與測試集,但實際生產環境中,往往實際的正負樣本是失衡的,這時就要在采樣方法上多做一些嘗試,才能使模型達到較好的效果,下面介紹幾種失衡樣本的抽樣方法。
(1)過采樣類
①隨機過采樣。它是從樣本少的類別中隨機抽樣,再將抽樣得來的樣本添加到數據集中,從而達到類別平衡的目的,這種方法操作簡單,少量樣本被重復選取,無形中加大少量樣本的權重,但這樣容易出現過擬合的情況。本文嘗試了這種方法,效果提升不明顯。
②SMOTE過采樣。其思想就是在少數類的樣本之間,進行插值操作來產生額外的樣本。它以每個樣本點的k個最近鄰樣本點為依據,隨機的選擇N個鄰近點進行差值乘上一個[0,1]范圍的閾值,從而達到合成數據的目的。該算法的核心是假設特征空間上鄰近的點其特征都是相似的。它并不是在數據空間上進行采樣,而是在特征空間中進行采樣,因此它的準確率會高于傳統的采樣方式。本文使用SMOTE過采樣方法對少量的正例樣本進行采樣,將正反例比例由1:12提升至1:3,大大提升了模型預測效果。
③Border-Line SMOTE過采樣。這個算法一開始會先將少數類樣本分成3類,分別是DANGER:超過一半的k近鄰樣本屬于多數類;SAFE:超過一半的k近鄰樣本屬于少數類;NOISE:所有的k近鄰個樣本都屬于多數類。而Border-line SMOTE算法只會在“DANGER”狀態的少數類樣本中去隨機選擇,然后利用SMOTE算法產生新樣本。該方法是SMOTE采樣方法的一個改進算法,在不均衡樣本處理方面具有事半功倍的效果。
(2)欠采樣類
①隨機欠采樣。隨機從多數類中刪除一些樣本,該方法的缺失也很明顯,那就是造成部分信息丟失,對模型的分類提升效果不理想。
②EasyEnsemble欠采樣。將多數類樣本隨機劃分成n份,每份的數據等于少數類樣本的數量,然后對這n份數據分別訓練模型,最后集成模型結果。
③BalanceCascade欠采樣。這類算法采用了有監督結合boosting的方式,在每一輪中,也是從多數類中抽取子集與少數類結合起來訓練模型,然后下一輪中丟棄此輪被正確分類的樣本,使得后續的基學習器能夠更加關注那些被分類錯誤的樣本。
