面向人臉檢測MTCNN網絡的加速硬件設計
2022-03-01 13:12:52孫慶斌
計算機工程與設計 2022年2期
孫慶斌,何 虎
(清華大學 微電子學研究所,北京 100084)
0 引 言
在眾多的人臉檢測算法[1]中,MTCNN神經網絡算法兼具準確率高和速度快的優點,并且MTCNN在小目標檢測上很有優勢,所以在當今工業界中應用十分廣泛。但是,包括人流量較大的場所進行體溫監測、過馬路違章行人檢測等在內的許多場景都需要檢測的實時性,而在通用CPU上運行推理算法不能滿足實時性的要求。目前,工業界中很多用通用GPU對神經網絡推理進行加速,但是GPU能耗高、價格貴,尤其不適用于移動充電設備。專用神經網絡硬件加速器能耗低、成本小,是加快神經網絡推理速度最理想的選擇。比如哈弗大學學者Bradley McDanel等基于FPGA設計了全硬件全棧優化的卷積加速器[2],Mateja Putic等設計了可以動態配置的DNN(deep neural network)加速器[3]。清華大學劉雷波實驗室針對MTCNN神經網絡做了專門優化的硬件并進行了流片[4]。密歇根大學的Cong Fu等基于FPGA ZYNQ 706開發板設計了針對MTCNN網絡的加速器[5]。由于做MTCNN加速硬件的并不多,所以本文基于FPGA zcu102針對MTCNN人臉檢測神經網絡設計了專門優化卷積和全連接加速器。相對于前人,加速器接口部分采用了動態分塊算法減小卷積分塊后數據的重復量,極大減小了數據的傳輸時間。同時,本設計在能耗和路徑延遲方面也做了很多優化。測試結果表明,本設計在沒有DMA的情況下就能把MTCNN網絡推理加速到ARM CPU的6倍以上。
1 MTCNN算法
MTCNN算法是一種多任務的人臉檢測算法,可以同時進行人臉以及人臉關鍵點在圖片中位置的檢測。MTCNN是由三級網絡:P-Net(proposal network)、R-Net(refine network)、O-Net(output network)級聯而成,每個網絡都有多個檢測任務,包括人臉分類、邊框回歸和關鍵位置檢測。如圖1所示,P-Net之前對圖片每次乘以縮放系數z,縮放到設置的最小尺寸,得到N張圖片,形成圖像金字塔。把所有放縮之后的圖片輸入P-Net,獲得每個最小尺寸區域是人臉的概率和糾正值,利用非極大值抑制(NMS)算法合并重疊區域較多的候選框,最后結合糾正值把坐標回歸到原圖;O-Net之前把P-Net檢測出的人臉區域從原圖中截取出來,統一放縮成24*24,所有的圖片輸入R-Net,同樣得到每個最小尺寸區域是人臉的概率以及糾正值。通過非極大值抑制以及坐標回歸得到更少的接近正確結果的候選人臉坐標區域;O-Net與R-Net網絡類似,把R-Net檢測出區域從原圖中截取出來輸入O-Net,最終獲得人臉區域候選框以及人臉上5個關鍵點的位置。
