基于DRAM犧牲Cache的異構內存頁遷移機制
2022-03-09 05:41:56裴頌文錢藝幻葉笑春劉海坤孔令和
計算機研究與發展 2022年3期
裴頌文 錢藝幻 葉笑春 劉海坤 孔令和
1(上海理工大學光電信息與計算機工程學院 上海 200093)
2(計算機體系結構國家重點實驗室(中國科學院計算技術研究所) 北京 100190)
3(華中科技大學計算機科學與技術學院 武漢 430074)
4(上海交通大學計算機科學與工程系 上海 200240)
在大數據技術快速發展的當下,傳統的隨機動態存取存儲器(dynamic random access memory, DRAM)逐漸暴露出其局限性,如存儲密度小、帶寬有限、能耗大等[1-3],揭示了傳統DRAM無法滿足越來越大的內存需求.因此,為了解決這一問題,近年來涌現的非易失性存儲器(non-volatile memory, NVM)[4-7]被廣泛關注,并與DRAM組成異構內存系統[8-11],大量研究圍繞非易失性內存和異構內存展開[12-15].NVM擁有比DRAM更大的存儲密度,無靜態能耗,即不需要反復刷新保存數據,從而成為構建主存的理想存儲設備.
然而,與傳統DRAM相比,NVM同樣具有寫操作時延高、耐久性差、寫操作能耗高等缺點.以相位存儲器(phase change memory, PCM)為例,相比簡單的電荷移動,PCM需要更多的能量來改變相變材料(基硫族化合物)內部的原子結構.另外,PCM的寫入時延大約是DRAM寫入時延的10倍.更詳細的DRAM與部分NVM的特性對比如表1所示.因此,當DRAM和NVM構成異構內存時,應將訪問頻率更高的“熱”內存頁存放在DRAM中,而將“冷”內存頁存放在NVM中,如此,系統便可以同時兼備NVM和DRAM兩者的性能優勢.但這同時又衍生出了新的問題,即如何進行內存頁面的放置遷移操作.
近年來,許多相關研究都試圖解決在NVM和DRAM之間進行內存頁遷移的問題,如多級隊列替換算法(multi-queue replacement algorithm, MQRA)[16]、CLOCK-DWF[17]、基于雙向散列鏈表的頁面遷移機制(THMigrator)[18]等.雖然它們在一定程度上優化了異構內存系統帶來的問題,但也造成了冗余的頁面遷移操作,從而降低系統的性能.由于不準確的遷移執行參數與預測機制,進行遷移的頁面實際上可能不夠“熱”,而有些頁面則可能會過早地被遷回NVM,這將導致2種設備之間頻繁地往返遷移.同時頁面遷移造成的不可避免的操作和資源消耗,例如頁面的重新分配、頁表的更新、帶寬消耗等,都將帶來巨大的系統開銷.因此,不必要的遷移所產生的代價可能反而超過了頁面遷移帶來的收益.此外,NVM的大量數據寫入操作也縮短了設備的使用壽命,并增加了訪問時延.
我們通過實驗觀察到,當應用程序對海量數據進行處理時,主存DRAM中被逐出的“冷”頁,可能會在短時間內再次變“熱”.在這種情況下,頁面將進行重復的遷移操作,這將會增加NVM的寫入次數且消耗不必要的系統資源.
定義1.重復遷移.對任意內存頁面x和遷移操作序列M=(M1,M2,…,Mi,…,Mn),若當前執行的遷移操作Mi使得x的遷移總次數n≥2,則遷移操作Mi為x執行了一次重復遷移.
定義2.冗余遷移.對任意內存頁面x和遷移操作序列M=(M1,M2,…,Mi,…,Mn),若當前執行的遷移操作Mi使得x的遷移總次數n≥2,且對頁面x的第i次遷移與第i-1次遷移之間的時間間隔t≤σ,則遷移操作Mi為x執行了冗余遷移.
其中σ是較小的時間閾值,由不同的內存器件和內存層次結構的差異而定.

Fig. 1 The percentage of re-migration of CoinMigrator, MQRA and THMigrator圖1 CoinMigrator/MQRA/THMigrator的重復 遷移操作占比
如圖1所示,以CoinMigrator,MQRA,THMigrator為例,對于基準測試bzip2,cactusADM,omnetpp,sjeng,與總的遷移次數相比,平均有72.50%,66.33%,69.050%,69.11%的遷移操作為重復遷移.此外,由于遷移參數的主觀人為設定,一些研究中的頁面“冷”“熱”程度判斷機制可能無法準確判斷并預測一個頁面是否真的“熱”.同時,被判定為“熱”頁的頁面可能不會立即執行遷移,由于前一個頁面未完成遷移操作而導致當前頁面需要等待,在這種情況下,在當前頁面完成遷移時,它可能不會再與之前一樣“熱”,并且由于“冷”“熱”判斷標準的不同被對應遷回NVM的頁面可能比遷移到DRAM的頁面更“熱”.這樣的頁面遷移是不必要的,它們不僅會降低系統性能,同時也增加了系統資源的消耗.
為了解決這些問題,本文提出了一種基于DRAM的犧牲Cache(DRAM-based victim Cache, DVC)的異構內存頁遷移機制(victim Cache for page migration on hybrid main memory system, VC-HMM).當執行頁面遷回時,主存DRAM中的“冷”頁將遷移到DVC中,而不是立即寫回PCM.在“冷”頁再次變“冷”之后,遷移控制器將判斷該頁是否為臟頁.由于PCM仍保留原始頁面數據,故若頁面不臟,則不需要寫回.VC-HMM還可以根據遷移收益情況自主地調整遷移參數,從而自適應不同的工作負載.本文工作的主要貢獻有3個方面:
1) 提出了一種基于DRAM犧牲Cache的異構存儲系統結構來消除冗余遷移.
