一種結合多通道特征改進群組相關的立體匹配算法
2022-02-18 08:30:02鄭秋梅王生坤王風華
重慶理工大學學報(自然科學) 2022年1期
鄭秋梅,王生坤,王風華,于 濤
(中國石油大學(華東) 計算機科學與技術學院, 山東 青島 266580)
在計算機視覺領域中,立體匹配在場景幾何重建、無人駕駛、工業測量等領域發揮著重要作用。雙目立體匹配是用數學運算模型計算左右2幅視圖中的對應點及視差,最后求取深度信息的過程[1-2]。基于手工設計特征的傳統雙目立體匹配缺乏上下文信息,匹配效果受不同經驗參數影響較大,對弱紋理、遮擋、反射表面、重復紋理等病態區域匹配效果較差,不適合在復雜環境下應用[3-4]。通過卷積神經網絡提取雙目圖像的多通道特征由于包含更多上下文信息,相比手工設計特征得到了更好的效果。特征的通道數與網絡的擬合能力和網絡提取上下文信息的能力有重要關系。Chang等[5]使用殘差網絡提取左右圖像的多通道特征。但是,大規模池化使得獲得的特征中損失了高層語義信息,這會使視差圖相鄰像素間出現較大差異。Chang等[5-6]在每個視差層連接左右特征圖,構建四維匹配代價,有效計算了特征相似性,但每個視差級別只產生單通道的相關圖會損失部分信息,在構建更加準確的匹配代價來提升視差圖精度方面仍有一定困難。
特征提取中高層語義信息損失和匹配代價構造過程中的信息損失,使得提升匹配精度仍有一定困難。本文通過在特征提取部分引入改進的特征金字塔網絡,分別對左右視角圖像進行特征提取,提取包含雙目圖像高層語義信息的多通道特征;考慮不同通道上的特征信息通常對于提高病態區域匹配精度有影響,在對多通道特征處理時,使用改進的群組相關——平均群組相關模塊來構建輕量化的匹配代價,在保證匹配精度的同時控制網絡的計算負擔。
1 關鍵技術
大部分傳統立體匹配算法包括以下步驟:雙目圖像特征提取、匹配代價計算、代價聚合和視差回歸。基于深度學習的立體匹配則通過卷積神經網絡將傳統立體匹配算法步驟統一成一個端到端的網絡來提升算法的視差估計性能。
1.1 特征提取
特征提取作為立體匹配的基礎和關鍵部分,提取特征的準確性和穩健性會對后續視差效果產生重要影響。基于深度學習的立體匹配用神經網絡學習到的多通道特征[7-10]取代了傳統手工特征。特征提取模塊一般使用全卷積神經網絡或者殘差網絡,殘差網絡促進了網絡的深度訓練,通過使用擴展卷積可以捕獲更多的全局上下文信息。