基于GhostNet 殘差結構的輕量化飲料識別網絡
2022-03-12 05:56:46曹遠杰高瑜翔
計算機工程 2022年3期
曹遠杰,高瑜翔
(1.成都信息工程大學 通信工程學院,成都 610225;2.氣象信息與信號處理四川省高校重點實驗室,成都 610225)
0 概述
卷積神經網絡自提出以來在計算機視覺領域被廣泛應用。在生活中運用智能機器可以節省人力資源,例如自動售水機、無人超市等。但是當售水機部署在學校等人流量較多的地方時,售水機暴露出效率低、耗時長等缺點。假設給機器安裝上飲料自動識別,飲料選擇和刷臉支付一體化會使售水機效率更高。因此,飲料等商品的識別對于無人售賣機、智能化超市等是非常必要的。
深度學習在目標識別與檢測上有著較強的魯棒性,深層神經網絡能夠在復雜環境下對目標具有較好的識別性能。隨著對目標檢測性能要求的提高,研究人員提出了許多深層神經網絡。例如,2014 年ILSVRC 競賽提出的VGGNet[1]和 GoogleNet[2],2015 年提出 的ResNet 以及后來提出的DenseNet[3]等。但是隨著性能的提高卷積層數也隨之增加,從而出現權重參數較大和設備推理速度慢的問題。因此,上述方法在實際應用中常因為參數量高和效率低而不能部署在資源有限的設備上。
為解決效率和存儲問題,研究人員采取剪枝[4]、量化[5]、知識蒸餾[6]以及設計輕量化網絡的方法來提高推理的速度。例如針對參數和推理速度推出的YOLOv3-Tiny[7]網絡是YOLOv3[8]網絡的一個簡化版;邵偉平等[9]提出采用MobileNet 作為YOLOv3 主干的網絡,在基本沒有精度損失的情況下模型尺寸減小到26 MB,相對于YOLOv3 減少了90%;劉萬軍等[10]提出采用深度可分離卷積[11]構建反殘差模塊來替換YOLOv3-Tiny 的主干網絡,在精度無損失的情況下模型尺寸減小到18.2 MB,相對于YOLOv3-Tiny減少了47.7%。但是以上這些網絡相對于內存較低的處理器還是過于龐大。
