高校圖書館查收查引中他引區分策略研究與實現
2022-03-13 23:24:34吳幗幗
新世紀圖書館 2022年2期
關鍵詞:高校圖書館


摘 要 圖書館的查收查引服務,有助于學者及其單位客觀認識自身科研成果產出和學術發展。論文結合查收查引工作實踐,從數據、算法、交互3個層面分析構建了他引區分策略,并對其進行系統實現。通過隨機抽取樣本報告做對比驗證,實驗得出該策略在時間效率和操作便捷性上更具優勢,最后針對影響因素進行探討,希望為學者唯一身份標識領域的研究提供思路參考。
關鍵詞 高校圖書館;查收查引;他引;姓名消歧;Python
分類號 G258.6
DOI 10.16810/j.cnki.1672-514X.2022.02.004
Abstract The search and citation service of the library helps scholars and their units to objectively understand the output of their own scientific research results and academic development. Combining the work practice of checking, receiving and citation, the article analyzes and constructs a different citation strategy from three levels of data, algorithm and interaction, and implements it systematically. Through a random sample report for comparative verification and analysis, this strategy has advantages in time efficiency and operational convenience, and the influencing factors are discussed, which hopes to provide a reference for scholars’ research in the field of unique identification.
Keywords University library. Search for citations. Other citations. Name disambiguation. Python.
0 引言
查收查引服務是指根據用戶需求在國內外權威數據庫中檢索學術文獻被收錄和被引用的情況。查收查引服務作為圖書館情報分析中的重要工作,最早可追溯到20世紀80年代。定量分析方法在科研績效分析評價中的廣泛使用[1],使得查收查引服務在圖書館參考咨詢服務中逐漸開展和普及而來。蘇秋俠通過對“985工程”高校網站數據實證調研發現,38所高校圖書館網站均設置了“查收查引”欄目[2]。在查收查引服務中,除了關注自引文獻情況,了解學者的研究方向,其中進行他引的區分有助于學校、科研單位、學者個人更為客觀、全面地了解自身科研學術成果。本文從目前高校圖書館的查收查引服務中他引區分實踐出發,分析目前圖書情報界常用的他引區分中學者唯一身份標識問題的評判依據和區分算法,系統性地構建了算法復雜度為O(n)的他引區分策略,并以Web of Science數據庫為例進行他引區分系統實現,驗證該他引區分策略的可行性。
