
聯邦學習通信開銷研究綜述
2022-03-01 12:33:42邱鑫源葉澤聰崔翛龍高志強
計算機應用 2022年2期
邱鑫源,葉澤聰,崔翛龍,高志強
(1.武警工程大學研究生大隊,西安 710086;2.武警工程大學反恐指揮信息工程研究團隊,西安 710086;3.武警工程大學烏魯木齊校區,烏魯木齊 830049)
0 引言
眾所周知,機器學習的性能依賴于大量可用的訓練數據:數據越豐富,機器學習所得模型的性能往往會越好。然而人們越來越重視數據隱私安全,法規制定者和監管機構也出臺了很多規范數據管理和使用的法律。面對數據共享需求與隱私保護要求之間不可調和的矛盾,聯邦學習這一解決方案應運而生[1-3]。
聯邦學習是一種借助多個參與方的本地數據,聯合訓練一個全局模型的分布式機器學習架構。具體地,每個參與方的數據存儲在本地,在中央服務器的協調下,多個參與方聯合完成機器學習任務(如圖1),其工作流程描述如下。

圖1 聯邦學習架構Fig.1 Architecture of federated learning
1)參與方選擇:中央服務器從滿足條件的參與方集中選擇合適的參與方;
2)初始化:被選擇的參與方從中央服務器下載初始模型的參數;
3)本地訓練:每一個被選擇的參與方利用自己的本地數據訓練初始化模型,把更新的參數傳給中央服務器;
4)聚合:中央服務器收集各個參與方更新的參數;
5)模型更新:中央服務器根據聚合結果更新全局模型的參數,并下發至參與方。
重復步驟3)~5),直到全局模型滿足既定的要求,即達到預設的性能指標或達到預設的時間。
圖2 體現了聯邦學習各節點可采用的降低聯邦學習通信開銷的幾類方法。
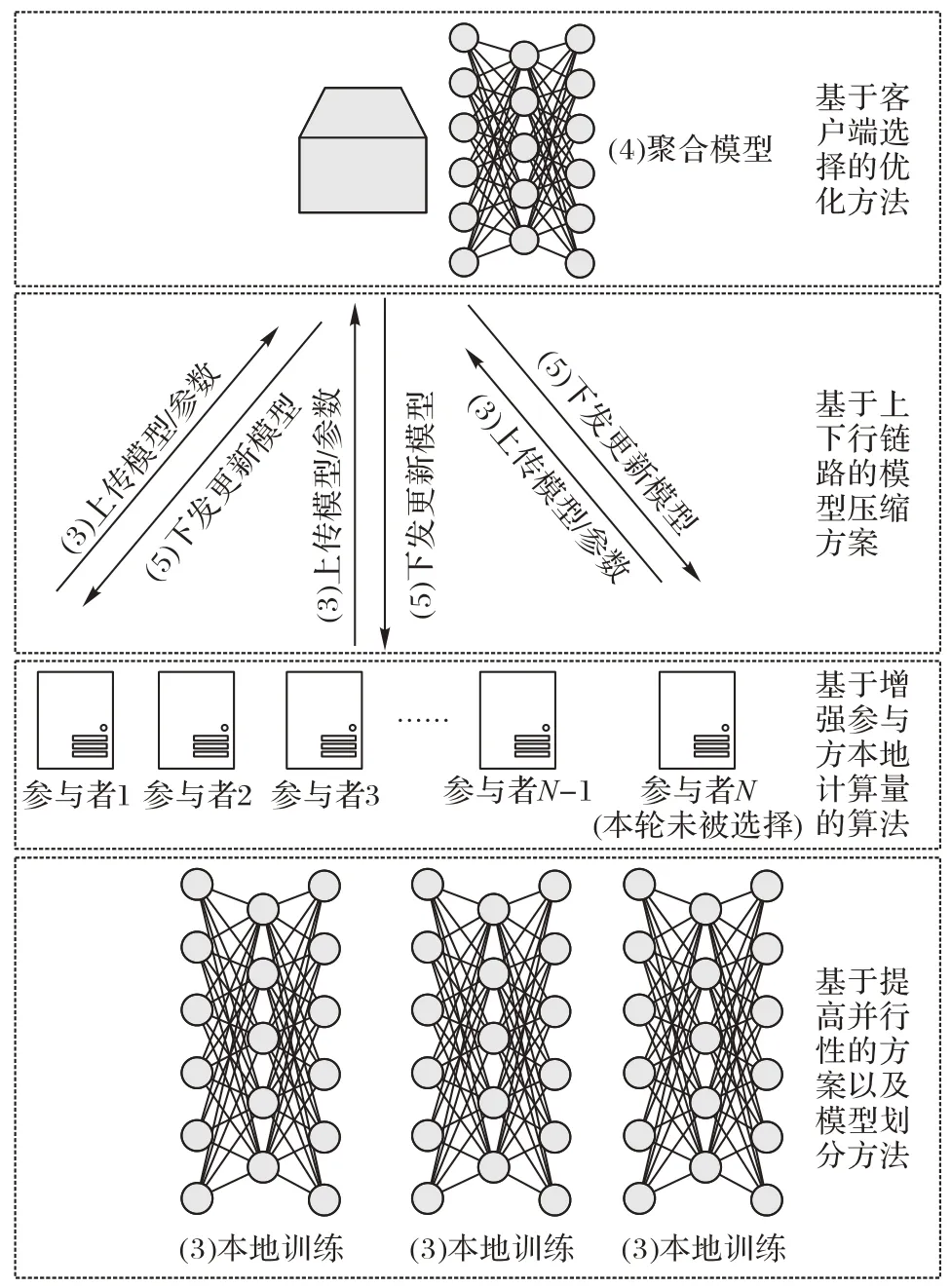
圖2 聯邦學習工作流程的第3)~5)步Fig.2 Steps 3)-5)of federated learning workflow
從工作流程可以看出,參與方與中央服務器需要不斷交換大量模型參數,通信時間、通信次數、傳送數據的總比特數較高,造成了較高的通信開銷;其次,聯邦學習越來越多地部署在通信帶寬有限、電量有限的移動設備上,加之有限的網絡帶寬和大量的客戶端增加了連接受限的客戶端掉隊的概率,延長了通信時間。因此,通信開銷和通信效率成為了聯邦學習的關鍵瓶頸之一,研究如何降低聯邦學習的通信開銷變得十分必要。然而目前國內學者主要對其隱私保護[4-6]、應用場景[7-9]等進行了綜述研究,卻鮮見與聯邦學習通信開銷方面有關的研究[10]。研究如何降低聯邦學習通信開銷,對聯邦學習的落地應用,尤其是在電量有限、通信帶寬受限的移動設備上的應用[11],具有很重要的現實意義。
通信開銷一般包含兩層含義:一是通信數據總量;二是通信總時耗。由于聯邦學習是一個不斷交互更新的通信過程,本文研究的通信開銷特指聯邦學習達到預設性能指標(如特定精度值)所需傳輸的數據總量和通信輪次。因此,降低通信開銷通常可以從減少通信總次數、降低通信頻率以及減少單輪通信回合的通信總比特數入手。減少通信總次數主要依靠降低模型更新頻率和選擇更少的客戶端進行通信;而減少單輪通信回合數據量則主要依靠進行適當的模型壓縮,以降低通信占用的帶寬。
McMahan 等[12]提出的聯邦平均算法將每個客戶端上的局部隨機梯度下降(Stochastic Gradient Descent,SGD)與執行模型平均的服務器相結合,是一種通過增加本地計算能力降低通信頻率的典型算法。模型壓縮,比如模型稀疏化、量化、聯邦蒸餾、低秩與子抽樣等技術,則是采用減少單輪通信回合的數據量的思路,可以大幅壓縮要傳輸的局部模型,從而節省通信開銷。
本文的主要工作如下:
1)對近幾年降低聯邦學習通信開銷的基本方法,進行整理,如圖3~4 所示:圖3 將各類方法進行了歸納分類,圖4 對目前一些主流算法按照發表時間進行了羅列,體現了降低通信開銷方法的研究進展。

圖3 降低通信開銷的典型算法Fig.3 Typical algorithms of reducing communication overhead

