WSN中能耗均衡的非均勻分簇路由算法
2022-03-01 13:12:44苗俊先趙一帆楊俊東丁洪偉
計算機工程與設計 2022年2期
苗俊先,趙一帆,李 波,楊俊東,丁洪偉+
(1.云南大學 信息學院,云南 昆明 650500;2.云南民族大學 電氣信息工程學院,云南 昆明 650500)
0 引 言
無線傳感器網絡(wireless sensor network,WSN)是由許多微型傳感器節點通過自組網形成[1],主要用于環境參數的監測[2,3]。近些年,其廣泛應用在農業、醫療、工業生產等領域[4,5]。節點能量的利用率取決于路由協議,因此,研究高效的路由協議已成為傳感網面臨的重大挑戰[6]。
LEACH協議簇首選擇、簇群規模和分布隨機性強[7],LEACH-C協議簇首選擇忽略位置因素,導致簇內通信能耗不均衡。文獻[8]中以網格劃分方式分簇,但是單簇首負載過大。石美紅等[9]優化分簇方法和引入雙簇首提升網絡能耗均衡,但簇間以最小能耗選擇中繼節點,加快中繼節點的死亡。文獻[10]提出非均勻分簇的雙簇首協議,緩解單簇首的通信壓力,副簇首選擇未考慮與主簇首的距離。黃利曉等在文獻[11]中提出能耗均衡的LEACH改進協議,用間距、剩余能量和密度因子競選簇首。文獻[12]中EBRAA算法通過層次聚類提高分簇的均勻性。文獻[10-12]3種算法簇首競選時加權值固定不變,各因子的權值缺乏動態調整并且未考慮簇群規模對簇間能耗均衡的影響。
綜上所述的路由協議未綜合考慮簇首工作量、成簇規模、簇內和簇間通信傳輸等對能耗均衡的影響,且簇內節點能耗均衡性缺乏衡量標準,為此提出一種能耗均衡的非均勻分簇路由算法(a non-uniform clustering routing algorithm for balanced energy consumption,ANRB)。通過改進的K均值算法和成簇半徑調整簇群規模實現非均勻分簇,并以雙簇首減緩簇首通信壓力;利用基尼系數對簇內節點能耗均衡性評估,選擇更利于能耗均衡的節點為主簇首,使用動態權值調整副簇首競選中各因子的影響;增加轉發次數和節點數等因子優化中繼節點選擇,均衡簇間能量消耗。
1 系統模型
1.1 網絡模型
WSN中各傳感器節點以隨機的方式拋撒在監測區域內,且位置不隨時間發生變化,每個節點具有唯一的ID號和位置信息相對應[13];傳感器節點可以感知自己的位置及剩余能量等信息,可以進行簡單的信息處理,能夠根據傳輸距離自動調整發射功率;Sink節點能量無限且處理數據能力強大;所有節點的初始能量、計算能力、數據傳輸能力等性能完全相同,當能量消耗殆盡時節點將自動退出網絡系統。
