基于主成分分析的電站鍋爐受熱面灰污監測方法
2022-02-02 08:48:30鄺藝文魯曼田
湖北電力 2022年5期
關鍵詞:模型
鄺藝文,魯曼田,譚 鵬,張 成
(1.廣東省能源集團有限公司沙角C電廠,廣東 東莞 523936;2.華中科技大學能源與動力工程學院,湖北 武漢 430074)
0 引言
2022年在全球原材料價格上漲的大背景下,隨著“碳達峰”目標的提出,火電廠的電力生產面臨越來越大的壓力。我國燃煤機組的發電煤耗已經達到世界平均水平,且明顯低于印度和澳大利亞等相對落后的國家,與歐洲等國家水平接近,但與日本等處于領先水平的國家還存在約25 g/(kW·h)的差距[1-2],說明我國燃煤機組的煤耗水平還有一定的下降空間。加強火電廠精細化管理,提高火電生產的經濟性,是緩解全國電力資源緊張的重要途經。由于煤質的變化,混煤摻燒會影響鍋爐的積灰結渣特性,導致了受熱面積灰結渣的現象[3]。如不及時清除積灰,會降低火電生產的經濟性,因此需要對鍋爐的各個受熱面進行灰污監測,并根據不同受熱面的污染情況進行針對性地吹灰[4]。
火電廠在線性能監測模型涵蓋了電廠機組的性能計算模塊,收集現場的實時數據,運用性能計算模型,計算包括鍋爐、汽輪發電機及各個輔機的經濟性能指標[5]。目前常用的灰污監測板塊主要是計算基于機理建模的潔凈因子、熱阻或污染率,然后由此對受熱面灰污情況進行監測分析或者預測報警。Tong等[6]提出了一種受熱面灰層熱阻在線監測模型,其設計的支持向量回歸(SVR)模型可以對低溫過熱器熱阻去噪后進行在線預測。Kumari等[7]設計了一個基于動態非線性回歸的潔凈因子監測模型,從而得到優化的吹灰策略來確定臨界潔凈因子和吹灰循環的持續時間。劉經華等[8]根據煙氣壓降設計了一種受熱面表面積灰厚度的計算模型,可以對對流受熱面積灰厚度進行在線監測。Zhang等[9]提出了一種聲學系統,用于監測鍋爐水冷壁附近的溫度變化,并建立反應積灰狀況的新清潔系數,采用該方法對積灰結渣情況進行監測。李孟威等[10]采用清潔因子作為健康指標監測鍋爐受熱面健康狀況,并提出融合經驗模態分解(EMD)和長短期記憶網絡(LSTM)的模型來預測未來鍋爐積灰。錢虹等[11]提出了基于生產數據挖掘和證據融合的吹灰需求度置信規則庫研究,利用數理統計、貝葉斯理論、均值聚類等相關方法確定規則庫相關參數,使置信規則庫的吹灰需求度結果更加接近積灰程度的表達。綜上所述,這些基于機理分析建立的灰污監測模型需要全面而完整的參數數據,計算量大且復雜,而由于各電廠實際情況不一樣,有些電廠可能沒有相關測點數據,從而導致建模困難,使得模型的通用性較差。
設備狀態在線監測與預警診斷系統直接影響著電廠設備的安全運行和電能的平穩生產[12]。由于監測系統中采集的數據眾多,如果直接分析處理,工作量較多,因此減少數據維數,盡可能多地提取出可以反映原始變量信息的數據就顯得非常重要[13]。主成分分析(Principal Component Analysis,PCA)是一種將多指標變量轉換成綜合指標來進行判斷的統計方法。通過正交變換將可能存在相關性的變量轉換為線性不相關且能最大程度區分每個變量的正交基,轉換后的這組變量被認為是主成分[14-16]。主成分分析的基本思想是數據降維和特征提取,其實際應用十分廣泛,比如人口統計學、分子動力學模擬、數學建模、數理分析等學科中均有應用,是一種常用的多變量分析方法[17]。Makis 等人[18]對考慮交叉和自相關的動態主成分分析法進行研究,以減少風險比例回歸模型中協變量的數量。楊國田等[19]利用主成分分析法對火電廠DCS 系統數據進行特征提取,消除各特征變量間的耦合性,然后結合神經網絡的輸入,得到火電廠NOx排放預測模型。許壯等[20]將主成分分析(PCA)和隨機森林(RF)相結合建立了SCR脫硝反應器出口NOx質量濃度預測模型,結果表明:與SVM和BP神經網絡模型相比,RF算法得到的SCR系統模型具有更好的預測效果。李楊等[21]基于PCA 提取主成分,利用PSO 算法優化模型參數,建立了PCA-PSOLSSVM 鍋爐效率預測模型。Misra 等[22]在化工鍋爐的生產過程,采用多尺度主成分分析進行了故障監測與診斷的研究。王文標等[23]提出了基于改進交叉分段PCA的工業鍋爐故障監測系統,實例監測結果表明該方法比傳統PCA 方法的故障檢測效果更好。Swiercz 等[24]基于多通道主成分分析方法對某蒸汽鍋爐管道系統泄漏進行故障檢測,提高了電廠鍋爐的安全性。朱少民等[25]采用主成分分析(PCA)技術對主泵的傳感器進行狀態監測,使用某核電廠主泵的運行數據建立PCA監測模型,并利用該模型對傳感器的小漂移故障和共模故障進行識別,仿真結果表明該模型對主泵傳感器具有很好的監測效果。張弛等[26]文中提出了一種基于PCA和優化參數SVM的智能變電站故障診斷方法,該方法首先利用PCA分析影響因素,從而實現數據降維,然后構建出多分類SVM分類器,并通過ICA進行參數尋優,最后利用優化的SVM分類器對篩選后的樣本數據進行訓練與測試,測試結果得到了理想的效果。綜上,PCA方法不需要對過程機理進行深入了解,通過樣本數據就能建立有效的模型。因此本文提出一種基于主成分分析法的電站鍋爐受熱面灰污監測方法,對電站鍋爐的各個不同受熱面的灰污程度進行實時監測。
1 研究方法
1.1 PCA分析
PCA 的基本思想是數據降維和特征提取,在數學上的本質是找到“合適的”基向量對矩陣進行線性變換,是一種基于線性映射的特征提取技術[27]。通過一定變換將高維數據變換到一個新的低維空間,使高維數據的最大方差投影在第一個低維空間的坐標(即第一主成分分量)上,第二大方差投影在第二個低維空間的坐標(第二主成分分量)上,以此類推[28-29]。PCA 分析將獲取樣本數據以矩陣的形式記錄為X={xij}m×n,m和n分別是該矩陣的行數和列數;將數據劃分為訓練集和測試集;為了避免數據集的不同屬性取值量級變化對數據分析處理的影響,將所有屬性進行標準化。根據訓練集的均值及方差對訓練集進行標準化處理,測試集的標準化處理與訓練集相同。標準化處理的具體過程如下:
首先計算訓練集的協方差矩陣C:

