基于遷移學習的示功圖診斷方法
2022-02-26 01:40:54段志剛李漢周司志梅葉紅趙慶婕
石油化工自動化 2022年1期
段志剛,李漢周,司志梅,葉紅,趙慶婕
(中國石化江蘇油田分公司 石油工程技術研究院,江蘇 揚州 225009)
游梁式抽油機是油田開發的主要設備之一[1],及時掌握抽油機的作業情況對于提高石油產出量具有重要作用。由于井下環境復雜,抽油機在作業過程中往往會受到一些干擾導致作業異常[2],常見的作業異常包括: 上/下行遇阻、不平衡、供液不足、凡爾失靈、氣體影響等幾十種,其形成原因與表現形式各不一致,如何及時有效地識別不同作業故障非常具有挑戰。
現階段國內對于抽油機的故障診斷主要依據采油工程師對于示功圖的分析和油井管理經驗來確定[3-4]。懸點示功圖,也稱地面示功圖或光桿示功圖,是抽油井采油現場采集的第一手資料。示功圖不同的幾何形狀則代表著作業的不同工況,標準無異常的示功圖為平行四邊形,如果油井發生供液不足,示功圖的形狀則類似于一把刀,如圖1所示。傳統的示功圖故障檢測基于專家系統[5],對不同形狀的示功圖進行總結分析[6]。然而實際測量出的示功圖千變萬化,形成原因與故障對應關系錯綜復雜,過于依賴專家知識導致系統開發費時費力,且魯棒性較低。基于支持向量機算法(SVM)等分類模型也可以獲得不錯的效果[7],但前提是合理的特征選擇,同樣需要一定程度的領域知識和實驗分析。因此筆者嘗試從深度學習的角度出發,將示功圖的故障檢測問題轉化為圖像分類問題,實驗表明,無需大量領域知識和特征選擇即可實現對傳統方法的有效提升。
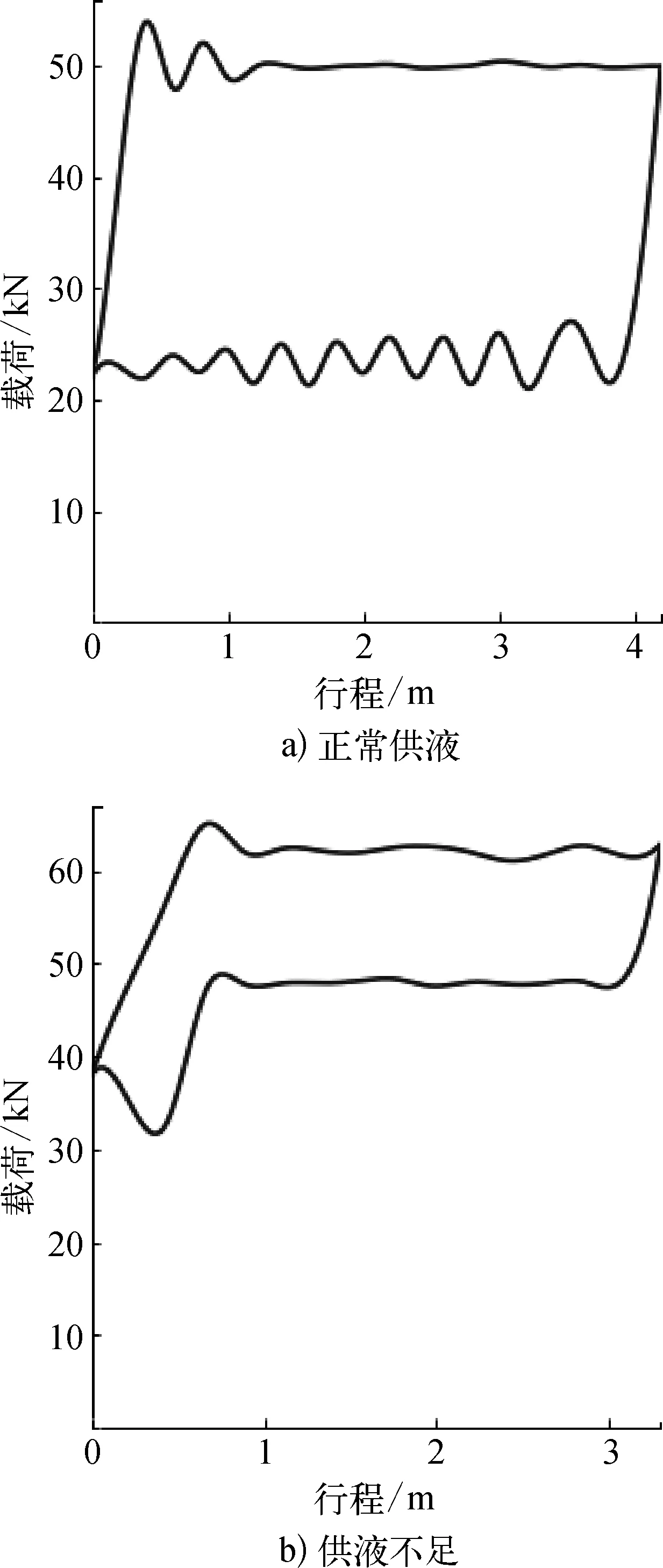
圖1 標準示功圖與供液不足時示功圖對比示意
該方法主要內容如下:
1)針對專家系統的性能限制,提出了利用基于卷積神經網絡的圖像分類方法實現對示功圖的異常診斷。
2)由于人員和成本的限制,很難獲得大量有標注的數據。本文基于預訓練的殘差網絡在少量示功圖標注數據上進行微調,將ImageNet數據集上標注好的語義信息遷移到示功圖分類上,避免了網絡從零初始化的過程。通過遷移學習使模型在少量有標注數據的情況下,依然取得了不錯的效果。
1 示功圖診斷的相關工作
1.1 基于示功圖的作業診斷方法
