基于改進的加權補集樸素貝葉斯物流新聞分類
2022-02-15 07:13:48許英姿任俊玲
計算機工程與設計 2022年1期
許英姿,任俊玲
(北京信息科技大學 信息管理學院,北京 100192)
0 引 言
常用文本分類算法主要有樸素貝葉斯[1](Naive Bayes,NB)、支持向量機[2](support vector machine,SVM)和K近鄰[3](k nearest neighbor,KNN)等。NB算法以其計算效率高、精確度高且穩定性強的特點,成為常用的文本分類算法之一。縱觀國內外學者使用NB算法對專業領域的文本進行分類的研究,趙燕等[4]建立了適用于農業文本分類的NB模型;孫宇[5]構建NB模型,挖掘稻米產品物流因素與顧客滿意度間的關系。在物流領域,現有工作大多集中于對物流數據的挖掘與分析[6,7]或對評論文本的情感分析[8,9],物流新聞文本相關研究較少。
根據各大官方物流新聞網站調研結果,不同類別物流新聞總數差距較大,物流新聞具有類間分布不均衡的特點,較大程度影響了分類器的實際分類效果。針對分類數據集不均衡的特點,王占偉[10]對樣本空間進行改進,提出基于重采樣技術的非平衡分類算法;Naderalvojou等[11]對分類加權算法進行改進,提出一種正負項和類別相關度的概率特征加權算法。以上方法均未考慮改進算法對分類時間的影響。本文針對物流新聞文本專業性強且類別分布不均衡的特點,構建物流新聞語料庫,使用在中文數據集中表現最好的卡方檢驗[12,13](chi-square test,CHI)進行特征選擇,考慮局部、全局和類內、類間的特征加權算法進行特征加權,實現基于加權補集樸素貝葉斯(weighted complement Naive Bayes,WCNB)的物流文本分類模型,通過不均衡的物流新聞文本分類實驗驗證模型的有效性與性能。
1 基于補集的樸素貝葉斯模型
1.1 樸素貝葉斯原理
樸素貝葉斯[14]是一種基于貝葉斯定理和特征條件獨立假設的概率統計方法。根據貝葉斯定理,假設有v個類別集合C={c1,c2,…,cv};T={t1,t2,…,tm} 表示m篇文本,每個文本由n維特征詞向量X={x1,x2,…,xn} 表示,其中xi∈T(1≤i≤n)。 則對任何滿足P(tk)>0的tk都有公式
(1)
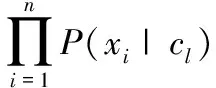
由于在給定的輸入中P(cl)是一個常量,且取最大后驗概率作為樣本所屬類別
(2)
式中:c(tk) 為該文本所屬類別對應的數值。
1.2 補集樸素貝葉斯模型
傳統分類算法都假設類的樣本數量大致相同,面對不均衡樣本時,由于少數類信息表達不充分,而多數類信息提取更充分,分類模型易將少數類樣本分到多數類,導致分類性能大大降低。補集樸素貝葉斯[15](complement Naive Bayes,CNB)模型的基本思想是在估計文本屬于某一類別的概率時,通過估計文本不屬于該類別的概率,即利用補集的特征來表示當前類別的特征,進而預測待分類文本的類別,以解決分類模型容易傾向大類別而忽略小類別的問題。