圖4 降低通信開銷的研究方法時間軸Fig.4 Methods of reducing communication overhead in chronological order
2)明確了幾類主流方法作用原理,并對比其作用節點(如圖2 所示),詳細介紹、分析了如圖3 所示的幾種典型算法。
3)由于目前還沒有標準化、統一化、權威性的指標來衡量聯邦學習的通信開銷,本文從優化角度、應用場景角度出發,對文獻中的幾種典型算法進行了對比分析。
4)對聯邦學習通信開銷技術研究的發展趨勢進行了總結和展望。
1 基于降低模型更新頻率的優化方法
起初,在聯邦學習工作流程的本地訓練中,客戶端都是在本地運行SGD 等算法后生成本地模型。而聯邦學習隨機梯度下降(Federated SGD,FedSGD)算法是每一輪通信都在隨機選擇的客戶端上進行單個批次梯度計算,這種方法計算高效,但需要再將梯度計算結果傳給中央服務器,通信代價較高。針對這一問題,降低通信代價的一種行之有效的辦法就是降低通信頻率,即降低模型更新頻率。部分學者通過犧牲計算代價換取通信開銷,即增加參與方的計算量或提高并行性以減少訓練模型所需的通信次數:
1)增加參與方的計算量:每個參與方在每個通信回合之間執行更復雜的計算。具體地,每個參與方執行隨機梯度下降的多次迭代以計算權重更新,而不是在每次迭代后進行權重更新進行通信。
2)提高并行性:引入更多的參與方在每個通信回合之間獨立工作,使得計算更快,減少通信時間,不過更多參與方可能導致相對更多通信開銷。
1.1 增強參與方計算量
為了克服FedSGD 通信代價較高的缺陷,很多學者提出一些犧牲本地計算代價換取通信代價的算法,其中包括聯邦平均(Federated Averaging,FedAvg)算法等[12-15],其在CIFAR-10 測試集上性能對比如表1 所示。CIFAR-10 測試集是用于識別普適物體的小型數據集,一共包含10 個類別的尺寸為32×32 的RGB 彩色圖片,數據集中一共有50 000 張訓練圖片和10 000 張測試圖片。CIFAR-10 測試集獲取地址:https://github.com/tensorflow/models。

表1 CIFAR-10測試集上同一目標精度下不同算法的通信輪次Tab.1 Communication rounds of different algorithms with same target accuracy on CIFAR-10 test set
McMahan 等[12]提出的聯邦平均算法將局部隨機梯度下降與執行模型平均的服務器相結合,通過客戶端先多次迭代本地更新再將本地迭代結果發送給服務器。
實驗結果如表2~3 和圖5 所示。表2~表3 中E表示每個客戶端在每一通信輪次上對數據集進行本地訓練的次數;B表示用于客戶端更新所需的本地最小批次量的大小;u表示每個用戶每輪預計更新的數量,(nk為客戶端k擁有的數據樣本數,K為客戶端集合中客戶端總數量,Ε[nk]為nk的期望值,n為客戶端集合中樣本總數)。在FedSGD 中,E=1,B=∞。表2 的MNIST 測試集是手寫數字數據集,來自美國國家標準與技術研究所,由250 個志愿者手寫數字構成。該數據集圖像是固定大小(28×28 像素),包含60 000 個用于訓練的圖片和10 000 個用于測試的圖片。MNIST 測試集獲取地址:http://yann.lecun.com/exdb/mnist/。表3 的SHAKESPEARE 測試集是語言模型測試集,采集了莎士比亞戲劇作品中各角色的臺詞,常用于字符預測,以莎士比亞作品集前80%行(3 564 579 個字符)作為訓練集,后20%行(870 014 個字符)作為測試集。SHAKESPEARE 測試集獲取地址:https://www.gutenberg.org/ebooks/100。由表2~3 和圖5 可以看出,不論是在卷積神經網絡(Convolutional Neural Network,CNN),還是在長短期記憶(Long Short Term Memory,LSTM)網絡上,為了達到相同目標精度,該方法所需通信輪次明顯少于隨機梯度下降,但FedAvg 僅在數據獨立同分布(Independently Identically Distribution,IID)時,優化效果明顯,數據非獨立同分布(non-Independent Identically Distribution,non-IID)時性能較差。

