基于輕量級全連接網絡的H.266/VVC 分量間預測
2022-03-10 09:25:16霍俊彥王丹妮馬彥卓萬帥楊付正
通信學報 2022年2期
霍俊彥,王丹妮,馬彥卓,萬帥,楊付正
(1.西安電子科技大學ISN 國家重點實驗室,陜西 西安 710071;2.西北工業大學電子信息學院,陜西 西安 710072)
0 引言
隨著信息互聯網迅猛發展和智能移動終端廣泛普及,海量視頻信息不斷涌現。4K/8K 超高清視頻、全景視頻、短視頻等新興視頻業務層出不窮。視頻業務的蓬勃發展給傳輸帶寬帶來了巨大的挑戰。以提高視頻壓縮效率為目標的視頻壓縮編碼技術一直是學術界和工業界研究的熱點。近期,遠程辦公和在線教育需求激增,在有限的網絡帶寬條件下提供高質量視頻服務尤其迫切。
2020 年8 月,由隸屬于ISO/IEC的MPEG 組和隸屬于ITU-T的VCEG 組成立的聯合視頻專家組(JVET,joint video experts team)完成了新一代視頻編碼標準H.266/通用視頻編碼(VVC,versatile video coding)[1]的制定。除傳統視頻外,該標準還可實現超高清視頻[2]、360 視頻[3]和寬動態視頻[4]的高效壓縮編碼。相比于上一代視頻編碼標準H.265/高效視頻編碼(HEVC,high efficiency video coding)[5],H.266/VVC 在保證相同視頻圖像質量的前提下,可節省近50%的碼率,代表了當前視頻編碼技術的最高水平。
H.266/VVC 沿用基于塊的預測編碼、變換編碼和熵編碼的混合編碼框架,其卓越的壓縮性能歸因于在各個模塊引入了大量新的編碼技術[6-7]。其中,在塊劃分上,H.266/VVC 擴大編碼樹單元(CTU,coding tree unit)尺寸,并允許采用二叉樹、三叉樹和四叉樹對CTU 進行迭代劃分得到編碼單元(CU,coding unit)[8],同時,支持亮度色度獨立劃分CU[6]。對于幀內預測模塊,H.266/VVC擴展了角度預測模式,并新增了基于矩陣的幀內預測(MIP,matrix-based intra prediction)技術[9]、幀內子塊劃分技術[10]及分量間線性模型(CCLM,cross-component linear model)預測技術[11]。對于幀間預測模塊,H.266/VVC 引入仿射運動補償技術[12]、幾何劃分技術[13]、雙向光流補償技術[1]等新技術。上述技術旨在提高預測塊的準確度,降低預測殘差。之后在對預測殘差進行處理的模塊中,H.266/VVC 通過新增多核變換[14]、低頻不可分變換[15]和子塊變換[14]等技術優化變換模塊,同時通過擴展量化參數范圍、增添依賴量化技術來優化量化模塊。此外,為了進一步改善視頻編碼質量,在環路濾波模塊中,H.266/VVC 引入自適應環路濾波技術[16]。
眾所周知,基于神經網絡(NN,neural network)的算法在計算機視覺任務上取得了巨大成功,已廣泛應用于圖像分類[17]、目標檢測[18]、圖像增強[19]等領域。近年來,NN 逐漸滲透到視頻編碼領域,成為進一步提高壓縮效率的有效手段[20-21]。基于NN的視頻編碼大致可分為2 個方向。第一類是基于NN 建立全新的視頻編碼框架,具體分為基于NN的圖像編碼和基于NN的視頻編碼。Minnen 等[22]提出的基于自編碼器的圖像壓縮網絡是典型的面向圖像的編碼方案,通過變換網絡及熵模型網絡進行圖像壓縮,有效去除空間冗余。基于NN的視頻編碼方案采用網絡實現運動估計和補償。以深度視頻壓縮(DVC,deep video compression)模型為例,該模型采用光流估計網絡獲取幀間運動信息,通過基于自編碼器的網絡對運動信息和殘差信息壓縮,達到有效去除時空冗余的目的。第二類是在傳統編碼框架內利用NN 設計新的編碼工具,具體可針對現有框架中的幀內預測、幀間預測、分量間預測、概率分布預測、變換、環路濾波、上/下采樣等技術進行改進,取代傳統框架中對應的工具或引入新的工具,實現更高的壓縮效率。