(3)
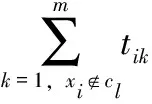
用CNB模型對文本tk進行分類,得該文本的類別最大值cCNB(tk)
(4)
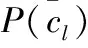
2 特征選擇與權重計算
2.1 基于卡方檢驗的特征選擇
基于特征獨立性的NB算法假設所有特征詞對文本分類的貢獻相同,但實際上,向量化后文本的特征維數高達上萬維,每個特征詞的重要性也不相同的。若一個特征詞在某一類別中多次出現,而在其它類別中很少出現,則認為該特征詞具有較高的類別區分度[16]。
常用的特征選擇方法有基于詞頻、方差、信息增益、互信息、卡方檢驗等[17]。常規的特征選擇方法對小類別的特征提取不足,卡方檢驗度量了特征詞與類別的關聯程度[18],能通過計算關聯度來進行特征選擇。特征詞xi相對于類別cl的卡方值χ2(xi,cl) 計算公式如下
(5)
式中:fa表示類別cl中出現特征詞xi的文本數;fb表示除類別cl的其它類別中出現特征詞xi的文本數;fc表示類別cl中未出現特征詞xi的文本數;fd表示除類別cl的其它類別中未出現特征詞xi的文本數。
利用最大值思想計算特征詞xi對于訓練集文本的卡方值,公式為
(6)
對特征全集的卡方值進行降序排列,并選取前z個特征詞以構成特征子集。
2.2 基于TF-IDF特征加權算法的改進
2.2.1 TF-IDF加權算法分析
詞頻-逆文檔頻率[19](term frequency-inverse document frequency,TF-IDF)為應用最廣泛的特征詞權重計算方法之一。TF是局部加權因子,反映特征詞xi相對于文本tk的重要度,默認出現次數越多越重要;IDF是全局加權因子,反映特征詞xi相對于整個訓練集的重要度,即包含特征詞的文本越少,特征詞越重要。
第i個特征詞權重計算公式如下
(7)
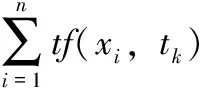
(8)
TFIDF(xi,tk)=TF(xi,tk)·IDF(xi)
(9)
式中:N表示訓練集的文本總數;df(xi) 表示包含特征詞xi的訓練集文本數;TFIDF(xi,tk) 為特征詞xi的TF-IDF 值。
在特定的分類任務中,N是一個常數。因此,IDF(xi) 隨著df(xi) 的增大而減小,即特征詞xi的IDF(xi) 值與出現該詞的文本數成反比。故IDF能使TF的敏感性降低。
