基于深度學習的網絡異常檢測和智能流量預測方法
2022-02-11 09:32:26張嬌陽
無線電通信技術 2022年1期
張嬌陽,孫 黎
(西安交通大學 信息與通信工程學院,陜西 西安 710049)
0 引言
異常檢測[1-2]和流量預測是無線網絡數據分析和管理中的重要任務,有利于提高網絡的智能化管理水平,實現網絡資源的優化分配和按需調度。在邊緣計算場景下,異常檢測和流量預測任務在距離數據源更近的位置——基站進行計算,以減少移動業務交付的端到端時延,發掘無線網絡的內在能力,從而提升用戶體驗。
現有的異常檢測研究工作中,監督學習和無監督學習算法已被廣泛應用于流量異常檢測研究中。基于有監督學習的異常檢測方法依賴于已標記網絡正常行為的數據集,然而在實際應用中,沒有異常的數據集非常罕見并且獲得代價昂貴。無監督學習的異常檢測方法中,K均值(K-means)聚類方法[3-4]由于其簡易性,被廣泛應用到異常檢測任務當中。基于 K-means 聚類的異常檢測方法通過將數據劃分為正常流量集群和異常流量集群的方式來檢測異常。但是,該異常檢測的方法依然存在一些問題,直接利用聚類算法檢測異常可以檢測到高流量區域的異常,但會忽略低流量區域存在的異常。另外有基于流量模式的K-means聚類的異常檢測方法[5],在大規模長時間序列檢測問題中,存在處理區域數量有限、處理數據時長有限等缺陷。
現有的流量預測研究工作中[6],基于統計的方法將無線網絡流量預測視為時間序列預測問題,其性能取決于利用哪一種統計模型進行建模,常用的模型包括回歸移動平均(ARIMA)、α穩定模型等,但這些基于統計的模型無法同時建模多種因素的影響。為了挖掘無線網絡流量數據中隱藏著的復雜依賴性關系,深度學習模型被應用到無線網絡流量預測中。文獻[7]提出了一種基于深度學習的混合模型進行時空流量預測,采用自編碼器建模空間依賴性,同時采用長短期記憶網絡建模時間依賴性。但是這種建模方式是有損的,而且需要對每個區域分別進行建模,無法同時獲得預測結果。文獻[8-9]采用卷積神經網絡方法進行建模,可以實現用一個模型對無線網絡流量進行預測。然而,空間依賴性不能只局限于與目標位置相鄰的區域,以市中心的大學和郊區的大學為例,兩個地區屬于地理位置不相鄰的同種功能區,流量模式存在強相關性,如果僅能學習相鄰區域的相關性,會缺失如上例所述的非相鄰但功能相同的區域間的重要信息,導致學習效果不佳。上述基于卷積神經網絡的研究工作僅能捕獲目標區域相鄰的局部區域的相關性,不能捕獲全局的空間依賴性。非局部神經網絡(NLnet)預測方法對全局空間相關性進行建模,但是忽略了不同通信數據間的相關性。