深度學習視頻編碼(DLVC,deep learning video coding)模型通過在傳統編碼框架中引入多項深度編碼工具提升了傳統框架的壓縮效率。上述算法可利用現有NN,如多層感知器(MLP,multi layer perceptron)、隨機神經網絡、卷積神經網絡(CNN,convolutional neural network)、遞歸神經網絡(RNN,recurrent neural network)和生成式對抗網絡(GAN,generative adversarial network)等,根據視頻編碼的特性進行網絡架構設計,已展現出了在視頻編碼領域的可期前景。總之,一方面,NN 具有強大的非線性擬合能力,可有效提高視頻壓縮效率;另一方面,NN 計算復雜度相當高,在與傳統編碼框架結合時需要在編碼性能與復雜度之間進行優化和折中,如H.266/VVC 已采納的MIP 技術就是源于NN 設計并合理簡化后的幀內預測算法,這為在傳統視頻編碼框架下開展基于NN的算法設計提供了可行思路。本文重點針對NN與分量間預測結合的內容展開研究,已有算法的詳細介紹見1.2 節。
本文面向H.266/VVC,提出一種基于輕量級NN的分量間預測(NNCCP,neural network based cross-component prediction)算法,通過NN 構造準確度高的色度預測值,從而提高視頻壓縮效率。通常,在圖像的局部區域內,若像素間亮度差值越小,像素相關性越強,其色度相關性也越強。基于該現象,本文利用亮度差值,從參考區域中提取固定數量的參考像素組成參考子集。進一步將該參考子集與待預測像素的亮度差向量和該參考子集的參考色度向量輸入色度預測模塊構造色度預測值。由于參考子集的元素數量固定,色度預測模塊可針對H.266/VVC 各種尺寸的CU 使用統一的神經網絡進行處理。將 NNCCP 集成至H.266/VVC 參考軟件VTM10.0[23],并通過實驗驗證其編碼性能的提升。實驗結果表明,NNCCP 算法可提高色度預測準確度,有效提升H.266/VVC的壓縮效率。
1 相關研究
1.1 H.266/VVC 高效色度幀內預測
H.266/VVC的色度幀內預測算法大致可分為三類,第一類為默認傳統預測模式,包括PLANAR、DC、水平和垂直4 種模式,原理是根據前面已編碼塊的重建色度預測當前塊的色度分量;第二類為亮度推導模式,該模式借用對應位置亮度的幀內預測模式作為色度的幀內預測模式;第三類為H.266/VVC 新引入的CCLM 模式,該模式利用同位置的重建亮度值通過線性模型計算色度預測值。通常,YCbCr 顏色空間的各個分量之間存在較強的相關性,如圖1 所示。因此,利用分量間相關性設計算法是提高壓縮效率的有效手段,上述第二類和第三類色度幀內預測模式皆是基于分量間相關性所設計的。
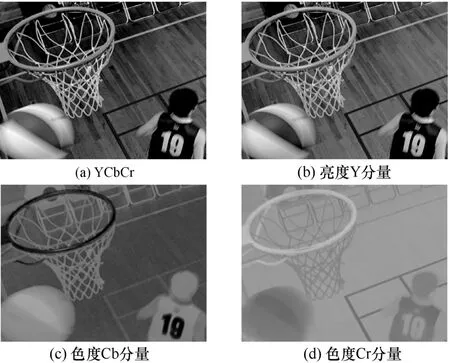
圖1 BasketballDrill 序列YCbCr 圖像和三分量
H.266/VVC的CCLM 技術是基于圖像局部區域內亮度與色度呈線性關系的假設提出的,CCLM預測過程如圖2 所示,對于當前CU,其參考區域為當前CU的上、右上、左和左下的像素。在對當前CU 進行編碼之前,參考區域的亮度和色度均已重建。CCLM 首先利用參考區域的重建亮度和重建色度建立線性模型;然后根據該線性模型和當前CU的重建亮度信息求解出當前CU的色度預測值。需要指出的是,針對YCbCr 4:2:0 采樣格式的視頻,亮度圖像需進行下采樣,從而與色度圖像的分辨率一致。
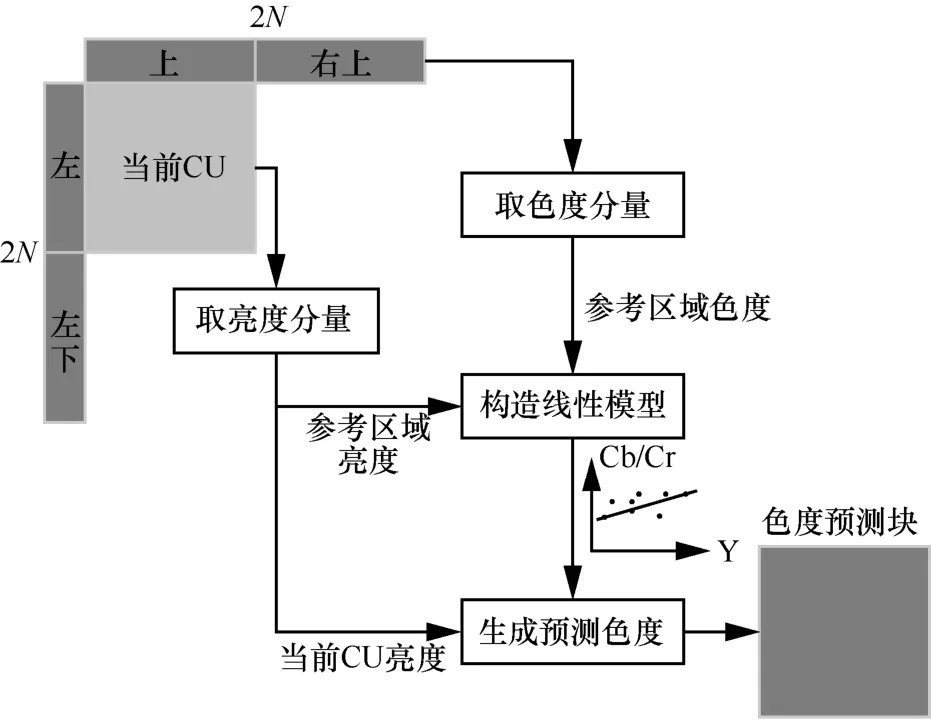
圖2 CCLM 預測過程
CCLM 算法在H.266/VVC 中的整體性能[24]如表1 所示。在相同重建視頻質量下,CCLM 可為Y、Cb、Cr 分量分別節省1.54%、13.89%、14.76%的編碼碼率。在復雜度方面,H.266/VVC 官方提供了使用CCLM 算法與不使用CCLM 算法的時間占比,編碼時間和解碼時間幾乎相同。該數據進一步驗證了分量間預測的簡單有效性。
