面向概念漂移數據流的自適應分類算法
2022-03-09 05:49:40陸克中伍啟榮吳定明
計算機研究與發展 2022年3期
蔡 桓 陸克中 伍啟榮 吳定明
(深圳大學計算機與軟件學院 廣東深圳 518061)
在當今的數字時代,數據起著至關重要的作用,它以驚人的速度增長,如何處理和分析這些數據變得越來越重要[1].與在靜態場景中構建模型的批處理學習不同,在線學習面臨2個重大挑戰:1)分類器必須在每個實例到達后立即進行處理,而無需使用存儲或重新處理[2].2)數據流可能會發生概念漂移,即數據分布與輸入變量和輸出變量之間的關系可能會隨時間發生變化[3].因此,部署在非平穩數據流中的分類器必須通過1次遍歷來學習,同時能適應數據分布的動態變化.
近些年來,在處理概念漂移數據流分類問題上取得了很多研究成果.圍繞概念漂移的研究可以歸納為主動檢測[4-6]和被動適應[7-8]2大類.主動檢測算法通過檢測分類器性能或數據流的特征分布來確定數據流的穩定性,當判斷發生概念漂移時觸發概念漂移處理機制來適應新環境.被動適應方法不去主動檢測是否發生概念漂移,而是通過不斷對數據或者模型進行更新以適應新環境,主要有塊學習、增量更新、遺忘因子機制和集成方法等.主動檢測方法通常具有更好的概念漂移適應能力,但也往往具有更高的時間和空間復雜度.
隨著神經網絡的迅速發展,研究人員已開始開發基于神經網絡的數據流分類方法.由新加坡南洋理工大學Huang等人[9]提出的極限學習機(extreme learning machine, ELM)是一種具有單隱層的高效前饋神經網絡,研究人員被廣泛吸引來開發ELM方法.ELM隨機選擇輸入層權重和隱含層偏差.一旦確定了輸入權重,就不會通過迭代進行調整.因此,與傳統的神經網絡相比,ELM具有學習時間短、泛化能力強的優勢[10].而Liang等人[11]進一步提出的在線順序極限學習機(online sequential extreme learning machine, OSELM)是一種增量學習算法,可滿足數據流分類的要求[12].該算法可以逐步更新分類模型而無需重新訓練.由于OSELM相對于其他算法具有速度快、分類性能好的優勢,基于OSELM算法進行優化成為數據流分類研究的一個重要方向,也產生了很多衍生算法[13-17].但OSELM算法也存在不足,比如只能處理漸進的概念漂移,而無法適應突然改變的概念[18].而大多數基于OSELM優化的算法直接提前指定1個隱含層節點數且在不同數據集上保持固定,這很容易產生欠擬合或過擬合問題.也有學者將遺忘因子引入OSELM,但同樣提前指定1個固定的遺忘因子,導致分類器無法在數據流穩定階段和概念漂移階段取得良好的平衡.此外,數據流往往存在噪音,而原始OSELM及大多數優化算法沒有對噪音進行有效區分,而是對每個新到達的實例都相同處理,因此分類決策邊界很容易被噪音(異常值)破壞.
針對上面提到的問題,以及在FROSELM(online sequential extreme learning machine based on regularization and forgetting factor)[19]和FGROSELM(online sequential extreme learning machine with generalized regularization and adaptive forgetting factor)[20]等算法的啟發下,本文提出了一種自適應在線順序極限學習機(adaptive online sequential extreme learning machine, AOSELM)分類算法.AOSELM算法首先引入自適應模型復雜度機制,在初始化階段可以自適應確定出最佳隱含層節點數,并加入正則項,優化模型復雜度.其次通過自適應遺忘因子和概念漂移檢測機制,將概念漂移和遺忘因子結合,使分類模型在發生概念漂移時自動調小遺忘因子,而在數據流穩定時自動調大遺忘因子,從而適應數據流的動態變化.最后通過引入異常點檢測機制,增強模型抗噪音能力.
1 相關工作
本節我們將重點介紹OSELM和FROSELM這2種算法.為了簡單起見,2種算法都考慮用于2分類問題,即只有單個輸出節點.
1.1 OSELM算法
在線順序極限學習機OSELM算法是由Liang等人[11]于2006年提出,該算法是Huang等人[9]提出的ELM算法的在線學習方法.算法分為初始化階段和在線學習階段2個階段.


(1)
Wi和bi分別為輸入權重和第i個隱含層偏置,而Y0=(y1,y2,…,yN0)T.根據廣義逆求解方法可計算得:
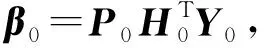
(2)
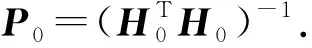
在線學習階段,數據流逐條被處理,無需保存歷史數據.當新實例(Xk+1,yk+1)到達時,記hk+1=(g(W1,b1,Xk+1)…g(WL,bL,Xk+1)),可計算得過渡矩陣P和輸出層權重β的更新:
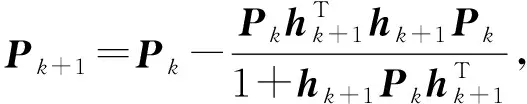
(3)
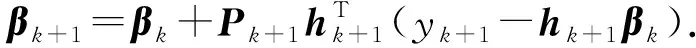
(4)
從式(3)(4)可以看出,OSELM的輸出權重是根據最后一次迭代的結果和新到達的數據進行遞歸更新的,一旦新數據被學習,就可以立即丟棄,符合在線學習處理方式的要求,因此該算法的計算開銷和內存要求大大降低.OSELM具備速度快和泛化能力強的特點,并且可以增量更新模型.
1.2 FROSELM算法
具有遺忘機制的正則在線順序極限學習機FROSELM算法是由杜占龍等人[19]于2015年提出.該算法將遺忘因子(forgetting factor, FF)方法和正則化技術引入OSELM,根據實例的時間順序分別為每個樣本分配不同的權重.初始化階段過渡矩陣P0和輸出層權重β0分別為

(5)
(6)
其中,C為懲罰項系數,I為單位矩陣.在線學習階段過渡矩陣P和輸出層權重β的更新公式分別為

(7)
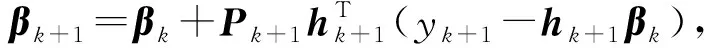
(8)
其中,λ為遺忘因子,當λ=1且C=0時,FROSELM退化為原始OSELM.FROSELM算法為最近的樣本分配較高的權重,而為舊的樣本分配較低的權重,以表示它們對學習模型的不同貢獻,因此使模型能夠適應數據流的動態變化.
2 自適應在線順序極限學習機算法
數據流的動態變化特點要求分類器能夠不斷地更新,以便更改分類器使其適應當前的數據分布.而概念漂移的發生使得不同時刻目標概念與當前特征的映射關系不斷變化,且是否發生概念漂移、概念漂移的位置以及概念漂移的類型均無法提前獲知.目前大多數算法都采用提前指定模型參數的方式進行學習,比如對模型復雜度直接影響的隱含層節點數以及決定概念漂移適應能力的遺忘因子等.這種做法使得分類模型只能在特定的數據集才能發揮較好的性能,因此,本文提出的AOSELM算法引入自適應機制來增強模型的分類效果和概念漂移適應能力,此外,還引入異常點檢測機制,增強模型抗噪音能力.本節將對AOSELM算法的基本思想及其實現過程進行詳細介紹.
2.1 算法基本思想
現有的數據流分類算法大致可分為3種:1)大部分傳統算法是對數據流新到達實例(Xi,yi)進行增量式處理(稱為批學習),這種方法需要保存大量的歷史數據,且反復學習會消耗大量時間,因此逐漸不適合用于處理大規模數據流任務;2)將數據流劃分為相同大小的數據塊B1,B2,…,Bi,…(稱為塊學習),分類器只針對最新的數據塊進行學習和更新;3)分類器只針對最新的單個實例進行1對1的分類和學習,而不保存歷史實例數據(稱為在線學習),這種方法更適合大數據時代數據不斷快速產生的特點,也是當前研究的熱門方向,因此本文采用這種方式進行處理.
AOSELM算法分為初始化階段和在線學習階段.在初始化階段,在OSELM算法初始化階段的基礎上,引入自適應模型復雜度機制.采用2折交叉驗證的方法,確定最佳的隱含層節點數(number of hidden layer nodes),記為Nh.然后使用最優的隱含層節點數以及加入懲罰項學習訓練集,得到自適應優化后的初始模型,并保存輸出層權重β0.在在線學習階段,AOSELM算法針對每個到達的實例,先進行分類.如果分類正確,則直接結束本輪學習并進入下一個實例,不對模型進行更新.如果分類不正確,則引入自適應遺忘因子和概念漂移檢測機制,提出概念漂移指數(concept drift index),記為ICD.通過ICD判斷數據流是否產生概念漂移,如果發生概念漂移,則將ICD和遺忘因子λ結合,使模型根據當前數據流自適應調整遺忘因子λ大小,從而使模型更好地適應數據流的變化.此外還引入異常點檢測機制,防止模型因異常點而過度更新,從而增強分類器的抗噪音能力.圖1展示了所提出的自適應在線順序極限學習機算法的總體框架:
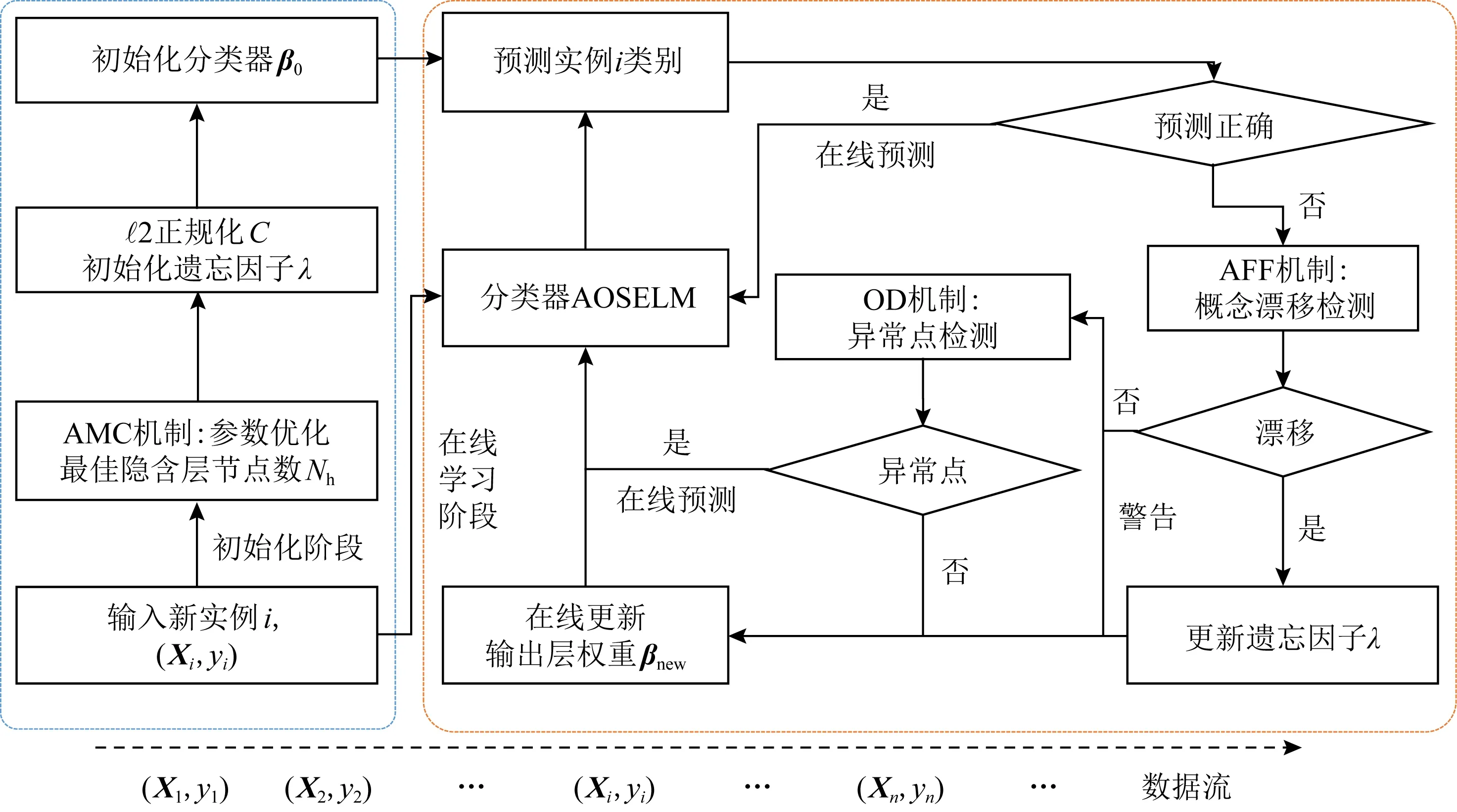
Fig. 1 The overall framework of AOSELM圖1 AOSELM算法的整體框架
2.2 自適應模型復雜度機制
分類器的分類性能通常都會受到模型復雜度的影響,如圖2所示.當模型復雜度太低時,分類決策邊界就會像線條1那樣欠擬合;而當模型復雜度太高時,分類決策邊界又會像線條2那樣過擬合.機器學習的目的就是學習產生如線條3那樣的理想決策邊界.因此,選擇合適的模型復雜度對分類器的性能起著至關重要的影響.
