
基于小樣本無梯度學習的卷積結構預訓練模型性能優化方法
2022-03-01 12:33:48李亞鳴鄧洪武王志勇
計算機應用 2022年2期
李亞鳴,邢 凱*,鄧洪武,王志勇,胡 璇
(1.中國科學技術大學計算機科學與技術學院,合肥 230027;2.中國科學技術大學蘇州高等研究院,江蘇蘇州 215123)
0 引言
隨著深度學習的發展和計算硬件設備的改進,作為深度學習代表性網絡結構之一的卷積神經網絡(Convolutional Neural Network,CNN)在圖像識別和音頻處理方面取得了快速發展并得到了廣泛應用。卷積結構神經網絡具有表征學習能力,能夠以相對較少的參數量快速有效地提取圖片和音頻數據中的特征信息,避免了傳統算法中復雜的特征預處理過程。近年來出現的卷積結構的深度學習預訓練模型如ResNeXt[1]、DenseNet[2]在一些大型圖像數據集上的性能表現已大幅優于傳統的圖像識別模型。
盡管基于卷積結構的深度學習預訓練模型已經在圖像處理領域現有數據集上取得了優異性能,但其在泛化性上仍面臨挑戰。首先,在實際生活中,大型數據集的獲取往往需要消耗大量的人力財力,在許多場景下難以滿足模型對數據規模的需求。其次,卷積神經網絡模型通常是基于反向傳播以及梯度下降進行學習的,隨著網絡層次越來越深,在優化的過程中,容易出現訓練結果收斂于局部最小值而非全局最小值的情況。Zhang 等[3]指出基于梯度下降的方法通常需要高昂的花銷對超參數進行調整才能達到模型性能的提升,并且作為反向傳播的提出者,他認為反向傳播可能并非大腦自然存在的機制[4],并不一定是深度學習未來的方向。另外由于權重共享,卷積結構對局部數據采樣構建局部特征,高層組合局部采樣點構建高維抽象特征,容易出現對局部敏感,而對全局不敏感的情況,并且其普遍采用的池化過程中會丟失部分有價值的信息,導致進一步忽略局部信息與整體信息之間的相關性[5]。上述的這些問題限制了卷積神經網絡性能的進一步提升。
針對上述問題,研究者們提出了多種解決思路對模型進行改進。針對梯度下降算法所存在的問題,Adam[6]、AdaGrad[7]等算法引入二階動量,積累之前狀態的動量替代梯度,實現了自適應學習率,加快了前期收斂,但也存在訓練后期學習率震蕩、模型無法收斂,以及過早停止訓練導致泛化性差等問題。參數初始化[8]和中間層標準化策略[9]等方法對于深度學習模型性能提升相對有限,殘差連接[10]和ReZero[11]等方法則通過增加跳躍式傳遞結構的方式讓低層信號直接傳遞到高層,增強了梯度的反向傳播,加快了模型優化的收斂。Swish 激活函數[12]和Mish 激活函數[13]則通過設計更平滑的激活函數替代ReLU(Rectified Linear Unit)激活函數,在復雜度增加很小的情況下提高了模型的穩定性以及準確性,平均性能更優。但這些方法仍然無法解決梯度下降的根本問題,模型的性能仍然受到限制。
針對模型訓練過程對數據集規模的要求,目前的研究主要是進行數據增強處理,或是利用元學習,或是對模型添加先驗信息的方式,以此來從較少樣本中學習到較好的模型。這些方法都在一定程度上解決了數據量不足導致模型泛化能力差的問題,但仍然對先驗信息提出了一定要求,對于小樣本數據仍然面臨較大挑戰。
針對卷積結構以及池化層的缺陷,文獻[14]提出基于本地重要性的池化(Local Importance-based Pooling,LIP)方法,采用注意力機制來自適應地保留下采樣中的重要信息,貢獻較小的信息則被過濾掉。文獻[15]提出一種基于感興趣區域的池化(Region of Interest pooling,RoI pooling)方法,選擇對不同大小的區域進行池化,能夠在一定程度上增加核心區域信息的關聯程度,更好地提取有效信息。這些方法能夠一定程度提升模型性能,但沒有解決池化層存在的問題,仍會丟失部分有價值的信息。
另外,卷積神經網絡中卷積層在提取信息的過程中往往存在特征提取冗余的問題,網絡權重的相關性過高,導致模型泛化性下降[16]。當數據集質量較差時,卷積層的輸出結果中將包含部分與樣本核心語義無關的噪聲信息,這些噪聲信息將不僅會影響模型提取特征信息的質量,導致模型性能變差,還會消耗過多的算力。因此,如何準確評估采樣點提取特征的有效性,篩選出沒有貢獻的噪聲信息,也成為提高卷積神經網絡模型性能的關鍵。
在本工作中,提出一種基于資本資產定價模型(Capital Asset Pricing Model,CAPM)[17]以及小樣本數據來定向生成網絡有效結構的方法,基于最優傳輸理論以及時不變穩定性對模型中間輸出結果進行去噪,并以自監督的方式進行無需梯度下降和反向傳播的表征學習,避免了梯度下降算法帶來的缺陷,能夠生成各個類別有效信息的類別感知表征向量,減少了傳統方法中池化層帶來的信息損失,并基于自注意力機制生成最終的表征嵌入向量。
本文的主要工作如下:
1)針對卷積結構預訓練模型,基于資本資產定價模型來定向組合生成網絡有效結構,基于時不變穩定性和自監督的方式,無需梯度下降和反向傳播來進行表征學習,避免了對梯度的依賴;
2)基于小樣本數據,利用數據增強技術生成調制序列數據,通過協整檢驗分析因果關系并據此定向修剪網絡結構;
3)理論和實驗分析表明,本文方法可應用于多類卷積結構預訓練模型,對數據集規模的要求有數量級下降,同時模型性能和泛化性有明顯提高。
1 相關工作
1.1 基于卷積結構深度學習模型的圖像識別方法
早期的卷積神經網絡發展并不順利,文獻[18]提出的LeNet-5 采用反向傳播算法對模型進行優化,具備卷積層、池化層和全連接層三種基本模塊,在數字識別任務上取得了一定效果,但在一般實際任務中的表現不如支持向量機(Support Vector Machine,SVM)、Boosting 等算法。直到AlexNet[19]的提出證明了卷積神經網絡在大規模圖像數據集上的可行性,使用ReLU 激活函數,證明其效果在深層結構中超過Sigmoid 激活函數,并首次將Dropout[20]以及LRN(Local Response Normalization)等技術應用到卷積神經網絡中,增強了模型的泛化性。同時AlexNet 采用GPU(Graphics Processing Unit)進行運算加速。后續提出的VGGNet[21]對卷積核以及最大池化層作了改進,構建了更深的網絡結構,證明了增加隱藏層深度以及小卷積核能夠有效提高卷積神經網絡的性能,但隨著網絡深度的增加,模型性能會出現先升后降的網絡退化現象。在MobileNet V2[22]中提到激活函數ReLU 使得模型在輸入輸出過程中,由于信息不可逆,導致部分信息損失,模型中大量隱藏神經元對不同輸入輸出相同值,導致權重矩陣的秩較小,深層網絡中矩陣連乘使得模型出現梯度消失問題。ResNet[10]提出殘差連接結構,將模型深度提高到152 層,性能得到大幅提升,獲得ILSVRC(ImageNet Large Scale Visual Recognition Challenge)2015 比賽分類任務的冠軍。
ImageNet 2012 數據上訓練得到的預訓練模型在其驗證集上取得了很好的效果,但仍然有性能優化空間。傳統卷積神經網絡方法一般只采用圖片頂層特征做預測,因為頂層的特征語義信息較為豐富。頂層特征中目標位置比較粗略,而底層的特征語義信息較少,但是目標位置比較準確,所以有些算法采用多尺度特征融合的方式,利用融合后的特征做預測。在特征金字塔(Feature Pyramid Network,FPN)[23]中預測是在不同特征層獨立進行的,將高層與底層的特征信息進行融合,得到了信息更豐富的融合特征并進行預測,模型性能得到提升。PyNET[24]中則采用了金字塔的思想,結合全局信息以及底層信息,低尺度得到的信息被上采樣,然后和高層次的特征連接到一起,然后繼續處理,結合了局部與全局的信息。這些方法都增加了新的采樣方式,能夠從樣本中提取更多的有效信息。
1.2 資本資產定價模型
在網絡模型中,不同神經元能夠提取不同含義的信息,本文引入CAPM,將有價值的特征語義信息作為資產,然后對信息進行取舍組合,實現收益最大化。CAPM 是一種基于風險資產期望收益均衡基礎上的預測模型,其核心思想是理性的投資者將選擇并持有有效的投資組合,即那些在給定期望回報率的水平上使風險最小化的投資組合[25]。
如圖1 所示,不同股票組合構成了組合可行區域,有著不同的收益以及標準差,資本市場線與組合可行區域上沿相切,切點P為理論上的最佳市場組合,達到風險與收益的平衡,相較于同樣風險的M組合,P組合具有更高的收益率。構建有風險的投資組合時,一般的策略是投資回報達到無風險投資的回報,或者更多。