示功圖作為油田作業診斷的第一手資料,一直受到國內外學者的廣泛關注[8]。早期學者將專家系統用于抽油機工況診斷,利用領域知識與經驗建立了典型示功圖的規則集合的知識庫,可以使用推理機解析規則識別示功圖,實現識別診斷[9]。周寧寧等[10]通過模糊理論實現示功圖診斷,解決示功圖表示不明確的問題,將特征缺失面積與缺失行程定義為隸屬變量,設計隸屬函數求解出最佳隸屬度作為樣本類別。楊洋等[11]基于灰色理論,將經過歸一化后消除量綱、尺度的示功圖利用網格法得到灰度矩陣,再求解其灰度關聯特征得到6個元素的特征向量,最終與基準庫的11種典型示功圖特征作灰度關聯分析,從而實現診斷。Sun等[12]通過不變矩理論提取示功圖的幾何特征作為輸入,分別使用BP神經網絡和SVM作為分類器識別示功圖類型,其中SVM表現更好,83%的正確率高出BP神經網絡5個百分點。而隨著深度學習的發展,仲志丹等[13]通過稀疏自編碼器自動提取示功圖圖像特征,并通過softmax分類器做分類,在其測試集上獲得了98%的準確率[14]。
1.2 基于深度卷積網絡的圖像分類
深度學習[15]作為機器學習的一大分支,一直是業界的研究熱點之一,近年來,尤其在機器視覺和自然語言處理等領域獲得了重大突破。深度學習的概念起源于人工神經網絡,多層感知機就是一種最基礎的深度學習結構,無需手動設計特征,淺層輸入隨著網絡深入進行特征組合并在高層獲得更加抽象的表示,再通過梯度下降算法優化訓練損失就可以自動迭代地學習出恰當的樣本表達。圖像分類是深度學習最廣泛的應用場景之一,其主要任務是將圖片數據中同種類型的圖片識別出來,強調對圖像整體的語義理解。相較于多層感知機,深度卷積神經網絡通過卷積核進行特征抽取,結合池化層進行采樣,既使得模型對圖片的平移,放縮等變化具有一定程度的抗干擾能力,也可以有效降低網絡的復雜性,減少參數量,在圖像分類領域中應用最為廣泛。Alex等[16]提出的AlexNet首次將深度卷積網絡應用于大規模圖像分類ImageNet上,大幅超越傳統算法。谷歌團隊在ILSVRC2014上發布的GoogleNet[17]基于Network in network思想進一步提出Inception模塊以稠密組實現了有效降維,減少了模型參數的同時也減輕了過擬合問題。隨后不久又提出的batch normalization進一步提升GoogleNet的泛化能力,獲得了更好的效果。然而隨著網絡深度的進一步加深,模型卻由于過擬合和梯度消失等原因出現了退化現象,直到深度殘差網絡ResNet的出現[18],通過殘差結構將網絡深度成功地加深到152層,進一步解放了深度學習的上限[19]。