表2 MNIST測試集上99%目標精度下FedSGD與FedAvg所需通信輪次[12]Tab.2 FedSGD and FedAvg communication rounds under 99%target accuracy on MNIST test set[12]

表3 SHAKESPEARE測試集上54%目標精度下FedSGD與FedAvg所需通信輪次[12]Tab.3 FedSGD and FedAvg communication rounds under 54%target accuracy on SHAKESPEARE test set[12]

圖5 CIFAR-10測試集上FedSGD與FedAvg測試精度對比[12]Fig.5 Test accuracy comparison of FedSGD and FedAvg on CIFAR-10 test set[12]
Alistarh 等[13-15]在McMahan 的基礎上優化了FedAvg 算法,增加每一輪迭代在每個客戶端本地更新參數的計算次數,將該方法與FedSGD 算法進行對比。通過MNIST 卷積神經網絡測試,結果表明:當數據IID 時,該算法可以明顯降低通信成本;但當數據non-IID 時,算法依舊只能輕微地減少通信開銷。顯然,聯邦學習的數據基本都呈non-IID,因此FedAvg 算法及Alistarh 提出的優化算法雖然較FedSGD 算法通信成本更低,但其實應用場景有限,需要進一步探究針對non-IID 數據的優化算法。
因此,Li 等[16]提出了更通用的FedProx(Federated Proximal)算法,在每一輪中,只對一部分客戶端進行采樣以執行更新,這種算法在數據為non-IID 時優化效果更明顯。FedProx 算法可以動態地更新不同客戶端每一輪需要本地計算的次數,不需要參與方在每次更新時統一運算次數,因此該算法更適用于非獨立同分布的聯合建模場景。
1.2 提高并行性
并行計算分為同步并行和異步并行,引入更多參與方后,可以顯著減少整個聯邦學習系統的通信時間和單個參與方的通信量。但同步并行計算中存在顯著的“短板效應”:當某個參與方出錯需要重新計算時,該節點計算所需時間比其他所有節點都多很多,但此時其他節點依然需要一直等待該節點完成計算方可進行下一步,這樣空轉時間長,工作效率低。
為了解決這種“短板效應”,Shi 等在文獻[17]中提出了一種設備調度方案,以平衡訓練輪與每輪之間的關系。Zhou等[18]則從算法框架的角度出發,將通信與訓練并行,基于集合分層計算策略、數據補償機制和NAG(Nesterov Accelerated Gradient)算法,提出重疊聯邦平均(Overlap FedAvg,Overlap-FedAvg)算法,該算法可與許多其他壓縮方法正交,以最大限度利用集群,以FedAvg 算法為基線對比組,在數據non-IID 場景下分別使用MLP 等模型在不同數據集上訓練,Overlap-FedAvg 算法單次迭代訓練需要的時間都短于普通FedAvg 算法,實驗結果如表4 所示。

表4 Overlap-FedAvg與FedAvg平均每次迭代耗時對比[18]Tab.4 Comparison of average wall-clock time of Overlap-FedAvg and FedAvg for one iteration[18]