1 查收查引業務研究及他引區分問題
隨著我國學術科研事業的蓬勃發展,查收查引需求量愈來愈大,促使各圖書館尤其是高校圖書館逐步將查收查引業務從參考咨詢中獨立出來,形成查新站、信息服務中心等專職部門進行學術文獻的收錄和引用報告的開具。業務最初多為人工查收查引,包含十余個步驟,隨著信息化時代的發展,查收查引工作逐步向業務半自動化、流程自動化轉變。業務半自動化實現主要依靠機器輔助檢索,樊亞芳提出利用文獻管理工具去重、統計總他引次數[3],這里CALIS技術中心與北京大學圖書館開發的論文收錄與引用檢索系統具有代表性[4]。查收引證工作流程自動化方面的代表有山東大學闞洪海基于水晶報表研發的查收引證報告自動生成系統[5]。2011年底中國科學院軟件研究所研發了“引證報告自動生成原型系統”,王學勤在該原型系統基礎上實現數據預處理、增加檢索數據源等功能模塊優化[6],李桂影提出使用Web of ScienceTM新平臺精煉檢索結果去除自引[7],北京郵電大學嚴潮斌提出查收引證服務融入機構知識庫[8],但目前機構庫多采用接口或數據抓取等方式獲取文獻源數據,這兩種方式均獲取不到作者識別號字段,存在元數據缺失現象。
查收查引業務中的他引區分究其根本,與學術界姓名消歧(即Author Name Disambiguation)為同族問題。沈喆等對2016至2020年姓名消歧相關研究歸納梳理發現在特征表示上網絡表示學習、異構網絡元路徑以及概率模型受到研究者的青睞,模型仍以機器學習為主,集中于優化聚類算法效率,并指出相關研究在模型推廣和時間復雜度上存在問題,模型推廣上目前實證研究多基于如AMIner、DBLP等僅涵蓋計算機信息科學的研究成果的數據庫,應用于大型綜合數據集合如Web of Science的相關研究較少;在時間復雜度上,目前相關研究中用到的聚類算法在增量消歧中時間復雜度較優的為O(n)[9]。目前他引區業務通過系統區分的代表有CALI查收查引、機構知識庫[10]。但系統獲取數據庫的數據多為接口實現,會出現部分字段如作者識別號、地址等字段缺失現象進而影響區分;另外,其判別標準都是對姓名、姓名別稱的判斷,這就導致判斷的準確率不高,部分結果仍然需要科研人員人工干預再次核對。湯森路透(http://thomsonreuters.com/)推出的ResearcherID和ORCID (open researcher and contributor ID) 兩者均可解決學術研究中的研究者姓名混淆的問題。ORCID著重于作者的標識[11],ResearcherID著重于作者學術科研產出展示與分析,ResearcherID 旨在將作者與其學術作品緊密結合[12]。最受業界推崇的根本解決方法仍為建立researchID和ORCID的統一身份標識體系。但目前國內學者作者標識意識不高,很少有學者發文標注作者ResearcherID或ORCID,且作者識別號申請機制并未嚴格控制,存在一個學者對應多個作者識別號的現象。