然后對其進行特征值分解,即可求解得到協方差矩陣的特征值特征向量,特征值分解為:

式(2)中,A為特征值構成的對角矩陣(對角元素滿足λ1≥λ2≥… ≥λn);V∈Rm×n為正交矩陣(單位正交化后的特征向量矩陣);P為V的前a列,包含了所有主元信息。計算前a個特征值的累計貢獻率:
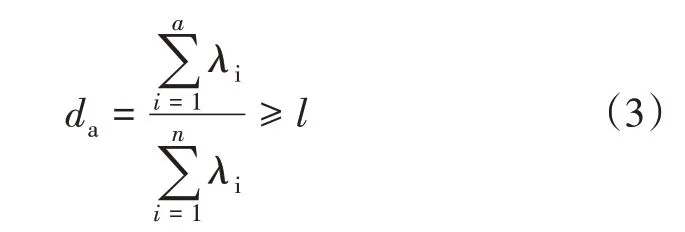
式(3)中,l為累計貢獻率下限,若前a個特征值的累計貢獻率da小于l,則繼續增加主元個數a,直至滿足條件。
1.2 統計量檢驗
對標準化的數據進行統計量校驗,分別計算訓練集和測試集降維后數據的SPE 統計量,并計算訓練集SPE統計量的控制限。表示數據在主元空間和殘差空間投影的變化程度,將其與相應的控制限值進行比較就可以判斷出過程中是否有故障發生[30]。
具體計算公式如下:
SPE統計量的計算公式為:

式(4)中,X為標準化后的訓練集,P為訓練集的協方差矩陣特征值分解后由特征向量的前a列構成的矩陣。
SPE統計量的控制限計算公式為:
將計算好的測試集的SPE統計量與訓練集SPE統計量的控制限進行比較,由此可以判斷對象的故障情況。
2 數據處理及數據分析
本文以某電廠660 MW 燃煤機組的運行數據為例,對其鍋爐受熱面灰污情況進行診斷,并驗證了所提出方法的有效性。機組運行參數的歷史數據從該廠的DCS系統中獲取,數據的采樣周期為1 min,覆蓋機組3個月的運行數據。基于主成分分析法的灰污監測具體流程如圖1所示。