IDF主要有兩個缺陷,第一,僅有極少數文本出現某一特征詞時,其IDF值趨近無窮大;第二,若某一特征詞出現在很多文本中,則IDF約等于零[20]。此外,IDF忽略了特征詞在類內和類間的分布,當特征詞在某一類內頻繁出現,而在其它類中出現較少,則認為該詞具有良好的類別區分能力,但由于包含該詞的文本數較多,其權重可能并不高。
2.2.2 TF-IECF與TF-RIECF
為減小具有高TF、增強具有低DF與高類別區分度的特征詞對權值的影響,本文用具有以下屬性的新全局加權因子替換IDF因子:
(1)當DF值增加時,全局加權因子具有較大的衰減率;
(2)為避免被零除,df(xi) 不能當作分母;
(3)函數是有界函數。
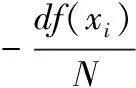
(10)
(11)
觀察式(10)和式(11),IEF與RIEF因子仍未解決特征詞在類內和類間的分布問題,本文引入類內及類間加權因子。類內加權因子I(xi)反映所有類別中包含特征詞xi文本數最多的那一類的分布情況,值越大代表該詞在某類中分布越廣;類間加權因子B(xi)反映特征詞xi在各類間的分散程度,值越大代表該詞出現的類別越集中。類內加權因子I(xi)和類間加權因子B(xi)的公式如下
(12)
(13)
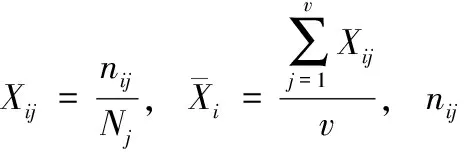
綜上,本文將改進的特征加權算法命名為詞頻-類別逆(根)指數頻率(term frequency-(radial) inverse exponential class frequency,TF-(R)IECF),其公式如下
(14)
(15)
3 TF(R)IECF-WCNB模型
TF(R)IECF-WCNB模型分別使用TF-(R)IECF特征加權算法計算文本中經過CHI特征選擇后的特征詞權重。假設特征詞xi在文本tk中歸一化后的權重為wik,并用wik修改式(3)
(16)
特征詞xi對類別cl的權重Wil計算公式如下
(17)
將式(17)標準化
(18)
根據式(18)修改式(4),得出待分類文本D的最大后驗概率cWCNB(D) 為
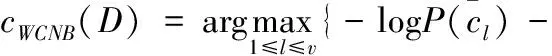
(19)
文本D的所屬類別即為cWCNB(D)所對應的類別。
4 物流新聞分類方法
4.1 物流新聞語料庫構建
文本分類已經涉及多個領域,但迄今為止,尚沒有公開的物流新聞分類語料庫。因此,本文爬取中國物流信息中心網、中國貿易金融網等多家官方物流信息網站共4856條物流新聞,新聞文本具有真實性與一定的權威性。從物流領域的角度出發,結合當下物流熱點,在各網站物流新聞劃分的基礎上,將物流新聞語料庫劃分為6個類別[21]:采購、倉儲、運輸、冷鏈、電子商務和快遞配送。物流新聞語料庫類別分布情況如圖1所示。
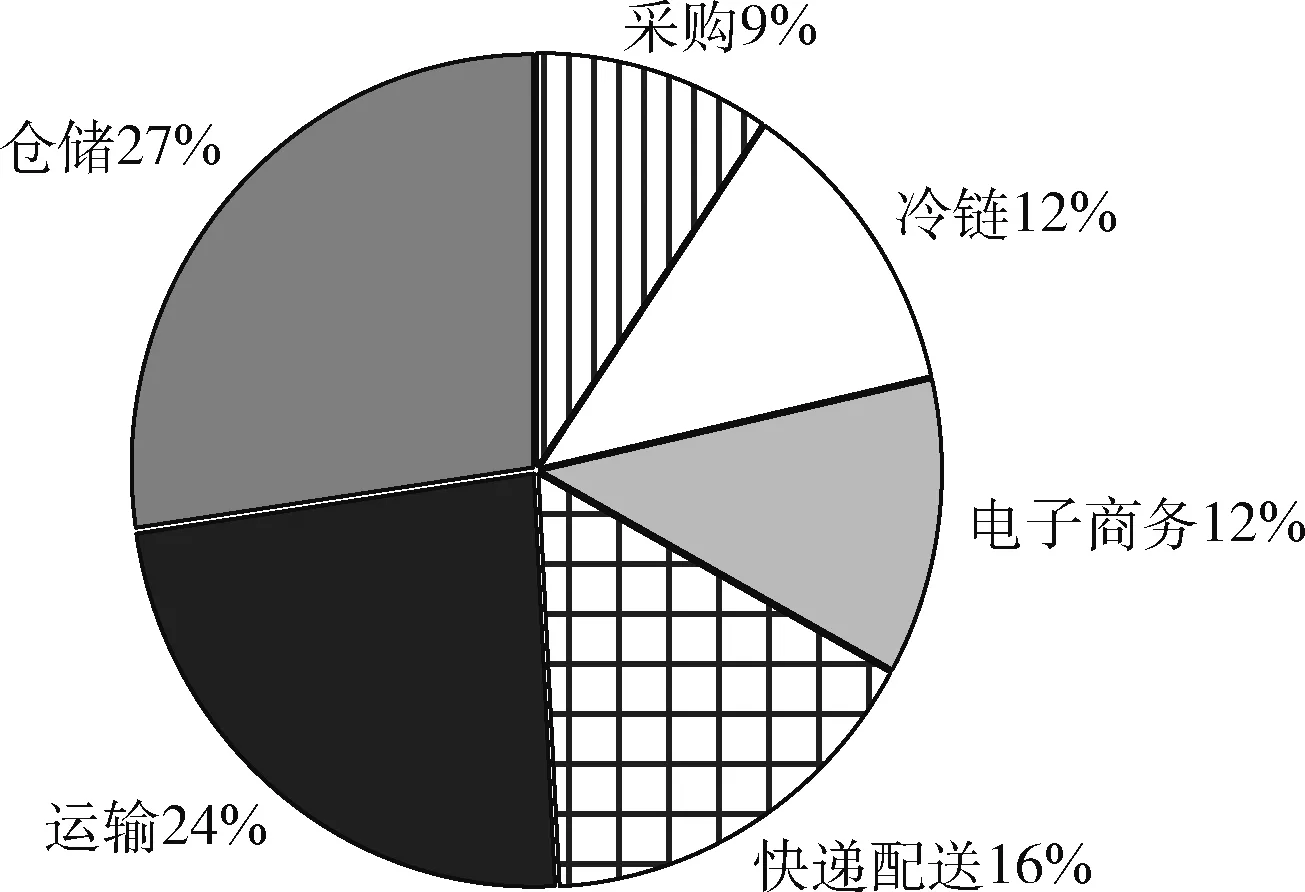
圖1 物流新聞文本分布