在數據采樣階段,可以嘗試過采樣與欠采樣結合的方法,調整正反例數據比例,生成相對均衡的正負樣本,提升模型分類預測效果。
2.2 數據清洗
2.2.1 空值處理
本文用到的控制處理方法有:(1)直接刪除特征;(2)使用指定數據值填充缺失值,如零值、均值、眾數或中位數等填充。針對缺失率超過80%的指標特征,直接進行刪除。對于像用戶年齡、網齡、終端價格等。數值類的數據,通過均值來填充;針對用戶的通訊能力、網絡粘性相關的特征,直接使用零。
2.2.2 異常值處理
本文使用的異常值處理方法主要有:(1)直接刪除異常數據記錄;(2)使用零值或均值替換異常數據。針對用戶年齡小于0或大于100的數值,這樣的樣本數據較少,均采用均值替換;對于在枚舉值之外的類別字段異常值,直接刪除對應的記錄。
2.2.3 文本數據處理
對于文本類型的數據,本文有以下三種處理方法:(1)利用one-hot encoding處理字段;(2)使用label encoding處理字段;(3)將字段標注成類別特征直接進行模型訓練。一般地,針對舉值較少的字段運用one-hot encoding處理,如套餐的top6、終端品牌等;枚舉值較多的字段,本文會使用label encoding方法處理,如省份、地市等。
2.3 特征工程
在正反例篩選之后,進一步對數據做特征工程,主要是數據降維,本文用到的數據降維方法主要有下面兩種。
2.3.1 主成分分析
PCA是最常用的無監督線性降維方法,它的目標是通過某種線性投影,將高維的數據映射到低維的空間中,并期望在所投影的維度上數據的方差最大,以此降低數據維度。
設樣本為m行n維的數據,PCA的一般步驟如下:
(1)將原始數據按列組成n行m列的矩陣X;
(2)計算矩陣X中每個特征屬性(n維)的平均向量M(平均值);
(3)將X的每行(代表一個屬性字段)進行零均值化,即減去M;
(4)按照公式C=1/m XXT求出協方差矩陣;
(5)求出協方差矩陣的特征值及對應的特征向量;
(6)將特征向量按對應特征值從大到小按行排列成矩陣,取前k(k<n)行組成基向量;
(7)通過Y=PX計算降維到k維后的樣本特征。
2.3.2 線性判別分析