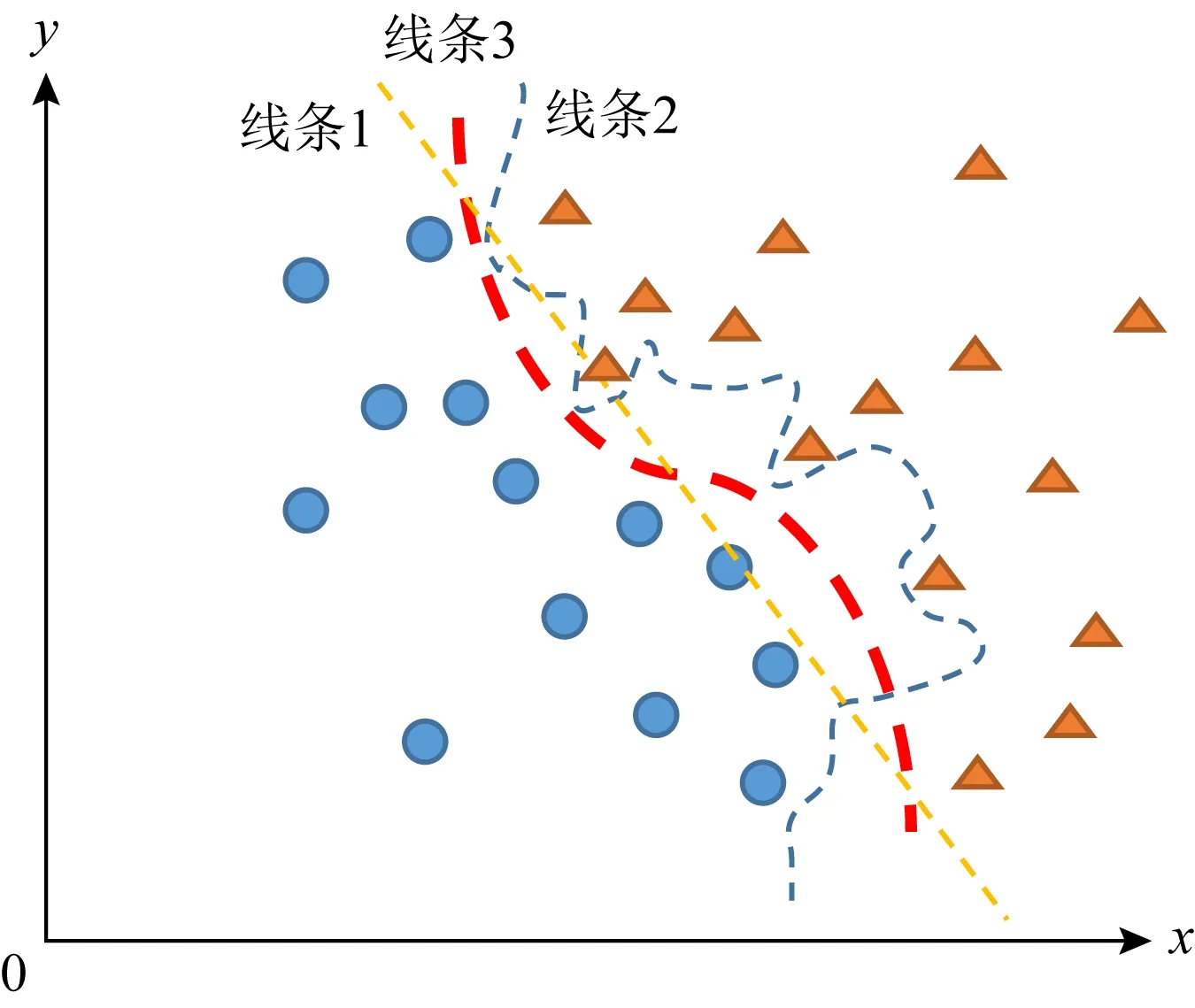
Fig. 2 Model complexity and decision boundary圖2 模型復雜度與決策邊界示意圖
對于OSELM算法而言,隱含層節點數是決定模型復雜度的關鍵參數,Nh的選擇也對分類器的分類性能和泛化能力起著重要影響.在處理分類任務時,不同數據流因為特征數不同、輸入和輸出之間的映射關系復雜程度不同等原因,往往適合不同大小的模型復雜度.然而大多數算法直接提前指定1個隱含層節點數且在不同數據集上保持固定,明顯不符合現實需求.因此,AOSELM算法引入了自適應模型復雜度(adaptive model complexity, AMC)機制.
自適應模型復雜度機制的具體方法是在初始化學習階段,與大多數算法直接指定1個固定的隱含層節點數Nh不同,首先設定Nh∈[2,2Nin],其中Nin為輸入層節點數,即數據流的特征數,使用2折交叉驗證的方式計算每個Nh對應的平均分類準確率.然后通過加入節點數量懲罰項來選出最佳的隱含層節點數Nh.進一步使用最佳的Nh和訓練集進行學習,并加入懲罰項,最終學習得到更加合適的初始分類模型.這樣算法在處理不同數據流任務時,就會自適應地計算出最合適的Nh,從而確定最合適的模型復雜度,避免出現欠擬合或者過擬合問題.另外,在處理數據流任務中,在線學習階段規模往往比初始化階段大很多,比如本文的實驗中初始化階段實例數占比均小于3%,因此,AMC機制并不會明顯增加模型整體的時間開銷.
2.3 自適應遺忘因子和概念漂移檢測機制
在FROSELM算法中,遺忘因子λ大小是決定分類器遺忘速度和適應速度的關鍵參數,而算法提前指定遺忘因子λ值且一直保持固定,無法有效地適應數據流的概念漂移.另外,由于我們往往無法提前獲知是否發生概念漂移、概念漂移發生的位置以及概念漂移發生的類型,因此有必要引入自適應遺忘因子機制.AOSELM算法引入自適應遺忘因子和概念漂移檢測(adaptive forgetting factor and concept drift detection, AFF)機制.該機制借鑒漂移檢測方法(drift detection method, DDM)提出概念漂移指數ICD,并將概念漂移指數ICD和遺忘因子λ相結合,使模型能夠根據當前數據流概念漂移情況自適應地調整遺忘因子λ大小,從而使模型能更好地適應數據流的變化.
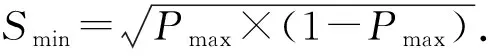
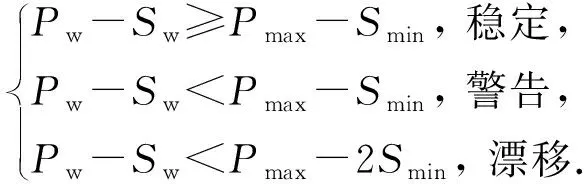
(9)
基于DDM本文提出了概念漂移指數ICD來描述當前數據流概念漂移的程度,ICD的計算方法:
ICD=(Pw-Sw-Pmax)/Smin.
(10)
將遺忘因子λ與概念漂移指數ICD結合,使遺忘因子λ能夠隨概念漂移指數ICD自適應地調整.遺忘因子λ的計算方法:
λ=1+0.01ICD.
(11)
當遺忘因子λ=1時,則退化為OSELM,不具備遺忘能力,因此將λ最大值設為0.999.結合式(9)~(11)可以看出,當概念漂移系數ICD≥-1時,則判斷數據流處于穩定階段;當概念漂移系數ICD←1時,則發出概念漂移警告,在線更新模型;當概念漂移系數ICD←2時,則判定數據流已經發生概念漂移,根據式(11)自適應更新遺忘因子λ.隨著概念漂移系數ICD的變小,遺忘因子λ也在自適應變小,從而使分類器具有更強的遺忘能力,能更快地適應新概念.
2.4 異常點檢測機制
數據流往往存在噪音,而原始OSELM算法及大多數改進算法沒有對噪音進行有效區分,而是對每一個新到達的實例都相同處理,全部進行更新,因此分類決策邊界很容易被噪音(異常值)破壞.
AOSELM算法引入異常點檢測(outlier detection, OD)機制,對預測錯誤且概念漂移系數ICD≥-1(即數據流處于穩定狀態)的實例進行異常點檢測.如果判斷為異常點,則直接跳過該實例,不在線更新分類器;如果判斷不是異常點,則按照OSELM算法在線更新分類器.OD機制可以避免決策邊界過多受到異常點的影響,從而提升模型整體的抗噪音能力.
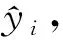
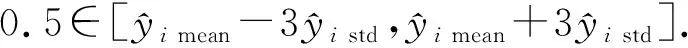
(12)
如果式(12)成立,則認為當前實例沒有遠離分類決策邊界,從而判斷不是異常點;否則認為當前實例遠離分類決策邊界,判斷屬于異常點.
2.5 算法偽代碼
AOSELM算法通過引入自適應策略和異常點檢測形成較優分類模型,使其更好地適應概念漂移,算法偽代碼見算法1所示:
算法1.AOSELM算法.
輸入:數據流(X,y)、訓練集實例數N0、保留模型數Nm、保留預測數Np;

① 初始化階段,隨機生成輸入層權重和隱含層偏置;
② 基于訓練集(Xtrain,ytrain)進行交叉驗證;
③ 引入AMC機制,計算最佳隱含層節點數Nh;
④ 加入L2正則化參數C;
⑤ 計算出輸出層權重β0,得到初始分類模型;
⑥ 將β0保存到模型表中,結束初始化階段;
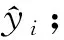
⑧ 計算相關參數P,Pw,Sw,Pmax,Smin;
⑨ 將P保存到預測表中;
⑩ 更新Pnew=(Pnew+1)%Np;
2.6 復雜度分析
本節將從時間復雜度與空間復雜度2個層面分析AOSELM算法的計算復雜度.初始化階段,假設用于訓練的實例數為N0,由于AMC模塊需要交叉驗證確定最佳的隱含層節點數,因此初始化階段時間開銷為O(N0×(Tp+Tu)×2Nin),其中Tp和Tu分別為OSELM算法1次預測和更新的時間開銷,Nin為輸入層的節點數.但由于實驗中N0占總實例數的比值均小于3%,且實際應用中數據流往往不斷產生,因此我們更關心在線學習階段的時間和空間復雜度.