1.2 能耗模型
在能耗計算方面提出的算法與LEACH協議都采用一階無線電能耗模型[14],數據傳輸和融合能量消耗較大,其中數據傳輸又分為接收和發送兩部分,假設相距為d的兩節點間有lbit的數據需要傳輸,數據傳輸能耗計算公式為
(1)
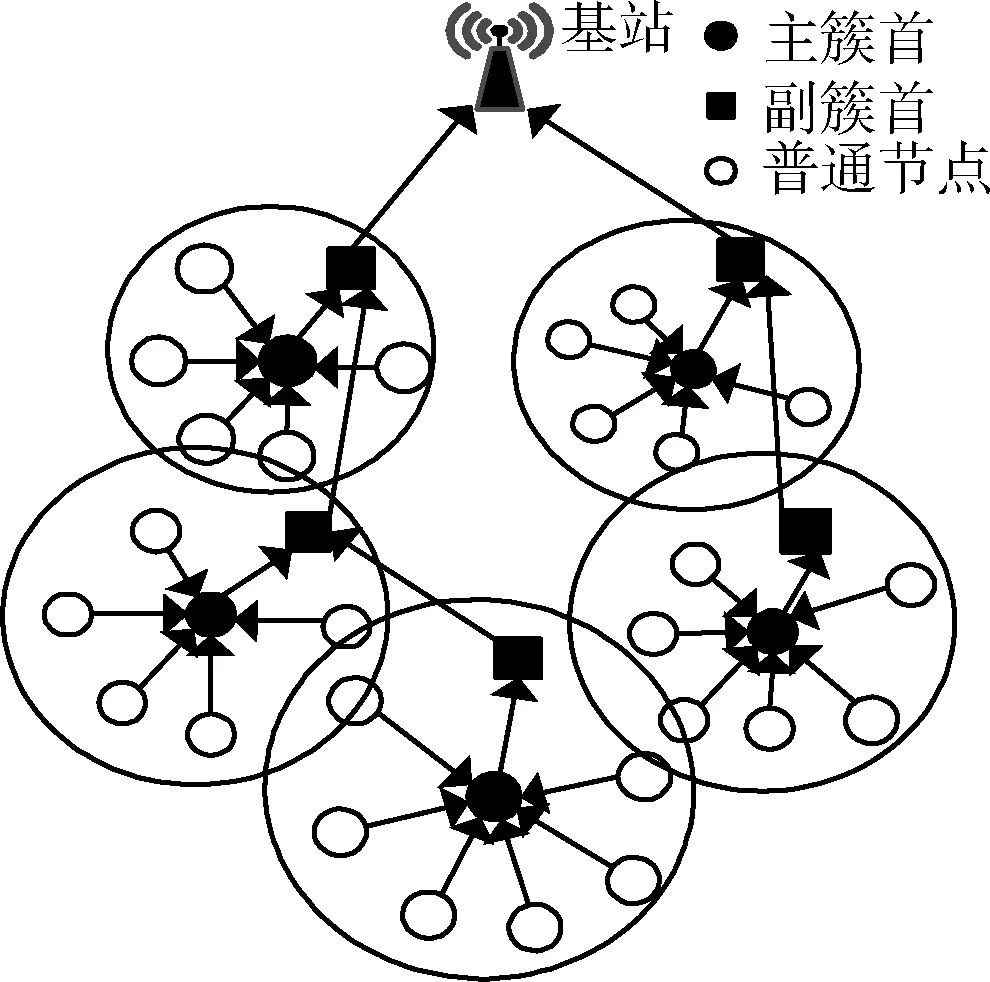
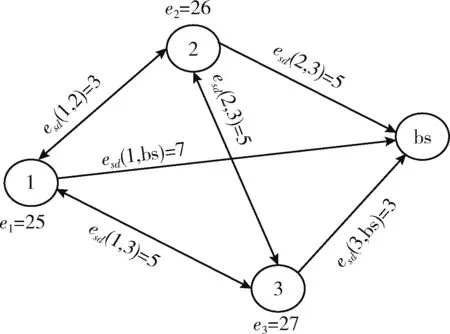
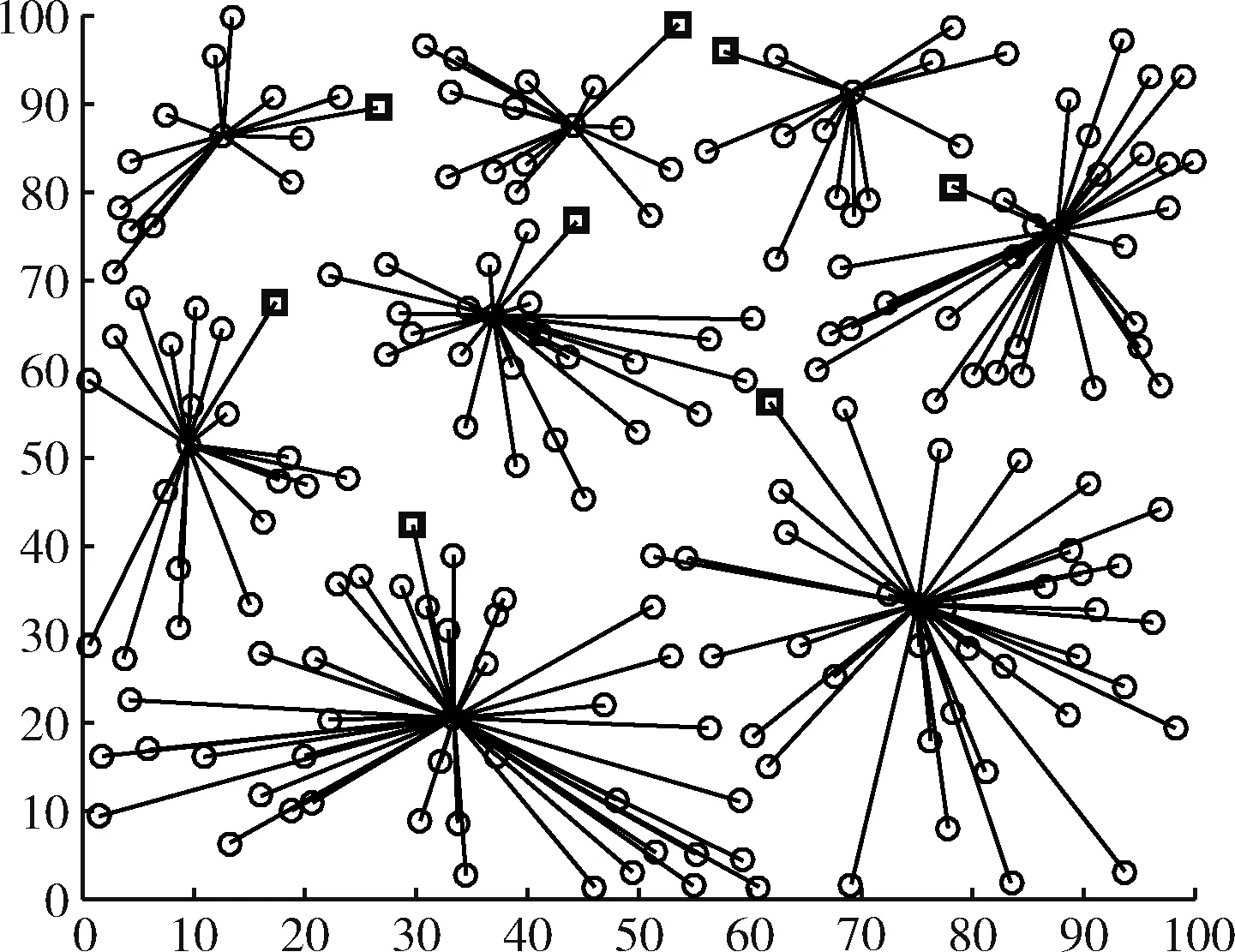
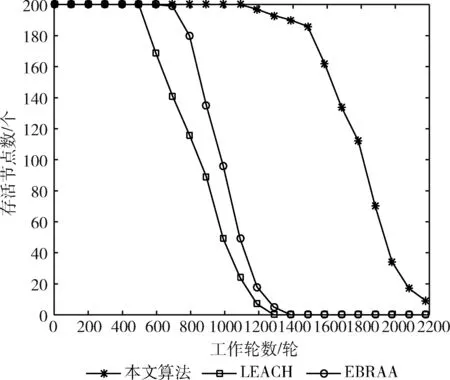
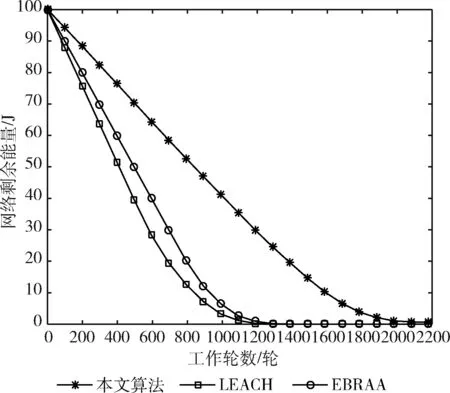
其中,d0為距離閾值常量,當d (2) 節點接收數據能耗只考慮與接收數據包的大小關系,其接收能量計算公式為 ERx(l)=lEelec (3) 考慮到簇間數據的相似性低,簇內數據相關性大且具有冗余性,因此在簇首接收完簇內數據后進行必要的數據融合,且假設融合后的數據量長度不變,融合1 bit數據能耗為Eda。 ANRB路由算法按照輪的思想運行工作,包括聚類分簇、雙簇首競選、簇間路由構建以及數據傳輸4個階段。網絡運行初始化時,各節點將自身的位置和能量信息向基站匯報,基站將接收到的信息匯總后采用改進的K均值算法進行聚類劃分并將分簇結果和聚類中心廣播出去,各簇首廣播通知入簇消息,各節點根據收到廣播信號的強弱入簇。從第二輪起,每一輪使用基尼系數對節點能耗均衡性預測,選取最有利簇內能耗均衡的節點擔任主簇首,當本輪和上一輪的主簇首(臨時簇首)相同時,無需進行廣播,否則交換兩個簇首的成員節點信息,廣播告知其余節點。各節點競選副簇首,主簇首依據簇內節點數目建立TDMA時隙表并通知簇內各節點。之后,進入簇間路由構建階段,各個副簇首根據自身到基站的距離,進行單跳或者多跳的路徑構建并形成自己的路由表,中繼節點按照事先規定的原則選擇。最后各簇按照規劃的簇間路由進行數據傳輸,簇內各節點在對應的時隙表向主簇首發送數據,空閑時隙自動進入休眠狀態,簇間數據傳輸采用載波監聽多路訪問,系統數據傳輸模型如圖1所示。為了及時更新各節點的自身信息,在每一輪的最后各簇節點將剩余能量等信息以控制信息的形式告知主簇首,主簇首經過傳輸向基站進行匯總更新。 