2 他引區分策略研究
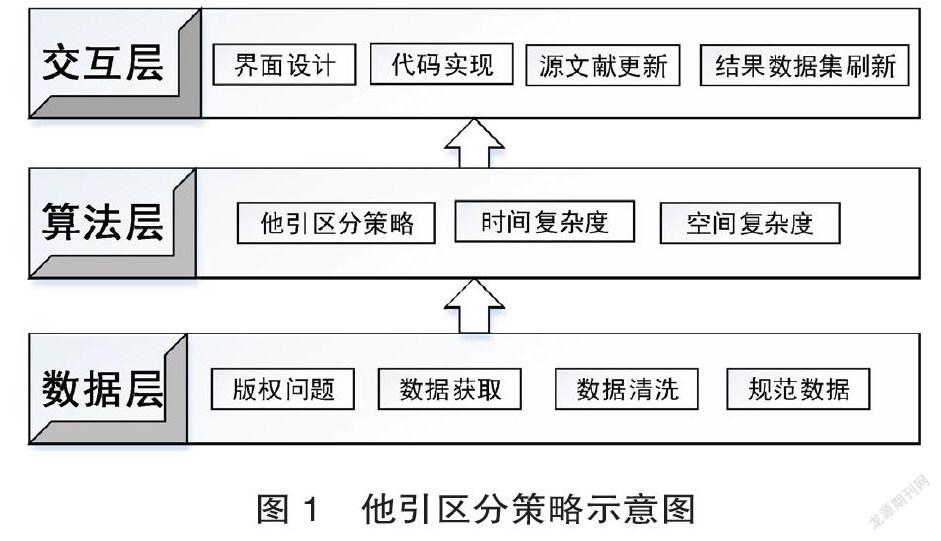
為解決數據接口獲取數據庫元數據字段缺失問題,使他引區分數據獲取更加規范、數據質量有所保證,區分流程更加優化,確保區分結果準確率的同時提升人工他引區分效率,本研究通過梳理分析查收查引服務中他引區分工作實踐,構建他引區分策略,如圖1所示。
2.1 數據層
在數據層首先要考慮知識產權的保護及版權問題,目前我國公共文化機構中與版權有關的數據庫資源主要包含開放存取數據庫、自建數據庫、商業數據庫[13],學術評價中涉及到的主要為商業數據庫。目前對于商業數據庫的版權保護,主要依賴于圖書館與數據庫商簽署的采購合同中的規定,為有效規避版權問題,本他引區分策略的數據層的相關操作中不對商業數據庫資源進行抓取,采用比較保守的方式。源數據獲取在已購買可訪問商業數據庫的網絡環境下進行,由于商業數據庫平臺在數據注入、數據加工上存在疏漏,需要對源數據(即施引文獻、被引文獻記錄信息)進行清洗,去除“臟數據”和“噪音數據”,得到包含用于他引區分的關鍵字段的“數據范式”,得到規范化的數據字段。
2.2 算法層
在算法層需要考慮他引區分算法、算法的時間復雜度及空間復雜度。算法執行的效率度量方法分為事后分析法和事前分析評估方法[14]。事后分析法是設計好測試程序和數據,利用計時器記錄不同算法編寫的程序運行時間,通過比較進而得到算法效率的高低。事前分析估算方法是在編寫程序之前,依據統計方法對算法進行估算。在進行算法的分析時主要針對算法的時間復雜度和和空間復雜度。時間復雜度用來度量算法運行需要的時間,空間復雜度是指算法所需的存儲空間需求。算法時間復雜度是時間度量,漸近時間復雜度T(n)=O(f(n))簡稱為時間復雜度,記作:T(n)= O(f(n)),它表示隨問題規模n的增大,漸近時間復雜度T(n)=O(f(n))簡稱為時間復雜度,算法執行時間的增長率和f(n)的增長率相同,其中f(n)是問題規模n的某個函數[15]。隨著輸入規模n的增大,T(n)增長最慢的算法為最優算法。在他引區分算法的設計中應充分考慮循環、遞歸等函數對于算法執行效率、算法時間復雜度、空間復雜度的影響,注意結合實踐經驗,在保證結果準確度的基礎上,對算法進行優化。
2.3 交互層
交互層是在算法層的基礎上,結合數據層處理后得到的規范化數據,通過編寫代碼對他引區分算法進行實現,進而得到操作流程清晰規范的完整他引區分系統。首先在界面的設計上應充分考慮“交互設計七大定律”[16],依據“Occams Razor”奧卡姆剃刀原理和HICKS law ,精減實體數量保證功能設計中盡量簡單,在滿足功能的基礎上給用戶最少的選擇,實際使用中交互選擇時間就會縮短,從而提高交互效率和信息產出。1956 年喬治米勒對短時記憶能力定量研究發現人類頭腦最好的狀態為記憶7(±2)項信息塊,所以在交互界面設計上設置5~9個信息塊即可。關于信息塊在頁面布局上依“The Law of Proximity”接近原則設計,非交互信息設置為不可編輯或灰色色塊。數據結果集的刷新采用Reload重載函數代碼實現,刷新后的結果集前臺展示。
3 源數據獲取與處理
3.1 數據獲取與處理工具選擇