從表4 可看出,該重疊FedAvg 框架具有并行性,能夠在保持與FedAvg 幾乎相同的最終精度的前提下,大大加快聯邦學習過程,非常適用于模型相對較大且客戶端的網絡連接緩慢或不穩定的場景,對不平衡和non-IID 數據分布具有魯棒性,可以減少在分散數據上訓練深度網絡所需的通信輪次。表4 中MLP 為多層感知機(MultiLayer Perception),也稱作人工神經網絡(文獻[12]用MLP 和CNNCifar 驗證了FedAvg 的有效性,文獻[18]則對普通FedAvg 和Overlap-FedAvg 進行性能對比)。
2 基于模型壓縮的優化方法
模型壓縮也稱為稀疏化,更新的模型結構用更少的變量刻畫,壓縮方案可以是隨機稀疏模式、概率量化、梯度量化、子抽樣、低秩等方法的一種或多種組合。如圖2 所示,壓縮方案可以在聯邦學習的不同階段執行:參與方訓練本地模型之前(下行鏈路),即中央服務器壓縮全局模型的規模后廣播給各參與方;參與方上傳更新模型之前(上行鏈路),各參與方壓縮本地訓練模型參數的規模后上傳給中央服務器。
Kone?ny 等[19]為了減少上行鏈路的通信消耗,考慮通過結合低秩、稀疏化、隨機分散和概率量化,設計結構化更新和壓縮更新的方法。結構化更新即直接在受限空間學習更新,使用較少數量的變量進行參數化;壓縮更新即學習完整的更新模型后,進行壓縮再發送給服務器。在卷積網絡和遞歸網絡上實驗結果表明:該算法與傳統FedAvg 算法相比,可實現通信回合次數減少兩個數量級,不過其收斂速度略有下降。Dinh 等[20]的實驗結果表明,所有參與者的梯度稀疏程度共同影響了全局收斂性和通信復雜性。下面給出隨機稀疏、量化、知識蒸餾等基本策略。
2.1 隨機稀疏
隨機稀疏是根據預先設定的隨機稀疏模式,由稀疏矩陣刻畫本地更新的模型H,該模式在每一輪中為每個客戶端獨立重新生成矩陣。
Shi 等[11]將訓練算法與本地計算、梯度稀疏相結合,提出更靈活的柔性稀疏法(Flexible Sparsification,Flexible Spar):對參與方施加誤差補償,本地計算允許在每兩個全局模型更新之間對5G 移動設備執行更多的本地計算,從而減少通信回合的總次數;梯度稀疏允許參與者只上傳一小部分具有顯著特性的梯度,從而減少每一輪的通信有效載荷。在5G 移動設備上進行實驗,結果如圖6~7 所示,表明該方法能耗更低,適用于異質移動設備,與統一稀疏化(Unified Sparsification,Unified Spar)在收斂速度和最終精度方面表現出非常相似的性能特征,但二者的最終精度都略低于FedAvg 算法,這也反映了模型壓縮的缺點:在降低通信開銷的前提下,不可避免地犧牲部分精度,造成最終模型性能下降。

圖6 同一目標精度下Flexible Spar、Unified Spar和FedAvg能耗對比[11]Fig.6 Energy consumption comparison of Flexible Spar,Unified Spar and FedAvg under same target accuracy[11]
Sattler 等[21]基于非獨立同分布、不平衡和小規模batch的本地數據,提出一種新型稀疏三元壓縮(Spatio-Temporal Context,STC)框架,其中STC 通過稀疏化、三元化、錯誤累積和最佳Golomb 編碼擴展當前的top-K梯度稀疏化的上行和下行壓縮方法,在減少每一通信輪次傳輸數據量的同時還可以降低通信頻率。然后,Li 等[22]運用了與文獻[11]和文獻[21]類似的思想,集成局部計算和梯度稀疏,提出了具有動態批處理大小FT-LSGD-DB(Flexible Top-KLocal Stochastic Gradient Descent with Dynamic Batch size)的柔性Top-K局部隨機梯度下降算法,通過允許參與方執行不同“K”值的梯度稀疏化,實現了靈活壓縮。與文獻[11]較為相近,文獻[22]在進行性能評估時同樣以FedAvg 作為基準,并加入了貪婪壓縮法(Greedy Sparsification,Greedy Spar)作對比,實驗結果如圖8 所示:圖8(a)~(b)表示在CIFAR-10 數據集上使用ResNet20 模型進行訓練時,隨著參與方數量增大、參與方異構性水平更高時,FT-LSGD-DB 算法相較其他算法節省的能耗更多;圖8(c)~(d)為在MNIST 數據集上使用LeNet5-Caffe模型進行訓練,體現了FT-LSGD-DB 算法在節省通信消耗方面的優勢,該方法在適應異質移動邊緣設備和提高聯邦學習邊緣的能量效率方面具有很大潛力。
