基于無監督圖神經網絡的學術文獻表示學習研究
2022-01-24 15:41:44任衛強曹高輝
情報學報 2022年1期
關鍵詞:特征
丁 恒,任衛強,曹高輝
(華中師范大學信息管理學院,武漢 430079)
1 引言
科學研究是人類認知世界的手段,對社會、科技、經濟、文化的發展具有重大的影響。學術文獻是科學研究活動的重要成果,也是科學工作者之間交流思想的主要工具。文獻計量學研究表明,學術文獻發表的數量以每年8%~9%的速度快速增長[1],展現著科研活動和學術交流的繁榮景象。然而,爆炸式增長的文獻數量也為科研活動帶來了負面影響,研究人員難以處理海量的學術文獻,面臨著嚴重的信息過載問題。基于此,以計算機信息處理技術為核心,面向海量學術大數據的信息服務(如Web of Science、Google Scholar、Mendeley等),已成為研究人員不可或缺的科研工具。
如何從學術文獻中抽取重要的信息,將學術文獻表示成計算機算法更易處理的形式,是實現學術文獻的分類、組織、檢索和推薦的一個核心問題。傳統方法主要是依靠專家經驗構造人工特征對學術文獻進行表示,例如,在學術信息檢索中以論文標題和摘要文本構建倒排索引,文獻分類和推薦系統中以詞袋模型、向量空間模型、主題模型構建學術文獻表示向量[2-3]。
近年來,基于深度學習的學術文獻表示學習受到了廣泛關注。例如,文獻[4-6]采用神經語言模型從大規模學術文獻語料庫中自動學習文獻的語義特征,將學術文獻表示成稠密向量,進而實現分類、檢索和推薦,其主要缺點在于神經語言模型僅考慮了學術文獻的文本語義信息,忽視了學術文獻之間的關系結構信息。有鑒于此,文獻[7-9]提出用圖神經網絡從文獻引文網絡中提取文獻間的關系結構信息,并與文獻文本語義信息相融合,從而構造學術文獻表示向量的思路。然而,現有研究大多采用有監督圖神經網絡學習文獻特征表示,其存在兩個缺點:①有監督圖神經網絡需要針對具體的任務構建大量的、高質量的標注數據;②有監督圖神經網絡獲取的文獻特征表示與標注數據集的任務高度耦合,難以直接遷移到其他任務上,導致特征表示的普適性較差。
相較于有監督圖神經網絡,無監督圖神經網絡可直接從無標注文獻網絡數據中學習通用的文獻特征表示,進而應用于文獻分類、學術檢索、論文推薦等不同的下游任務,被認為是一種更具優勢的學術文獻表示學習方法。然而,無監督圖神經網絡在學術文獻表示學習上的效果尚不明確。基于此,本文將無監督圖神經網絡方法應用于學術文獻的表示學習,自動從不同類型的學術文獻網絡中學習論文的特征表示向量,并且進一步探討特征向量在文獻分類、學術檢索、論文推薦等下游任務的應用情況。本文旨在通過系統性的模擬實驗回答以下三個研究問題,為構建基于預訓練文獻表示向量的學術大數據應用提供有效參考依據。
問題1:在文獻分類和論文推薦兩個下游任務場景中,哪種無監督圖神經網絡方法具有更好的效果?可能的內在原因是什么?
問題2:無監督圖神經網絡特征表示維度變化對文獻分類和論文推薦任務的最終效果有何影響?
問題3:哪種類型的學術文獻網絡(引文網絡、共被引網絡和文獻耦合網絡)更適合學習文獻的通用特征表示?
2 相關研究
2.1 表示學習研究