Chang等[5]基于殘差網絡,附加空間金字塔池化模塊(spatial pyramid pooling,SPP),在多個尺度上聚合特征。Guo等[11]則采用和文獻[5]類似的殘差網絡結構,但沒有使用SPP模塊。Zhang等[12]提出一種新型的 “domain normalization”方法,將學習到的表征的分布歸一化。特征金字塔網絡(feature pyramid networks,FPN)[13]利用了圖像的金字塔特征,具有從低到高的語義信息,因此可以考慮將其改進應用于雙目立體匹配中來提高匹配效果。
1.2 匹配代價計算
匹配代價是立體匹配中左、右圖像的像素之間相似程度的度量標準,代價越小,相應的像素點越相似,最后依據匹配代價計算雙目立體圖像的視差圖。三維匹配代價[14-15]通過取左圖像特征與右圖像特征在預定視差范圍內的相似性度量方法構建,如L1、L2或相關距離。三維匹配代價中的相似性度量提供了一種有效的方法來測量特征相似性,但因為在每個視差等級只產生一個單通道的特征圖,所以會丟失較多信息。三維匹配代價所包含的信息豐富度有限,四維匹配代價[5,16-17]則是讓網絡學習合適的相似度量來比較特征,四維匹配代價可以通過在預定義的視差范圍上的特征差異來構建[18],或者通過連接空間金字塔池化網絡的不同分支特征[5]來構建。四維匹配代價比三維匹配代價承載更豐富的信息,但是通過連接獲得的代價卷中不包含特征相似性的信息,需要在后續模塊中使用更多參數來進行相似性度量。Guo等[11]提出一種混合方法,結合了三維和四維的優勢,構造群組相關四維匹配代價,相比于只通過特征連接構成的四維匹配代價來說能減少參數,但由于對特征的分組,使得匹配代價的準確性極容易受到分組數的影響,會造成一些信息損失。此外,也有一些方法考慮到四維匹配代價有較高的參數量及三維卷積代價聚合過程中造成的較大計算量[19-20],提出代替基于匹配代價的三維卷積模塊,雖然能夠有效加快推理速度,但在準確性方面與四維匹配代價相比仍有較大差距。
2 結合多通道特征改進群組相關的立體匹配算法
網絡采用端到端方法設計,使用殘差網絡作為特征提取基礎結構,將改進的特征金字塔網絡引入特征提取階段來提取雙目圖像的包含高層語義信息的多通道特征。匹配代價計算過程中通過改進的群組相關方法,來補充匹配代價的信息。算法的網絡結構主要由多通道特征提取、匹配代價計算、代價聚合和視差回歸3個部分組成,整個網絡結構如圖1所示。