圖1 系統傳輸模型 2.2.1 非均勻分簇 文獻[12]中的AGNES協議以層次算法分簇,當數據量大時該算法運行復雜,同時該協議未考慮成簇規模,考慮到遠離基站的節點需要尋找臨近簇群轉發數據,距離基站近的簇群應盡量減少簇內通信能耗,采用相對較小的規模來預留更多的能量作為其它簇群的數據轉發能耗,同時遠離基站的節點應減少分簇數目,以增大簇群規模減少向基站數據傳輸的次數。本文引入節點成簇競爭半徑[15]以及鄰居節點數,并通過非均勻分區的方式,調整簇群規模的大小,實現距離基站的簇群規模較小,遠離基站的簇群規模較大,具體分簇過程如下: 步驟1 初始化:在監測區域(L×L)內,L=100,基站設置在(50,150),成簇競爭半徑值R0=30, 各節點的競爭半徑計算如式(4),Tr=10表示鄰居節點半徑,分簇聚類個數k=8。 以縱坐標為基準,將監測面積分成3個區域(節點縱坐標大于80,節點縱坐標小于40,節點縱坐標位于40和80之間),針對不同區域內的節點,其鄰居節點半徑有所不同,統計各節點的鄰居節點數,具體分區以及鄰居半徑計算如式(5) (4) 其中,w∈(0,1) 表示距離權重因子,dmax,dmin表示各傳感器節點到基站距離的最大和最小值。di是節點i到基站的距離,Ri表示節點i的成簇競爭半徑,由式(4)可知其值會隨距離基站的大小而變化 (5) yi表示節點i的縱坐標,Tr1,Tr2,Tr3表示3種不同區域內節點的鄰居半徑取值。結合式(4)和式(5)可知距離基站近的簇群鄰居半徑大,其鄰居節點數多,靠近基站的節點在簇群中心初始化時被選中的概率增大,即在基站附近會有更多的簇群。 步驟2 優化初始中心:假設傳感器網絡中有N個節點,節點集合s={s1,s2,…,sN}, 每個節點都是二維坐標點即si=(xi,yi), 與傳統的K均值算法隨機產生k個初始中心不同,本文只隨機產生一個初始中心,初始中心需要同時滿足兩個條件:所選節點的鄰居節點數大于平均每個節點的鄰居數,所選節點與所在區域內已有的初始中心節點i的距離要大于2Ri。節點的選擇如下:每個非初始中心節點尋找與已知初始中心最短距離的平方,記為D2(i), 由式(6)計算所有節點最短距離的和記為sum以及各節點當選為初始中心的概率值,同時獲取各節點的累加概率。