機器學習應用的效果很大程度上取決于特征表達,即如何構建樣本數據的特征表示。傳統的機器學習時代,特征表達主要依靠人類的先驗知識,通過人工分析提取樣本的重要信息,將其組織為特征向量,即所謂的特征工程[10]。然而,特征工程嚴重依賴專家知識且耗時耗力,因此,自動從原始數據中學習數據的有效表示(即表示學習研究)逐漸成為研究熱點[11]。近年來,深度學習技術使得表示學習在圖像識別、語音和信號處理以及自然語言處理等領域取得了顯著成果。例如,計算機視覺領域,相較于人工視覺特征,利用卷積神經網絡的自動提取視覺特征大大地降低了圖像識別的錯誤率[12];語音識別應用中,在傳統聲學特征梅爾倒譜系數(Mel-frequency cepstral coefficients,MFCC)的基礎上,通過神經網絡增強特征表示能夠進一步提升語音識別的最終效果[13];自然語言處理研究中,通過訓練大規模預訓練語言模型獲得文本的向量表示,例如,基于詞上下文預測的Word2Vec[14]、基于上下文Word Embedding雙向動態調整的ELMo[15]以及基于Transformer的雙向語言模型BERT(bidirectional encoder representation from transformers)[16-17]已成為當前自然語言處理任務的標準基線。
如何針對不同的具體任務構建合適的神經網絡結構,是基于深度學習的表示學習研究的一個重要問題。從已有的實證研究來看,卷積神經網絡(convolutional neural networks,CNN)、遞歸神經網絡(recurrent neural network,RNN)和基于注意力機制的Transformer神經網絡已成為圖像、音頻和文本數據表示學習的關鍵組件。實證研究表明[11],通過深度神經網絡學習特征,表示學習能夠具有較強的數據表征能力,可以不依賴于某一特定任務,學習到更通用的先驗知識。因此,將表示學習引入學術數據處理和表征,對論文、作者、期刊、機構、研究問題、方法、技術、數據集等學術實體的識別、分類、組織、檢索和推薦具有較大的潛在價值。
2.2 圖嵌入研究
圖結構廣泛存在于現實場景中,如社交網絡、通信網絡、分子結構、引文網絡等,真實的圖數據具有高維度、難處理的特點,如何將高維圖轉化為低維向量表示,即圖嵌入研究(graph embedding)一直是學術研究的熱點[18]。目前,圖嵌入領域主要有基于因子分解的、基于隨機游走的和基于深度學習的三大類方法。基于因子分解的圖嵌入有局部線性嵌入[19]、拉普拉斯特征映射[20]、圖因子分解機[21]等方法,該系列方法以線性代數為理論基礎,依靠特征值分解、奇異值分解等矩陣分解技術,將原始高維向量轉換為低維特征向量,且保留原始矩陣中的重要信息。基于隨機游走的圖嵌入有DeepWalk[22]和Node2Vec[23]等,該系列方法受自然語言處理研究中的詞向量(Word2Vec)研究啟發,以圖中任一節點為起始點,通過無偏或有偏隨機游走獲得節點序列,再使用Word2Vec算法學習節點的嵌入向量,嵌入向量能夠表征節點在圖中局部結構信息。基于深度學習的圖嵌入有基于自編碼器和鄰接矩陣的SDNE(structural deep network embedding)[24]、基于卷積神經網絡的圖卷積神經網絡GCN(graph convolutional network)[25]以及基于編碼器-解碼器結構的圖自編碼器GAE(graph auto-encoder)[26]等,該系列方法能夠利用深度神經網絡模擬高維非線性函數,從而獲得更精準的節點嵌入向量,具有更強的圖數據表示能力。
在圖嵌入研究中,以圖自編碼器(GAE)為代表的無監督圖神經網絡方法,不僅能夠編碼節點的網絡結構信息,而且能夠利用節點的屬性信息,從多種角度學習到圖數據中蘊含的先驗知識。由于學術數據的先驗知識不僅存在于學術文獻的文本語義信息中,還蘊藏于學術文獻構成的關系網絡里,且學術數據的表示可應用的領域和任務較多,利用圖神經網絡獲取學術數據的通用表示有利于促進學術大數據的挖掘與應用。
3 基于圖的學術文獻表示學習
3.1 文獻關系網絡
