基于用戶畫像技術的商品推薦研究與實現
2022-03-11 08:40:54王國珺
信息記錄材料 2022年1期
關鍵詞:用戶
王國珺
(福州職業技術學院 福建 福州 350000)
0 引言
所謂推薦算法就是利用用戶的一些行為,通過一些數學算法,推測出用戶可能喜歡的東西。大數據推薦算法最早源于國外對于Hadoop系統的算法優化,Pessemier在2011年便著手研究在Hadoop系統和Mapreduce框架下的推薦算法,推薦算法也第一次在大數據環境下進行相關理論研究和數據測試[1]。
常見的推薦方法很多,但當前最流行的兩種方法是基于內存的過濾和協同過濾。其中內容的過濾,主要是獲取物品或用戶的屬性信息及某種相似度定義,通過相同的相似度定義來與物品或用戶進行匹配。而協同過濾主要是依靠以往的行為,例如已有的評級或交易,這里的評級包括用戶對物品的顯示評級和隱式評級,認為過去表現出相似偏好的用戶在未來偏好也會類似。
ALS算法是基于模型的推薦算法,基本思想是對稀疏矩陣進行模型分解,評估出缺失項的值,以此來得到一個基本的訓練模型,然后依照此模型可以針對新的用戶和物品數據進行評估。ALS是采用交替的最小二乘法來算出缺失項的,交替的最小二乘法是在最小二乘法的基礎上發展而來的。
本案例采用協同過濾方法的ALS算法實現商品推薦。
1 基于大數據倉庫用戶畫像的業務研究
在數據倉庫業務中,事實表中放研究對象,維度表中放一般事實的屬性。關于業務研究主要分為以下4個步驟:
1.1 選擇業務過程
業務過程是由組織完成的微觀活動,例如,獲得訂單、開具發票、接收付款、處理服務電話、注冊學生、執行醫療程序、處理索賠等。業務過程包含以下公共特征,理解它們將有助于區分組織中不同的業務過程:業務過程通常用行為動詞表示,因為它們通常表示業務執行的活動。與之相關的維度描述與每個業務過程事件關聯的描述性環境。
?業務過程通常由某個操作型系統支撐,例如,賬單或購買系統。
?業務過程建立或獲取關鍵性能度量。有時這些度量是業務過程的直接結果,度量從其他時間獲得。分析人員總是想通過過濾器和約束的不同組合,來審查和評估這些度量。
?業務過程通常由輸入激活,產生輸出度量。在許多組織中,包含一系列過程,它們既是某些過程的輸出,也是某些過程的輸入。
1.2 聲明粒度
聲明粒度意味著精確定義某個事實表的每一行表示什么。粒度傳遞的是與事實表度量有關的細節級別。它回答 “如何描述事實表中每個行的內容” 這一問題。粒度由獲取業務過程事件的操作型系統的物理實現確定。
典型的粒度聲明如下:
?機場登機口處理的每個登機牌采用一行表示
?倉庫中每種材料庫存水平的每日快照采用一行表示
聲明粒度是不容忽視的關鍵步驟。如果不能清楚地定義粒度,整個設計就像建立在流沙之上,對候選維度的討論處于兜圈子的狀態,不適當的事實將隱藏在設計中。不適當的維度始終籠罩著DW/BI實現。設計組的每個人都要對事實表粒度達成共識,這一點非常重要。
業務過程確定后,設計小組將面臨一系列有關粒度的決策。明確在維度模型中應該包含哪個級別的細節數據。
有許多理由要求以最低的原子粒度處理數據。原子粒度數據具有強大的多維性。事實度量越詳細,就越能獲得更確定的事實。將所知的所有確定的事情轉換成維度。在這點上,原子數據與多維方法能夠實現最佳匹配。
本案例研究中,最細粒度的數據是用戶訂單中涉及的單個產品,假設要開發的系統按照一個購物車中某種產品為單一項而上卷所有銷售。盡管用戶可能不會對分析與特定訂單交易關聯的單項感興趣,但您能預測所有他們需要獲得的數據的方法。例如,他們可能希望知道周一與周日的銷售差別,或者他們希望評估是否值得存大量某品牌的商品等。盡管上述查詢不需要某一特定交易的數據,但他們提出的查詢請求需要以準確的方式對詳細數據執行分片操作而獲得。如果僅選擇提供匯總數據,則無法獲得這些問題的正確答案。