依據輪盤法則和初始中心選擇條件篩選合適的初始中心,這樣不僅考慮節點的鄰居節點數,也參照與現有初始中心的距離,既可以避免初始中心的邊緣化又可以使選出的中心彼此分開,使得所選簇群在分布上具有均勻性,按照此方法依次將k個初始聚類中心選出記為c={z1,z2,…,zk} (6) (7) 在所有聚類中心更新完畢后,每個簇群計算各自的數據點與聚類中心距離的平方和,Jt是聚類目標函數,其代表所有簇群內距離平方的總和,目標函數計算公式為 (8) 步驟4 迭代計算:重復計算步驟3中式(7)和式(8),直到前后兩次聚類目標函數差值滿足 |Jt-Jt+1|≤ε或者迭代次數滿足t=T時完成聚類。 步驟5 輸出聚類結果:各聚類中心依據自身競爭半徑選擇本簇成員節點,不屬于任何簇群的節點,按照就近原則加入相應的簇群。各簇群求取距離的平均值,以平均值作為本簇群的中心點,距離中心點最近的節點選擇為本簇群的簇群中心。 2.2.2 雙簇首競選 在簇首選擇方面,選擇合理的簇首有利于減少網絡的能耗,從而增加網絡的穩定性。本文算法在能耗均衡方面和網絡的生命周期上進一步改進,將經濟學中衡量收入差距的基尼系數作為節點能耗均衡性優劣的標準,在此將節點的剩余能量代替個人收入,得到均衡節點能量差距大小的計算式(10) (9) (10) fitbv(i)=1-Gv(i) (11) 其中,nv表示簇群v內包含的節點個數,u表示該簇群內所有存活節點能量的平均值,ei,ej代表標號不同的節點當前剩余能量,Gv(i)表示節點i當選本簇主簇首時各節點剩余能量對應的基尼系數,且Gv(i)∈(0,1)。 將式(11)作為衡量簇內節點能量均衡性的指標,該值越大表示簇內節點能耗越均衡,反之簇內節點能耗均衡性差。 為了簡化討論和分析能耗預測的過程,假設簇群v中只有3個節點,各節點的位置關系以及初始能量如模型圖2所示。暫且僅考慮數據傳輸能耗,定義每個節點接收數據的能耗為1個單位,esd(1,2)=3,esd(1,bs)=7代表節點1分別到節點2和基站的傳輸能耗值,ei代表節點運行到當前輪的剩余能量,實際ANUR算法在傳輸能耗和接收數據能耗計算時通過式(1)和式(3)進行,在圖2中分別計算候選節點擔任主簇首的剩余能量,代入式(10)、式(11),求取基尼系數最小的節點與臨時主簇首進行對比,如果臨時簇首的基尼系數就是最小值,則臨時簇首當選為最終主簇首,否則臨時簇首當選為普通節點。