基于MATLAB的醫(yī)學影像數(shù)據(jù)遷移學習的實現(xiàn)
2022-03-03 05:43:38黃夏璇袁師其何寧霞武文韜
醫(yī)學新知 2022年1期
黃夏璇,黃 韜,袁師其,何寧霞,武文韜,呂 軍
1. 暨南大學附屬第一醫(yī)院神經(jīng)內(nèi)科(廣州 510630)
2. 暨南大學附屬第一醫(yī)院臨床研究部(廣州 510630)
3. 西安交通大學公共衛(wèi)生學院(西安 710061)
近年來,基于深度學習的計算機視覺技術(shù)越來越多地應用于臨床影像數(shù)據(jù)的分類和識別。在深度學習和機器學習領(lǐng)域,不論是數(shù)據(jù)還是模型都可進行一定的遷移,尤其是在某些應用場景下,如目標數(shù)據(jù)量較大但標注的數(shù)據(jù)樣本較少時,機器可依靠模型的遷移捕捉到其他數(shù)據(jù)集中與目標數(shù)據(jù)集共享的參數(shù)信息,并將其遷移至目標數(shù)據(jù)集中,進而加強深度學習訓練模型識別圖像的能力[1]。遷移學習(transfer learning)作為一種機器學習方法,可將模型學習到的知識從源領(lǐng)域遷移至另一個目標領(lǐng)域,使得模型可以更好地獲取目標領(lǐng)域的知識。遷移學習的方式包括基于樣本的遷移、基于特征的遷移、基于模型的遷移以及基于關(guān)系的遷移四類。目前應用相對廣泛的是通過源領(lǐng)域的數(shù)據(jù)和目標領(lǐng)域的數(shù)據(jù)空間模型對共同參數(shù)實現(xiàn)知識的遷移,即在已有的數(shù)據(jù)集中把訓練好的數(shù)據(jù)集進行初始化,把結(jié)果遷移到需要學習的數(shù)據(jù)集中,并通過卷積神經(jīng)網(wǎng)絡(luò)(convolutional neural networks,CNN)提取圖像特征(包括顏色或邊緣等)進行訓練,以達到提高識別圖像準確率的目的[2]。MATLAB作為一款科學計算軟件,擁有豐富的數(shù)據(jù)類型和結(jié)構(gòu)、精良的圖形可視化界面以及針對圖像數(shù)據(jù)進行分析等的應用工具。相對于難以實現(xiàn)圖像數(shù)據(jù)準確分析的傳統(tǒng)計算機輔助診斷(computer-aided diagnosis,CAD)[3],基于傳統(tǒng)機器學習方法的MATLAB遷移學習,更易對圖像進行特征提取和自動化分類,從而為醫(yī)學圖像共性提取提供更好的平臺。本研究以具體的圖像數(shù)據(jù)為例,介紹如何使用MATLAB軟件實現(xiàn)遷移學習。
1 資料與方法
1.1 研究對象