近年來研究人員設計一些高效的網絡模型,例如IANDOLA 等[12]提出SqueezeNet,主要是將3×3 的卷積替換為1×1 的卷積,通過減少3×3 卷積的通道數等來減小計算量和參數量;HOWARD 等[13-14]提出了MobileNets,采用大量的深度可分離卷積設計的神經網絡,該結構可以很大程度地減少參數量和計算量。但是使用深度可分離卷積也存在缺陷,例如EfficientNet網絡[15]使用了大量低計算量(FLOPs)和高數據讀寫量的操作。由于GPU 訪存帶寬的限制,網絡浪費大量的時間在顯存中讀寫數據。當顯存較低時,即使計算量較低推理速度也很慢。例如EfficientNet-B3 的計算量不到ResNet50[16]的1/2,推理速度卻比ResNet50 慢了1 倍。本文針對目標檢測網絡計算量、參數量大以及設備推理速度慢等問題,設計一種基于GhostNet[17]殘差結構網絡架構作為YOLOv4-Tiny 的主干來降低計算量和參數量,以提高運算效率。
1 YOLOv4-Tiny 網絡
YOLO 算法[18-19]是近年來較受歡迎的神經網絡算法,該算法使用回歸的方法進行目標檢測。YOLO 用一個神經網絡結構可以同時預測出預測框和類別概率,具有執行速度快、檢測效率高的特點。YOLOv4[20]是2020 年提出的神經網絡算法,YOLOv4-Tiny 是縮小版的YOLOv4,YOLOv4-Tiny 結構如圖1 所示。
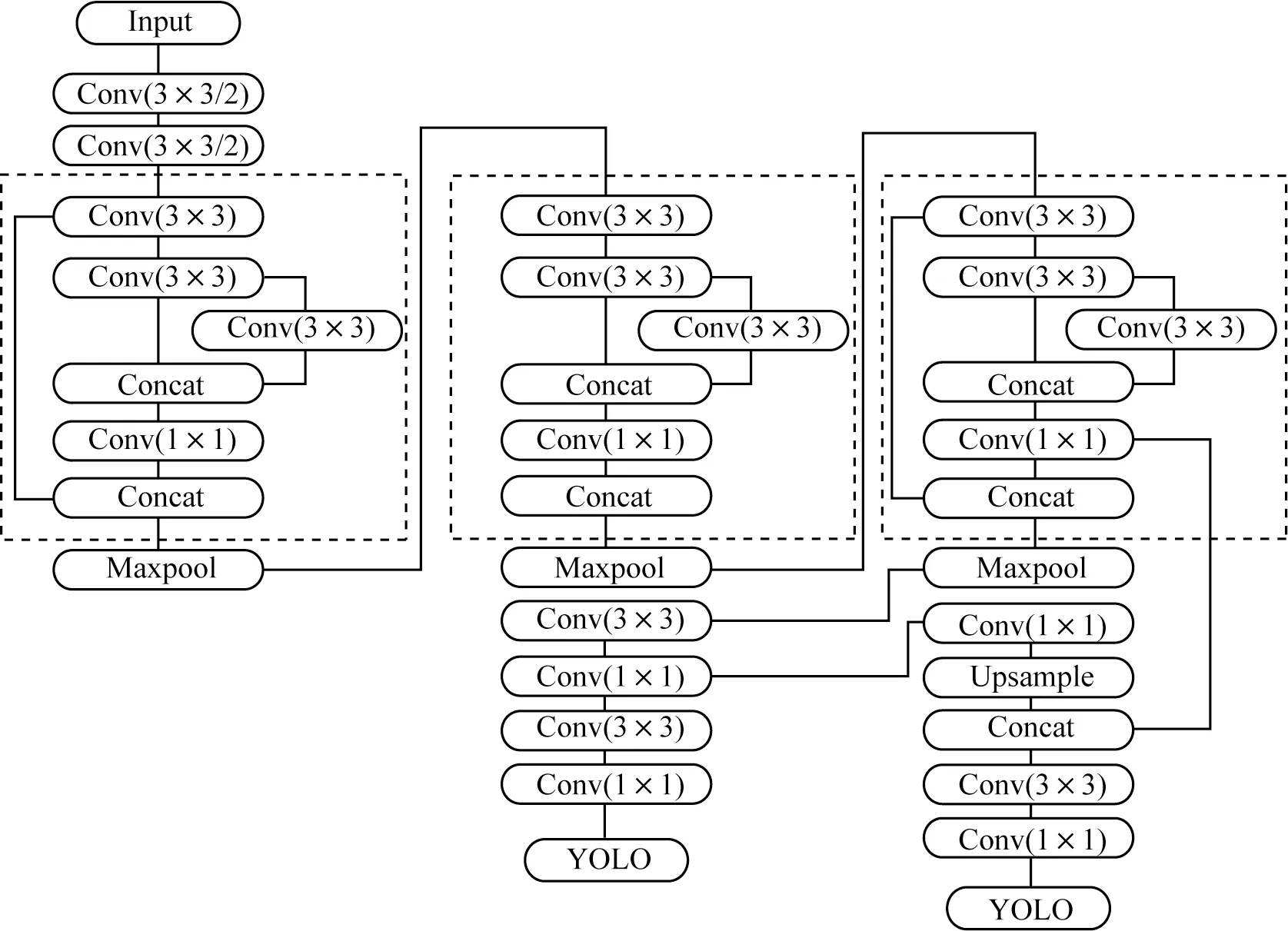
圖1 YOLOv4-Tiny 網絡結構Fig.1 YOLOv4-Tiny network structure
YOLOv4-Tiny 模型尺寸僅為23 MB,有21 層卷積層、3 層Maxpool 層和2 層步長為2 的卷積。當輸入為416 尺寸時輸出為13×13 和26×26 兩種大小的輸出層[21]。圖1 中虛線部分為Resblock_body[22],該結構經過第一個卷積層后將特征圖分組后進行后續的操作。YOLOv4-Tiny 采用了兩層兩步長的普通卷積和3 個Resblock_body 結構作為主干。采用Resblock_body 結構提高了特征的復用,相較于YOLOv3-Tiny,采用傳統卷積作為主干網絡有著更好的特征提取,在加快推理速度的同時使得參數更少。