當節點1當選主簇首時u1=20.67, Δ1=2.67,fitbv(1)=0.935; 當節點2當選為主簇首時u2=21.33, Δ2=0.89,fitbv(2)=0.979; 當節點3當選主簇首時u3=21.33, Δ3=1.11,fitbv(3)=0.974, 各節點當選為主簇首的剩余能量分布如圖3所示,計算并分析3個節點當選主簇首后對應的能耗均衡函數值fitbv, 節點2的能耗均衡函數值最大,同時從圖3剩余能量值的柱形圖可以看出,以節點2為主簇首得到的簇內節點剩余能量更均衡,從簇內節點的總能耗方面分析,節點1,2,3分別當選主簇首簇內節點的總能耗為16,14,14個單位值,選擇2,3節點當選總能耗相同,但是節點2更有利于能耗均衡。由此可知能耗均衡函數可以反映簇內節點的均衡性,每一輪各簇在上一輪簇首的基礎上按著上述方法對簇內節點進行能耗預測,選出均衡性更高的節點擔任簇首。 圖2 節點間的能量消耗 圖3 節點當選簇首能耗分析(已添加橫縱坐標及單位) 考慮到單簇首工作任務不僅包含數據的接收、融合,還包括發送、中繼、成簇廣播等,每一輪能量消耗較多,不利于網絡能耗的均衡。在主簇首選擇完成后,通過引入副簇首分擔主簇首的發送和中繼任務,減少主簇首的通信能耗。根據副簇首的功能,將綜合考慮其與基站和主簇首的距離以及剩余能量進行選舉,定義選舉副簇首的公式如下 (12) γ=g/e(1-g),g=ei/e0 (13) 其中,di為節點到基站的距離,dmax,dmin分別表示簇內節點與基站相距距離的最大和最小值,節點和主簇首間的距離用ditoc表示,γ∈[0,1] 是關于能量比值g的函數,其值動態可變,節點的初始能量用e0表示,中繼節點在轉發數據時能量消耗大,因此從能量大于平均值的節點中選擇副簇首。由式(12)可知,距離基站近,剩余能量高且相距主簇首近的節點f(i) 值較大,相比之下容易被選為副簇首。網絡中節點的剩余能量會隨運行時間不斷減少,γ的值將逐漸變小,副簇首選擇將加大能量因子在選舉中的影響作用。 2.2.3 簇間路由的構建 (14) 在滿足(14)條件下,將綜合分析節點能量,傳輸距離,節點轉發次數以及所在簇群節點數量等因素選擇中繼節點。因此,定義候選中繼節點j的權重 (15) 其中,dij,djm,dim分別是節點i到中繼節點j, 中繼節點j到目的節點m, 節點i到目的節點m的距離。k(j),kav分別表示中繼節點j的簇群成員數和平均每一簇群所包含的節點數,t(j) 為中繼節點j運行到當前輪時累計轉發i節點所在簇群數據的次數,tall是i節點的所有侯選節點總計轉發來自i簇群數據的次數,其初始值為1,其值由每一輪統計累加得到,qi為加權因子,其和為1,根據網絡環境將其值分別設置為q1=1/3,q2=1/3,q3=1/6,q4=1/6, 經分析可知,剩余能量充足,中繼節點所在簇群成員節點數越多,承擔轉發次數少的副簇首越容易被選為i的中繼節點,每一次中繼都是按照最小權值原則選擇,為了及時更新路由表信息,在每一輪數據傳輸的最后,各簇將剩余能量、中繼次數等信息傳輸給基站,由基站以控制信息的形式反饋給各簇中的節點。 