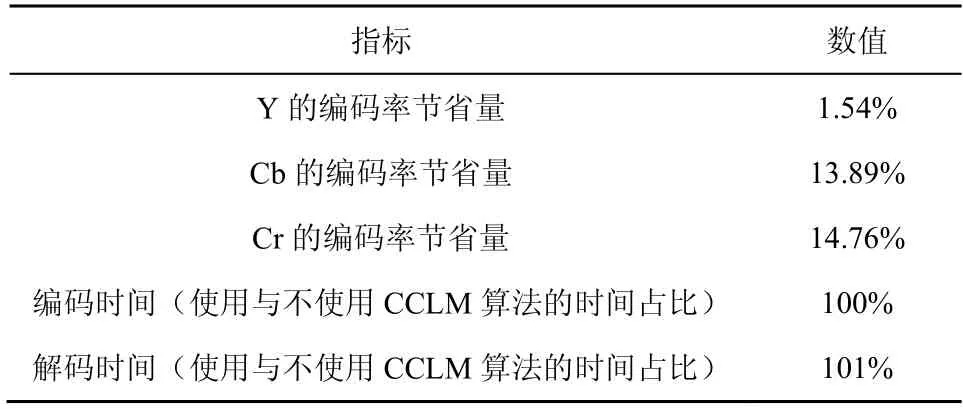
表1 CCLM 算法在H.266/VVC 中的整體性能
為了充分利用分量間相關性,CCLM 算法歷經數次演進。Lee 等[11]揭示了YCbCr 4:2:0 采樣格式的分量間仍存在冗余,可使用分量間線性模型設計色度預測算法。考慮到編碼塊內容的多樣性,Zhang等[25]提出了基于多分段線性模型的分量間預測技術。出于對復雜度和編碼性能的綜合考慮,H.266/VVC 采納了單線性模型的CCLM 技術[26]。為了提高CCLM 預測準確度,H.266/VVC 引入了3 種線性模型[27],通過率失真準則為當前CU 選取最優線性模型。同時,H.266/VVC 在保證編碼性能的前提下對CCLM 進行了復雜度優化。Laroche 等[28]提出基于參考區域的最大/最小值構造線性模型參數的算法,該算法可顯著降低復雜度。進一步,筆者前期在分析像素歐氏距離與相關性關系的基礎上,提出基于參考像素位置構造模型參數的算法[29]。該算法在降低CCLM 計算復雜度的同時引入少量編碼增益,被H.266/VVC 采納。
1.2 基于神經網絡的色度幀內預測
事實上,亮度與色度之間的關系往往是復雜的。圖3 以BasketballDrill 序列中2 個不同內容的圖像塊為例,給出了亮度分量與色度分量的對應關系。由圖3 可以看出,圖像塊內亮度與色度分量的關系復雜,僅利用簡單的線性模型很難處理圖像塊內所有的情況。同時,由于圖像內容多樣,不同內容圖像塊的亮度與色度的相關性也不同,且與內容有關。因此,亮度進行簡單的映射通常不能實現準確的色度預測。得益于NN 強大的建模能力,基于NN的分量間預測成為提高色度壓縮效率的研究熱點。
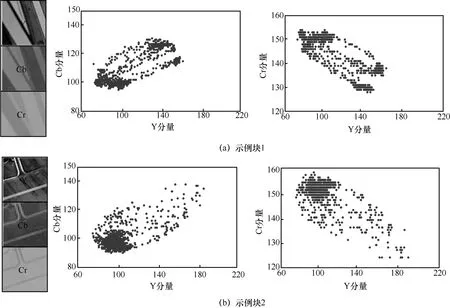
圖3 YUV 空間下亮度分量與色度分量的散點圖圖像(YCbCr 4:2:0 格式)
Blanch 等[30]通過引入基于卷積網絡的注意力模塊來建立參考像素和待預測像素之間的關系。Zhu 等[31]提出以CTU 為單位的色度預測方法,充分利用空間和分量間相關性,同時將量化參數(QP,quantization parameter)作為邊信息輸入,進一步提高預測準確度,降低預測誤差。Li 等[32]通過基于卷積網絡和全連接網絡的混合神經網絡改進色度預測性能。縱覽以上各個方案,基于NN 構造色度預測值,尤其是CNN,可更好地使用非線性函數表示亮度與色度之間的映射關系。然而,現有算法通常需要針對不同的編碼參數(例如QP、編碼尺寸等)訓練不同的網絡參數,這在實際視頻編碼系統中是難以應用的。此外,基于CNN的色度預測算法通常具有極高的復雜度,其解碼端復雜度相比于傳統預測算法成倍增加。對編碼參數的依賴和極高的復雜度導致基于CNN的分量間預測算法在實際應用上受到了極大限制。
近期,繼H.266/VVC 標準發布后,JVET 著手開展基于NN 視頻編碼的探索性研究。實用化的基于NN的分量間預測算法也屬于其中一個重要的議題:一方面,成熟的CCLM 算法通過建立簡單的線性模型來表示整個CU 亮度和色度之間的關系,存在較大誤差,性能提升潛力有限;另一方面,已有的基于CNN的色度預測準確度高,但存在復雜度過高的問題,現階段難以實用。
2 基于輕量級NN的分量間預測算法
在視頻編碼中,亮度與色度之間的關系通常局部化到一個編碼塊內討論。不同于采用線性模型的CCLM 算法,基于NN的預測方法通過數據驅動建立亮度與色度之間的非線性映射。筆者通過研究發現,來自局部近鄰的已編碼塊的亮度和色度信息能夠為網絡提供非常重要的先驗信息。因此,本文提出一種基于輕量級NN的分量間預測算法,借助亮度差從參考區域中提取參考子集,從而縮小參與建模的像素規模,即僅采用數個與待預測像素具有較小亮度差的像素進行建模,最終利用輕量級全連接網絡實現色度預測。具體來說,遴選出少量且有效的參考像素,利用網絡對相關性強的像素賦予大權重,而相關性弱的像素則賦予很小或零權重,進而為色度預測提供有效信息,達到降低預測誤差、提高色度壓縮效率的目的,同時滿足視頻編碼對低復雜度的需求。