分析算法可知,P-Net具有通道少、圖片數量多而且大小不同的特點,P-Net的用時大約占整個網絡推理用時的80%。O-Net以及R-Net具有網絡規模小,多張圖片并行且圖片大小相同的特點。所以,對應的加速器硬件設計的特點為:
(1)并行的通道數目少,同時圖片分塊送入加速器片上RAM時,并行計算的圖像塊數目多;
(2)計算核心的規模小,同時計算核心的數目多;
(3)圖片并行計算時不需要彼此等待同步之后再進行下一步計算。
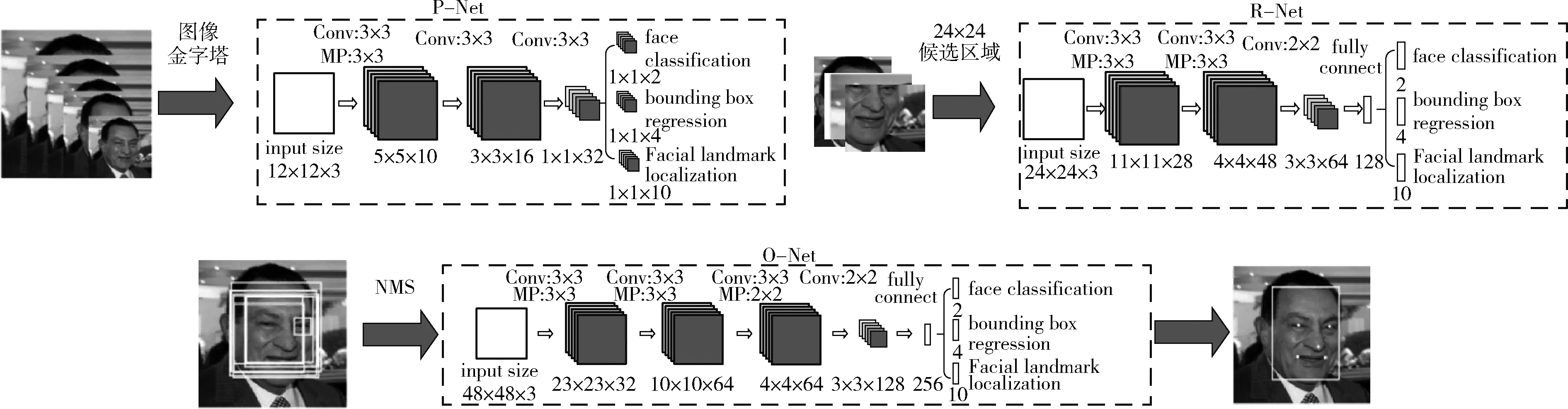
圖1 MTCNN網絡推理過程[6]
2 SoC軟硬件設計
上一節分析了MTCNN算法以及其加速硬件的特點。所以,本設計基于以上分析針對MTCNN網絡進行了軟硬間協同的優化。其分別體現在嵌入式軟件代碼編寫、加速器硬件架構以及軟硬件接口的設計上。下面從這3個方面對整個加速器嵌入式系統進行介紹。
2.1 嵌入式軟件
MTCNN網絡包含了卷積、全連接、池化、非極大值抑制(NMS),坐標回歸(bound box regression)等諸多算法,但是卷積、全連接占用了大部分推理時間,所以本設計僅把卷積、全連接用加速硬件實現,其它算法在ARM CPU上運行。在原始算法中,P-Net每張圖片串行運算,而在本設計的嵌入式軟件中,三級網絡所有圖片都是并行運算的。如此網絡參數只需傳輸一次而且被多張圖片使用而不用重復傳輸,大大增加參數的復用率減少了參數的傳輸時間。在PC的matlab程序中,圖片縮放算法采用的Piotr Dollar工具箱中的resample函數。在調試嵌入式C語言程序時,需要把ARM上跑出來的中間數據和matlab跑出來的程序進行對比。對比發現錯誤之處需要使嵌入式軟件預處理數據和matlab數據完全一致。因此,本設計的嵌入式軟件移植了工具箱中的圖片縮放算法,即用嵌入式C語言實現和matlab Piotr Dollar工具箱中放縮算法函數完全一致的運算過程。這也使得本設計的運行結果和原始matlab官方算法運行結果0誤差。
2.2 加速器SoC
2.2.1 SoC整體架構
圖2所示即為加速器SoC組成框架,FPGA的上位機把交叉編譯好的程序從JTAG接口傳輸到PS端的DDR中[7]。神經網絡參數和圖像在PC中轉換為二進制文件提前存放在開發板的SD卡中。當程序開始運行時,利用BSP包中的FATFS文件系統從SD卡中讀取參數和圖像到DDR中。當需要進行卷積和全連接計算時,ARM通過64位的AXI總線把中間數據、圖像或者權重、prelu、bias參數從DDR傳輸到加速硬件的局部RAM中,待所有的一塊圖像計算完成后,ARM處理器把加速器的計算結果從局部RAM傳輸到DDR。當前DDR和加速器之間的數據傳輸完全由ARM處理器控制,ARM不能同時控制傳入傳出數據,如此傳入數據就會浪費很多時間。以后也會有對應的解決方案加入。而在進行計算之前,ARM將會通過AXI-lite總線把每一層卷積以及全連接的配置信息傳輸到控制器中的寄存器中。控制器根據配置信息控制局部RAM輸出到數據通路的數據以及數據通路流水線中的操作。
