基于多特征融合與CELM的場景分類算法
2022-01-22 07:48:46沈慧芳周樹東
計算機工程與應用 2022年1期
王 光,陶 燕,沈慧芳,周樹東
1.遼寧工程技術大學軟件學院,遼寧 葫蘆島 125000
2.中國科學院海西研究院泉州裝備制造研究所遙感信息工程實驗室,福建 泉州 362000
近幾十年來,隨著遙感技術的快速發展以及數據獲取的成本降低,對遙感圖像的研究逐漸成為遙感領域的熱點之一。遙感圖像的語義解譯在多種應用中扮演著重要角色,如城市規劃、交通控制、土地利用制圖以及災害監測等[1-4]。場景分類的目的是給當前圖像分配對應的語義標簽,是遙感圖像語義解譯的重要手段。因此,如何在圖像中捕捉具有鑒別性的特征并取得精確的圖像分類結果是遙感場景圖像分類亟待解決的難題。
現有的場景分類方法,大多數主要依賴于傳統手工設計的局部特征描述子。其中,基于視覺的詞袋模型(bag-of-visual-words,BoVW)首先提取像素點局部不變特征作為視覺單詞,然后根據視覺單詞出現頻率構建直方圖表示整張圖像[4-5]。雖然該方法在場景分類中取得了一定的效果,但是BoVW模型完全忽略了產生的視覺單詞的位置信息,無法得到圖像之間的相互聯系。因此Lazebnik 等人[6]提出了空間金字塔匹配核(spatial pyramid matching kernel,SPMK),首先將圖像劃分為不同尺度的網格,計算每個尺度上單元格中各個視覺單詞的頻率,以此估計兩幅圖像的相似度。然而,SPMK 模型只能計算兩幅圖像中固定位置之間的聯系,無法體現鄰接單元之間的相關性。Yang 等人[4]提出的空間共現核(spatial co-occurrence kernel,SCK)能夠同時捕捉固定位置和相鄰單元之間的相互聯系。雖然局部特征描述子在場景分類中取得了較好的成果,但由于遙感圖像自身存在的一些特性,如不同語義圖像通常包含相同的對象或者同一語義圖像尺度差異大,傳統的手工設計方法難以獲得魯棒的特征,因此限制了圖像分類的性能。