針對異常檢測和流量預測任務面臨的上述問題,本文提出一種基于特征降維的異常檢測方法和多數據集聯合預測的移動網絡流量預測方法。基于特征降維的異常檢測方法首先在全局范圍內提取所有區域流量特征,利用特征數據鎖定可疑異常出現的網格,再分別對出現可疑異常警報網格中的原始流量數據使用K-means聚類方法進行局部異常檢測,本方法可以快速準確檢測大規模流量數據的可疑異常,更適用于規模大、持續時間長的蜂窩網絡數據。在多數據集聯合預測的移動網絡流量預測方法中,引入注意力機制學習各個時刻不同業務間的相關性,并利用循環神經網絡記憶這種相關性,進一步提高了流量預測的準確度,適用于對歷史數據量少、相關業務數據多的活動進行預測。
1 系統模型和數據集描述
1.1 系統模型
系統模型由邊緣計算網絡架構組成,如圖1所示[10],邊緣計算架構分為終端設備、邊緣、云端三層。終端層由各種設備組成,主要完成收集原始數據并上報的功能,以事件源的形式作為應用服務的輸入。邊緣計算層由網絡邊緣節點構成,廣泛分布在終端設備與計算中心之間,邊緣計算層通過合理部署和調配網絡邊緣側的計算和存儲能力,實現基礎服務響應,邊緣計算層的上報數據將在云計算中心進行永久性存儲。本文的異常檢測和流量預測功能依托邊緣計算下沉到基站完成。

圖1 邊緣計算網絡架構Fig.1 Edge computing network architecture
1.2 數據集描述
本文使用的蜂窩流量數據集由意大利電信移動公司提供[11],該數據集是大數據挑戰賽的一部分。原始數據集收集了整個米蘭城市內每隔10 min的手機活動記錄(62天, 300百萬條記錄,大約19 GB)。米蘭市的面積為550 km2,根據基站分布情況,被劃分為100 × 100正方形網格。每個正方形網格的大小約為0.235 km×0.235 km,在本節中每一個正方形網格被稱為網格或網格區域。米蘭市的部分網格區域如圖2所示。
在原始數據集中,每條手機流量活動記錄均由以下條目組成。
① 網格編號(Square ID):對已劃分網格的編號;
② 時間戳(Time-stamp):每一條手機流量活動的時間戳;