這里需要特別注意的是:基于大數據倉庫的這種智能的用戶畫像的系統幾乎總是要求數據盡可能以最細粒度來表示,不是因為需要查詢單獨的某行,而是因為查詢需要以非常精確的方式對細節進行切分。
1.3 確定維度
維度要解決的問題是“業務人員如何描述來自業務過程度量事件的數據”應當使用健壯的維度集合來裝飾事實表,這些維度表示承擔每個度量環境中所有可能的單值描述符。如果粒度清楚,維度通常易于區分,因為它們表示的是與“誰、什么、何處、何時、為何、如何”關聯的事件。常見維度的實例包括日期、產品、客戶、雇員、設備等。在選擇每個維度時,應該列出所有具體的、文本類型的屬性以充實每個維度表。
事實表粒度選擇完畢后,維度的選擇就比較直接了。產品與事務立即呈現。在主維度框架內,可以考慮其他維度是否可以被屬性化為訂單度量。例如,銷售日期、銷售店面、哪種銷售的產品被促銷、處理銷售的店員、可能的支付方法等。我們將這些以另外的設計原則表達。
詳細的粒度說明確定了事實表的主要維度。然后可以將更多維度增加到事實表維度應用于該案例中:日期、產品、促銷、支付方式。
1.4 確定事實
可以通過回答“過程的度量是什么”這一問題來確定事實。商業用戶非常愿意分析這些性能度量。設計中的所有候選事實必須符合第2步的粒度定義。明顯屬于不同粒度的事實必須放在不同的事實表中。典型事實是可加性數值,例如,訂貨數量或成本總額等。
需要綜合考慮業務用戶需求和數據來源的實際情況,并與4個步驟聯系起來,如圖1所示。強烈建議堅決抵制僅僅只考慮數據來源來建模數據。將注意力放在數據上可能不會像與商業用戶交流那樣復雜,但數據不能替代業務用戶的輸入。遺憾的是,許多組織仍然在采用這種看似最省力的數據驅動的方法,當然這樣做基本不能取得成功。
設計的最后一步是確認應該將哪些事實放到事實表中。粒度聲明有助于穩定相關的考慮。事實必須與粒度吻合:放入訂單中交易的單獨產品線項。在考慮可能存在的事實時,可能會發現仍然需要調整早期的粒度聲明或維度選擇。
2 用戶畫像大數據倉庫的框架設計
在Spark生態圈中,MLlib組件支持ALS算法,它是協同過濾式推薦算法中非常經典的一種。主要實現通過學習用戶對商品的評分來推斷出用戶的喜好,并向用戶推薦適合的產品,或學習商品的信息,尋找可能潛在的用戶進行推薦。
當前案例截取是電商平臺用戶購物的流程,見圖2。
通過該業務,分析用戶畫像的行為,例如用戶的留存率、新增用戶占日活躍用戶比率、用戶行為漏斗分析、用戶相對商品復購率分析、商品推薦計算等。涉及的庫表眾多,這里只選取有代表性的9張表,分別是訂單表、訂單詳情表、商品表、用戶表、商品一級分類表、商品二級分類表、商品三級分類表、支付流水表、商品評分表[2]。
圖3為亞馬遜網站的一個截圖,每款商品都會有評分數據。應用ALS算法,可通過用戶對商品的評分,實現通過商品尋找可能有興趣的人,或通過人查找有興趣的商品的功能。
設計的第l步是通過對業務需求以及可用數據源的綜合考慮,決定對哪種業務過程開展建模工作。當前基于大數據倉庫用戶畫像的業務應該將注意力放在最為關鍵的、最易實現的用戶業務過程。最易實現涉及一系列的考慮,包括數據可用性與質量以及組織的準備工作等。在此電商購物業務案例研究中,管理層希望更好地理解通過當前系統獲得的客戶購買情況。因此將要建模的業務過程是訂單下單到交易完成的過程。該數據保證商業用戶能夠分析被銷售的產品,它們是在哪幾天、哪個商店、處于何種促銷環境中被哪類人群購買。表1是系統總線矩陣[3]。

表1 系統總線矩陣
3 推薦算法的實現