2 YOLO-GhostNet 算法
2.1 GhostNet 殘差結構
在經過卷積后的特征圖是比較相似的,GhostNet的思想是將傳統的卷積分兩步進行:第1 步使用較少的卷積核生成一部分特征圖;第2 步對第1 步生成的特征圖使用比較簡單的計算獲得另一部分特征圖,最后將兩組特征圖拼接在一起。第2 個部分的計算可以采用3×3或5×5的通道卷積來替代。標準卷積與GhostNet卷積過程如圖2 所示。
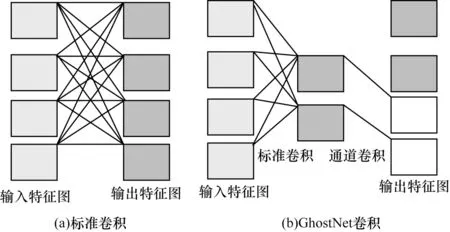
圖2 標準卷積與GhostNet 卷積Fig.2 Standard convolution and GhostNet convolution
假設輸入特征圖為Di×Di×M,標準卷積核的寬和高為K,GhostNet 卷積的第1 部分卷積核的寬和高為K′,第2 部分為K′′,輸出特征圖為Do×Do×N。
標準卷積的計算量為:
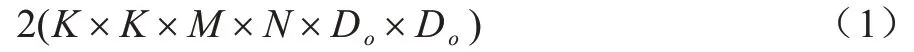
GhostNet 卷積的計算量為:
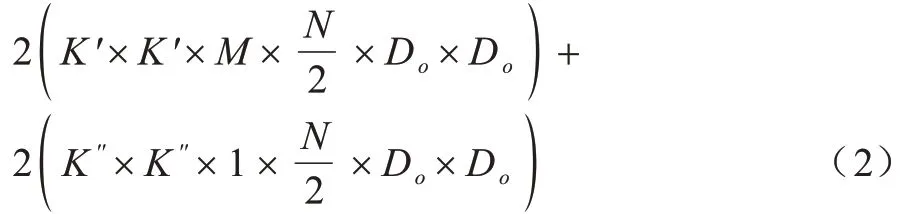
標準卷積的參數量為:

GhostNet 卷積的參數量為:
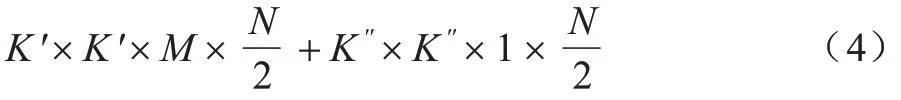
針對Resblock_body 計算量大、參數量大、推理速度慢等問題,本文提出采用GhostNet 殘差結構。該結構使用標準卷積與點卷積進行降通道,這里第2層卷積層通道為第1 層卷積層的1/2,然后使用5×5 的通道卷積獲得另一半特征圖,通過一個Concat 層拼接起來后與第一層特征圖相加。GhostNet 殘差結構如圖3 所示。

圖3 GhostNet 殘差結構Fig.3 GhostNet residual structure