③ 接收短消息活動量(SMS-in Activity):某一特定網格內每10 min內接收的短消息活動流量值;
④ 發送短消息活動量(SMS-out Activity):某一特定網格內每10 min內發送的短消息活動流量值;
⑤ 接聽電話活動量(Call-in Activity):某一特定網格內每10 min內接聽的電話活動流量值;
⑥ 撥打電話活動量(Call-out Activity):某一特定網格內每10 min內撥打的電話活動流量值;
⑦ 互聯網活動量(Internet Activity):某一特定網格內每10 min內互聯網接入活動流量值;
⑧ 國家代碼(Country Code):電話國家代碼。
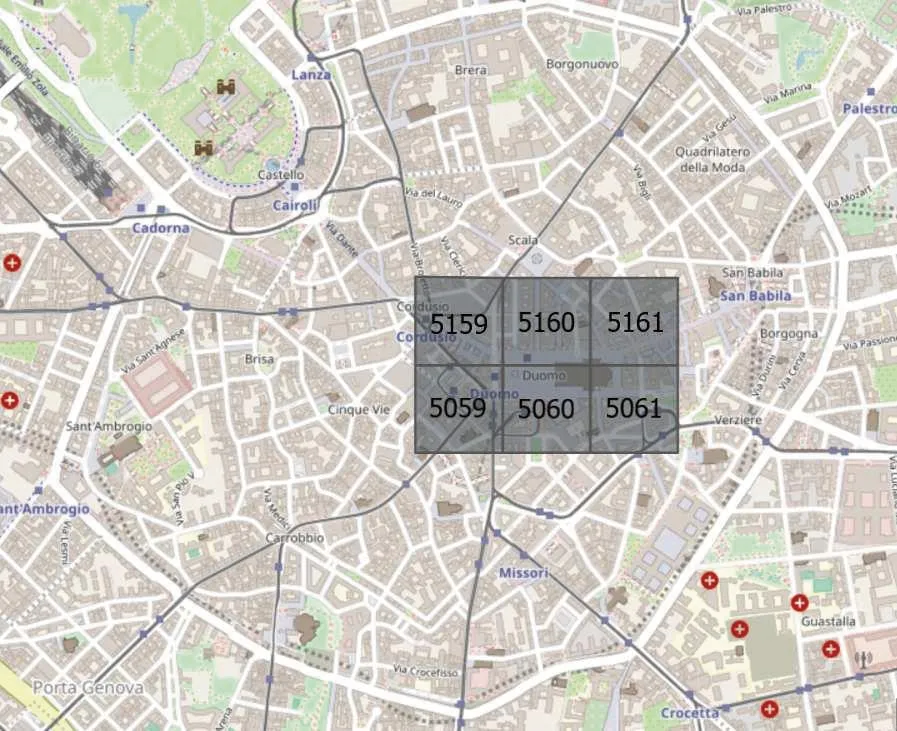
圖2 米蘭部分網格區域Fig.2 Part of the grid area in Milan
2 基于特征降維的網絡流量異常檢測方案
2.1 基于長短期記憶自編碼器的流量特征提取與異常網格標識
在大規模蜂窩數據異常檢測任務中,由于數據收集覆蓋范圍大,流量數據持續時間長,直接在全局范圍對原始數據進行異常檢測會花費大量時間,消耗計算機資源。所以在全局范圍內異常檢測前需要對流量數據進行合理的降維處理,提取高維流量數據的特征,便于獲取全局范圍內的異常信息。
蜂窩流量數據記錄了不同時刻各個網格的流量值,相鄰時刻流量值具有強相關性,為了有效提取這種相關性,這里使用長短期記憶(Long Short Term Memory,LSTM)自編碼器對原始蜂窩流量數據提取流量特征,使用這一模型可以更好地學習歷史時間序列的相關性,同時提取蜂窩流量數據的流量特征,模型框圖如圖3所示。
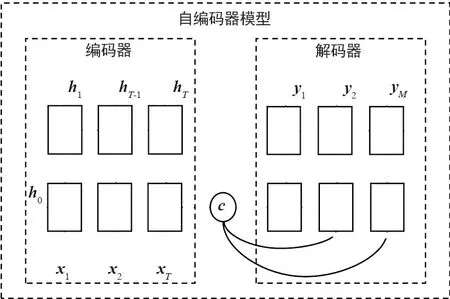
圖3 LSTM自編碼器結構Fig.3 LSTM autoencoder structure
其中,LSTM的網絡結構是鏈式循環的結構[12],能夠用來處理長時依賴的問題,一個方塊代表一個時刻的LSTM單元,包括3個門:輸入門、遺忘門、輸出門。輸入門控制著網絡的輸入,遺忘門控制著網絡的記憶單元,決定之前的哪些記憶將被保留,哪些記憶將被去除,輸出門控制著網絡的輸出。
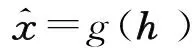
(1)
式中,N代表x的維度,下標i代表向量的第i個分量。
