基于決策邊界的傾斜森林分類算法
2022-03-01 13:46:00闞學達張攀峰
計算機工程與設計 2022年2期
關鍵詞:分類
闞學達,桂 瓊,張攀峰
(桂林理工大學 信息科學與工程學院,廣西 桂林 541004)
0 引 言
作為多分類器的代表,由Leo Breiman提出的隨機森林(random forests,RF)是分類算法的重要技術之一[1]。該算法被廣泛應用于電力系統電荷預測[2,3]、入侵檢測[4]、密碼體制識別[5]以及圖像分割[6]等方面。然而,該算法分類準確率還有待進一步提高[7]。此外,隨機森林算法在分類不平衡數據集時,對少數類分類準確率過低,導致整體分類準確率下降[8]。因此,提高其對不平衡數據的分類準確率非常重要。對于處理不平衡數據方面,現有研究主要從數據集出發,將數據預處理融入到分類算法中[9]。文獻[10]、文獻[11]通過對抽樣與投票的過程進行加權,使少數類有更高概率被抽樣,并且對分類結果較好的決策樹賦予更高的投票權重,有效提高隨機森林對于不平衡數據的分類能力。在提高隨機森林算法的分類準確率方面,文獻[12]提出基于改進網格搜索的隨機森林參數優化算法,通過尋找最優參數使得隨機森林算法分類準確率有所提高。文獻[13]將雙邊界支持向量機替代決策樹的分裂準則,取得不錯的效果。然而支持向量機的求解時間較長,增加每個結點求解分裂準則時間。針對進一步提高隨機森林分類準確率并且使其適應不平衡數據分類,本文提出一種基于決策邊界的傾斜森林(oblique forests based on decision boundary,OFDB)分類算法。OFDB算法把傾斜分裂超平面這一概念引入隨機森林的分裂準則中。通過賦予各個類自適應權重,提高OFDB算法不平衡數據分類能力。為使算法可以解決多類分類問題,本文在單個結點分裂過程中采用“一對多”的策略。實驗結果表明,OFDB算法分類準確率相比于的隨機森林算法有較大提升,并且OFDB算法在處理不平衡數據集方面,比隨機森林算法有更好的表現。
1 隨機森林與決策邊界
隨機森林是由決策樹組成的組合分類器,由裝袋、決策樹構建、袋外估計組成。
對于給定的n個元組m個屬性的分類數據集
(1)
假設隨機森林擁有k個單分類器,裝袋的基本思想是,對于循環i(i=1,2,…,k), 第i個決策樹從訓練數據集D中有放回地抽取n個元組,并且對被抽取的元組進行標記。
隨機森林構建決策樹常使用Gini指數作為分裂準則,用于衡量數據分區D的不純度。基尼指數定義如式(2)所示[14]
(2)
pi表示D中元組屬于Ci類的概率。考慮確定分裂屬性A與確定分裂點的情況下,數據集D被該規則劃分為D1、D2,該分裂準則的基尼指數計算公式如式(3)[14]
(3)
通過求解每個結點基尼指數GiniA(D)最小值得到每個結點最優分裂準則。最終得到k個決策樹的分類模型序列 {h1(X),h2(X),…,hk(X)}。
隨機森林預測采用多數投票法如式(4)所示[1]
(4)
其中,H(X)表示組合分類模型,hi是單個決策樹分類模型。在預測中以多數表決的方法,得到隨機森林總體的分類結果。袋外估計(out of bag estimation,OOBE)用來估計隨機森林的分類能力,其使用每個決策樹訓練子集中沒有被抽樣的元組來對這個決策樹進行測試。
邏輯回歸是解決分類問題的一種常見算法。對于給定的樣本屬性X,y的取值如式(5)
hθ(X)=g(θTX)
(5)
其中,θ為權重參數,函數g如式(6)所示[15]
(6)
由式(5)、式(6)可知,當函數g(z)中z>0時,g(z)>0.5,此時預測該樣本類別y取值為1。反之,當函數g(z)中z<0時,g(z)<0.5,此時預測該樣本類別y取值為0。對于一個訓練完成的邏輯回歸模型hθ(X)=g(θTX), 將樣本Xi帶入決策邊界θTX計算該式是否大于0來判斷該樣本屬于某一類。θTX=0被稱之為該模型的決策邊界。邏輯回歸的代價函數如式(7)所示[16]
(7)
代價函數表示對于確定的θ模型對數據集X分類錯誤程度。對于給定數據集,X與y的值是確定的,θ為自變量,求解代價函數的最小值,即可求得分類錯誤程度最低時θ取值,確定決策邊界。
2 OFDB算法
2.1 基本概念