2.1 NNCCP 算法框架
本文提出的NNCCP 算法框架如圖4 所示,該框架包含數據預處理模塊和色度預測模塊。其中,數據預處理模塊以當前CU的上、右上、左、左下參考區域的參考像素和當前像素的亮度值作為輸入,經過提取參考子集后輸出M×1的亮度差向量和參考色度向量;色度預測模塊將預處理模塊輸出的亮度差向量和參考色度向量作為輸入,通過全連接網絡構造色度預測值。下面介紹NNCCP 算法的詳細過程。
圖4(a)所示的數據預處理模塊包含3 個步驟:向量化、求亮度差和提取。首先將參考區域的像素(包括重建亮度值和重建色度值)進行一維向量化;然后對每個待預測像素i,求解i與參考像素的亮度差;最后從4N個亮度差值中提取出M個亮度差絕對值較小的像素組成參考子集,并得到亮度差向量|ΔY|i,其色度值組成參考色度向量Ci。若參考子集的像素數不足M個,|ΔY|i、Ci各自使用固定值進行填充,補足M個元素。
統計發現,在局部區域內,像素間的亮度差值越小,其相關性越強,色度相關性也越強。本文設計的數據預處理模塊從參考區域中提取出亮度差值小的像素構成參考子集,參考子集中的像素具有與待預測像素相關性強的優點。
圖4(b)所示的色度預測模塊以|ΔY|i和Ci作為輸入,其中,|ΔY|i通過L層全連接網絡后得到權重向量Wi。最終,當前像素的色度預測值為
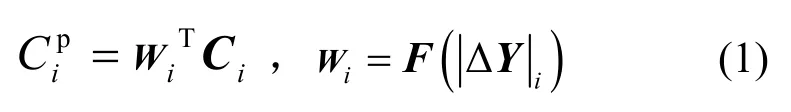
其中,F(·)表示通過NN 學習的映射函數,向量Wi、Ci和|ΔY|i的定義為
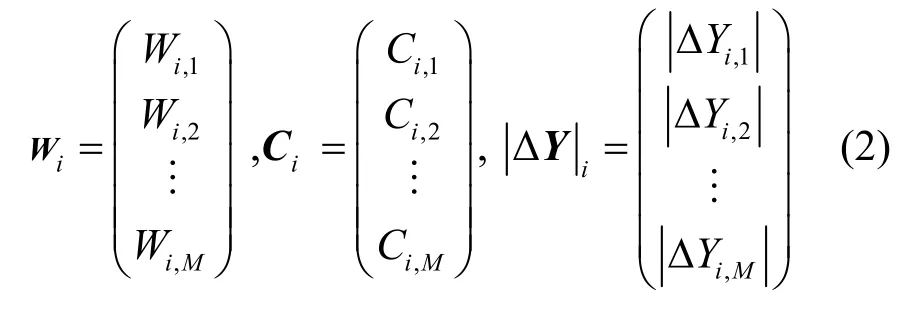
對于圖4(b)中的全連接網絡,網絡從輸入到輸出的描述如下:M維向量|ΔY|i作為第一層的輸入,之后每層進行非線性加權后作為下一層的輸入。非線性加權可表示為
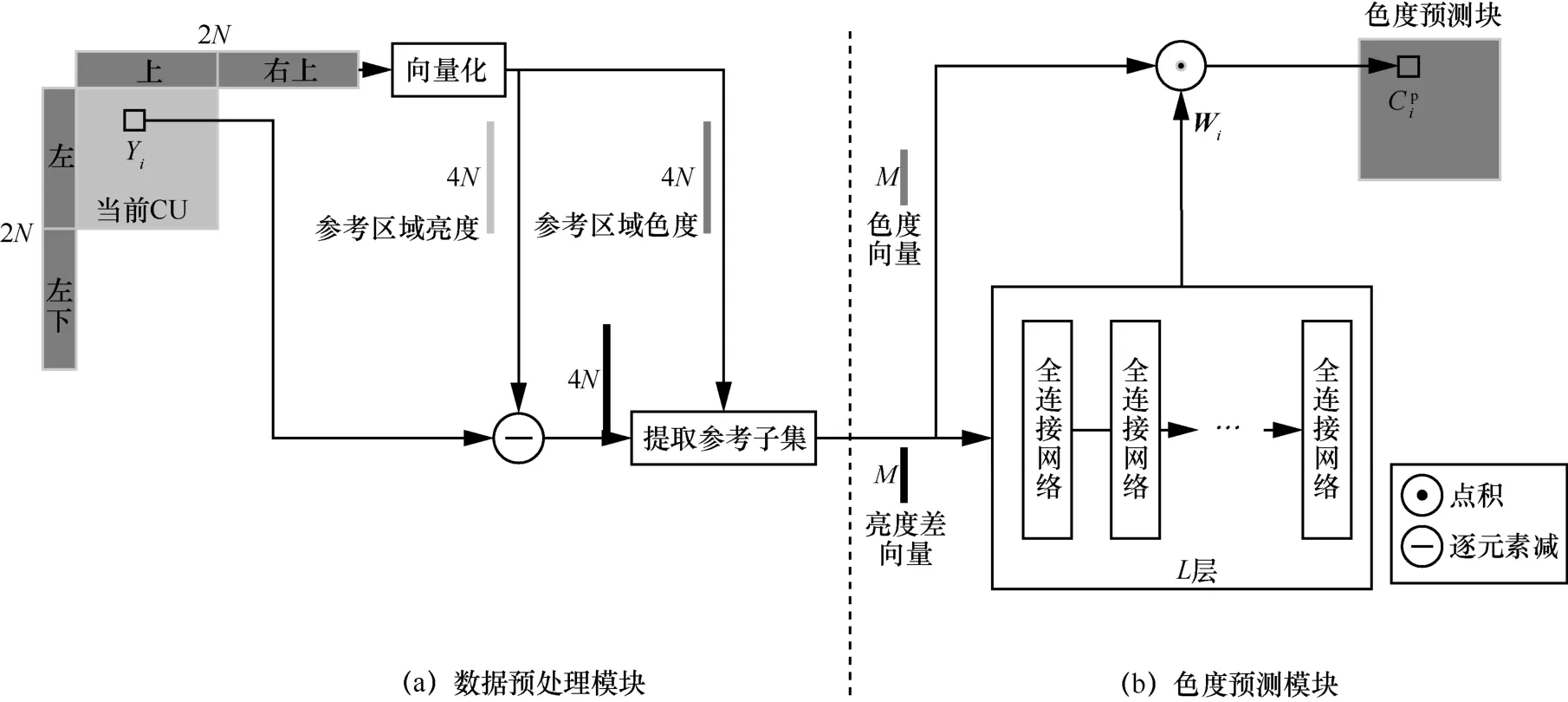
圖4 NNCCP 算法框架
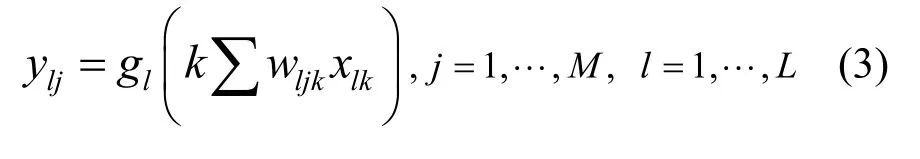
其中,M是每層的神經元個數,L是網絡層數,xlk是第l層的第k個輸入,wljk是第l層的第j個神經元對第k個輸入的權值,gl(·)是第l層的激活函數,ylj是第l層的第j個神經元的輸出結果。由于網絡輸出層的輸出結果為0~1,本文網絡最后一層的激活函數采用歸一化指數函數Softmax,其他層的激活函數均采用修正線性單元ReLU。
2.2 損失函數
理論上,色度預測模塊中全連接網絡的損失函數是輸出權重W與真實權重Wo之間的差距,即
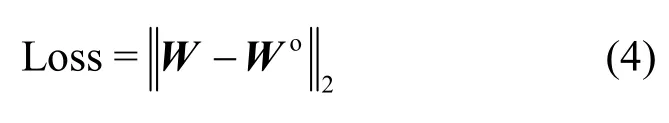
事實上,真實權重難以估計。考慮到NNCCP的目的是得到更準確的預測結果,因此可將色度預測量Cp與色度原始量Co的平方誤差和作為損失函數。
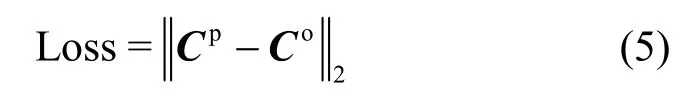
為了提高壓縮效率,通常將預測殘差變換至頻域進行量化和熵編碼。為了有效與視頻編碼結合,接近真實的編碼損失,本文使用離散余弦變換(DCT,discrete cosine transform)。具體地,對預測殘差進行DCT,將其絕對誤差和作為損失函數
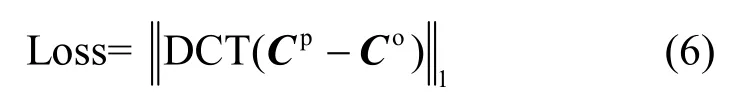
2.3 網絡訓練
本文所提NNCCP 算法基于Pytorch 深度學習框架,實驗環境為64 位Windows10 操作系統,模型采用Adam 優化器,初始學習率和批大小設置為1×10-4和128。
為了驗證本文算法的色度預測性能和泛化性,采用公開的DIV2K[33]數據集作為訓練和驗證的數據來源。具體地,將800 張訓練圖片、100 張驗證圖片均統一裁剪為4×4的塊作為訓練集和驗證集。最優模型參數根據其在驗證集上的色度預測性能來選取。
2.4 H.266/VVC 集成