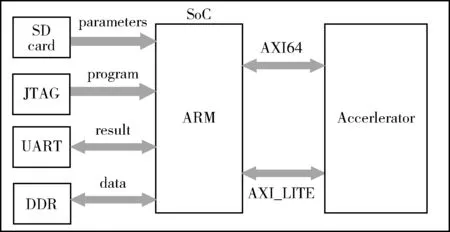
圖2 加速器SoC組成框架
2.2.2 加速器計算通路
圖3所示為加速器計算基本單元的結構圖,每個基本單元中有4個乘法器可以并行計算圖像的4個channel,然后加法樹將結果累加起來。由于多數卷積層輸入圖像不止4個channel,計算出來的中間結果需要暫存在輸出的RAM中,例如,卷積輸入圖像有16個channel,每次并行計算4個channel,計算核心循環4次才能把圖像的所有channel累加起來,所以在沒有計算完所有channel之前,channel累加的中間結果都存儲在輸出RAM中。因此在加法樹之后需要累加單元將之前暫存的中間結果累加起來。卷積和全連接共用同一個計算通路,而不用再添加額外的計算資源。若是卷積計算,由于同一個視野中的像素的計算結果要在很多個周期之后才需要,中間計算結果也要存放在輸出的RAM中,所以累加單元的累加數據來自于輸出的RAM;若是全連接計算,由于其相當于只有一個視野,同一個視野中一個像素的中間結果在下一個周期要立刻累加進下一個像素點中,全連接的同一個視野中像素的計算中間結果不再存儲在輸出的RAM中,而是立刻返回來作為下一時刻累加單元的累計數據。所以全連接計算中累加數據來自于累加單元的輸出。一個計算核心包含4組基本電路,4組基本電路之間共享輸入圖像數據,但是權重、prelu和bias這些參數來自不同kernel的同一個位置,即4組電路同時并行運算4個kernel的圖形的同一個視野位置。綜上可知,一個計算核心包含16個乘法器、20個加法器、4個激活單元,乘法器用于權重和圖像的相乘、加法器用于通道之間的累加以及bias參數的累加、激活單元中有乘法器,如果輸入數據小于0則與prelu參數相乘,如果輸入數據大于0或者不需要進行prelu激活計算則直接乘1。
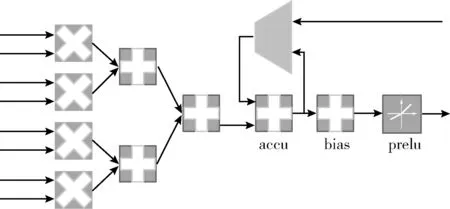
圖3 計算基本單元
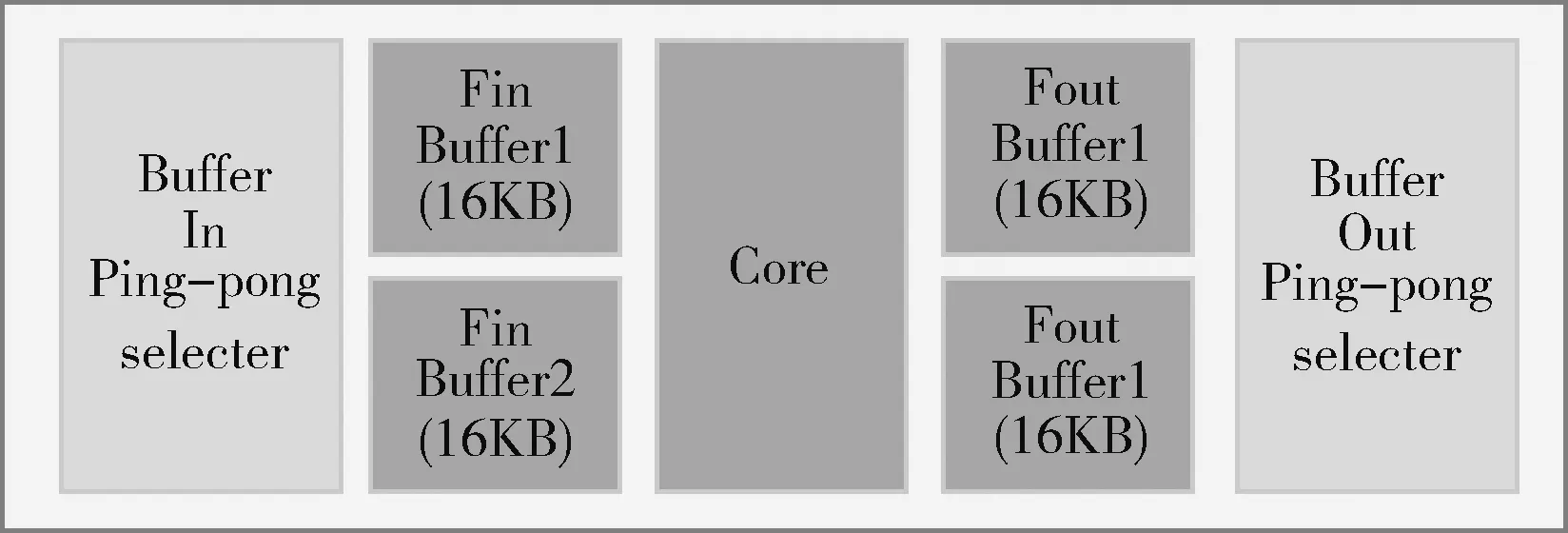
圖4 數據通路組成
圖4說明了整個數據通路的結構組成,除了4組基本計算單元之外,還有兩個ping-pong的存放輸入圖像的RAM,之所以用ping-pong的RAM,是因為在一個輸入圖像RAM準備好數據之后,計算核心開始計算,ping-pong RAM中的另一個RAM可以同時傳輸數據,如此計算時間和傳輸分塊圖像數據的時間兩者中時間長的操作便把時間短的操作的時間覆蓋,節約了很多時間。兩個存放中間結果及最終結果的RAM,目前在ARM從存放中間結果RAM獲取計算結果的操作和計算并不同時進行,在加入DMA之后可以實現并行操作。兩個接受控制器信號,選擇ping-pong RAM的模塊可以根據控制器的控制信號決定輸入圖像數據輸入到哪個RAM之中以及計算結果從哪個RAM獲取并對相應的RAM進行選通。
