基于置信度時間相關矯正的視頻流目標檢測算法
2022-01-21 10:29:30陳穎焦良葆曹雪虹
現代計算機 2021年33期
陳穎,焦良葆,曹雪虹,
(1.南京郵電大學通信與信息工程學院,南京 210003;2.南京工程學院人工智能產業技術研究院,南京 211167)
0 引言
近年來,多媒體技術迅猛發展,圖像識別技術作為計算機視覺領域中的重要分支,被廣泛應用到航天航空領域、軍事領域、公共安全領域、工農業等相關領域。而伴隨著國家大力發展基礎建設,全國建筑業安全生產理念也逐步進行推廣,為了提高建筑業對施工人員的安全帽佩戴檢測[1]情況,降低由于作業人員沒有佩戴安全帽而造成的事故發生率,將圖像識別技術[3]應用到實時檢查工人是否佩戴安全帽非常重要[2]。本文使用YOLO網絡[4]對施工場所的施工人員是否佩戴安全帽進行檢測,由于會產生漏檢錯檢情況,導致最終結果的不準確。所以本文考慮通過檢測出漏檢錯檢圖片,并對其錯誤檢測數據進行矯正。
1 目標檢測算法
1.1 數據獲取
通過實地施工場所拍攝的視頻,并對數據集進行篩選,選取符合課題的視頻,使用opencv[5]將每個視頻切分成幀圖片,建立目標檢測的訓練集和測試集,包含了背光、逆光、近距離、遠距離、部分遮擋和安全帽種類各異等情況,并將所述數據集劃分為訓練數據集和測試數據集,部分樣本數據如圖1所示。并采用LabelImg標注工具[6]通過對每一張圖像中的目標進行人工標記感興趣區域和類別標注。

圖1 安全帽佩戴樣本圖像
1.2 目標檢測算法
YOLOv3網絡是由Joseph Redmon等[7]提出的一種目標檢測算法。傳統的YOLOv3網絡對視頻流的目標檢測[8]框架如圖2所示。

圖2 傳統視頻流目標檢測模型
YOLOv3的主干網絡Darknet-53通過借鑒Resnet[9]的思想,在網絡中加入了殘差模塊,有利于用于深層網絡的梯度消失和爆炸問題。網絡中沒有使用池化層和全連接層,而是通過改變卷積核的步長來實現特征圖的尺寸變換。
YOLOv3在特征融合[10]方式上通過借鑒FPN的思想,采用上采樣(Up Sampling)和合并(Concatenate)操作來融合三個尺度(13×13、26×26和52×52)的特征圖,在多個尺度的融合特征圖上分別進行獨立檢測,提升小目標的檢測能力。并使用k-means聚類算法[11]獲得YOLOv3中三個檢測尺度的9個anchor值,并輸入到網絡中。
其中基于特征提取網絡構建包含損失函數Logistic的目標檢測模型[12]。采用上述訓練數據集對所述目標檢測模型的損失函數進行迭代訓練,并使用預訓練權重,訓練結束得到所需的權重文件。
檢測過程中會生成檢測數據文件,文件中有預測邊框的坐標與寬高(bx,by,bw,bh)和置信度P0,公式如下:

其中σ(x)=1∕( 1 +e-x),cx,cy代表單元格從左上角的偏移量,pw,ph代表錨框的寬度、高度。
所述目標置信度P0為預測邊界框內存在目標的可能性,其計算公式為:

其中Pr(Object)表示當前網格內是否包含目標的中心點,如果包含,則為1,反之為0;表示網絡的預測邊界框和真實邊界框面積的交并比[13],當P0大于0.5時,表示當前目標框內有目標被檢測出。
2 基于時間相關的置信度矯正模型
2.1 基于時間相關的置信度矯正模型
由于視頻流[14]中的時間相關性,本文提出了基于時間相關的置信度矯正模型,如圖3所示,分別采用一次指數平滑法[15]、簡單移動平均法[16]、加權移動平均法[17]和自適應濾波法[18]四種對沒有明確規律性的時間序列預測方法[19]來建模,進行對比,選取最優模型。