H.266/VVC 設計成多種使用前面已編碼塊的色度預測當前塊的色度分量的模式,如 DC、PLANAR、各種角度模式等。為了有效應用于視頻編碼框架,進一步提升編碼性能,本文將離線訓練好的NNCCP 模型作為一種新增的色度幀內預測模式,以C++語言集成到H.266/VVC 編解碼器中,與已有的預測模式共存,是對現有色度預測模式的有效補充。集成后,H.266/VVC 色度幀內預測模式包括PLANAR、DC、水平、垂直、亮度推導色度模式、NNCCP 和3 種CCLM,共9 種預測模式。
在編碼器側,所有候選預測模式通過率失真性能度量準則進行模式選擇,選出率失真代價最小的模式,并將最優預測模式編號傳輸。最優預測模式可表示為
當活性炭投加量為0.04和0.06g時,有NOM存在的溶液中DBP的去除率明顯低于沒有NOM存在的溶液,表明在低濃度活性炭存在的情況下,NOM分子的存在會大幅度影響活性炭對DBP分子的吸附,但隨著活性炭濃度的上升,該影響不是很顯著。
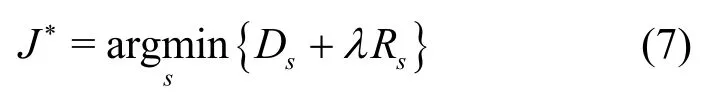
其中,s是色度幀內預測候選模式,Ds和Rs分別是采用不同色度幀內預測模式時的編碼失真和編碼比特數,λ是拉格朗日因子。
在解碼器側,通過碼流解析得到的每個CU的最優預測模式序號,并根據最優預測模式進行色度預測值的構造。
2.5 算法的通用性
NNCCP 算法不僅易于集成至H.266/VVC 編碼框架中,還具有良好的通用性。
1) H.266/VVC 采用了靈活的塊劃分技術,支持二叉樹、三叉樹和四叉樹劃分,同一視頻中存在多種尺寸的方形塊和矩形塊。這樣一來,參考區域的參考像素數量隨著塊尺寸的變化而變化。針對參考區域像素數量不固定的問題,NNCCP 算法設計了統一的數據預處理方法,從不同數量的參考像素集合中選取固定數量的相關性強的參考像素組成參考子集。因送入色度預測模塊的參考子集像素數量固定,對于任意尺寸CU,NNCCP 算法均可使用相同的神經網絡,不需要針對不同尺寸CU 單獨設計。
2) 視頻編碼往往需要根據帶寬自適應調整編碼參數,例如QP。經測試,NNCCP 架構適用于不同的QP 配置。因此,對于不同的QP,NNCCP 算法可使用統一的網絡結構及網絡參數。該特性優于為不同QP 設計不同網絡結構或訓練不同網絡參數的方案。
3) NNCCP 算法適用于不同的顏色分量。在YCbCr 顏色空間上,色度分量包含Cb 和Cr 這2 個分量,所提NNCCP 算法針對Cb 和Cr 分量共享一組網絡參數。此外,本文以YCbCr 4:2:0 采樣格式為例,所提算法同樣適用于YCbCr 4:4:4、YCbCr 4:2:2 和RGB 等其他顏色空間。
3 實驗結果
為了充分驗證NNCCP 算法在視頻編碼上的性能,本節從4 個方面對其性能進行分析與評估,包括NNCCP 超參數選擇、色度預測性能評估、編碼性能評估及NNCCP 選中比例分析。
3.1 NNCCP 超參數選擇
NNCCP 算法的網絡結構存在2 個關鍵的超參數,即M和L。參考子集的像素數M決定色度預測模塊的輸入,網絡層數L決定神經網絡的學習能力,二者均影響色度預測的準確性。為了確定NNCCP 算法的最佳M和L,本文進行了超參數選擇實驗。實驗分為2 個方案:方案1 通過固定L數值改變M的方式探究M對預測結果的影響,從而選取最佳的M;方案2 是在方案1的基礎上通過給定的M改變L的方式確定最佳的L。
圖5 給出了超參數取不同數值時NNCCP 算法在DIV2K 驗證集上的DCT 域損失曲線,每條曲線的標簽為(M,L),其中,圖5(a)~圖5(c)是固定L、改變M的損失函數曲線,圖5(d)是固定M、改變L的損失函數曲線。圖5(a)~圖5(c)展示了方案1的3組實驗結果。可以觀察到,在相同L下,隨著M值的增加,損失數值逐漸降低,并且損失數值的降低幅度呈減小趨勢。在相同L下,M=16的損失數值最小,M=8 次之,M=4的損失數值最大且明顯大于M=8 和M=16的損失數值。為了保證預測效果,本文的M在8 和16 中選取。
在色度預測模塊中,神經網絡的運算次數CN可定義為