對所構建的他引區分策略進行驗證主要采用WOS(Web of Science)平臺數據,它是情報分析工作中查收引證工作重要依托平臺[17]。在數據的處理上,除WOS平臺自帶的數據導出功能,還使用到了noteExpress文獻管理工具軟件。NoteExpress核心功能包含數據收集、管理、分析、發現和寫作等[18],可為整個科研流程中高效利用電子資源提供幫助:檢索并管理得到的文獻摘要、全文;在撰寫學術論文、專著或報告時在正文指定位置便捷地添加筆記;按照不同格式要求自動生成參考文獻。同時還可以通過自定義樣式導出題錄的樣式,進行簡單的數據規范化處理。
選擇WOS導出與noteExpress軟件相結合使用的原因主要為:初期采用Python編寫程序直接進行數據的規范化處理,但后來發現當檢索員采用不同瀏覽器或選擇瀏覽器的兼容/IE不同模式,以及當WOS版本更新后,從WOS端導出的txt文件中的內容格式會發生變化,相對應的需要進行代碼的修改。由此可見,使用代碼實現數據規范化處理,存在一定的局限性。相對應地,noteExpress能很好地解決這兩方面的問題。
3.2 數據規范化處理操作說明
數據的規范化處理主要包含作者姓名地址數據對、作者識別號兩部分基準數據清洗和規范化。因施引文獻的時間發生在被引文獻刊出后,所以可以同時對被引、施引文獻進行數據規范化處理。
作者姓名地址數據的處理方法為:在WOS平臺中首先檢索出被引文獻以及其在WOS核心合集中的施引文獻,勾選后添加至“標記結果列表”后按照日期順序排列。而后選擇“其他文件格式”后以“其他參考文獻軟件、全記錄”方式導出txt文本格式文件,一般默認文件名稱為savedrecs.txt。之后在noteExpress中選擇“導入題錄”,設置題錄來源為來自文件,過濾器對應選擇noteExpress自帶的Web of Science過濾器。導入后重點核對列表文獻與在WOS網頁端的頁面中文獻是否一致,如有缺少作者、地址等信息的進行手工補充,如果已知作者其他姓名寫法、地址其他寫法、其他地址等信息也可進行補充完善,對源數據進行擴展完善。然后在noteExpress導出題錄頁導出文獻題錄,此處需要“自定義樣式”設置提出題錄模板,導出含有“作者姓名、地址、獲取號”的被引文獻nebase.txt以及施引文獻列表nelist.txt文本文件。需特別注意在導出題錄時應選擇UTF-8編碼格式,否則會影響后期他引區分。最后使用Python編寫程序處理得到形如{文獻序號1:作者A-該作者地址集;作者B-該作者地址集……作者N-該作者地址集}規范化數據。
與此同時,作者識別號字段在noteExpress處理時會出現缺失。所以仍需采用WOS平臺自帶的“打印”功能另存為txt格式文件,通過編寫Python代碼讀取文本文件進行數據處理,數據抽取出被引、施引文獻中各篇文獻的作者識別號數據,形成“文獻序號—作者識別號”數據對作為二維數組進而做比對分析。
4 算法設計及其復雜度分析
4.1 算法設計
他引區分是以被引文獻中的作者姓名、地址、作者識別號等唯一身份標識信息為判定依據。在對施引文獻集合中的文獻逐條進行辨別的過程中,通過比較可得到每一條作者自引或是他引的“施引文獻”記錄,從而得到被引文獻的他引文獻結果集。
