數字人文領域的知識圖譜:研究進展與未來趨勢
2022-03-21 04:06:20朱麗雅張洪亮羅紹輝蘭度
知識管理論壇 2022年1期
朱麗雅 張洪亮 羅紹輝 蘭度

關鍵詞:數字人文 ? ?知識圖譜 ? ?智慧數據 ? ?數據資源建設 ? ?語義挖掘
分類號:G252.8
引用格式:朱麗雅, 張珺, 洪亮, 等. 數字人文領域的知識圖譜:研究進展與未來趨勢[J/OL]. 知識管理論壇, 2022, 7(1): 87-100[引用日期]. http://www.kmf.ac.cn/p/277/.
1 ?引言
數字人文(Digital Humanities, DH)起源于20世紀40年代末的人文計算。人文計算側重于對計算與人文學科之間的交叉領域進行研究、學習與創新[1]。隨著時代的信息化程度不斷加深,以及數字資源的不斷增加,僅憑人文計算難以完成更高層次的學術發現。因此,數字人文的概念應運而生,它是在計算機技術、網絡技術、多媒體技術等新興技術支撐下開展人文研究而形成的新型跨學科研究領域[2]。在我國,如何通過數字化激發創新創造活力,推動文化產業邁向高質量發展,從而更好地滿足人民群眾日益增長的精神文化需求,成為一項重要課題。例如,2019年中華人民共和國文化部發布的《文化部“十三五”時期文化產業發展規劃》中強調要促進數字文化產業創新發展,包括推進“文化+”和“互聯網+”戰略,促進互聯網等高新科技在文化產業各環節的應用。2020年,國家“十四五”規劃提出實施文化產業數字化戰略。隨著“數智時代”的到來和數字人文的興起,數字人文研究中的數據基礎設施和數字學術環境已經成為數字人文資源開發利用的重要方面。
在研究數字人文的過程中,結合知識圖譜能為其帶來新的方法與新的思考。一方面,知識圖譜作為人工智能時代一種先進的知識組織方式,能夠為數字人文研究提供優良的技術支持,去發掘那些以往在文本資源中看不見的模式和聯系。另一方面,知識圖譜作為智慧數據的表現形式,為數字資源的挖掘分析提供了基礎,進行大規模的知識圖譜構建能夠提高建設智慧化數字人文系統的效率,并為該領域研究者以及其他想要了解人文學科的人員提供專業的、智能的知識服務。然而,數字人文領域知識圖譜的研究成果雖然多,但比較分散,缺少一個系統的體系。因此,本文將深入開展數字人文領域知識圖譜研究,并整合相關研究成果。
2 數字人文領域知識圖譜概念辨析與文獻收集
2.1 ?概念辨析
在圖書館和數字人文領域,知識圖譜的概念深深植根于知識組織系統[3]。數字人文領域知識圖譜旨在利用知識圖譜這一先進的知識組織方式,對原本分散的、異構的海量數據進行整合,從而滿足領域學者的研究需求,并實現智能知識服務。與通用知識圖譜相比,數字人文領域的知識圖譜具有以下特點:
首先,在數據方面,研究者已經認識到了傳統資源利用與開發模式的局限性,開始有意識地將數字人文領域普通的數字化資源轉為智慧化資源。從以往只具有檢索功能的數據庫形式逐漸轉變為具有推理分析功能的智能平臺形式,充分利用新的信息技術來深入挖掘知識。
其次,數字人文領域知識圖譜立足于學者導向的研究需求,其目的和通用知識圖譜不同,不是要求涵蓋各范圍廣泛的知識以實現全方面的知識檢索,而是在實現大范圍的知識覆蓋的基礎上,構建更為全面的知識體系,來搭建支持智慧化的領域知識服務平臺。
最后,數字人文知識圖譜所涉及的領域較為廣泛,在構建知識圖譜的過程中,需要充分考慮不同研究領域的影響。例如,周莉娜等[4]在構建唐詩知識圖譜時提出,由于唐詩知識涉及到詩學、文獻學、史學這三大領域,通過分析三大領域現存的未決問題,就能夠較為全面地發掘出唐詩知識圖譜的構建需求。因此,數字人文領域知識圖譜與通用知識圖譜在構建方法上也存在諸多不同,尤其體現在本體構建、知識抽取、知識推理等構建技術中。