圖1 資本資產定價模型Fig.1 Capital Asset Pricing Model
1.3 模型的不變性與Wasserstein度量
1.3.1 模型的不變性
圖像識別任務中模型的不變性指的是樣本經過各種幾何變換,其核心語義信息不發生變化,模型仍然能將其夠映射到原始樣本對應的類別。對經過變換的樣本圖片具有一致的表達,是使得模型具備泛化性的重要保證。常見的有平移不變性、尺度不變性、旋轉不變性等,一般通過不同的數據增強規則或者特定的網絡結構使得模型具備對應的能力。卷積神經網絡中的卷積層以及池化層一定程度上為模型提供了平移不變性,目標出現在樣本的任何區域,卷積層都能夠提取特征信息,輸出同樣的響應,而最大池化層中,即使最大值在感受野內出現了移動,仍然能夠返回最大值。而在SPP-Net[26]中,引入SPP(Spatial Pyramid Pooling)層,通過SPP層來解除了卷積神經網絡對于固定尺寸圖片輸入的限制,并采用多尺度訓練方法,使用不同尺寸的樣本圖片進行訓練,為不同尺寸的圖片增強了模型的尺度不變性。對于旋轉不變性等,卷積神經網絡并沒有加入對應的先驗特性,需要大量的增強數據進行訓練。
1.3.2 最優傳輸理論及Wasserstein度量
最優傳輸研究的是兩個分部之間變換的問題,最早是對土堆搬運問題的研究,后來被抽象為給定兩個度量空間D、G以及對應的分布α、ν,尋找最優傳輸變換G=T(D),將服從分布α的隨機變量轉換為服從分布ν,并最小化消耗函數[27]。最優傳輸問題為非凸優化問題,其解的存在性難以保證,后被松弛為線性問題,使得最優傳輸理論得到快速發展[28-29]。
Wasserstein 距離(簡稱W 距離)是一種在兩個概率測度空間中近似尋找最優傳輸距離的方法。相較于JS(Jenson’s Shannon)散度,W 距離在兩個概率分布的支撐集沒有重疊或重疊較少的情況下,仍然能夠反映出兩個分布的遠近,并且它值域不限制在0 到1,不存在上下限,能夠很好地定義為資產定價模型中的收益。兩個分布之間的W 距離定義如下:

其中:Π(P1,P2)表示所有以P1和P2為邊緣分布構成的聯合分布γ(d,g)的集合;γ(d,g)表示將分布P1轉換為P2需要從d傳輸到g的傳輸量,可以看作最優傳輸中的消耗量[30]。
2 基于調制序列的卷積網絡結構定向修剪
2.1 基于小樣本的調制序列數據生成
從大規模數據中找到有意義的關系能夠有效提高神經網絡的性能,目前主流的研究都是將神經網絡看作黑盒,利用海量數據窮舉獲得相關性關系,而因果關系能夠更好地解釋神經網絡的機制[31]。在因果推理中,因和果具有先后順序性,因此通過觀察時序數據能夠更好地發現因果關系,但小樣本數據屬于非時序數據,因此本文基于干預調制的方法,利用現有的數據增強技術對小樣本數據進行擴充,生成序列數據。文獻[32]指出當對樣本進行干預處理時,同時也限制了樣本隨其他因子變化的自然趨勢,改變了原始數據的分布,不同的干預方式將導致完全不同的相關性關系,可以觀察模型對于經過指定干預方式生成的樣本所作出的響應。
因此本研究首先制定數據增強規則f對樣本數據進行擴充:

其中:x為單個樣本;y為經過變換后的增強樣本;t為從調制曲線上采樣得到的連續性變換參數,用于生成具有時間連續性的圖片變換參數序列,以高斯模糊、移動觀測窗口等變換方式對數據集中所有的樣本都進行變換處理,參數則分別對應于高斯方差大小以及窗口坐標;ε為隨機擾動項,能夠避免采樣的重復性,增強數據分布的魯棒性、多樣性。
考慮K個類別的數據集,每個類別中包含n個樣本,基于具有時間連續性的參數以對同一類別中的每一個樣本進行同樣的m次連續性的數據增強,生成了大小為n×m的增強樣本矩陣。即每個類別的原始樣本都生成m組長度為n的時間樣本序列,每一組都包含由n個原始樣本基于同一參數進行變換處理得到的n個增強樣本。同時也構成了n組長度為m的空間樣本序列,每一組都包含由其中一個樣本基于不同參數進行變換處理得到的m個增強樣本,如圖2 所示。基于調制曲線生成具有時間連續性的噪聲能夠對原模型造成更明顯的擾動,對特征不變性的研究更有利。