定義1 傾斜決策樹(Oblique Decision Tree):傾斜決策樹是以決策邊界作為樹中每個結點的分裂準則的決策樹。假設類obliqueDecisionTree,對于該類的每個實例對象Node,變量classLabel表示當前結點的類標號;變量dataset表示當前結點的數據分區;變量leftChildTree與rightChildTree分別指向其左子樹右子樹;變量obliqueSplitHyperplane表示當前結點分裂超平面的θ值。
定義2 傾斜分裂超平面(Oblique Split Hyperplane):OFDB算法中每個傾斜決策樹結點Node的傾斜分裂超平面如式(8)所示
θT·X+θ0=0
(8)
傳統隨機森林算法分裂準則可表示為式(9)
x=b
(9)
其中,x表示某一確定屬性,b表示確定常數。式(9)可由式(8)表示,即傳統分裂準則為傾斜分裂超平的一種特例,傾斜分裂超平面考慮更為廣泛的情況。在預測過程中,將新的樣本元組X帶入式obliqueSplitHyperplane·X中,以判斷該樣本位于傾斜分裂超平面的某一側,進而被劃分至左子樹或右子樹的數據分區中。對于特定的樣本元組,計算如式(10)所示
obliqueSplitHyperplane·X= (θ0,θ1,…,θm)T·(1,x1,…,xm)
(10)
定義3 葉子結點標記自適應權重(leaf node labeling adaptive weights):在決策樹結點轉化為葉子結點時,使用加權后的多數類標記該結點。葉子結點標記結果為式(11)
(11)

(12)
|D| 表示數據集D的樣本個數, |DC| 表示數據集D中屬于C類的樣本個數。
2.2 基本思想
基于決策邊界的傾斜森林分類算法是一種以隨機森林作為框架,以傾斜分裂超平面作為決策樹結點分裂準則的分類算法。其主要針對隨機森林算法中的分裂過程做出改進,以此提高分類準確率。
在隨機森林模型的框架下,構建k個傾斜決策樹,并且為k個傾斜決策樹進行有放回抽樣并且舍棄重復元組作為訓練子集。每個傾斜決策樹遞歸地對每個結點進行分裂直至滿足終止條件,之后將根據式(11)將對葉子結點進行類標記。
在傳統隨機森林算法中為求得最優分裂準則,通常會以最小化該結點Gini指數為目標。假設,求解得分裂準則為在屬性ai(i=1,2,…,m) 上分裂點為常數b,即分裂準則為垂直于數據空間某一維度的超平面。但是這樣的分裂方式不能很好抓住數據空間中的幾何結構,文獻[13]提出基于雙邊界支持向量機的傾斜決策樹,但是由于支持向量機的求解時間過長,該方法僅在小數據集上具有較好表現。為保證構建傾斜分裂超平面的基礎上提升運算性能,本文使用式(7)作為代價函數以求解超平面的θ參數作為傾斜分裂超平面。
考慮代價函數為凸函數,即函數局部最小值即是全局最小值,本文使用梯度下降法求解代價函數最小值。參數θ更新規則如式(13)
(13)
為保證梯度下降法迅速收斂,本文在訓練之前使用式(14)對數據集進行規范化處理,將其取值映射至區間[0,1]之間
(14)
考慮在單個結點上通過一個超平面只能解決二分類的問題。為使算法可以解決多分類問題,本文使用“一對多”的策略,在單個結點使用最多類與其它類進行二分類,使算法適用于多分類問題。
考慮到正負類樣本比例不同而對分類算法效果產生的影響,本文在葉子結點上設置如式(11)所示的類標簽計算方法,按照樣本中類的比例對葉子結點標記方法做出改進。
2.3 OFDB算法描述
算法1: OFDB分類算法
Input:dataset,targetattribute,maxDepth,estimators
Output: oblique forests.
(1)forT=1 toestimatorsdo
/*T表示每個決策樹, 隨機森林共有estimators個決策樹*/
(2) call FIT function on randomly sampleddataset;
/*調用算法2, 遞歸地訓練每個決策樹*/
(3) save out-of-bag estimation result ofT;
(4)endfor
算法2: OFDB決策樹結點訓練算法FIT
Input:dataset,targetattribute,maxDepth
Output: oblique decision tree.