2.2 ?文獻收集
2.2.1 ?文獻來源
(1)檢索范圍。本文的研究文獻主要通過國內外數據庫獲取。考慮到研究的新穎性,選取了2010年至2021年的文獻。國內文獻來源于中國知網,選擇圖書情報類的學術核心期刊,如《中國圖書館學報》《情報學報》《數據分析與知識發現》等期刊;國外文獻來源于WOS、Elsevier、EBSCO及Springer 等數據庫,選擇Information Science & Library Science領域的學術核心期刊,如MIS Quarterly、Journal of Information Technology、International Journal of Information Management等期刊。
(2)檢索關鍵詞。國內數據庫以“數字人文”“知識圖譜”為檢索詞,國外數據庫以“digital humanities”“knowledge graph”為檢索詞,分別采用標題、主題途徑進行檢索,并對檢索結果進行篩選、去重、勘誤,去除了與主題關聯度較低的文獻。考慮到僅采用以上兩個關鍵詞進行檢索具有局限性,無法深入反映知識圖譜在數字人文領域中的具體研究內容,又選取“智慧數據”(smart data)、“本體”(ontology)、“知識抽取”(knowledge extraction)、“關聯數據”(linked data)”等作為檢索詞來挖掘知識圖譜在數字人文研究中的具體應用,保證檢索結果可以較為全面地覆蓋數字人文領域的代表性研究成果,并再次對檢索結果進行篩選、去重、勘誤。最終得到國內文獻131篇、國外文獻187篇作為初始樣本。
2.2.2 ? 研究熱點簡述
整體而言,數字人文領域知識圖譜的研究呈現出多學科、文理交融的特點,涵蓋了歷史學、文獻學、計算機科學、管理學、圖書館學等多種學科。它將過去研究中容易割裂的技術與文化進行了有機融合,利用其他學科豐富的數據資源與成熟的實踐體系,為數字人文領域知識圖譜研究帶來有力的基礎支撐,極大地豐富了該領域的研究內容,對推進數字人文智慧化研究體系具有重大意義。研究的主要熱點集中在以下3個方面:
(1)數字人文領域數據資源建設。此類研究是國內外數字人文領域知識圖譜的研究起點,主要探索與數字人文領域相關的各類數據資源建設,包括古籍文獻、圖像、視頻、音頻等各類結構化、半結構化及非結構化數據源。F. Kaplan[5]將數字人文的大數據研究作為一個結構化的研究領域,提出了三個同心研究領域的劃分。在其基礎上,國內外學者就數字人文領域數據資源分類、特色、數字化方法等問題進行了深入研究,如董政娥等[6]針對數字人文特點,對數字人文文獻資源進行了調查。數據資源建設作為數字人文知識圖譜構建的基礎步驟,能夠為其提供數據源支持。
(2)數字人文知識圖譜構建技術。此類研究是數字人文領域知識圖譜研究中的重點,利用各類數字人文領域數據源,面向數字人文領域數據的特點,研究本體構建、知識抽取、消歧等問題,解決不同知識圖譜的融合和跨語言實體的對齊問題。在這類文獻中,國內的起步雖然較晚,但是針對我國的文化特色開創了不少針對性研究,如陳濤等[7]構建的SinoPedia平臺,采用RDF三元組對目前公共領域的百科概念術語賦予唯一的URI進行資源的持久化,有助于中文知識圖譜和中文領域本體的標準化和推廣應用。