用Matlab2014a作為實驗仿真平臺,將ANRB算法、LEACH以及EBRAA算法3種算法分別運行2200輪,模擬在監測區域為100×100 m2的場景下,隨機生成200個數據點作為傳感器節點,實驗仿真中用到的其它參數設置如下:節點收發數據能耗Eelec=50 nJ/bit, 節點融合能耗Eda=5 nJ/bit, 自由空間模型放大系數εfs=10 pJ/bit/m2, 多徑衰落模型放大系數εamp=0.0013 pJ/bit/m4, 節點數據包長度l=4000 bit, 控制包長度l=200 bit,w=0.8, 節點的初始能量e0=0.5 J, 距離閾值d0=87.7 m。 圖4是本文算法的仿真成簇圖,簇中心為主簇首節點,每一簇的黑色方形為副簇首節點,其余黑色圓圈代表普通傳感器節點,從成簇可以看出,靠近基站的簇群成簇規模小,反之簇群規模大,相比文獻[12]中的EBRAA算法在簇群實現均勻分布的前提下,各簇群規模得到了調整。 圖4 本文算法成簇 3.2.1 存活節點數 存活節點數指標是描述網絡系統中節點數目隨著網絡運行時間變化的情況,各算法網絡初始設置均相同,網絡運行時間變化,系統中存活節點數越多則表示網絡的完整性好即系統越穩定。3種不同算法的存活節點數和運行輪數仿真對比分析如圖5所示,對各算法第一節點,第100節點以及第180個節點的死亡輪數進行統計得到圖6所示的柱狀圖。我們定義各算法的第一死亡節點所對應的輪數作為網絡的生命周期。從圖5、圖6綜合分析可以得出ANRB協議的生命周期為1162輪,相比LEACH協議的生命周期明顯延長649輪,與EBRAA算法相比也推遲470輪;分析一半數量的節點死亡情況,ANRB算法是1796輪,約為LEACH協議的2倍,是EBRAA算法的1.8倍;從80%的節點死亡分析,本文算法相當于另外兩種算法的1.8倍。在運行結果的基礎上表明本文算法能較好延長生命周期,均衡網絡能耗,與EBRAA算法對比,本文算法優勢是引入了能耗均衡評估函數,在每輪簇首競選時減少了簇內通信能耗而且各節點能耗得到均衡,其次雙簇首工作機制,也能減少單簇首通信負擔,優化中繼節點的選擇使得簇間傳輸能耗得到均衡,這些改進均可以延長網絡生命周期。 