2.2.3 加速器架構
如圖5所示,加速器的整體架構是參照英偉達GPU GeForce 8800的架構來進行設計,加速器含有一個控制模塊控制數據流以及數據通路中的算子操作。加速器的數據通路中有4個group,對應英偉達統一計算設備架構CUDA中的block。每個group中有5個計算核心。每個計算核心都含有局部的存儲輸入圖像和輸出結果的RAM。4個group共享存儲weight、激活以及bias參數的RAM。綜上所述,整個加速器含有20個核、一個控制器、3個共享的RAM。

圖5 加速器架構
其中,加速器的控制器和數據通路都針對MTCNN做了特殊的優化。①支持輸入圖像的動態分塊:輸入圖像塊的大小不再固定,而作為配置信息由AXI-lite總線傳入控制器,因此支持輸入圖像大小的改變;②能耗優化,每次計算輸入圖像的總塊數作為配置信息傳入控制器,控制器把閑置的group關閉,以節約能耗;③共享存儲器的數據在group之間進行廣播,在group內部脈動傳輸[8,9],參數在核之間經過一級寄存以減小RAM 的扇出,提高頻率。
加速器中的控制器負責控制所有核的運算,其接受ARM通過AXI lite總線傳輸過來的控制信息。這些控制信息包括:權重weight的大小、通道數目、kernel的數目,傳送入加速器的圖像塊的長寬以及通道數,本次計算傳入的總的圖像的塊數,圖像數據是否傳輸完成以及計算結果是否全部取完的握手信號,20個計算核心各自計算完成一次之后以及整層卷積或者全連接計算完成之后的同步復位信號。同時,為了便于數據的復用以及數據的并行計算,加速器中的卷積和全連接的計算順序和原算法的計算順序有所差異[10]。
2.3 軟硬件接口
由于加速器中的存儲圖像的局部RAM的容量是有限的,所以圖像要分塊傳入。同時,要把分塊后的圖像和參數按照加速器的計算方式重新排列。對于weight參數,PC中的排列順序為長、寬、channel、kernel,重新之后的weight參數的排列順序為4個channel、4個kernel、長、寬、分塊后channel數目、分塊后kernel數目。同樣,圖像分塊后也需要按照4個channel、分塊后長度、分塊寬度、分塊后通道數的順序重新排列。其中,分塊前通道如果不是4的倍數,則用0補足;kernel的數目如果不是4的倍數,則用0補足。
軟硬件接口函數的功能主要包括:對參數和圖像分塊、重新排序、發送控制信息、發送圖像和權重數據、取回加速器運算結果。接口中包含了針對MTCNN所做的特殊優化。第一,完全自主設計了對卷積輸入圖像的動態分塊算法。接口函數中,分塊的圖像的大小由存放輸入圖像和運算結果的RAM的大小以及所有待測圖像的最長邊的最小值來確定最大的分塊,極大減小了重復傳輸數據量,節約了數據的傳輸時間。如式(1)所示