本研究以MIMIC公共數(shù)據(jù)庫中的MIMIC-CXR數(shù)據(jù)庫為例,該數(shù)據(jù)庫是由Johnson等于2019年1月發(fā)布的一個包含放射學報告的大型胸部X射線影像公開數(shù)據(jù)集,其不僅將DICOM的影像格式轉(zhuǎn)換為 JPEG格式,還提取了文本報告中的重要信息并轉(zhuǎn)換成結(jié)構(gòu)化的標簽形式,通過NLP算法從影像報告中提取了14個類別標簽[4-6]。本研究選取胸腔積液資料組8 522名患者,其中男性4 477例(52.53%),女性4 045例(47.47%),每例患者均進行了至少一次的X線檢查,共計獲得不同檢查時間的15 620張X線圖像數(shù)據(jù)。為減小數(shù)據(jù)類別預測的偏差,以NegBio和CheXpert 兩個開源工具從報告文本中得到的標簽為依據(jù),從中選取提示胸腔積液陽性(Pleural Effusion)和陰性(Normal)的X線圖像數(shù)據(jù)各500張作為本研究的數(shù)據(jù)樣本。
1.2 實驗環(huán)境
本研究所有實驗均基于Ubuntu20.04位操作系統(tǒng),針對CNN模型的訓練過程,采用以MATLAB語言為主的編程環(huán)境,具體軟件及硬件配置見表1。

表1 軟硬件環(huán)境配置Table 1. Configuration of hardware and software environment
1.3 選擇卷積神經(jīng)網(wǎng)絡(luò)模型
作為深度學習應用的主要算法,CNN是一種融合了卷積計算和深度結(jié)構(gòu)的前饋神經(jīng)網(wǎng)絡(luò)[7]。相較于傳統(tǒng)的機器學習方法,CNN可更好地提取圖像特征,減少人工手動提取分類準確率低的不足[8]。目前使用較多的網(wǎng)絡(luò)結(jié)構(gòu)主要有AlexNet[9](8層)、VGGNet[10](16層)、GooleNet[11](22層)、ResNet[12](152~1000層),多數(shù)模型都是基于它們改進而來。隨著CNN層數(shù)逐漸加深,模型性能和層數(shù)不斷改進和完善,但也出現(xiàn)了訓練誤差增大的退化以及梯度隨著連乘變得不穩(wěn)定的梯度消失現(xiàn)象[13]。為此,ResNet模型利用殘差網(wǎng)絡(luò)引入恒等跳躍鏈接,提高前后兩個殘差塊之間的信息流通,避免網(wǎng)絡(luò)過深引起的退化及梯度消失問題,使訓練網(wǎng)絡(luò)隨著深度的增加達到先減后增的趨勢。因此,本研究以ResNet模型進行演示。表2展示了不同CNN典型模型的主要特點和優(yōu)缺點對比[14]。

表2 CNN典型模型比較Table 2. Comparison of CNN typical models
1.4 加載圖像并讀取數(shù)據(jù)集
