基于MPE-ANN-SVM的癲癇腦電檢測分類研究*
2022-02-03 07:02:56石雨菲王瑤胡珊田翔華陳子怡周毅
生物醫學工程研究 2022年4期
石雨菲,王瑤,胡珊,田翔華,陳子怡,周毅△
(1.中山大學 中山醫學院,廣州 510080;2.中山大學 生物醫學工程學院,廣州 510006;3.新疆醫科大學 醫學工程技術學院,烏魯木齊 830011;4.中山大學附屬第一醫院,廣州 510080)
引言
癲癇(Epilepsy)是一種由大腦神經元集群高度同步化異常放電引起的反復性發作的神經系統疾病[1],嚴重影響患者正常生活。目前癲癇患者在全球范圍內近6 500萬[2-3],其中約有30%的癲癇患者無法通過藥物治療得到有效控制,被稱為藥物耐受性癲癇患者[4-5]。在藥物耐受性癲癇患者中,有25%可以通過致癇灶切除術進行治療[5-6],部分患者可接受生酮飲食或神經調控,而其余癲癇患者的發作性癥狀尚無任何合適的治療手段可以控制[7]。
腦電信號(electroencephalography,EEG)是記錄大腦電活動的無創方式,能夠監測癲癇發作時大腦的異常放電現象,對其發作進行預測[8]。利用計算機技術分析EEG信號實現癲癇發作的檢測研究,可有效輔助醫生對藥物耐受性癲癇患者進行治療和控制,對臨床癲癇治療具有重大意義[9-10]。然而現有模型泛化性及魯棒性不足,且對于臨床真實數據的研究不夠深入。為緩解上述問題,本研究利用多尺度排列熵、人工神經網絡與支持向量機方法設計MPE-ANN-SVM模型應用于癲癇腦電分類。該模型使用多尺度排列熵[11]與人工神經網絡來提取腦電信號特征,使用支持向量機[12]和人工神經網絡[13]兩種機器學習算法對提取到的特征進行分類。
1 方法
1.1 多尺度排列熵
多尺度排列熵為多個尺度下的排列熵,能夠反映信號隨機性與復雜性[14]。多尺度排列熵的計算方式為:將長度為N的時間序列X=(x1,x2,x3…,xn),經過粗粒化后,求其排列熵[15]。具體的計算步驟如下[16]:
對時間序列X=(x1,x2,x3…,xn)粗粒化處理,得到
(1)
其中,j=1,2,…,[N/s],[N/s]為N/s向下取整,s為尺度因子。
對粗粒化后得到的序列重構有:
Yl(s)={yl(s),yl+1(s),…,yl+(m-1)λ(s)}
(2)
其中,m為嵌入維數,λ為延遲時間,l為重構分量且l=1,2,…,N-(m-1)λ。