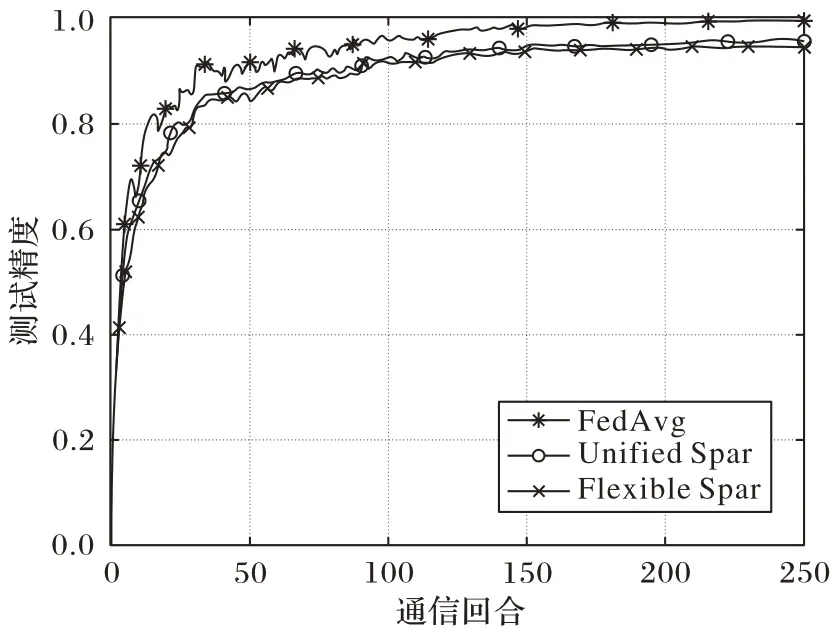
圖7 同一目標精度下Flexible Spar、Unified Spar和FedAvg所需通信次數對比[11]Fig.7 Communication times comparison of Flexible Spar,Unified Spar and FedAvg under same target accuracy[11]
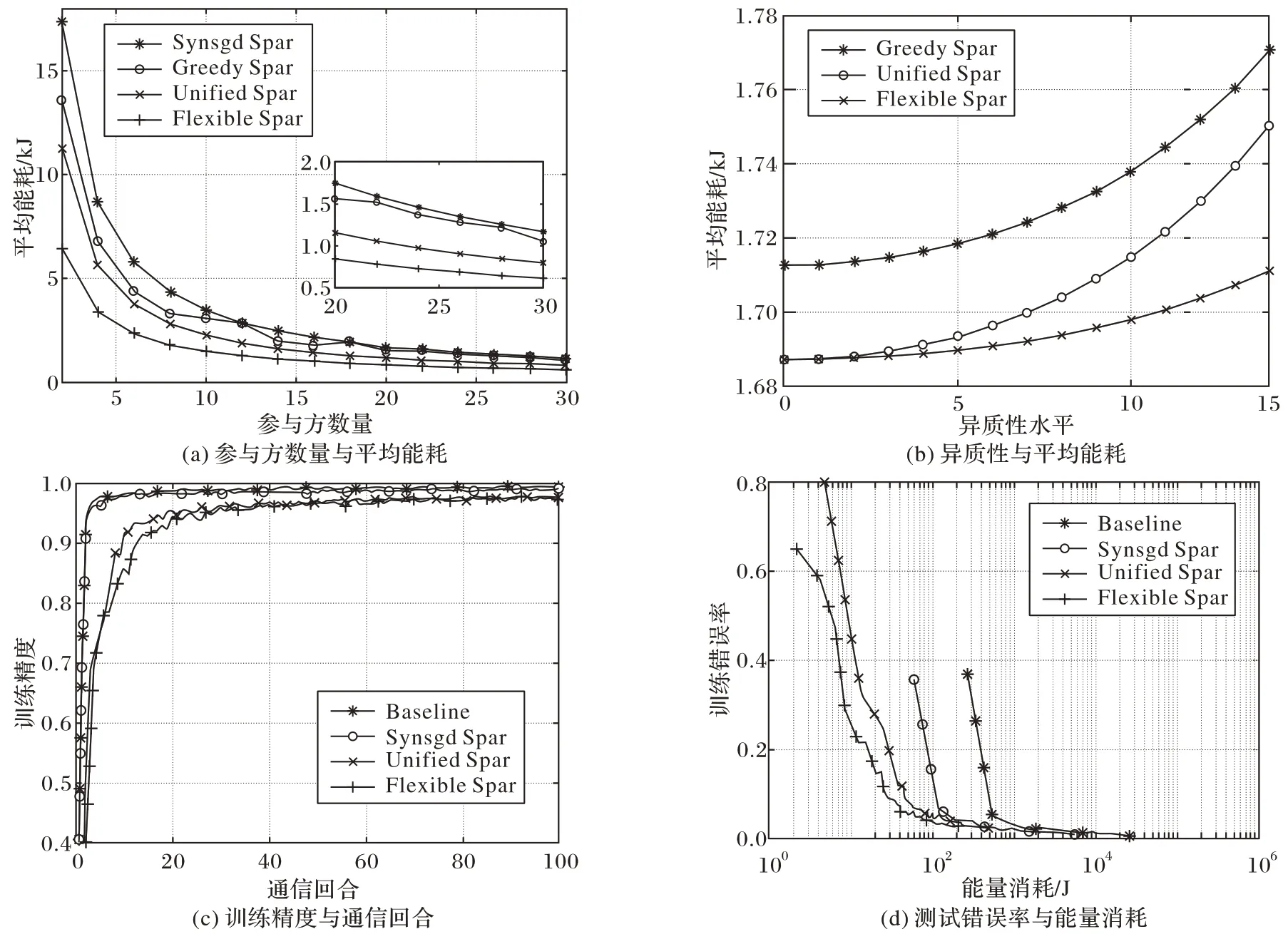
圖8 Flexible Spar等算法能耗、精度、通信次數對比[22]Fig.8 Comparison of Flexible Spar and other algorithms on energy consumption,precision and communication times[22]
2.2 量化
量化最初用于數據壓縮,對需要數百萬參數的深度學習至關重要,能夠顯著降低通信成本,但依舊有損模型性能。量化一般分為概率量化與梯度量化。前者是本地更新模型向量化后,對其權重量化;后者是將梯度量化成低精度值以降低通信帶寬,應用更為廣泛。通過量化本地計算梯度,將梯度量化為低精度值而非直接上傳原始梯度值,能降低每回合通信代價、通信比特數,但這樣會降低精度,反而增加總體計算能耗。
最開始提出的量化方案是線性的,但最基本的線性量化方法,性能往往表現得不夠好。因此,Ye 等[23]以非線性的方式劃分空間,提出了一種基于cosine 函數的非線性量化方案cosSGD(cosine SGD),不需要誤差反饋等額外梯度恢復信息[24]來調整梯度,與之前的線性量化、文獻[24-26]中的低比特壓縮方案相比,能夠在更新客戶端梯度時將數據量壓縮至原來的0.1%,極大地節省了通信開銷。此外,Chen 等[27]將能量最小化問題描述為混合整數非線性規劃問題,融合無線傳輸和權重量化,以最小化全局模型的損失函數為目標,應用廣義彎曲分解(Generalized Benders’Decomposition,GBD)算法,提出不同5G 移動設備的帶寬分配和靈活權重量化(Flexible Weight Quantification,FWQ)的壓縮策略。在CIFAR-100、CIFAR-10 測試集上實驗,結果如圖9 所示,得出FWQ 與隨機量化(Rand Quantification,RandQ)、全精度(Full Precision)、統一量化(Unified Quantification,UnifiedQ)策略相比,實現了保證精度的前提下,總體計算和通信能耗最小化。同樣地,Chang 等[28]結合多個接入信道(Multiple Access Channel,MAC)技術,提出了MAC 感知梯度量化方案:根據各用戶梯度信息性和底層信道條件,基于MAC 的容量區域優化進行參數優化,這種信道感知量化與均勻量化相比,能夠更加充分利用信道,但未來需要與隨機稀疏等策略[29-31]相結合,降低其通信開銷,進一步提升性能。
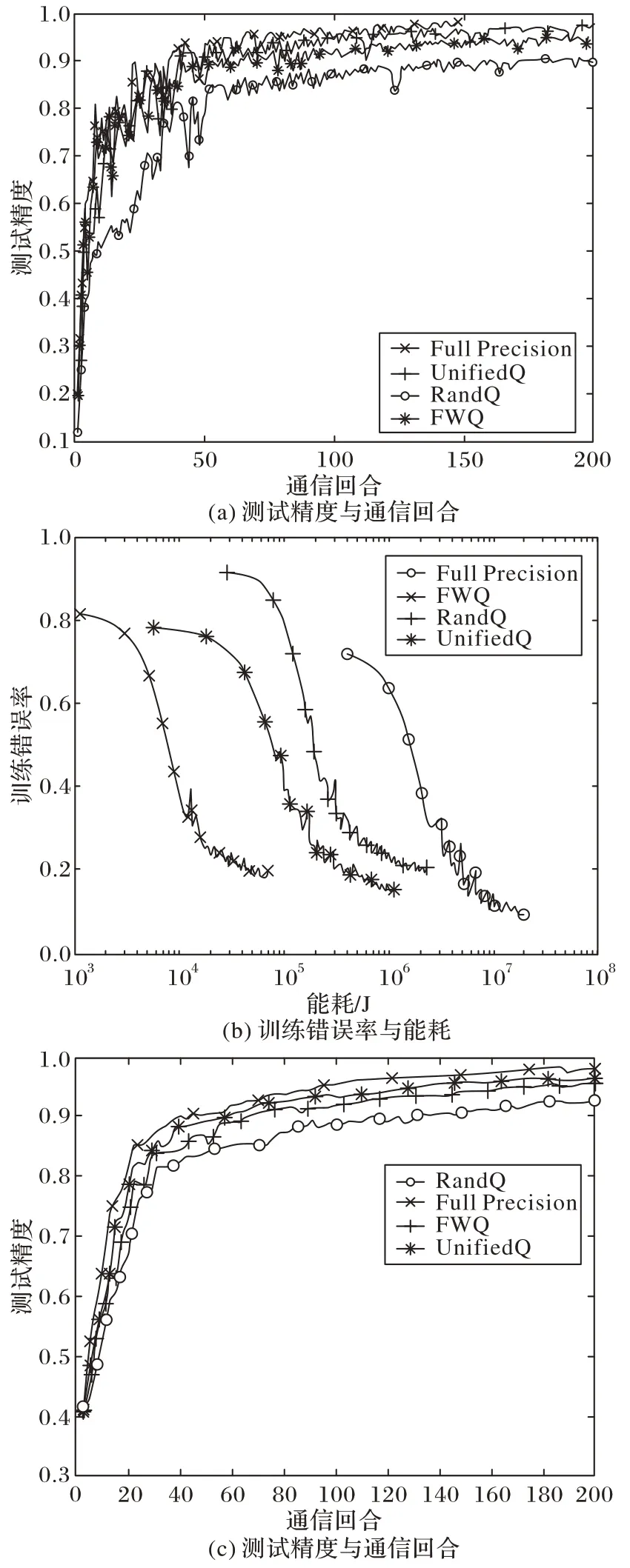
圖9 CIFAR-100以及CIFAR-10測試集上FWQ等算法的精度、能耗對比[27]Fig.9 Comparison of accuracy and energy overhead of FWQ and other algorithms on CIFAR-100 and CIFAR-10 test sets[27]