學術文獻往往并非孤立存在,而是通過相互聯系形成網絡結構,比如引文網絡、共被引網絡、文獻耦合網絡等。網絡在數據科學、計算機科學中又稱為圖,是一種常見的數據結構,一般用G=(V,E)表示。其中,V表示網絡中所有節點的集合;E表示網絡中所有邊的集合;vi∈V表示V中第i個節點;eij=(vi,vj)∈E表示節點vi和vj之間的邊。對于學術文獻網絡G而言,vi表示一篇學術論文,eij表示論文vi和論文vj之間的引用、共被引或文獻耦合關系。在數學上,網絡G的結構信息可用n×n的鄰接矩陣A表示,矩陣A的第i行第j列元素記為Aij,Aij=1表示節點vi與節點vj之間存在一條邊;反之,則Aij=0。網絡G中所有節點的屬性信息用屬性矩陣X∈Rn×d表示,矩陣X中一行xv∈Rd表示節點v的屬性向量。因此,具有節點屬性的圖又可以表示為G=(X,A)。在學術文獻網絡中,屬性矩陣X代表著所有論文的文本語義信息,而A則代表學術文獻之間構成的網絡結構信息。
學術文獻表示學習,是指利用神經網絡從大規模、高維度學術文獻數據中自動地獲取文獻的低維向量表示,是表示學習研究在學術數據領域的具體應用。目前,學術文獻表示學習主要有以下兩大類方法。
(1)基于文本數據的文獻表示學習。主要利用神經語言模型,將篇幅較大、詞項較多的論文的文本信息編碼成低維稠密實數向量,解決傳統詞袋模型下論文表示向量詞項空間過大的問題。
(2)基于圖數據的文獻表示學習。主要利用圖神經網絡模型,從文獻關系網絡中提取有效信息,進而將論文編碼成低維向量,其核心思想是論文之間的關系結構一定程度上能夠表達論文本身的特征。
從數學形式上看,前者可記為f(X)→Z,只利用了論文的文本語義信息X;后者可記為f(X,A)→Z,不僅利用文本語義信息X,同時利用文獻網絡的結構信息A。Z是神經網絡f輸出的文獻特征表示矩陣,矩陣Z中任一行zv表示文獻v的特征表示向量,該向量可被應用于文獻分類、學術檢索、論文推薦等下游任務中。模糊的學科邊界、高度交叉融合的學科體系,導致“一詞多義、一義多詞”的現象普遍存在于學術論文中,純粹基于文本語義信息的文獻表示學習方法具有先天的缺點,因此,本文主要探討以圖神經網絡為基礎,可綜合利用兩種信息的學術文獻表示學習方法。
3.2 無監督圖神經網絡
目前,圖神經網絡主要分為有監督、半監督和無監督三大類型。其中,無監督圖神經網絡不僅具備圖神經網絡能夠同時編碼文獻文本語義信息和文獻關系結構信息的能力,同時具有無需標注數據的優勢,且網絡訓練過程與下游任務解耦,所學習到的文獻表示具有較強的通用性。因此,本文聚焦于多種代表性無監督圖神經網絡方法在學術文獻表示學習上的應用效果,選擇的代表性無監督圖神經網絡有圖自編碼器(GAE[26])、變分圖自編碼器(variational graph auto-encoders,VGAE)[27]、對 抗正則化變分圖自編碼器(adversarially regularized variational graph autoencoder,ARVGA)[27]和深度互信息圖神經網絡(deep graph infomax,DGI)[28]。
無監督圖神經網絡主要由編碼器、解碼器以及學習目標三個部分構成。
(1)編碼器。以文獻網絡的鄰接矩陣A和文獻文本語義信息矩陣X為輸入,通過編碼函數f獲得文獻特征表示矩陣Z,記為f(X,A)→Z。
(2)解碼器。在文獻特征表示矩陣Z的基礎上,通過解碼函數獲得重構鄰接矩陣記為
(3)學習目標。在文獻網絡的鄰接矩陣A、重構鄰接矩陣A^、文獻特征表示矩陣Z等的基礎上,根據目標函數評估、優化文獻特征表示矩陣Z的表達能力。
表1 列舉了四種無監督圖神經網絡各部分的差異。

表1 四種無監督圖神經網絡差異分析表
