曲流河儲層構型建模方法研究進展*
2022-03-11 04:03:50葉小明劉小鴻李俊飛
中國海上油氣 2022年1期
葉小明 劉小鴻 張 嵐 徐 靜 李俊飛
(中海石油(中國)有限公司天津分公司 天津 300459)
儲層構型,是指不同級次儲層構成單元的形態、規模、方向及其疊置關系[1]。自Miall于1985年提出儲層構型的概念及方法以來[2-3],儲層構型已成為研究熱點方向[4-5],其中以曲流河研究最多,成果最為豐富,研究方法也最為成熟。目前,國內外學者通過露頭、現代沉積、水槽實驗等方式建立了豐富的曲流河儲層定性及定量模式[6-9],指導了眾多密井網老油田曲流河儲層的精細構型解剖,在油田開發后期綜合調整、剩余油挖潛中起到了較好的效果[10-11]。
近年來,伴隨著地質研究逐漸向定量化發展,如何將精細曲流河儲層構型分析成果定量地表征在三維地質模型中成為研究熱點,并形成了一些切實可行的技術方法[12-15],為構型研究成果在實際油田開發中應用起到了較好的推動作用。傳統的三維建模一般只達到了微相級次,而構型建模則是指對單一微相砂體內部構型界面及構型單元的三維定量模擬,其實質是細化了模型的界面級次,將儲層內部次級界面納入了非均質性的定量表征范疇。針對曲流河沉積,構型建模主要指點壩砂體內部側積體和側積夾層的建模。點壩內部的側積夾層對于油藏內部的流體運動具有重要影響,只有將其精確地表征到模型中,提高剩余油分布的預測精度,才能更好地指導油田后期調整與挖潛[16]。對曲流河儲層構型建模的研究進行總結和評述,有利于更好地理解曲流河儲層構型建模研究難點及解決方法,合理應用其開展實際油田構型建模,推動構型建模方法發展,促進辮狀河、三角洲等其他類型儲集層構型建模方法的完善。
1 曲流河內部構型特征
點壩是曲流河主要的砂體類型,也是構型研究的重點,點壩內部構型研究主要是對砂體內部各要素(側積體、側積層、側積面)進行識別描述。側積體是點壩的主體,側積層(側積泥巖)是識別點壩內部側積面、劃分每期側積體的關鍵。側積層一般是指側積體之間沉積的泥質層,產狀多呈斜插的泥質楔子,傾向指向河道遷移方向的一側,傾角一般為5°~10°左右[1,10,12]。
定量地描述側積層的產狀、側積體的規模是曲流河砂體內部構型研究的核心。因此,針對曲流河儲層構型建模,其研究重點為如何在三維模型中定量表征側積體和側積夾層的空間位置及其相互關系。由于側積夾層對流體具有遮擋作用,因此,實際建模過程中其重點在于對側積夾層模型的建立。
