
基于Python的拉勾網數據爬取與分析
2022-02-24 00:08:31賈宗星馮倩
計算機時代 2022年2期
賈宗星 馮倩

摘? 要: 研究并設計實現了一個基于Python的爬蟲,用來爬取拉勾網數據資源。針對想要的信息數據進行定向爬取,對爬取到的信息進行存儲、數據清洗及可視化分析。最終得到全國范圍內招聘Python工程師的公司以及相關的待遇及要求。
關鍵詞: Python; 爬蟲; 數據清洗; 可視化分析
中圖分類號:TP399? ? ? ? ? 文獻標識碼:A? ? ?文章編號:1006-8228(2022)02-05-03
Crawling and analyzing data of lagou.com with Python
Jia Zongxing, Feng Qian
(College of Information Science and Engineering, Shanxi Agricultural University, Taigu, Shanxi 030801, China)
Abstract: In this paper, a Python based crawler is designed and implemented to crawl data resources of lagou.com. Directional crawling is carried out for the desired information data, and the crawling information is stored, cleaned and visually analyzed. Finally, the company that recruits Python engineers nationwide and relevant treatment and requirements is obtained.
Key words: Python; crawler; data cleaning; visual analysis
0 引言
每到畢業季,畢業生須對招聘職位等信息有詳細地了解,才能更好地應聘到心儀的工作。比如,要了解全國范圍內招聘Python工程師的公司以及相關的待遇及要求,網上有海量招聘信息,靠人工采集數據方式速度慢效率低,且容易出錯。本文針對此種情況,設計出了一個基于Python的爬蟲,用來爬取拉勾網招聘信息,并對這些數據進行清洗以及可視化的分析,最后得到想要的信息。
1 相關技術介紹
1.1 Python語言
Python 語言作為一種當前最為流行的數據分析語言, 有著簡單易學、 面向對象、 可擴展、 庫豐富等特點[1]。
1.2 網絡爬蟲技術
網絡爬蟲,又稱蜘蛛機器人,是抓取網頁數據的程序,最終是根據用戶需求,在一定規則下,得到用戶需要的數據信息[2]。爬蟲模塊的系統框架由解析器、控制管理器、資源庫這三部分組成。控制器的首要任務是給多線程中的各個小爬蟲線程確定它們的工作任務。解析器的主要作用是進行網頁的下載,頁面的整理。資源庫的作用是存放下載好的網頁信息,通常采用數據庫來存儲。
2 拉勾網數據爬取與分析
本文選取的目標網址為:拉勾網https://www.lagou.com。這是較專業的互聯網相關行業招聘網站,速度快,職位多。本文要抓取的內容是全國范圍內招聘Python工程師的公司相關的要求信息及待遇,包括崗位id、所在城市、公司全名、工作地點、學歷要求、職位名稱、薪資以及工作年限等。
本次設計將爬取到的信息存到Excel表中,以表格及圖表的形式來進行結果的展示。
2.1 數據的獲取
利用爬蟲獲取數據的思路就可以確定為:發送get請求,獲取session、更新session,發送post請求、獲取數據并存儲。具體實現如下:
首先設置要請求的頭文件。請求頭文件是訪問網站時訪問者的一些信息,如果不設置頭文件的話,很大程度會因為訪問頻度過高而被當作機器人封殺。再通過開發者工具獲取User-Agent和Referer。將以上內容寫入代碼中:
my_headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS
X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36",? ? ? "Referer":https://www.lagou.com/jobs/list_Python?city=%E5%85%A8%E5%9B%BD&cl=false&fromSearch=true&labelWords=&suginput=","Content-Type":
"application/x-www-form-urlencoded;charset=UTF-8"
}
其次在測試時發現一次最多能爬取1-3頁爬蟲就會被中斷,解決辦法是使用time.sleep()間隔爬取。
接下來就是session的獲取以及兩次請求的發送,代碼如下:
ses=requests.session() #通過requests獲取session
ses.headers.update(my_headers)
#對頭文件中的session進行更新
ses.get(
"https://www.lagou.com/jobs/list_python?city=
%E5%85%A8%E5%9B%BD&cl=false&fromSearch=true&labelWords=&suginput=")
content = ses.post(url=url, data=datas)
這樣就可以得到存儲職位信息的json對象,先創建一個空的列表,然后對json格式的數據進行編碼轉換,遍歷獲得工作地點、學歷要求、公司名、發布時間、職位名稱、工作年限、福利待遇、工作類型、薪資等,這樣數據獲取的工作就完成了。
2.2 爬蟲主函數的編寫
首先確定將要交給爬蟲的工作量,代碼如下:
page=int(input('請輸入你要抓取的頁碼總數:')),
接下來設置一個空的列表,并設置好表頭信息,代碼如下:
info_result=[]
title=['崗位id', '城市', '公司全名', '福利待遇', '工作類型',
'工作地點', '學歷要求','發布時間', '職位名稱', '薪資',
'工作年限']
info_result.append(title)
之后利用循環以及try,except模塊循環采集信息。代碼如下:
for x in range(1, page+1):
url'https://www.lagou.com/jobs/positionAjax.json?