(3)數字人文知識圖譜平臺智能應用。此類研究是數字人文領域知識圖譜研究發展的必然路徑,主要著重于數字人文中的關聯數據技術運用,以支持大規模、可重用的數字人文研究,如R. Hoekstra等[8]介紹了數字人文數據管理項目的生態周期,在數字人文領域使用關聯數據技術能使研究人員以靈活的方式發布和使用數據。此外,也著重于通過對數據的重新組織構建,將其轉化為能夠支持領域研究的“智慧數據”,并形成全局知識網絡,為社會公眾、科研人員、科研機構等提供開源共享的智能知識服務[9]。
根據以上文獻收集后整理出的研究熱點,下文將從數字人文領域數據資源建設、數字人文知識圖譜構建技術、數字人文知識圖譜平臺智能應用三個方面進行詳細討論。
3 ?數字人文領域數據資源建設
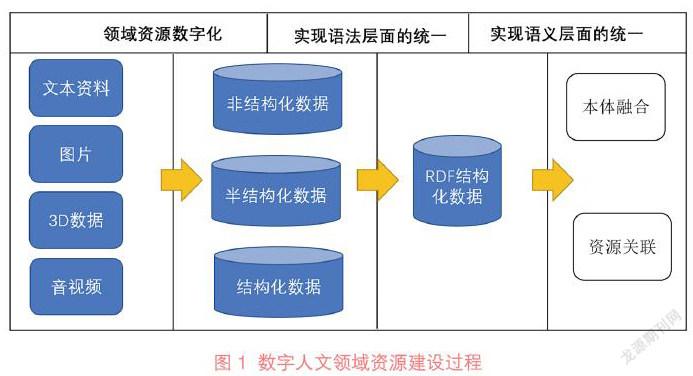
數字人文領域資源建設需經過3個階段,如圖1所示。
第一階段是進行數據集的構建,目的是實現資料的電子化,并以數據庫等形式儲存[10];第二個階段是將結構化數據、半結構化數據以及非結構化數據轉化成RDF結構化數據,實現語法層面的統一;最后一步則是通過本體融合和資源關聯來實現關聯不同數據源的資源,實現資源的分布式融合,進而實現語義層面的統一。
3.1 ?實現領域資源數字化
數據集的構建位于數字人文應用流程的基礎階段,GLAMs(Galleries, Libraries, Archives and Museums,藝術館、圖書館、檔案館和博物館)在數據積累方面有較大的優勢,因此他們一般是數據集構建的主體機構,將紙質材料信息進行數字化并對其進行組織。數字人文數據主要是文本形式,同時還有一些多源數據形式,例如圖片、音頻、視頻、3D等數據。針對不同的數據資源形式,也存在著不同的構建技術,下文將對不同的領域資源數字化過程進行分析。
(1)文本資料。文本資料包括地方古典文本資料、圖書、筆跡、家譜資料等,這些文本資料需通過圖像技術記錄和保存原始文檔的外觀結構和內容,這一過程主要利用圖像感光技術(Charge-Coupled Device,CCD)、圖像傳感技術(Complementary Metal Oxide Semiconductor,CMOS)等技術來對資源進行采集,這一過程需要與圖像光學字符識別(ORC)結合使用,使圖像轉化為計算機可識別的ASCII碼,再轉化為文本資源,同時需要機器學習來實現識別任務。例如M. Kestemont等[11]著重研究中世紀拉丁手稿,通過卷積神經網絡對手稿進行識別,并對自動分類的可行性進行了闡釋。
(2)圖片。圖片包括地圖、畫作、壁畫等,其電子化方法與文本資料類似,主要使用OCR與機器學習技術進行掃描與識別任務。如S. A. Oliveira等[12]著眼于19世紀初威尼托地區的拿破侖卡德斯地圖,提出了第一個可以自動分割和解釋19世紀初威尼托地區的拿破侖卡德斯地圖的全自動系統,該系統使用機器視覺算法來提取出每個碎片的幾何圖形,并進一步對手寫的標簽進行分類、讀取和解釋。
(3)3D數據。3D數據有文物、器皿、雕塑等。3D數據數字化是利用攝影、數字化掃描及編輯等最新的技術手段對信息進行數字化存儲或重新構建三維數字模型,最后使用相關軟件進行數字化還原[13]。三維掃描技術,可以根據需求,記錄文物最真實、最全面的形態特征。如今,3D掃描技術越來越多地應用于文物保護領域。這種方法使文物的展示和檢索更加數字化。同時,該技術的應用也更有利于文物研究、文物共享和文物傳播。這一方面國外起步較早,有影響力的項目多,國內盡管起步晚,但也取得了不少有效的成果。比較著名的項目是斯坦福大學曾經開展的“米開朗基羅項目”,該項目針對世界著名的雕塑進行三維掃描,對其進行數字化保護。