在編碼器部分,四種無監督圖神經網絡都采用了圖卷積神經網絡GCN,圖卷積神經網絡的計算公式為
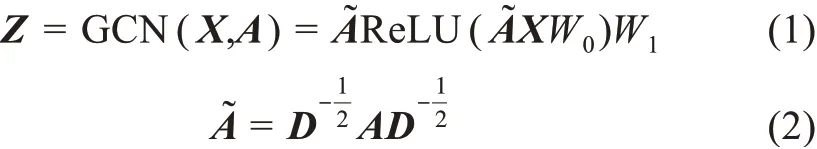
其中,GCN表示圖卷積神經網絡;D表示鄰接矩陣A對應的度矩陣;ReLU為線性整流函數;W0和W1為圖卷積神經網絡待學習的參數。圖自編碼器通過1個圖卷積神經網絡GCN輸出文獻特征表示矩陣Z。變分圖自編碼器則和對抗正則化變分圖自編碼器用GCNμ(X,A)和GCNσ(X,A)輸出文獻特征表示矩陣Z,且GCNμ(X,A)和GCNσ(X,A)是W0相同、W1不同的兩個圖卷積神經網絡,分別捕獲文獻特征表示的均值μ和文獻特征表示的方差σ,且不僅生成文獻特征表示矩陣Z,還通過標準正態分布N(z v|0,1)采樣獲得的先驗表示矩陣深度互信息圖神經網絡則用圖卷積神經網絡編碼隨機擾動矩陣從而輸出噪聲特征表示矩陣在解碼器部分,圖自編碼器、變分圖自編碼器和對抗正則化變分圖自編碼器都采用內積運算θ(ZZT)獲取重構鄰接矩陣其中,ZT表示Z的轉置矩陣,θ表示Sigmoid函數。深度互信息圖神經網絡則通過矩陣運算θ(ZWs→T)和輸出重構矩陣A′和其中,θ表示Sigmoid函數,W是一個大小為d×d可學習的參數矩陣,s→表示文獻全局特征表示向量,具體計算公式為

其中,z v是文獻特征表示矩陣Z的其中一行,代表文獻v的特征表示向量,大小為1×d;表示向量的轉置。注意,與前三種神經網絡不同,深度互信息圖神經網絡解碼器輸出的重構矩陣時,不僅考慮了各個文獻的特征表示,而且考慮了整體特征表示s→的信息。
在學習目標部分,四種圖神經網絡采用了不同的損失函數作為網絡學習優化目標。涉及的損失函數有LCE交叉熵損失函數、KL相對熵損失函數和JS散度損失函數。交叉熵的計算公式為
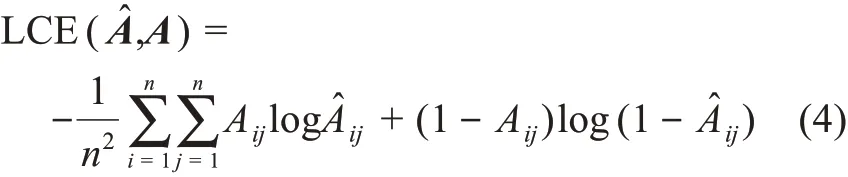
其中,n表示文獻網絡中論文數量;Aij為原始鄰接矩陣A的第i行第j列;為重構鄰接矩陣的第i行第j列;LCE(A^,A)實質上衡量了矩陣A和矩陣的差異。
KL相對熵的計算公式為
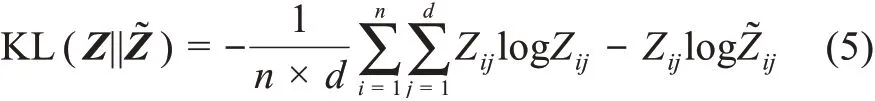
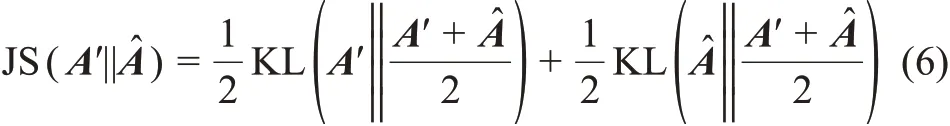
min||·||和max||·||分別表示最小化和最大化目標函數,因此,四種無監督圖神經網絡學習目標及含義分別為:
對抗正則化變分圖自編碼器中判別器D(Z)的計算公式為
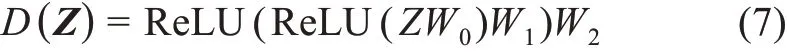
其中,D是一個三層的多層感知機,以文獻特征表示矩陣Z為輸入時,判別器可輸出一個n×1的矩陣D(Z);W0、W1和W2為多層感知機中待學習的參數。同理,以先驗表示矩陣為輸入時,判別器也將輸出一個n×1的矩陣
3.3 特征學習算法與過程
學術文獻表示學習的根本目標是獲得一個具有較強特征表達能力的文獻特征表示矩陣Z。在基于無監督圖神經網絡的學術文獻表示學習框架下,文獻特征表示矩陣Z是由編碼器輸出而得,即f W(X,A)→Z,其中,f代表編碼器中的圖卷積神經網絡,W表示圖卷積神經網絡中所有可學習的參數。算法1描述了學術文獻特征表示矩陣Z的學習過程,學習到的文獻表示向量zv可作為特征向量應用于下游任務;迭代次數T為250,特征維度d的取值范圍為[32,64,128,256,512]。
算法1:基于無監督圖神經網絡的學術文獻表示學習算法
輸入:文獻關系網絡G=(X,A),訓練的迭代次數T,特征維度大小d。
Step1.隨機初始化編碼器參數W;
Step2.編碼器進行運算,輸出文獻特征表示矩陣Z;
Step4.根據學習目標計算損失函數;
Step5.采用隨機梯度下降更新編碼器參數W;