(1)ifdatasetis nullthen;
/*數據集為空, 則將當前結點轉化為葉子結點*/
(2) Node convert to leaf;
(3)return0;
(4)endif
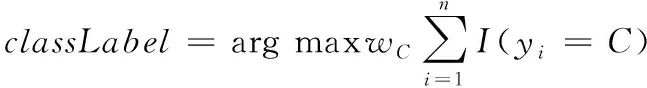
(6)ifNode.depth==maxDepththen
/*達到最大深度, 則將當前結點轉化為葉子結點*/
(7) Node convert to leaf;
(8)return0;
(9)endif
(10)ifthe class of sample is purethen
/*數據集類純粹, 則將當前結點轉化為葉子結點*/
(11) Node convert to leaf;
(12)return0;
(13)endif
(14)fori=1 tondo
/*采用“一對多”的策略, 使算法適用于多分類問題。遍歷n個元組的數據集, 將元組個數最多的類作為正類, 其余作為負類*/
(15)ifX[targetattribute][i]==majority class of Nodethen
(16) X[targetattribute][i]=1;
(17)else
(18) X[targetattibute][i]=0;
(19)endif
(20)endfor
(21) get obliqueSplitHyperplaneof Node fromdataset;
/*按照式(13)的更新規則, 求解式(8)傾斜分裂超平面, 保存為當前結點的分裂超平面*/
(22)fori=1 tondo
/*按照式(10)將當前數據元組按照分裂超平面繼續劃分給左右子樹*/
(23)ifX[i]·splitCriterion≥0then
(24) divide X[i] into left child tree;
(25)else