在時間復雜度方面,假設在線學習階段數據總數為N.首先所有實例都需要進行預測,因此時間開銷為O(N×Tp).假設有N1個正確預測實例,由于預測正確則直接結束這一輪的在線學習,避免更新模型,所以這部分額外的時間開銷可以忽略.對于預測錯誤的N-N1個實例,首先需要進行概念漂移檢測,當發生概念漂移檢測結果是警告或漂移時(假設有N2個實例),均需要在線更新模型,由于概念漂移檢測和更新遺忘因子的時間開銷可以忽略,因此AFF模塊時間開銷為O(N2×Tu).剩下的N-N1-N2個實例需要進行異常點檢測,由于需要Nm個模型進行預測,因此OD模塊時間開銷為O((N-N1-N2)×Nm×Tp)的時間.最后,當判斷為異常點時,直接跳過本次實例,而當判斷不是異常點時(假設有N3個實例),需要在線更新模型,這部分時間消耗為O(N3×Tu).因此AOSELM在線學習階段時間開銷為O(N×Tp+(N2+N3)×Tu+(N-N1-N2)×Nm×Tp).由于Tu?Tp,因此AOSELM算法的時間復雜度與模型預測錯誤的實例個數(N-N1)成正比.
在空間復雜度方面,AOSELM算法采取的是在線學習方式,對每個實例逐個處理,學習完后直接刪除舊的實例數據,只是額外增加了1個(Nh×No+1,Nm)大小的矩陣儲存模型參數β以及1個(Np,1)大小的矩陣儲存最近的Np個預測結果.由于本文實驗中輸出層節點數No均為1,因此,額外增加的內存消耗約為O(Nh×Nm+Nm+Np),由于Nh,Nm和Np都是常量,且實驗中設定的數值都很小,所以AOSELM算法的空間復雜度為O(1).
3 實驗與結果
為了驗證本文提出的AOSELM算法的性能以及其對概念漂移數據流的適應性,本文在理論研究的基礎上進行了大量的實驗.本節主要介紹實驗環境和數據集、參數敏感性分析、算法性能對比以及通過消融實驗來衡量AOSELM算法所引入的3個機制的效果.驗證實驗的設計、性能評估以及算法機制分析是本節的核心內容.
3.1 實驗數據集
為了驗證AOSELM算法的性能,實驗數據集選取5個人工合成數據集和2個真實數據集,實驗數據集簡要信息如表1所示.實驗中默認所有算法的訓練集實例數為500,懲罰參數C=0.1.本文實驗平臺為Windows 10,CPU為Intel i7-2.5 GHz,內存為8 GB,所有分類算法均基于Python語言實現.
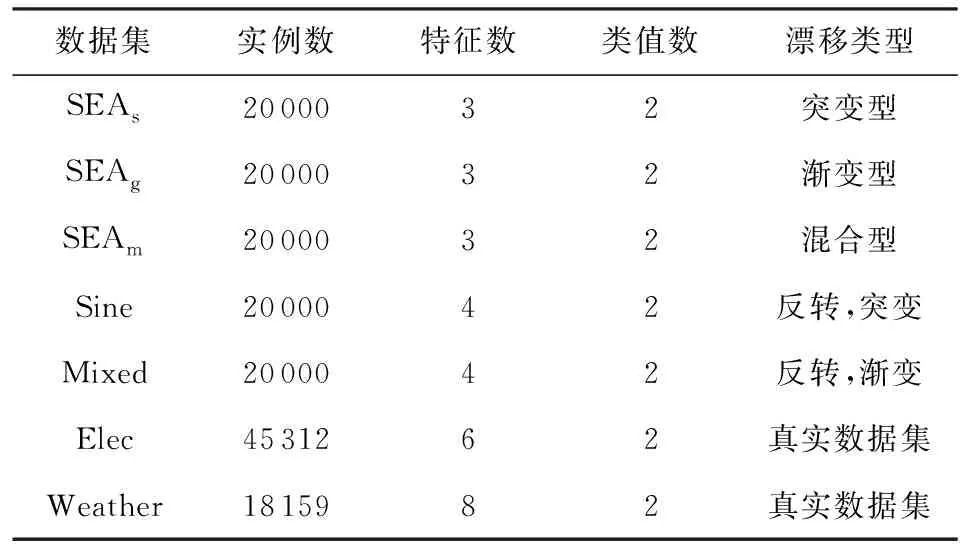
Table 1 Experimental Data Set Information表1 實驗數據集信息
1) SEAs,SEAg和SEAm數據集.SEA生成器在SEA算法[22]中被提出.通過改變閾值,可以模擬概念漂移.數據集中含有3個屬性,其中只有2個屬性是相關的.通過使用SEA生成器生成了3個數據集,每個數據集包含20 000個實例,并添加了3%的噪聲.另外,3個數據集均包含2次概念漂移,且都發生在實例編號為5 000和15 000的位置.其中,SEAs數據集包含2次突變型概念漂移;SEAg數據集包含2次漸變型概念漂移;SEAm數據集包含1次突變型概念漂移和1次漸變型概念漂移.
2) Sine數據集.數據集中含有4個屬性,其中只有2個屬性是相關的.數據集包含20 000個實例,且在5 000,10 000,15 000這3個位置發生突變型反轉,即概念漂移前后目標值剛好相反.
3) Mixed數據集.數據集中含有4個屬性,其中只有2個屬性是相關的.數據集包含20 000個實例,且在5 000,10 000,15 000這3個位置發生漸變型反轉,即概念漂移前后目標值剛好相反.
4) Elec數據集.是廣泛應用于數據流學習中的真實數據集.該數據集是來自澳大利亞新南威爾士州電力市場1995—1998年的部分數據,包含45 312個實例.數據集一共包含6個相關屬性,由于那里的電力價格不是固定的,而是根據供求關系而變化,因此目標是預測每天電力價格的變化(1表示上升,0表示下降).
5) Weather數據集.包含1949—1999年在內布拉斯加州Bellevue收集的天氣信息,包含18 159個實例.數據集一共包含8個相關屬性,目的是預測給定日期是否下雨.
3.2 對比算法
將本文提出的AOSELM算法與其他6種數據流在線分類算法進行性能比較,分別是:
1) OSELM算法.由Liang等人[11]于2006年提出,該算法是Huang等人[9]提出的極限學習機ELM算法的在線學習方法,具有速度快、分類性能好的優勢,被廣泛應用.
2) ROSELM(regularized online sequential extreme learning machine)算法.由Huynh等人[23]于2011年提出,該算法將正則化技術引入OSELM,從而提高了分類器的泛化能力.
3) FROSELM算法.由杜占龍等人[19]于2015年提出,該算法將將遺忘因子FF方法和正則化技術引入OSELM,根據實例的時間順序分別為每個樣本分配不同的權重.
4) FGROSELM算法.由Guo等人[20]于2018年提出,該算法采用一種新的廣義正則化方法來代替傳統的指數遺忘正則化,使算法具有恒定的正則化效果以及更好的概念漂移適應能力.
5) 霍夫丁樹(Hoeffding tree, HT)算法.由Domingos等人[24]提出,是一個流行的增量決策樹算法,其創造性地使用Hoeffding界確定選擇劃分屬性時所需的樣本數,在很多研究中具有優秀的分類性能.
6) 樸素貝葉斯(naive Bayes, NB)[25]算法.是一種廣泛應用的分類算法,以其簡單性和低計算量而聞名,實驗中使用的是傳統樸素貝葉斯算法的在線學習版.
3.3 參數敏感性分析
為了解釋引入自適應模型復雜度機制(AMC)、自適應遺忘因子和概念漂移檢測機制(AFF)的動機,本節設計了參數敏感性分析實驗,用來驗證隱含層節點數Nh和遺忘因子λ對模型分類性能的影響.
圖3展示了不同隱含層節點數Nh值下OSELM算法在不同數據集上的分類準確率.從中可以發現,當隱含層節點數Nh太小時,模型的學習能力不夠,因此分類器的性能不佳.而隱含層節點數Nh太大又會加大模型的復雜度,從而大大增加模型的學習時間.目前大多數算法都采用提前指定隱含層節點數Nh的方式進行學習,這顯然不能取得最佳的性能,不同數據流因為特征數不同、輸入和輸出之間的映射關系復雜程度不同等原因,具有不同的最佳隱含層節點數Nh.因此AOSELM算法引入了自適應模型復雜度機制,在初始化階段,采用交叉驗證的方式確定該數據集的最佳隱含層節點數.
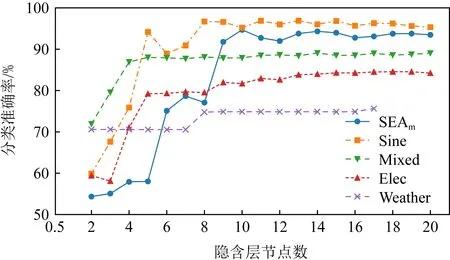
Fig. 3 Classification accuracy of OSELM with different Nh values on different data sets圖3 不同Nh值OSELM在不同數據集的分類準確率
圖4和圖5分別展示了不同遺忘因子λ值下FROSELM算法在Sine數據集上的分類準確率和累計分類準確率.從圖4、圖5中可以發現,當遺忘因子λ較大時,雖然分類器能夠在數據流穩定時期取得更好的分類準確率,但當數據流發生概念漂移時卻更難適應新概念,從而降低了模型累計分類準確率.相反地,當遺忘因子λ較小時,雖然分類器能夠更快地遺忘舊模型,從而更好地適應概念漂移,但在數據流穩定時期卻喪失了更好的分類性能.由于我們往往無法提前獲知是否發生概念漂移、概念漂移發生的位置以及概念漂移發生的類型,因此有必要引入自適應遺忘因子機制.

Fig. 4 Classification accuracy of FROSELM with different λ on Sine圖4 不同λ值FROSELM在Sine的分類準確率

Fig. 5 Cumulative classification accuracy of FROSELM with different λ on Sine圖5 不同λ值FROSELM在Sine的累計分類準確率
AOSELM算法借鑒DDM方法提出了概念漂移指數ICD,并將概念漂移指數ICD和遺忘因子λ相結合,使模型能夠根據當前數據流概念漂移情況自適應地調整遺忘因子λ大小,從而使模型能更好地適應數據流的變化.
3.4 對比實驗
在對比實驗中,將AOSELM算法與相關的算法進行對比,包括FGROSELM,FROSELM,ROSELM,OSELM,HT,NB.其中HT和NB是傳統分類器的在線方法,具有簡單、高效、易于理解的特點.而FGROSELM,FROSELM,ROSELM以及本文所提出來的AOSELM均是基于OSELM優化的算法.在對比的7種算法中,只有FGROSELM,FROSELM,AOSELM這3種算法引入了遺忘機制.