式(8)表明,運算次數受M和L影響,且M起主要影響。隨著M增加,運算次數急劇增加。同時,M對數據預處理模塊的處理速度起決定性作用,并且數據預處理模塊中提取操作的復雜程度隨M值的增加而增加。基于上述分析,為了在獲得較小損失的前提下不引入極高的復雜度,本文將M定為8。
圖5(d)進一步展示了M=8 時3 種L取值對應的損失曲線。對比發現,損失數值隨著L的增加而降低,且當L增加至3 層時,損失數值的降幅變緩。圖5(d)的實驗結果表明,L=3 或L=5的損失數值非常接近并且均小于L=1的損失數值。由式(8)可知,L=5 時網絡的運算次數高于L=3 時網絡的運算次數。基于此,本文將L定為3,即采用3 層全連接網絡。
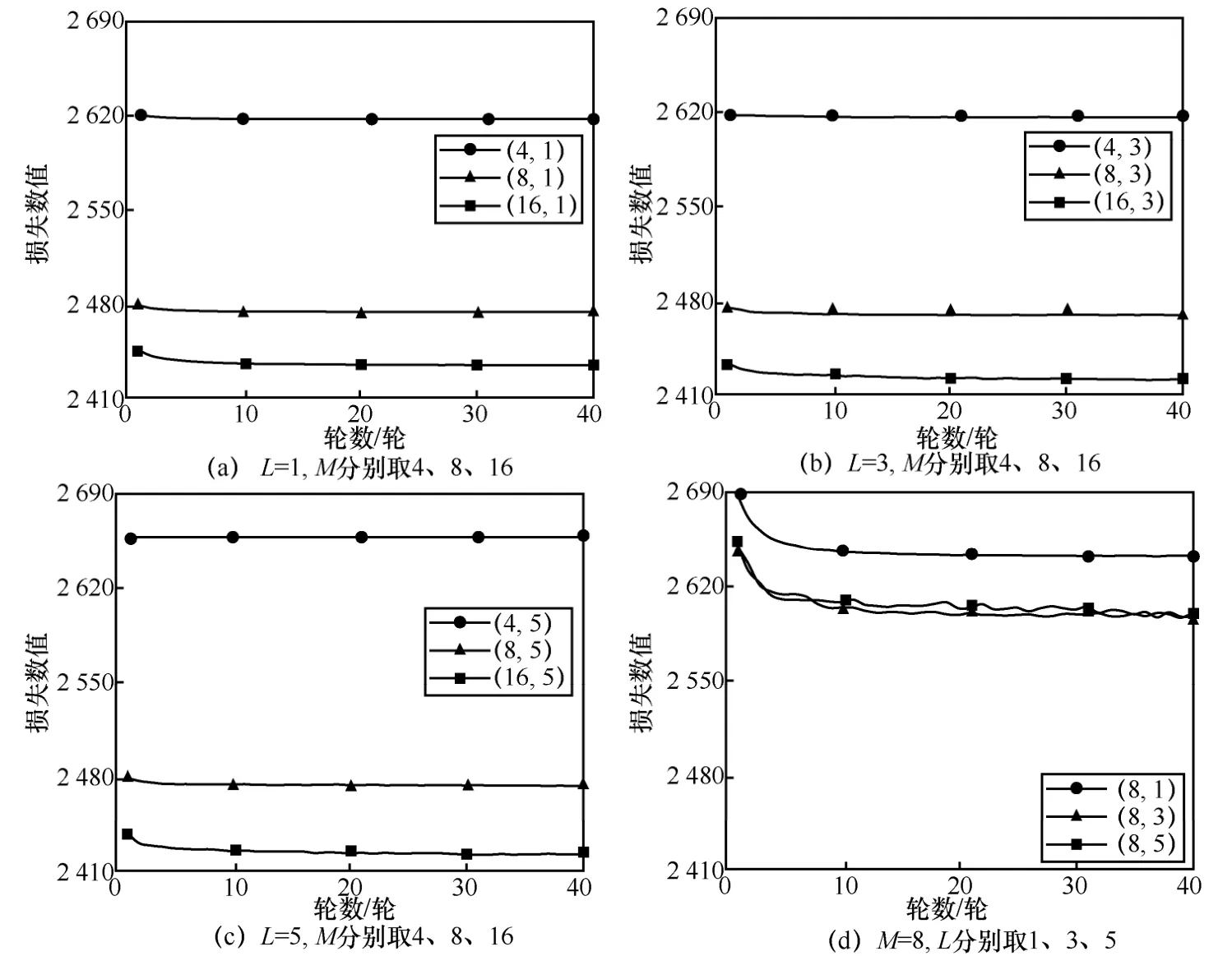
圖5 超參數取不同數值時NNCCP 算法在DIV2K 驗證集上的DCT 域損失曲線
綜上所述,在復雜度和預測準確度的權衡之下,所提NNCCP 算法選定M=8,L=3。表2 列出了NNCCP 算法的網絡結構參數。其中,全連接網絡層數為3 層,每層節點數量為8,第一、二層使用ReLU 激活函數,最后一層使用Softmax 函數。
由表2 可以看出,本文使用的神經網絡的神經元總數量僅為24,網絡參數較少,內存占用很少,是一個輕量級網絡,集成至視頻編解碼框架中具有較小的復雜度。后續的性能測試實驗均基于此網絡結構開展。
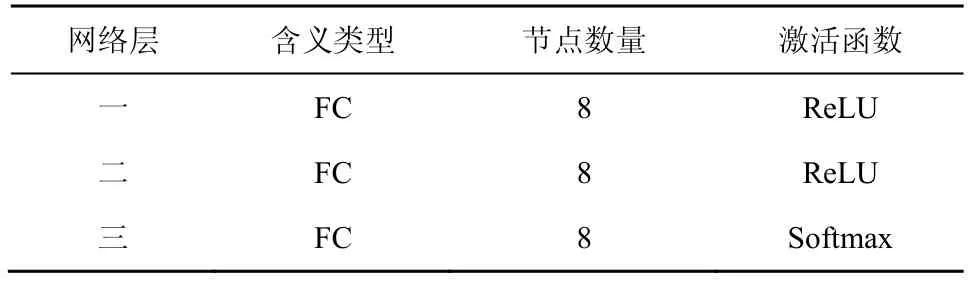
表2 NNCCP 算法的網絡結構參數
3.2 色度預測性能評估
為了比較CCLM 算法和NNCCP 算法的性能,本節對這2 種算法構造出的色度預測塊進行對比。實驗過程如下,將圖像分成固定尺寸的塊,利用參考區域的原始像素、當前塊的原始亮度值分別通過CCLM 算法和NNCCP 算法進行色度預測,并將預測結果與原始色度進行對比。需要指出,本節實驗均在色度預測塊上進行,并非直接用于觀看的解碼重建塊,在實際視頻編碼中,為了保證觀看視頻質量,還需將此色度預測塊與原始色度塊的殘差進行編碼,并傳輸至解碼端,得到最終用于觀看的重建塊。
首先,本節從H.266/VVC 通用測試條件(CTC,common test condition)[34]推薦的BasketballDrill、BQMall、MarketPlace 和Tango2 視頻中分別選取64×64的色度塊,通過CCLM 算法和NNCCP 算法進行色度預測。圖6 展示了2 種算法構造的色度預測塊的效果對比,其中,圖6(a)~圖6(d)依次為原始塊、亮度塊、采用CCLM 算法構造的色度預測塊和采用NNCCP 算法構造的色度預測塊。分析發現,在復雜紋理區域或存在邊界內容區域上,對圖像塊中所有像素使用單一線性模型的CCLM 算法產生了較大的預測誤差,而NNCCP算法由于提取與當前像素相關性強的參考像素,減少了參考區域中不相關信息的干擾,提高了預測準確性,主觀效果更自然,同時色度上也更接近原始圖像色度。

圖6 CCLM 算法與NNCCP 算法色度預測效果對比
進一步,本節在DIV2K 驗證集上分別計算通過CCLM 算法、文獻[30]算法及NNCCP 算法進行預測的峰值信噪比(PSNR,peak signal to noise ratio),從而客觀評估每種算法的預測效果。PSNR 根據色度預測值與色度原始值計算得到。為了驗證不同尺寸塊上不同算法的性能,實驗對16×16、8×8及4×4 尺寸的色度塊進行了離線預測的PSNR 測試,實驗結果如表3 所示。從表3 可以發現,隨著塊尺寸的減小,參考區域和圖像塊的相關性增強,CCLM 算法、文獻[30]算法及NNCCP 算法下的PSNR 都隨之提高。對比上述3 種算法在同尺寸圖像塊上的離線預測PSNR,NNCCP 算法的預測PSNR 在每種尺寸的圖像塊上都是最高的,文獻[30]算法次之,CCLM 算法最低。特別地,在同尺寸的圖像塊上,NNCCP 算法的預測PSNR 相較于CCLM算法的提升量為6 dB 左右,相較于文獻[30]也有1 dB左右的提升量,同時,隨著塊尺寸變化,PSNR 提升量基本恒定。上述實驗數據說明對不同尺寸塊使用統一的網絡結構及網絡參數的NNCCP 算法均有優秀的色度預測準確度,進一步驗證了NNCCP 算法的通用性。