(4)音視頻。音視頻數據包括訪談、紀錄片等多媒體數據。對音視頻進行數字化即是利用技術對其進行掃描、翻拍、轉錄,進而實現數字化。近年來,聲像檔案搶救性保護逐漸成為重點研究方向之一,與此同時,結合數字技術也逐漸成為一種必然趨勢[14]。要使音頻檔案與視頻檔案得到長久保存并被更多人利用,數字化是一種較為可行的方法[15]。因此,在音視頻數字化的過程中,對其進行修復是其中非常重要的一個環節,例如內蒙古自治區檔案館通過COOL EDIT PRO2.1與ADOBE AUDITION CC等修復軟件對音頻文件進行數字化修復,首先將音量標準化提高,其次進行音量降噪處理,最后手工干預殘存噪點;至于視頻修復,則要堅持“最小干預”的修復原則,在“聽清楚、看清楚”的基礎之上,最大化保留音視頻檔案的原始憑證作用[16]。
3.2 ?實現資源語法層面的統一
隨著科技發展,人工智能、智慧數據等不斷進入人們的視野,各行各業對其研究也不斷加深,正推動著數字人文發展從“互聯”走向“智聯”。人文學科的數據資源類型多樣、來源多源、數據海量、環境異構,因此在該領域進行數據資源建設需要實現語法和語義層面的統一,由此來有效解決存在的諸如數據異構、實體消歧、關聯共享等問題,實現數據的語義增強和價值提升。
對于結構化數據,通常采用RDB2RDF的方法進行轉換,如使用D2R工具、R2RML映射語言[17]等。EXCEL和CSV文件也具有結構化數據的特點,可以使用OpenRefine來進行數據轉換。半結構化數據是介于結構化數據和非結構化數據之間的一種數據,可以被看成是結構化數據的一種形式,并不符合關系型數據庫的數據模型結構,但包含相關標記,可以用來分隔語義元素以及對記錄和字段進行分層,因此它也被稱為自描述的結構。我們可以使用XML2RDF或JSON2RDF等工具來實現非結構化數據向RDF結構數據的轉換,這一過程被稱為RDFizer實現。非結構化的文本數據需要結合自然語言處理(NLP)和命名實體識別(NER)技術,抽取出結構化數據,再進行RDF轉換。而對于圖像和音頻視頻文件的結構提取,主要先通過目標檢測識別出資源實體,再進行轉換。
3.3 ?實現資源語義層面的統一
結構化、半結構化和非結構化的數據資源統一轉化成 RDF結構的數據后,只是達成了語法層面的統一,為實現語義層面的統一,為實現資源的分布式融合,還需要將本地RDF數據集與對外開放的關聯數據資源進行關聯。
不同數據源資源之間的語義關聯,通常通過本體融合和資源關聯兩步來完成:
(1)本體融合。目前本體融合的研究主要集中于尋找本體之間的映射,隨著本體技術的發展,通過本體概念、實例及屬性之間的語義匹配機制和映射方法,實現本體最小元素之間的相似對應關系,從而實現本體的最終融合[18]。目前國內外對本體融合的研究越來越多, 也有許多成熟的本體融合系統,如PROMPT、GLUE等。AnchorPROMPT[19]是由斯坦福大學開發的用來尋找本體之間映射的工具,該工具首先進行概念比較,然后利用本體結構判斷可能相似的本體成分,但是對于復雜概念和關系的本體映射,AchorPROMPT則無法處理。GLUE[20]是基于實例的本體映射生成系統之一,利用機器學習技術,根據分類本體尋找本體間1:1的映射。M. Lamé等[21]提出一種新的本體對齊框架,能夠使文化遺產數據提供者生成定義良好且形式化良好的術語。
(2)資源關聯。不同機構在將實體數據進行RDF結構化的過程中,往往會用各自機構的域名來定義資源的URL地址,這些資源之間需要進行關聯操作。可以使用LIMES、SILK、LDIF等工具和框架來進行不同資源之間的自動化關聯,主要原理是通過機器學習和字符相似度的一些算法來進行資源屬性值的對比。
4 ?數字人文領域知識圖譜關鍵構建技術