為了彌補手工制作特征的局限,提出了無監督特征學習的方法,通過模擬圖像中的差異對圖像進行分類。Hu 等人[7]采用線性流形分析技術將原始圖像塊從高維空間映射到低維空間中,然后在流形空間中使用K均值聚類對圖像塊進行編碼。Risojevic等人[8]首先采用四元數特征過濾器進行無監督特征學習,然后基于四元數正交匹配追蹤進行稀疏編碼,該方法能夠捕捉像素顏色與強度之間的內部聯系。Othmana等人[9]采用無監督的方式將初始的卷積特征送入稀疏編碼器對土地利用場景進行分類。無監督的特征學習方法雖然具備捕捉差異信息的能力,但由于缺乏圖像的語義標簽,無法根據識別結果對聚類過程進行改善,因此對圖像分類性能的提升能力有限。
近來,卷積神經網絡以其自主的特征學習能力和強大的特征表示能力在多種任務上取得了重要進展,不僅克服了手工制作特征表達能力單一等缺陷,而且能夠通過訓練過程中的損失函數對模型參數進行優化。Chen等人[10]基于單層的玻爾茲曼機和多層的深度置信網絡分別學習低水平特征和高水平特征,然后使用邏輯回歸分類器對高光譜圖像進行分類。張康等人[11]利用8層深度的網絡結構結合softmax和支持向量機對遙感圖像復雜場景進行分類。Flores 等人[12]采用預訓練的ResNet-50 DCNN模型對特定遙感場景數據中的訓練集進行特征提取,以此得到高斯混合模型的先驗知識,然后用得到的模型對測試集進行分類。雖然深度卷積神經網絡在眾多分類任務中取得了良好的表現,但是大多數網絡精度依賴于網絡的深度或者大量的標簽數據。然而,大量標簽數據集意味著需要耗費更多的人力物力,而且網絡越深,訓練復雜度越高。因此,本文基于遷移學習的思想,選取具備一定圖像理解能力的預訓練卷積神經網絡,采用實驗數據集對其進行特定領域圖像分類的參數微調,實現運用淺層的卷積神經網絡、有限數據集進行準確場景分類的目的。針對單一的預訓練卷積神經網絡提取特征的能力有限,本文融合三種不同結構的預訓練卷積神經網絡實現全方位多尺度的特征提取。