為了保證隱變量h中信息的有效性,在構建自編碼器時,通常限制隱變量h輸入的維度小于輸入數據x的維度,這使得編碼器能夠完成數據壓縮的任務。
經過LSTM自編碼器可以得到蜂窩流量數據的低維特征,在新的低維空間找到與整體數據樣本表現出來的特點不一致的數據點標記為可疑異常,鎖定可疑異常出現的網格,下一步對所有可疑異常出現的網格進行局部異常檢測。
2.2 異常流量檢測
通過上一步使用LSTM自編碼器獲得新的蜂窩流量特征,在新的特征空間發現可疑異常出現的網格。獲取到所有異常可能出現的網格后,在每個可疑異常出現的網格中對原始數據進行聚類檢測異常,將聚類結果中流量值大且同一類中樣本數少的樣本標記為異常數據。
這里選擇K-means[13]進行異常檢測,與其他聚類方法相比,K-means算法的時間復雜度更低,占用的計算資源更少,因此,這里選用 K-means算法檢測可疑異常。應用該算法時,首先采用戴維森堡丁指數(DBI)確定聚類集群的最佳數目,DBI定義為:
(2)
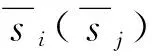
(3)
mi,j=‖ai-aj‖2,
(4)
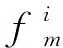
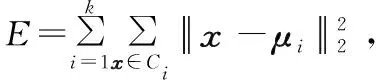
(5)

將數據集中的樣本劃分為若干不相交的子集,每個子集為一個“簇”,通過這樣的劃分可以尋找出異常數據對應的簇。最后,因為異常流量值與正常流量值有很大的差異,所以異常流量樣本將組成單獨的集群,將具有最少樣本數量且流量值數量級別最高的集群認定為異常。
3 基于注意力機制的多數據集聯合預測方案
本節使用經過上述方法剔除異常后的5種數據,包括互聯網數據、接聽的話音業務數據、撥打的話音業務數據、接收的短消息業務數據和發送的短消息業務數據,然后利用互聯網數據和其余業務數據的相關性預測未來的互聯網數據。預測模型如圖4所示,首先將各類業務分別輸入相同的循環神經網絡中,記錄各時刻的輸出,然后將同一時刻所有業務數據在循環神經網絡(RNN)單元的輸出輸入到注意力單元中,計算當前時刻其余業務與目標業務的相關性,各個時刻依次進行相同操作,最后一個時間節點目標業務的輸出即為流量預測的結果。
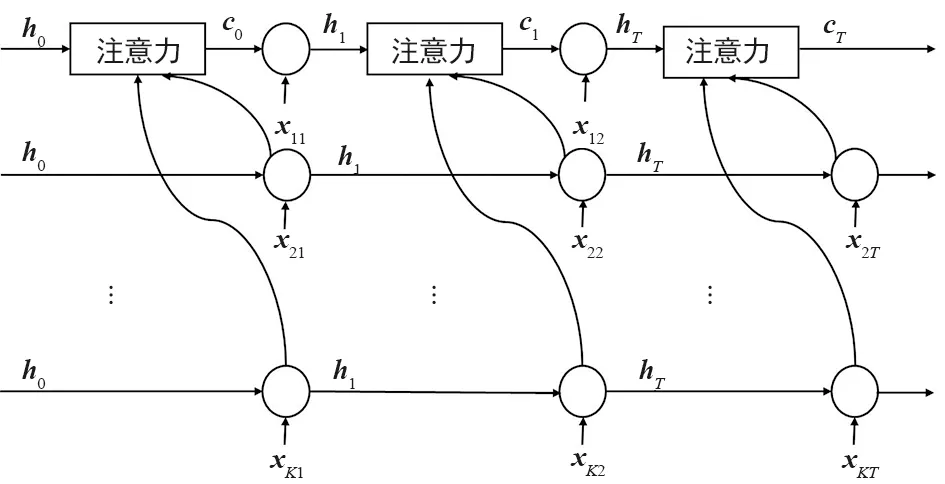