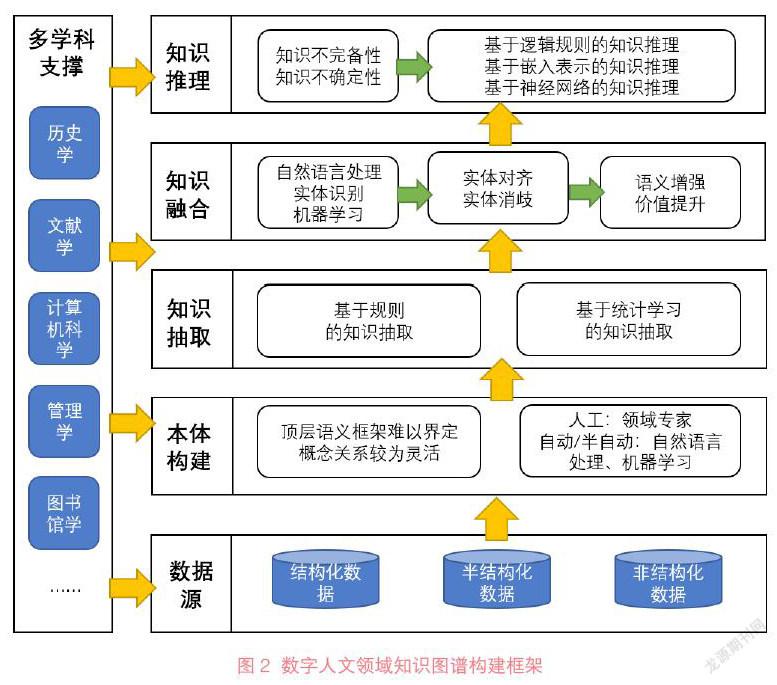
4.1 ?數字人文領域知識圖譜構建框架
關聯數據和廣義知識圖譜都是用節點和邊來表示實體和關系,本文主要探討如何用關聯數據來解釋廣義知識圖譜中的技術。關聯數據表示的語義知識圖譜中的實體必須以RDF命名,不同圖譜之間具有標準的SPQRQL查詢語言,因此可以解決知識表示和網絡服務問題。數字人文領域知識圖譜與通用知識圖譜的構建方法存在諸多不同,尤其體現在本體構建、知識抽取、知識融合等構建技術中。本節將知識圖譜的構建技術和數字人文領域的知識特點相結合,在通用知識圖譜的結構框架基礎上,對數字人文領域的知識圖譜構建框架進行歸納,如圖2所示:
4.2 ?關鍵構建技術分析
4.2.1 ?本體構建
本體根據其描述的目標范圍,可分為通用本體和領域本體。前者旨在建立可廣泛應用于不同場景的本體知識,是對通用類知識的一種規范描述;后者則是對具體領域建立相對應的知識規范描述[22]。
目前主流的本體構建方法分為人工構建和基于機器學習的自動化或半自動化構建兩種。前者依靠領域專家的知識及經驗,因此成本高且效率低下,與此同時,不同專家對同一事物的理解也不盡相同,因此人工構建的可拓展性較差。后者是指在已建立的本體語義框架下,結合自然語言處理、機器學習等技術從語料中自動抽取相關術語及屬性關系,目前這種構建方法已經逐漸成為主流。
國外在領域本體的構建方法上的系統分析研究已經較為成熟,通過文獻分析可知,國外典型的本體構建方法有8種,分別為:IDEF5法、骨架法、TOVE法、METHONTOLOGY法、KACTUS工程法、SENSUS法、七步法以及循環獲得法[23]。相較之下,國內起步較晚,技術相對落后,因此需要借鑒國外的構建方法,同時結合新的內容,形成新的觀點方法。目前國內比較有代表性的本體構建方法主要有兩種,分別是基于敘詞表的構建方法和基于本體論工程法的半自動化與自動化構建方法[24]。
近年來,一些學者構建了一些大型通用本體,如DBPedia Ontology、YAGO等。自然科學領域中大型實用化的領域本體發展迅速,因為其概念間的關系比較明確。目前比較有影響力的領域本體有GeoNames Ontology、The Drug Ontology、UMLS SemNet、Gene Ontology及SNOMED等[25]。與自然科學領域不同,在頂層語義框架難以界定、概念關系較為靈活的人文社會科學領域中,大規模的實用化本體則較為少見[26]。部分學者嘗試開展對歷史哲學等相關領域的本體構建研究,如國史本體、二十四史本體、哲學本體等 [27-28];鄧君等[29]針對檔案領域構建了口述歷史檔案資源領域本體模型,有助于檔案領域學者展開深層次研究;與此同時,在戲劇、民俗等領域,一些學者利用元數據、本體技術等進行信息資源描述和組織[30]。
在語義環境下,領域本體的應用已成為一種必然,雖然國內目前的構建方法還不夠完善,但自動化及半自動化的構建方法必將是未來的發展趨勢。領域本體構建的進一步優化將著眼于以下幾個方面:建立完善的評價機制,提高本體的重用性以及注重本體的共享性。同時,構建數字人文學科領域的大規模的實用化本體也將成為日后學者研究的重要方向之一。
4.2.2 ?知識抽取
隨著自然語言處理技術的不斷發展,數字人文領域內知識抽取的方法已經趨向于成熟,主要可以分為兩個角度:基于規則的方法和基于統計學習的方法。