(26) divide X[i] into right child tree;
(27)endif
(28)endfor
(29) create left child tree and call FIT function;
(30) create right child tree and call FIT function;
步驟1 OFDB算法中每個傾斜決策樹進行訓練子集抽樣,舍棄每個子集中的重復抽樣元組。
步驟2 遞歸地訓練每個傾斜決策樹。如果滿足結束條件,則將當前結點轉化為葉子結點。以加權的多數類賦值給當前結點的classLabel。將當前數據分區作為訓練集,求解出傾斜分裂超平面θTX+θ0=0。 根據求解出的傾斜分裂超平面,計算式(10)obliqueSplitHyperplane·X的取值,將每個元組劃分至左子樹或右子樹中繼續訓練。
步驟3 統計袋外估計結果,返回一個OFDB分類器。
2.4 算法分析與評價
2.4.1 算法正確性分析
對于給定的輸入數據集,OFDB算法首先劃分多個數據子集,分別用于訓練每個傾斜決策樹。對于給定的最大深度與決策樹個數參數,決策樹總會在滿足條件時停止遞歸,并且標記該葉子結點。最終返回一個OFDB分類模型。在每個非葉子結點上保存傾斜分裂超平面θTX+θ0=0。 因此,每個預測元組總能通過傾斜分裂超平面被劃分至子樹中,最終到達葉子結點,返回葉子結點類標號作為該元組的預測值。
2.4.2 時間復雜度分析
假設OFDB算法決策樹個數為e,最大深度為d。訓練決策樹均為滿二叉樹。對于一個深度為m遞歸生成的滿二叉樹,則遞歸時間復雜度為O(d2)。對于一個傾斜森林有e個傾斜決策樹,則循環e次訓練每個決策樹時間復雜度為O(e)。假設數據集樣本個數為n,屬性個數為m,對于每個結點分裂過程,首先遍歷數據分區,判斷是否滿足終止條件,時間復雜度為O(n)求解決策邊界使用梯度下降法,求解梯度方向需要O(mn),再對每個參數進行更新O(m),迭代i次O(i),則其時間復雜度不超過O(nm2i)。將數據分區劃分給左右子樹時間復雜度為O(n)。所以OFDB算法時間復雜度不超過O(ed2nm2i)。