圖2 樣本數據增強Fig.2 Sample data augmentation
2.2 基于協整檢驗的卷積網絡結構定向修剪
文獻[33]指出一個經過初始化的神經網絡模型,當數據變化時,其損失函數相較于輸入數據的雅可比矩陣通過平展處理可看作一個向量,在不同類別的數據之間,性能越好的結構,對應的雅可比矩陣也將越不具有相關性,因此可以不需要對模型進行訓練就能快速評估網絡結構的好壞。類似地,對于采樣點而言,其數據分布越平穩,與其他分布的重疊越少,則其采樣質量將越高。如2.1 節所闡述的,基于調制曲線生成的增強樣本對原始數據集進行了擴充,形成了時間樣本序列。對時間序列而言,如果均值沒有系統的變化(無趨勢),方差也沒有系統變化,且嚴格消除了周期性變化,就稱之是平穩的[34]。因此首先考慮從時間序列平穩角度基于增強的樣本數據對每個采樣點穩定提取特征的能力進行評估,繼而對預訓練模型網絡結構進行修剪。
為了評估不同采樣點穩定提取特征的能力,本文采用W距離對不同數據分布進行度量。對于同一采樣點,從時間角度看,其輸出構成一個時間序列,序列中的每一組數據都可以看作一個數據分布,因此可以計算相鄰時刻兩個數據分布之間的W 距離。由于相鄰時刻的兩種變換具有連續性,沒有發生突變,那么相鄰的兩個分布之間的距離將趨于較小,具有時間一階穩定性。增強的樣本時間序列具有連續性,穩定提取特征的采樣點輸出值在時間一階角度下計算得到的W 距離值序列也將趨于穩定,而部分采樣點提取的噪聲信息將不具有穩定性。
為了評估節點響應調制變化的能力,本文采用協整檢驗對序列數據在各節點的輸出以及由調制曲線采樣得到的參數序列數據進行檢驗。協整是考察兩個或者多個變量之間的長期平穩關系,能夠在具有單獨隨機性趨勢的幾個變量之間找到穩定的關系[35]。經過時間一階平穩性驗證后,通過協整檢驗可以發現模型中能夠對調制序列作出響應的部分采樣點。對于二元時間序列X、Y,如果存在非零線性組合β=(β1,β2),使得Z=β1X+β2Y弱平穩,則認為兩個分量X和Y存在協整關系[36]。
對數據集中的每一個類別的增強樣本數據單獨進行考慮,保留能夠穩定提取該類別特征信息的部分采樣點,去除提取與該類別無關信息的部分采樣點。考慮每個采樣點對應的W 距離值序列的標準差序列,將標準差大于指定閾值的部分采樣點看作無法穩定提取該類別圖片的核心語義信息。根據一般神經網絡剪枝的規則[37],將這部分采樣點的輸出值置為0。保留W 距離序列標準差低于一定閾值的dimdenoise個采樣點。最后,通過協整檢驗篩選掉不具備協整關系的部分節點,完成對預訓練模型的修剪。文獻[38]指出網絡修剪本質上其實是最優網絡結構的搜索過程,即以監督的方式,為每一類數據都構建了一個新的網絡結構,能夠保留模型提取的潛在有效信息。
3 基于資本資產定價模型的表征向量生成
傳統的卷積結構以及池化結構都只考慮鄰近像素或采樣點之間的相關性,而忽略了與其他采樣點之間的協作關系,從而導致大量有效信息的損失。并且在小樣本數據的情況下,模型發現的相關性關系往往缺少泛化性[31]。相較于直接構建多分類模型,本文方法引入資本資產定價模型為數據集中的每一個類別構建單分類模型,基于最優傳輸理論,計算W 距離衡量采樣點間的相關性,通過無需梯度傳播的正向學習特征圖中采樣點之間的組合關系,生成能夠使單類樣本與其他類具有明顯區分性的類別感知表征向量。
卷積結構中每個采樣點所提取的特征偏重于不同的信息,如輪廓、紋理等[39-40]。將不同的采樣點看作資本資產定價模型中的不同股票,采樣點之間的組合看作資本市場,沿用CAPM 中的定義,將收益序列的標準差看作CAPM 中的市場風險。在已知收益序列的情況下,可以直接計算出組合內采樣點的最佳權重,證明如下:
假設有N個風險資產,它們的收益率用隨機變量r表示:

資產投資組合中它們的份額記為Q:

設eN×1=[1 1…1]T,則有eTQ=1,即所有投資份額的總和為1。則期望收益向量為:
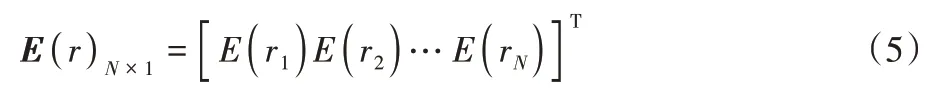
協方差為:
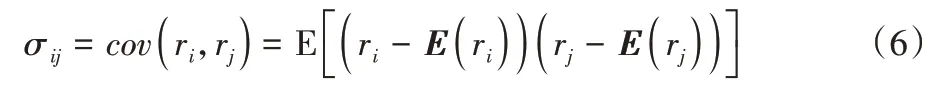
同時記協方差矩陣為V,對于某一投資組合p而言:

期望收益和收益方差分別為:

此時的優化目標為在給定收益期望μp的情況下,最小化風險即:

在此,假設V是正定矩陣,此時V的逆存在。構造拉格朗日輔助函數:

使目標函數取得極值:
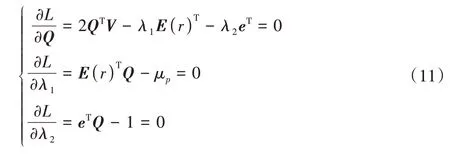
得:
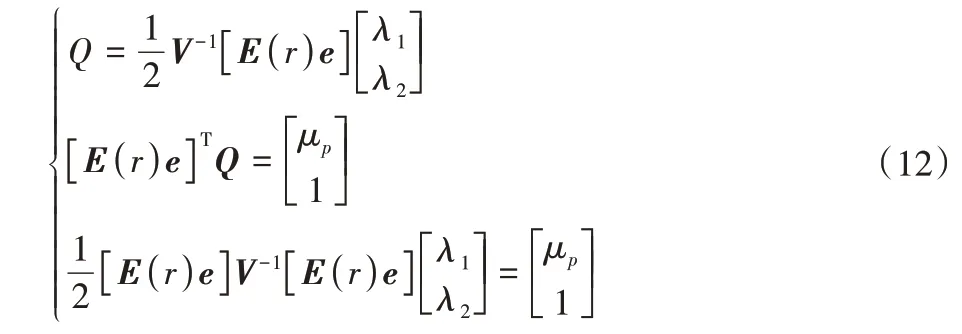
記[E(r)e]V-1[E(r)e]為A,則:

將式(13)代回式(12)得到權重向量最優解:

因此當收益和風險的定義方式確定后,可以計算其特征合成的權重最優解Q*,然后對組合內采樣點值進行加權求和作為新采樣點是輸出結果,這一結構也可以看作是一種選擇性連接[41]。
根據最優傳輸理論,可以通過計算不同采樣點對應的數據分布之間傳輸的最小代價對不同采樣點之間的協作關系進行評估,而W 距離能夠近似兩個分布之間的最優傳輸代價,因此本文首先基于W 距離計算采樣點的相關系數矩陣來衡量采樣點之間的相關程度,高相關系數代表采樣點間存在增益關系,低相關系數代表采樣點間存在互補關系,然后將增益互補的采樣點組合在一起將能夠將不同意義的信息結合在一起,對單個采樣點提取的特征信息進行增益以及補充,提高采樣點提取特征信息的能力。
首先對數據集中的不同類別的增強樣本數據分別從空間角度進行考慮。對于卷積結構輸出的特征圖中的每一個采樣點,從空間角度看,形成了一個空間樣本序列,序列中的每一組數據可都看作一個數據分布。以其中一組為標準分布P0,將空間序列中每一組數據形成的分布Pi與之計算W距離,計算公式如下:

其中:Wij代表第i(1≤i≤dimdenoise)個采樣點對應的空間序列中第j(1≤j≤n)組分布與標準分布之間的W 距離。由于每一組數據都是由同一類別樣本中的一個樣本經過變換得到的增強數據,所以可看作是該類別圖片的類內距離Win,得到類內W 距離矩陣。基于類內W 距離矩陣計算得到相關系數矩陣C,用于衡量采樣點間的協作關系。
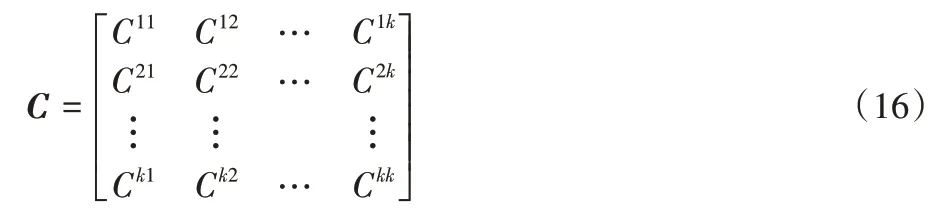
其中:Cij表示第i個采樣點與第j個采樣點W 距離序列之間的相關系數。類似地,再從數據集中隨機選擇其他類增強圖片空間序列作為類外圖片,保證類外多樣性,將序列中每一組數據形成的分布與同類內圖片的標準分布計算W 距離,作為該類別圖片的類外距離Wout,得到多組距離后取均值與類內距離序列保持統一維度,因此可定義采樣點的收益函數R:

通過計算可得到收益矩陣,為了添加類內的多樣性,本文從空間序列數據中重新選擇不同的數據分布作為標準分布,并對分布取平均,重新計算得到包含類內多樣性的收益矩陣,并且數據分布也將更加穩定。
由于所有采樣點的感受野都已經覆蓋了整個樣本圖片,相較于根據相關系數從所有采樣點中選擇采樣點進行組合,本文方法選擇所有采樣點中收益最大的一部分采樣點作為備選采樣點,再依據相關系數矩陣從中選擇采樣點進行組合,以最大化特征信息質量。以特征圖中的每個采樣點作為中心采樣點,從備選采樣點中選擇采樣點進行組合,即資本市場,再根據組合內采樣點的收益序列矩陣計算夏普比率得到各個采樣點的最佳的權重,加權求和之后生成單分類特征向量,其收益提升,并且分布更加穩定,得到了更高質量的特征表示。
本文方法的整體框架如圖3 所示,針對圖片多分類(K類數據)任務,首先獲取增強樣本圖片序列經過預訓練模型卷積層輸出得到的原始特征向量,基于分布穩定性檢驗以及協整檢驗生成K種噪聲定向修剪方式,原始特征特征向量分別經過K種噪聲修剪方式得到K個經過修剪的向量。然后基于資本資產定價模型生成K種節點組合方式CAPMi(1≤i≤K),對修剪后向量中的節點進行重新組合生成類別感知表征向量。即從數據分布的角度為數據集中的每一個類別都構建了全新的結構,通過無需梯度的正向學習更好地提取指定類別相關的信息,解決了傳統卷積結構以及池化帶來的信息損失的問題,同時也避免了基于梯度下降進行優化帶來的問題。

