基于孤立森林算法的電力用戶數據異常快速識別研究
2022-02-17 12:10:58王燕晉易忠林鄭思達劉巖孫海濤
電子設計工程 2022年3期
王燕晉,易忠林,鄭思達,劉巖,孫海濤
(國網冀北電力有限公司營銷服務中心(計量中心),北京 100032)
隨著我國信息技術水平的不斷提升,電力系統建設逐漸朝著信息化方向發展,由于電力用戶數量龐大,所需采集和處理的信息量巨大,容易導致電力系統通信或電力設備出現異常狀況,使得信息數據異常,為電力系統的數據采集和處理帶來了諸多不便[1-2]。因此,對電力系統用戶數據異常狀況進行識別與檢測就變得十分重要[3]。
該文針對這一問題,采用了孤立森林算法的相關知識,設計了一種新的電力用戶數據異常快速識別方法,并通過實驗驗證了該方法的有效性。
1 電力用戶數據異常信息挖掘
對電力用戶數據異常信息的挖掘主要包括數據檢測、數據理解、數據評估等步驟。電力用戶數據異常信息挖掘流程如圖1 所示。

圖1 電力用戶數據異常信息挖掘流程
根據圖1 可知,數據處理服務器需要在海量的電力系統網絡數據中進行識別檢測的首要任務是數據檢測,根據數據特征利用序列數據檢測法將采集到的電力用戶信息數據進行分類,然后根據該類別的相關規則對數據進行基本的檢測識別[4-5]。數據挖掘示意圖如圖2 所示。

圖2 數據挖掘示意圖
觀察圖2 可知,由于部分數據可能會受到噪聲等因素干擾,需要對其進行降噪處理,以保持數據源的真實性、完整性,然后需要對數據異常問題進行初步檢測,排除正常數據,對可能存在異常的數據進行數據理解。數據理解就是對有待處理的問題數據進行更深層次的分析,在計算機能力范圍內最大程度挖掘出該數據的所有相關信息,并對該數據可能存在問題的方面進行理解,同時搜尋關于該問題的相關解決方案和信息[6]。在此之后需要進行數據評估,根據相應的問題等級劃分規則并根據該問題的風險程度對異常問題進行風險評估,電力信息系統根據異常狀況的評估結果采取相應的處理方案,以對數據異常情況進行及時處理。
2 電力用戶數據異常快速識別
基于孤立森林算法的電力用戶數據異常檢測示意圖如圖3 所示。
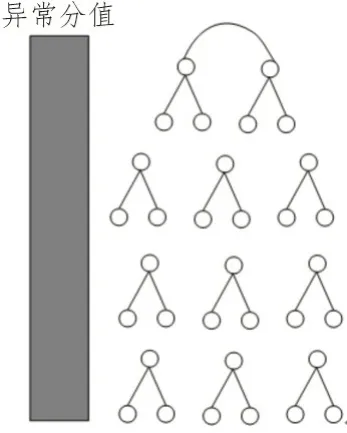
圖3 基于孤立森林算法的電力用戶數據異常檢測示意圖
2.1 孤立森林模型構建
由于不同電力系統具有不同的特征,因此需要有針對性地構建孤立森林算法模型。首先,根據電力系統用戶信息數據的規模設定孤立森林模型的數據集,隨機選取部分具有一定差異性的系統用戶數據作為孤立森林構造樹iTree的數據樣本,并導入相關的電力用戶信息數據集;然后對電力用戶數據集進行預處理,將數據按照一定規則進行排列,選取適當數量的數據樣本作為二叉樹的根數據;在此基礎上將其他訓練數據進行分離,根據一定的特殊性和差異性將數據集分離成多個子數據集,一直分離到子數據集中只有一個數據點為止;然后隨機選取一個數值范圍作為數據抽取閾值,根據這一數值范圍對數據森林進行切割,根據相應的判別標準對劃分結果進行判別[7-8]。
觀察圖4 可知,正常數據應該被劃分在高密度區,否則就會被劃分在低密度區域,此時則表示該數據存在異常;如果檢測結果不確定,那么需要重復該環節,循環進行數據訓練集的分離與切割,直到所有數據異常情況檢測完畢[9]。