圖4 基于注意力機制的多數據集聯合預測方案Fig.4 Multi-data set joint prediction scheme based on attention mechanism
以第一個時刻為例,注意力單元內部結構如圖5所示。
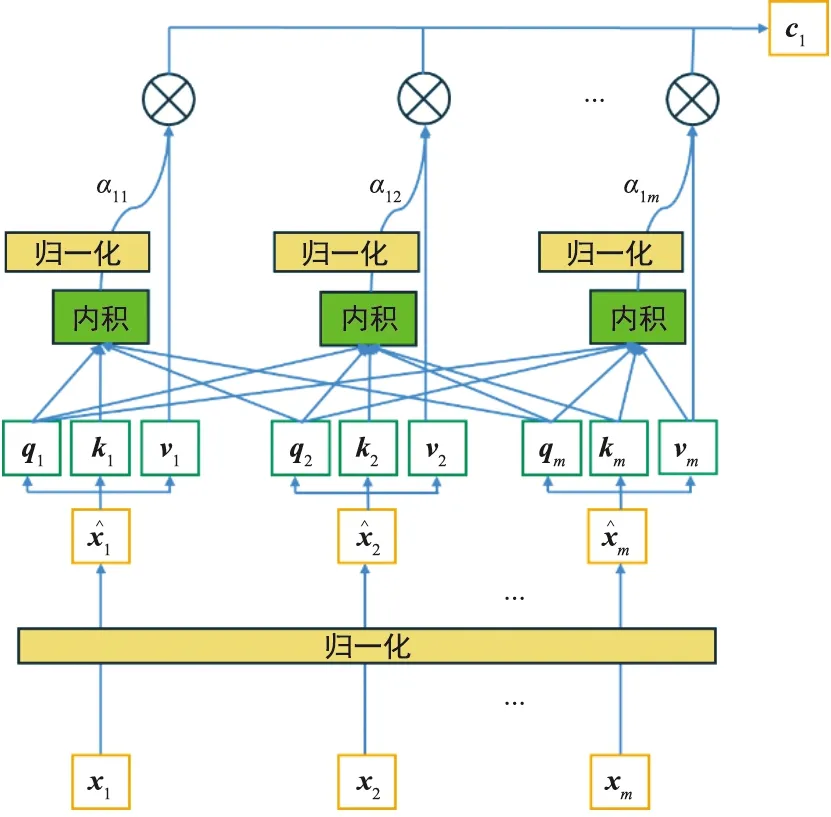
圖5 注意力模塊內部結構Fig.5 Internal structure of attention module
為保證模型訓練正確,將輸入模型的數據分別進行歸一化,接下來生成查詢張量qj、鍵張量kj、值張量vj,考慮到預測目標是互聯網數據,所以僅需要對互聯網數據生成查詢張量qj。然后根據查詢張量qj和鍵張量kj計算不同數據的相似度α1m。
(6)
最后使用相似度張量和值張量做乘法得到自注意力機制的輸出。
4 實驗結果
4.1 數據預處理
流量數據根據數據集可知,每個流量活動值(SMS-in Activity,SMS-out Activity,Call-in Activity,Call-out Activity,Internet Activity)表示某一網格在10 min內所有用戶的通信強度。在實驗中,為了避免數據稀疏,首先將每條流量活動記錄的5種活動值相加為一個值,該值描述一個網格內所有用戶的總活動量。然后,將數據時間間隔由10 min匯總到1 h。因此,本文中所需檢測的異常確切指代高于正常模式的流量值。
4.2 評估指標
為全面評估不同的異常檢測算法,將本文異常剔除方案與其他異常剔除方案進行流量預測對比。流量預測過程中,采用了2個評價指標進行評價。
第一個是均方根誤差(RMSE),這是度量模型預測值和真實值之間平方差的指標。定義為:
(7)
第二個是平均絕對誤差(MAE),這是度量預測值與真實值之間絕對誤差的指標,定義為:
(8)
4.3 基準方法
為了證明所提出異常檢測效果優越性,將基于特征降維的異常檢測方法、經典K-means聚類方法以及基于流量模式的異常檢測3種方法進行性能對比。分別對經過3種異常檢測方法剔除異常后的流量數據分區域進行預測,輸入歷史記錄中168 h的流量預測未來84 h的流量值,在預測過程中,采用如下的基準方法。
(1) 線性回歸模型
回歸問題中最簡單的模型,模型的具體表示形式如式(9):
y=wTx,
(9)
式中,x代表輸入的歷史流量數據,w代表要學習的參數。