Step6.反復執行Step1~Step5T次;
Step7.輸出Z作為最終學習到的文獻特征表示矩陣,文獻v的表示向量為zv∈Rd。
4 實驗構建
4.1 任務場景設計
本文選擇文獻分類和論文推薦為下游任務場景,從而分析學習到的學術文獻特征表示的有效性。具體而言,在文獻分類任務中,實驗執行以下4個步驟:①文獻表示學習,將文獻網絡G=(X,A)輸入無監督圖神經網絡獲取文獻特征表示Z;②數據集切分,將文獻網絡G中的所有文獻切分為兩個訓練集Z1:v={z1,…,zv}和測試集Zv:n={zv+1,…,zn},樣本比例分別為70%和30%;③分類模型訓練,將訓練集數據輸入邏輯回歸分類器訓練分類模型;④評價指標計算,將訓練好的分類模型運用到測試集上,獲取MarcoF1(宏平均F1值)和MicroF1(微平均F1值)兩個評價指標。
在論文推薦任務中,實驗執行以下5個步驟:①文獻表示學習,將學術文獻網絡G=(X,A)輸入無監督圖神經網絡獲取文獻特征表示Z;②測試文獻采樣,從文獻網絡G中隨機抽取30個文獻,作為論文推薦任務的測試文獻;③推薦列表獲取,依次從文獻特征表示矩陣Z中取出測試文獻對應的特征向量z v,利用余弦相似度公式計算其與學術文獻網絡G中所有其他文獻的相似性,并篩選相似性最大的前20篇文獻為候選推薦列表;④相關性標注,兩位標注專家查看測試文獻和推薦列表候選文獻標題和摘要的內容,判斷測試文獻與推薦列表中每個文獻之間的相關性大小并進行打分,分值為1~5;⑤評價指標計算,在相關性標注的基礎上計算Hit@K和Ndcg@K指標,K的取值為[5,10]。
4.2 數據集處理
基于無監督圖神經網絡的學術文獻表示學習算法,必須執行在既包含文獻網絡關系又包含文獻文本語義特征的數據集上,因此,本文以三個大小不同的學術文獻網絡數據集Cora、CiteSeer和DBLP(database systems and logic programming)為基礎,針對文獻分類和論文推薦兩個任務進行預處理,從而構建了實驗數據集。表2列舉了處理后數據集的具體信息。
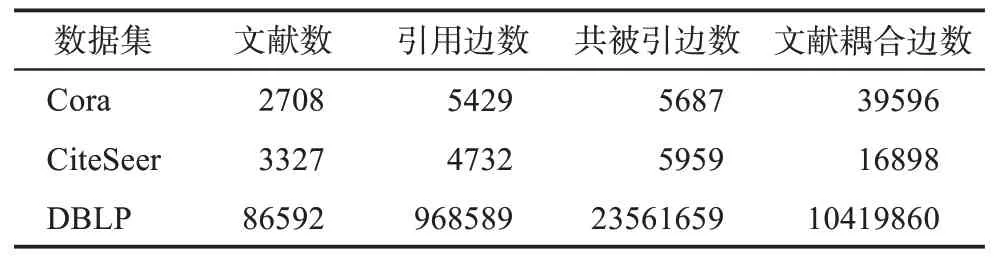
表2 三個學術文獻數據集的具體信息
具體而言,Cora原始數據集共包含2708篇文獻,每篇文獻的文本特征為1433維的one-hot向量,文獻引文網絡的邊數為5429。本文根據Cora原始引文網絡抽取出共被引關系5687條和文獻耦合關系39596條,從而構建了Cora數據集的共被引網絡和文獻耦合網絡,且從此網站①https://people.cs.umass.edu/~mccallum/data/獲取到Cora數據集中每篇文獻對應的標題和摘要。CiteSeer原始數據集共包含3327篇文獻,每篇文獻的文本特征為3703維的one-hot向量,文獻引文網絡的邊數為4732,共被引網絡邊5959條、文獻耦合網絡邊16898條。本文從原始DBLP數據中隨機采樣出86592篇文獻及其對應的引文關系968589條,共被引關系23561659條,文獻耦合關系10419860條,每篇文獻的文本語義特征向量通過Spacy中的Word2Vec模型獲取②https://spacy.io/,文獻的文本語義向量為文獻標題中所有詞的詞向量的均值向量。。為了提升實驗結論的可拓展性,本文對每個下游任務都采用兩個數據集進行實驗,具體信息如表3所示。

表3 任務數據集選擇及其說明
4.3 實驗組設置③https://scholarbank.nus.edu.sg/handle/10635/146027
為了回答在第1節中提出的三個研究問題,本文共設計了兩組實驗,相關設置如下。