圖5 存活節點數統計 圖6 第1,100,180節點死亡統計 (已添加橫縱坐標及單位) 3.2.2 網絡能耗 網絡的剩余能量是衡量系統穩定的一個重要指標,在同等條件下傳感網中剩余能量的多少將直接決定著網絡生存期的長短。圖7仿真了3種算法網絡剩余能量和運行輪數的關系對比圖,分析可知ANRB協議的剩余能量總是比其余兩種算法的剩余能量高,其主要原因是ANRB算法簇內以最大能耗均衡值為依據選舉主簇首,用動態權值調整副簇首的選擇,同時遠離基站的簇群規模相比EBRAA算法要大,可以減少遠距離傳輸的次數,從而節省能耗。LEACH協議的頻繁分簇和隨機分簇導致能耗消耗較多,與之對比本文算法在能耗上較少。 圖7 網絡剩余能量統計 3.2.3 吞吐量 吞吐量表現在監測者通過網絡可接收監測區域信息量的多少,本文定義從網絡開始運行到全部節點死亡基站在整個過程接收的數據包個數作為吞吐量。為了體現算法的穩定性,將各算法分別運行10次,并分別取平均值作為算法吞吐量的統計值,如圖8所示,ANRB算法在吞吐量統計值上明顯高于其它兩種算法,分別是LEACH協議的1.66倍,EBRAA算法的1.42倍。這主要是因為本文算法能夠較好均衡簇內和簇間的能耗,網絡的生存時間上要比其余算法長,在相同的初始能量環境下,基站將會接收更多的數據包數。因此,ANRB算法具有很好的穩定性。 圖8 網絡吞吐量統計(已添加橫縱坐標及單位) 本文算法為了均衡節點能耗,從成簇規模、簇首競選、引入簇內能耗均衡函數,以及優化中繼節點選擇等幾個方面進行能耗均衡的提升,副簇首節點擔負數據的發送和中繼,主簇首的通信負載得到減輕,簇首節點的能量得到均衡,并通過能耗均衡函數預測簇內能耗均衡性,簇間路由優化中繼節點的選擇,進一步考慮中繼點的轉發次數以及其所在簇群的節點數量,有效避免中繼節點在每一輪運行中由于承擔過多的轉發次數而消耗較大的能量,從仿真結果分析可知ANRB算法的生命周期比LEACH和EBRAA協議要長,相比而言分別延長649輪和470輪,在吞吐量方面是LEACH協議的1.66倍,EBRAA協議的1.42倍,表明本文算法在能耗均衡上得到進一步提升。下一步將在最優跳數方向進行研究,在滿足能耗均衡的基礎上以最小跳數來減少數據傳輸延時。2 ANRB算法
2.1 算法思想
2.2 算法實現


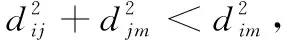
3 仿真與結果分析
3.1 仿真環境設置
3.2 仿真結果分析


4 結束語