needAddtionalResult=false'
datas={
'first': 'false',
'pn': x,
'kd': 'python',
}
try:
info=get_json(url, datas)
info_result=info_result + info
print("第%s頁正常采集" % x)
except Exception as msg:
print("第%s頁出現問題" % x)
采集好信息后,將采集到的信息存儲在Excel表中以備待用。
3 數據的可視化展示
這里主要對上面爬取到的數據進行清洗和分析,再通過Excel表可視化展示。基本步驟為:提出問題,理解數據,數據清洗[4],構建模型,數據可視化[5]。
3.1 提出問題
本次數據分析主要研究的問題為:
⑴ 各個城市的招聘情況;
⑵ Python工程師招聘對于學歷的要求;
⑶ Python工程師招聘對于工作年限的要求。
3.2 理解數據
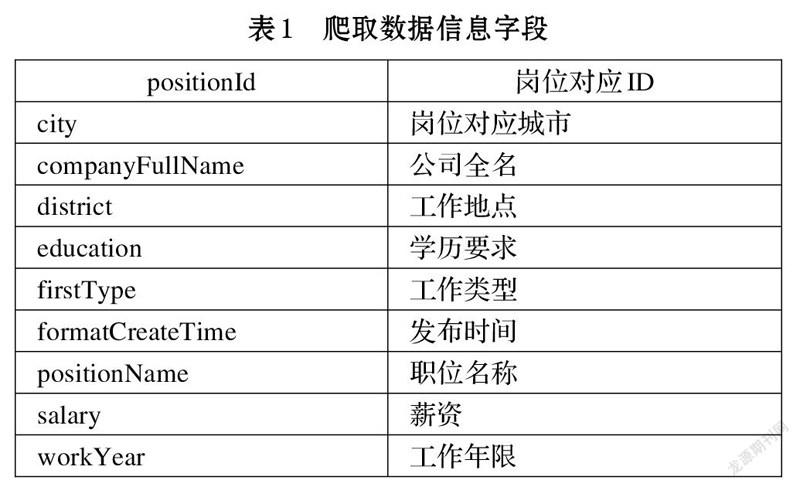
本次爬取的數據一共有10個字段,如表1所示。
3.3 數據清洗
數據清洗的步驟為:①選擇子集,②列名重命名,③刪除重復值,④缺失值處理,⑤一致化處理,⑥數據排序,⑦異常值處理。
⑴ 選擇子集
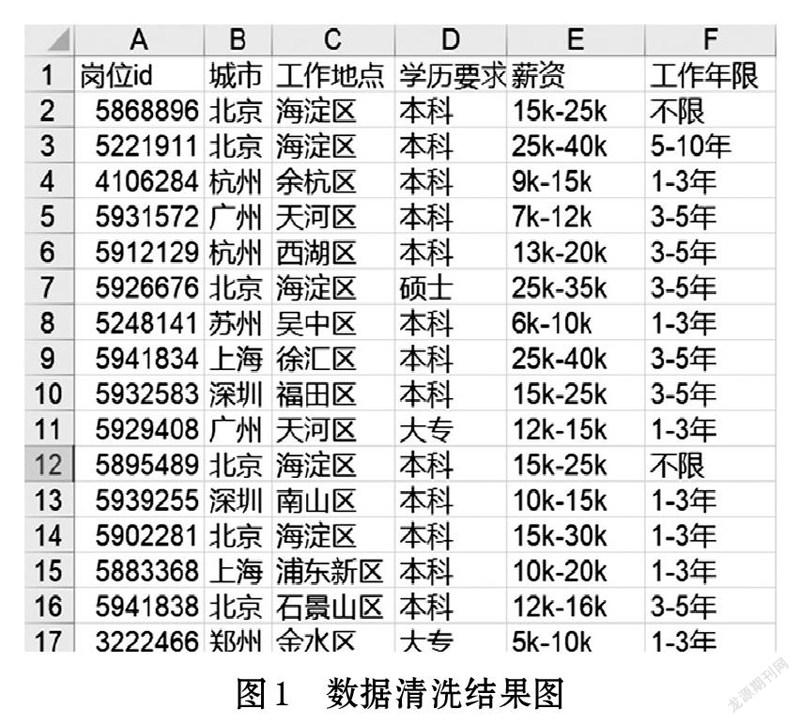
根據提出的問題,本次分析主要要用到的有positionId、city、district、education、salary以及workYear字段。先將不需要的信息進行刪除或隱藏,可以得到清洗結果,如圖1所示。
⑵ 刪除重復項
在前面的步驟中列名已經設置好了,所以可以忽略列名的重命名這項工作,直接進行刪除重復項的工作。由于每一個崗位都有一個它們獨特的崗位id,所以可以用該id鍵做主鍵進行去重操作,刪除重復項。
⑶ 缺失值處理
對刪除過重復項的數據進行查看,發現不存在缺失值,所以這項操作就可以直接忽略了。如果存在缺失值的話,可以用以下方式進行填充。①通過人工手動補全。②刪除缺失數據。③用平均數,中位數,眾數等統計值進行代替。④用機器學習的算法或者是統計模型來計算出相應的值,并用該數據進行填充。
⑷ 一致化處理