根據圖1所示,實驗使用的新聞文本類間數量有一定差距,倉儲類與運輸類占總數據集的51%,其余4類共占49%,體現物流新聞的不均衡性。
4.2 物流新聞分類流程
物流新聞分類流程分為三大模塊:構建物流新聞語料庫、TF(R)IECF-WCNB分類器分類和輸出分類結果。本文通過獲取已發布的物流新聞來構建物流新聞語料庫,將原始語料庫劃分為訓練集和測試集,對分類器進行訓練和測試,最終輸出分類結果。全流程用Python語言實現。物流新聞分類流程如圖2所示。
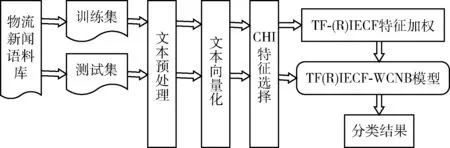
圖2 物流新聞分類流程
TF(R)IECF-WCNB分類器分類分為兩大過程:訓練過程和測試過程。訓練過程利用劃分的訓練集訓練分類模型。主要步驟為:
步驟1 文本預處理。實現所有文本的分詞、剔除停用詞和去標點符號等操作。根據物流領域專業文本詞匯特征,在原有jieba分詞詞庫的基礎上,人工構建并添加物流專業詞庫,防止物流專業詞匯在分詞階段被誤切,如:“冷鏈”被誤切為“冷”和“鏈”。依據物流新聞文本特點,修改中文停用詞表,作為本文的停用詞表。使用正則表達式匹配并刪除無關的英文及標點符號;
步驟2 文本向量化。將分詞后的文本轉化為向量空間模型(vector space model,VSM)中的向量,生成文本-詞語矩陣,矩陣元素a[i][j] 表示第j個詞語在第i個文本下的詞頻;
步驟3 CHI特征選擇。原始文本-詞語矩陣特征維度過大,進行特征選擇不僅可以篩選出正確分類有貢獻的特征詞,還能大大縮短分類時間。計算每個向量的CHI值,將計算結果按照降序進行排序,選擇前z個特征詞,構成特征子集;
步驟4 特征加權。對特征子集中的特征詞用TF-IECF或TF-RIECF特征加權算法計算每個特征詞的權重,并以權重更新文本-詞語矩陣;
步驟5 構建并訓練模型。構建加權補集樸素貝葉斯模型,以特征加權后的文本-詞語矩陣作為輸入,訓練模型。
測試過程中的測試集經過相同的預處理、向量化和特征選擇后,利用已訓練的加權補集樸素貝葉斯模型對物流新聞測試集進行分類,最終輸出分類結果。
5 實驗與分析
5.1 評價指標
文本分類的評價指標分為局部指標和全局指標。局部指標主要有準確率P和召回率R。準確率描述當前類別分類正確的文本占分類至當前類別文本總數的比例;召回率描述當前類別分類正確的文本占當前類別文本總數的比例。全局指標有精確度和Kappa系數[22]。相較于精確度,Kappa 系數更適合應用于多分類模型評價。本文使用兩種局部指標與全局指標Kappa系數來評價模型。
兩種局部指標公式如下
(20)
(21)
式中:TP表示正確分類至當前類別的文本數;FP表示其它類別文本錯分類至當前類別的文本數;FN表示當前類別文本錯分類至其它類別的文本數
(22)
(23)