2.4.3 分類性能分析
與RF算法的分裂準則相對比,OFDB算法將一個傾斜分裂超平面θTX+θ0=0作為分裂準則,而前者分裂準則可以表示為在m維的空間中使用超平面0×x1+…+1×xi+…+0×xm-b=0來劃分所有的數據。RF算法分裂準則可表示為垂直于數據集空間中的某個屬性軸的超平面,但是OFDB算法的分裂超平面不必垂直于某個屬性軸,而是相對于RF算法的分裂準則是“傾斜”的,這使得OFDB算法分裂準則可以更適應數據集空間的幾何結構。本文使用“傾斜”一詞表明OFDB算法與RF算法分裂準則的區別。OFDB算法使用分裂超平面的同時也保留決策樹結點分裂的可解釋性。
2.4.4 評價指標
在分類準確性評價方面。以隨機森林的袋外估計結果作為計算評價指標的依據,并使用混淆矩陣統計分類結果并且計算評價指標。Leo Breiman已經證明了隨機森林中袋外估計的無偏性[1]。混淆矩陣見表1。

表1 混淆矩陣
其中TP表示被正確分類為正類的正類樣本個數。FN表示被錯誤分類為負類的正類樣本個數。FP表示被錯誤分類為正類的負類樣本。TN表示被正確分類為負類的負類樣本。本文使用準確率accuracy衡量分類器總體分類性能,使用TPR、FPR、F1-score來衡量分類器對不平衡數據的分類效果。
評價指標計算如式(15)至式(18)
(15)
(16)
(17)
(18)
TPR表示正類中被正確分類為正類的比例,在本文中正類表示少數類。FPR表示被錯誤分到正類樣本中的負類樣本所占比例。F1-score綜合考慮正類與負類的準確率,是評價不平衡數據的良好指標。TPR與F1-score取值越高說明分類器對于少數類的分類性能越優。FPR取值高說明分類器對負類樣本并沒有很好的劃分。
3 實驗結果分析