對于薪資列,都是數字,之后可能會進行排序的操作,而且這部分的數據以范圍的形式存在,不好處理。所以將這個薪水列細化為:最低月薪[bottom],最高月薪[top],平均月薪三列。
3.4 構建模型和數據可視化
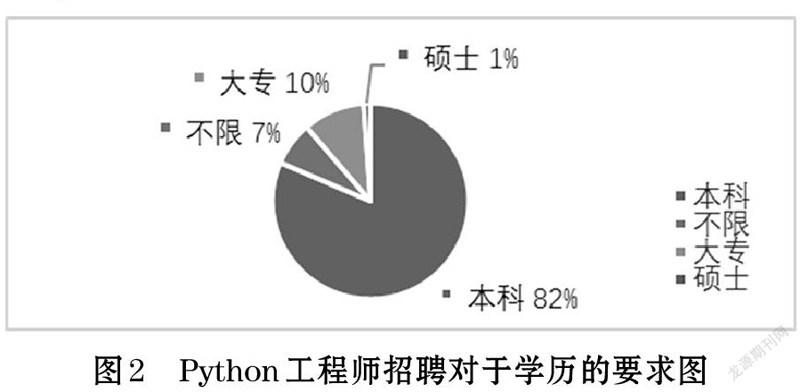
數據清洗的工作做完之后,就開始進行模型的構建,這部分主要用到的Excel表中的數據透視圖來進行關系之間的建模。根據提出的問題構建模型:Python工程師招聘對于學歷的要求(如圖2)。
從圖2可以看出,我國對于Python工程師的學歷并不是很看重。本科生的機會崗位有360個,占了總崗位數量的82%。大專學歷次之。也就是說,現階段對于Python工程師人才需求,準入的門檻不高。
Python工程師各個城市的招聘情況如圖3所示。由圖3各個城市的招聘情況看,北京明顯一枝獨秀,有148個崗位機會,上海和深圳次之,分別有87和75個。可以看出北上深等城市對于Python工程師的需求多。
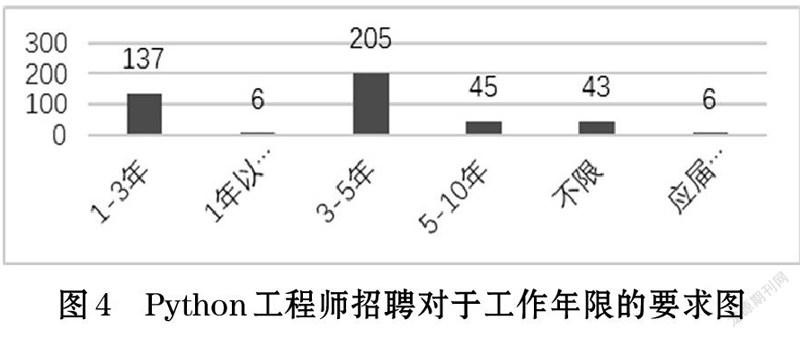
Python工程師招聘對于工作年限的要求如圖4所示。從圖4可以看出,3-5年工作經驗的機會崗位比較多,幾乎占據了總崗位的一半。接下來是1-3年工作經驗的,有137個。而招聘應屆生和工作經驗在一年以下的幾乎沒有。
4 結論
本文設計了一個基于Python的爬蟲,爬取拉勾網招聘信息,對數據進行清洗以及可視化的分析。通過可視化的圖表分析得出:北上深等一線城市對Python工程師的需求較多,對于Python工程師的學歷要求不高,但對工作經驗要求較高。
參考文獻(References):
[1] 宋超,華臻.電腦編程技巧與維護[J].2021.2
[2] 郭鋒鋒.基于python的網絡爬蟲研究[J].佳木斯大學學報
(自然科學版),2020.3
[3] 張懿源,武帥等.基于Python的疫情后就業影響分析[J].
計算機時代,2021(1)
[4] 戴瑗,鄭傳行.基于Python的南京二手房數據爬取及分析[J].
計算機時代,2021(1)
[5] 魏程程.基于Python的數據信息爬蟲技術[J].電子世界,
2018(11):208-209