基于規則進行知識抽取的核心要點,就是關系規則的定義和規則兩邊的實體抽取,規則的精確度直接影響著所抽取知識的質量。在數字人文領域,基于規則的方法需要考慮詞語之間的搭配關系和上下文語境。該方法具有準確率高、構建方法簡單的優點。例如,劉悠然等[31]提出了一種基于規則的古漢語句型統計方法,該方法在標注高頻字后,便能依據設定的約束規則對未標注字詞進行標注并統計句型,從而簡化古漢語研究過程中的人工統計工作。該統計方法在約束規則設置合理的情況下,對句型統計的正確率能夠高于95%。但是,該方法也同時具有諸多局限性。尤其是對于數字人文領域內的文本,規則的針對性比較強,也就代表著其泛化能力較弱。例如,謝明鴻等[32]提出了通過固定句式搭配規則來識別人物關系,但由于中文文本的表達方式十分多樣,會出現預測結果和實際不一致的情況。如果需要獲得更好的抽取效果,就要重新制定新的規則。因此,數字人文領域的研究者更傾向于采用基于統計機器學習的方法。
基于統計機器學習的方法在數字人文領域得到了越來越廣泛的應用,相比于基于規則的方法,基于統計學習的方法不需要構建規則,一般都是自動地從訓練語料中學習參數。例如,L. L. Liu等[33]采用基于條件隨機場的方法對用于歷史研究的文學漢語命名實體的算法識別進行了研究。該方法在測試中的表現良好,從《地方志》中抽取出了大量人名和地名,用于豐富中國傳記數據庫(CBDB)。秦賀然等[34]利用TextRank模型對古漢語文本進行關鍵詞抽取。通過實驗,利用TextRank模型抽取了《春秋經傳》中的關鍵詞,準確度能達到84%,這些關鍵詞能夠讓數字人文領域的學者快速地了解到春秋時期的歷史事件和春秋的時代面貌。并且,該模型的應用空間也十分廣泛,不但能用于古漢語文本,而且也能應用于現代漢語,例如構建自動摘要系統。
綜合來看,為了獲取更豐富的數據以支持數字人文領域內知識圖譜的構建,可以在抽取之前進行數據預處理,減少抽取時間,提高準確率。也可以將基于規則和基于統計的方法相結合,由于數字人文領域的實體和關系具有一定的特征,可以通過人工少量標注之后,自動生成規則,同樣也有利于提高領域內知識抽取的精度和效率。
4.2.3 ?知識融合
傳統的知識融合問題主要涉及三方面,分別為知識融合框架、知識融合算法以及知識融合應用。知識融合算法可分為兩類,分別是基于信息融合技術的知識融合算法和基于融合規則的知識融合算法,其中,大部分知識融合框架都是基于本體來構建的[35]。知識融合算法基于信息融合技術和基于規則的知識融合算法。針對前者,很多研究都是借鑒信息融合算法, 將其移植到知識融合中, 構造針對知識融合的全新算法。基于Bayes方法、D-S理論、蟻群優化算法的3種知識融合方法是融合決策處理的流行方法。周芳等[36]在知識管理領域中, 通過融合處理, 提高了結果可信度,并提升實現系統任務目標的能力。后者則是通過找尋信息之間的關聯,用規則來進行知識表示。
而在數字人文領域,針對其特點,知識融合主要用于在不同來源實體間建立關聯關系,將從多個分布式異構信息來源中發現的數據進行整合,同時進行識別和判斷,消除可能存在的歧義、數據冗余和不確定性等問題,最終形成新的知識[37]。知識融合可以有效解決在數字人文領域所存在的數據異構、實體消歧、關聯共享等問題,實現數據的語義增強和價值提升。如陳濤等[38]在構建CBDBLD(CBDB關聯數據平臺)時,將轉換的RDF數據與上海圖書館人名規范庫、VIAF、DBPedia等數據集進行關聯,采用SILK或者LIMES框架進行關聯;F. Frontini等[39]提出了一種算法,來自動消除法國文學批評語料庫中所被提及的歧義,其成功地將通用知識庫(如DBpedia)與特定領域的知識庫結合在一起。
4.2.4 ?知識推理