2.3 聯邦蒸餾
2015 年,Hinton 等[32]提出知識蒸餾法(Knowledge Distillation,KD):先利用大規模數據訓練得到一個教師網絡,將教師網絡的知識遷移到學生網絡上,使得學生網絡的性能表現和教師網絡相似;并以手寫數字識別和語音識別為例,驗證了知識蒸餾方法的有效性及模型的泛化能力。而后,Jeong 等[33]提出了聯邦蒸餾(Federated Distillation),其基礎是只交換局部模型輸出而非交換傳統聯邦學習采用的模型參數,這些輸出的尺寸通常比模型尺寸小得多,因此可以減少通信消耗。聯邦蒸餾與聯邦平均有著完全不同的通信輪廓,更適用于異構客戶端,頗具新穎性,但其基本原理較為復雜,只有少數著作[32,34-35]試圖分析其收斂性。聯邦蒸餾的工作流程如下:
1)在本地訓練期間,每個工作節點存儲每個標簽的平均logit向量。
2)每個工作節點定期將其本地平均logit向量上傳到參數服務器,并對接收到的其他工作節點的本地平均logit向量進行平均。
3)每個工作人員從服務器下載構建所有標簽的全局平均logit向量。
4)在基于知識蒸餾的本地訓練中,每個工作節點選擇其教師網絡的logit作為全局平均logit,標記為與當前訓練樣本的基本事實(ground-truth)相同的標簽。
Sattler 等[36]利用知識蒸餾的協同蒸餾(Cooperated Distillation,CD)的關鍵原理,提出壓縮聯邦蒸餾方法(Compressed Federated Distillation,CFD),可以將實現固定性能目標所需的累積通信量從8 570 MB 減少到0.81 MB,相當于通信量減少至原來的0.009%。目前,聯邦蒸餾可以大幅減少通信代價,適用于缺少標簽的異質數據、異構模型的場景,但囿于方法要求較為苛刻(如當兩個網絡模型大小相差太大時,知識蒸餾會失效)以及交換輸出還可能增加用戶隱私泄露的風險,聯邦蒸餾的收斂性和應用性研究需要進一步研究。
2.4 低秩與子抽樣
目前主流的壓縮方法是隨機稀疏和量化,子抽樣和低秩等方法研究尚少。其中,子抽樣的方法是本地更新模型由其隨機子矩陣刻畫;低秩是本地更新模型H∈由秩至多是k的矩陣刻畫,其中k小于本地更新模型的秩,與3.1 節的隨機稀疏方法相類似,低秩中每一通信輪次均為每個客戶端獨立生成刻畫矩陣。該方法在文獻[16]中也有所應用。Yang 等[37]基于MAC 的自然信號疊加,針對模型聚合問題,提出了一種稀疏和低秩建模方法。
3 基于客戶端選擇的優化方法
在聯邦學習中,客戶端的數量可能非常大,但由于模型分發和重新上傳的帶寬相當有限,一般只選取一部分參與方參與訓練過程。因此客戶選擇策略對于聯邦學習過程計算效率、通信效率、最終模型的質量以及公平性等至關重要。客戶端選擇算法需要根據數據集是否IID、是否有用戶退出等實際情況選擇最優方案。
3.1 數據IID場景下的FedCS算法
Nishio 等[38]提出了一種 FedCS(Federated Client Selection)算法,根據累計有效參與值(Cumulative Effective Participation,CEP)選擇模型迭代效率最高的客戶端進行聚合更新,以此提高整個聯邦學習算法的收斂效率,進而降低通信代價;但該算法只有在基礎的動態神經網絡等典型網絡性能較好或數據IID 時,精度與通信開銷性能較好,對于拓撲結構或參數較為復雜的情況,該方法客戶端選擇公平性和客戶端聚合效率會更低,反而會造成通信次數增加。
3.2 數據non-IID場景下的Hybrid-FL算法