a=min(max(width,height)image0,…, max(width,height)imagei)
(1)
計算出待測圖像最長邊的最小值,式(2)和式(3)計算出輸入和輸出RAM容量允許的最大分塊尺寸
(2)
(3)
如式(4)所示求三者的最小值即可得到該層卷積計算的最大尺寸
tile_size=min(a,b,c)
(4)
在進行卷積運算時,同樣尺寸的圖像分兩塊傳入比分3塊傳入加速器,重復傳輸的數據要少很多。第二,由于級聯的3個網絡中有多個圖像并行傳入,P-Net輸入的圖像大小不等,R-Net和O-Net輸入的圖像大小相等。如果每個圖像獨立并行運算,總需要彼此等待同步之后才能進入下一步運算,耗費大量的時間。本設計接口函數使用了圖像間混合運算的方法。如圖6所示,圖像分塊之后,把每個圖像的分塊數目,按照順序存放進圖像池;計算完成之后,從輸出圖像池按照之前的順序,按照相應的數目分配回去,這樣便不再用處理圖像并行計算的問題。即把圖像并行計算轉化成圖像塊并行計算的問題。控制器和數據通路不必再得知圖像塊屬于哪個圖像,只需獲取其進行卷積運算還是全連接運算的配置信息即可。
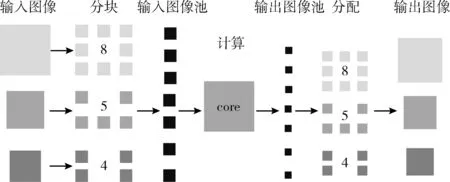
圖6 圖像間混合計算
3 加速器驗證和性能分析
3.1 加速器設計和驗證
整個加速器的設計全部在Xilinx Vivado開發軟件中進行,編寫Verilog在Vivado中用進行了全面的仿真功能驗證。首先,寫硬件描述語言Verilog進行加速器中計算基本單元和控制器的設計。計算基本單元中的乘法器和加法器調用Xilinx vivado設計工具中的IP并調用FPGA的BSP資源。控制器全部用HDL實現。產生相應位數的隨機數進行計算核心單元的驗證。給定控制器設定好的控制信號,通過檢驗控制器輸出信號是否符合相應的功能設計來驗證控制器的功能。控制器和數據通路功能驗證正確之后,將MTCNN算法全部用嵌入式C語言實現,與matlab程序跑出來的結果完全一致;然后編寫軟硬件接口函數,接口函數中調用了對圖像和參數排序的子函數。調式排序子函數時,把排序前后的數據通過串口打印出來,把打印出來的數據復制到EXCEL表格之中,把排序之后的數據對應到其排序之前的相應位置看是否正確。接口函數中卷積和全連接的排序子函數是不同的,通過參數對進行全連接或者卷積計算進行控制,同時進行相對應得排序。接口函數中還有接受發送數據的子涵數,可以串口打印出發送的數據和matlab程序的數據進行對比調試。整個嵌入式C語言程序首先從SD卡中讀取參數和數據,三級網絡之前都要用ARM對圖像進行截取和縮小等預處理。預處理中的截取和縮小圖片的運算過程完全和matlab程序運算過程一致。用驗證過的軟硬件接口函數替換嵌入式C語言的卷積和全連接函數,此時整個的MTCNN算法便可以在ARM和加速器上進行軟硬件的協同驗證了。