圖3 本文方法的整體框架Fig.3 Overall framework of the proposed method
4 基于自注意力機制的多分類模型
經過資本資產定價模型組合后生成的表征向量完成了特征穩定提取的過程,這些表征向量分別包含不同類別信息,并且它們之間具備穩定的偏序關系;但這一結果無法作為特征向量用于特征分類,構建多分類模型還需要將這些特性信息融合在一起生成統一的特征向量。如果將這些表征向量簡單地連接起來,類別之間的互信息將會丟失,難以得到最優的結果,因此需要制定方法學習表征向量之間的互信息并進行融合。
文獻[42]中在人臉識別任務上提出了一種基于自注意力機制生成權重的方法。自注意力機制是一種注意力機制改進方法,不借助外部信息,而更專注于數據內部之間的關聯性[43]。人臉樣本經過不同的組網絡生成包含胡子、膚色等不同屬性的組感知向量后,基于卷積層輸出的特征圖,生成多個組感知表征向量的權重,再將所有的組感知表征向量加權生成最終的特征向量,其模型性能優于傳統的人臉識別模型。
因此可以考慮根據樣本圖片歸屬于某一類別的概率對這些信息進行融合,概率最大的類別感知表征向量貢獻也將越大。類似地,本文方法引入自注意力機制實現表征向量之間互信息的融合。由資本資產定價模型所生成的多個表征向量可看作一個整體,通過計算自注意力能夠挖掘不同表征向量之間的互信息,并且可以得到單類別表征向量與整體語義空間的關系,從而指導權重向量的生成,完成對多個表征向量的融合,為最終生成統一的特征向量提供有效的信息。
基于自注意力機制,本文方法采用scaled dot-production attention[43]進行相似度計算得到的注意力,自適應地生成類別感知表征向量的權重,其結構如圖4 所示。針對K個類別的數據,以監督的方式生成K維的向量,使用Softmax 方法對其進行歸一化處理,將其作為K個類別感知表征向量的權重向量,與類別感知表征向量做加權求和處理,完成對信息的融合,增強了數據之間關聯性。由資本資產定價模型(CAPM)組合生成的表征向量偏重于樣本與各個類別的關聯信息,但也存在部分信息的損失,因此,將其與去噪后的特征圖相加,兩者形成一種信息的互補,最大化有效信息,生成最終特征向量,結構如圖4 所示。通過全連接層對特征向量進行聚合,可以生成具有弱相關性的embedding 向量。

圖4 自注意力機制結構Fig.4 Structure of self-attention mechanism
5 實驗與結果分析
5.1 實驗設置
5.1.1 數據集
對于訓練,本研究采用ImageNet 2012 數據集[44]中的訓練集,其中包含1 000 類圖片,每類1 300 張圖片,從中隨機選擇K=10 和K=100 類圖片,每類隨機選擇25 張圖片構建小樣本量級訓練集。對于測試,采用ImageNet 2012 數據集中的驗證集,其中包含1 000 類圖片,每類包含50 張圖片。另外本研究在CIFAR-100 數據集[45]重新進行了同樣的實驗,其中包含100 類圖片,每類各有500 個訓練圖片和100 個測試圖片,并且每個圖片都帶有類別標簽以及超類標簽,可用于評估概念層次間的偏序關系。訓練過程中,每類隨機選擇了25 張訓練集圖片構建小樣本量級訓練集,其他數據構成測試集,并在該測試集上進行測試。
5.1.2 度量指標
在本文方法中,統一采用W 距離對數據分布之間的距離進行評估。在網絡修剪實驗中,考慮到樣本不平衡的情況,采用召回率在ImageNet 2012 驗證集上進行評估。在最終模型性能評估實驗中,采用Top1-Acc 和Top5-Acc 分別在ImageNet 2012 驗證集和CIFAR-100 測試集上進行評估。
5.1.3 實驗設置
實驗是基于Pytorch 深度學習框架下完成的,硬件配置如下:處理器為Intel Xeon gold 6320,內存為32 GB,GPU 為NVIDIA GeForce RTX 2070。對于輸入的圖片,分辨率大小統一調整為224×224×3,并使用均值向量(0.485,0.456,0.406)以及標準差向量(0.229,0.224,0.225)對圖片進行標準化處理。
5.2 網絡剪枝性能評估
在數據增強過程中,本文方法采用了高斯模糊、尺度變化、滑動窗口等方式對樣本作了連續性增強,生成了序列數據。考慮K類增強的數據樣本,每個類別都計算得到一個長度為dimorigin的標準差向量Si(0≤i≤K)。需要定義噪聲篩選的閾值,篩選出大于此閾值的采樣點編號集合,對應于特征圖中的采樣點編號,將對應的值將置為0,即構建得到K種網絡結構修剪方法。從圖5 可以觀察到,部分噪聲采樣點的標準差異常大,可看作無法對同類別圖片穩定提取信息。為了避免標準差向量中極值的影響,本文選擇標準差向量中小于中間值的部分數據定位為Smid,閾值τ表達式定義為:
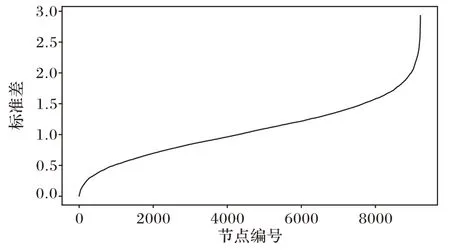
圖5 隨機類別對應的排序后的標準差分布Fig.5 Sorted standard deviation distribution corresponding to random class
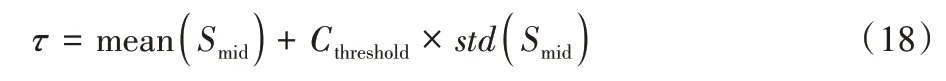
其中:Cthreshold為常數,在實驗中根據統計學相關經驗以及多次實驗將其取值為5 能夠篩選掉20%左右的噪聲采樣點。隨后通過協整檢驗保留置信度大于95%的部分采樣點完成對網絡模型的修剪。
為驗證經過修剪后的網絡結構性能,構建K個與AlexNet 預訓練模型中的全連接層同樣結構的二分類器進行驗證,對于K類中的每一個類別,選擇該類的20 張圖片作為正類,另外從ImageNet 2012 數據集中隨機選擇20 類,每個類別選擇20 張圖片,共400 張圖片作為負類,獲取經過按照本類修剪方式修剪后的特征圖,輸入到模型中完成訓練,獲取測試集樣本輸出的指示向量,以召回率為指標評估K個二分類模型性能。觀察圖6 可以看到當K=10 時,預訓練模型經過修剪后,其中8 個類別的召回率得到了提升,說明通過檢驗時間一階數據分布的穩定性確實能夠剔除與類別核心語義信息無關的噪聲,提高模型穩定提取特征信息的性能。