針對直接使用卷積神經網絡架構作為最終的分類器訓練時間長、難度大等問題,研究學者們提出了采用預訓練卷積神經網絡作為特征提取器結合簡單高效的線性分類器的解決方案。其中,支持向量機(support vector machine,SVM)[13]是目前使用最為廣泛的分類器,但其表現能力對參數的選擇比較敏感,而且需要足夠的訓練數據,分類結果無法在兩者之間取得平衡。Huang等人[14]提出了一種基于單隱藏層前饋神經網絡的極限學習機(extreme learning machine,ELM),該方法通過隨機初始化隱藏節點的參數,然后通過計算Moore-Penrose 廣義逆矩陣求解輸出權重,能夠避免一般方法通過反向傳播的迭代求解最優參數的緩慢過程,在一定程度上提高了網絡的訓練速度。基于此類方法,Kannojia等人[15]設計了一種三個并行的卷積神經網絡,分別結合ELM對MNIST數據集進行分類,達到了超高的分類精度。但是ELM 中隱藏節點的參數是隨機初始化的,并且卷積層得到的特征送入隱藏層之前沒有進行任何的正則化操作,因而會導致節點利用率低以及過擬合等問題。為了解決此問題,Zhu等人[16]提出了ELM的改進版本CELM。該方法能夠根據樣本分布初始化隱藏節點的參數,并且對深度卷積特征進行L2 正則化之后送入分類器,不僅保證了模型的訓練速度,而且提升了網絡的泛化能力。本文將在特定數據集上進行精調的CaffeNet、VGG-F、VGG-M 三種預訓練卷積神經網絡作為特征提取器,將提取的三種特征融合后送入CELM分類器,得到最終的遙感圖像語義分類結果。
綜上所述,本文的主要貢獻如下:
(1)利用有限的實驗數據集對在強大的ImageNet數據集上預訓練的卷積神經網絡進行微調,實現了少量數據集的高分類性能;
(2)融合CaffeNet、VGG-F、VGG-M 三種不同的網絡框架提取到的全方位多尺度特征,加強了圖像的特征理解能力;
(3)引入了具有良好泛化能力的CELM 分類器,實現了高效的分類性能和快速的訓練速度。
1 實驗數據與預處理
本文采用由武漢大學發布的SIRI-WHU 和WHURS19 RGB3 通道遙感影像數據集以及由UC-Merced計算機視覺實驗室發布的UC-Merced高分辨率遙感影像數據集作為實驗數據集。