2 曲流河儲層構型建模研究現狀
從地質建模主要研究流程來看,儲層構型建模仍屬于相建模的范疇,只是研究精度更細。在油田開發早期可能只需要模擬出砂泥巖分布就能滿足開發需要,到了中后期則需建立精細的微相模型,在砂體內模擬出點壩等各種微相類型。而伴隨油田步入高含水乃至特高含水期,為了基于地質模型來精細預測剩余油分布,則需將微相砂體內部構型界面表征出來。由于曲流河河道及點壩級次構型建模方法已較成熟,這里主要重點關注側積夾層級次構型單元的建模方法。目前針對側積夾層模型的建立主要包含基于面的建模方法、基于網格的隨機建模方法以及等效表征等方法。
2.1 基于面的建模方法
針對側積夾層建模,基于面的建模方法主要分2個步驟,第1步為在三維空間中生成側積面,第2步則是將多個側積面表征到網格模型中去。側積面的生成是該類方法的研究重點,主要包括了確定性建模方法及隨機建模方法兩種,而將多個側積面表征到網格模型中目前主要采用確定性的重采樣方法。
2.1.1確定性建模方法
針對如何在三維空間中生成側積面,國內學者開展了較多研究,且在實際油田小區塊應用中取得了較好的效果。各研究方法中,以確定性建模方法為主。2009年,岳大力 等以孤東油田曲流河沉積為例,探索了儲集層構型界面的幾何建模方法,采用三次樣條插值方法來生成側積面[17]。基于該方法生成的側積面后期還需通過人機交互處理才能采樣到網格模型中,一定程度上增加了建模人員的工作量。2012年,范崢 等提出一種點壩內部構型的嵌入式建模方法,該方法包括側積面模式擬合、側積層厚度插值以及側積層模型嵌入等主要環節[13]。該方法建立的模型賦予了側積層厚度的概念,更加符合實際地質認識,但采用了網格局部加密方式,應用中若處理不好,對油藏數模收斂性會產生一定影響。2014年,劉衛 等提出基于界面約束法的曲流河點壩內部構型建模方法[18],通過生成側積層頂、底界面,采用多級界面聯合約束方法建立儲層結構模型。該方法利用非均勻粗化的方式將側積層表征進模型中,由于側積層與側積體采用了2種不同規模網格,在數值模擬中收斂性變差。2017年,張建興 等以孤東油田七區西為例,利用基于構型單元的側積體建模方法建立了構型模型,并用油藏數模預測了剩余油分布[19]。2017年,孫紅霞 等提出了構造界面約束下的側積層構型網格模型構建方法[20],指出構型模型網格方向既要準確刻畫側積層的產狀,又要保證側積體網格的正交性。2019年,牛博 等采用界面約束原理建立了石臼坨凸起西部明化鎮組下段區域三維構型模型(圖1)[21]。其用構型界面將點壩內部不同構型要素的頂底界面進行逐級封隔和組合封裝,在側積層、側積體內部分別進行網格細分,解決模型網格數與側積層精度之間的矛盾。