將式(1)-(2)升序排列,每一個粗粒化序列都 能得到一組新的序列s(v)=(l1,l2,…,lm),其中v=1,2,…,V。V≤m!,s(v)的數目與重構序列m!的數目一致。
計算不同尺度下的排列熵:
(3)
其中,pv為第v次符號序列出現的概率。
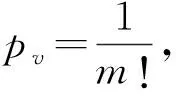
(4)
HP的值越小,該時間序列越有序,腦電信號復雜性降低;值越大時,該時間序列的規律性越弱,腦電信號復雜性升高。
1.2 人工神經網絡分類器
人工神經網絡是由具有適應性的簡單神經元組成的廣泛并行互連的網絡,能夠模擬生物神經系統對真實世界物體所作出的交互反應[17]。神經元作為神經網絡的基本組成單元,具有溝通信息的作用[18]。神經元結構見圖1。
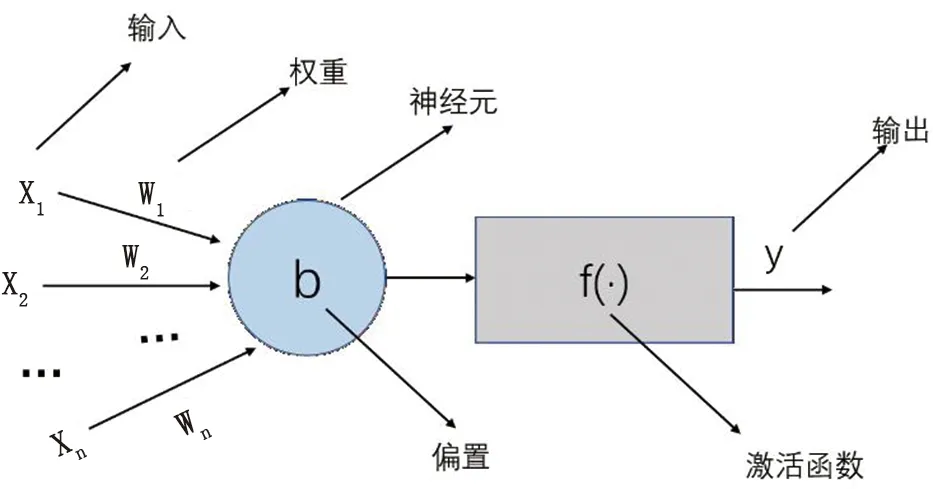
圖1 神經元結構示意圖
感知機是由一個神經元組成的模型,而多個神經元交織在一起則生成神經網絡模型。神經元的主要參數是權重矩陣和偏置矩陣,網絡學習過程就是不斷更新神經元內部的參數,使其輸出預測值與實際值之間的誤差盡可能小[19]。
神經網絡一般由三個部分組成:輸入層(Input Layer),隱含層(Hidden Layer),輸出層(Output Layer)。其中輸入層負責接收外部信息;隱含層則是神經網絡的核心,負責對輸入層接收到的信息進行學習,并且在學習過程中不斷更新權值(Weight)和偏置(Bias);輸出層負責輸出結果[20]。
將輸入層X=(x1,x2,x3,...,xn)和權重矩陣W=(ω1,ω2,...,ωn)兩者相乘并加上偏置函數b之后,輸入隱含層中,可以得到非線性激活函數σ,計算公式如下:
(5)
輸出Y在非線性函數激活之前的步驟僅為線性組合,對于復雜問題難以找到合適的最優解,而非線性更接近客觀事物性質本身,能夠表達變量間的相關性,因此,引入非線性函數可得到模型最優解。通過使用非線性函數,可將數據特征映射至一個非線性系統,得到更多的原始信息,由輸出層得出:
Y=σ(v)
(6)
1.3 支持向量機分類器
支持向量機(support vector machine,SVM)是Cortes和Vapnik于1995年對線性分類器提出的一種最優準則設計[21-22]。SVM能夠較好地解決小樣本、高維性等問題,其基本思想可以總結為:在特征空間內尋找一個用于分類樣本的最佳超平面,該平面可正確分類樣本,同時也能使得各樣本集距離該平面的間隔最大,分類器的泛化性能也因此特性較好[23]。具體算法如下[24]:
用一個維度為n的向量x來表示數據點,用y取值-1或1將兩種類別區分開來。區分的平面其方程可以表示為:
wTx+b=0
(7)
基于該平面將兩類數據分隔,定義函數f(x)為:
f(x)=wTx+b
(8)
若f(x)=0,數據點的位置剛好在超平面上;f(x)<0,則對應y=-1的數據點;f(x)>0,則對應y=1的數據點。根據上述規則選擇完最優分類面后,使用新數據測試分類效果。測試時,定義f(x)為:
(9)
式中,λi為拉格朗日因子,且滿足條件λi≥0和yi(w,φ(xi)+b)=1。K(xi,x)為核函數。
2 實驗
2.1 實驗數據集
實驗數據來自于新疆某三甲醫院神經科腦電圖室的癲癇患者。患者入組嚴格遵循部分性(發作)癲癇患者的入組標準。所采集的癲癇患者處于靜臥狀態來減少肢體活動對腦電信號的干擾。數據采集設備為尼高力(NicholetOne)腦電圖機。腦電數據為24長程視頻頭皮腦電圖,用雙極導聯法同步記錄22導波形。數據采樣頻率為500 Hz。相關癲癇發作事件起始已在腦電數據中由經驗豐富的臨床專家進行標注。本次實驗數據信息見表1。
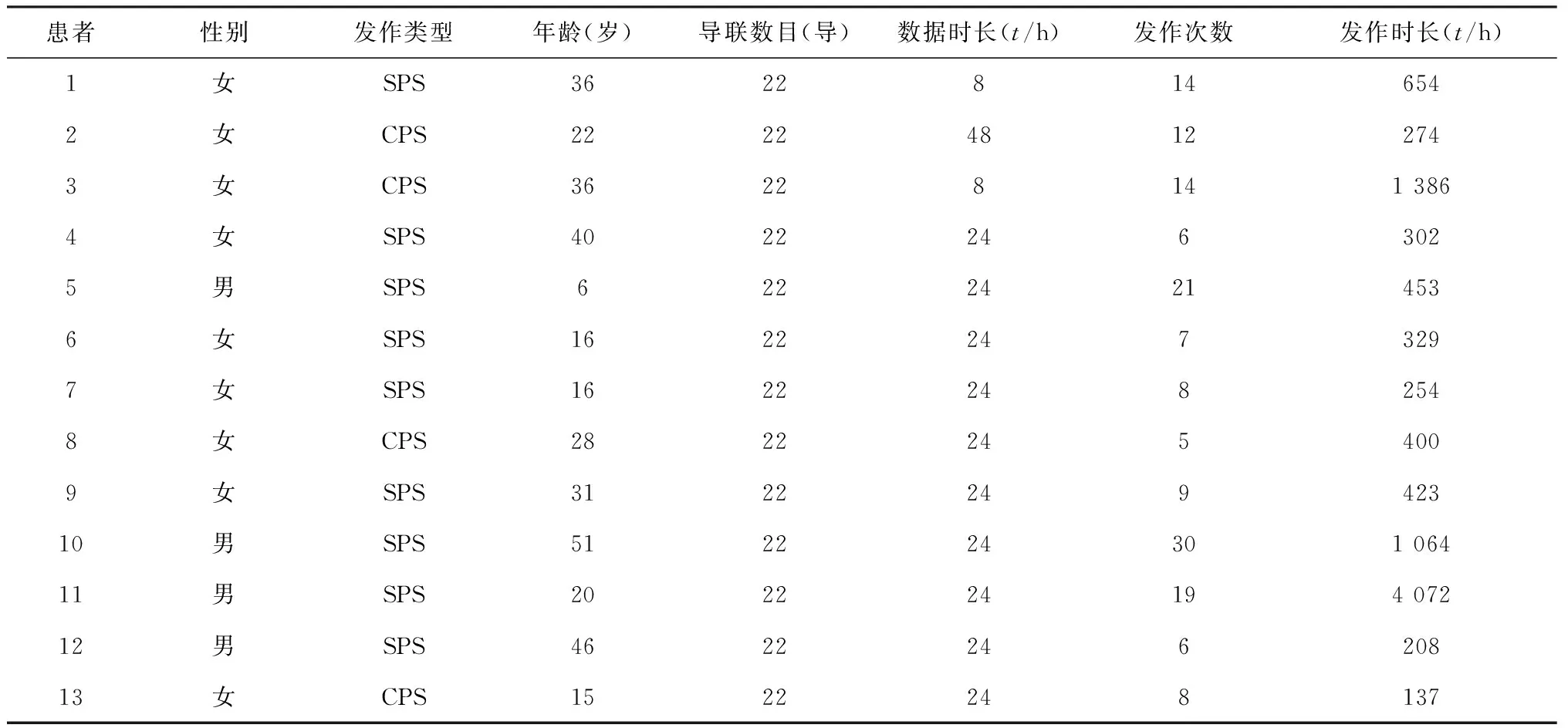
表1 實驗數據信息說明
本次實驗樣本包含13名患者,其中4名男性患者,9名女性患者,患者的年齡區間跨度為6~51歲,能夠增強模型的泛化能力。本次實驗腦電圖記錄的總持續時間在360 h左右,數據中的癲癇發作起始點和終止點由臨床癲癇專家所標記。13位患者共計159次發作,平均每人發作12次。選取完數據后,經過計算,可得發作期的持續時間為9 960 s(166 min左右)。
經研究表明,由于發作前期無固定的時間選擇,發作前期數據一般由人為設置,一些研究選擇固定發作前期持續時間為20~90 min,本研究將發作前期腦電數據定為發作前半個小時的腦電信號。對于發作期數據的選取,根據臨床專家標注的癲癇腦電數據,選取發作期腦電數據全集。最后形成分類的初步樣本庫。
2.2 實驗過程
2.2.1實驗設計概述 本研究設計的檢測結構見圖2。先由2.1中所述的患者信息提取原始腦電信號,得到數據集A。基于數據集A,使用多尺度排列熵提取信號特征,最終得到非線性數據集A1,該數據集包括5 457條發作前期信號特征和3 876條發作期信號特征。使用一個隨機數函數,隨機提取2 000條發作前期數據集A2-1和2 000條發作期數據集A2-2作為訓練樣本庫,訓練模型。剩余數據為測試數據樣本庫。