其中,SIRI-WHU 數據集含有12 類土地場景,每類場景含有200 張圖像,總計2 400 張圖像,圖像像素大小為200×200,空間分辨率為2 m;WHU-RS19數據集涵蓋19類土地場景,每類場景中包含50~61 張圖像,每類圖像的具體數據如表1所示,共計1 005 張圖像,圖像像素大小為600×600;UC-Merced 數據集包含21 類土地場景,每類場景包含100 張圖像,共計2 100 張圖像,圖像像素大小為256×256,空間分辨率為1 英尺。圖1~圖3 分別顯示了UCMerced、SIRI-WHU 與WHU-RS19 數據集中不同類別的圖像樣本。

圖1 UC-Merced樣本Fig.1 Samples of UC-Merced

圖2 SIRI-WHU樣本Fig.2 Samples of SIRI-WHU

圖3 WHU-RS19樣本Fig.3 Samples of WHU-RS19
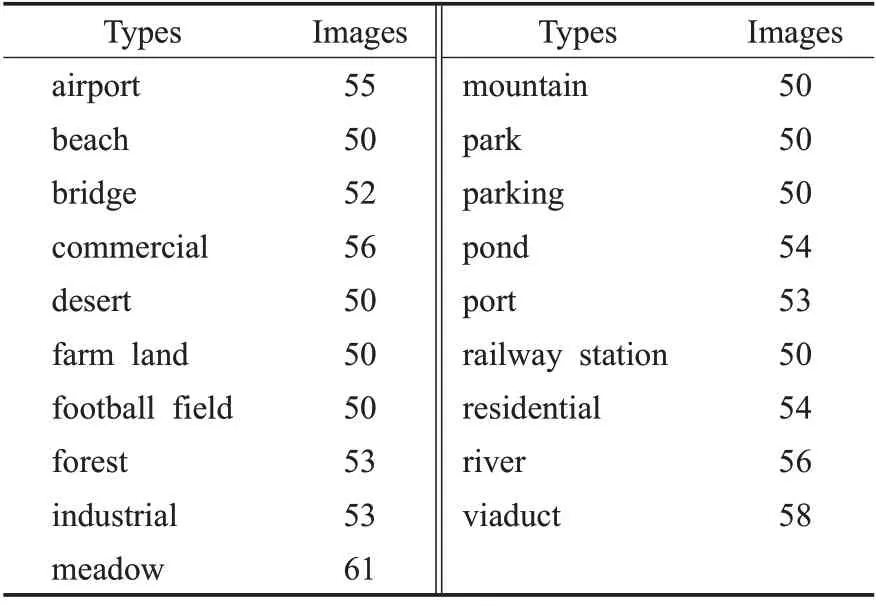
表1 WHU-RS19數據集樣本分布Table 1 Sample distribution of WHU-RS19 dataset
CaffeNet、VGG-F 與VGG-M 三種卷積神經網絡接收的是固定像素大小的圖像輸入,因此實驗數據集的圖像在進入網絡之前,需要將對應的圖像規則化為統一規格。對于CaffeNet 網絡,輸入像素大小為227×227;VGG-F 與VGG-M 網絡的輸入像素大小為224×224。文章采用縮放的方式對圖像進行預處理,規則化輸入圖像。
2 研究方法
本文提出了一種結合多特征融合與CELM 的方法對遙感圖像進行場景分類。網絡的輸入為3 通道RGB圖像,首先利用SIRI-WHU 數據集對3 種不同的預訓練卷積神經網絡進行參數微調;接著將圖像送入微調后的網絡并對提取到的3種特征進行融合;最終送入CELM分類器,網絡的輸出為對應圖像在不同語義標簽上的類別分數。網絡的總體結構設計如圖4所示。
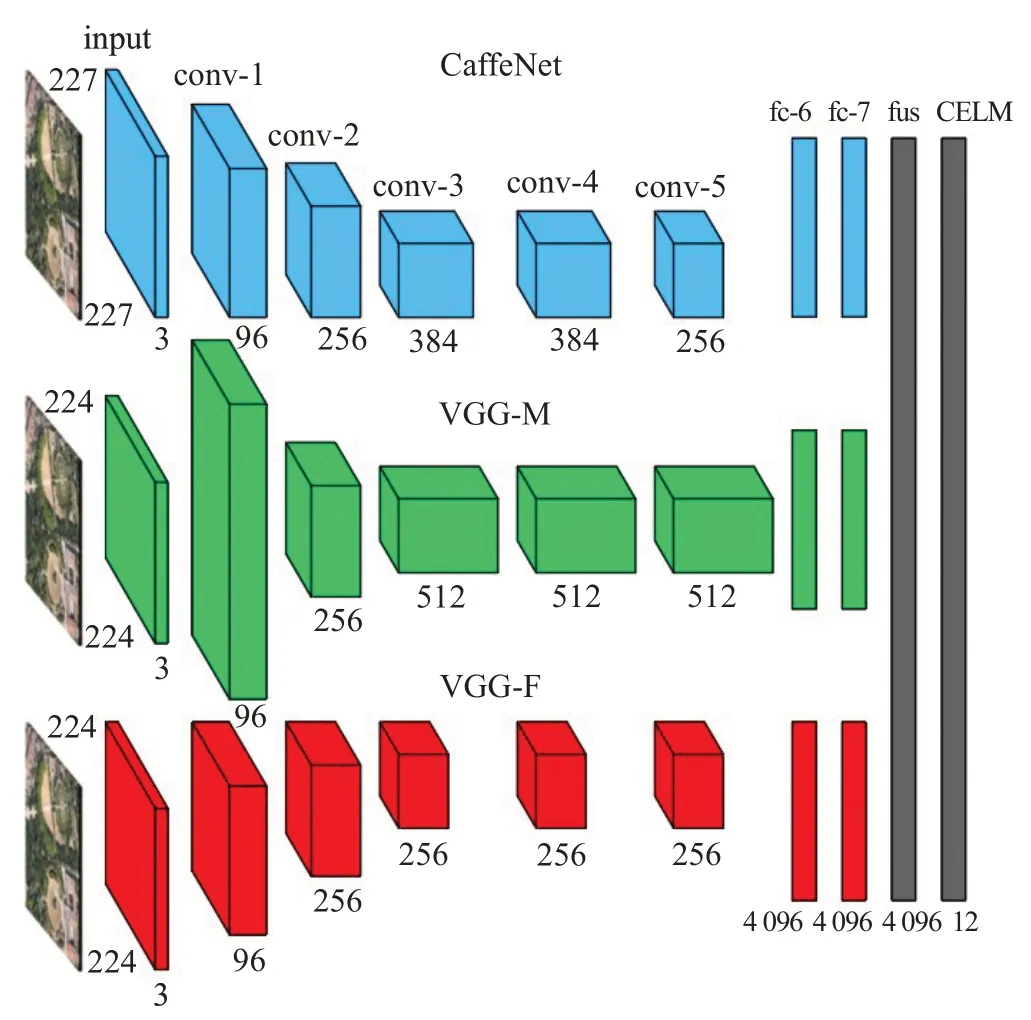
圖4 網絡的總體結構模型Fig.4 Structure model of proposed network
2.1 預訓練CNN參數微調