Fig. 6 Classification accuracy of contrast algorithm on SEAm圖6 對比算法在SEAm上的分類準確率
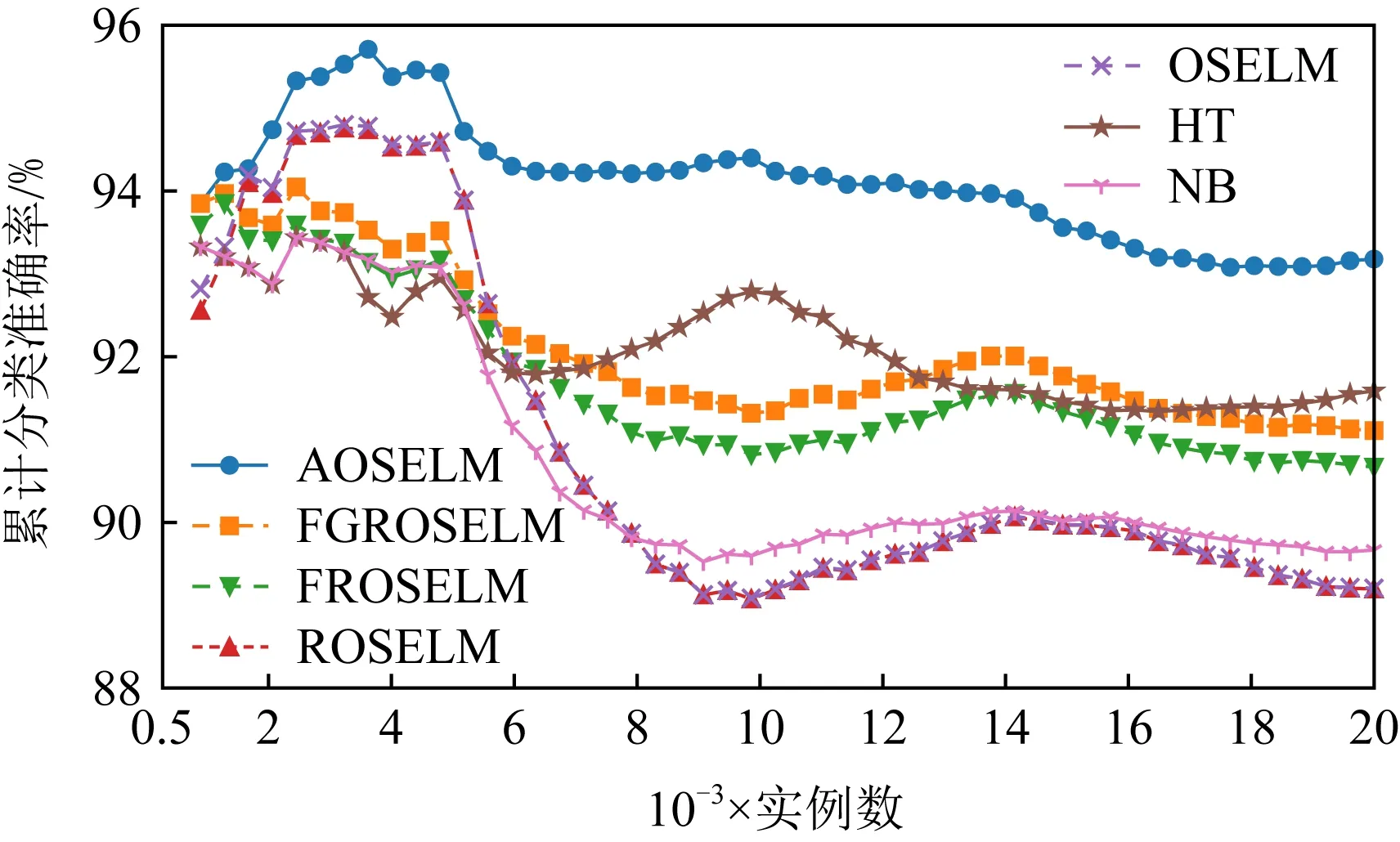
Fig. 7 Cumulative classification accuracy of contrast algorithm on SEAm圖7 對比算法在SEAm上的累計分類準確率
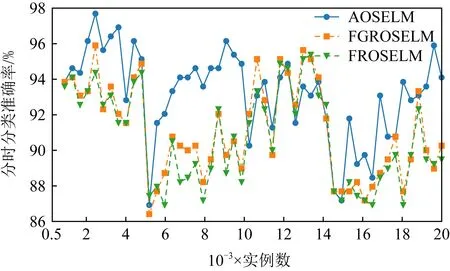
Fig. 8 Classification accuracy of OSELM optimization algorithm on SEAm圖8 OSELM優化算法在SEAm上的分類準確率
圖6~9分別展示了全部7種對比算法和具有遺忘機制的3種OSELM優化算法在SEAm數據集上的分類準確率和累計分類準確率.從圖7中可以看出7種算法均能在面對概念漂移時更新分類器,從而適應新概念,但ROSELM,OSELM,NB這3種算法表現較差.而從圖8的分類準確率中可以看出,當發生概念漂移后,AOSELM算法相比另外2種同樣具有遺忘機制的FGROSELM和FROSELM算法能夠更快地適應概念漂移,分類性能也能在概念漂移發生后更快反彈.從累計分類準確率中可以看出,AOSELM算法具有更好的分類性能,分類準確率比FGROSELM和FROSELM這2種算法提高了大約2.5%.
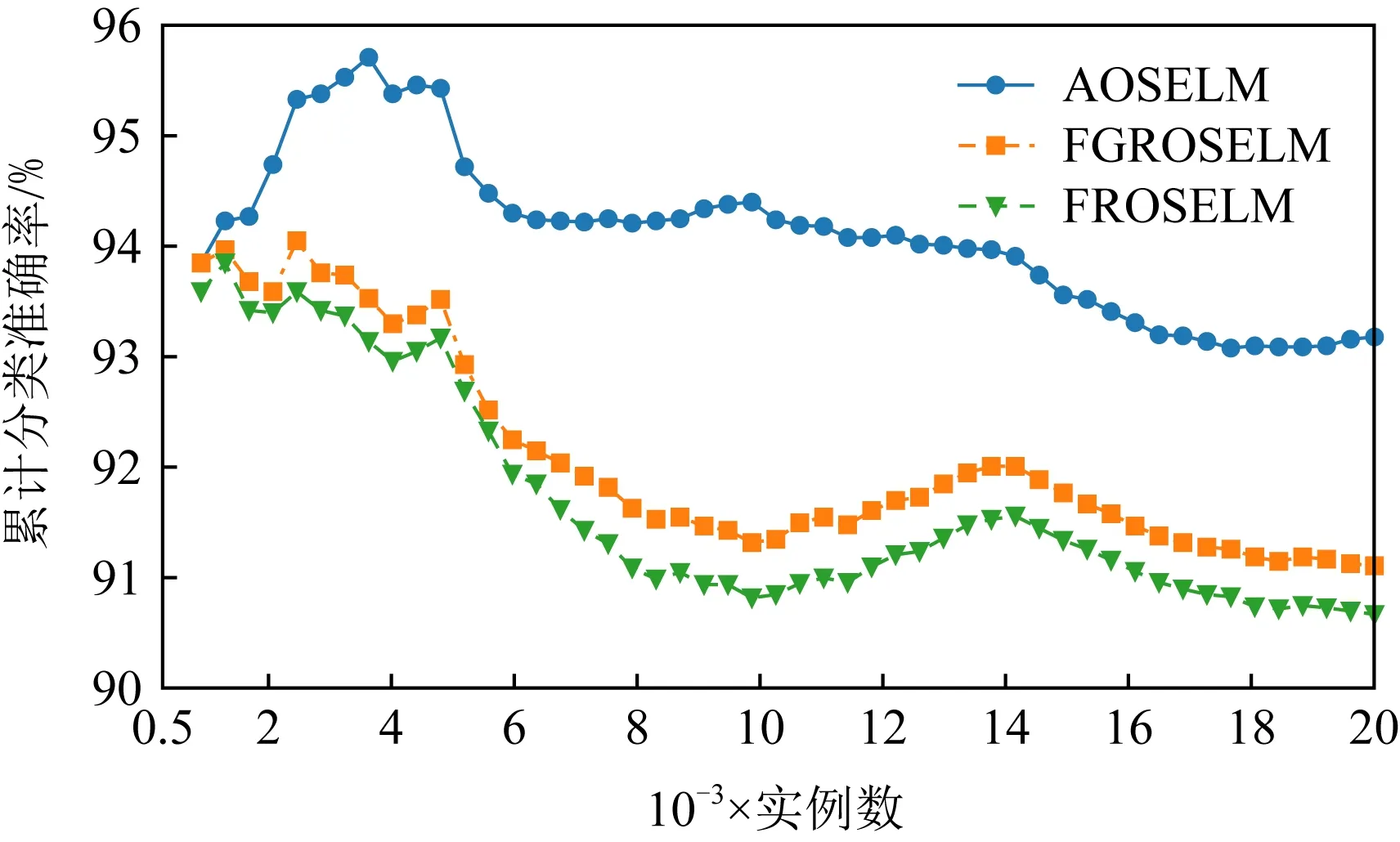
Fig. 9 Cumulative classification accuracy of OSELM optimization algorithm on SEAm圖9 OSELM優化算法在SEAm上的累計分類準確率
圖10~13分別展示了全部7種對比算法和具有遺忘機制的3種OSELM優化算法在Sine數據集上的分類準確率和累計分類準確率.從圖10~13中可以看出,當出現反轉型概念漂移時,ROSELM,OSELM,HT,NB這4種算法由于不具備遺忘機制,因此完全無法適應反轉型概念漂移,整體分類性能也非常糟糕.而具有遺忘機制的AOSELM,FGROSELM,FROSELM這3種算法在面對反轉型概念漂移時均能做出有效反應,適應新概念.其中,AOSELM算法又比另外2種算法具有更高的分類準確率以及更快的概念漂移適應能力.當檢測到發生概念漂移時,AOSELM算法能夠自適應地調小遺忘因子λ,可以更快地遺忘舊概念,從而具有更高的整體分類準確率,實驗結果顯示比FGROSELM和FROSELM算法高大約3%.