圖6 模型經過修剪后,單類別召回率普遍提升Fig.6 Most single class recall rates increasing after model pruning
另外,本文方法探究了不同類別對應的修剪后網絡模型有效結構的相似程度。選擇蛇、蝴蝶、貓、獵豹、狗、魚、鳥、蜘蛛幾個綱目作為實現對象,從ImageNet 2012 訓練集中屬于這些綱目的部分類別中隨機選擇小樣本量級的樣本作為實驗數據。按照第3 章所闡述的方法,針對這些類別對模型進行修剪分別生成各自對應的有效結構,計算每個類別保留的采樣點編號,模型相似比例為修剪后模型保留采樣點的編號的交集大小,以物種貓為中心的結果如圖7 所示,其中sna、but、cat、le、dog、fish、bird、spi 分別代表蛇、蝴蝶、貓、獵豹、狗、魚、鳥、蜘蛛。觀察貓與其他物種的單分類模型相似比例,可以看到貓與同物種的其他貓類相似比例最高,除此外,與狗和獵豹兩個物種的相似比例較高,這也符合人類對于物種的視覺認知,這一結果表明模型中不同類別之間存在穩定偏序關系的可能性,CNN 模型本身具備提取概念層次特征信息的能力,也說明本文方法能夠使模型在最優路徑上進行傳輸。

圖7 不同物種對應的單分類模型有效結構相似比例Fig.7 Similar ratios of effective structures of single classification models for different species
5.3 模型性能評估
經過修剪后的特征圖中采樣點已經能夠穩定提取信息,而這些采樣點之間的相關性仍然比較大,為了節約計算成本,考慮最大化收益以及信息的多樣性,對于每個采樣點,根據相關系數矩陣另外選擇相關系數最大的5 個采樣點以及相關系數最小的5 個采樣點,一共11 個采樣點作為CAPM 中的資本市場。每個采樣點可計算得到收益序列以及標準差,可計算最優市場組合,即11 個采樣點的最佳權重,加權求和之后作為新生成的表征向量中的一個采樣點。得到新的表征向量后,采用第4 章中闡述的方式計算每一個采樣點的收益,觀察經過選擇性組合前后采樣點的收益變化來評估類別感知表征向量的性能。
隨機選擇類別觀察部分節點經過CAPM 組合優化前后的收益變化,結果如圖8 所示,可以觀察到通過本文方法所構建的新結構對節點進行重新組合后,新生成的表征向量中采樣點整體的收益都得到了提高,即單類別的區分性得到了顯著提高。另外,實驗中隨機選擇了部分采樣點觀察它們經過資本資產定價模型組合前后在分布上的變化,圖9 為3 個節點組合前后的W 距離分布情況,即類內距離Win和類間距離Wout。可以觀察到經過組合后,Win分布更加平穩,并且能夠與Wout分布明顯區分開來,這一結果表明本文方法能夠顯著提高不同類別樣本之間的區分性。