Kappa系數公式中,ai表示第i類文本的實際樣本數量;bi為預測出的第i類文本樣本數量;M表示樣本總數;Kappa取值范圍[0,1],數值越大代表模型分類效果越好。
除局部、總體指標外,本文定義模型分類時間,特指文本向量化至輸出最終分類結果的時間間隔,也用于評價模型性能。
5.2 結果與分析
本文分別使用基于NB模型、MNB模型、CNB模型、TFIDF-WCNB模型、TFIECF-WCNB模型和TFRIECF-WCNB模型的6種分類器,進行兩組實驗。
實驗1:為了達到最優模型性能,對原始特征詞用CHI進行特征選擇時,實驗對特征詞維度z的取值從0開始以間隔400為單位逐漸遞增。z=0代表不進行特征選擇。特征詞維度z的取值對CNB模型的全局指標Kappa系數的影響如圖3所示。
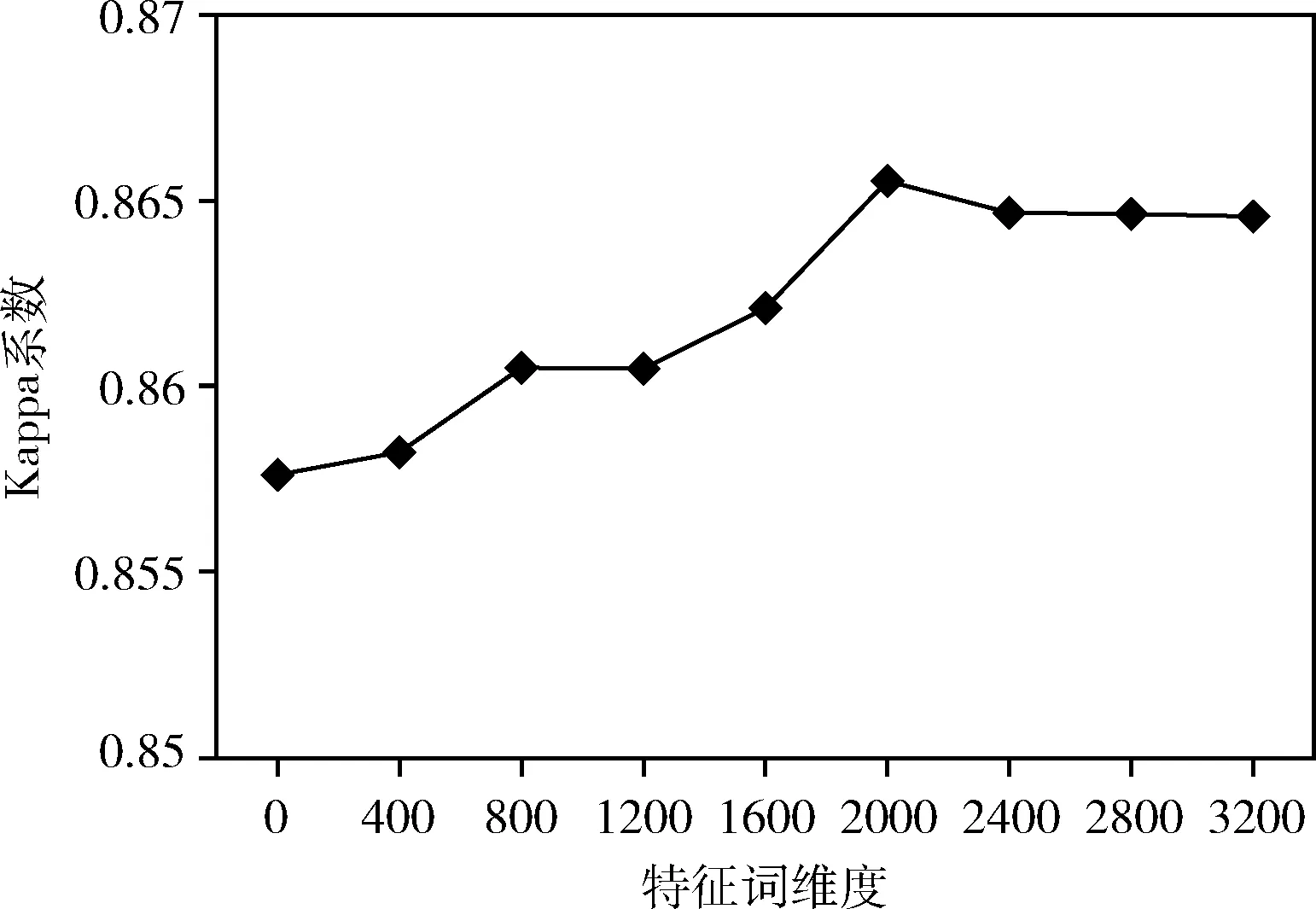
圖3 特征詞維度取值對Kappa系數的影響
從圖3的折線圖可以看出,特征詞維度z從0以400為單位遞增到2000的過程中,隨著特征子集增大,所選特征詞對各類別特性表述的完整性提高,描述的類別信息增多,CNB模型分類的Kappa系數也不斷增加;當z取值大于2000時,特征子集所表述的類別信息臨近飽和,特征詞維度的增加并不能增多其對各類別信息表述,反而導致模型出現輕微過擬合現象,故Kappa系數隨著z值的增加而緩慢減小,直至平穩。當z=2000時,模型分類性能最優。
實驗2:在特征詞維度z=2000的條件下,比較各模型在物流新聞語料庫的6個不同類別內的分類性能。實驗采用Laplace平滑方法,即先驗平滑因子α=1。各模型不同類別下的準確率P和召回率R對比如圖4所示。

圖4 z=2000時各模型局部指標對比
由圖4可以看出,各模型不同類別的分類效果不同,運輸類、冷鏈類和電子商務類分類效果較好;快遞配送類分類效果最差。傳統NB模型在6種模型中,其準確率和召回率皆為最低,分類性能最差。在NB模型的基礎上,形成的服從多項分布的MNB模型其局部指標較NB模型有較大提升。適用于不均衡數據集的CNB模型與適用于均衡數據集的MNB模型相比,無論大類別還是小類別,其兩種局部指標大都有所提高,且小類別表現更好,驗證了CNB模型能有效利用補集的思想彌補傳統模型小類別信息提取不充分的缺陷。運用傳統特征加權思想的TFIDF-WCNB模型,由于其IDF因子原有的缺陷且忽略了特征詞在類內、類間的分布,分類準確率較CNB模型并無較明顯提升,相反,在運輸類、冷鏈類、電子商務類中其準確率不升反降,表明對不均衡數據集的特征詞用傳統算法進行加權,不一定能取得理想的效果。本文對CNB模型進行改進,提出的TFIECF-WCNB模型和TFRIECF-WCNB模型與TFIDF-WCNB模型相比,局部指標都有一定程度的提高,且小類別較大類別提升更明顯。從總體上看,TFRIECF-WCNB模型的在各類別的分類效果最好,TFIECF-WCNB模型次之,實驗結果驗證了基于TF(R)IECF-WCNB模型的分類器對類別分布不均衡物流新聞分類的有用性。