圖1 點壩側積體模型及剖面(據文獻[21])
2.1.2隨機模擬方法
采用隨機模擬方法進行側積面的模擬,研究相對較少。2013年,黃繼新 等將基于沉積界面的建模方法從濁積扇體建模推廣到河流相構型建模中,并以吉林油田某區塊為例進行了建模[22]。該方法在界面數學模型構建、界面疊加樣式描述等方面還存在較多問題,目前主要應用于濁積扇體建模。2013年,李宇鵬 等借鑒計算機圖像學中矢量圖形存儲的思路,提出基于空間矢量的曲流河點壩砂體構型建模方法,該方法通過基于目標的模擬直接用面和體生成構型模型[12,23]。圖2為利用該方法建立的側積體構型模型,由于模擬中沒有定義網格,有效提高了模擬速度。
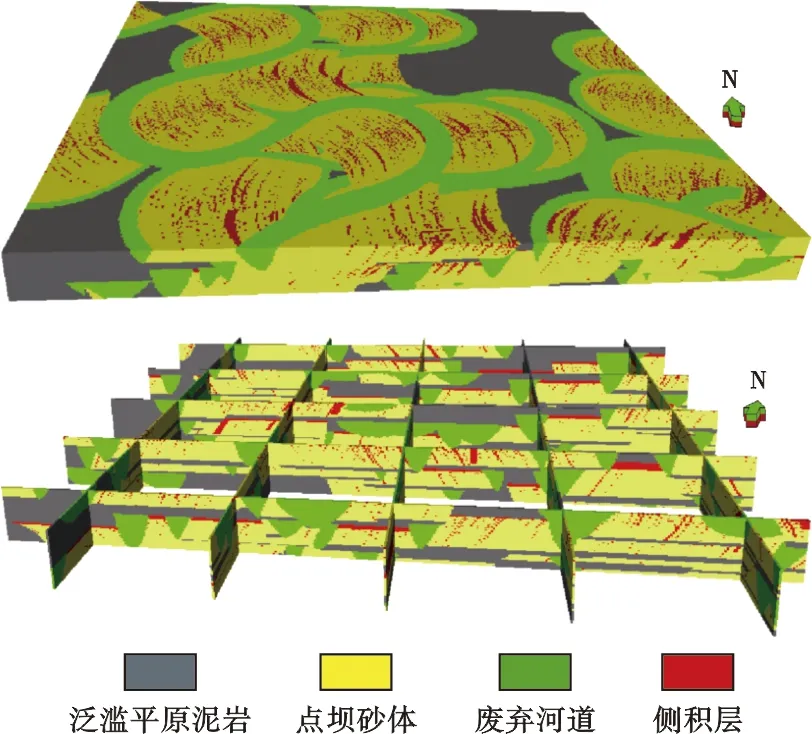
圖2 點壩內部側積體構型模擬結果(據文獻[23])
2.2 基于網格的隨機建模方法
隨機建模是指以已知的信息為基礎,以隨機函數為理論,應用隨機建模方法,產生可選的、等可能的儲層模型的方法[24]。按照隨機模擬空間賦值方式的不同,可以把隨機建模方法分為兩大類:基于象元的方法、基于目標的方法。與前面分類中基于面的建模方法先生成側積面,再重采樣到網格模型中不同,此處分類中的隨機建模方法在進行建模時一般為直接基于網格開展。
2.2.1基于象元的方法
根據建模方法所應用的統計學特征,又可將基于象元的方法分為基于兩點統計學的方法和多點統計學方法。曲流河儲層內部構型建模方法也經歷了從基于兩點統計學的序貫指示模擬到多點統計學模擬方法的不斷發展。
2006年,岳大力以孤島油田館陶組為例,利用序貫指示模擬及人機交互后處理方法[25],采用Direct軟件,建立了中一區某井區三個單層的構型模型(圖3)。由于序貫指示模擬應用起來相對簡單,軟件系統也比較成熟,白振強[26]、蘭麗鳳[27]、王鳳蘭[28]等均利用該方法在大慶薩北油田、薩中開發區等區塊開展了小范圍的曲流河構型建模及數值模擬,總結出構型控制下的剩余油分布模式,并提出相應的挖潛措施,取得了較好的應用效果。
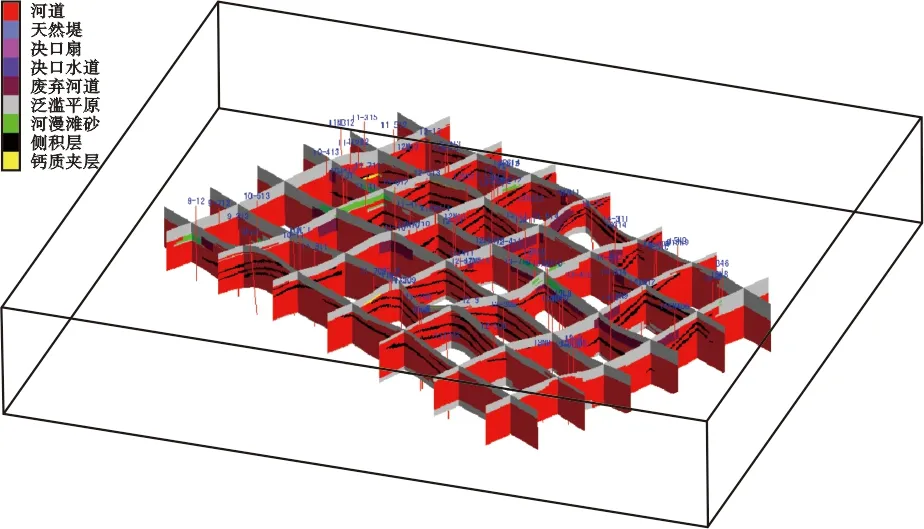
圖3 儲層構型模型柵狀切片(據文獻[25])