3.1 實驗數據集
實驗主要分為2個部分:①通過人工數據集驗證OFDB算法的可行性,并將傾斜分裂超平面可視化與RF算法的分裂準則比較;②使用真實數據集橫向對比OFDB算法與RF算法,以分類準確率等評價指標來衡量分類效果。真實數據集名稱、樣本個數、屬性個數以及樣本類分布情況見表2。所有數據集中的元組不含缺失值。在訓練之前,對于數據集中離散的標稱屬性,統一設置虛擬變量。
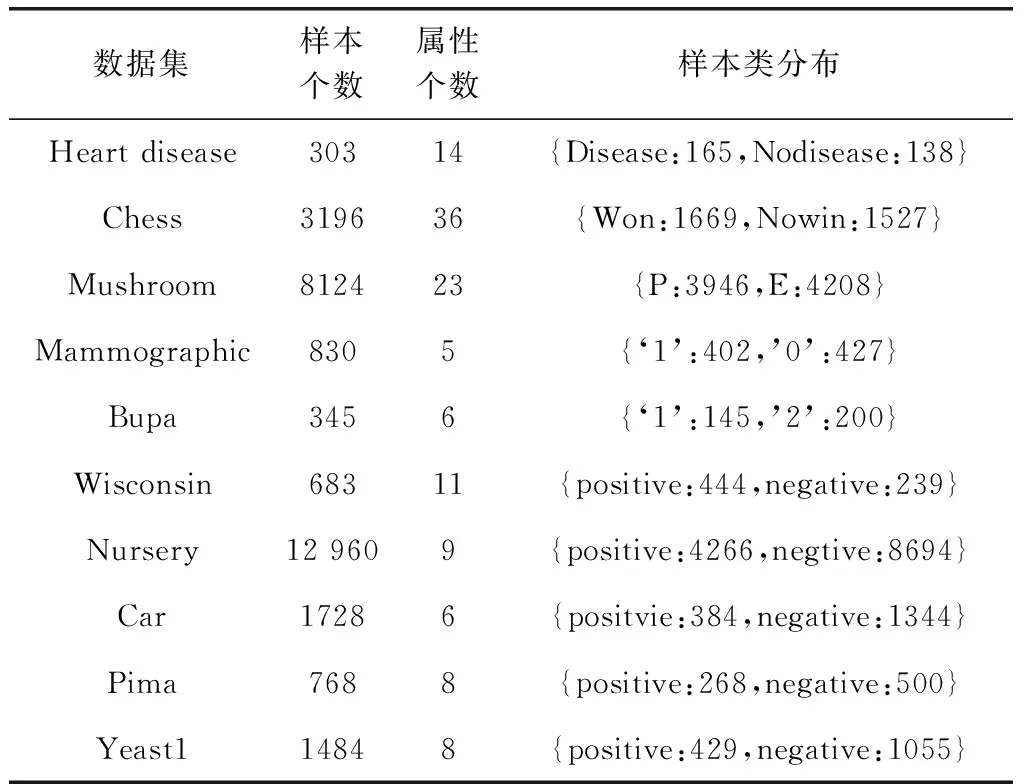
表2 數據集說明
3.2 實驗結果分析
實驗1:OFDB算法與RF算法分裂準則對比實驗
為了將分裂準則可視化,人工數據集維度為2維。使用互相獨立的正態分布隨機生成比例相同的正負類樣本點。實驗直觀表示了OFDB算法與RF算法分類過程的區別。OFDB算法傾斜分裂超平面與RF算法分裂準則如圖1、圖2所示。
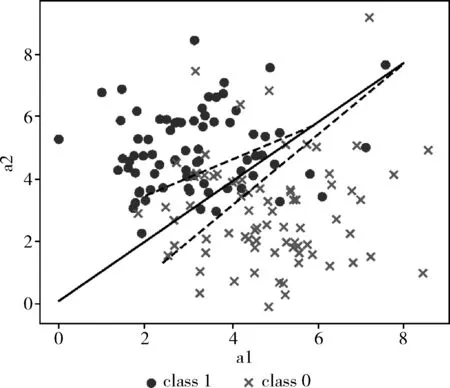
圖1 OFDB算法傾斜分裂超平面
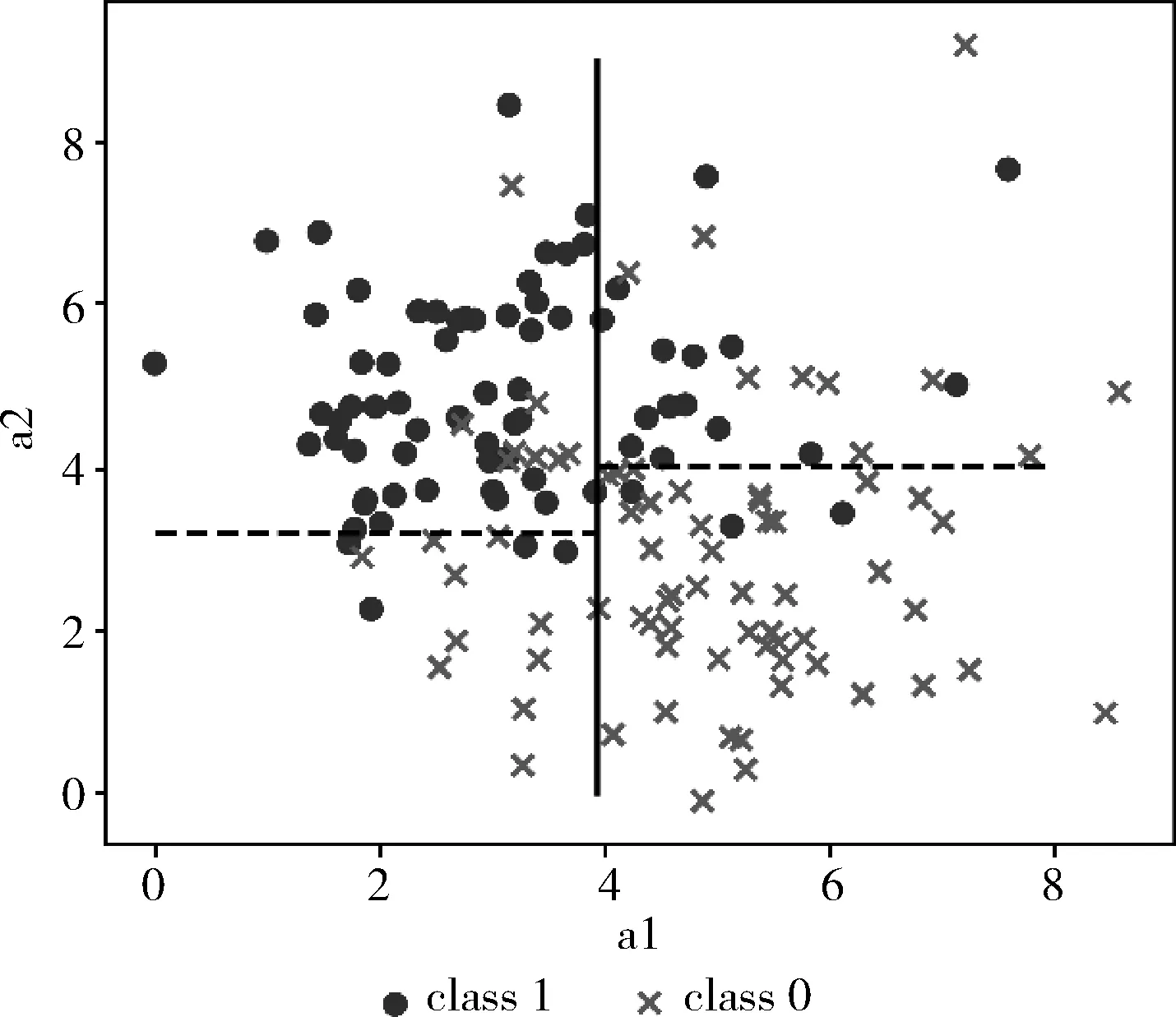
圖2 RF算法分裂準則
圖中不同樣式的點代表兩類不同的元組,直線代表決策樹深度為0的根結點的劃分,每顆決策樹的根結點只有一個。而兩條虛線代表決策樹中深度為1的結點的劃分,深度為1的結點有兩個,分別是根結點的左子樹與右子樹結點。隨著決策樹深度的增加將會有更多的劃分對數據進行分區,最終以每個區域的多數類標記該區域,以此來進行預測。由圖1、圖2可知,RF算法的分裂準則必是垂直于數據集空間中的某個屬性軸的超平面,OFDB算法則是以一個“傾斜”的超平面對數據集進行劃分,RF算法的分裂準則可以由OFDB算法的傾斜分裂超平面所表示出來,因此OFDB算法傾斜分裂超平面可以考慮到RF算法分裂準則的所有分裂情況。
實驗2:OFDB算法與RF算法分類結果對比實驗