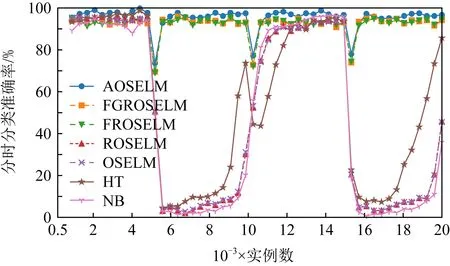
Fig. 10 Classification accuracy of contrast algorithm on Sine圖10 對比算法在Sine上的分類準確率
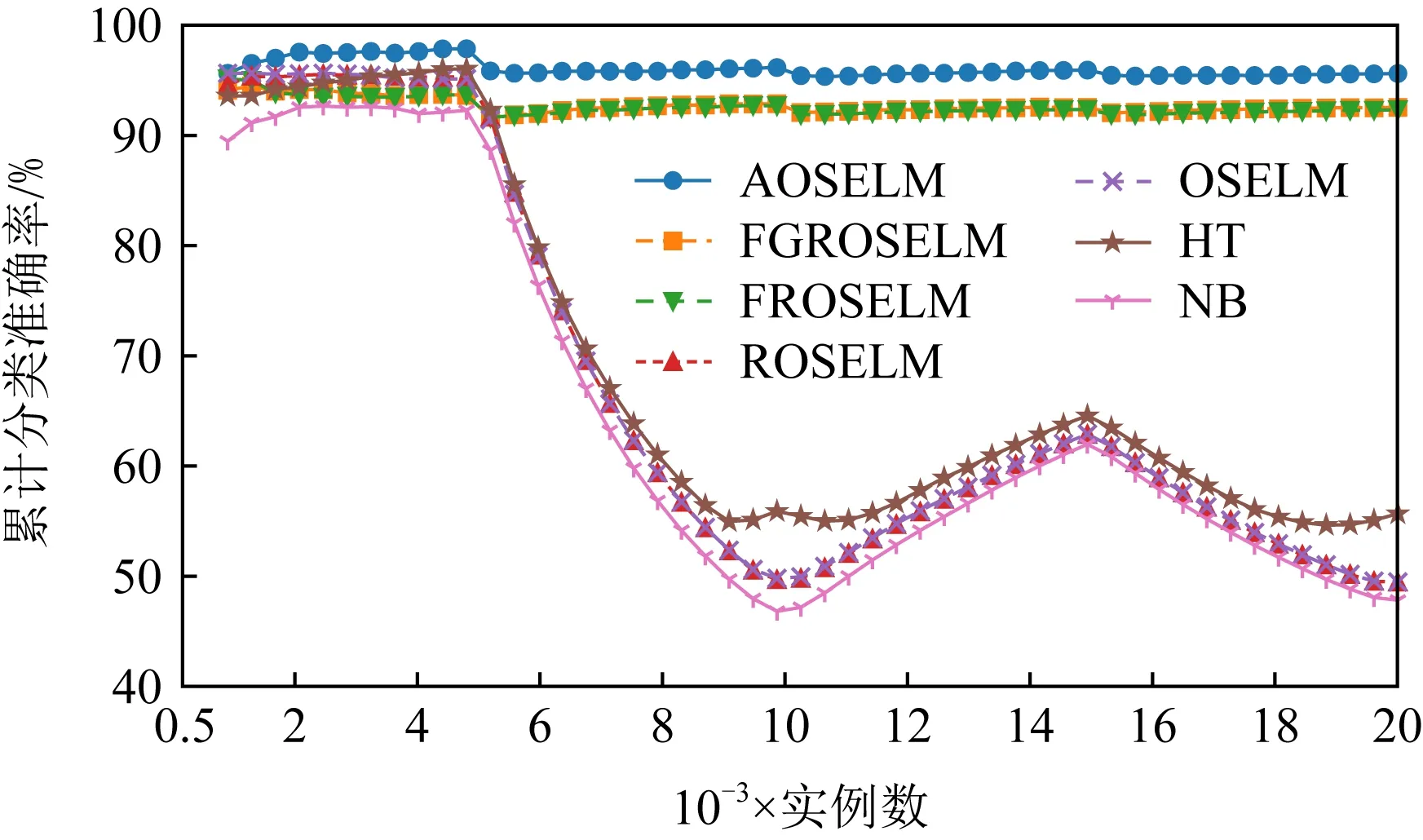
Fig. 11 Cumulative classification accuracy of contrast algorithm on Sine圖11 對比算法在Sine上的累計分類準確率
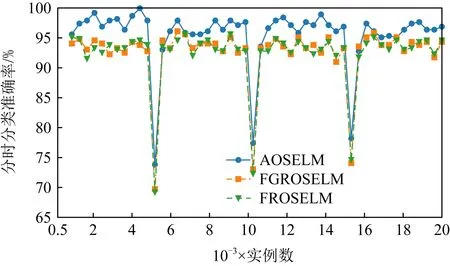
Fig. 12 Classification accuracy of OSELM optimization algorithm on Sine圖12 OSELM優化算法在Sine上的分類準確率
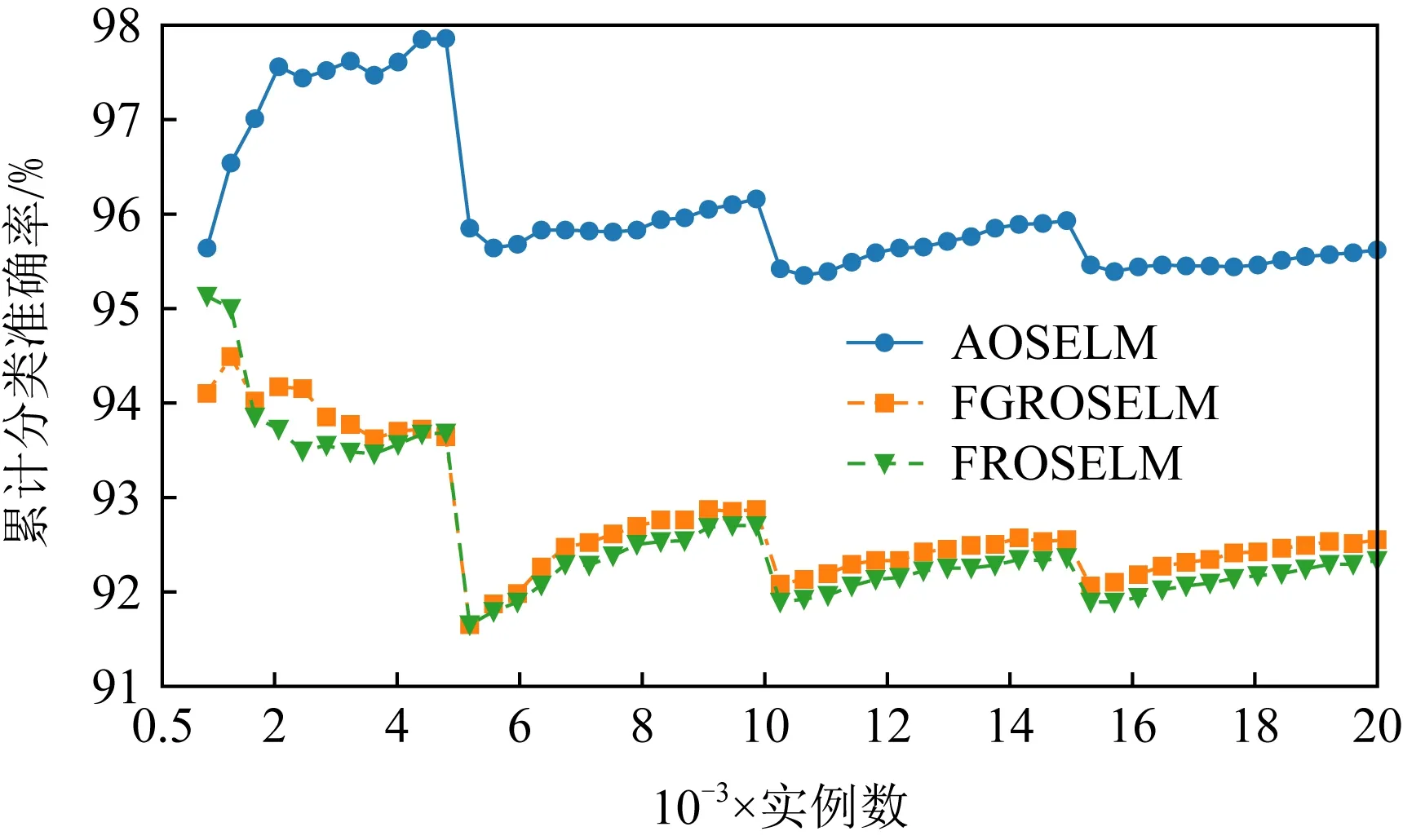
Fig. 13 Cumulative classification accuracy of OSELM optimization algorithm on Sine圖13 OSELM優化算法在Sine上的累計分類準確率
表2、圖14和圖15展示了AOSELM算法和對比算法在不同數據集上的平均分類準確率.從表2中可以看出,在5個人工數據集上,AOSELM均展示了更好的分類性能,分類準確率比其他對比算法提高明顯.尤其是在反轉型數據集Sine和Mixed上,不具備遺忘機制的ROSELM,OSELM,HT,NB這4種算法表現十分糟糕,而AOSELM卻仍然能保持很高的預測準確率.相比另外2種具有遺忘機制的FGROSELM和FROSELM算法,AOSELM也能提高2~3%.
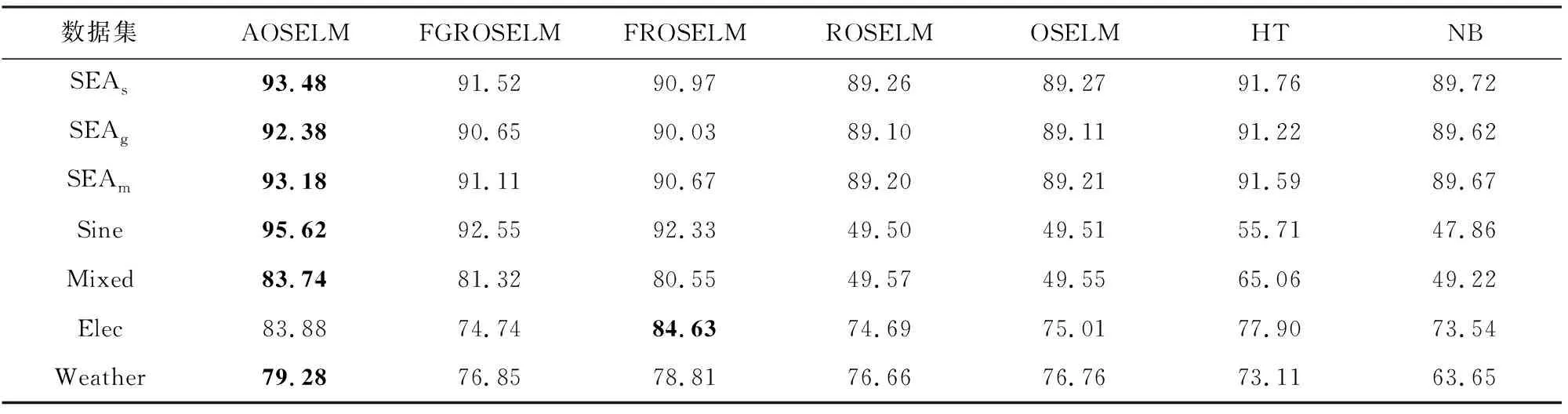
Table 2 Classification Accuracy of Contrast Algorithms on Different Data Sets表2 對比算法在不同數據集上的分類準確率 %
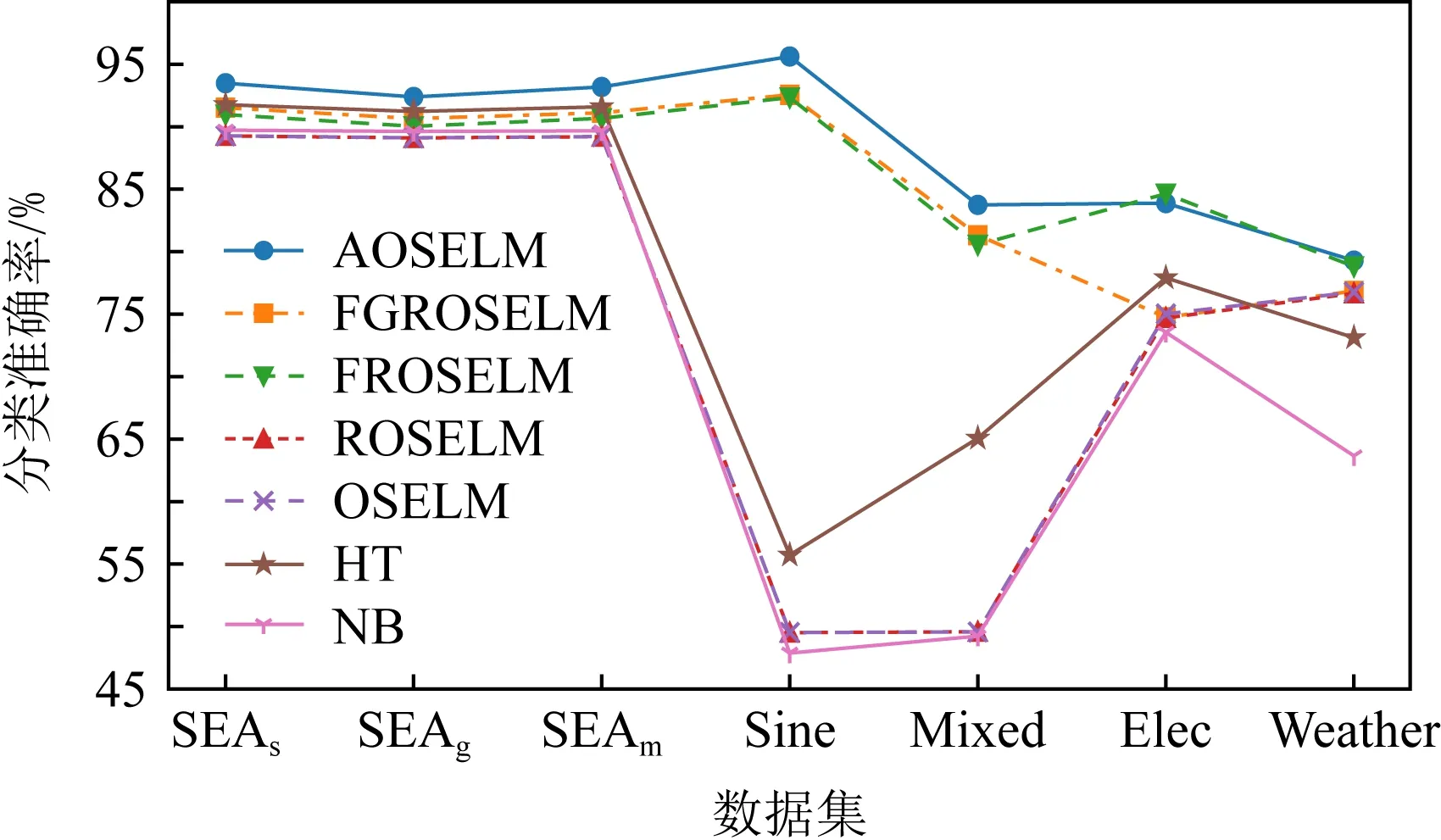
Fig. 14 Classification accuracy of contrast algorithm on different data sets圖14 對比算法在不同數據集上的分類準確率

Fig. 15 Classification accuracy of OSELM optimization algorithm on different data sets圖15 OSELM優化算法在不同數據集的分類準確率
但在2個人工數據集上,AOSELM算法雖然比多數對比算法具有明顯性能優勢,但與FROSELM算法表現相當,并未能取得更高的分類準確率.針對這種情況,畫出人工數據集Sine、真實數據集Elec和Weather的概念漂移指數ICD監控過程圖,如圖16~18所示.