在軟硬件協同驗證時,把比特流燒寫進FPGA,首先用串口打印的方式調試接口函數。此時可以把打印出的加速器的計算結果和matlab的計算結果進行對比,如果返回結果不對則可以用Vivado開發工具中的ILA IP實時觀測卷積和全連接在加速器上運行時的計算通路和控制器的信號波形,對每個控制信號、其中一個核的數據以及接受到的控制信號進行觀測,進還原得子函數進行驗證,在接口函數中要通過排序還原函數把行硬件的debug,直到最后從加速器取回的計算結果和matlab程序的計算結果完全一致。計算結果完全一致以后還要對排序計算結果排序還原成MTCNN原算法計算的排列順序即寬、高、通道的順序。此時,整個加速器已經完全能有正常的功能輸出完全正確的數據了。之后,把MTCNN嵌入式C語言程序中的卷積核全連接函數全部換成接口函數,用串口打印出識別出的人臉框的坐標和人臉關鍵點的坐標。把串口打印出加速器的運行的結果和PC運行的結果進行對比,結果正確。如圖7所示,圖片是PC中matlab運行結果,第一張圖片中框出一張人臉,并標出人臉中關鍵點位置。右側文字部分是ARM和加速器運行串口打印的結果,可以看到檢測到一張人臉,并得到人臉框和人臉關鍵點在圖中的坐標位置。第二張圖片有兩張人臉,matlab運行結果框出兩張人臉并對人臉關鍵點進行標記。同樣,ARM串口打印出的結果顯示有兩張人臉,并給出了兩張人臉的關鍵點的坐標。而且串口打印出的數據和matlab跑出的數據完全一致,誤差為0。

圖7 運行結果對比
3.2 加速器性能分析
在時鐘為100 MHz時,對整個SoC工程布局布線,成功生成比特流,表1顯示了整個加速器SoC的資源利用情況。從圖中可以看出,資源利用在合理的范圍內。之后,對全部由嵌入式C語言實現的MTCNN程序和ARM以及加速器實現的程序在各種優化條件下測量性能。用ARM中的Timer對識別一張具有兩張人臉的圖片進行計時。整個代碼運行在Xilinx ZCU102開發平臺上。ARM的處理器為Cortex-A53,頻率為1.2 GHz,加速器為100 MHz。表2顯示了不同平臺下檢測此圖片的時間、對應的能耗以及該平臺的工作貧頻率。經過測試,ARM和加速器運行的程序比ARM O2下快6倍,比ARM O0條件下快104倍。其中加速器的功耗也是ARM O2優化的將近1/4。另外,在測試過程中也對傳輸數據、獲取結果以及計算的時間單獨做了分析,以了解當前加速器瓶頸所在,利于進一步的優化。下面以20塊18*18*4的圖像塊的傳輸、計算以及20塊16*16*12的輸出的獲取時間為例,分析傳輸和計算時間以解決瓶頸問題。如圖8所示,20塊18*18*4的圖像的計算時間是98 μs,傳入總時間為520 μs,20塊16*16*12的計算結果傳回DDR的時間為6720 μs。計算可以得出總的計算量為4 423 680個操作,用時一共98 μs。計算峰值為45 GOPS,計算性能良好。