對于給定的訓練集,設法將樣本投影到一條直線上,使得同類的投影點盡可能接近,異類樣本的投影點盡可能遠離(類內方差最小,類間方差最大);在對新樣本進行分類時,將其投影到這條直線上,再根據投影點的位置來確定新樣本的類別。
其一般步驟是:
(1)計算數據集中每個類別下所有樣本的均值向量;
(2)通過均值向量,計算類間散布矩陣SB和類內散布矩陣式SW;
(3)依據公式;
(4)按照特征值排序,選擇前k個特征向量構成投影矩陣U;
(5)通過的特征值矩陣將所有樣本轉換到新的子空間中。
2.4 模型介紹
2.4.1 模型選擇
本文講述的5G套餐潛在用戶識別模型是一個典型的二分類模型。在模型選擇時,需要綜合考慮模型的調參收斂效率,以及模型的準確率與魯棒性,本論文主要采用是樹模型,分別用LightGBM與隨機森林搭建融合AI模型,將兩個模型的預測結果按照既定權重(專家經驗與試點迭代)樹綜合評判目標用戶的推薦概率。
LightGBM與RandomForest分類算法,都是以決策樹為基學習器,構建n個并行學習器,并結合所有的學習器輸出結果。本課題實際的正反例樣本數據是失衡的,正反例約1:7,且數據量大,樣本數據約為1200萬,考慮到數據集體量大和服務器性能一般的現狀,上述兩個算法對內存的消耗不高,收斂效果也不錯,故采用LightGBM與RandomForest算法模型比較合適。在實現本模型時,本文對樣本集進行了抽樣,對反例進行欠采樣,將訓練集數量控制在500萬,模型維度為90+,針對n_estimator參數設置為[100,500],subsample參數取值設置在[0.7-0.9]等,根據運營商數據特殊的業務場景,對分類算法涉及的若干參數的取值范圍都進行了縮放,此處也是對兩種AI分類算法的一個改進。
2.4.2 參數調優
本文采用網格搜索和隨機搜索的方式進行參數調優。
2.4.3 模型評價
采用F1-score對模型進行評估。相關評價指標定義:TP(True Positive):真 實 為1,預 測 也 為1;FN(False Negative):真實為0,預測為1;FP(False Positive): 真實為1,預測為0;TN(True Negative):真實為0,預測也為0。