由于側積層三維空間形態復雜,傳統序貫指示方法難以表征其復雜的空間結構和幾何形態。相對于傳統的地質統計學,多點地質統計學利用訓練圖像代替變差函數,在一定程度上克服了傳統地質統計學的不足,較多學者將該方法應用到了曲流河構型建模當中。2012年,鄒拓等以港東油田一區為例,采取層次模擬、試驗篩選、分級預測交互方式,利用多點地質統計法,建立了網格大小為2 m×2 m×0.5 m 的構型模型[29]。2016年,劉可可 等利用多點地質統計學Snesim算法,再現了點壩內夾層三維形態[30]。其將利用多點地質統計法和序貫指示法建立的模型進行了對比,前者建立的模型在夾層側積形態、延伸長度及平面連續性等方面都與實際更為相符,具明顯優越性(圖4)。2020年,陳仕臻 等以勝利油田史南區塊為例,提出構型模式控制下的曲流河多尺度地質建模方法,實現井間點壩和側積層的合理預測,模型吻合度提高至92.7%[31]。利用多點地質統計學建模方法來開展曲流河構型建模過程中,重點是訓練圖像的獲取,由于側積夾層空間展布樣式多樣,如何隨機模擬或者手工繪制適合研究區域的側積層訓練圖像是該方法的關鍵。

圖4 點壩內夾層展布模型對比(據文獻[30])
2.2.2基于目標的方法
基于目標的方法以目標物體作為基本模擬單元,由于其能較好的再現模擬目標體的形態,也被一些研究人員應用到曲流河構型建模當中。基于目標的模擬方法又可細分為基于目標體結果的方法和基于目標體形成過程的方法[32],近年來,基于過程的建模方法逐漸成為研究熱點。
在曲流河建模過程中,基于目標體結果的模擬方法主要應用于曲流河微相級次模型的建立,在點壩內部側積層構型建模方面應用相對較少。如2002年,Deutsch等提出基于目標的層次模型Fluvsim[33-34],模擬了河道、溢岸、決口扇等微相的分布;Journel提出基于流線分布的河流相模擬方法,通過局部隨機修改方位角再現河流流動方位的變化[35]。在側積層建模方面,2010年,喬勇 等開展了基于改進布爾模擬的點壩建模,其對布爾方法進行了改進,使模擬砂體更符合真實地質形態,更能夠模擬曲流河側向遷移過程,進而模擬側積層分布[36]。該研究只建立了二維構型模型,如何利用該方法模擬側積層三維分布還需進一步研究。2011年,尹艷樹 等設計開發了一種新的側積層建模方法[14],其采用基于目標方法,首先模擬河道主流線,然后沿中線建立河道剖面,通過蒙特卡羅隨機抽樣等完成點壩和側積層建模[14]。