場景圖像不同于單一的對象圖像,通常具有類間差異小、類內差異大等特征,分類難度較高。在ImageNet數據集上進行預訓練的CaffeNet、VGG-F 與VGG-M 模型雖然已經具備強大的圖像理解能力,但是針對于更加復雜的場景分類,仍有提升的空間。因此,采用一定的遙感場景訓練樣本對3種網絡進行參數微調,優化特征提取性能。因為3種網絡均由5個卷積模塊和3個全連接層組成,最后采用softmax 分類器得到最終類別概率。3 種網絡參數的調整方法基本相同,此處僅對VGG-F模型的參數調整過程進行闡述。

最后采用交叉熵的方式計算網絡的損失函數,并根據隨機梯度下降的方法最小化損失函數對預訓練網絡進行微調,求解最優的網絡參數θ*。
2.2 多特征融合
預訓練的CaffeNet、VGG-F與VGG-M模型中分別有5個卷積模塊,每個模塊中卷積層的核大小與核數量不同,具體參數如表2所示。可以得出,CaffeNet與VGG-F的每層卷積核的大小相同,因此感受野相同,但由于卷積核內參數以及卷積核的數量不同,因此能夠捕捉到圖像中相同尺度下的不同特征;VGG-M 的卷積核大小略小于其他兩個網絡,因此對圖像中的細節信息的鑒別能力更強;并且由于模型的輸入圖像規格不同,因此相同大小的卷積核捕捉到的圖像感受野也有所不同。對3種網絡的特征進行融合,最終實現全方位多尺度的特征提取。

表2 模型的卷積核概況Table 2 Convolution kernel overview of model
預訓練的CaffeNet、VGG-F 與VGG-M 模型在經過特定領域數據集的參數調優之后,舍棄最后一層全連接層與softmax層以及對應的參數。gC(Xi;θC)、gF(Xi;θF)和gM(Xi;θM)分別表示樣本Xi在CaffeNet、VGG-F 與VGG-M 最后一層提取到的特征表示。隨后,將3 個特征向量以元素相加的方式送入融合層,得到全方位多尺度的融合特征:f([gC(Xi;θC),gF(Xi;θF),gM(Xi;θM)])。
2.3 CELM分類器