圖16~18分別展示了人工數據集Sine、真實數據集Elec以及真實數據集Weather的概念漂移監控過程圖.對比可以發現,在人工數據集中,概念漂移是明確發生的,且在非概念漂移位置,數據流是穩定的,概念漂移指數ICD也基本穩定在[-1, 0]之間.而在真實數據集Elec和Weather中,數據流一直處于混亂的狀態,概念漂移指數ICD一直在-1上下波動,同時沒有明確的概念漂移發生點,并不能激活AOSELM算法中的自適應遺忘因子和概念漂移檢測機制.這解釋了為何AOSELM算法沒有比FROSELM算法在真實數據集上具有更好的分類性能.
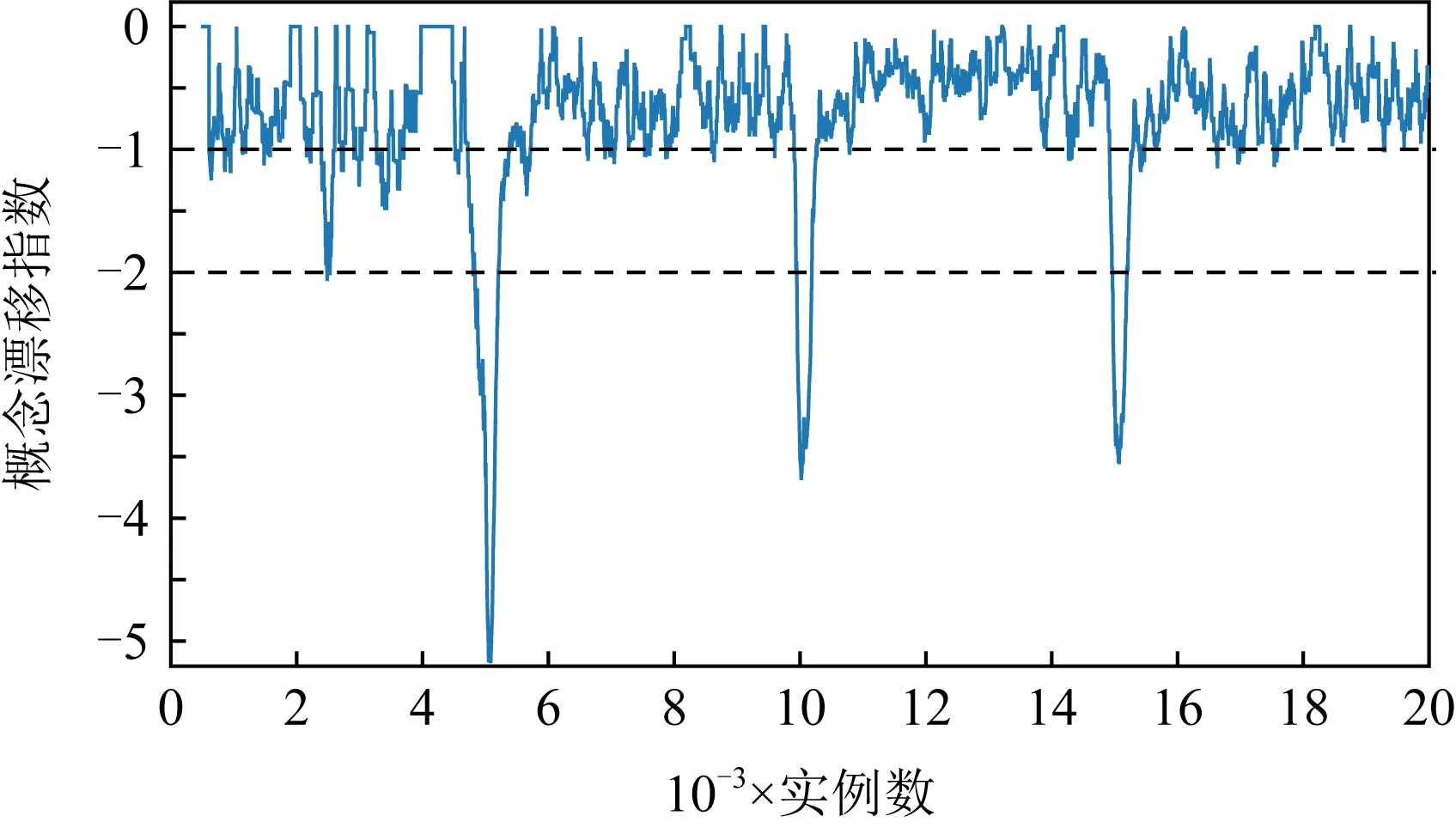
Fig. 16 Concept drift monitoring diagram on Sine圖16 人工數據集Sine概念漂移監控過程圖
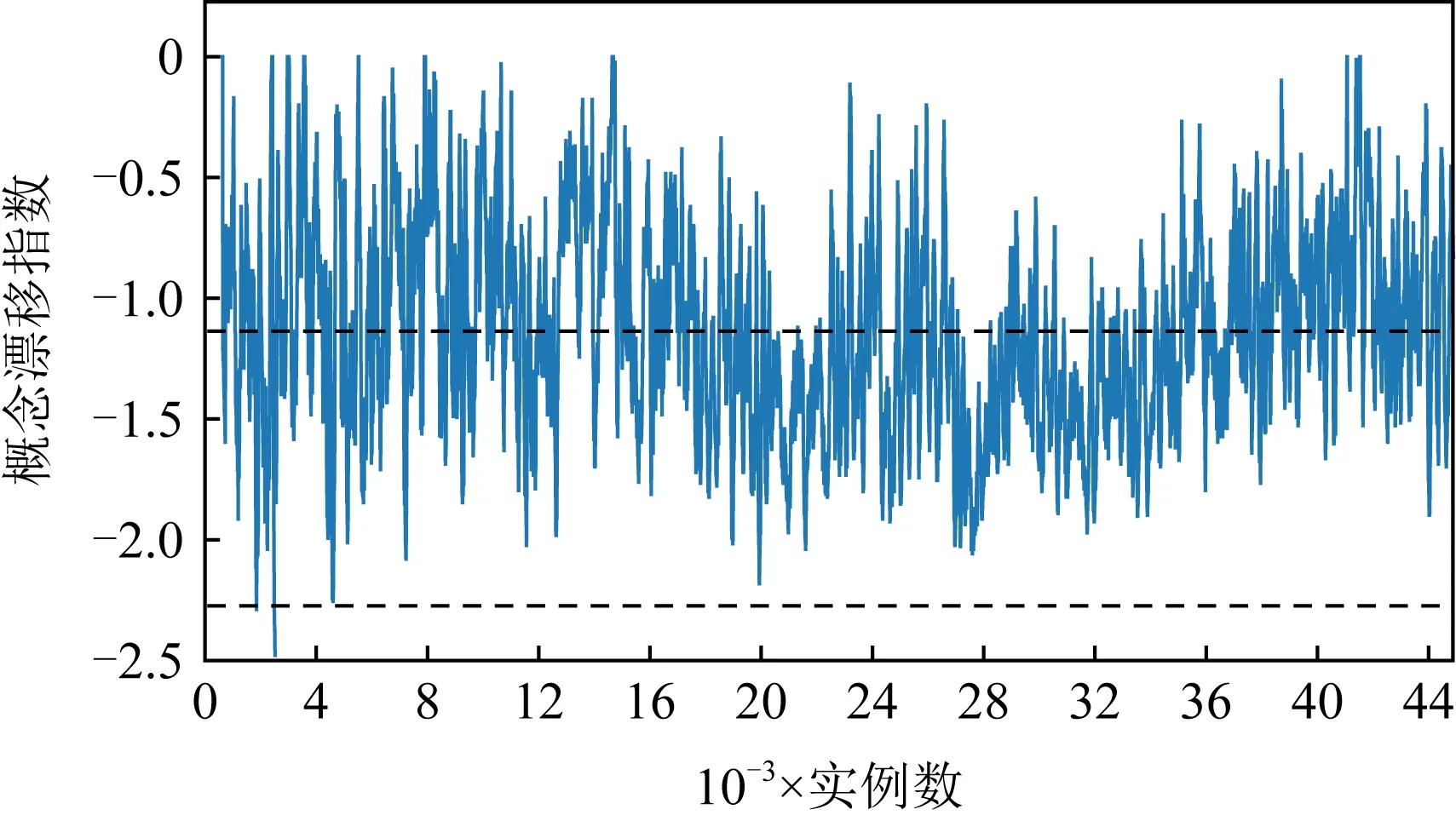
Fig. 17 Concept drift monitoring diagram on Elec圖17 真實數據集Elec概念漂移監控過程圖
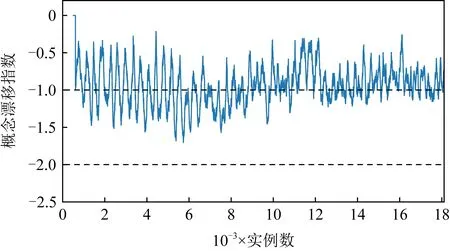
Fig. 18 Concept drift monitoring diagram on Weather圖18 真實數據集Weather概念漂移監控過程圖
3.5 算法機制分析
本節通過消融實驗來測量AOSELM算法所引入的自適應模型復雜度(AMC)、自適應遺忘因子和概念漂移檢測(AFF)以及異常點檢測(OD)這3種機制的效果.在消融實驗中,通過將AOSELM算法中省略機制相應的模塊,得到AOSELM_del_AMC,AOSELM_del_AFF,AOSELM_del_OD這3種算法,然后對比性能.