本 研 究 使 用 MATLAB 2021a(MathWorks,Natick,MA)軟件對圖像進行預處理,操作流程為:①將所有數(shù)據(jù)集中的灰度圖像轉(zhuǎn)換為RGB圖像;②將圖片尺寸統(tǒng)一轉(zhuǎn)換為224×224×3(ResNet適用的通道數(shù));③讀取全部數(shù)據(jù)集,得到標簽胸腔積液陽性和陰性標簽的數(shù)據(jù)各500張。
1.5 分割數(shù)據(jù)集與建立網(wǎng)絡(luò)
該階段關(guān)鍵步驟在于改進網(wǎng)絡(luò)結(jié)構(gòu):①讀取原始ResNet網(wǎng)絡(luò)模型,通過K折驗證,將數(shù)據(jù)集拆分為10倍進行分析,即將數(shù)據(jù)集均分成10部分,將第一部分作為測試集,其余子集作為訓練集,每次用不同的部分作為測試集重復訓練模型,并計算模型的平均測試準確率作為驗證結(jié)果,用于模型評估;②確定訓練數(shù)據(jù)中需要分類的種類,創(chuàng)建新的網(wǎng)絡(luò)層數(shù),將新的網(wǎng)絡(luò)層中的參數(shù)'Weight Learn Rate Factor'和'Bias Learn Rate Factor'分別設(shè)置為10;③為防止過擬合,創(chuàng)建softmax網(wǎng)絡(luò)層更好地調(diào)整網(wǎng)絡(luò)結(jié)構(gòu);④將批量訓練和測試圖像的大小調(diào)整為與輸入層大小一致,將構(gòu)建的網(wǎng)絡(luò)在深度網(wǎng)絡(luò)設(shè)計器顯示可得到相對應的網(wǎng)絡(luò)結(jié)構(gòu)及其分析結(jié)果。
1.6 訓練網(wǎng)絡(luò)
在ResNet 50網(wǎng)絡(luò)模型構(gòu)建完成后,對網(wǎng)絡(luò)進行模型訓練和參數(shù)設(shè)置,并用訓練集對網(wǎng)絡(luò)進行訓練。根據(jù)訓練結(jié)果進行微調(diào),得到如下參數(shù):學習率為1.00e-04,最小批次為25,最大訓練回合數(shù)為64。并對數(shù)據(jù)進行增強,具體措施包括批量處理圖像,以50%的機率隨機對圖像從水平和垂直方向上進行縮放、翻轉(zhuǎn)、裁剪和平移,增加訓練數(shù)據(jù)的多樣性以及訓練模型的識別和泛化能力。此次訓練迭代次數(shù)為250次,訓練完成時間為2min 38s,訓練的準確和損失過程如圖1所示。
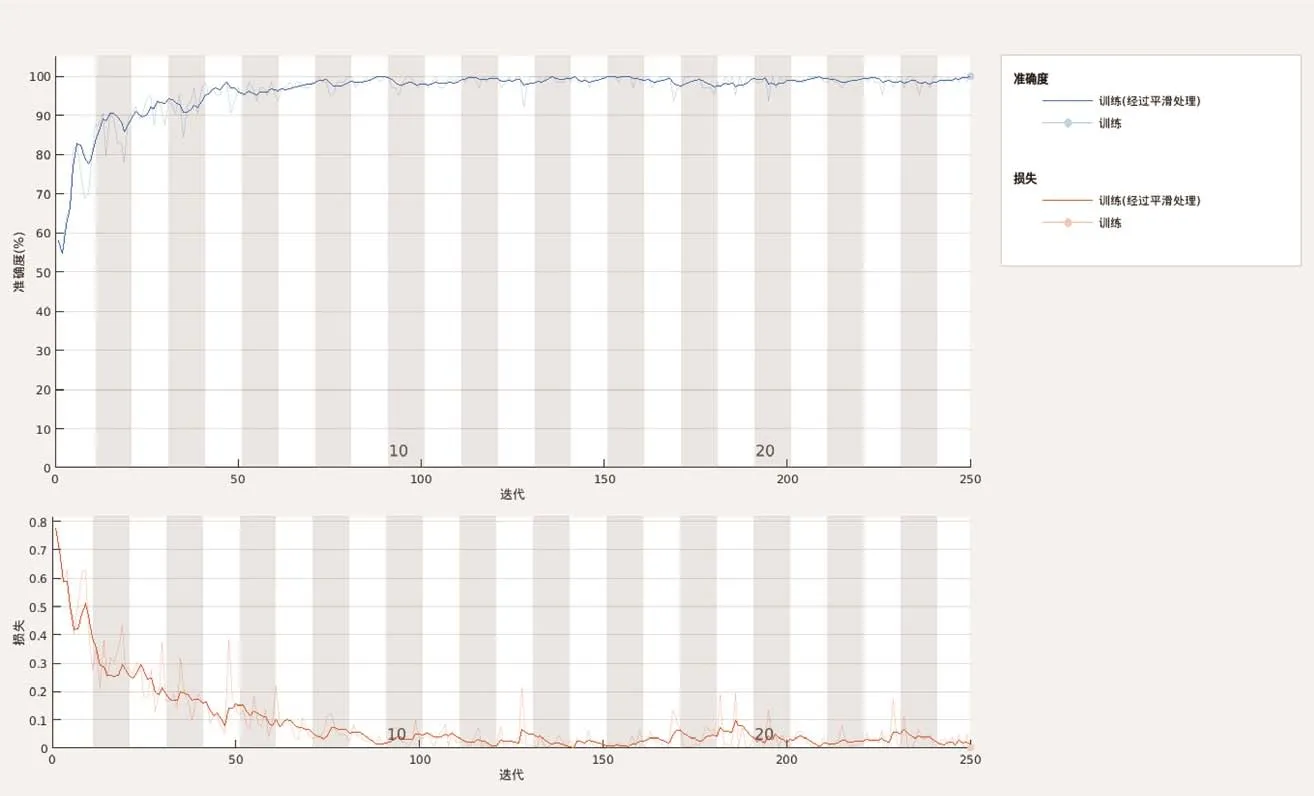
圖1 迭代次數(shù)250次的訓練過程Figure 1. Training progress with 250 iterations
2 結(jié)果
2.1 數(shù)據(jù)集