圖4 異常檢測
2.2 基于孤立森林的異常數據識別檢測
基于以上構建的孤立森林模型,結合電力系統的實際數據情況進行電力用戶異常數據識別檢測。在對電力系統中的電力用戶數據進行異常檢測時,首先要對數據源進行清理,減少或排除噪聲數據及其他干擾因素對原始數據造成的影響,并對數據進行初步降重檢測,刪除重復或相似度過高的冗雜數據,保證孤立森林算法的原始數據真實、完整并且具有差異性[10-11]。
基于孤立森林的異常數據識別流程如圖5 所示,主要有以下幾個操作步驟:
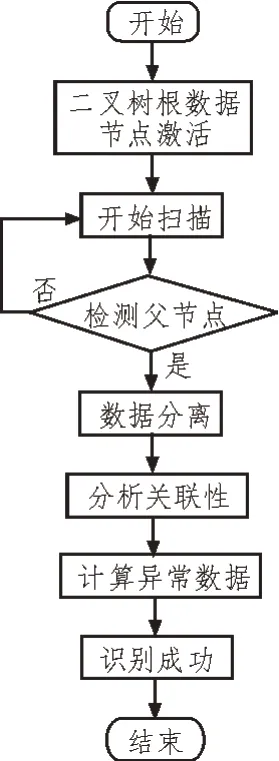
圖5 基于孤立森林的異常數據識別流程
1)將原始數據集D導入到孤立森林模型中,根據二叉樹模型中的根數據集設定情況,將電力用戶數據對應放置在二叉樹根數據節點中。
2)采用孤立森林算法進行隨機的數據分離,使數據落在相應的二叉樹葉子節點上。
3)根據用戶信息數據的特殊性和差異性不斷進行數據分離,直到子數據集只含有一個數據為止。
4)由于異常數據S往往比較稀少,與其他數據關聯性較小,因此容易較早地被分離出來,而且能夠比較容易地被識別出來。
5)計算異常數據S所在的葉子節點數據與根節點的距離和層級關系,如式(1)所示。
6)通過歸一化公式計算所有二叉樹的平均高度,估計異常數據S的異常指數,如式(2)所示,以進一步提高異常數據識別的準確性。

上述公式中,C(n)表示異常數據S(x,n)到根節點的距離,n表示異常數據在其所在的數據集D中的異常指數,H表示該運算過程中所有二叉樹的平均高度,ξ是計算二叉樹平均高度需要用到的歐拉指數[12-13]。
檢測過程如圖6 所示。

圖6 檢測過程
通過以上運算步驟能夠較為精準地識別異常數據的位置和相關信息,并且利用歸一化公式對異常數據進行了更精準的計算檢測,所得結果越趨近于1,表示該數據是異常數據的可能性就越大;反之,計算結果越接近于0,那么該數據是異常數據的可能性就越小[14-16]。
3 實驗研究
為了驗證文中基于孤立森林算法的電力用戶數據異常快速識別方法在實際應用中是否具有良好的使用效果,通過設計實驗來對其進行性能檢驗,并選用了傳統的基于K-means 算法的電力用戶數據異常識別方法和基于LOF 算法的電力用戶異常數據識別方法同時進行對比實驗。
實驗的基礎設備是具備Windows10 運行系統和電力系統標配內存的計算機服務器,在該計算機設備上,構建二叉樹棵數為100、樣本數據量為128 GB、異常數值比例設定為0.05的孤立森林iTree 模型。將原始數據導入到孤立森林模型中,通過字段檢測程序對數據集進行初步識別,然后根據二叉樹模型進行數據分離和異常檢驗,并進行異常數據評估。3 種算法的誤差數據檢測精準度如表1 所示。

表1 3種算法的誤差數據檢測精準度
總結表1,得到檢測精準度實驗結果如圖7所示。

圖7 檢測精準度實驗結果
上述實驗結果表明,基于孤立森林算法的電力用戶數據異常快速識別方法在數據異常識別中具有更好的應用效果。根據表1 數據所示,該文采用的孤立森林算法在同一檢測數據集的情況下,檢測結果精準度更高,最接近于1;而另外兩種算法的識別檢測精準度都在0.89 左右,相比于iForest 算法的精準度,傳統算法的精準度水平并不是很理想。
3 種算法的識別耗時如表2 所示。

表2 3種算法的識別耗時
由表2 數據可知,iForest 算法對數據集進行異常數據識別所用時間為1.012 s,而K-means 算法用時達到了9.876 s,LOF 算法更是用了18.678 s,三者之間的識別消耗時間差距十分明顯。對于目前的電力系統用戶異常數據識別來說,檢測速度越快越有利于保證電力系統整體安全。
綜上所述,相比于傳統的電力用戶數據異常識別方法,基于孤立森林算法的電力用戶數據異常快速識別方法在異常識別時間上具有很大優勢,而且具有較高的精準度,進而有利于提高電力系統用戶數據異常檢測的整體效率。
4 結束語
該文針對傳統的電力用戶數據異常識別方法存在的不足進行了分析,并研究了基于孤立森林算法的電力用戶數據異常快速識別方法。通過構建孤立森林算法和二叉樹模型,加強了信息數據挖掘、檢測、識別過程的運算精準度,完善了電力用戶數據異常識別方法。然后將該文研究方法與傳統的數據異常識別方法進行了對比實驗,通過實驗結果證明了該文研究方法在數據異常信息識別方面具有較高的精準度,而且識別速度明顯比傳統方法快,驗證了基于孤立森林算法的電力用戶數據異常快速識別方法的精準性和高效性。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