基于當前建模方法在整合與沉積過程有關的地質信息方面存在的不足, Pyrcz 等提出了基于沉積過程的隨機建模方法,并開發了模擬河流相儲層的Alluvsim算法[37]。該方法提高了建模精度,降低了儲層預測不確定性,但在河道中線生成、側積層刻畫及井數據條件化方面還存在一些不足[37]。2013年,李少華 等針對Alluvsim算法進行了改進,改進后的算法能靈活控制側積層傾角、延伸長度等關鍵參數,實現點壩內部構型模擬[38]。2015年,趙永軍 等[39]基于河道遷移演化模擬、側積層定量三維分布模式及沉積過程模擬提出一種復雜曲流帶儲層三維構型建模新方法,實現曲流帶內部構型單元規模、幾何形態及其相互配置關系的定量表征,但該方法在擬合井數據方面還有待進一步研究。2017年,Yan Na 等開發了一套針對曲流河沉積的三維正演地層數值模型PB-SAND[40],并對英國北約克郡中侏羅統點壩沉積內部構型進行了模擬,證明了該方法的可行性及強大的模擬能力,但目前基于該方法開展實際油田構型建模的實例較少。2019年,舒曉 等提出了基于曲流河演化模擬、井數據擬合的點壩內部構型建模方法[41],并在渤海灣盆地 A 油田進行了應用,結果顯示該方法不僅能構建具有真實形態的構型模型,同時能忠實于井數據。
2.3 等效表征方法
無論是采用哪種建模方法,其建立的曲流河構型模型最終都要表征到網格模型中。由于側積層尺度非常小,往往采用局部網格加密方法來表征。從已發表文章來看,建立的各構型模型網格尺度平面上大部分都為5 m×5 m~10 m×10 m,垂向上大部分為0.25~0.5 m。這樣的模型的確是提高了地質模型精度,但是卻為油藏數值模擬帶來了巨大挑戰,如果將地質模型粗化,構型模型當中精細的滲流屏障必定被粗化掉,難以反映到流動模擬當中,構型建模的意義也就大打折扣。這也導致目前大部分儲層構型建模只能局限在小范圍內開展,無法在全油田范圍內進行。
針對這一問題,2016年,霍春亮 等提出了一種儲層成因單元界面等效表征方法并開發了配套軟件,其核心思想為將側積夾層對流體滲流的影響通過網格界面傳導率表征到油藏數值模擬模型中去,而不是將其幾何參數反映到油藏數值模擬模型中[16]。基于該方法及軟件,可依據構型研究得到的側積層產狀直接生成三維側積面(也可將基于網格建立的地質模型中側積夾層通過界面重建,提取出三維側積面),然后將多個側積面與粗化后的數模模型求交,輸出構型界面兩側網格間傳導率乘數數據卡,提供給數值模擬軟件,開展基于側積夾層構型定量表征的生產動態歷史擬合及油藏數值模擬。該方法在渤海河流相油田進行了實際應用,有效提高了數值模擬運行效率及剩余油分布的預測精度[42-43]。