2.1 基于特征金字塔網絡的多通道特征提取
在基于深度學習的立體匹配中,多通道特征提取的準確性和穩健性對后續匹配效果起著重要作用。僅僅獲得圖像特征的全局上下文信息和多尺度信息是有欠缺的,還要充分利用高層特征的語義信息,為此,本文特征金字塔網絡引入特征提取模塊。特征提取模塊結構如圖2所示。輸入圖像尺寸為H×W,基本殘差網絡包含提取特征的基本殘差塊,并利用空洞卷積來進一步加大感受野。
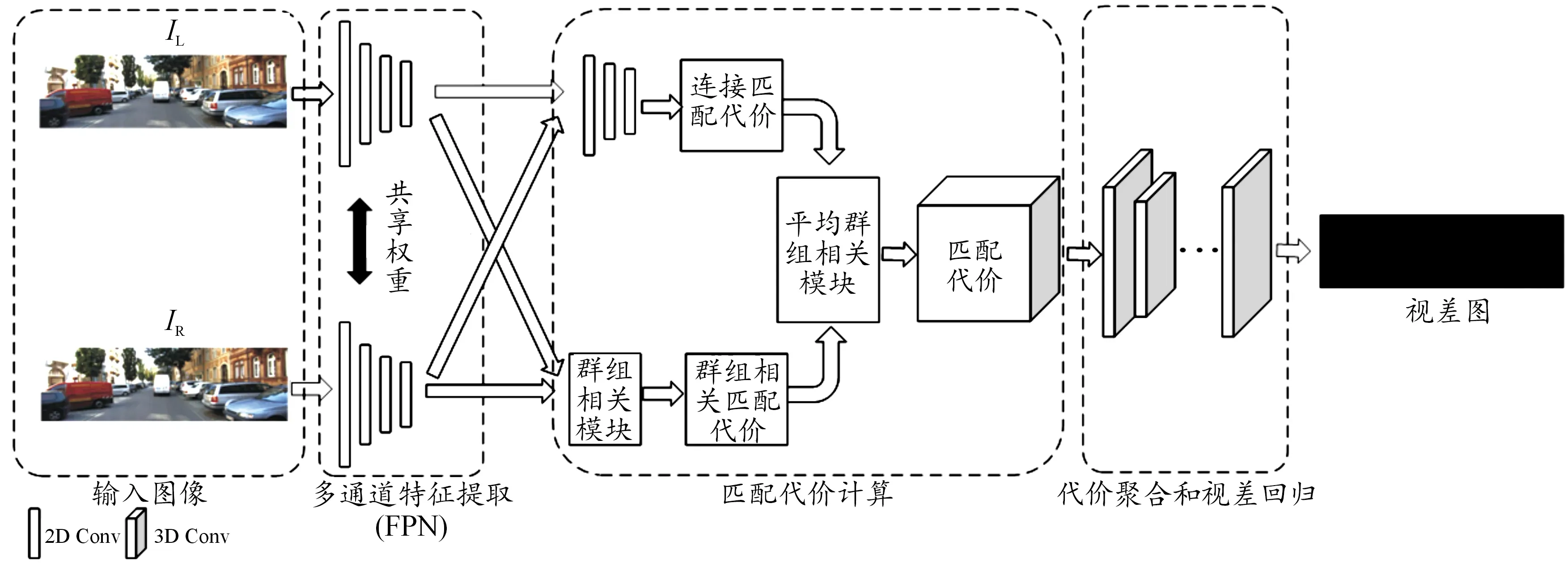
圖1 本文算法網絡結構
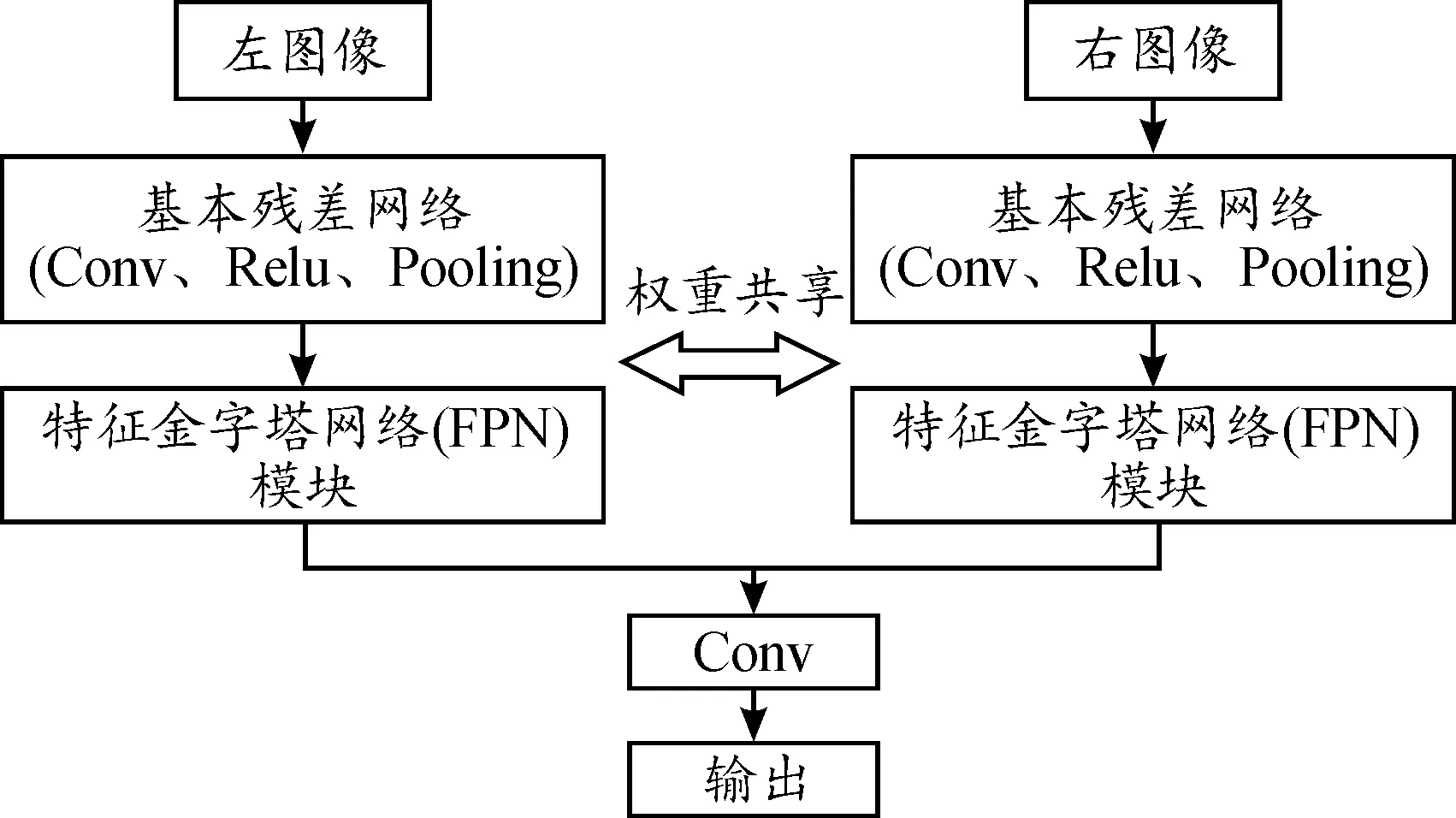
圖2 特征提取模塊結構
本文改進的特征金字塔網絡結構如圖3所示,網絡設計4個不同尺度的特征提取層:(H×W)/2,(H×W)/4,(H×W)/8,(H×W)/16。高層特征被上采樣到與相鄰低級特征一致的分辨率,并添加到它們中來融合不同尺度的特征圖。在上采樣之前要通過一個卷積層將不同級別的特征圖通道縮減為相同數量,保證多尺度特征融合時特征大小和通道維度自上而下的一致性。這一過程層層迭代,逐步整合不同尺度的金字塔特征,以更好地利用上下文信息,最后得到的特征圖大小為(H×W)/4。在構建最終的輸出特征時,改進特征金字塔網絡特征輸出采用特征拼接的方式,使特征通道數為320,最終得到大小為320×(H×W)/4的多通道特征。通過改進的特征金字塔網絡,不僅融合了不同尺度的特征信息,也讓深層網絡中高層語義部分的信息能夠融合到稍淺層的網絡,相對于文獻[5]和文獻[11]中的特征提取結構,改進的特征金字塔網絡可以補充對高層語義信息的提取來豐富特征信息,有利于后續匹配代價的準確性。

圖3 本文改進的特征金字塔網絡結構
2.2 平均群組相關匹配代價
在得到所有左、右輸入圖像的深層特征后,將特征編碼到網絡中,使其具有幾何感知能力。之后的工作就是利用多通道特征構建匹配代價。
MC-CNN[7]和GC-Net[10]用連接左、右特征的方法,通過深層網絡學習匹配代價估計,而不是用距離矩陣。基于特征提取模塊提取到多通道特征,利用空間金字塔池化模塊,通過在每個視差層連接左特征圖和相應的右特征圖構造連接匹配代價。空間金字塔池化模塊包含4個不同尺寸的平均池化(8×8,16×16,32×32,64×64),并且采用了1×1卷積和上采樣結合多維特征組成了一個四維連接匹配代價,大小為(H×W×Dmax)/4×64。經過空間金字塔池化模塊可以提取和聚合多個尺度上的信息,生成不同級別的多維特征圖,包含了全局特征信息。本文采用的空間金字塔池化模塊如圖4所示。