本研究使用的胸腔積液影像測試集和訓練集呈均勻分布,陽性和陰性各500張,利用K折交叉驗證的方法獲得訓練集和測試集。如圖1所示,部分準確率曲線圖在訓練完成時達到80%,損失率則明顯下降至20%以下。在迭代次數(shù)為250次的訓練中最高準確率可達100%,耗時約2min 38s,訓練時間與計算機性能密切相關(guān)。表3對比了不同迭代次數(shù)訓練的結(jié)果,迭代次數(shù)較少的訓練相對效果更理想,準確率高且耗時少。本研究還使用Grad-CAM代碼生成熱圖,使模型提取的胸腔積液陽性標簽X線圖像中的重要特征區(qū)域可視化,以評估胸腔積液的陰性和陽性,并隨機抽取部分預測結(jié)果進行驗證,如圖2和圖3所示。
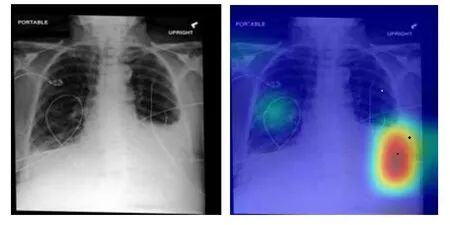
圖2 胸腔積液的Grad-CAM和原X線胸片F(xiàn)igure2. Grad-CAM heatmaps source and X-ray chest radiograph of pleural effusion
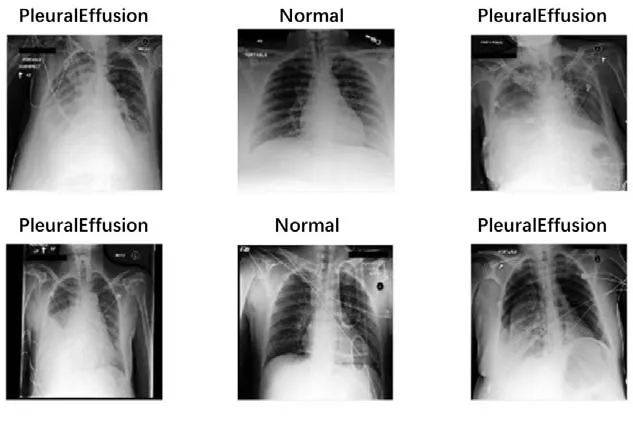
圖3 胸腔積液部分預測結(jié)果Figure 3. Some predicted results of pleural effusion

表3 不同迭代次數(shù)結(jié)果Table 3. Results of different iterations
2.2 混淆矩陣分析
混淆矩陣可以更好地衡量算法的性能,并且提供了精度和召回性能的角度,適用于本研究均勻分布的測試數(shù)據(jù)集,由迭代250次最佳訓練結(jié)果繪制形成的混淆矩陣如圖4所示。縱坐標以真實標簽的角度預測分類結(jié)果,橫坐標以分類器的角度預測分類結(jié)果。以縱坐標為例,在真實標簽為陰性(Normal)的所有圖像中,有457個圖像被正確預測為陰性(Normal),43個圖像被錯誤預測為陽性(Pleural Effusion),因此真實標簽為陰性的圖像中被正確預測的比例為91.4%,即該診斷性實驗的特異度為91.4%。同理,在真實標簽為陽性的圖像中被正確預測的比例是84.8%,即本次實驗的敏感度為84.8%。通過計算,綠色對角線下獲得的全部真陽性和真陰性標簽預測結(jié)果占所有圖像樣本的比例為88.1%,即本實驗分類準確率(ACC)為88.1%。
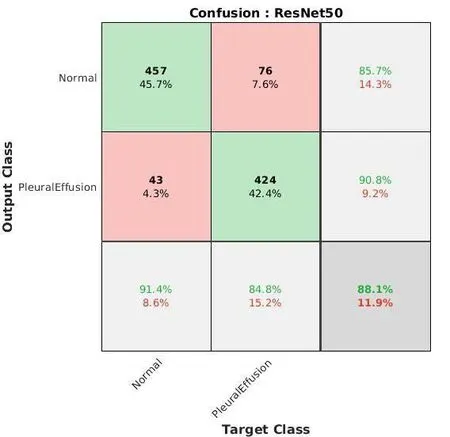
圖4 混淆矩陣Figure 4. The confusion matrix
2.3 AUC計算