圖19~22分別展示了消融實驗在SEAm和Sine數據集上的分類準確率和累計分類準確率.從圖19~22中可以發現,當刪除了AMC機制后,AOSELM_del_AMC算法在在線學習的初始階段性能表現較差.而當刪除了AFF機制后,AOSELM_del_AFF算法在面對概念漂移時適應的速度最慢,整體性能也更容易受到概念漂移的影響,尤其在Sine數據集發生反轉型概念漂移時,分類器整體性能損失非常大.
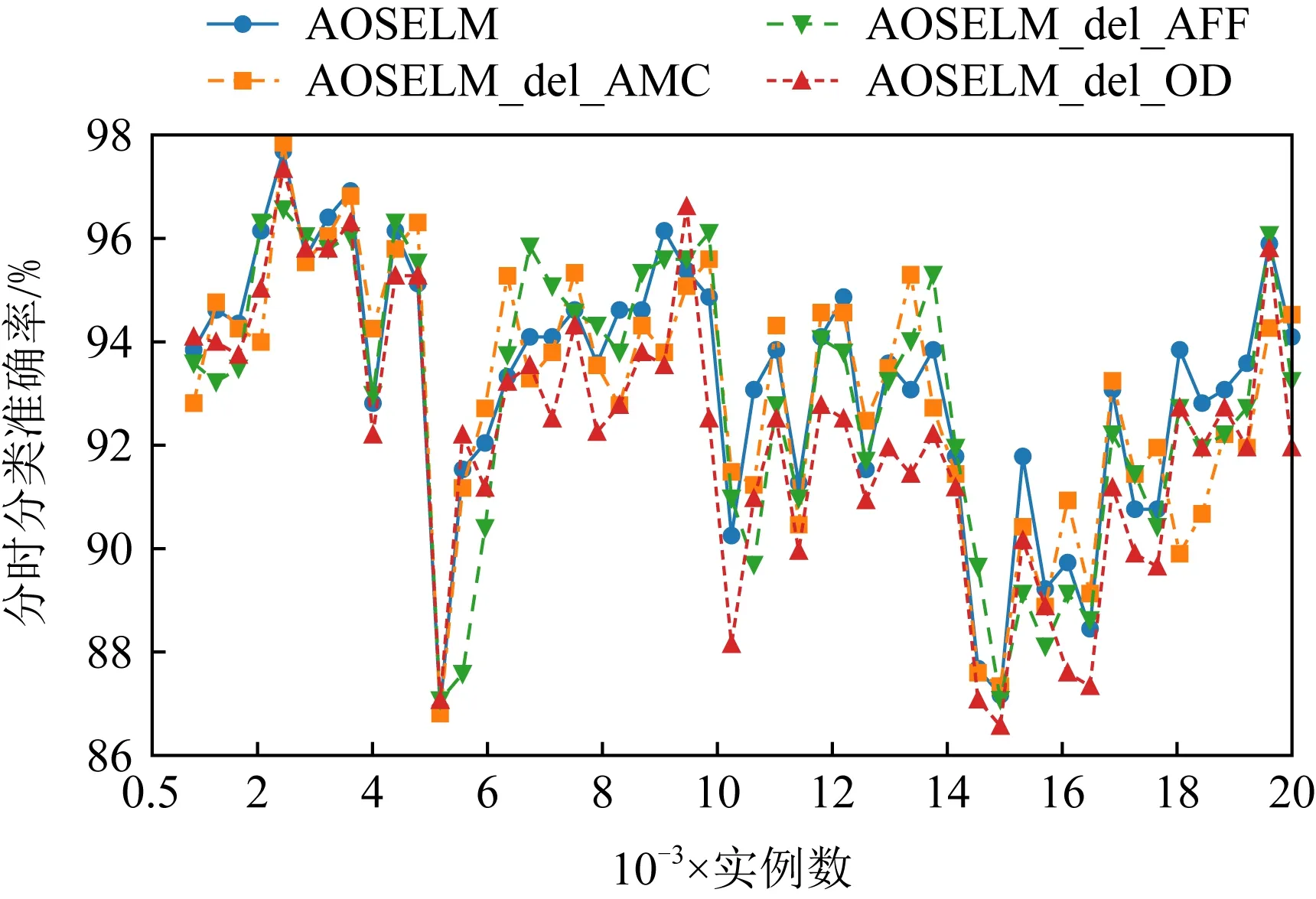
Fig. 19 Classification accuracy of ablation experiment on SEAm圖19 消融實驗在SEAm上的分類準確率
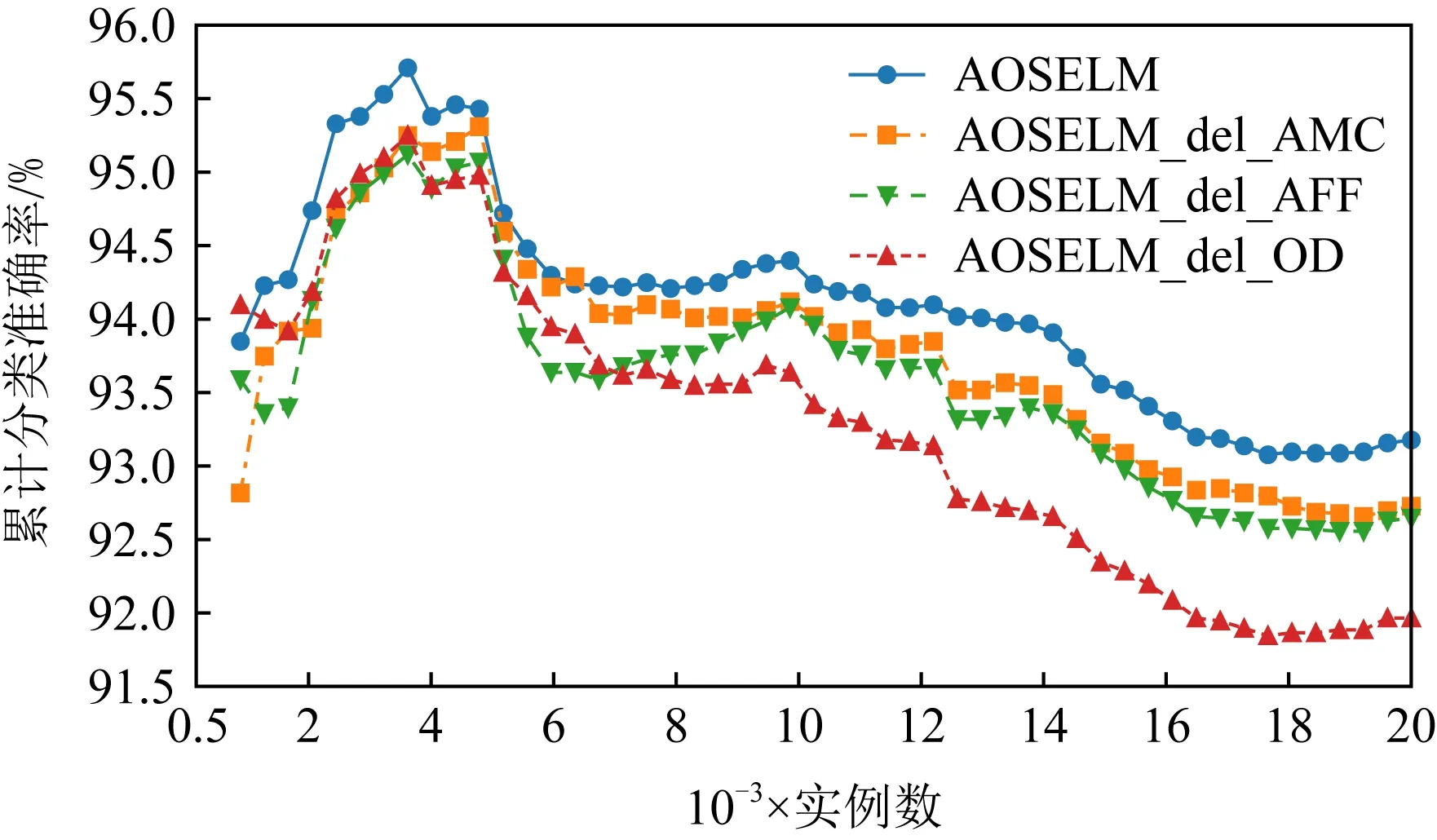
Fig. 20 Cumulative classification accuracy of ablation experiment on SEAm圖20 消融實驗在SEAm上的累計分類準確率
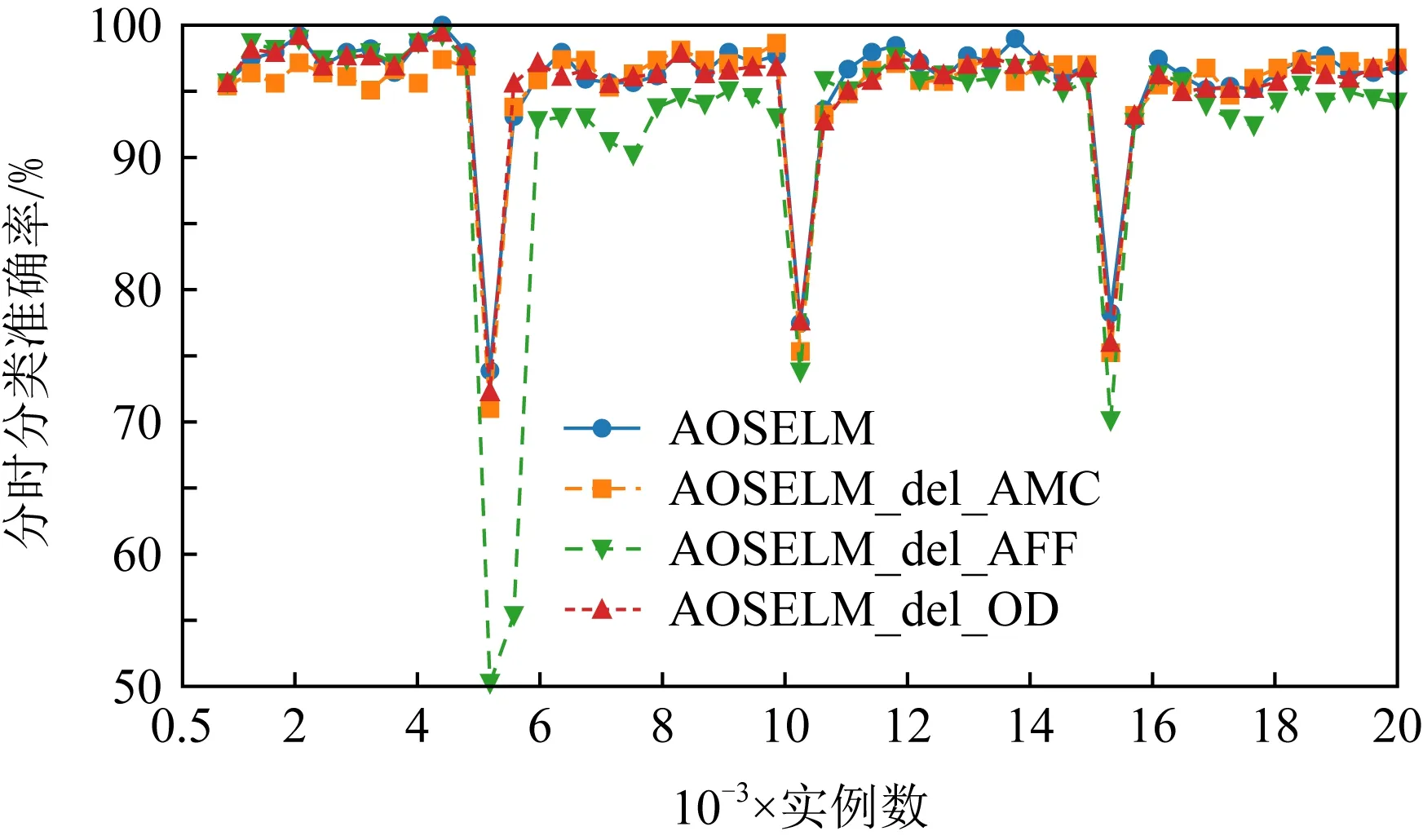
Fig. 21 Classification accuracy of ablation experiment on Sine圖21 消融實驗在Sine上的分類準確率

Fig. 22 Cumulative classification accuracy of ablation experiment on Sine圖22 消融實驗在Sine上的累計分類準確率
表3和圖23展示了消融實驗在不同數據集上的平均分類準確率.實驗結果表明:AOSELM算法引入的自適應模型復雜度(AMC)、自適應遺忘因子和概念漂移檢測(AFF)以及異常點檢測(OD)這3種機制均起到了很好的效果,在人工數據集上均提高了分類器的分類準確率.