圖8 隨機選擇類別,資本資產定價模型組合優化前后所有采樣的收益R分布Fig.8 After randomly selecting a class,distribution of income R of all samples before and after combinational optimization of capital asset pricing model
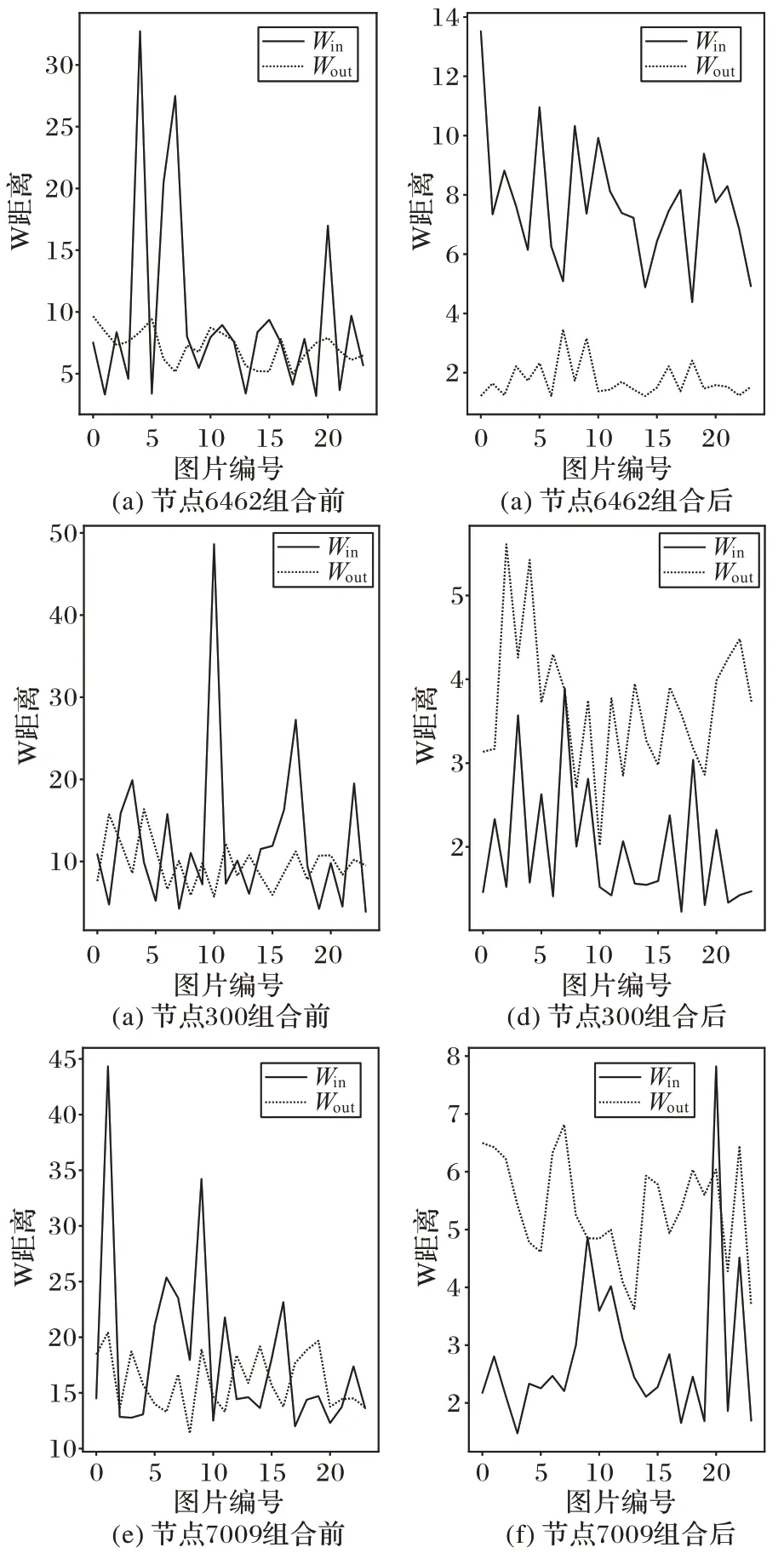
圖9 資本資產定價模型組合優化前后單采樣點的可區分性Fig.9 Distinguishability of single node before and after combinational optimization of capital asset pricing model
為了評估本文方法生成的最終特征向量性能,構建一個包含3 層全連接層的多分類模型并計算準確率Acc 作為評價指標。首先評估原始網絡結構的性能,獲取訓練集樣本輸入預訓練模型的原始特征向量進行訓練,將測試集樣本輸入多分類模型得到輸出指示向量,計算準確率作為預訓練模型的基準性能。然后將訓練集樣本對應的原始特征向量輸入到本文方法所構建的網絡結構中,得到新的特征向量,輸入到同樣結構的全連接層完成模型訓練,獲取測試集樣本對應的指示向量,仍計算準確率作為提出的方法性能。
分別在ImageNet 2012 數據集上隨機選擇100 類以及CIFAR-100 數據集上進行評估,結果如表1 所示,模型經過改進后,在ImageNet 2012 數據集100 類圖片上Top-1 Acc 從58.82%提高到了68.50%,Top-5 Acc 從83.51%提高到了92.25%。在CIFAR-100 數據集上Top-1 Acc 從61.29%提高到了69.15%,Top-5 Acc 從81.43%提高到了89.55%。這一結果表明本文方法能夠基于小樣本量級的訓練數據顯著提升CNN 預訓練模型的性能。
為驗證本文算法能夠直接應用到其他卷積神經網絡模型中,使用同樣的方法分別對ResNet 預訓練模型進行修改對性能進行評估,結果顯示在表1 中,Top-1 Acc 和Top-5 Acc分別由78.51%和94.20%提高了85.72%和96.65%,說明本文方法能夠直接應用到主流的卷積神經網絡預訓練模型中,不需要做復雜定制化處理。

表1 圖片分類任務性能比較 單位:%Tab.1 Performance comparison of image classification tasks unit:%
6 結語
本文提出了一種基于資本資產定價模型以及小樣本的無需梯度傳播的正向學習的方法,為小樣本生成序列化增強樣本數據,并通過協整檢驗分析因果關系對預訓練模型的結構進行修剪并選擇性構建一種新的結構,能夠更好地提取特征信息,并通過無需梯度傳播的正向學習生成了質量更高的特征向量,解決了傳統神經網絡優化過程對梯度的依賴;并且進行了一系列實驗對網絡結構以及特征向量質量進行了評估,表明本文方法能夠明顯提高預訓練模型的性能和泛化能力,并且能夠直接應用到主流的卷積神經網絡模型中,無需做定制化處理。未來計劃尋找更多的有效策略對模型中的采樣信息進行整合和提煉,利用協整分析和CAPM 等干預方式來降低模型的復雜度并進一步提高模型性能。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