(1)
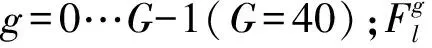

圖4 空間金字塔池化模塊結構
通過連接構造的匹配代價不包含特征相似性信息,為了補充連接匹配代價相似性信息,提出用平均群組相關模塊(average group-wise correlation)來構建一個輕量級的成本量,應用在雙目立體匹配過程中構建最終用于聚合的匹配代價V。
(2)
式中:Vc為連接匹配代價;Vg為群組相關匹配代價,最終獲得平均群組相關匹配代價V的大小也是(H×W×Dmax)/4×64。群組相關匹配代價通過對特征進行分組,在包含特征的相似性同時,獲得了輕量化的匹配代價,連接匹配代價有效利用特征提取模塊獲得的特征多尺度信息。通過引入平均分組相關模塊,結合了連接和群組相關匹配代價的優勢,在保證獲得更加準確的代價信息,提高匹配精度的同時,可以使網絡不增加內存消耗,有利于減輕后續成本體積過濾模塊的計算負擔。
2.3 代價聚合和視差回歸
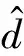
(3)
(4)
式中:λi為第i次視差預測的系數;d*為真實視差圖。采用L1損失函數去訓練整個網絡進行端到端的有監督學習。平滑L1損失計算如下:
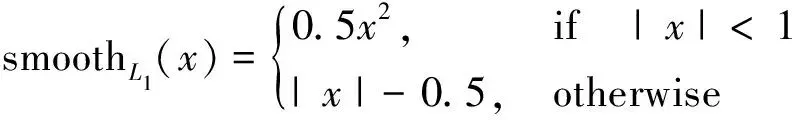
(5)
在代價聚合和視差回歸階段,通過對擁有更加豐富信息和體積相對較小的四維平均相關匹配代價的處理,使得網絡獲得更多信息,有利于提高視差精度,減少計算負擔。
3 實驗
在SceneFlow[14]、KITTI 2012[21]和KITTI 2015[22]3個立體數據集上評估了本文算法。
3.1 數據集
SceneFlow:一個包含35 454張訓練圖像和 4 370張測試圖像的合成數據集,它提供了密集且詳盡的視差圖作為真值,圖像尺寸為540×960。通常使用端點誤差(EPE,end point error,表示檢測到的視差圖和真實值之間對應像素的歐式距離之和)衡量測試結果。