實驗2使用準確率與其它不平衡數據評價指標對OFDB算法與RF算法的分類結果進行對比。以分類準確率做為評價指標。最大深度參數maxDepth分別取3,5,7;決策樹個數參數estimators分別取5,10,20。表3至表7
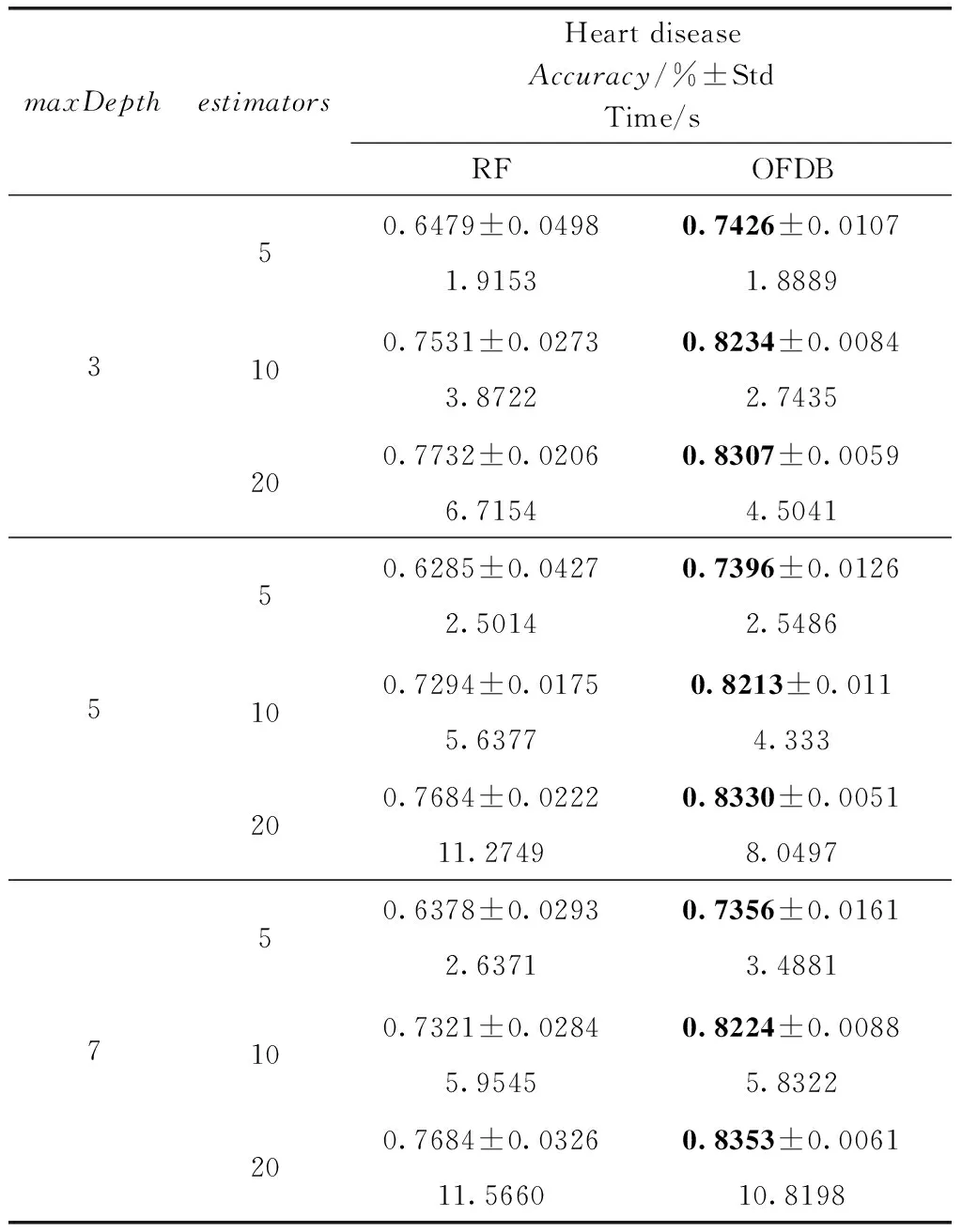
表3 Heart disease數據集分類準確率對比

表4 Chess數據集分類準確率對比
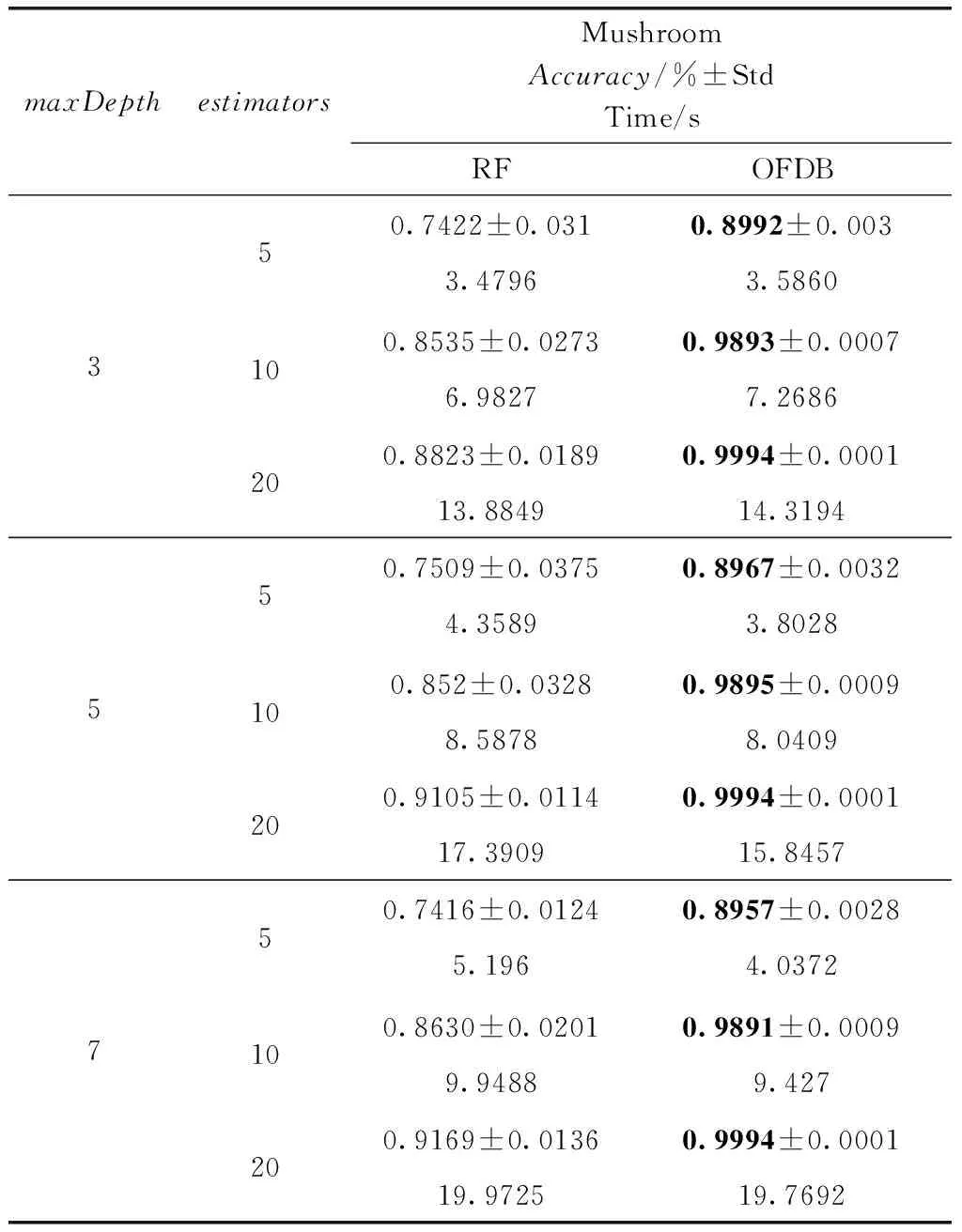
表5 Mushroom數據集分類準確率對比

表6 Mammographic數據集分類準確率對比
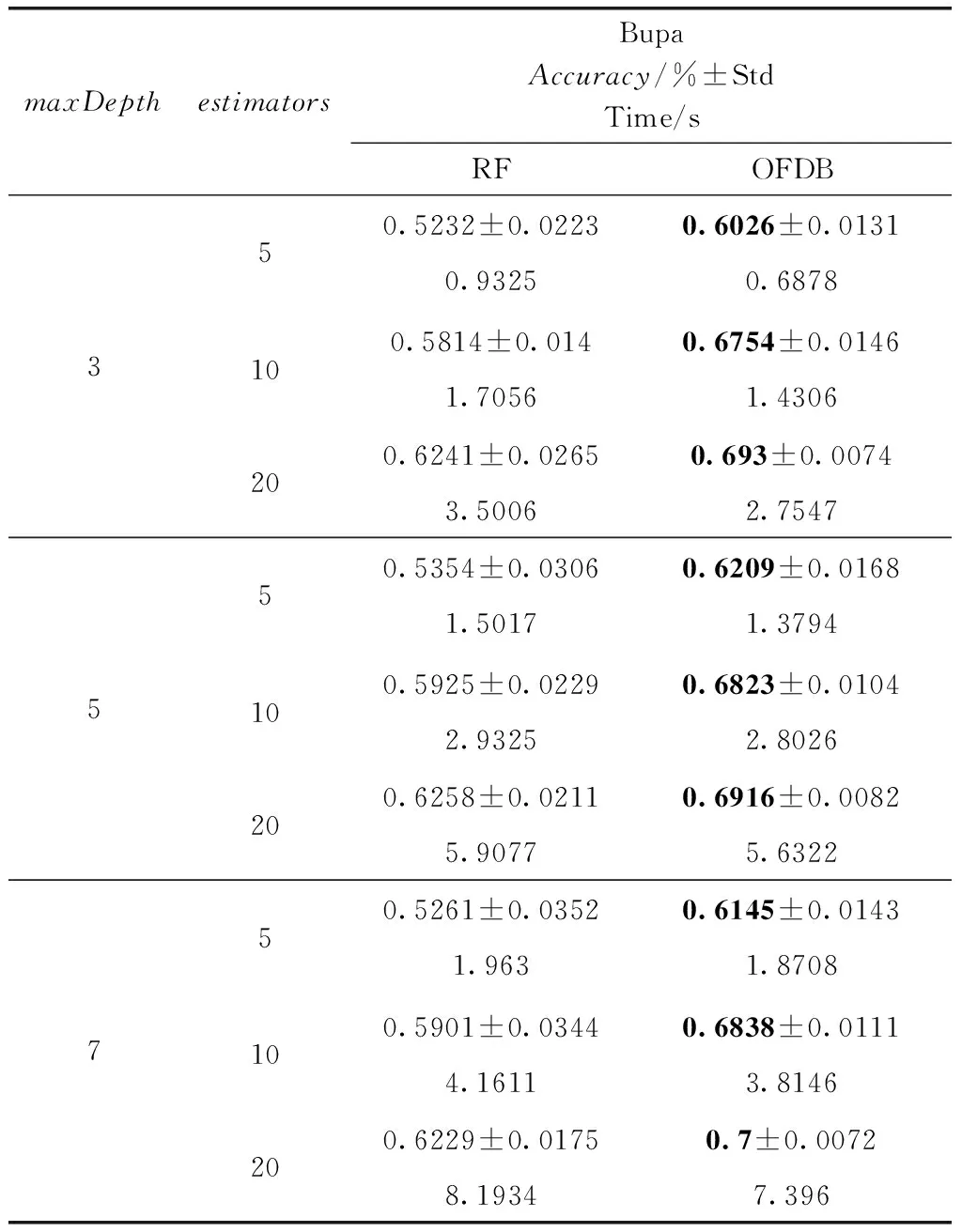
表7 Bupa數據集分類準確率對比
展示5組實驗,分別在5個數據集Heart disease、Chess、Mushroom、Mammographic、Bupa上,使用不同的參數,展示袋外估計分類結果的準確率。其中較優的實驗數據使用粗體標出。為減小隨機數所產生的單次實驗結果不確定性,所以在本次實驗中,實驗結果取10次實驗的平均值,并且計算標準差與運行時間。
觀察表3至表7可以得出,對于Heart disease、Chess、Mushroom、Manmographic、Bupa數據集,OFDB算法分類準確率高于RF算法。隨著estimators的增加,OFDB算法的分類準確率有所提高。然而在estimators大于10后,總體的分類準確率提高較少。對比estimators取值10和20的情況,多出一倍的決策樹個數卻只得到分類準確率0.01左右的提升。隨著參數maxDepth的增加,OFDB算法的分類準確率并沒有明顯的提升。這可能是因為主要的分類工作是在深度較低的結點中完成的,剩余少數樣本OFDB算法難以劃分。對比標準差,OFDB算法明顯具有優勢,分類結果具有較高的穩定性,這是由于使用決策邊界替代了原具有較高隨機性的結點分裂準則。主要體現在候選分裂屬性隨機選取。運行時間方面,OFDB運行時間與RF運行時間相差不大。