實驗組1:以三個數據集的文獻引文網絡為輸入鄰接矩陣,依次采用四種無監督神經網絡,選擇不同大小的特征維度d,執行文獻分類和論文推薦任務獲取評價指標,并以深度隨機游走(Deep-Walk)[22]、Doc2Vec[29]、Paper2Vec[30]的結果作為對比基線。該實驗組在固定文獻網絡結構的條件下,通過改變無監督圖神經網絡的結構和文獻特征表示維度大小獲取實驗結果,以期回答問題1和問題2。
實驗組2:以Cora數據集的引文網絡、共被引網絡、文獻耦合網絡為輸入鄰接矩陣,以固定的無監督圖神經網絡,通過貪心算法選擇最優特征維度d,執行文獻分類和論文推薦任務獲取評價指標。該實驗組在固定任務和確定無監督圖神經網絡模型的條件下,通過改變輸入網絡的結構獲取實驗結果,以期回答問題3。
5 實驗結果分析
5.1 學習方法比較分析
表4 顯示了三種基線方法和四種無監督圖神經網絡在Cora和CiteSeer兩個數據集上執行文獻分類實驗的最優結果。由研究結果可知,在文獻分類任務上,無監督圖神經網絡全面優于深度隨機游走,表明在文獻關系結構信息之上,融合文獻文本語義信息能夠有效提升文獻特征表示能力。深度互信息圖神經網絡在兩個數據集中均獲得了最高評價指標,在Cora數據集上,宏平均F1和微平均F1值分別為0.808和0.820;在CiteSeer數據集上,宏平均F1和微平均F1值分別為0.657和0.692。變分圖自編碼器僅次于深度互信息圖神經網絡,在兩個數據集的多項指標上均獲得了較好的結果。圖自編碼器和對抗正則化變分圖自編碼器則表現相當,在不同數據集的不同指標上互有勝負。
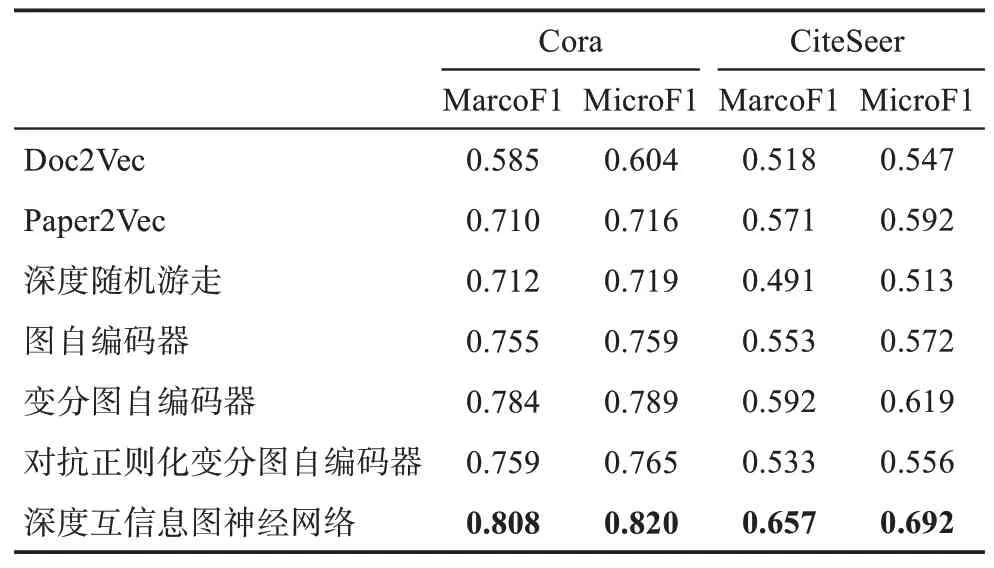
表4 三種基線方法和四種無監督圖神經網絡在文獻分類任務上的最優結果
表5 顯示了三種基線方法和四種無監督圖神經網絡在Cora和DBLP兩個數據集上執行論文推薦實驗的最優結果。在Cora數據集上,對抗正則化變分圖自編碼器表現最好,其Ndcg@5、Ndcg@10、Hit@5、Hit@10分別為0.596、0.646、0.571、0.660。在Hit@10指標上,深度互信息圖神經網絡的表現最優,而其他三個圖神經網絡則表現相當。在Ndcg@5和Ndcg@10指標上,對抗正則化變分圖自編碼器遠高于其他三個神經網絡,圖自編碼器則表現優于變分圖自編碼器和深度互信息圖神經網絡。在DBLP數據集上,對抗正則化變分圖自編碼器在Ndcg@5、Ndcg@10、Hit@5和Hit@10上都得分最高,其他三個神經網絡表現則相差不大。盡管深度互信息圖神經網絡和對抗正則化變分圖自編碼器的Hit@5指標均為0.457,但是對抗正則化變分圖自編碼器的Ndcg@5得分為0.573,相比于深度互信息圖神經網絡提高了6.5%,這說明對抗正則化變分圖自編碼器能夠將相關性更高的文獻排在推薦列表頂部。
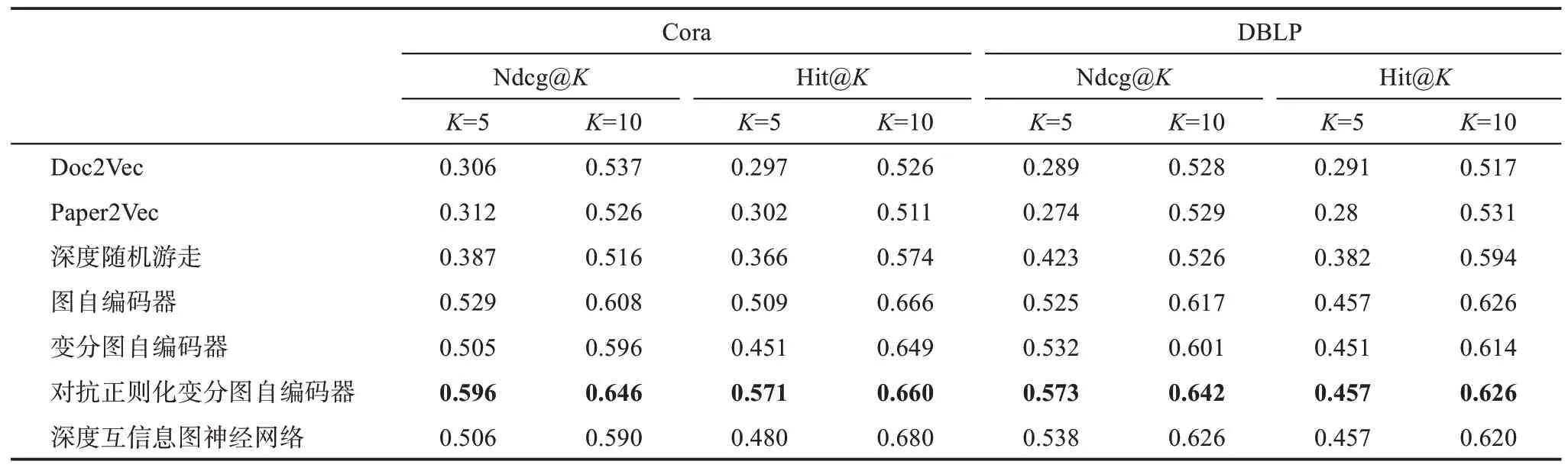
表5 三種基線方法和四種無監督圖神經網絡在論文推薦任務上的最優結果
上述實驗結果表明,相較于其他圖神經網絡學習到的特征表示,深度互信息圖神經網絡學習到的文獻特征表示具有更強的文獻差異區分能力。這可能是由于深度互信息圖神經網絡學習的目標是最大化局部文獻特征表示和全局文獻特征表示的互信息,即學習到更能夠表示每一篇文獻獨特性的特征向量,因此,其特別適合于文獻分類這種下游任務。而其他三種圖神經網絡的學習目標均希望使得重構鄰接矩陣和原始鄰接矩陣的相接近,實質上是讓文獻網絡中具有關聯關系的文獻具有更相近的特征表示向量。從這個角度來看,理論上圖自編碼器、變分圖自編碼器和對抗正則化變分圖自編碼器學習到的文獻特征表示更適合于論文推薦任務。然而,在Cora和DBLP兩個數據集上,深度互信息圖神經網絡表現并非最差,與圖自編碼器和變分圖自編碼器表現相當。本文認為,這可能與Cora和DBLP兩個數據集包含的所有文獻皆屬于計算機領域有關。正是由于Cora和DBLP數據集中文獻都屬于同一領域,執行論文推薦任務時深度互信息圖神經網絡捕捉到的細節差異,有利于從主題領域相似的小文獻集合中找到更相關的推薦文獻。