2) 提出了適用于VC-HMM的基于雙向散列鏈表的頁面遷移機制進行更有效的遷移操作.
3) 提出了在不同工作負載下自適應更新遷移執行參數的方案,實現合理的遷移閾值控制.
實驗結果表明:與其他遷移策略(CoinMigrator,MQRA,THMigrator)相比,VC-HMM平均減少了至少62.97%的PCM寫操作次數,22.72%的平均訪問時延,38.37%的重復遷移操作,以及3.40%的系統能耗.
1 相關工作
由于NVM難以作為DRAM的直接代替,異構內存系統的提出給內存問題提供了解決的方案.而為了兼具NVM與DRAM兩者的性能優勢,基于異構存儲系統的頁面遷移機制研究顯得尤為重要.本節將首先介紹一些以往有關異構內存頁面遷移機制研究的相關工作,并分析它們的優點與不足.
由于NVM在進行寫操作時具有遠大于DRAM的訪問時延和能量消耗,許多研究著眼于如何減少NVM的寫入操作來提升系統性能.Lee等人[17]提出了Clock-DWF算法將寫請求頻繁的頁面遷移到DRAM中.對于一個進入內存的新頁面,當訪問為寫操作時,該頁面將直接載入DRAM中,反之放置于NVM中.對于在NVM中的頁面,一旦被寫請求命中則該頁面將遷移到DRAM中.如果DRAM容量已滿,Clock-DWF則會選擇寫請求命中次數最少或最長時間沒有被訪問的頁面作為“冷”頁逐出DRAM.該機制考慮到了寫操作對NVM的影響,但遷移的評判標準過于簡單,不能正確地判斷“冷”“熱”度從而增加遷移的次數.Kim等人[19]提出了基于自適應分類(adaptive-classification clock)的遷移機制.通過歷史的訪問模式,每個頁面將被設定為不同的狀態來判斷頁面是否為讀/寫密集以及是否執行遷移操作,減少了不必要的遷移.
除了以上通過監控頁面訪問來執行遷移的機制外,使用隊列結構存儲頁面信息的策略也在以往的研究中廣泛使用.Seok等人[20]提出了以4個LRU隊列為基礎的遷移模型.所有的頁面被分為4個類別:NVM寫頻繁頁面、NVM讀頻繁頁面、DRAM寫頻繁頁面以及DRAM讀頻繁頁面,并且根據最近的訪問時間進行有序排列.根據過去的訪問信息,模型能夠預測未來訪問的類型,更加準確地進行頁面的遷移,以減少NVM的寫操作.Zhou等人[16]提出了多級隊列遷移機制(MQMigrator)來提高遷移頁面判斷的準確性.多級隊列遷移機制的實現基于3個頁面屬性,即最小生存周期、基于訪問頻率的優先級以及訪問時間.每一個頁面都將基于“冷”“熱”度與生存周期來更新節點信息并移動到對應的隊列中.通過多個LRU隊列的維護,系統能夠更加準確地選擇最“熱”和最“冷”的頁面并且監控所有的頁面狀態,但維護成本和時間復雜度較高.Tan等人[21]提出了一種基于歷史訪問信息的統一“冷”“熱”度計算方式,相較于大部分研究中使用訪問次數作為“冷”“熱”度度量標準的方法,統一的計算方式能更加公平地表現頁面的訪問狀態.同時,遷移的閾值也能夠根據每次遷移的收益來進行更新.隨后,Tan等人[22]又進一步提出減少NVM寫入操作的機制.當一個臟頁寫回NVM時,只需要寫回以行大小為單位的數據而不用寫回整個頁面.該機制減少了冗余寫回操作的同時延長了部分NVM存儲單元的使用壽命.
除了減少NVM的寫入操作和提高“熱”頁的選擇準確性之外,一些研究也提供了其他的遷移思路.Ryoo等人[23]提出了一種基于粒度感知的遷移機制,遷移頁面的粒度大小將根據不同工作負載的不同訪問模式進行更新,減少不必要的遷移.為了解決遷移能耗的問題,Zhan等人[24]提出了一種基于能耗感知的遷移機制.該機制將權衡頁面繼續留存在NVM中和遷移到DRAM中2種情況的能量代價,為系統節約不必要的遷移能耗.
在內存系統結構的研究中,Guo等人[25]提出了新的內存系統結構DR-HBM,減少對NVM的寫入.在該結構中,DRAM被分為2個部分:容量較小的DRAM Cache與容量較大的DRAM主存.Cache僅僅緩存源于NVM的頁面并且按照頁面狀態的不同,在遷回時不用寫回NVM而暫時保存在DRAM中以便再次訪問.在Cache中第1次未命中的頁面不會立刻執行緩存直到再一次被請求.這樣的結構設計減少了NVM的寫入并且節約了遷移所占用的帶寬.Islam等人[26]提出了一種即時遷移的策略,通過在內存系統中添加新的硬件設備實現實時的頁面遷移而不需要中斷訪問,為系統減少了訪問的時延.
以上所有的遷移策略都對異構內存的頁面遷移進行了逐步的優化升級,但同時也具有一定的局限性.大多數的遷移策略只關注遷移的頁面,很少關注仍留存在DRAM或在遷移隊列中的頁面.通常在一個遷移過程中,一對“冷”“熱”頁面將會交替遷移,從DRAM中選中的“冷”頁將被NVM中的“熱”頁代替以節約DRAM的存儲空間,但是由于不公平的“冷”“熱”度評價機制,可能會存在“冷”頁面比“熱”頁面更“熱”的情況,或“冷”頁面被逐出后在短時間內再次變“熱”.另外,由于頁面達到遷移條件后可能不會立即執行遷移,所以當完成遷移時,當前頁面可能不會與之前一樣“熱”,甚至比在它之后執行遷移的頁面更加“冷”.在進行頁面逐出遷回時,從DRAM遷移回NVM的頁面都需要進行寫回操作,但是對于讀頻繁頁面來說,頁面中的數據可能并沒有經過修改,重新寫回NVM將增加NVM的寫操作且縮短NVM設備的使用壽命.此外,目前存在的大部分遷移策略沒有關注分析算法的時間復雜度,這也將產生額外的系統消耗.