該方法有效解決了側積夾層構型模型網格規模巨大導致的油藏數值模擬精度和效率問題,但針對如何定量評價側積層對流體滲流的影響,主要還是依據人工試錯方式來進行調整,還需要進一步完善,特別是與大數據、人工智能等方法的結合,來進一步提升研究效率。
3 存在問題及展望
近年來,曲流河儲層構型建模在技術方法及應用實踐中均取得了較大的進展,有效推動了曲流河儲層構型研究成果在精細剩余油預測及挖潛中的應用,并為其他類型儲層構型建模提供了借鑒。但由于其發展時間較短,從2005年左右我國第一個曲流河構型模型建立[4],到如今僅有十多年時間,還有很多問題需要攻關。
3.1 井區地下構型模式過于簡化
前人基于野外露頭、現代沉積等對曲流河開展了大量研究,建立了豐富的構型模式,如圖5所示,為王夏斌 等[44]通過Google earth衛星圖像的觀察分析,進行的塞內加爾河和墨累河典型區塊的構型素描及非均質性解釋結果,可以清晰地看出,在廢棄河道所圈定的范圍內,往往發育的是互相切割的多期側積層,具有較強的非均質性。但在實際地下構型應用中,各種模式往往被簡化處理,從已發表文獻來看,當前地下曲流河內部構型研究大部分都將側積層簡單地刻畫為一系列平行的模式(圖6)[21],簡化后的構型模式降低了點壩砂體內部的非均質性,導致基于此構型結果建立的構型模型與地下實際存在較大差距。如何在實際油田構型研究中充分考慮并應用不同的構型模式,得出更加合理的構型認識,是曲流河構型建模的基礎,也是需要重視的一個問題。
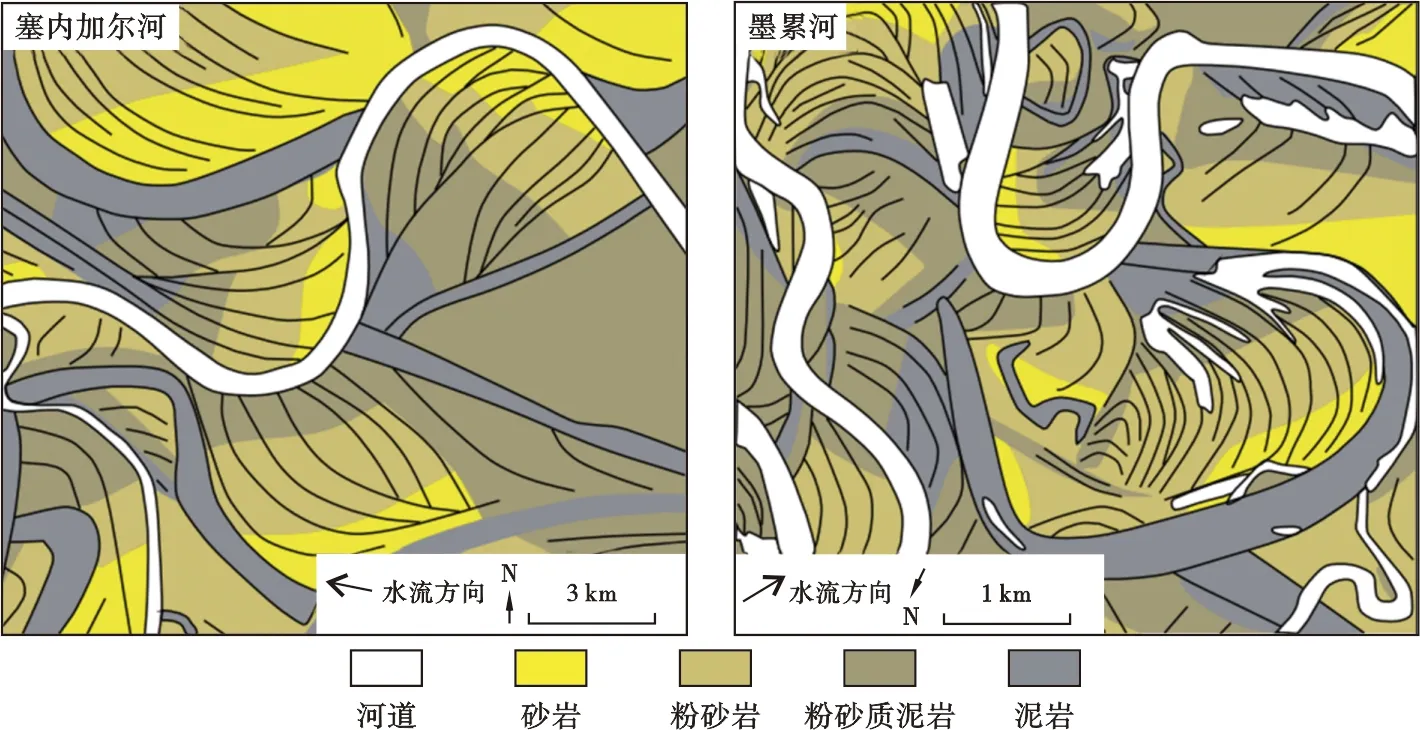
圖5 基于衛星圖像的曲流河構型素描及非均質性解釋(據文獻[44],有修改)
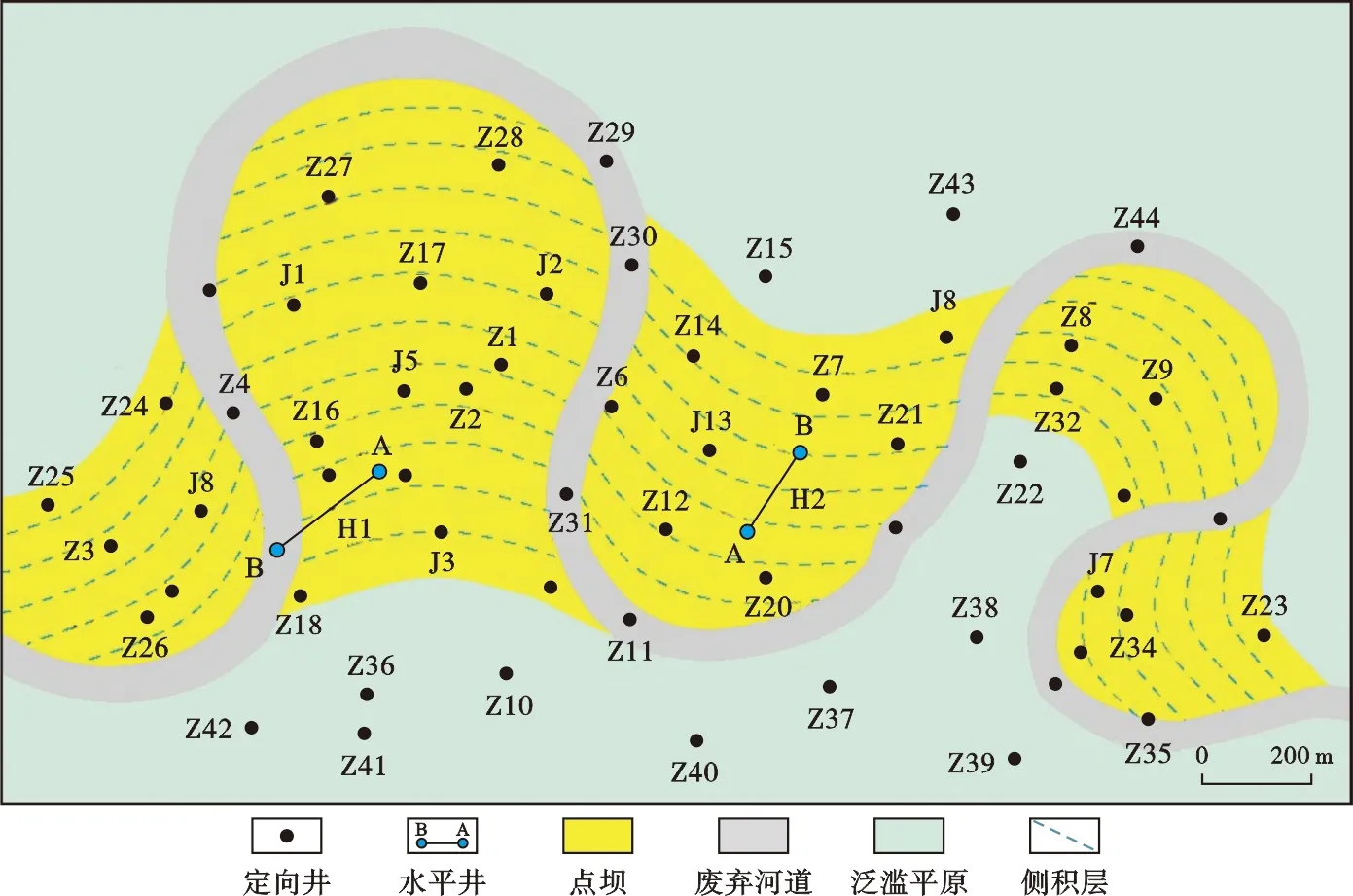
圖6 側積層平面分布圖(據文獻[21])
3.2 點壩內部構型不確定性表征研究不足