最終模型的F1-score為0.82。模型的整體訓練預測示意圖如圖4所示。
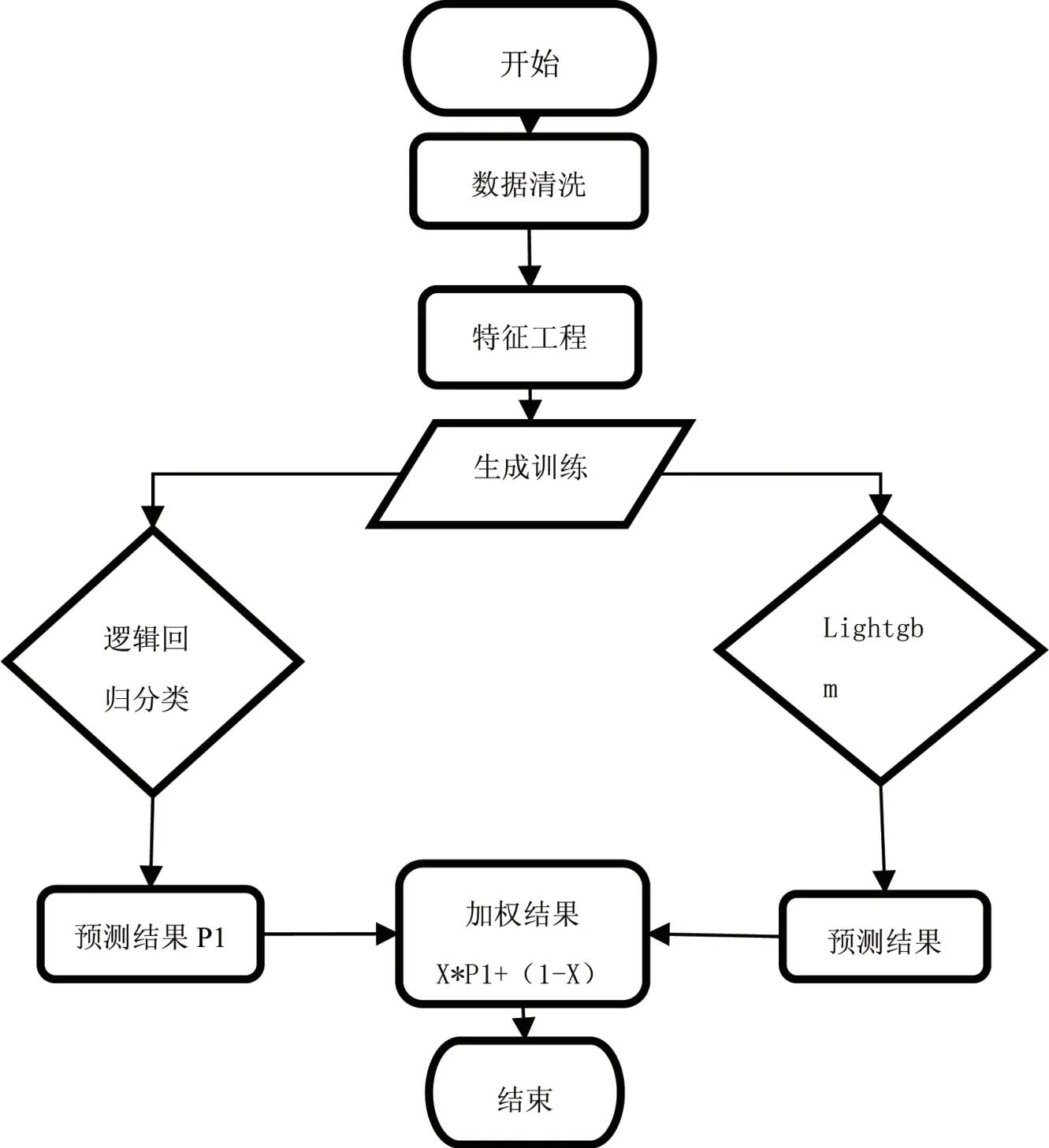
圖4 模型工作示意圖
3 市場應用分析
3.1 應用方案設計
為了驗證模型實際應用效果,本文對模型驗證設計了一套實際應用方案,具體如下:
(1)數據發布。利用訓練好的融合AI模型對全網5G終端非5G套餐的用戶進行預測打標,篩選更換5G套餐概率大于0.7的用戶,再將用戶詳單數據發布至能力開放平臺供各省訂閱。數據開放樣例數據如表1所示。
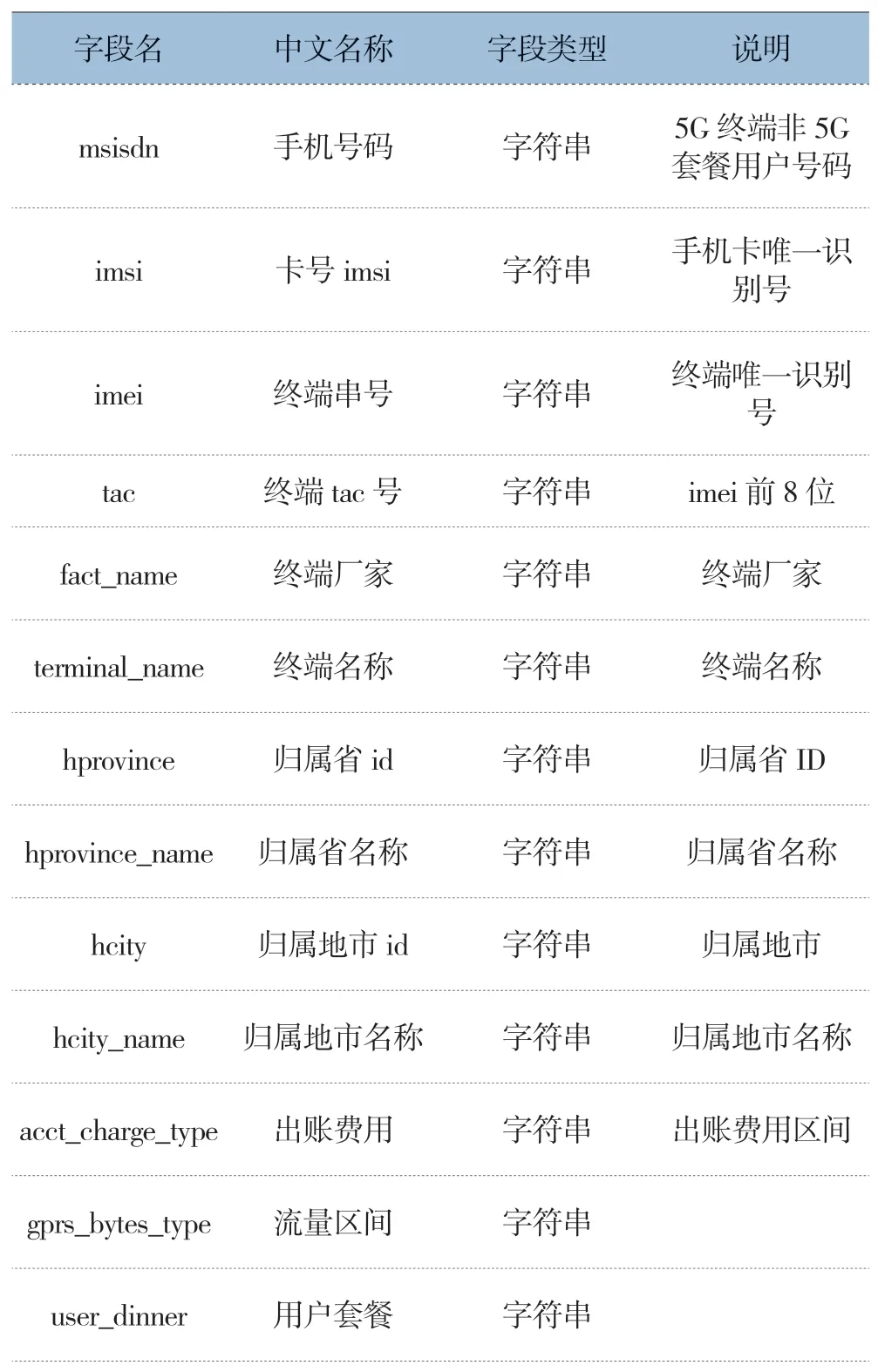
表1 2G終端數據開放樣例

?
(2)省分訂閱目標用戶詳單數據,選定一個省某一地市某一個營業廳A,進行外呼營銷,記錄實際營銷過程中存在的問題。
(3)模型迭代優化。根據試點營業廳A提出的問題進行模型優化迭代。
(4)優化模型驗證。選取其他多個試點營業廳,試點營業廳根據所提供的數據做外呼營銷,測試優化模型效果。
3.2 應用結果分析
第一階段:選取江蘇省某地市營業廳A試點,共提供500戶目標用戶,外呼成功318戶,成功更換5G套餐用戶9戶,外呼成功轉化率2.8%。
第二階段:選取江蘇省某地市4個營業廳進行試點,共提供1000個號碼,接通759戶,成功辦理62戶,成功率8.2%,較第一版本營銷成功率提升5.4個百分點。
4 結束語
本文提出了一種基于信令數據與融合AI算法的5G套餐潛在用戶識別方法,實現了人工智能算法在5G套餐遷轉營銷中的應用,解決了推薦5G套餐目標性差及推薦效率低的問題。在實際的市場應用中展現模型的高精準度,5G套餐推薦轉化率由自然轉化的1%提升至8.4%,實現了人工智能賦能5G套餐業務發展,對提升5G套餐市場占有率有重大意義。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
核科學與工程(2015年4期)2015-09-26 11:59:03
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