從圖中可以看出,計算和核心在進行計算的同時,ARM給輸入圖像ping-pong RAM中的未用RAM傳輸數據,傳輸計算并行,節約了時間。但是由于DDR中數據的傳輸全部用ARM控制,傳輸獲取數據便不能并行起來。由于,計算時間被掩蓋,目前來看加速器耗費的時間全部用來傳輸數據。綜合以上得出,目前的性能的限制在于圖像的傳入和計算結果取出時間。此后,考慮加入scatter-gather模式的DMA,這種模式的DMA在對所有的核心傳輸圖像塊時,即使地址不連續也可以只配置一次而把所有的數據傳輸完,這樣ARM就可以把傳輸數據的任務分擔給DMA,多通道DMA也可以實現傳入圖像和獲取計算結果同時進行,如此將大大提高操作的并行度減少傳輸數據的成本提高本設計的性能。同時目前的MTCNN網絡沒有經過量化,即仍然使用浮點數進行運算,如此傳輸數據的量大大增加,而且浮點計算單元占用的資源多延時長,支持的工作頻率低。此后將在盡可能小的損失精度的情況下把MTCNN網絡參數量化為整型,傳輸數據量將成倍減小,浮點乘法和加法轉化為int型乘法和加法也將大大減少資源的利用,有利于加速器在相同的資源下增大規模,同時加法器和乘法器的路徑延遲也將大大縮小,將成倍提高加速器的時鐘頻率[11]。如此加速器得性能將成倍得提升。
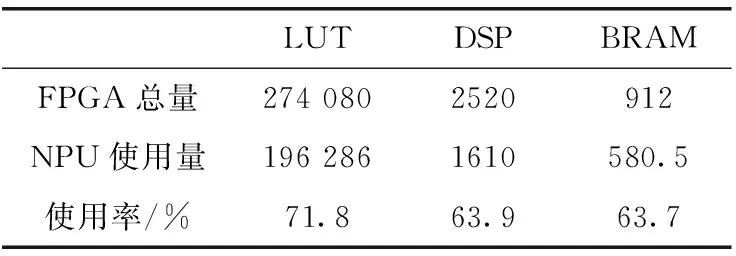
表1 SoC系統資源利用率
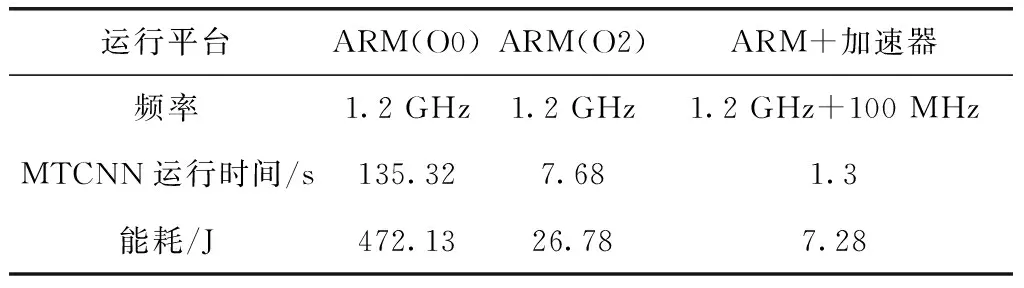
表2 不同平臺性能對比

圖8 傳輸和計算時間對比
4 結束語
本設計針對MTCNN人臉檢測神經網絡做了專門優化的基于Xilinx FPGA ZCU102平臺的硬件加速器,加速器采用了類似GPU的多核架構,硬件上采用多而小的這種眾核的架構,極度適應了MTCNN網絡卷積和全連接輸入圖像多通道少的特點。軟硬件接口中采用動態分塊算法、圖像間混合計算,group內參數脈動傳輸、閑置組可關斷等多種策略優化加速器的延時、能耗,解決了由于MTCNN網絡圖像多,如果串行運算需要多次傳輸參數以及即使并行運算也需要彼此同步的問題,尤其圖詳間混合運算使得運算沒有了圖像的概念而只有圖像塊的概念。經過設計仿真驗證等步驟成功得出和單純ARM運行相同的結果,由于移植matlab工具箱中的算法到嵌入式ARM平臺上,算法運算過程與matlab完全一致,使得最終結果誤差為0。經過性能測試評估,本加速硬件峰值計算性能達到45 GOPS。能耗相比ARM運行大大降低。此后,本設計將加入scatter-gather模式的DMA增大操作的并行度,優化數據傳輸時間。量化網絡模型參數,由于整形計算模塊占用資源大大減少,因此也可以增大計算核心規模[12],并把MTCNN算法中比較占用時間的池化和圖片放縮算法用硬件實現。優化結束之后將加入攝像頭、顯示器構建嵌入式系統,方便此設計直觀地進行驗證以及此后的商業落地。