為了進一步消除海量大數據處理帶來的冗余頁面遷移操作,減少PCM寫入次數,降低訪問時延并提高系統性能,本文進而通過增加新的設備并改進以往基于雙向散列鏈表的遷移算法,提出了基于DRAM犧牲Cache的異構內存頁遷移機制.
2 基于犧牲Cache的異構內存頁遷移機制
在異構內存系統中,由于NVM寫入操作表現出的低性能問題,在訪問速度較慢的NVM和訪問速度較快的DRAM之間進行內存頁面遷移顯得尤為重要.針對訪問時延較大的PCM,為了消除不必要的遷移操作,減少PCM的寫入并縮短訪問的時延,本文提出了VC-HMM,其中包括3個部分:基于DVC(DRAM-based victim Cache)的異構內存系統結構、適用于VC-HMM的頁面遷移策略以及遷移條件在不同工作負載下的自適應算法.
2.1 基于DRAM犧牲Cache的異構內存系統結構
圖2展示了VC-HMM的整體結構.與傳統的內存結構不同的是在DRAM與PCM之間添加了一個小容量的Cache作為DRAM主存部分的犧牲Cache,犧牲Cache由隨機動態存儲器DRAM構成,并用來存儲從主存DRAM中被逐出的“冷”頁.DVC使用訪問速度較快且頁面替換便利的直接映射.與垂直結構的異構內存系統中使用的DRAM Cache類似,DVC中的每一頁都有一個1 b的臟頁標志來標記頁面是否被修改.當DRAM逐出頁面時,將根據頁面的物理地址存儲在Cache對應的塊中.如果存儲時產生沖突,則原本在塊中的頁面將被遷回PCM.由于在Cache中的頁面原本就是從DRAM中淘汰的“冷”頁,所以就算沖突后被直接寫回也能一定程度上降低再次被遷移的概率.
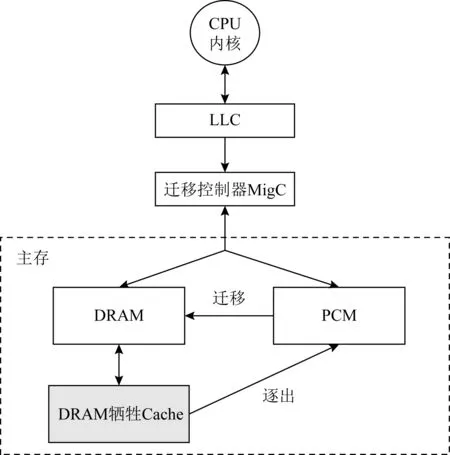
Fig. 2 DRAM-based victim Cache on hybrid main memory architecture圖2 基于DRAM犧牲Cache的異構內存系統結構
當一個頁面被判斷為“熱”頁時,遷移控制器(migration controller, MigC)將執行遷移操作,從PCM遷移的頁面將被拷貝到DRAM的空頁框中,而PCM將繼續保留此頁的數據以便將來的遷回寫入.通過這種方法,讀操作密集的頁面即使經歷了遷移和遷回也不必寫回PCM,減少了PCM的寫操作.為了實現PCM中原數據的保留,在MigC中添加了用來監視遷移頁面狀態的遷移頁面列表(migrated page list, MPL)用于判斷所請求的頁面的位置.如果所請求的頁面已經遷移到DRAM中,則MigC將重映射目的地址使請求進行正確訪問;而如果所請求頁面經過二次遷移存在于DVC中,請求將通過原本的目的地址在犧牲Cache中查找.MPL會同時通過記錄遷移的頁面是否進行過寫操作,從而在最后逐出DVC時進行寫回判斷,只有臟頁面需要進行寫回,對于其余的頁面只需要刪除相關的節點信息即可.
遷移控制器MigC基于THMigrator進行了改進.在THMigrator遷移機制中,頁面節點的記錄排序通過雙向散列鏈表來完成.雙向散列鏈表的結構能夠直接快速的訪問每個節點并完成增刪改查的工作,這大大降低了算法的復雜度,加快了遷移的速度.每當有頁面被訪問時,該頁的相關信息將被記錄為節點插入對應表的表頭,當表中頁面再一次被訪問時,該節點將重新被插入表頭,即按照最近最少使用遞減排序.通過這種排列方式進行頁面搜索時能夠把搜索范圍控制在較小的區域內.另外,雙向散列鏈表的結構能夠使使用更加頻繁的頁面更早的執行遷移,而不是以達到遷移標準的時間來作為遷移準則,這將減少不必要的遷移次數.例如,頁面A比頁面B先達到遷移閾值進入候選遷移列表(migration candidate list, MCL),但是頁面A此后再也沒有被訪問到,這時頁面B被頻繁使用,則MCL將把頁面B的記錄節點放在表頭,從而比頁面A更快地進行遷移.