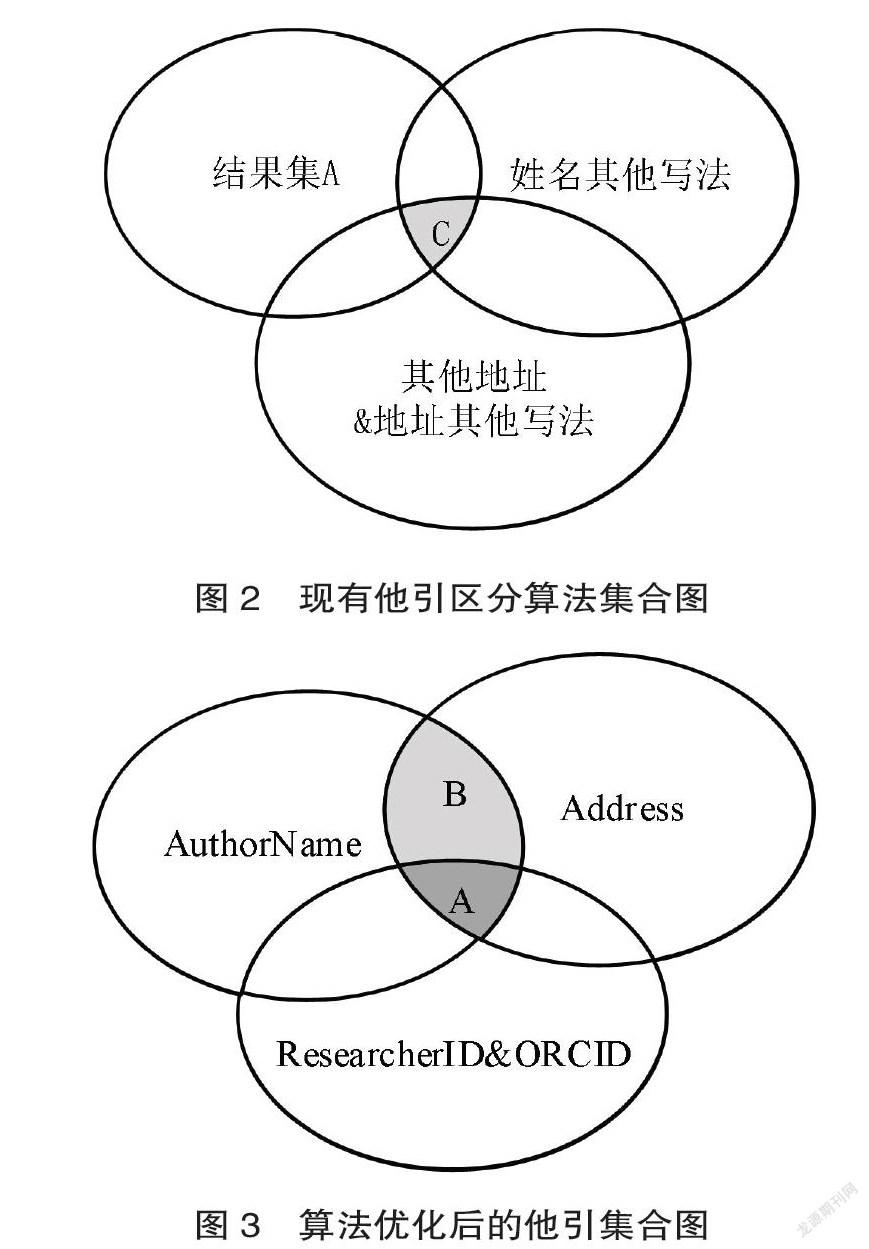
在他引區分算法的設計上,考慮到目前人工區分自引/他引大多是根據作者姓名判定,當出現重名現象時往往通過判定作者地址是否相同,在ResearcherID&ORCID屬性不為空時,有經驗的檢索員也會將其作為判定依據。從現有他引區分算法集合圖2中可以看出AuthorName+address判定出的結果集比AuthorName結果集要精確很多,AuthorName+address+ResearcherID&ORCID判定出的結果集A又比單姓名、地址、ResearcherID&ORCID的結果更加精準。與此同時,目前存在作者姓名簡寫、姓名寫法不規范、作者地址變更、同一地址寫法多樣等問題,所以我們考慮在結果集A的基礎上加上姓名其他寫法、作者其他地址、作者地址其他寫法等判定依據,從優化后的他引區分算法集合圖3可以看出結果集A+姓名其他寫法+其他地址&地址其他寫法得到的數據集C是判斷依據最為全面、結果最為精確的結果集。
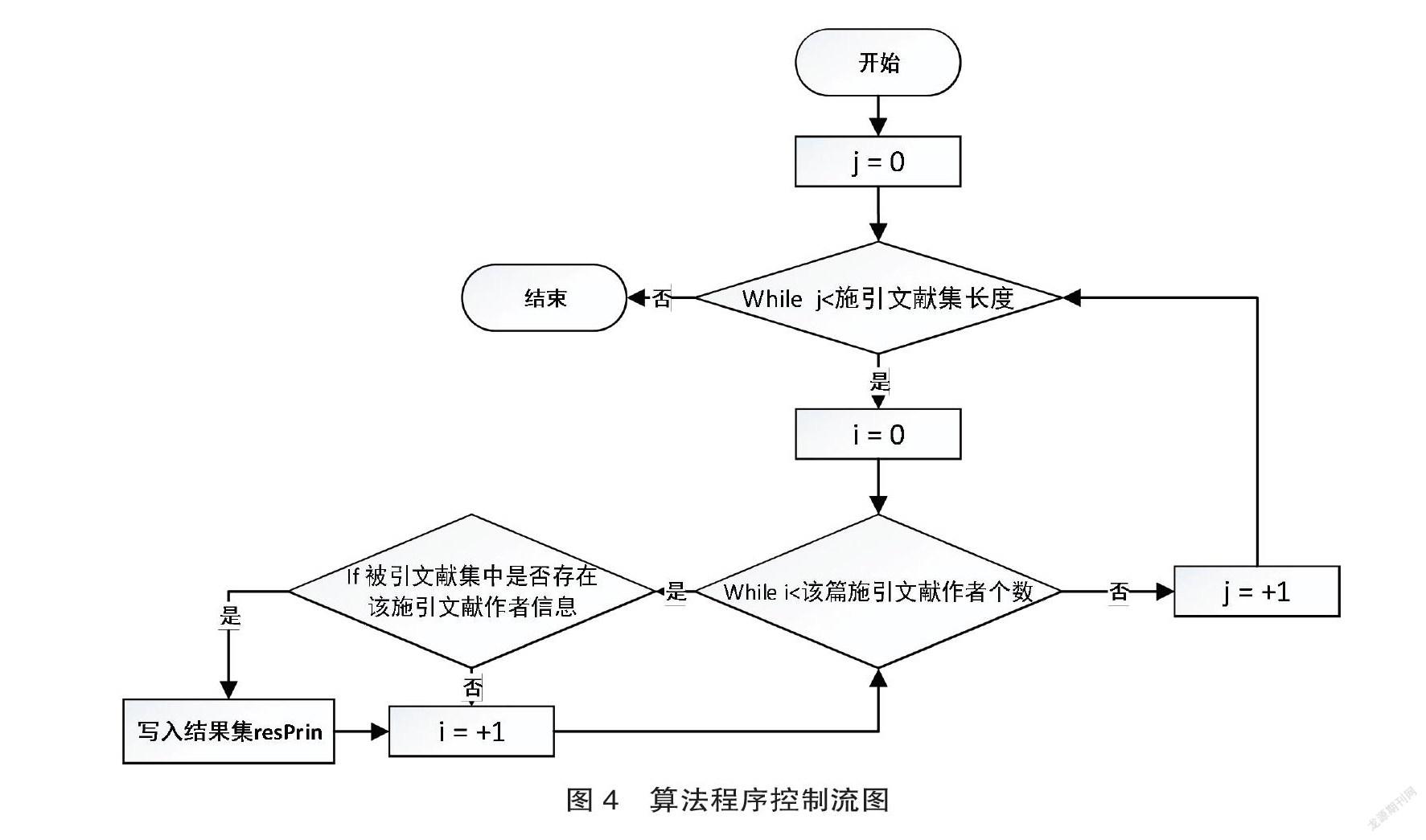
相對應地,該他引用區分算法程序控制流圖如圖4所示。
4.2 算法復雜度分析
在進行算法分析時,語句總執行次數T(n)是關于問題規模的N的函數,通過推導大O階方法分析算法的時間復雜度進而推導語句總執行次數T(n)的數量級。算法偽代碼為:
resPrin = [];j =0;? ? ? ? /* resPrin[ ]為他引結果集 */
while j< len(egData):? ? ? /* EgData 為施引文獻的二維數
組[[][][][]……]*/
test = egData[j]
i = 0;
while i <len(test):? ? ? ? ? ? ? ? ? ? ? ? ? /*遍歷施引文獻集合
中的作者集數組*/
if egSors.find(test[i]) != -1: /* EgSors 為被引文獻的
一維數組[……]*/
if j+1? not in? resPrin:? ? ? ? ? ?/*得到他引區分結
果,寫入結果集數組*/
resPrin.append(j+1)
i += 1
j +=1
根據算法導論中算法復雜度計算方法得出該算法的時間復雜度主要取決于施引文獻的文獻數目、以及施引文獻中含有作者數目。時間復雜度為:
(其中施引文獻為二維數組,m表示該施引文獻長度, n 表示施引文獻中每篇文獻中作者數組的長度。)
5 系統設計與實現
5.1 技術路線選擇
該他引區分系統實現采用C/S架構,使用Python語言編寫算法實現數據分析和處理,依照不同依據分別區分出他引文獻序號列表并前臺輸出展示。C/S架構即為客戶端/服務器(Client/Serve)模式,該架構更少依賴網絡傳輸且更為穩定。Python是一種動態的、面向對象的腳本語言,相比于Java、C語言等計算機程序設計語言,Python可以以很少的代碼高效完成任務。著名的網站包括YouTube就是Python寫的,Google也在大量使用Python進行開發,github上基于Python研究實踐越來越多。使用Python開發完成后通過Pyinstaller打包發布Windows平臺、MacOS平臺的可執行文件,可滿足跨平臺使用需求。與此同時,考慮到Web of Science數據庫版權問題本研究實踐并未進行數據抓取。本研究實踐中的實驗環境配置為:瀏覽器采用Internet Explorer11,實驗階段Web of Science[V5.31],開發語言Python為3.6.3版本。