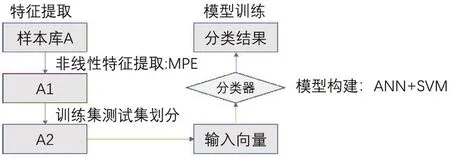
圖2 自動檢測識別分類結構
2.2.2多尺度排列熵特征值提取 為提高模型準確率,獲取腦電信號的有效特征,本研究對信號采取進一步處理,將計算非線性動力學特征指標的數據跨度設置為5 000個點,每10 s滑動提取一次特征值。同時對于不足5 000個點的數據,設置為1 000個點的方式提取,而超出5 000個點的數據則進行分段提取。本研究選取多尺度排列熵來獲取癲癇的非線性動力學特征。
患者在癲癇發作過程中,神經元集群會大量同步放電,使得原本復雜的腦功能有著不同程度的抑制[25]。經實驗驗證發現,從發作前期到發作期,多尺度排列熵表現為有不同程度的陡升陡降。本研究通過提取1號患者T3、T5、P3、O1導聯上的一次發作過程信號來描述多尺度排列熵在發作過程中的變化情況(見圖3)。
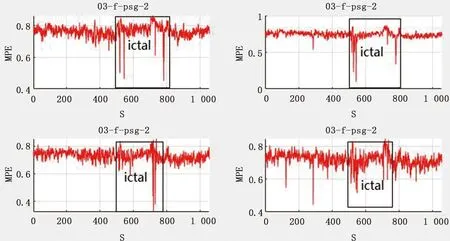
圖3 多尺度排列熵在發作過程中的變化規律Fig.3 Variation rule of multi-scale permutation entropy during seizure
最終,經過特征提取得到5 457條發作前期信號特征和3 876條發作期信號特征。
2.2.3模型訓練 由于SVM具有較好的泛化能力,而ANN不僅能夠有效提取信號特征,還具有更好的魯棒性,因此,本研究結合SVM與ANN提出一種新型網絡結構以實現癲癇的檢測識別,該模型具體的網絡參數信息見表2。
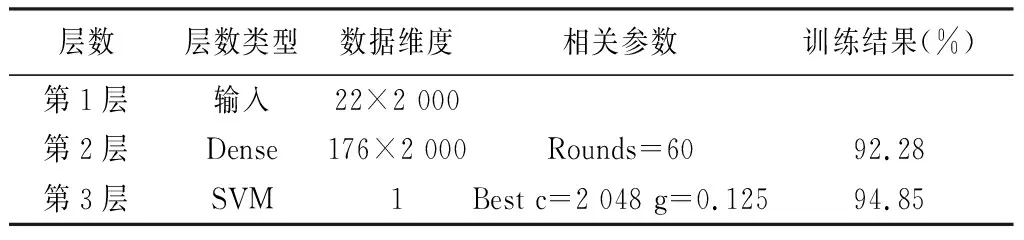
表2 ANN+SVM網絡結構
將傳統神經網絡的輸出層改為SVM,即將經過一次線性變換的數據送入SVM分類器中。經實驗發現,使用一層簡單Dense層的結果最優。
基于2.2.1中給出的自動檢測識別模型,將經多尺度排列熵提取特征值后的全導聯數據集A2-1和A2-2輸入至表2中的網絡進行訓練,即2個22×2 000的數據集。從第2層Dense層后,將176×2 000維的數據取出為A3,再將A3放入SVM分類模型訓練。將神經網絡中的訓練輪次設為60次后,送入SVM分類器中進行測試。結果顯示,模型準確率能夠達到94.85%。ANN層學習過程見圖4。
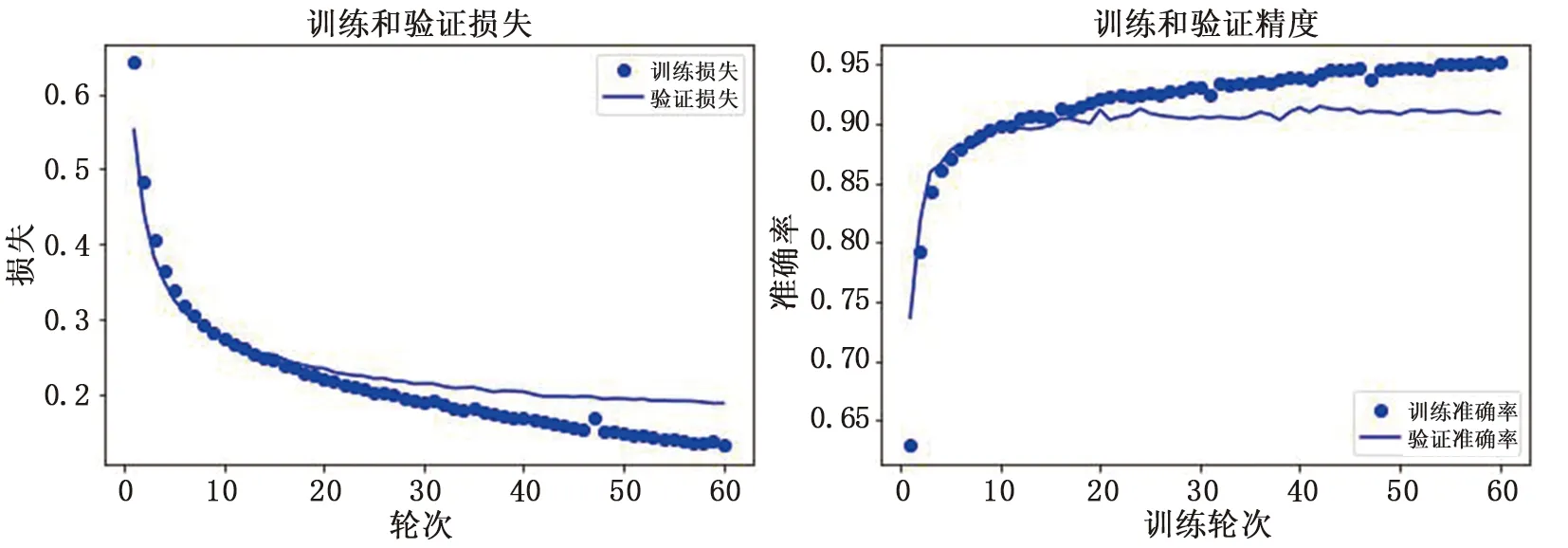