在VC-HMM中雙向散列鏈表結構依舊被使用在頁面排列中.為了更好地適應DVC的結構,在遷移控制器中設置了3個雙向散列鏈表:PCM頁面列表(PCM page list, PPL)、候選遷移列表(MCL)以及遷移頁面列表(MPL).PPL記錄在PCM中的頁面訪問情況,PPL與MCL中的節點結構如表2所示.PPL記錄PCM中頁面的“冷”“熱”程度、頁面編號以及生存周期.內存中所有的頁面將根據其物理地址計算得出一個唯一的頁號作為在表中的索引,MigC能夠根據頁號直接訪問頁面的信息而不需要遍歷查找.當一個在PCM中的頁面首次被訪問時,MigC將該頁面的信息初始化并插入PPL的表頭,且每次訪問都會將之重新插入表頭.“冷”“熱”程度將根據訪問的次數逐次遞增,生存周期也將隨著每一次的訪問被重置.生存周期用于控制一個頁面存在于列表中的時間,如果一個頁面長時間不被訪問,則當生存周期用盡,該頁面節點將被刪除.當PPL中的頁面達到遷移閾值時,該頁面節點將被插入遷移候選列表MCL的表頭,MCL將在頁面下一次被訪問時執行遷移.當有遷移還未完成時,MCL也能夠將頁面按照“冷”“熱”程度排序使更“熱”的頁面優先遷移.和PPL相同,在MCL中的頁面也將根據訪問情況更新節點信息,并且按順序執行遷移.每次有請求進入內存時,MigC都將檢查是否有頁面達到遷移閾值或超過生命周期,超過生命周期的頁面將被作為“冷”頁從列表中刪除以減少冗余的遷移操作.

Table 2 Page Node Structure of PPL and MCL表2 PCM頁面列表與候選遷移列表的頁面節點結構

Fig. 3 Migration framework for VC-HMM圖3 VC-HMM遷移框架
執行了遷移而進入DRAM的頁面將被作為新的節點插入遷移頁面列表(MPL)的表頭,并刪除在MCL中的舊節點,MPL中的節點結構如表3所示.MPL在PPL和MCL的基礎上記錄更多的頁面信息幫助遷移機制的實現,1b標簽參數IsInDRAM記錄了頁面存在的位置,頁面地址的映射被記錄用于請求的正確訪問,另外MPL將記錄頁面在DRAM中的讀寫操作次數來幫助遷移參數的動態自適應.MPL也將隨著頁面的訪問更新節點從而進行排序.當進行“冷”頁判斷時,MigC將逆序遍歷MPL從而查找需要進行遷移的“冷”頁.

Table 3 Page Node Structure of MPL表3 遷移頁面列表的頁面節點結構
2.2 頁面遷移與訪問
VC-HMM的遷移框架如圖3所示,具體遷移步驟為:
① MigC判斷所訪問內存頁是否存在于某個表中.如果在表中,則更新節點信息并將該節點置于表頭;如果不在表中,將頁面節點初始化并插入PCM頁面列表PPL的表頭.
② 如果所訪問頁面節點在遷移頁面列表MPL中,則根據標志位判斷該頁在DRAM還是DVC中,并執行地址重映射.如果所訪問頁面節點在候選遷移列表MCL中,則檢查是否有遷移正在進行,若有遷徙正在執行則等待當前遷移完成否則進行遷移操作.如果所訪問頁面節點在PPL中,則判斷是否達到遷移閾值,若達到遷移閾值則將節點插入MCL表頭.
③ 在MCL中按順序進行遷移,將該頁復制到DRAM的空頁框中,將該頁在MCL中的節點信息更新到MPL中并刪除原節點,初始化新節點信息并置為表頭.
④ 在MPL中從后往前檢索是否有滿足遷出條件的DRAM頁面,若有滿足遷出條件的DRAM頁面,檢查是否有DRAM到DVC的遷出操作正在進行,若沒有正在進行的遷出操作,則進行遷移操作并更新MPL中對應節點信息,將對應DRAM頁面重新置為空.若當前有遷移操作正在進行,則等待當前遷移操作結束.
⑤ 在MPL中從后往前檢索是否有滿足遷出條件的DVC頁面,若有滿足遷出條件的DVC頁面,檢查是否有DVC到PCM的頁面逐出正在進行,若當前有遷移操作正在進行,則等待當前逐出結束.若沒有正在進行的遷移操作,則通過MPL中該節點記錄的讀寫情況判斷是否需要寫回PCM中,若不需要寫回PCM中,則直接刪除節點.最后根據該頁面在DRAM中的讀寫情況計算遷移收益,若收益為正,則更新遷移參數使頁面更容易遷入DRAM且頁面的生命周期變長;若收益為負,則更新遷移條件使頁面更難遷入DRAM且頁面的生命周期變短.
⑥ 檢查PPL和MCL是否有超過生命周期的頁面節點,將之逐出.
遷移流程框圖如圖4所示:
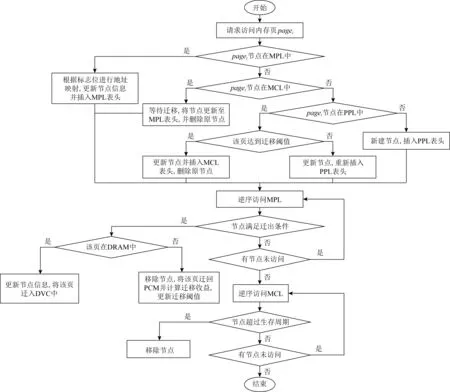
Fig. 4 Process of migration圖4 遷移流程
頁面的“冷”“熱”程度根據訪問次數遞增.遷移時,MigC將為遷移的頁面尋找DRAM中的空頁框,如果沒有可用的空頁框,MigC將在MPL中逆序查找并逐出最“冷”的頁面到DVC中.基于DRAM犧牲Cache的內存頁遷移機制的偽代碼實現方法如算法1所示:
算法1.內存頁面遷移算法.
輸入:當前訪問頁面的頁號pagei、頁面所在內存設備通道編號ChannelNumber.