5.2 系統實現
他引區分算法主要依據作者姓名地址、作者識別號等特征信息進行判定,均使用Python編寫代碼實現。
姓名地址依據下的他引區分實現方法為:首先基于Python的re函數庫分別讀取noteExpress處理后的被引文獻/施引文獻對應的文本文件,獲取作者地址數據后通過數據處理程序得到規范化數據對集合,即需字符串轉數組、數組拆分、字符串拼接、字符串轉數組、去空、循環嵌套等程序操作進行數據規范化處理。
作者識別號依據下的他引區分實現方法為:首先讀取被引文獻文本文件,無“作者識別號”字段則被引文獻作者識別號缺失,無需進行作者識別號的依據的判斷,在結果頁打印“源文獻無作者識別號信息”即可;當被引文獻存在作者識別號字段的情況下,再讀取被引文獻文本文件。由于不是每篇施引文獻都有作者識別號信息,所以該部分數據處理時根據文本文獻結構特點,首先判斷“入藏號”與“作者識別號”是否存在,當兩者均存在時則截取該條記錄的作者識別號信息存入施引文獻數組,若不存在“作者識別號”則說明該條記錄下的施引文獻無該字段,需向施引文獻數組中添加一條空記錄。最后通過程序對比被引文獻、施引文獻數組中每篇論文的作者識別號數據集合即可得到以作者識別號ResearcherID&ORCID為判定依據的他引區分結果集。由于考慮到目前作者識別號的使用并不是很廣泛,所以將其單獨實現并展示結果集,將來隨著作者識別號的推廣范圍增加、作者使用識別號的意識逐步提高,即可單獨使用該部分功能區分。
在交互層的實現上他引區分系統整體流程設計如圖5所示。首先讀取被引文獻文件、施引文獻列表文件;然后分別以為作者識別號、作者姓名地址為依據進行判定得出對應的結果集;最后同時輸出兩個結果集合供檢索員參考。在界面實現上,首先基于Python的tkinter工具進行展示界面繪制、然后通過函數調用方法分別運行區分功能得到作者識別號、姓名地址的依據下區分的結果集的可視化展示。當更換被引文獻、施引文獻后點擊“重新載入”按鈕觸發后臺Reload方法刷新程序得到對應的結果集。
至此該他引區分系統已經完成,通過Pyinstaller打包發布后即可應用于實際查收查引相關工作中。
6 同源數據集對比驗證分析及不足
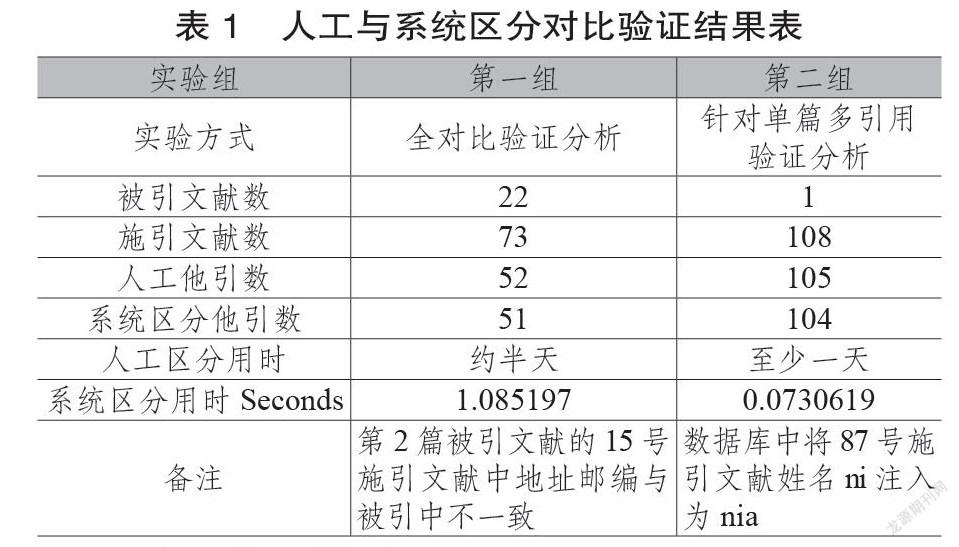
為驗證他引區分系統的可行性、準確性,隨機選取兩位檢索員的檢索引證報告,與本他引區分系統結果集進行對比分析。他引數據截至2020年8月30日。第一組報告中包含22篇被引文獻,其中施引文獻數超過2篇的有9篇,由于區分效率受被引/施引文獻中作者數目、被引文獻篇數影響,所以針對第一組報告進行全對比分析。與此同時,針對存在施引文獻較多或作者信息較多的情況,在第二組報告中選取多于50篇施引文獻的文獻進行重點對比分析,著重分析其結果可靠性以及時間效率。兩組實驗對比分析的結果如表1所示。第一組驗證分析中的基準數據為檢索員A 完成的引證報告,其中包含22篇被引文獻,73篇施引文獻共計52次他引,人工區分用時約半天。