各模型全局指標Kappa系數與模型分類時間見表1。
根據表1的分類結果,傳統NB模型分類效果最差,雖然MNB、CNB模型相對于NB模型在Kappa系數上有很大提升,但也大幅增加了其時間復雜度。對特征詞進行加權處理,在小幅提升Kappa系數的同時,能大幅縮短分類時間。本文提出的TFIECF-WCNB模型和TFRIECF-WCNB 模型在Kappa系數和分類時間這兩個指標上,都是最佳的。其中,TFRIECF-WCNB模型分類性能最優,其全局指標高達0.8945,且分類時間最短為50.5 s。

表1 z=2000時各模型Kappa系數與分類時間
綜合對局部、全局指標和分類時間的分析,本文提出的基于TF(R)IECF-WCNB模型的分類器能快速、準確地對物流新聞進行分類,并驗證了TF(R)IECF-WCNB模型在類別分布不均衡的物流新聞文本分類上的優勢和可行性。
6 結束語
本文采了一種改進的樸素貝葉斯模型即加權補集樸素貝葉斯模型,用以實現對不均衡物流新聞文本進行分類,并取得了較好的分類效果。NB算法是一個穩定的算法,基于NB算法改進的模型,在保證分類模型的強穩定性同時,還具有較高的計算效率與分類精度。
通過構建物流新聞語料庫,并針對語料庫中各類別文本數量分布不均衡與專業性強的特點,對文本進行預處理,使用卡方檢驗進行特征選擇,對傳統TF-IDF算法進行分析,提出、改進并形成了TF-(R)IECF特征加權算法,解決了傳統加權算法對特征詞在各類別間分布情況重視不足的問題。實驗結果表明,基于TF(R)IECF-WCNB模型的分類器,解決了傳統分類器容易傾向大類別而忽略小類別的問題,面對類別分布不均衡的物流新聞數據集,表現出良好的分類性能。
國民經濟快速發展的今天,物流業已成為助力經濟發展不可或缺的一部分。在物流業快速發展的背景下,快速而準確對物流新聞進行分類,以滿足新聞時效性、準確性和真實性三大特性,對相關物流機構及用戶來說具有重要的意義。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
制造技術與機床(2019年10期)2019-10-26 02:48:08
物流技術與應用(2019年8期)2019-09-04 03:29:56
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
汽車觀察(2018年12期)2018-12-26 01:05:44
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
小學教學參考(2015年20期)2016-01-15 08:44:38
現代企業(2015年2期)2015-02-28 18:45:09