① 初始化PPL,MCL,MPL,Threshold,currentTime;
②Request(pagei);
③ ifIsLocatedInPPL(pagei) then
④UpdatePPL(pagei);/*更新頁面的“冷”“熱”程度值并重置生命周期*/
⑤MoveToHead(pagei);/*將該頁節點置為表頭*/
⑥ ifpagei→value>Thresholdthen
/*“冷”“熱”程度值達到閾值則插入候選遷移列表表頭*/
⑦InsertMCL(pagei);
⑧RemovePPL(pagei);
⑨ end if
⑩ end if
/*在候選遷移列表中且沒有超過生命周期則進行遷移*/
/*被訪問頁面位于DRAM中*/
&&!IsLocatedInMPL(pagei) then
與遷移操作僅針對當前所訪問的頁面不同,遷回和逐出操作針對每一個完成遷移的頁面,可能在每一個時鐘周期中發生.MigC將在遷移判斷操作結束之后分別查看MPL和MCL列表.在MCL中通過從后往前逆序遍歷查看各頁面節點是否已超過生命周期,超過生命周期的節點將被直接刪除.類似地,在MPL中逆序查找需要遷移的DRAM和DVC“冷”頁,并進行遷移和遷回操作,隨后針對遷回PCM的頁面進行遷移收益核算.內存頁面逐出的偽代碼實現方法如算法2所示.通過MPL執行的逐出判斷將在分別尋找到滿足要求的一個DRAM和DVC頁面后結束本次遍歷.由于逐出操作面向的對象為“冷”頁,故本算法中僅將生命周期作為判斷“冷”“熱”程度的標準以簡化算法的執行.
當所訪問的頁面已經完成遷移時,MigC將通過MPL中保存的1 b標志位判斷該頁是在DRAM中還是在DVC中.如果IsInDRAM為true則該頁在DRAM中,MigC將通過MPL記錄的頁面地址映射重新映射請求的目標地址;如果IsInDRAM為false則該頁在DVC中,請求將通過原始目的地址與DVC中的地址進行比對從而執行訪問.
算法2.內存頁面逐出算法.
輸入:當前訪問頁面的頁號pagej.
① forpagej=rbeginMPL();
pagej≠rendMPL();
++pagejdo /*檢查已遷移頁面是否要逐出*/
② ifpagej→expirationTime>currentTime
then
③ ifpagej→IsInDRAM==true then
④VicfromDRAM(pagej);
⑤ else
⑥Revenue(pagej);
⑦VicfromCache(pagej);
⑧AdjustThreshold();
⑨ end if
⑩ end if
pagej≠rendMCL();
++pagejdo /*檢查候選遷移列表中是否有頁面超出生命周期*/
then
2.3 遷移參數的自適應調整
為了使遷移機制能夠自適應不同的工作負載,提高遷移的合理性,MigC將通過遷移收益自主地更新遷移參數.當一個頁面最終被逐出DVC時,MigC將計算這一次遷移的收益.遷移收益:
Rw=Writecount×(Timew_in_pcm-Timew_in_DRAM),
(1)
Rr=Readcount×(Timer_in_pcm-Timer_in_DRAM),
(2)
C=TimeP_D+TimeD_DVC+TimeDVC_P×dirty,
(3)
R=Rw+Rr-C.
(4)
式(1)和式(2)通過MPL記錄的讀寫操作次數計算頁面遷移到DRAM中和留存在PCM中的讀寫時延收益,Writecount表示遷移后該頁面所收到的寫操作次數,Timew_in_pcm和Timew_in_DRAM分別表示在PCM和DRAM中進行寫操作所需的時間.同理Readcount,Timer_in_PCM,Timer_in_DRAM表示遷移后該頁面所進行的讀操作次數以及在PCM和DRAM中進行讀操作所需的時間.
式(3)計算了遷移所需的時間代價,如果頁面最終被逐出時為臟,則dirty=1,反之dirty=0.最終的收益通過式(4)計算,如果R>0則表示遷移收益為正,遷移閾值將自動降低使頁面更容易遷移到DRAM中,在DRAM和DVC中的頁面的生存周期也將被延長;如果R<0則表示遷移收益為負,遷移閾值將自動增加使頁面更不容易達到遷移閾值,在DRAM和DVC中的頁面的生存周期也將被縮短.
本文通過線性增值的方式自適應地調整遷移參數,設置以步長為1進行線性增長.生存周期的增減將應用于下一個周期執行遷移頁面節點信息的初始化中,而不是更新目前遷移表中所有內存頁的生存周期.實驗中參數的初始數值與THMigrator的模型參數一致.
例如,當頁面x被認定為“冷”頁面,從而從DVC遷移回PCM時,MigC通過計算得出該頁面x遷移的收益.若收益R為正,則表示當前遷移參數合理有效,留存于DRAM中的頁面將被大概率訪問.然后,MigC降低遷移閾值,增加其他頁面遷移的機會.在下一次遷移時,提升頁面初始生命周期,增加頁面駐留在DRAM中的時間.
3 實驗與分析
本文采用GEM5[27]和NVMain[28-29]構建基于異構內存的多核處理器模型系統,GEM5模擬器是一個用于計算機系統架構研究的模塊化平臺.NVMain是一個架構級的主存儲器模擬器.本文通過GEM5與NVMain的結合,設計了具有DRAM犧牲Cache的水平型結構的異構內存系統,其中DRAM通道與PCM通道的比例為1∶3,DVC的大小為DRAM的1/16,采用時鐘頻率為2 GHz的TimingSimpleCPU,一級緩存設置為32 KB,二級緩存設置為256 KB.詳細配置如表4所示,內存結構中的1∶1/16∶3為DRAM容量、DVC容量以及PCM容量的比例.