5.2 特征維度影響分析
圖1 顯示了采用不同大小的特征維度d時,四種無監督圖神經網絡模型學習的文獻特征表示在文獻分類任務上的效果變化。由圖1可知,對于深度互信息圖神經網絡而言,當特征維度增大時,文獻分類各指標均呈現遞增的趨勢。而對另外三種無監督圖神經網絡來說,特征維度的增大反而使得文獻分類各指標呈現波動或降低的趨勢。理論上看,更大的特征維度能夠存儲更多的細節信息,從而使得學習到的文獻特征能夠刻畫文獻之間更細節的差異。正如第5.1節分析所述,深度互信息圖神經網絡通過最大化局部文獻特征表示和全局文獻特征表示的互信息,使得每篇文獻自身獨特的信息能夠保留在學習到的文獻特征表示向量中,因此,文獻分類結果受益于更大的特征維度。然而,圖自編碼器、變分圖自編碼器和對抗正則化變分圖自編碼器的學習目標并不能更有效地區分不同文獻之間的差異,只能讓文獻網絡中相連接的文獻具有更相似的表示向量,因此,分類任務上這三種圖神經網絡不能受益于更大的特征維度。
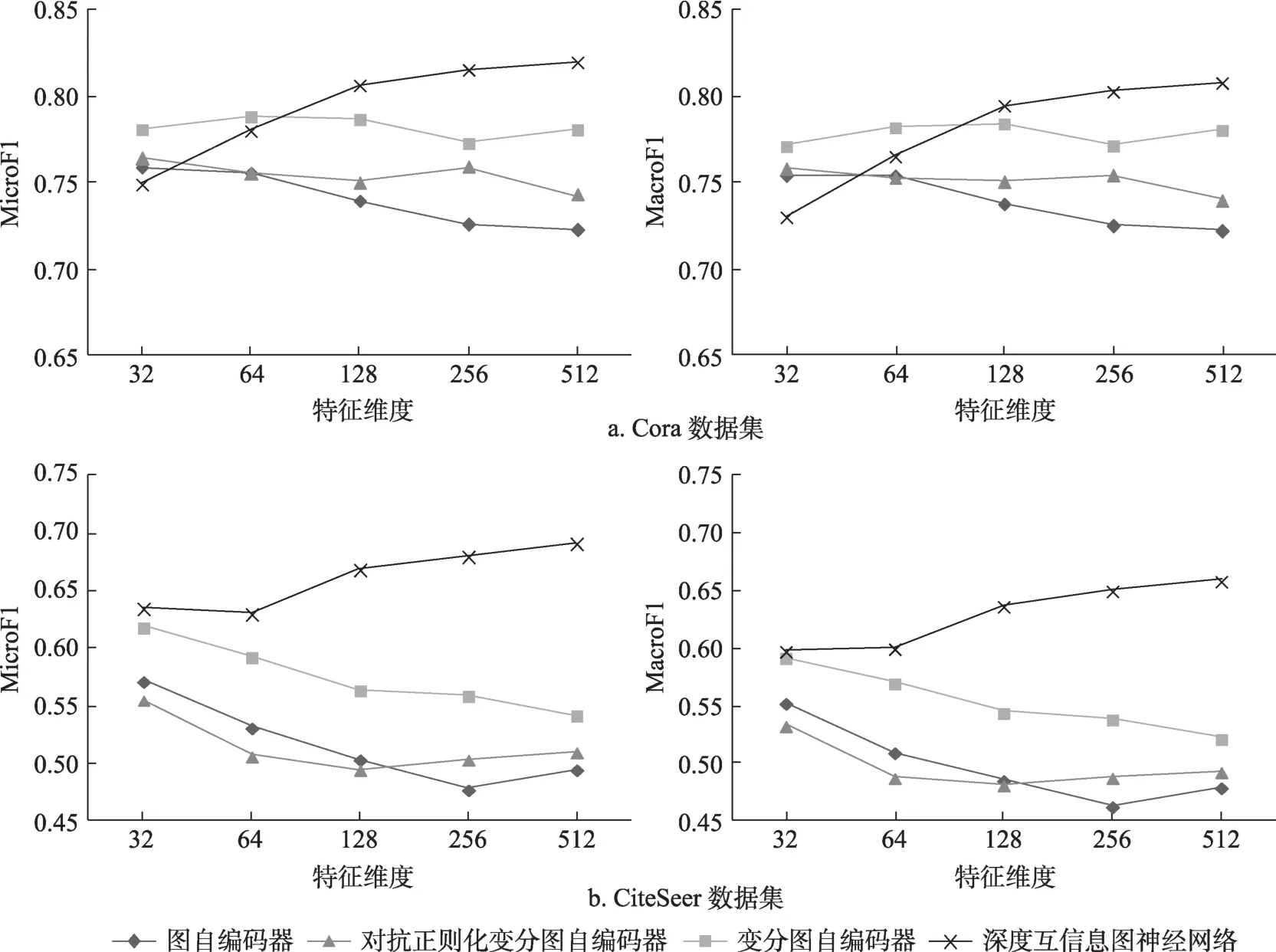
圖1 特征維度變化對文獻分類任務的影響
圖2 顯示了采用不同特征維度大小d時,四種無監督圖神經網絡模型學習的文獻特征表示在論文推薦任務上的效果變化。在DBLP數據集上,深度互信息圖神經網絡各指標均呈現先增后減的趨勢,且在d=128附近得到最大得分。圖自編碼器和變分圖自編碼器在各指標上呈現增減波動,沒有穩定提高或降低的趨勢。對抗正則化變分圖自編碼器各指標最小值均出現在d=64或d=128時且形成上凹拋弧線。在Cora數據集上,除圖自編碼器外的三種無監督圖神經網絡在d=32處已取得最優指標。深度互信息圖神經網絡各指標形成S形波動,其他三種圖神經網絡指標變化較平緩。總的來說,特征維度的增大不能夠給論文推薦結果指標帶來提升,本文認為,這代表四種無監督圖神經網絡的學習目標都無益于論文推薦任務。
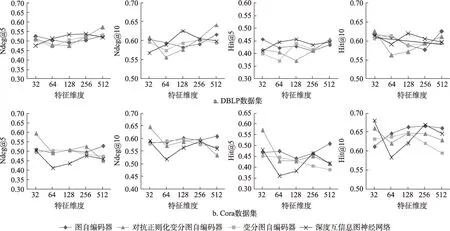
圖2 特征維度變化對論文推薦任務的影響
5.3 網絡類型影響分析
由于CiteSeer數據集只提供了文獻onehot文本特征,缺乏文獻的原始文本數據,而DBLP數據集沒有提供文獻分類標簽,故僅有Cora數據集可同時執行文獻分類和論文推薦兩個任務。圖3中的每個子圖都顯示了同一個數據集下(Cora數據集),采用同一種無監督圖神經網絡時,以三種不同文獻網絡為輸入而獲得的6個任務指標(包括文獻分類2個和論文推薦4個)的數值得分。由圖3可知,無論是文獻分類還是論文推薦任務場景,在其他條件相同時,相比于其他兩個文獻網絡,引文網絡似乎更適合學習文獻的通用特征表示,并且文獻耦合網絡在絕大多數情況下比共被引網絡更好。
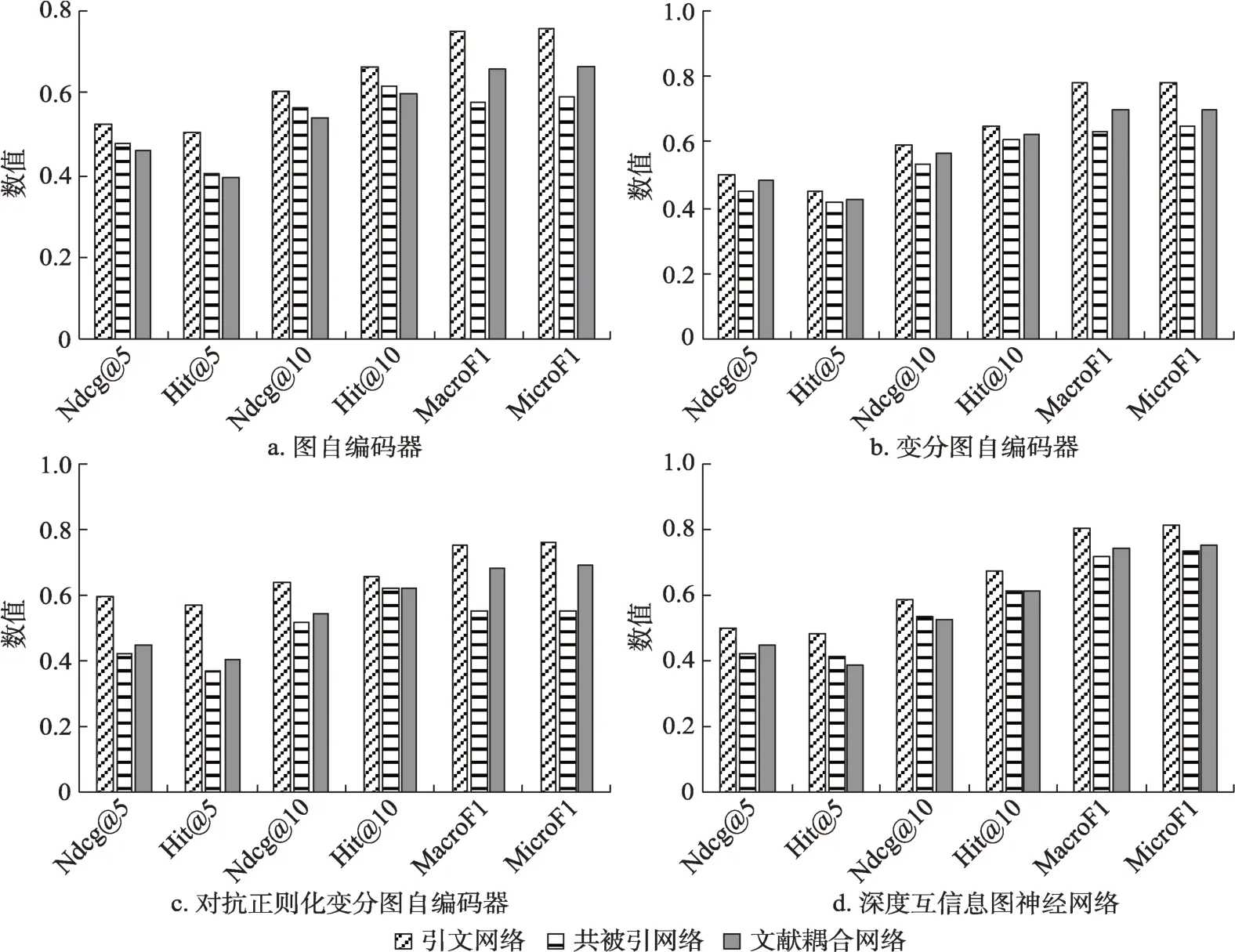
圖3 文獻網絡類型變化對文獻分類和論文推薦指標的影響