將提取到的融合特征送入CELM 分類器得到最終樣本標簽。CELM 是一種基于單隱藏層的前饋神經網絡的學習分類器,能夠通過學習不同類別樣本間的差異來初始化輸入權重和偏置,根據最小二乘法求解分類器的輸出權重。分類器模型的結構如圖5所示,其中f為樣本的融合特征,m為類別個數。
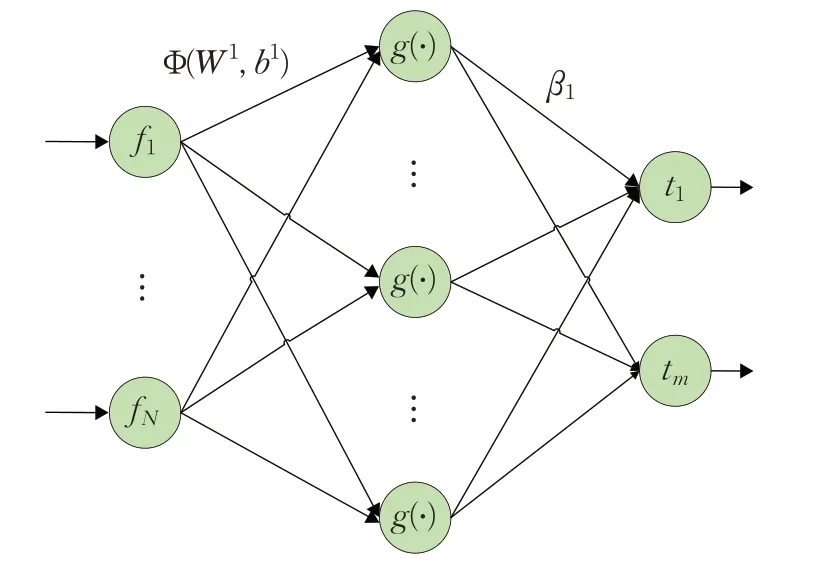
圖5 約束極限學習分類器Fig.5 Classifier of CELM
CELM模型輸入N個樣本的融合特征{f1,f2,…,fN}、隱藏節點的個數L以及激活函數g(?);模型輸出為輸入層到隱藏層的權重矩陣WN×L和偏置向量b1×L,以及隱藏層到輸出層的權重矩陣βL×m。模型的詳細過程闡述如下:
(1)判斷差異特征的個數是否小于L,若小于L,進行第(2)步,否則結束運算。
(2)從任意兩個類別中隨機選取兩個樣本Xc1和Xc2,并計算差異特征fc1-fc2。
(3)對差異特征進行標準化并計算對應的偏置:
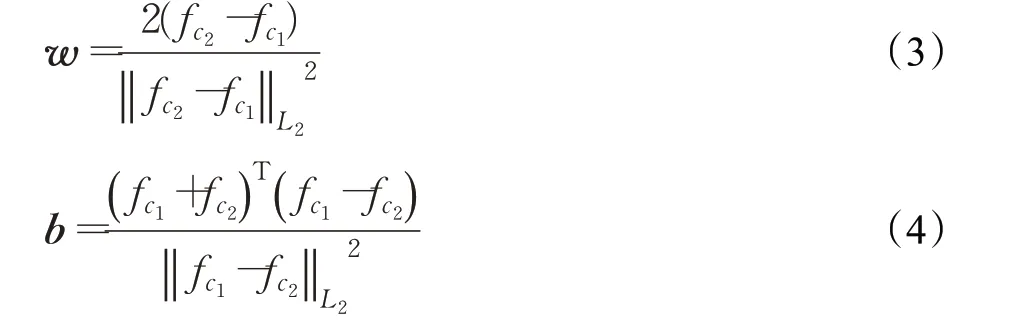
(4)采用w和b構建輸入權重矩陣WN×L和偏置向量b。
(5)計算輸出矩陣:

(6)通過求解最小二乘問題計算輸出層的權重矩陣:

3 實驗結果與分析
本文提出的基于多特征融合與CELM 的場景分類算法實驗過程中,每種類別中包含的訓練樣本與測試樣本的比例為7∶3,CELM 的隱藏節點數為3 000,采用sigmiod 激活函數。UC-Merced、SIRI-WHU 數據集與WHU-RS19 數據集的總分類準確率分別為97.70%、99.25%與98.26%。圖6~圖8 分別顯示了3 種數據集中測試集對應的混淆矩陣。
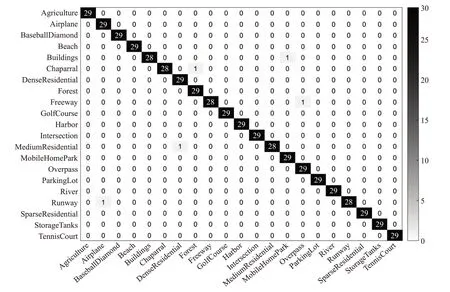
圖6 UC-Merced數據集混淆矩陣Fig.6 Confusion matrix of UC-Merced dataset

圖7 WHU-RS19數據集混淆矩陣Fig.7 Confusion matrix of WHU-RS19 dataset
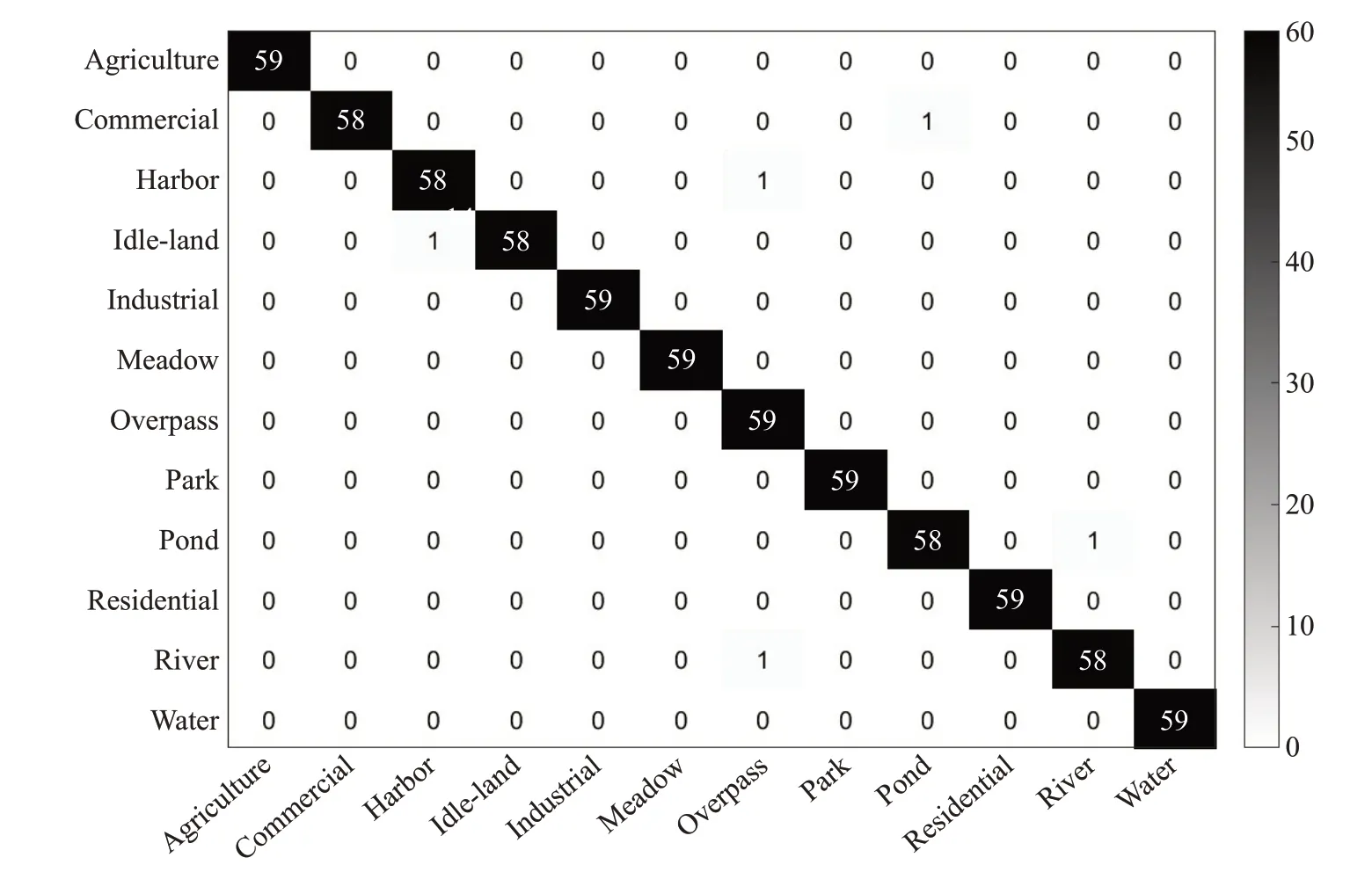