本案例操作系統選擇開源CentOS7,應用大數據工具選用Apache開源工具Hadoop、Hive、Spark、Zookeeper、HBase、Flume、Sqoop。
整個案例數據存儲以Hadoop為基礎,然后進行數據管理工具和分析工具及ETL工具的安裝與配置。由于MapReduce本身的中間結果復寫磁盤的特性,也決定了它并不適合交互性強、循環迭代的學習知識的過程,故在用戶畫像的產品推薦過程中,選用的基于內存計算的Spark工具,基于其內核,應用Spark SQL組件從Hive大數據倉庫中提取數據,應用Spark MLlib機器學習組件,完成ALS算法參數的學習過程,使其依據用戶對商品的歷史評價數據,正確實現商品的推薦過程,即通過某個商品找到可能購買的用戶,同時通過用戶找到可能購買的商品[4]。
3.1 測試數據表的準備
3.2 項目開發前Hive的準備
在Hive工具的conf/hive-site.xml文件中配置遠程服務,即加入下面參數配置項。
3.3 IDEA建立推薦算法的Maven項目
將Hadoop配置文件目錄etc/hadoop下的core-site.xml和hdfs-site.xml文件拷貝到項目中resources文件夾中。將Hive配置文件目錄/usr/local/hive/conf下的hive-site.xml文件拷貝到項目中resources文件夾中。拷貝路徑見圖4。
3.4 Recommend的實現
ALS協同算法,其全稱是交替最小二乘法(Alternating Least Squares),由于簡單高效,已被廣泛應用在推薦場景中,目前已經被集成到Spark MLlib和ML庫中[5]。
下面我們構造一組商品與用戶的評分矩陣,見表2。
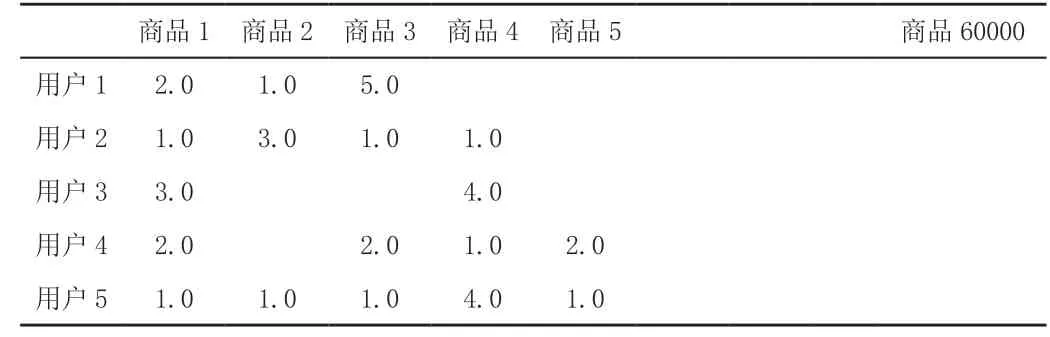
表2 商品與用戶的評分矩陣
我們應用推薦算法,其目的就是找出兩個屬性的相似性,例如找出兩個用戶的相似喜歡,進而完成推薦過程。例如,表中“用戶1”和“用戶2”喜好相對最像,唯一的是“用戶2”比“用戶1”多了一個對商品4的評分,所以肉眼我們可認為當向“用戶1”推薦商品時,可將“商品4”推薦給“用戶1”。
以下是部分recommend代碼:
其中:ratings:訓練的數據格式是Rating(userID,productID,rating)的RDD。rank參數指當我們進行矩陣分解時,將原來的矩陣A(m×n)分解成X(m×rank)矩陣與Y(rank×n)矩陣。
Iteration:ALS算法重復計算次數。
4 運行結果測試
進行測試,通過輸入不同的參數,觀察推薦結果,例如:輸入1,針對用戶推薦商品時,發現給用戶1推薦時,推薦了商品4。圖5顯示的是測試結果。
我們將學習參數按圖中紅色框中進行修改,然后再次研究推薦算法時,發現給用戶1推薦的商品不是商品4,而是商品3了。
5 結語
綜上所述,本文介紹了基于大數據倉庫技術和數據畫像進行商品推薦的過程,通過ALS算法,在選擇商品的時候更加科學。
猜你喜歡
車主之友(2022年4期)2022-08-27 00:58:26
知音·下半月(2022年5期)2022-05-23 23:17:04
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年5期)2016-11-28 09:55:15
非公有制企業黨建(2016年1期)2016-07-19 13:02:51
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
衛星與網絡(2016年12期)2016-02-05 09:23:23
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