(2) 支持向量回歸模型
支持向量回歸(Support Vector Regression,SVR)[14]是支持向量機一個重要分支,其思想在于尋找一個超平面使得所有樣本點到其距離最小。
(3) 長短期記憶網絡
LSTM網絡是深度學習常用模型之一,通過加入門機制解決傳統循環神經網絡中梯度爆炸和梯度消失的問題,常用于解決有關序列預測和分類的問題。
以上所有模型均取在測試集上表現最好的結果和本文所提出的方法進行比較。
4.4 結果及討論
4.4.1 異常檢測結果
特征降維后的數據可視化結果如圖6所示,可以看到異常蜂窩網絡數據的特征向量會與正常蜂窩網絡數據的特征向量分離,分別記為異常簇和正常簇。
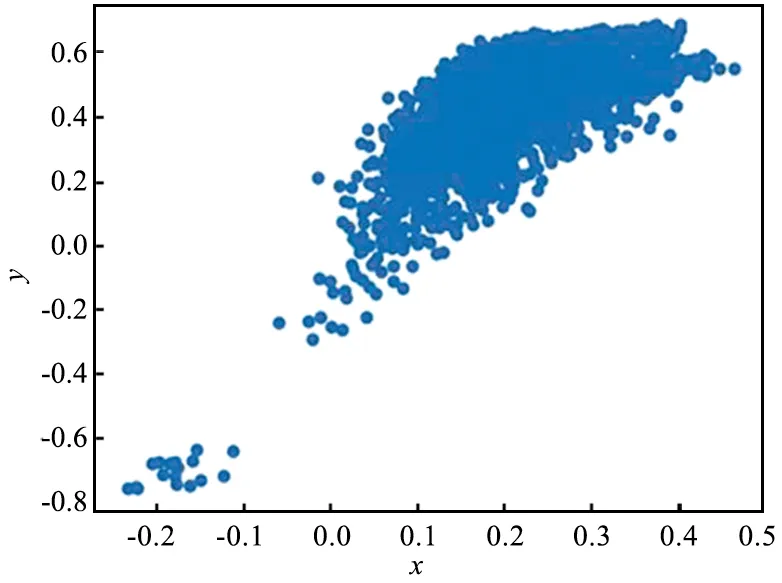
圖6 特征空間樣本分布Fig.6 Feature space sample distribution
可視化異常簇中出現的網格中的流量數據,以網格3667、3983、4181、4621為例,結果如圖7所示。可以看到流量數據整體呈現周期性分布,部分時刻會出現與常規模式不一致的極大值。將這些網格區域標記為可疑異常網格。然后對所有異常網格中的數據使用K-means算法,檢測可疑網格中異常出現的具體時刻,結果如圖8所示,檢測到了可疑網格中出現的流量突增異常。
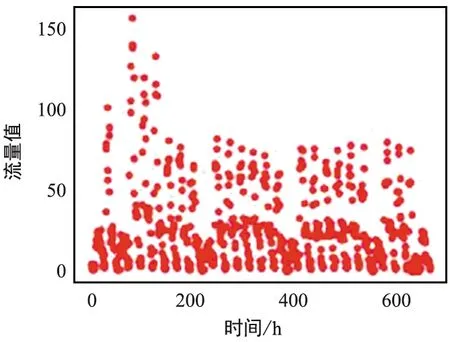
(a) 網格3667
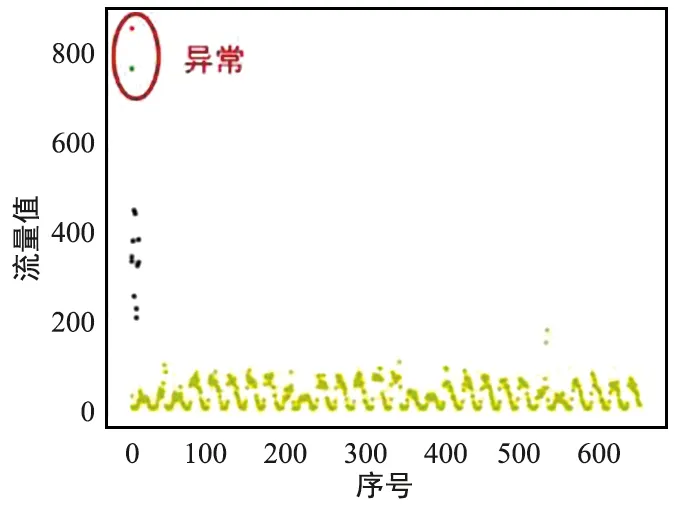
(a) 網格3667
獲得異常網格和異常出現的具體時刻后,為了驗證異常檢測的準確度,對通過該方案剔除異常后的數據進行流量預測,與使用其他異常檢測方法剔除異常后的流量預測效果進行對比,結果如表1所示。

表1 3種異常檢測方法在高、低流量區域內性能比較
經典的K-means算法將均值最大的簇標記為異常樣本,這些異常樣本中也包含部分未發生異常的高流量網格,所以使用該法剔除異常后的數據預測誤差在高流量地區小,在低流量地區大。基于流量模式的異常檢測方法在高、低流量地區異常檢測性能均不是最佳。基于特征降維的異常檢測方法通過訓練得到特征向量,可以排除虛假異常,快速、準確檢測到不同流量地區的異常。總而言之,在高流量區域,所提方案可以有效檢測出可疑異常,在低流量區域本方案可以以更高的準確度進行流量預測。