Table 4 Main Configurations of GEM5 and NVMain表4 GEM5和NVMain模擬器的主要配置
為了對VC-HMM進行全面分析,本文選擇了CoinMigrator、多級隊列替換算法(MQRA)和基于雙向散列鏈表遷移機制(THMigrator)作為參考.CoinMigrator遷移策略為NVMain模擬器自帶的隨機遷移策略,每一次的遷移決策由隨機數決定.MQMigrator遷移策略為Zhou等人[16]提出的頁面替換算法,遷移使用多個隊列來維護頁面的訪問信息,通過隊列優先級進行“冷”“熱”頁面的排序和選擇,但由于隊列數量多,且不能隨機訪問每個頁面節點.因此,本文提出的VC-HMM采用雙向散列鏈表結構維護頁面信息的數據結構,能實現頁面節點的隨機訪問而不需要遍歷鏈表,降低了頁面信息維護的復雜度.本文采用了SPECCPU2006[30]中的10個不同的基準應用程序,并將CoinMigrator的數據作為對應的標準化數據.
針對一個內存頁的讀寫配置與能耗配置如表5所示,參數來源于文獻[18],內存頁大小設置為4 KB.

Table 5 Configuration of the Memory for a 4 KB Memory Page
實驗數據通過GEM5和NVMain模擬器自身集成的Trace工具來產生,Trace工具可以以文本的形式輸出程序運行時的日志信息,在程序代碼中通過添加一些關鍵數據的打印操作,使用AddStat方法可以將運行時的數據輸出到日志信息中,通過這種輸出日志的跟蹤方法可以獲得讀寫操作的數量和分布以及遷移內存頁的數量等信息.實驗中用于測試的基準應用均使用了1 000萬條指令的運行.其他遷移參數的設置與前期研究[18]的配置一致.
3.1 訪問時延

Fig. 5 Normalized average access latency圖5 歸一化的平均訪問時延
實驗數據顯示,通常情況下使用VC-HMM的系統的平均訪問延遲比使用CoinMigrator,MQRA,THMigrator的系統的平均訪問延遲分別低22.72%,31.56%,23.63%,如圖5所示.基準中的每個應用在VC-HMM的使用中都有較好的效果.其中,與Coin-Migrator,MQRA,THMigrator相比,應用sjeng在使用VC-HMM時訪問時延的降低最明顯,分別為53.45%,60.58%,60.47%.圖5中應用omnetpp的訪問時延高于CoinMigrator,這是由于CoinMigrator的隨機概率判斷策略使得遷移不穩定,每一次的遷移并不完全一樣.本文經過多次的實驗,使數據盡可能趨于穩定.目前VC-HMM的總體訪問時延相比其他的遷移策略基本上都有明顯降低.即使對于所產生的訪問時延高于CoinMigrator策略,VC-HMM策略的訪問時延也僅高于1.5%.
VC-HMM的主要性能提升源于DRAM犧牲Cache,DVC將更多的頁面保留在讀寫速度較快的DRAM部分.即使一個頁面在遷移參數不精準的情況下進行遷移,該頁面仍然可以在訪問較快的DRAM中停留更長的時間,而不會由于“冷”“熱”度的快速動態變化而在PCM和DRAM之間頻繁遷移.這使得更多的請求通過訪問時延較短的DRAM進行訪問,而不是訪問讀寫時延長的PCM.不必要遷移操作的減少也避免了帶寬和其他系統資源的占用.實際上VC-HMM通過使已經執行的遷移變得更有效而不是單純調整遷移閾值來消除無效遷移.
3.2 PCM寫操作頻次
通過使用添加了DVC的異構內存系統,PCM訪問的次數也有了相應的減少.如圖6所示,使用VC-HMM的系統中,PCM的訪問次數相比使用CoinMigrator,MQRA,THMigrator的系統平均減少了67.38%,73.26%,62.97%.同時,對PCM的寫操作數也明顯減少.如圖7所示,相比使用CoinMigrator,MQRA,THMigrator的系統,使用VC-HMM的系統平均減少了81.28%,84.99%,75.89%的PCM寫入次數.
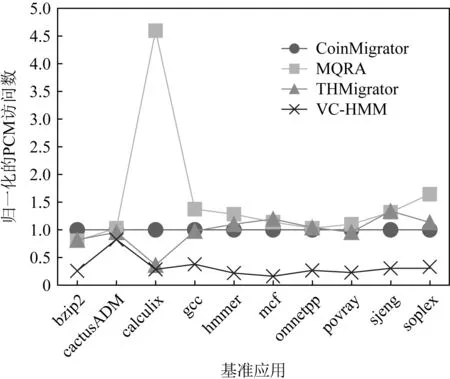
Fig. 6 Normalized PCM access times圖6 歸一化的PCM訪問數

Fig. 7 Normalized PCM write times圖7 歸一化的PCM寫操作數
盡管遷移閾值可能不夠精確,且由于遷移參數的人為制定無法選擇和預測真正最“熱”的頁面進行遷移,但VC-HMM增加了遷移頁留在DRAM部分的時間,使大部分的請求通過DRAM進行訪問,冗余遷移的減少也降低了對PCM的讀寫操作次數,延長了PCM的使用壽命.原頁面的保留也使得讀頻繁的“冷”頁面在遷移時不需要寫回,進一步降低了PCM被訪問的次數.
3.3 IPC
圖8比較了使用VC-HMM和其他3種算法的系統IPC(平均每個周期完成的指令數).這4種不同算法所產生的系統IPC差異不顯著,但VC-HMM仍能在一定程度上提高IPC.使用VC-HMM系統的IPC平均比使用CoinMigrator,MQRA,THMigrator的系統的IPC高2.36%,2.88%,4.03%.在所有基準應用中,sjeng的增長率最高,分別為11.36%,12.72%,24.32%,說明sjeng應用的存儲訪問的局部性較高.在這種情況下,所請求的頁面大部分被遷移到DRAM中,大大減少了請求的時間.