圖4 ANN中間模型 Fig.4 ANN intermediate model
2.3 評價指標與實驗結果
為驗證MPE-ANN-SVM模型的有效性及優越性,研究用敏感性(sensitivity,Sen)、特異性(specificity,Spe)與識別準確率(accuracy,Acc)三個參數作為評價指標。其中,Sen用于評價模型對發作期腦電數據的識別能力,Spe用于評價模型對發作前期腦電數據的識別能力[26],Acc用于評價測試數據與標注數據間的接近程度。具體公式表示如下:
(10)
其中,TP為真陽性,FP為假陽性,TN為真陰性,FN為假陰性。
為驗證本研究算法的泛化性能,探究不同方法對算法的影響,本研究將多個方法進行拆分,采用消融實驗來驗證各方法對 MPE-ANN-SVM 的貢獻,驗證結果見表3。
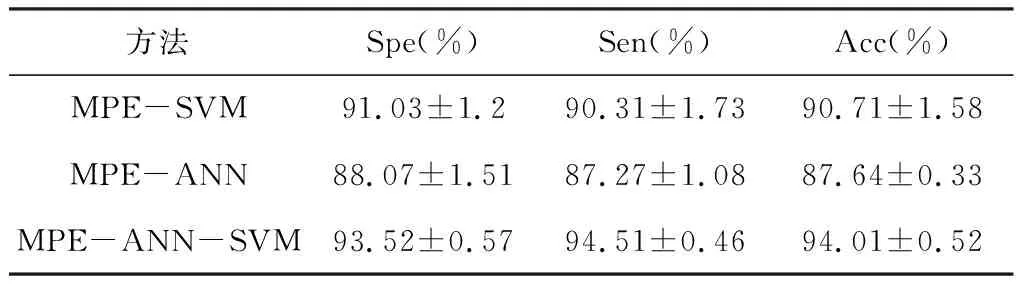
表3 分類檢測結果對比Table 3 Comparison results of classification detection
由表3可知,與單一的分類器相比,由于有效地結合了神經網絡分類器能提取更多有效信息和支持向量機泛化性能較好的優點,MPE-ANN-SVM模型具有更高的識別準確率、敏感率及特異率,能夠更好的應用于癲癇診斷。
3 結論
本研究基于MPE方法、ANN及SVM分類器設計了一種能夠有效實現癲癇分類識別的MPE-ANN-SVM模型。經驗證,該模型不僅具有良好的泛化性能及魯棒性,還能得到較好的識別準確率。其中,MPE方法能夠更好地提取原始腦電信號特征,ANN與SVM分類器具有較好的檢測識別性能,三種方法相結合能夠提高癲癇的識別效果。為提高模型準確率,本研究在實驗數據集上進行了部分處理,但研究仍是針對小群體患者進行,缺乏大量對比數據,后續還需加入更多的癲癇患者數據,豐富數據集并優化算法模型,得到更加豐富的特征,同時提高模型性能。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中國民間療法(2021年5期)2021-06-09 09:21:04
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
飲食科學(2017年5期)2017-05-20 17:11:53
光學精密工程(2016年6期)2016-11-07 09:07:19
西南軍醫(2015年4期)2015-01-23 01:19:30