假設經過卷積過后沒有改變特征圖大小,GhostNet 殘差結構與Resblock_body 結構的輸入特征圖大小都為F×F×P,第1 個卷積層大小都為C×C×P×Q,則GhostNet 殘差結構與Resblock_body 結構計算量之比為:
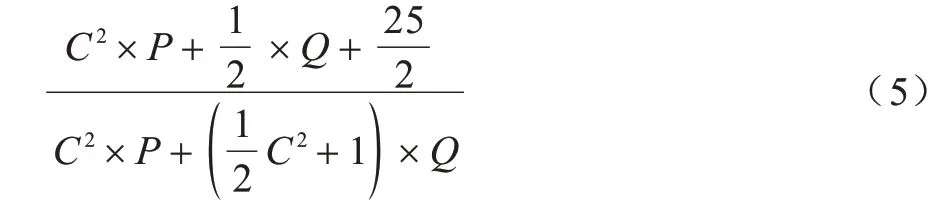
在步長為1 的卷積時,計算量之比等于參數量之比。P、Q為輸入輸出通道數,一般遠大于C,根據式(5)可以明顯看出,當輸入特征圖相同時,GhostNet殘差結構在參數量和計算量上都比YOLOv4-Tiny 的Resblock_body 結構更低,理論上推理速度也更快。
2.2 YOLO-GhostNet 網絡
YOLO-GhostNet 網絡各層參數如表1 所示。
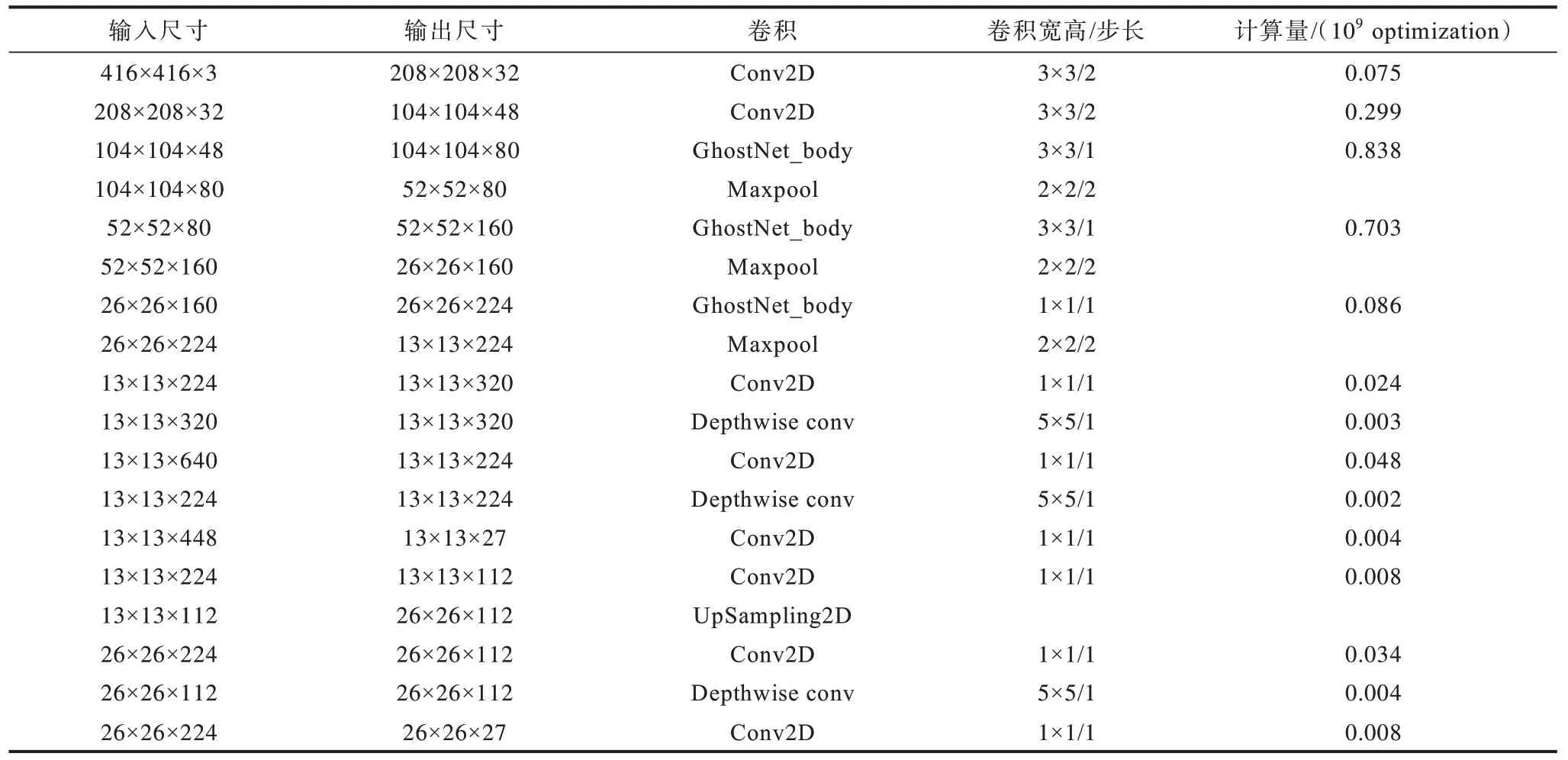
表1 YOLO-GhosNet 網絡參數Table 1 YOLO-GhosNet network parameters
YOLOv4-Tiny 網絡相對于YOLOv3-Tiny 網絡,無論是在識別精度還是模型尺寸上都有不少的改進。但是網絡在類似于CPU 這樣的處理器上,還是顯得有些龐大。因此,本文將GhostNet 殘差結構代替YOLOv4-Tiny 的Resblock_bod 結構,將網絡大部分3×3 標準卷積采用由一個點卷積和一個5×5 的通道卷積所組成的GhostNet 卷積替代。由式(1)和式(2)可知,使用GhostNet卷積替代標準卷積會隨著輸入通道的變化減少計算量和參數量,當輸入通道越大時,計算量減小越多。YOLO-GhostNet 相比于YOLOv4-Tiny 網絡計算量減小為原來的31%,參數量減小為原來的10%。
3 實驗結果與分析
3.1 實驗數據和平臺