6.1 對比分析結果
(1)通過他引區分系統的WOS中的ResearchID&ORCID作者識別號以及作者姓名地址數據對為判定依據得到的施引文獻列表中的自引文獻序號基本覆蓋人工區分出的自引序號。
(2)時間效率上,系統區分時間均在1秒以內,且算法程序的運行時間是相對穩定的,所以程序區分在時間效率上較人工區分具備時間優勢。第二組驗證分析中單篇文獻的施引文獻最多為108篇,時間效率上,系統區分他引用時仍在1秒以內,說明算法程序時間、空間復雜度是可以接受且受文獻數目影響較小的。
(3)結果準確性上,22篇文獻中除一篇施引文獻因施引文獻中的地址屬性與被引文獻中的路段信息不符,導致未識別出為自引文獻外,其他結果均與人工區分結果一致。
(4)操作便捷性上,人工區分需要多次對比被引/施引文獻中的姓名、地址、識別號等字段詳細信息,人腦每次可記憶的作者姓名數目、姓名地址數據對信息是相對固定的,而每篇文獻作者數目不定,像是藥學、物理學等合作研究者較多的作者數目可能上百個。相對應地,程序處理信息單元的優勢就突顯出來,只需導入被引/施引文獻,即可生成結果集合,操作更為便捷。
綜合兩組實驗數據分析可以發現,系統區分在時間效率以及操作便捷性上具有較為明顯的優勢,但是受文獻地址信息以及數據庫注入錯誤等問題的影響,他引區分結果集會出現小部分偏差,其中姓名拼寫問題的數據庫注入錯誤影響較大且不易避開。與此同時,檢索員反饋較多的姓名縮寫、簡寫、姓名順序寫法等問題,由于區分策略中采用的為地址信息中的作者姓名,所以姓名寫法問題的影響并不是很大。其次,本數據驗證對比分析是針對Web of Science大型綜合類數據庫展開的,由于未對數據源進行數據抓取,而是完全遵照查收查引實際工作流程展開的,所以數據集不會受到數據庫接口的影響,相對更為穩定,且網站端前臺展示的元數據信息也更為完善,更加貼合查收查引工作實際需求。一方面結合郵箱、地址等特征信息進行算法區分,與此同時借助在noteExpress進行數據規范化處理時,可進行必要且準確的人工干預,該人工干預是檢索員與作者本人為查收引證報告開具的,相較于等待科研學者自主在系統內消歧,其參與主動性和積極性更強,且在檢索員的專業指導和判定下人工干預結果更為真實可靠。
6.2 驗證分析中發現的不足及改進方法
針對地址信息中缺失路段信息、同一作者同一地址投稿時寫的郵編不一致等情況,下一步可以考慮將地址字段拆分為細粒度,即像是地址中的國家、省、市、區、路段、郵編等,檢索員可自行設置匹配度,目前系統相當于是精確匹配即匹配度100%時認定為同一個作者,設置顆粒度后可模糊區分在作者姓名匹配的前提下,地址信息字段低層級信息像是郵編、路段等信息不匹配情況。與此同時,針對作者姓名、地址等存在多地址或者多姓名寫法的問題,現為檢索員在noteExpress中核實后手工添加。下一步可考慮通過自學習算法建立學者信息庫,將每次開具引證報告中自己可提供的或查引中積累的該作者多地址,建立數據集合。這樣可以減少在noteExpress中完善作者寫法、多地址信息的操作步驟,隨著系統使用時間積累和數據集數據的不斷增加,可進一步提高區分結果的精準度。