針對點壩內部構型,目前采用最多的還是確定性建模,這也就導致了建立的模型只有1個實現。雖然油田一般到了開發中后期,有了較為豐富的動靜態資料才開展構型研究,對地下儲層認識的不確定性較開發早期階段顯著降低,但這并不意味著沒有不確定性。由于點壩內部側積夾層規模一般較小,即使在100米小井距的條件下也難以準確控制[45]。側積層傾角、延伸長度、寬度等產狀參數在不同油田差異很大,即使是同一油田或者同一點壩內部,受洪水事件差異性影響,這些參數也不一樣[14],比如汪巍 等[46]通過對橫穿點壩的水平井資料進行測量統計,得出曹妃甸11-1油田側積夾層水平寬度為0.7~4.7 m(表1),其中A9H井穿過的側積夾層水平寬度最小僅為0.9 m,而最大為4.6 m。側積層產狀及規模的復雜性加劇了側積層構型建模的難度,而這些參數都會對后期基于該地質模型的精細剩余油預測精度帶來影響。此外,側積夾層三維空間形態也并非是一個光滑的曲面。建議應加強對實際建模油田的不確定性表征,通過顯著性分析,優選主要不確定性變量,建立多套確定性的模型來涵蓋不確定性范圍。

表1 曹妃甸11-1油田側積夾層水平寬度統計(據文獻[46])
3.3 應注重多種建模方法綜合應用
近年來,針對點壩砂體內部側積夾層建模,雖然各種建模方法都取得較大進步,但單一應用一種建模方法開展構型建模時仍存在不足。如基于象元的序貫指示方法主要通過變差函數表示模擬對象的空間相關性,難以描述側積夾層的復雜空間結構特征,最終都需要經過人機互動手工修改,無形中增加了建模人員的工作量。基于目標體結果的方法由于在運算速度及井數據條件化等方面存在不足,在曲流河側積層建模中應用較少;而基于目標體過程的方法近年來成為一個新的研究方向,但其發展時間較短,算法還不夠成熟,且沒有成型的商業化應用軟件。多點地質統計學方法通過引入訓練圖像來替代變差函數,在幾何形態表征及井數據條件化等方面展現出更大優勢,特別是近年來在訓練圖像建立方面取得長足的進步,促進了該方法的推廣應用,但其在模擬目標連續性、非平穩數據處理等方面還需要進一步攻關。
考慮到各種建模方法都有各自的優勢及不足,實際研究中應綜合利用多種建模方法來最大化程度提高建立模型的精度。如可以利用基于目標體結果及過程的方法在構型單元幾何形態表征上的優勢,建立構型單元的訓練圖像,再利用多點地質統計學方法進行隨機模擬,再通過適當的人機交互修改完成最終構型模型的建立。可以將各類基于界面或者界面約束建模方法產生的側積夾層三維曲面,采用等效表征方法定量表征到油藏數值模擬模型中。
3.4 應加強高效數值模擬器的研發和應用