圖8 SIRI-WHU數據集混淆矩陣Fig.8 Confusion matrix of SIRI-WHU dataset
由圖中可以得出,在每種數據集中,大多數場景類能夠被正確分類。且每個場景中,至多有兩張圖像分類錯誤。因此,提出的基于多特征融合與CELM 的場景分類算法在遙感場景數據集中能夠取得比較普遍的適用性。
為了驗證提出的基于多特征融合與CELM 的場景分類算法的有效性,針對微調效應、特征融合效應以及分類器的選擇設計了3組對比實驗。
3.1 預訓練CNN微調
本組實驗采用SIRI-WHU 數據集分別對預訓練CaffeNet、VGG-F 與VGG-M 模型進行參數調優。每個網絡的迭代訓練次數為20,圖9顯示了迭代過程中的訓練集與驗證集的top1錯誤率,實驗選取驗證集錯誤率最低的模型作為最終的微調模型。表3顯示了3種預訓練卷積神經網絡與微調網絡在UC-Merced、WHU-RS19和SIRI-WHU數據集上的分類準確率。

表3 數據集的微調效應比較Table 3 Comparison of fine-tuned effects in datasets%
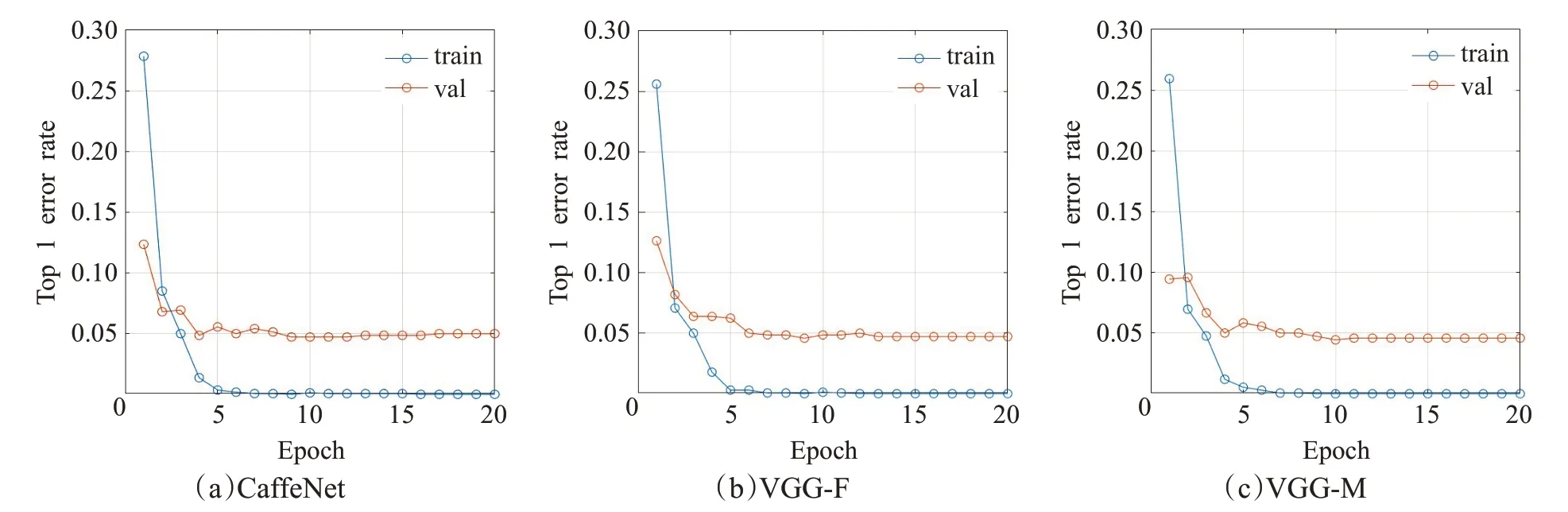
圖9 預訓練網絡微調過程Fig.9 Fine-tuned process of pre-trained CNN
由表3 可見,3 種網絡在經過參數調優后的分類效果均有不同程度的提高。因此可以得出,微調后的卷積神經網絡更有利于場景分類。
3.2 多特征融合
本組實驗是為了驗證不同網絡中卷積結構相對于單獨的網絡卷積結構,能夠捕捉多尺度互補特征。針對單特征、雙特征融合以及多特征融合進行了7組對比實驗。此外,對預訓練卷積神經網絡與精調的卷積神經網絡上的特征融合結果也進行了實驗對比。表4 顯示了每組對比實驗的分類精度。

表4 數據集特征融合效應對比Table 4 Comparison of feature fusion effects in datasets%