參考文獻:
朱玉奴. 查收查引用戶需求及高質量服務策略研究[J]. 情報探索, 2019(4): 65-70.
蘇秋俠. 智慧圖書館背景下查收查引服務探析:基于“985工程”高校圖書館網站的調查[J]. 圖書館學研究, 2019(24): 61-68.
樊亞芳.利用文獻管理軟件提高論文查收查引工作效率的實踐與應用[J].高校圖書館工作,2017,37(2):63-66.
馬芳珍,李峰,季梵,等.對CALIS查收查引系統的測試和應用效果評價[J].大學圖書館學報,2016,34(2):97-102.
闞洪海,趙杰.基于水晶報表的查收查引報告自動生成的設計與實現[J].現代情報,2017,37(4):129-133.
王學勤,郝丹,鄭菲,等.“查收查引報告自動生成系統”應用實踐研究[J].圖書情報工作,2014,58(16):131-137.
李桂影.基于Web of ScienceTM新平臺的查收查引技巧分析[J].圖書館學刊,2015,37(11):62-64.
嚴潮斌,陳嘉勇,侯瑞芳,等.查收查引服務支撐需求驅動下的高校機構知識庫建設[J].現代圖書情報技術,2015(5):94-100.
沈喆,王毅,姚毅凡,等.面向學術文獻的作者名消歧方法研究綜述[J].數據分析與知識發現,2020,4(8):15-27.
張旺強,祝忠明,李雅梅,等.機構知識庫作者名自動消歧框架設計與實踐[J].數據分析與知識發現,2019,3(6):92-98.
吳飛盈,季魏紅,謝浩煌,等.“互聯網+”時代ORCID在學術期刊審稿專家管理中的應用[J].編輯學報,2018,30(4):399-401.
竇天芳,張成昱,張蓓,等.ResearcherID現狀分析及應用啟發[J].圖書情報工作,2014,58(4):40-45.
高峰.公共數字文化資源整合中的數據庫版權問題[J].圖書館,2015(9):11-16.
CORMEN T H.算法導論[M]. 北京:機械工業出版社,2013:13-15.
徐雅靜.數據結構與算法[M]北京:北京郵電大學出版社,2019:48-53.
交互式設計七大定律 [EB/OL].(2018-11-20)[2021-01-21]. https://www.jianshu.com/p/5bca0d91f802.
倫志軍,張見影,安力彬.Web of Science數據庫及檢索方法[J].現代情報,2004(8):135-136.
盤俊春.撰寫和管理論文的實用輔助工具:NoteExpress[J].中國信息技術教育,2019(20):68-70.
吳幗幗 山東大學圖書館館員。 山東濟南,250100。
(收稿日期:2021-03-26 編校:陳安琪,劉 明)
3159500338210
猜你喜歡
科技視界(2016年21期)2016-10-17 19:32:37
科技視界(2016年21期)2016-10-17 19:25:20
商(2016年27期)2016-10-17 06:38:27
商(2016年27期)2016-10-17 06:30:59
科技視界(2016年20期)2016-09-29 13:17:57
科技視界(2016年20期)2016-09-29 11:22:45