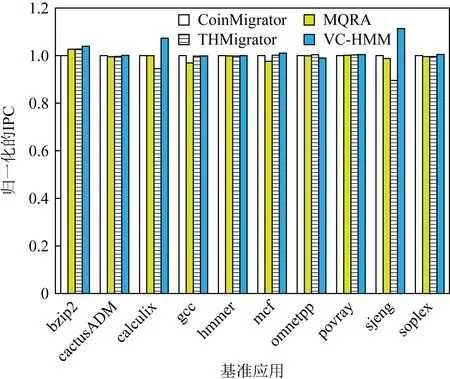
Fig. 8 Normalized IPC圖8 歸一化的IPC
然而,即使VC-HMM減少了大量的PCM寫入,使用VC-HMM的系統的IPC也沒有得到顯著的改善.本文分析其中一個原因是由于VC-HMM需要在每次遷移中進行二次遷移.遷移的頁面需要從DRAM到DRAM犧牲Cache進行額外遷移,即使MigC可以自主地調整遷移參數,但二次遷移依舊需要額外的時鐘周期來完成.
此外,不同應用程序的寫請求頻次多少、訪存地址的局部性強弱會使得VC-HMM機制下的IPC值發生變化.寫訪問量較少且局部性較好的應用在使用VC-HMM時能夠得到更好的性能提升.
3.4 冗余遷移操作
圖9比較了使用VC-HMM的系統與使用另外3種算法的系統的重復遷移操作次數,與使用CoinMigrator,MQRA,THMigrator的系統相比,VC-HMM平均減少了58.80%,52.40%,38.37%的重復遷移操作.其中在基準測試應用calculix和sjeng中,均未檢測到重復的內存頁遷移操作.

Fig. 9 Normalized re-migration times圖9 歸一化的重復遷移次數
由于當前實驗階段難以計算冗余操作中的σ值,本文實驗采用統計重復遷移操作的次數來量化冗余遷移操作的次數.在cactusADM及omnetpp應用中,VC-HMM的重復遷移次數高于THMingrator,這是由于VC-HMM擁有遷移閾值和頁面生存周期的自適應策略,對于局部性較差的應用來說,由于VC-HMM相比沒有DVC設備的策略需要額外的從DRAM到DVC設備的遷移,這將會導致動態自適應算法減少頁面在DRAM中的生存周期,從而使得頁面過早遷出,增加了冗余遷移的可能性.同時,DVC的直接映射策略也使得沖突頁面過早地遷回NVM,也增加了冗余遷移的次數.
DVC使得完成遷移的“熱”頁更久地保存在訪問速度較快的DRAM設備中,且“冷”“熱”頁并不成對進行遷移操作,這阻止了“冷”頁的誤遷回,從而減少了頁面再次變“熱”而導致的冗余遷移問題.在構建DVC時,本文使用直接映射策略作為DVC的映射規則,雖然直接映射策略下的訪問速度較快,但也更加容易引起沖突而加快頁面的遷回,導致部分冗余的遷移操作.由于遷移到DVC的頁面為從主存DRAM中逐出的“冷”頁.因此,雖然存在由于沖突而過早遷回的頁面,但并沒有對系統產生過大的影響.
3.5 系統能耗
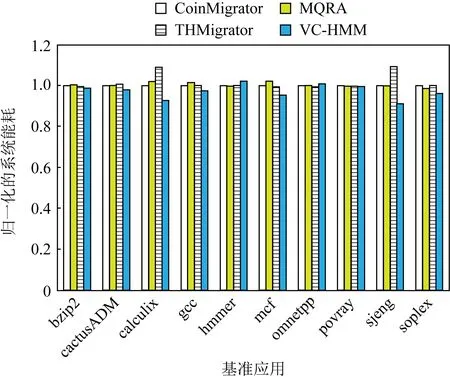
Fig. 10 Normalized energy consumption where the capacity of DVC is 1/16 of DRAM圖10 DVC容量為DRAM容量1/16時歸一化的 系統能耗
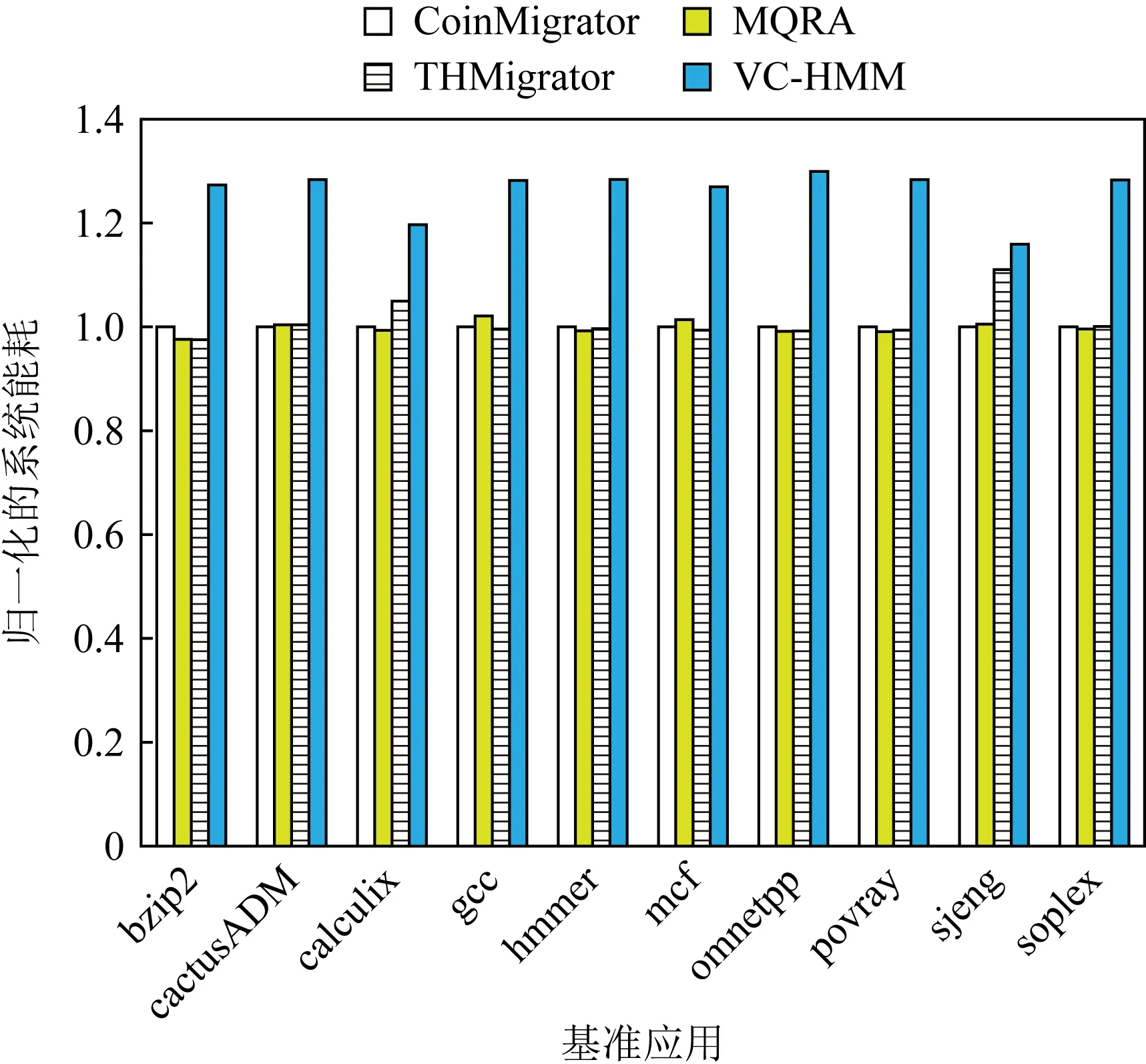
Fig. 11 Normalized energy consumption where the capacity of DVC is 1/8 of DRAM圖11 DVC容量為DRAM容量1/8時歸一化的 系統能耗