KITTI 2012:來自一個行駛中汽車的包含著在不同天氣條件下真實街景的數據集。這些圖像的視差真值是通過稀疏的激光雷達獲取的,由194幅訓練圖像和195幅測試圖像組成,以較少損耗的PNG格式保存,圖像尺寸為376×1 240。訓練使用KITTI 2012的彩色圖片,整個訓練數據進一步劃分為了訓練集(160圖片對)和驗證集(34圖片對)。
KITTI 2015:基于KITTI 2012進行豐富補充的真實街景數據集,包含以半自動過程建立視差真值的動態場景。網絡訓練時將訓練數據集劃分為80%訓練用數據集和20%的驗證用數據集。
3.2 實驗結果及分析
使用Linux系統服務進行實驗,服務器內存為20 G,搭配2個顯存為16 G的Tesla V100 GPU,考慮服務器原因訓練時設置批量大小為4。本文算法使用PyTorch實現網絡端到端的訓練,與基準網絡類似,使用Adam優化器(β1=0.9,β2=0.999 9)優化,最大視差深度設置為192 pixel。訓練采用變學習率的方法,初始學習率設置為0.000 1。首先,使用SceneFlow數據集進行16個Epoch的訓練,在網絡訓練了10、12、14個Epoch之后學習率變為之前的1/2,得到訓練模型,并在SceneFlow上測試訓練得到的模型。SceneFlow上訓練得到的模型在KITTI數據集上進行300個Epoch的微調,得到最終訓練模型和結果。
在數據評價指標方面,對于SceneFlow數據集,采用端點誤差(EPE)作為評估度量,即以像素為單位的平均視差誤差。對于KITTI數據集,使用在線評估網站的主要標準進行評價和對比。本文的方法在基準網絡GwcNet[11]上進行改進,并將實驗結果與基準網絡及KITTI數據集上其他排名靠前的一些方法如GC-Net[6]、PSMNet[5]、AANet[19]進行比較。
3.2.1SceneFlow 數據集
在SceneFlow數據集上的測試結果如表1所示,實驗結果表明,本文的算法在數據集上計算端點誤差的表現優于其他幾種算法,誤差率較小。

表1 SceneFlow測試結果
3.2.2KITTI 2012數據集
將本文獲得的測試集圖像提交到KITTI數據集網站進行在線評價,并與其他算法進行比較。在KITTI 2012數據集上的測試結果如表2所示,Out-Noc表示非遮擋區域的錯誤像素百分比,Out-All表示總錯誤像素的百分比,“3px”表示誤差數大于3個像素的百分比。
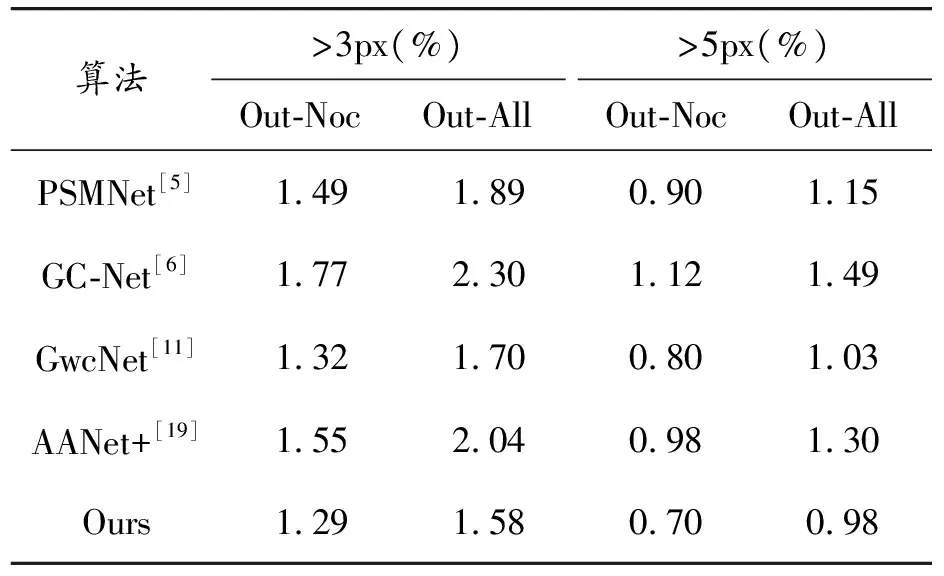
表2 KITTI 2012測試結果及對比