可以看出,單特征的分類性能有限,雙特征融合的分類精度比單特征高,多特征融合的分類精度比雙特征融合高,并且精調后融合的分類精度比預訓練融合的分類精度高。此外,多特征融合在3 種種數據集上產生的99.25%、98.26%以及97.70%的分類精度表明,采用CaffeNet、VGG-F 與VGG-M 網絡結構融合結合約束極限學習分類器捕捉的特征幾乎涵蓋圖像的全部信息。
3.3 CELM分類器性能
為了驗證不同分類器的分類性能,分別采用SVM、ELM與CELM分類器對UC-Merced、SIRI-WHU與WHURS19 數據集進行分類。其中,ELM 分類器的隱藏節點設為10 000。表5、6 和表7 分別顯示了3 種分類器在每種數據集的單個類別上的分類結果,可以看出,與其他分類器相比,CELM分類器取得了相對較好的性能。
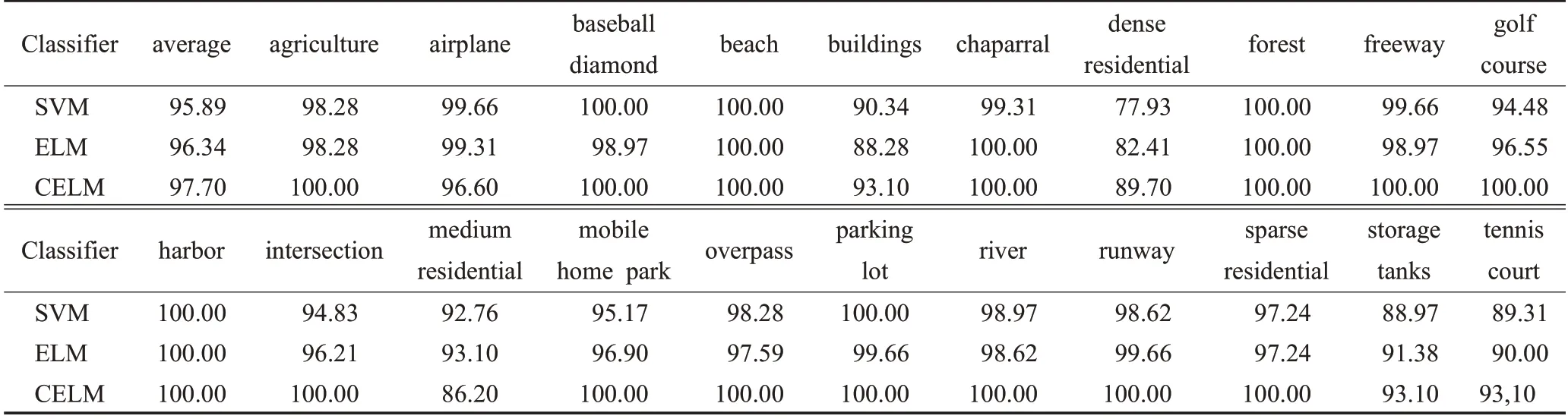
表5 UC-Merced數據集分類器性能Table 5 Classifier performance of UC-Merced dataset%

表6 SIRI-WHU數據集分類器性能Table 6 Classifier performance of SIRI-WHU dataset%

表7 WHU-RS19數據集分類器性能Table 7 Classifier performance of WHU-RS19 dataset%
4 結束語
本文提出了一種基于多特征融合與CELM 分類器相結合的卷積神經網絡模型用于場景圖像分類。方法首先選用3種不同的卷積神經網絡訓練模型,采用特定數據集對其進行參數微調;微調后的網絡對圖像進行特征提取,采用元素相加的方式對提取的3種互補特征進行融合;將融合后的特征送入CELM 分類器,得到每個類別的概率分數,并將概率最大的類別作為圖像的語義標簽。在UC-Merced、SIRI-WHU 與WHU-RS19 數據集上的分類結果表明,本文提出的場景分類模型采用深度較淺的卷積神經網絡,在特定的數據集上實現了較高的分類效果。下一步工作將采用無監督學習的方法獲取低水平的卷積核參數,使融合網絡能夠捕捉更具針對性的特征。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