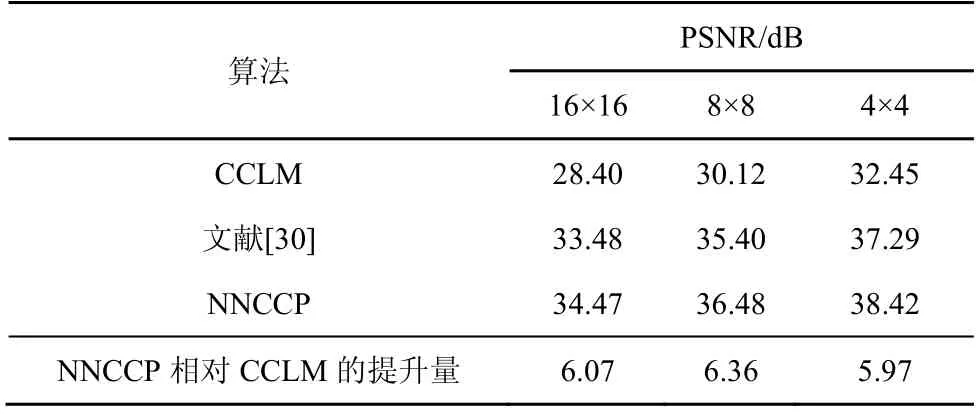
表3 色度預測性能比較
3.3 編碼性能評估
為了揭示NNCCP 算法對視頻編碼性能的影響,本節將其集成至H.266/VVC 參考軟件VTM10.0。在編碼過程中,NNCCP 算法與傳統色度預測模式競爭,通過率失真準則確定最優預測模式,并在碼流中傳輸對應模式序號。本節采用H.266/VVC 通用測試條件推薦的21 個測試序列,涵蓋了不同類型的視頻內容和不同的分辨率。本實驗采用全幀內配置(AI,all intra)編碼。編碼性能采用BD-rate[35]作為評估標準。當BD-rate 為負值時,表示在獲得相同視頻圖像質量的前提下所提算法可節省的編碼碼率。
將NNCCP 算法集成到VTM10.0 進行編碼測試,并與VTM10.0的編碼性能進行對比。表4 給出了詳細的BD-rate 對比結果,并分別計算了Y、Cb、Cr 和YCbCr 分量的BD-rate 值。實驗結果表明,在相同重建視頻質量下,NNCCP 算法在Y、Cb、Cr 上分別平均節省0.27%、1.54%和1.84%的編碼碼率。這證明了所提算法可提高壓縮效率,尤其是針對色度分量。為了綜合衡量所提算法的編碼性能,YCbCr 分量的綜合PSNR 由Y、Cb、Cr 分量加權計算[23]得到。相比于 VTM10.0,NNCCP 算法在綜合PSNR 下可平均節省0.46%的編碼碼率,有效提高了編碼性能。同時,由表4列出的各個序列的編碼性能可以看出,NNCCP算法具有良好的序列一致性。

表4 NNCCP 與VTM10.0 編碼性能比較
為了進一步評估NNCCP 算法在基于NN的色度預測算法中的性能,本節在CPU 平臺上將NNCCP 算法與文獻[30]算法、文獻[31]算法從多方面進行比較。觀察表5 中不同算法的網絡結構和網絡參數,文獻[30]算法針對不同尺寸的編碼塊訓練3 個網絡模型,文獻[31]算法與NNCCP 算法都實現了統一的網絡模型,其中文獻[31]算法的網絡層數是最多的,并且需要存儲上百萬的網絡參數量,這對視頻編碼和解碼器提出了很高的要求。由表5的數據可以看出,NNCCP 算法的網絡層數最少,同時需要存儲的總參數量遠低于文獻[30]算法和文獻[31]算法,所需存儲開銷最少。
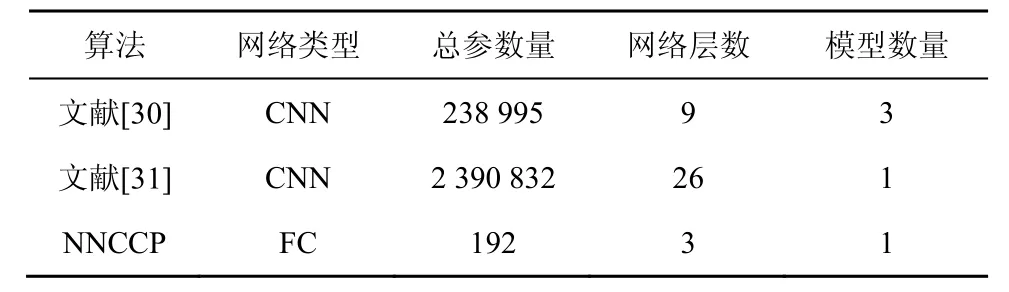
表5 不同算法的網絡結構和網絡參數比較
圖7 進一步展示了AI 配置下VTM 算法、NNCCP 算法、文獻[30]算法和文獻[31]算法的編碼性能和解碼復雜度的對比情況,其中x軸為相對于VTM的解碼時間增加量;y軸為相對于VTM的碼率節省量,值越小,表明碼率節省量越多。由圖7可以看出,文獻[30]算法可節省0.20%的編碼碼率,NNCCP 算法可節省0.46%的編碼碼率,文獻[31]算法可節省3.6%的編碼碼率。在解碼時間方面,文獻[30]算法的解碼時間相對于VTM 算法增加了874%,文獻[31]算法的解碼時間相對于VTM 算法增加了834%,而NNCCP 算法的解碼時間相對于VTM 算法僅增加了34%。視頻編碼和解碼是工業界的典型應用,視頻相關應用對壓縮效率和實時性都有非常高的要求。綜合考慮上述3 種算法的編碼性能和算法復雜度,雖然文獻[31]算法的編碼性能最佳,但其上百萬參數量的存儲需求和834%的解碼時間增加量在現階段難以實際應用。文獻[30]算法的網絡參數量相比文獻[31]算法大幅降低,但其編碼性能增益有限,解碼時間增加量也很高。因此,相比于文獻[30]算法和文獻[31]算法,本文提出的NNCCP 算法的解碼復雜度大幅降低,在解碼時間增加34%和網絡參數量僅有192的前提下可節省0.46%的編碼碼率,采用極低復雜度,有效節省了編碼碼率,提高了視頻編碼的壓縮性能。
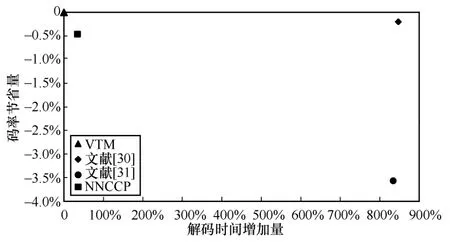
圖7 AI 配置下幾種算法的編碼性能和解碼復雜度的對比情況