在表2的對比結果中可以看出,本文算法的結果在誤差不超過3、5 px的標準下都超過了基準網絡GwcNet,且相比于其他方法也取得了更高的精度。圖5中(第1行為左輸入圖像,第2行起從上往下分別為預測視差圖、真實視差圖、誤差圖)將本文算法與GwcNet在KITTI 2012上進行可視化對比,錯誤率較低,并且可以看出在天空等弱紋理區域的匹配效果更好。

圖5 KITTI2012測試結果
3.2.3KITTI 2015數據集
在KITTI 2015數據集上的測試結果如表3所示,其中,D1表示第一幀立體視差異常值的百分比,D1-fg、D1-bg、D1-all分別表示在前景區域、背景區域和所有真實值像素上進行誤差評估百分比。All pixels指在誤差估計過程中考慮了測試圖像中的所有像素,Non-Occluded pixels指只考慮了非遮擋區域的像素。
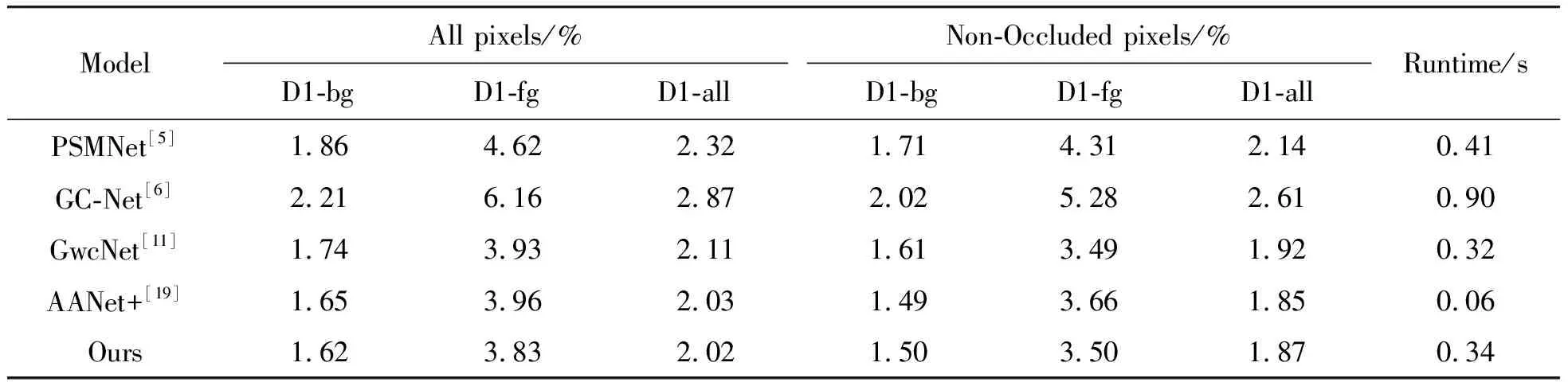
表3 KITTI 2015測試結果
在KITTI 2015數據集中,考慮所有像素時本文算法比基準網絡獲得了更好的精度。網絡雖然在計算匹配代價時引入了更多信息,但是網絡運行時間相比基準網絡僅增加6.25%左右,這表明本文算法在提高精度的同時并沒有增加較大的計算負擔。將本文算法在KITTI 2015驗證數據集上與GwcNet進行可視化對比,評估給出的誤差圖(誤差圖中藍色點為正確匹配點,黃色點為不匹配點,黑色點為忽略點)如圖6所示(第1行為左輸入圖像,第2行起從上往下分別為預測視差圖、真實視差圖、誤差圖),可以看出本文算法在弱紋理、邊緣等區域(如墻壁、車身)能生成更精確的視差圖。

圖6 KITTI 2015測試結果
4 結論
本文算法在SceneFlow、KITTI 2012和KITTI 2015數據集上與幾種典型的算法相比,匹配精度有所提升,特別是在弱紋理等病態區域,取得了更好的重建效果,并且相對于基準網絡,在提升效果的同時幾乎沒有增加計算負擔。雖然所提算法的時間開銷增加相比基準網絡基本可以忽略,但是由于代價聚合階段仍然使用計算成本較高的三維卷積使得網絡不能較好滿足實時性要求,仍需要對算法進行更深入地研究,進一步提升匹配效果。
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
軸承(2010年2期)2010-07-28 02:26:12