4.4.2 流量預測結果
使用上節所述方法,對5種業務數據分別剔除異常后,采用基于注意力的多數據集聯合預測方法和RNN預測方法進行對比試驗。表2為這兩種方法在RMSE和MAE上的預測效果。圖9(a)~圖9(c)為基于注意力機制的多數據集聯合預測方法對不同時長的流量數據的預測結果圖,圖9(d)~圖9(f)為基于RNN預測方法對不同時長的流量數據的預測結果圖。橙線為真實數據,藍線為預測數據,可以看到RNN預測方法可以準確預測流量數據周期性等大體趨勢,但是無法精準預測流量的細節,缺少對具體時刻流量值的信息預測。采用基于注意力的多數據集聯合預測方法的預測結果不只顯示數據的周期信息,而且在峰值處可以更準確地預測數據,對未來48 h、72 h、168 h的流量數據預測結果對比均顯示了該方法的有效性。
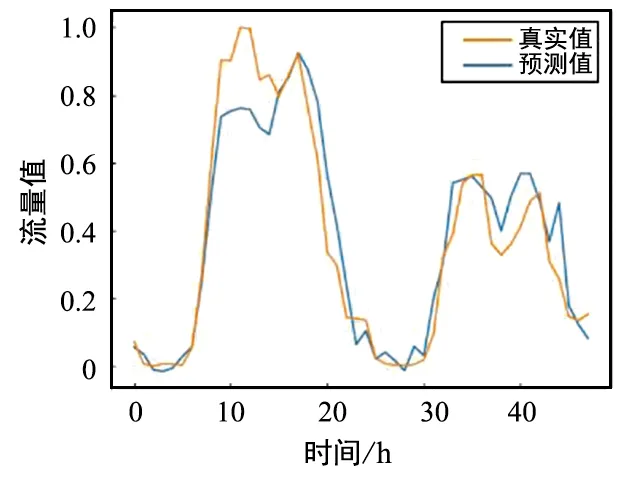
(a) 多數據集聯合預測模型預測未來 48 h流量值
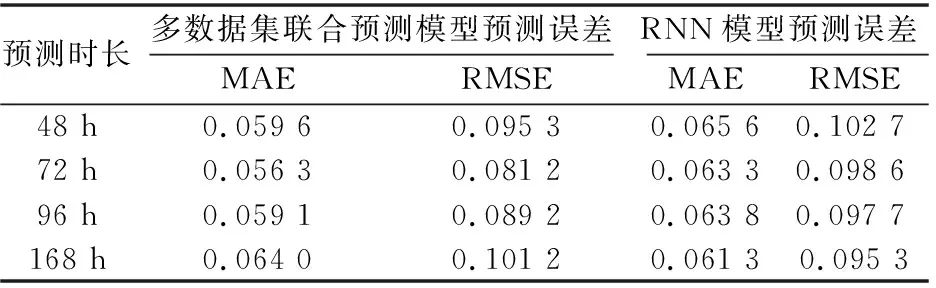
表2 兩種預測方法對不同時長數據的預測性能比較
由于訓練時長為168 h,所以當預測時長小于168 h時,多數據集聯合預測模型預測誤差在RMSE和MAE兩個指標上均小于RNN。利用注意力模塊可以學習目標業務數據與其余業務數據的相關性,充分利用業務間的相關性輔助目標業務預測,不僅可以預測流量數據變化周期,還可以更精準預測不同時刻流量值。
5 結束語
針對大規模蜂窩流量數據異常檢測中直接對原始數據進行檢測存在的數據冗余和計算冗余的問題,為減少移動業務交付的端到端時延,實現網絡資源的優化分配,提出了基于特征降維的蜂窩流量數據異常檢測方法。該方法利用LSTM自編碼器提取流量數據低維特征,再對新的特征空間進行理論分析,選取異常特征參數挖掘異常數據,實現針對大規模高維流量數據的異常檢測功能。該方法可以更好地檢測出高、低不同活躍度區域內的漏報異常;針對流量預測中存在的忽略不同通信數據間相關性的問題,提出基于注意力機制的多數據集聯合預測方案,將提出的流量預測方法與基準預測方法在不同時長預測任務中進行對比實驗,所提出的流量預測方法在RMSE和MAE性能指標上都獲得了最好的性能表現,從而證明了所提出方法的有效性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