針對FedCS 算法只能在數據IID 時同時保證高精度和降低通信開銷,但數據non-IID 時降低通信代價卻無法保證高精度的問題,Yoshida 等[39]在啟發式算法(heuristic algorithms)的基礎上提出了一種Hybrid-FL(Hybrid Federated Learning)的協議,該協議可以處理數據non-IID 的客戶端數據,解決在non-IID 數據上FedAvg、FedCS 算法精度、準確度等性能不高的問題,文獻[39]在數據non-IID 場景下仿真邊緣計算環境,在CIFAR-10 和Fashion MNIST 數據集上通過執行分類任務進行性能測試,結果表明non-IID 數據場景下,為了達到較高準確率時,該方法所需通信代價小于FedAvg、FedCS 算法,但Hybrid-FL 協議一定程度上增加了通信損耗:服務器需要通過額外的資源請求選擇部分客戶端,從而在本地建立一種近似獨立同分布的數據集用于聯邦學習的訓練和迭代。因此,下一步可以研究如何綜合運用Hybrid-FL 和FedCS 方法,平衡精度與通信代價之間的關系,在保證高精度的同時使通信開銷足夠低。
3.3 波動訓練環境下E3CS算法
在真實的聯邦學習中,被選中的客戶往往有機會退出,不會返回經過訓練的模型,也不會通知服務器他們的退出,這種情況將會形成一種波動的訓練環境。Huang 等[40]針對更接近現實的波動的訓練環境和數據的non-IID 分布,研究了客戶端選擇問題,在文獻[38]的基礎上,提出了FedCS 的改進方法E3CS(Exp3-based Client Selection),這一研究擴展了Exponential-weight 算法的應用領域。對該算法進行性能評估時,以隨機選擇客戶端和FedCS 為基準組,對EMNIST 和CIFAR-10 數據集未帶標簽的圖片進行分類,實驗結果表明雖然該方法的CEP 低于FedCS,但為了達到相同最終精度,所需通信次數更少。而后,Wu 等[31]在研究波動環境下的客戶選擇問題時,為了提高訓練收斂速度和最終模型精度,也運用了E3CS 隨機選擇算法,并進一步設計了“公平配額”設置,該方法在減少通信時間的同時能夠保證最終模型精度的損失很小。
4 模型劃分等其他方法
此外,還有模型劃分的分割方法等,在2.2 節中Chang 等研究之后,Xia 等[41]也同樣基于MAC 信道考慮聯邦學習,提出了一種聯邦分割算法:邊緣服務器通過空中計算[42]聚合由多個終端設備傳輸的本地模型,該算法采用基于閾值的設備選擇方案實現可靠的本地模型上傳,魯棒性更強,可實現快速收斂、通信回合更少,不過該算法只在目標函數具有強凸和光滑的假設下線性收斂到最優解。Hu 等[43]設計了一種基于分段流言算法(Gossip Algorithm,GA)的分布式聯邦學習,將模型進行劃分,劃分后各部分包含相同數量的彼此不重疊的模型參數,各個參與方通過將本地細分與來自其他參與方的相應細分進行匯總,來執行細分級別更新,該方法可通過以點對點(Point to Point,P2P)方式傳輸劃分的模型來充分利用節點到節點之間的帶寬,通過形成動態同步流言組實現了良好的訓練收斂性。Bouacida 等[44]將自適應聯邦退出(Adaptive Federated Dropout,AFD)和聯邦退出(Federated Dropout,FD)[45]與深度梯度壓縮(Deep Gradient Compression,DGC)[16]相結合,允許客戶端在本地訓練全局模型的特定子集,以減少下載和上傳,進而降低服務器?客戶端通信代價。在SHAKESPEARE 測試集上訓練時,該方案收斂時間僅為文獻[12]中FedAvg 算法的原來的1.8%,另外,由于某些子模型往往比其他子模型更具代表性,AFD 能夠構建最適合每個客戶數據的子模型,與不涉及壓縮的場景相比,精度提高了0.9 個百分點到1.7 個百分點。該實驗結果表明有選擇地刪除模型的部分子集可以在保證全局模型的質量的前提下,顯著減少需要與服務器交換的權值數量,降低通信開銷。