與此同時,研究者經過可視化方法發現,處理圖像任務的神經網絡其底層特征具有較高的一致性,大多為線條,紋理等信息,僅在上層任務相關的部分存在較大差別,將大量有標注數據的源領域知識遷移到少量標注或無標注目標領域的方法便稱為遷移學習[20]。由于ImageNet具有數據集規模大、種類多、信息豐富的特點,基于ImageNet預訓練好的模型通常具有很強的泛化能力,因此是機器視覺任務中最常見的源領域數據集。將該預訓練模型進一步在其他任務上進行微調時,相較于一個從頭訓練的模型,微調模型不但能提高精度,且在少量有標簽數據的情況下就可以獲得不錯的效果。
2 解決方案
2.1 問題定義
示功圖診斷指將油田作業示功圖分類至正常、不平衡、氣體影響、供液不足、凡爾失靈等30個類別中,屬于圖片多分類問題。常規示功圖數據在數據庫中以二進制編碼的形式保存,經由Python程序解碼后在畫布上作圖而形成圖片,保留橫縱坐標軸為模型識別提供尺度信息,并以224×224的分辨率保存在本地。
2.2 模 型
整個模型架構如圖2所示,輸出通過中間的預訓練模型進行特征提取,預訓練模型內部包括多個殘差塊;再通過全連接層將特征向量變成目標分類的概率分布實現模型預測;最后通過以softmax激活函數將概率分布歸一化,獲得最終的分類結果。
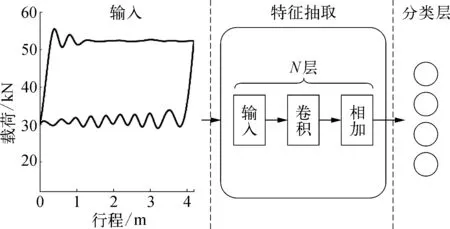
圖2 示功圖診斷神經網絡模型結構示意
2.3 基于深度殘差網絡的特征抽取模塊
殘差網絡泛指以多個殘差塊堆疊而成的深層網絡,每個殘差塊中又可以包含多個卷積層。殘差網絡的主要思想是: 將網絡的輸入與輸出相加作為該結構的最終輸出,使得模型在前向傳播的時候可以保持上一層信息不丟失地傳入下層,而在反向傳播時,又可以將梯度直接傳遞到上一層,從而避免梯度消失問題,大幅提高了模型的泛化能力。具體地,以ResNet為例,其殘差結構如式(1)所示:
hl+1=Relu(hl+F(hl,wl))
(1)
式中:hl,hl+1——分別為該殘差塊的輸入和輸出;F——殘差映射函數,如卷積操作等;wl——對應參數。Relu的激活函數如式(2)所示:
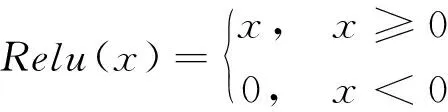
(2)
先將殘差網絡在ImageNet的有標注數據集上預訓練,接著刪除最頂層的分類層,把中間的輸出層作為特征抽取模塊。以該預訓練參數作為初始化進行遷移學習,可使模型獲得一定與圖像相關的先驗知識,使得模型無需重新學習低級語義信息,避免了參數從零初始化的窘境。
2.4 Softmax分類器
模型上層是任務相關的分類器,由一個全連接層加Softmax模型的激活函數組成。分類器函數如式(3)所示:

(3)
式中:H——最后一層輸出特征;W,b——對應全連接層的可學習參數。經過全連接層將向量維度修正為N維向量Z,每一維度代表著該次預測在對應示功圖分類的概率大小。Softmax模型的激活函數如式(4)所示:
(4)
通過Softmax分類器對概率分布進行歸一化,取概率最大值所在維度作為最終預測結果。
3 實 驗
3.1 數據準備
實驗數據取自某油田作業數據庫,通過人工標注出30個示功圖類別,將整個數據集以3∶1的比例劃分為訓練集和測試集,取典型7種示功圖的實驗結果進行分析,包括: 正常、抽噴、不平衡、供液不足、氣體影響、氣鎖和桿斷。具體數據分布見表1所列。
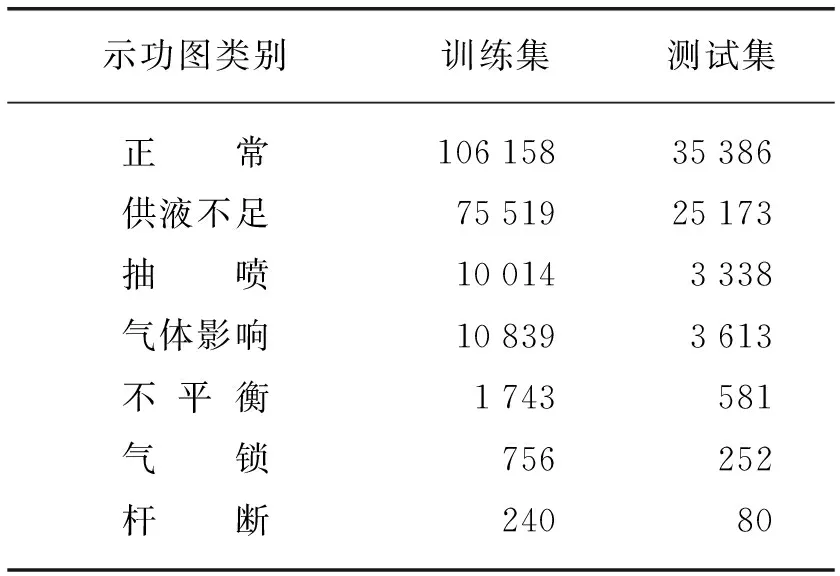
表1 訓練數據分布
表1中,正常、供液不足、抽噴、氣體影響等都屬于樣本充足的類型,不平衡是稍微欠缺,氣鎖和桿斷則屬于十分稀少的類別,因此該數據集存在很嚴重的樣本不均衡現象。每張圖片都經過數據增強來提高數據集質量,數據增強方式包括: 旋轉、放縮、裁剪,但不包括翻轉,因為示功圖翻轉之后有可能改變其所屬類別。
3.2 實驗設置
首先,預訓練的特征抽取模塊不固定參數,而是隨著整個網絡一同訓練,學習率為0.000 1,使得模型主要更新任務相關部分,而不至丟失預訓練信息。優化器為adam,具有較好的收斂效果。每批次實驗采樣個數為64,可較好地平衡訓練速度和精度。損失函數為交叉熵,評價指標為準確率,綜合評價指標為宏平均與微平均,其中宏平均是先對每一個類統計指標值,然后在對所有類求算術平均值,微平均是根據樣本數量采用加權的方式再取平均,可以更好地衡量模型對不平衡樣本的性能。詳細實驗參數設置見表2所列。
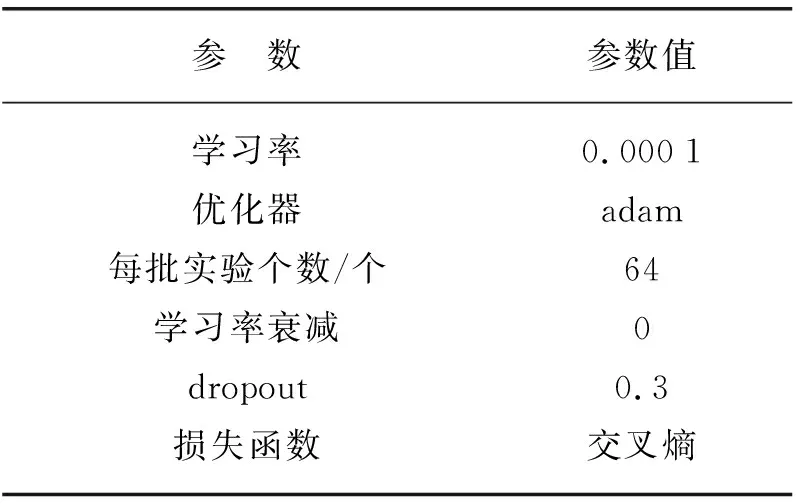
表2 實驗詳細參數
3.3 不同模型的實驗對比
本文探究了不同殘差網絡作為特征抽取器的效果,包括ResNet,DenseNet與MobileNet。
ResNet由微軟研究院的何愷明等人提出,率先將殘差結構引入深度神經網絡中,將網絡深度首次突破100層,是目前最經典圖像處理網絡之一。
DenceNet[21]是對ResNet的一次拓展,相較于ResNet,每個殘差塊是前后直連,DenceNet提出來一個密集連接機制,即網絡中的所有層都互相連接,具體而言,每一層網絡都會接受其前面所有層的輸出作為其輸入。在同等參數量時,具有比ResNet更好的性能。