圖3 基于時間相關的置信度矯正模型

圖3 基于時間相關的置信度矯正模型(續)
四種數據處理預測方法以原數據與處理后數據的標準差σ作為評價指標,即處理后數據越接近原數據,則這種方法就越適合預測下一期數據。
首先根據從YOLO網絡輸出的檢測文件,每個輸出信息框所屬圖片的編號ck,該對象的置信度得分pi(0≤pi≤1),輸出信息框的坐標信息xmin、ymin、xmax、ymax,其中每一個輸出信息框的輸出數據為xki=[ck,pi,xmin,ymin,xmax,ymax],依次檢測目標框置信度是否大于等于0.5,對于置信度小于0.5的對象判斷其是否為漏檢目標,根據檢測數據總結出相鄰幀圖片同一目標的目標輸出框坐標差小于20 px,通過該輸出框坐標依次從當前幀向前和向后,相鄰幀之間循環比較,如果在當前幀前后目標都有被正確檢測出,則判斷該目標漏檢。對于置信度大于等于0.5的目標判斷其是否為漏檢目標,將此目標輸出框坐標與前五幀和后五幀圖片的所有目標框進行比較,如果沒有與之相符合的目標框,則判斷為目標錯檢。
以下為使用四種數據處理方法對漏檢、錯檢目標在當前幀前目標被正確檢測出的置信度組合的數組進行處理,原數據與處理后數據的對比結果如表1所示。

表1 四種數據處理方法的σ值對比
通過對比得出,經過一次指數平滑法處理過的數據更接近原數據,所以本文使用此方法矯正漏檢目標置信度和抑制錯檢目標置信度,即采用模型c作為置信度矯正模型。
2.2 基于指數平滑法的置信度矯正
本文采取的指數平滑法為一次指數平滑法,該方法在本文中的建模過程如圖4所示。
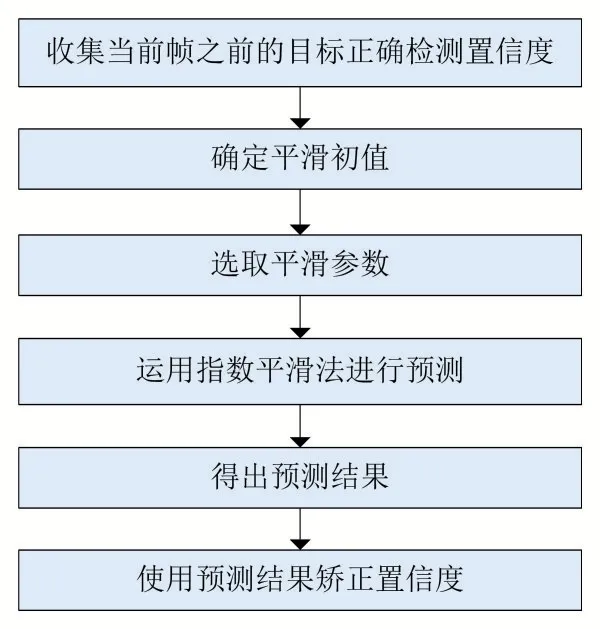
圖4 指數平滑法流程
一次指數平滑法有一個初值,由公式(6)得出。

低于20項n一般取3,大于20項的本文取5。
一次指數平滑需要滯后一期,則一次指數平滑的計算公式為:

本文中x[i]為漏檢、錯檢目標在當前幀前目標被正確檢測出的置信度組合的數組,1≤i≤n。
預測下一期數據:

指數平滑法中最重要的參數是平滑常系數α[16],α的取值范圍是[0,1],α值越大表示對未來的預測中越近期的數據權重越大。α一般是先根據經驗做一個大概的預估,基本判斷標準如下:
(1)時間序列比較平穩時,選擇較小的α值,α在0.05~0.20之間。
(2)時間序列有波動,但長期趨勢沒大的變化,可選稍大的α值,α在0.10~0.40之間。
(3)時間序列波動很大,長期趨勢變化大有明顯的上升或下降趨勢時,宜選較大的α值,α在0.60~0.80之間。
(4)當時間序列是上升或下降序列,滿足加性模型,α取較大值,α在0.60~1之間。
再重復試算過程,比較不同α值下,引入均方誤差σ概念來判斷平滑系數α是否準確:

通過實驗比較得出當α=0.9時,均方誤差最小,由于數據集是由視頻中提取,時間上屬于上升序列,所以較大的α值均方誤差較小。
3 評價指標與實驗結果分析
3.1 評價指標
本文采用對測試樣本計算精度(Precision)和召回率(Recall),引入精度均值(AP)作為評估指標。以Recall為橫軸,Precision為縱軸繪制P-R曲線并對其積分求出曲線下的面積即AP,表達式如下:


式(11)、式(12)中,TP為分類正確的正樣本[20],FP為分類錯誤的負樣本,FN為分類錯誤的正樣本,式(13)中P(r)為P-R曲線函數表達。
3.2 實驗結果與分析
圖5為數據集1中的第171幀圖片,存在檢測目標漏檢,此目標框原始檢測數據為[171,0.256614,49.407391,424.668915,117.287079,537.215149],該漏檢目標在當前幀之前能被正確檢測出的目標置信度為x[i]=[0.999987,0.999990,0.999991,0.999996,0.999950,0.999983,1.000000,1.000000,0.860279,0.999570,0.999864,0.999379,0.999144,0.939832]。通過一次指數平滑法對x[i]中數據進行處理,初值S0=0.999987,α=0.9,再由公式(7)、(8)、(9)預測出下一期數據xn+1為0.940425,即經過置信度矯正后此檢測目標的置信度為0.940425。

圖5 漏檢圖片
圖6為數據集1的第357幀圖片,存在檢測目標錯檢,此目標框檢測數據為[357,0.796121,1699.169800,385.834717,1813.965210,580.458984],該錯檢目標在當前幀之前被正確檢測出的目標置信度為x[i]=[0.823400,0.804521,0.764932,0.853120,0.743512,0.763596,0.782495,0.792402],通過一次指數平滑法對x[i]中數據進行處理,初值S0=0.823400,α=0.9,再由公式(7)、(8)、(9)預測出下一期數據xn+1為0.773921,將此異常置度修改為1-xn+1=0.226079,將錯檢置信度抑制為正常值。

圖6 錯檢圖片
本文基于YOLO網絡+置信度矯正算法與原基于YOLO網絡的檢測結果在多個真實數據集的驗證對比結果如表2,表3所示。

表2 基于YOLO網絡的檢測實驗結果
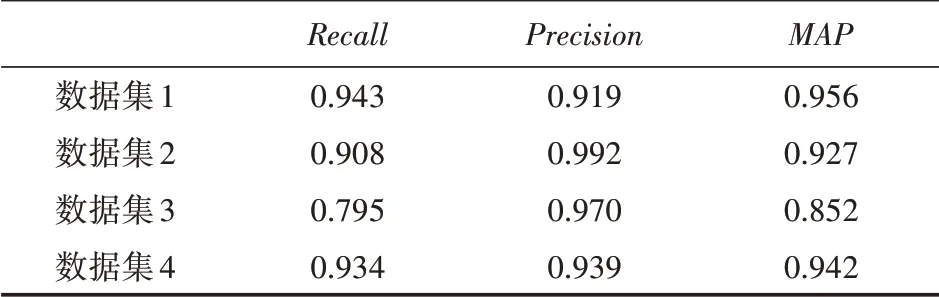
表3 基于YOLO網絡+置信度校正檢測實驗結果
通過以上兩個表格中數據的對比,結果表明本文提出的算法能夠針對異常檢測數據,使用指數平滑法對置信度較低的漏檢目標進行預測矯正;對錯檢數據的置信度進行抑制,從而降低目標檢測漏檢和錯檢率,MAP值平均提高了7.7%。
4 結語
本文使用YOLO網絡對視頻流進行目標檢測,由于光照和角度等環境的不確定因素,在對視頻流進行連續檢測的過程中會出現某一幀漏檢、錯檢或多幀連續漏檢,所以提出一種基于時間相關性的置信度矯正算法對這一情況進行改善,并對多個數據集進行驗證。從實驗結果可以看出,該算法能夠對異常數據進行矯正,對漏檢錯檢情況有很大改善,從而大大地提高了目標檢測的準確性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