從目前已經發表文獻來看,關于曲流河點壩內部側積層建模研究大部分都是局限于某一試驗區,有的建立的僅為單一點壩內部側積層模型。其原因主要由于側積層規模較小,要在三維地質模型中進行定量刻畫,平面及垂向網格都必須要設置的足夠小,這樣必然會導致建立的模型網格規模很大。如劉衛等人采用5 m×5 m×0.25 m的網格設置,建立的大港油田某單個點壩模型網格數就達到1 776 500個[18],如果建立全油田的點壩構型模型,網格數都將達到千萬級別以上。網格規模過大必定導致油藏數值模擬運算效率降低,以一個1 000萬左右網格規模的河流相油田構型模型為例,應用eclipse模擬器32核CPU并行計算,15年生產歷史,需要耗時20 h以上。雖然部分研究人員采用了局部網格加密、非均勻粗化等方法,其應用大部分也只是在小范圍內開展,并且局部加密后網格尺寸相差太大會導致孔隙體積差異變大,造成迭代算法收斂慢,增加數值模擬運算耗時[16]。李君 等人提出一種考慮夾層影響的滲透率粗化方法,通過判斷粗化網格內部不同砂體是否連通,實現在粗化的滲透率模型中反映精細地質模型中的側積夾層信息,但尚未見實際油田應用,作者也指出該方法作為一種純數學方法,在實際應用中還應加入更多地質約束條件來提高準確性[47]。霍春亮 等提出的儲層成因單元界面等效表征方法[16]采用網格間傳導率乘數來定量表征側積夾層對流體滲流的影響,突破了網格尺寸的限制,實現了油田級別側積層油藏模型定量表征,但若粗化后的油藏數值模擬模型網格尺寸太大,等效表征的精度也會受到一定影響,如可能存在兩個相鄰的側積面在油藏模型中穿過同一個網格。
近年來,斯倫貝謝Intersect、俄羅斯tNavigator等新一代數值模擬器的應用,在一定程度上解決了網格規模巨大運行效率低下的問題,但面對油田級別精細側積夾層構型模型,仍面臨挑戰,國內在該方面則相對落后,因此下一步應重點加強高效數值模擬器的研發攻關。隨著計算機軟硬件的不斷發展和進步,大規模網格數量的構型模型運算速度將得到大幅提升,將有效促進儲層構型建模技術的進一步發展。
4 結束語
系統介紹了曲流河儲層構型建模方法的研究進展,將目前已有的各種側積夾層建模方法歸納為基于面的建模方法、網格隨機建模方法及等效表征方法3大類。對當前曲流河儲層構型建模方法存在的問題進行了分析,指出當前曲流河儲層構型建模存在井區地下構型模式過于簡化、點壩內部構型不確定性表征研究不足等問題。在詳細分析當前曲流河儲層構型建模方法及存在問題的基礎上,指出多種建模方法綜合、高效數值模擬器的研發和應用等是其重要發展趨勢。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