3.4 NNCCP 選中比例分析
為了進一步分析NNCCP 對視頻編碼的影響,本節對NNCCP 算法的分布情況進行分析。圖8 為采用CatRobot(3840×2160)、Tango2(3840×2160)、ParkRunning3(3840×2160 )、MarketPlace(1920×108 )、KristenAndSara(1280×720 )、BasketballDrill(832×480)6 個典型測試序列以QP22編碼的第一幀、重新縮放到相同的分辨率下的可視化結果,并展示了NNCCP 模式作為最優預測模式的編碼塊。從圖8 可以觀察到,選中NNCCP的編碼塊尺寸多樣,既有方形塊,也有矩形塊。
為進一步挖掘選中NNCCP的規律,采用評價線性擬合程度的指標R2來定量分析編碼塊采用線性模型的預測值與原始值的擬合程度。通常,R2范圍為[0,1],越逼近1,擬合程度越高,線性模型的可靠性就越高。對圖8 中NNCCP 編碼塊的R2值進行統計,其分布曲線如圖9 所示。觀察各個序列R2的分布情況可以明顯發現,NNCCP 編碼塊的R2大量集中在0 值附近,即NNCCP 編碼塊的R2普遍較小。

圖8 NNCCP 選中區域分布展示
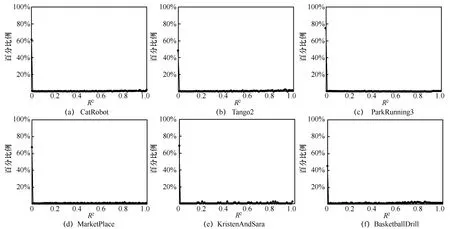
圖9 選中NNCCP 編碼塊的R2的統計分布曲線
圖10 進一步給出了各類序列NNCCP 編碼塊和CCLM 編碼塊R2的平均值。對比發現,在A1~E 序列下,NNCCP 編碼塊的R2平均值皆明顯小于CCLM的R2平均值。對于所有序列,NNCCP 編碼塊的平均R2僅為0.27,而CCLM 中的平均R2高達0.69。因此,對于使用線性模型擬合程度較差的編碼塊,即R2較小時,通常會選擇NNCCP 模式;對于采用線性模型擬合程度較好的編碼塊,即R2較大時,NNCCP 和CCLM都可較好地進行預測,通常會選擇 H.266/VVC的CCLM 模式。
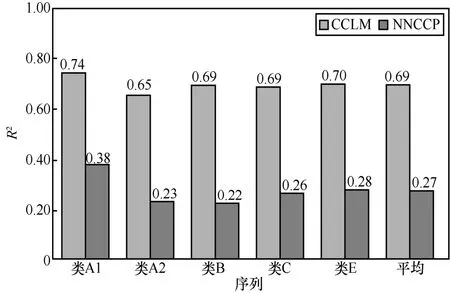
圖10 各類序列NNCCP 編碼塊和CCLM 編碼塊R2的平均值
表6 進一步給出了測試序列在不同編碼QP 下選中NNCCP 模式的像素數占比。對于不同的QP參數,NNCCP的選中像素數占比可達13.36%~16.57%。不同QP 下像素數占比并未存在明顯差異。觀察各個序列NNCCP的選中比例可以發現,對于內容簡單的序列而言,H.266/VVC 中原有的色度預測模式已足以對此類內容實現準確的預測,此時NNCCP的選中比例較低,如圖8 中KristenAndSara 序列;當序列內容豐富、復雜時,NNCCP的選中比例較高,如圖8 中的CatRobot、Tango2 和MarketPlace 序列。對于內容豐富的序列,原有色度預測模式不足以應對紋理復雜多樣的編碼塊,在此情況下存在較多R2偏小的內容,此時NNCCP 作為一種新的預測模式,通過率失真準則篩選為最佳預測模式。NNCCP 改善了R2偏小的編碼塊的預測效果,對內容豐富的序列可以達到較準確的預測。

表6 測試序列在不同編碼QP 下選中NNCCP模式的像素數占比
4 結束語
本文提出了一種基于輕量級全連接網絡的色度預測算法。相比于現有基于神經網絡的色度預測方法,NNCCP 算法在獲得編碼性能提升的同時,使用了輕量級的全連接神經網絡,其在解碼端引入的時間復雜度大幅低于現有網絡算法。所提網絡可適用于不同尺寸的編碼塊和不同QP,網絡設計時充分考慮了視頻編碼的特點。
本文將NNCCP 算法作為一種新的色度幀內預測模式集成到H.266/VVC 軟件平臺。實驗結果表明,該算法在H.266/VVC 基礎上還可獲得0.46%的碼率節省量,尤其可有效提高色度分量的壓縮效率。
NNCCP 算法可有效應用于H.266/VVC,同時該算法也為下一代視頻編碼標準提供了可行的研究思路。一方面,可考慮進一步降低NNCCP 算法的復雜度;另一方面,隨著計算能力的不斷發展,可設計更高效的網絡結構進行分量間預測,進一步提升視頻壓縮效率。