本文實驗采用10 097張飲料數據集,分別包括雪碧、可樂、綠茶和王老吉4種飲料,每個種類大約2 500張。測試集908張,訓練集8 281張,驗證集908張。本次實驗在Windows10操作系統下進行,軟件平臺為PyCharm,訓練與驗證框架為Keras Tensorflow1.13-GPU 以及CPU 版本。硬件為AMD Ryzen5 3500X型號CPU,GTX1060 6G型號GPU,Batchsize設置為4,學習率采用0.001與0.000 1訓練100個epoch,直到Loss不再變化自動終止訓練。
3.2 結果分析
4 種飲料在2 個算法檢測精度如圖4 所示。由圖4 可知,YOLO-GhostNet 在可樂和綠茶2 個種類的精度比YOLOv4-Tiny 算法高,在另外2 種種類略微低一點。平均精確度均值(mAP)為79.43%,相較于YOLOv4-Tiny 基本沒有損失。YOLO-GhostNet 網絡有12 個BN 層,BN 層在訓練時對算法有用,但是在推理時會增加算法訪存量和復雜度。由于BN 層在做線性運算,因此可以將BN 層融入到卷積層。由于深度學習網絡有較好的魯棒性,進行BN 層的融合基本不會影響精度,還可以加快推理速度。BN 層優化前后部分參數如表2 所示。
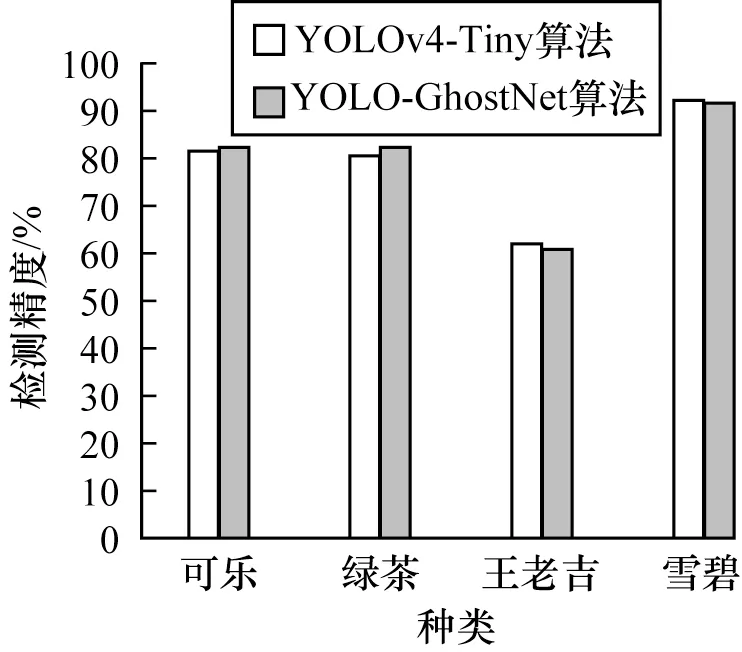
圖4 YOLO-GhostNet 與YOLOv4-Tiny 算法檢測精度對比Fig.4 Comparison of detection accuracy between YOLO-GhostNet and YOLOv4-Tiny algorithm
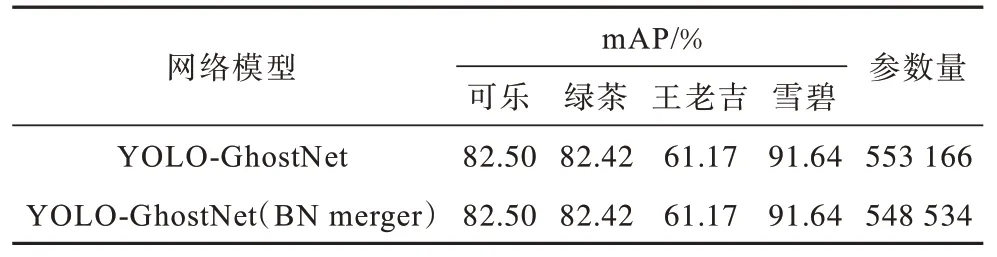
表2 YOLO-GhostNet 網絡BN 層優化前后部分參數Table 2 Some parameters before and after BN layer optimization YOLO-GhostNet network
由表2 可知,經過BN 層優化后YOLO-GhostNet網絡在各種類的精度并沒有損失,反而在參數個數上減少了4 632 個參數,對于參數影響雖然不大,但是在一定程度上減少了網絡訪存量,使得在CPU 上的推理速度快了22%,GPU 上的推理速度快了10%。