圖10比較了使用VC-HMM的系統與使用另外3種算法的系統的能耗情況.與使用CoinMigrator,MQRA,THMigrator的系統相比,VC-HMM平均減少了2.74%,3.16%,4.29%的系統能耗.由于系統性能的提升,VC-HMM在降低運行時間、提高系統效率的同時減少了能耗.但同時,能耗將根據使用的DVC的容量大小而改變.圖11對比了DVC容量為DRAM容量的1/8時所產生的能耗.與使用CoinMigrator,MQRA,THMigrator的系統相比,使用比先前增加1倍容量的DVC時,VC-HMM平均增加了24.92%,24.35%,22.97%的系統能耗.VC-HMM在應用hmmer與omnetpp上的能耗大于其他的遷移策略.對于局部性較差的應用來說,遷移的頁面也會較多,從而導致內存訪問和靜態維持數據所需的能耗增加,且額外的DRAM到DVC的遷移操作和DVC沖突問題也將增加能耗.此外,DVC容量的增大將減少數據沖突的發生,導致所需保持的數據增加,這些數據的訪問以及達到生存周期之前的數據刷新都將產生大量能耗.
由于DRAM利用電容內存儲電荷的多少來存儲數據的特性,晶體管漏電使得DRAM需要周期性地充電,且訪問前需要對區塊進行預充,這將產生不小的系統能耗來維持DRAM的運行.過大的DVC將使得靜態能耗增加,且得不到合理的使用.另外,由于異構內存的遷移使得大量的內存訪問集中于DRAM,所以DVC的容量大小將不同程度上影響系統能耗.
4 總 結
本文提出了一種基于DRAM犧牲Cache的異構內存頁遷移機制VC-HMM,該機制實現了比THMigrator模型更低的訪問延遲,消除了部分無效的遷移操作.此外,VC-HMM在局部性較強的應用中取得了較高的訪存性能.
實驗結果表明:與使用CoinMigrator、多隊列算法MQRA和基于雙向散列鏈表的遷移機制THMigrator的系統相比,使用VC-HMM的系統的平均訪問延遲降低了22.72%,31.56%,23.63%.同時,VC-HMM相比CoinMigrator,MQRA,THMigrator減少了81.28%,84.99%,75.89%的PCM寫操作,并在一定程度上提升了系統IPC.另外,在減少重復遷移操作方面,VC-HMM平均減少了相比另外3種機制58.80%,52.40%,38.37%的重復遷移操作.在能耗方面,與使用CoinMigrator,MQRA和THMigrator的系統相比,VC-HMM平均減少了2.74%,3.16%,4.29%的系統能耗.未來,我們計劃利用機器學習算法識別和監測“熱”頁面,并著力于研究更智能的頁遷移決策,以獲得更高的異構內存綜合性能.
作者貢獻聲明:裴頌文提出了算法思路和實驗方案;錢藝幻負責完成實驗并撰寫論文;葉笑春提出指導意見并修改論文;劉海坤與孔令和提出指導意見.
猜你喜歡
大灰狼畫報·益智版(2024年3期)2024-12-09 00:00:00
工業設計(2022年8期)2022-09-09 07:43:20
保健醫苑(2022年1期)2022-08-30 08:39:14
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
文苑(2018年21期)2018-11-09 01:23:06
家庭影院技術(2017年9期)2017-09-26 03:41:45
中國衛生(2015年9期)2015-11-10 03:11:12
中國衛生(2014年3期)2014-11-12 13:18:12
中國火炬(2014年4期)2014-07-24 14:22:19