為表明OFDB算法相比于RF算法對于少數類分類有更優異的性能,以不平衡數據評價指標TPR、FPR以及F1-score衡量分類效果。如表8所示,針對參數maxDepth取值5,estimators取值10的情況,給出OFDB算法與RF算法在5個不平衡數據集Wisconsin、Nursery、Car、Pima、Yeast1上的對比結果。觀察表8可以得出,對不平衡數據集的分類OFDB算法相比RF算法具有更好的效果。

表8 不平衡數據集上OFDB算法與RF算法不平衡分類指標對比
4 結束語
本文提出一種基于決策邊界的傾斜森林分類算法OFDB。OFDB算法使用傾斜分裂超平面來改進RF算法中的結點分裂過程。針對不平衡數據處理分類問題,使用自適應權重改進葉子結點的類標號。為使算法適用于多類分類問題,在結點分裂過程中采取“一對多”的策略。實驗部分,使用人工數據集直觀對比OFDB算法與RF算法的分裂過程。通過真實數據集的實驗結果顯示,OFDB算法相較于RF算法具有更良好的分類性能,并且對不平衡數據分類能力有所提高。但對于極度不平衡數據集,OFDB算法分類效果仍較差。之后的研究中將側重于提高分類器對于不平衡數據集的分類能力,以及提高分類算法訓練效率。
猜你喜歡
西北民族大學學報(自然科學版)(2021年4期)2021-12-29 02:54:24
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
學生天地(2019年32期)2019-08-25 08:55:22
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級語數英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