YOLO-GhostNet 與YOLOv4-Tiny 以及經過BN 層優化后的YOLO-GhostNet算法各項參數如表3 所示。

表3 YOLO-GhostNet 與YOLOv4-Tiny 各參數對比Table 3 Comparison of parameters between YOLO-GhostNet and Yolov4-Tiny
由表3可知,YOLO-GhostNet相較于YOLOv4-Tiny算法在輸入為416×416×3 大小時,平均精確度基本無損失,模型尺寸和計算量卻下降較多,大幅減少了設備的資源消耗,提高了模型的性價比,在推理時間上由于GPU 對卷積加速支持程度的區別,推理時間并沒有快很多,而在CPU 處理器上運行時,優勢可以明顯體現出來,對CPU 和計算資源不足的處理器是非常合適的。
4 結束語
本文設計一種YOLO-GhostNet 輕量級網絡模型。該模型采用GhostNet 殘差結構代替原網絡的Resblock_body,能夠解決計算量和參數量大以及推理速度慢而難以部署到計算資源少的設備的問題。此外,將YOLO-GhostNet 算法運用NCNN 框架經過半精度量化和BN 層優化后,在AMD Ryzen5 3500X 型號CPU 上推理時處理一張圖片只需要45 ms,相對YOLOv4-Tiny 算法速度提高58%,量化后的模型大小為1.1 MB,可在CPU 上達到實時檢測的效果。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
哲學評論(2021年2期)2021-08-22 01:53:34
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中華詩詞(2019年7期)2019-11-25 01:43:04
模具制造(2019年3期)2019-06-06 02:10:54
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
現代企業(2015年9期)2015-02-28 18:56:50