MobileNet[22]是一種輕量級的神經網絡,采用深度可分離卷積代替普通卷積操作,以降低模型的計算量和參數量。MobileNet在盡可能保證圖像分類精度的同時,大幅縮短了網絡推理速度,是追求實時性應用的不二之選。
3.4 實驗結果與分析
不同模型精度的實驗對比見表3所列,從表3來看,三個模型在微平均精度上差距不大,MobileNet最高,為98.75%,ResNet其次,為98.71%,DenceNet則稍低一些,為98.27%,比前兩者低了0.5個百分點。在宏平均精度上的差距較為明顯,ResNet具有最高的宏平均精度為97.13%,相較于宏平均精度第二的MobileNet高出1.2個百分點,且大幅超過DenceNet的宏平均精度。

表3 不同模型精度的實驗對比 %
具體從各個類別分析,對于樣本數量十分充足的類別: 正常、氣體影響、抽噴和供液不足,三個模型均取得了不錯的效果,對于樣本數量相對較少的不平衡示功圖,各個模型都達到了99%以上的準確率,甚至高于樣本充足的四種示功圖。但是隨著樣本數量進一步減少時,氣鎖和桿斷的訓練集樣本均小于1 000個,模型精度大幅下降。以ResNet為例,在訓練樣本為756的氣鎖示功圖上,精度為94.44%,相較于前五種示功圖下降了4個百分點,訓練樣本數為240的桿斷,效果最差,精度只有91.25%,低了7個百分點。其他兩個模型也存在著同樣的現象。由此可見,在該數據集上1 000個訓練樣本是劃分長尾樣本的分割線,數據量達到1 000之后對精度就不會有有效提升,數量在1 000以下則影響巨大。
從三個模型對于氣鎖和桿斷等不均衡樣本來看,ResNet具有最強的魯棒性,DenceNet最差,可見DenceNet各個層的充分連接帶來的強大擬合能力在此處反而使得模型忽略了少數樣本的特征。MobileNet更加簡潔,因此效果更好,但是相較于ResNet更為強大的遷移學習能力,在少樣本上自然稍遜一籌。
4 結束語
本文探索了深度學習背景下的示功圖診斷方法,一方面將示功圖診斷作為圖像分類問題進行建模;另一方面基于預訓練的深度殘差網絡在示功圖分類上做遷移學習,既提高了模型的精度,也減少了訓練對大量樣本的依賴。實驗表明,該方法簡潔有效,具有較強的實用性。
在未來的工作中,將重點研究示功圖故障樣本不平衡問題,尤其是少樣本示功圖的處理方法,嘗試結合數據挖掘等方法進一步提高少樣本故障的檢測精度。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