圖1 PCA流程圖Fig.1 PCA flow chart
2.1 數據預處理

2.2 灰污監測結果分析
本文選取與鍋爐積灰結渣相關和受熱面傳熱相關的運行參數。對于對流受熱面、半輻射半對流受熱面和空氣預熱器選擇的運行參數包括負荷、受熱面進出口蒸汽壓力與溫度以及受熱面進出口煙氣溫度等;對于空氣預熱器選擇的運行參數還可以是負荷、給煤率、排煙氧量、進口煙氣壓力、出口煙氣壓力等。對于超臨界與超超臨界鍋爐輻射受熱面(即爐膛水冷壁)選擇的運行參數包括負荷、給水壓力、給水流量、一級減溫水流量、二級減溫水流量、給水溫度、低過入口蒸汽溫度等。對于亞臨界鍋爐輻射受熱面(即爐膛水冷壁)選擇的運行參數包括負荷、給水壓力、給水流量、一級減溫水流量、二級減溫水流量、給水溫度、汽包壓力、汽包水位等。
以某660 MW 電廠屏式過熱器為例,根據機組實際測點,選取機組負荷、屏過進出口蒸汽溫度、屏過進出口煙氣溫度、屏過出口蒸汽壓力6 個運行參數的數據。數據預處理后,由于吹灰器進行吹灰后,受熱面潔凈程度較高,故將吹灰器吹灰后一段時間的數據作為訓練集Xtrain,其中Xtrain∈R35177×7。再選取任意兩天數據作為測試集Xtest,其中Xtest∈R2880×7。對訓練集與測試集進行標準化處理,并進行主成分分析。
分別計算標準化處理后訓練集與測試集的SPE統計量,選擇置信度為95%即α= 0.05 的SPE 統計量控制限Q0.05。當測試集的SPE統計量SPEtest<Q0.05則認為受熱面污染程度較低,暫時不需要進行吹灰,反之若SPEtest≥Q0.05,則認為受熱面污染程度較高,需要進行吹灰。
如圖2 所示,橫軸為采樣數,豎軸為SPE,圖中豎線為吹灰器的吹灰動作,位于上方的曲線為潔凈因子曲線,接近0 的曲線為SPE 曲線,橫線為95%控制限。對同一數據源進行潔凈因子計算,用以對比判斷PCA方法的準確性和有效性。從分析結果來看,PCA 方法得到的SPE 曲線與計算得到的潔凈因子曲線的變化趨勢基本符合規律,即潔凈因子降低時SPE 升高,潔凈因子極小值點附近也即SPE 位于極大值點附近或超過SPE控制限(即SPEtest≥Q0.05)時,此時則應進行吹灰;同時,從圖2中可以看到在第一次吹灰前存在SPE超過控制限的時間段,其潔凈因子也處于下降趨勢,表明在該時間段受熱面的潔凈程度較低,而此時吹灰器并沒有吹灰,存在吹灰不及時行為,降低了受熱面的換熱效果。
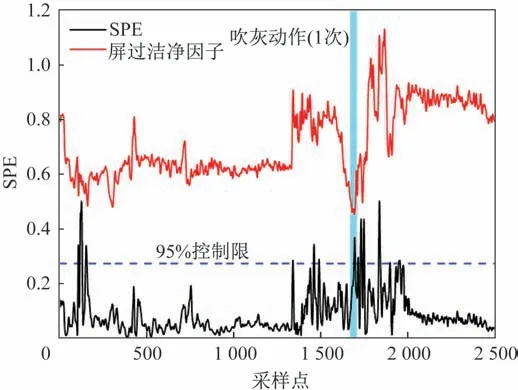
圖2 屏式過熱器PCA法與潔凈因子灰污監測對比Fig.2 Comparison between PCA method of screen superheater and clean factor dust monitoring
同理以低溫再熱器和高溫再熱器為例,根據機組實際測點,選取相關運行參數數據。劃分訓練集及測試集,并對訓練集與測試集進行標準化處理后,進行主成分分析建模。
該電廠高、低溫再熱器的主分析法SPE 統計量與潔凈因子灰污監測對比曲線,如圖3-圖4 所示,可知,PCA方法得到的SPE曲線與潔凈因子曲線的變化趨勢基本相同;同時,從圖中可以看到,吹灰進行之前潔凈因子存在下降趨勢,且SPE曲線位于控制限臨界區域,說明此時吹灰的必要性;但吹灰動作之后,存在SPE曲線超過控制限和潔凈因子較低的采樣點,說明此時受熱面比較臟污,而此時吹灰器并沒有吹灰,反應了前期吹灰效果不理想,后期吹灰不及時的問題,影響了受熱面的換熱效果。綜上可驗證基于主成分分析法對電站鍋爐受熱面灰污監測的有效性,為電廠吹灰提供一定的指導意見。

圖3 低溫再熱器PCA法與潔凈因子灰污監測對比Fig.3 Comparison of low temperature reheater PCA method and clean factor ash pollution monitoring

圖4 高溫再熱器PCA法與潔凈因子灰污監測對比Fig.4 Comparison of high temperature reheater PCA method and clean factor ash pollution monitoring
3 結語
本文針對燃煤機組實際運行數據所提出的數據預處理方法,能有效地剔除運行數據中的異常值,保證了后續PCA 分析時數據的有效性;采用PCA 方法,選擇置信度為95%,即α= 0.05 的SPE 統計量控制限Q0.05作為受熱面灰污情況的判斷依據,通過對比機理建模的潔凈因子,驗證了基于主成分分析法的受熱面灰污監測方法的準確性;由于各個電廠的和鍋爐結構和運行參數測點不一,導致基于機理建模的模型出現計算困難或者不準確的問題。相較于機理建模需要全面而完整的數據,PCA 法可為燃煤電廠提供靈活且可靠的灰污監測結果。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