本研究采用10折交叉驗證評價分類模型的性能,使用曲線下面積(the area under the ROC curve,AUC)為評價指標[15],以假正類率(false positive rate,F(xiàn)PR)為橫軸,真正類率(true positive rate,TPR)為縱軸,繪制得出ROC曲線。AUC 值越大,代表模型的預測結(jié)果和真實情況越接近,模型性能越好。本次模型訓練獲得的影像數(shù)據(jù)遷移學習預測結(jié)果的AUC值為93.53%(圖5)。
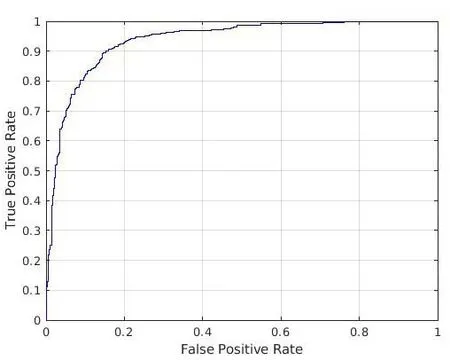
圖5 訓練結(jié)果AUC圖Figure 5. The AUC diagram of training results
3 討論
胸腔積液作為臨床上常見的胸膜病變,最常見的病因是結(jié)核和腫瘤。近年,隨著肺癌發(fā)病率的逐年上升,惡性胸腔積液病例也日趨增多。由于胸腔積液發(fā)展迅速且持續(xù)存在,患者常因大量積液的壓迫出現(xiàn)嚴重呼吸困難,甚至死亡,故早期診斷胸腔積液對患者的治療和預后十分重要。本研究隨機抽取MIMIC-CXR數(shù)據(jù)庫中陽性、陰性胸腔積液影像數(shù)據(jù)各500例作為數(shù)據(jù)集,使用遷移學習方法,以ResNet模型為基礎(chǔ)實現(xiàn)胸腔積液分類的早期識別。
數(shù)據(jù)集包含的大量胸腔積液影像具有肺葉與胸壁間的積液程度、密度增高影、縱隔移位和肋間隙增寬等特征,有助于在臨床上快速診斷胸腔積液。本研究基于ResNet模型提取了上述特征,對胸腔積液原始圖像進行重復多次的訓練,并經(jīng)過數(shù)據(jù)增強后得到了AUC為93.53%的結(jié)果,表明ResNet網(wǎng)絡(luò)模型具有良好的性能。有研究也發(fā)現(xiàn),利用ResNet網(wǎng)絡(luò)模型與遷移學習的混合模式,可改善圖像分類的準確性和魯棒性[16]。
綜上所述,基于模型的遷移學習方法實現(xiàn)了模型構(gòu)建和數(shù)據(jù)訓練的有效結(jié)合和增強,不僅優(yōu)化了模型,避免了因標記樣本過少可能導致的過擬合問題,且能得到較好的預測效果。因此,基于神經(jīng)網(wǎng)絡(luò)模型的醫(yī)學影像訓練遷移學習方法可為臨床醫(yī)生早期診斷胸腔積液提供一定的依據(jù)。
本研究存在一定局限,如實驗訓練時僅對胸腔積液進行了二分類,在圖像處理上對同一病灶多個圖像之間的相關(guān)性處理尚有不足,下一步可將二分類延伸至多分類多特征,實現(xiàn)對遷移學習的拓展和深入。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
中學生數(shù)理化·七年級數(shù)學人教版(2019年4期)2019-05-20 10:06:32
中學生數(shù)理化·七年級數(shù)學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