為了進一步解釋文獻網絡類型變化而導致文獻分類任務效果的差異,本文統計了三種文獻網絡中不同類型邊的數量,具體如表6所示。其中,同類文獻節點間邊的數量是指文獻網絡中邊兩側的文獻節點屬于同一類別文獻時邊的總數,非同類文獻節點間邊的數量是指文獻網絡中邊兩側的文獻節點不屬于同類別文獻時邊的總數。由表6可知,Cora數據集引文網絡中一共有5429條邊,其中連接同類文獻節點的邊的數量占81.4%,非同類文獻節點的邊的數量占18.6%。從引文網絡構造共被引網絡后,共被引網絡中同類文獻節點間邊的數量占比下降到73.6%,非同類文獻節點間邊的數量占比上升到26.4%。這表明從引文網絡構建共被引網絡時,網絡中不同類型文獻節點間的聯系(邊的數量)密度增大,本來不屬于同一類型的文獻節點被連接起來,從而弱化了從網絡中學習到的文獻表示向量的類別區分能力。同理,在文獻耦合網絡中,同類文獻節點間邊的數量占75.8%,非同類文獻節點間邊的數量占24.2%,低于引文網絡但略高于共被引網絡,因此,其在文獻分類任務上的效果排名第二(圖3)。
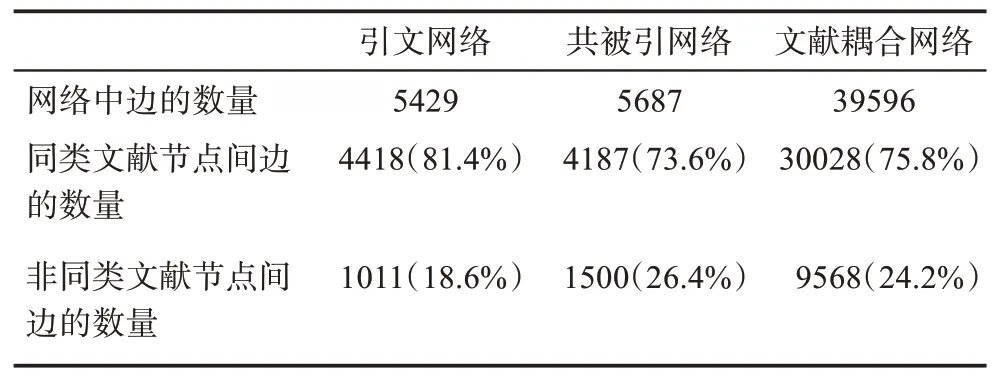
表6 Cora數據集三種文獻網絡中邊類型統計數據表
為了洞察文獻網絡類型導致論文推薦任務效果差異的原因,本文從Cora數據集中隨機選擇了3個文獻節點,并人工統計了這些節點在不同類型文獻網絡中鄰居節點相關性得分的平均值,結果如表7所示。由表7可知,對于同一個文獻節點,其在引文網絡中的鄰居節點的相關性得分平均值高于其他兩個文獻網絡。這表明相較于其他兩個文獻網絡,引文網絡中由邊相連的節點之間可能具有更強的關聯性,更利于圖神經網絡學習文獻間的相似性,從而有利于論文的推薦任務。
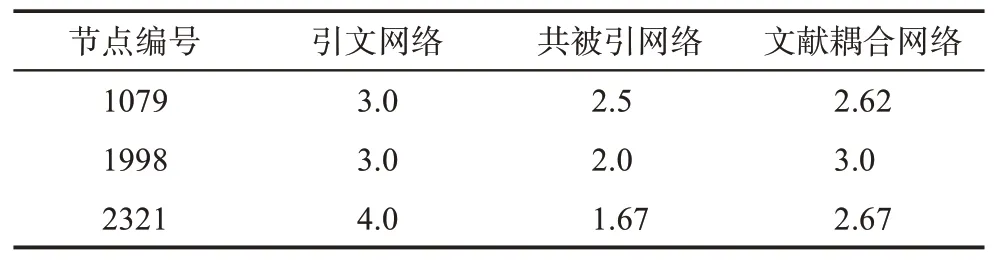
表7 鄰居節點相關性得分統計數據表
6 結 語
學術文獻的表示學習是優化學術文獻搜索、學術文獻分類組織、學術文獻個性化推薦等學術大數據服務的基礎。本文將自編碼器、變分圖自編碼器、對抗正則化變分圖自編碼器和深度互信息圖神經網絡這四種無監督圖神經網絡方法引入學術文獻的表示學習研究,以文獻分類和論文推薦為下游任務進行了相關實驗。本文的主要貢獻:①分析了四種無監督圖神經網絡的差異,提出了以“編碼器-解碼器-學習目標”為核心的、基于無監督圖神經網絡的文獻表示學習框架(見表1),并梳理出四種圖神經網絡的矩陣表達形式;②通過實驗發現深度互信息圖神經網絡的學習目標更適合于文獻分類任務,而對抗正則化變分圖自編碼器更適合于論文推薦任務;③實驗發現特征維度的增大能夠有效提升深度互信息圖神經網絡的文獻類別差異表征能力,而四種無監督圖神經網絡的學習目標似乎都無益于論文推薦任務;④Cora數據集上的實驗表明,相較于共被引網絡和文獻耦合網絡,引文網絡更適合于學習通用的文獻表示向量。
盡管本文選用了Cora、CiteSeer和DBLP等多個數據集進行了實驗,然而這些數據集都僅只是從真實學術文獻網絡中抽樣的部分數據。從理論上看,通過圖神經網絡學習文獻的表示向量會受到文獻鄰居節點文獻的影響,因此,采樣部分文獻數據可能會學習到有偏的文獻表示,即文獻最終的表示向量由采樣到的鄰居節點決定,而不是真實學術網絡中所有鄰居節點決定。未來將分析不同的采樣策略如何影響文獻表示學習和相應的下游任務指標,這是一個有趣且值得研究的問題。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化(高中版.高考數學)(2022年3期)2022-04-26 14:04:16
數學年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學學報(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數學(2019年8期)2019-11-25 01:38:14
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