Table 3 Classification Accuracy of Ablation Experiment on Different Data Sets
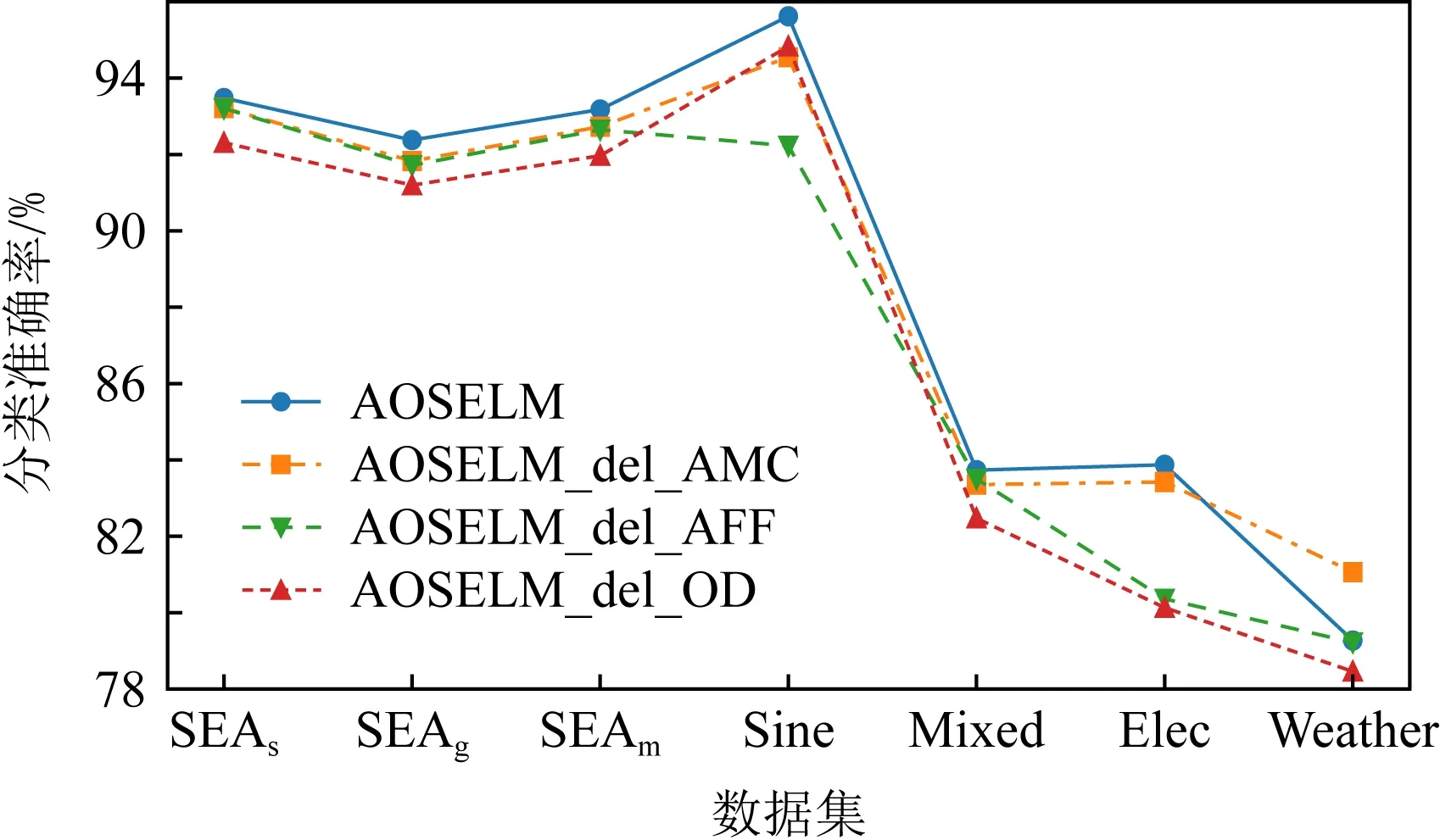
Fig. 23 Classification accuracy of ablation experiment on different data sets圖23 消融實驗在不同數據集上的分類準確率
3.6 算法效率分析
在線學習要求分類算法能及時反饋分類結果,為了驗證AOSELM算法的分類效率,實驗統計了AOSELM算法的時間開銷,并與原始的OSELM算法進行對比.實驗結果為重復10次實驗的平均值,如表4所示:
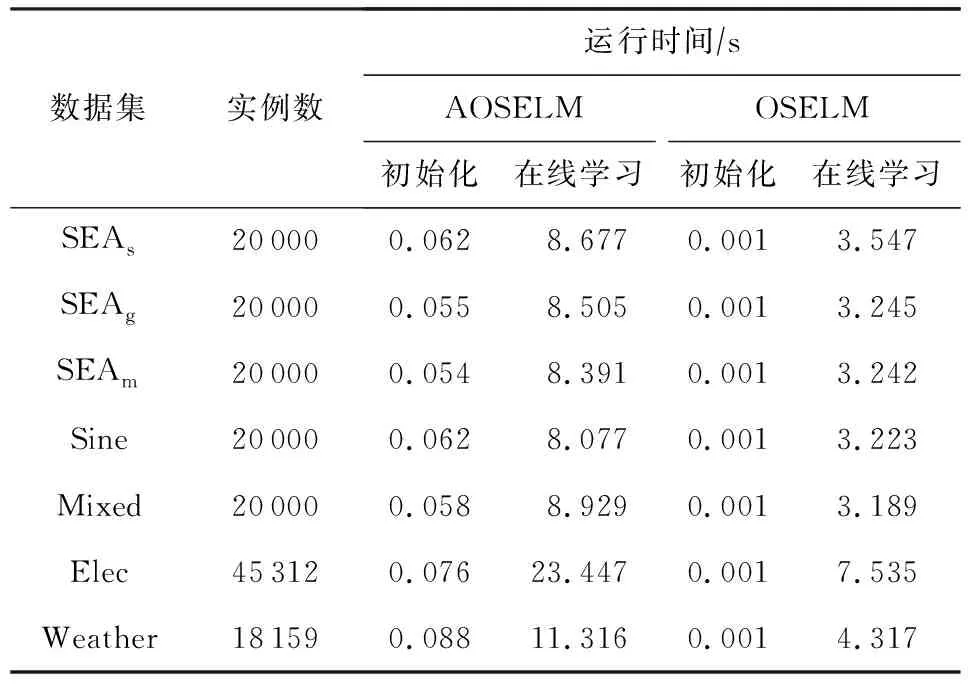
Table 4 Running Time of Contrast Algorithms on Different Data Sets
從表4中可以看出,在初始化階段,AOSELM算法由于引入AMC機制,運行時間比原始OSELM算法高出50倍以上,但由于用于訓練的實例數占比很小,因此初始化階段的時間消耗在整體上可以忽略.在線學習階段,AOSELM算法的運行時間為OSELM算法的2~3倍.此外,AOSELM算法的預測準確率越高,運行時間相比OSELM的倍數越低,驗證了AOSELM算法的時間復雜度與模型預測錯誤率成正比.
4 總 結
本文提出了一種自適應在線順序極限學習機(AOSELM)算法,其基于在線學習方式,引入了自適應模型復雜度機制、自適應遺忘因子和概念漂移檢測機制以及異常點檢測機制,從而可以在動態變化的數據流環境下應對多種類型的概念漂移.通過自適應模型復雜度機制,在初始化階段可以自適應確定出最佳的隱含層節點數Nh,并加入正則項,優化模型復雜度.其次通過自適應遺忘因子和概念漂移檢測機制,將概念漂移和遺忘因子結合,使分類模型在發生概念漂移時自動調小遺忘因子,而在數據流穩定時自動調大遺忘因子,從而適應數據流的動態變化.最后通過異常點檢測機制,增強模型抗噪音能力,使分類的決策邊界不易被異常點破壞.因此,AOSELM算法能夠自適應地在線處理各種類型的概念漂移數據流.
在仿真實驗部分,通過參數敏感性分析驗證了隱含層節點數Nh和遺忘因子λ對模型分類性能的影響,解釋了引入自適應模型復雜度機制與自適應遺忘因子和概念漂移檢測機制的動機.然后在對比實驗中,通過將AOSELM算法與其他6個數據流分類器進行對比,驗證了AOSELM算法的有效性,尤其是在5個人工數據集上,AOSELM算法表現出了更穩定、更準確的分類效果.最后,通過消融實驗驗證所引入AMC,AFF,OD這3種機制的效果,證實了3種機制對AOSELM算法性能提升的有效性.然而,如何解決更復雜的真實數據流分類問題仍然是研究的難點,下一步工作將結合代價敏感學習和在線集成方法解決概念漂移數據流中的復雜分布問題.
作者貢獻聲明:蔡桓提出了算法思路并撰寫論文;陸克中提出了實驗方案;伍啟榮負責完成實驗;吳定明提出指導意見并修改論文.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
現代裝飾(2022年1期)2022-04-19 13:47:32
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
現代裝飾(2020年2期)2020-03-03 13:37:44
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·高一版(2018年9期)2018-10-09 06:46:48
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
中學生數理化·高一版(2017年9期)2017-12-19 12:15:14