此外,還有一些從策略、框架設計角度出發的解決方案:Li 等[46]引入了一種漸進的模型共享(Gradually Sharing,GS)策略和雙頭設計(Double Head,DH),在TTC(TCP Traffic Classification)上的實驗如表5 所示。當逐步共享頻率設置為80 輪時,該方法可以比標準FedAvg 與HDAFL(Heterogeneity Dynamic Adopted Federated Learning)分別節省60%和56%的通信量。表5 中:IID 指各客戶端的數據集分布是相同的,即每個客戶端都擁有一個與其他客戶端的樣本數量相同的數據集,且單個客戶端無法覆蓋整個標簽;non-IID 指數據集在客戶端上的分布是不同的,但是每個客戶端的數據可以覆蓋整個標簽;dispatch 指不同的客戶端擁有不同類的數據,即分布不同。Tran 等[47]考慮到參與方在自身數據規模、信道增益、計算和通信能力方面的差異性,提出無線網絡下聯合學習問題的解決方法:使用Pareto 效率模型探究學習時間與參與方能耗之間的平衡,通過找尋最優準確率參數來探究計算與通信時間的平衡。

表5 TTC數據集上DH+GS等算法的模型精度比較[46] 單位:%Tab.5 Comparison of model precision of DH+GS and other algorithms on TTC dataset[46] unit:%
5 結語
研究如何降低聯邦學習通信開銷,對聯邦學習的落地應用,尤其是在電源有限的移動設備上的應用,具有很重要的現實意義。本文首先針對聯邦學習的工作流程和發展現狀,重點關注了聯邦學習框架中的通信開銷研究進展。目前,大多數文獻都從壓縮的角度出發解決通信開銷問題,如隨機稀疏化、量化、聯邦蒸餾等,這些方法的思路都是通過減少上行、下行傳遞的數據量來減輕通信開銷,而降低通信頻率則一般是通過增加計算開銷來降低通信開銷,優化通信開銷時最好綜合考量性能,不能一味增加計算開銷換取更低的通信開銷。因此,降低通信頻率的另一種方法是考慮使用并行計算,但是這種方法會引入更多參與方,雖然可以減少通信時間,但是一定程度上會導致更多參與方與中央服務器之間進行通信,從而增加通信成本;此外,同步并行中的“短板效應”也在一定程度上降低了其通信效率,對參與方穩定性有較高要求。值得注意的是,目前一部分自適應的靈活壓縮方案以及基于客戶端選擇和模型劃分等方案,對參與方要求相對要更低,可以針對實時情況動態更新改變通信策略,十分具有創新性,拓寬了研究思路,但是使用這些方法要注意將質量損耗控制在可接受范圍內。
盡管聯邦學習作為一種新興技術,有很多自身優勢,應用場景越來越普遍,如與區塊鏈等新興技術領域,但仍然存在一些值得改進的地方:
1)面向5G 移動設備場景下的研究。目前,隨著高通信速率的5G 技術的發展,越來越多聯邦學習的應用場景擴展部署到了5G 移動邊緣等設備上[11,20,48],這類設備不僅通信帶寬有限,且電源有限,希望系統能耗盡可能小,因此對移動終端的聯邦學習通信代價技術的研究需要進一步深化到綜合考量總能耗的研究。
2)non-IID 數據和異構終端場景下的研究。聯邦學習中參與方的數據通常以非獨立同分布、非對齊、多噪聲等形式存在,同時存在跨模式(如跨視頻與文本數據的聯邦學習)、跨語言等帶來的數據異質問題,然而,目前很多研究方法還是僅在數據IID 等理想狀態下性能較好、行之有效,下一步需要重點研究如何在數據異質、系統異構、波動環境的真實狀態下以及保證準確性和公平性前提下,提升模型性能,降低聯邦學習的通信開銷。
3)通信開銷與計算開銷的綜合優化。在實際中,應用聯邦學習的系統需要通盤考慮整體性能,一味犧牲計算代價或模型精度以獲取低通信開銷是不可取的,目前一些自適應的靈活壓縮方案等為研究提供了思路,下一步需要針對各工作節點的特點,繼續深化綜合考量系統的整體性能、優化通信機制。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
意林原創版(2016年10期)2016-11-25 10:28:30
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