知識推理是針對知識圖譜中已有事實或關系的不完備性,挖掘或推斷出未知或隱含的語義關系。一般而言,知識推理的對象可以為實體、關系和知識圖譜的結構等。目前主要有基于邏輯規則的知識推理、基于嵌入表示的知識推理以及基于神經網絡的知識推理三類方法。作為知識圖譜的核心功能之一,知識推理為解決數字人文歷史性所帶來的知識的不完備和不確定提供了思路,但在當前的數字人文項目中還少有成熟應用。
基于路徑規則的知識推理通過隨機采樣提取到的關系路徑特征來提高計算效率,但是降低了知識圖譜中信息的利用率;同時利用監督學習方法建立的關系推力模型很大程度上會受到訓練數據的影響。對此,劉嶠等[40]提出雙向語義假設,對全局關系進行推理,結合局部模塊進行加權合并,最終得到完整的邏輯規則推理算法。周莉娜[41]提出了面向本體構建的領域知識推理框架,通過TPO4DK模型,構造形式化的推理規則,對唐代詩人之間以及詩歌—詩人本體中的詩人流派屬性、詩歌題材與主題屬性進行知識推理,實現對唐詩文獻學的版本證偽的應用。陸泉等[42]提出一種基于OWL語言的模糊本體表現模型,通過SWRL語言表示精確規則和模糊規則,構建面向知識發現的推理模型。該模型可以同時描述精確知識和模糊知識,簡化了對模糊知識的表示和處理;同時,數字人文資源所蘊含的多源異構數據,特別是圖像數據資源之間的語義關系和概念層次結構也推動領域內的知識推理,如周知等[43]參考Eakins圖像語義層次模型和王曉光等人提出的數字圖像語義描述層次模型[44],對圖像資源的語義進行了多層描述,實現實體之間、概念之間的深度關聯,滿足知識推理的需要。
基于嵌入表示的知識推理技術優勢同樣明顯。通過將圖結構中隱含的關聯信息映射到歐氏空間,使得原本難以發現的關聯關系變得顯而易見。因此,基于嵌入表示的推理是知識圖譜推理技術的重要組成部分。基于神經網絡的知識圖譜推理,充分利用了神經網絡對非線性復雜關系的建模能力,能夠深入學習圖譜結構特征和語義特征,實現對圖譜缺失關系的有效預測。一般地,應用于知識圖譜推理的神經網絡方法主要包括CNN方法、RNN方法、圖神經網絡(Graph Neural Networks,GNN)方法、DRL方法等[45]。
5 ?數字人文領域知識圖譜平臺智能應用
5.1 ?相關平臺項目概述
在信息技術飛速發展的背景下,信息獲取、存儲和傳播的方式都產生了巨大變革,數據成為數字人文研究的基礎與核心之一,因此,數字人文學者對于領域內研究資料的處理方式也產生了翻天覆地的變化。在傳統的人文研究中,學者往往注重數據的收集與整理。但由于數字化技術的欠缺以及原始資料本身的質量問題,學者整理出來的數據經常是不完整、碎片化的。在數字化技術得到深入發展之后,人文領域的數據雖有了較為快捷與全面的收集,但仍然是雜亂的,并不利于領域內學者的研究。隨著數字人文領域知識圖譜規模的逐漸擴大,傳統的關系型數據庫無法有效管理其中的數據。該領域學者的研究往往需要多個數據集的交叉查詢,例如圖像、文字、音頻等數據之間都存在一定的關聯,發掘這些聯系有助于人文研究的推進。因此,目前的研究一般采取關聯數據技術(即語義知識圖譜)來實現數字人文領域的數據管理。陳濤等[46]將關聯數據技術與廣義知識圖譜進行了對比后指出,關聯數據側重于知識的發布與鏈接,與注重“挖掘”的廣義知識圖譜不同,關聯數據技術更側重于“推理”,即展示資源之間的關聯關系。利用關聯數據技術能夠支持大規模、可重用的數字人文研究[47],通過對數據的重新組織構建,將其轉化為能夠支持領域研究的“智慧數據”,并形成全局知識網絡。表1列舉出了國內外數字人文領域平臺建設的幾個典型代表。
從中可以看出,數字人文關聯數據平臺所橫跨的領域十分豐富,主要有歷史學、檔案學、藝術、文學等。其中,歷史學是數字人文平臺實踐最多的領域之一,而其他相關領域也與歷史學有著千絲萬縷的聯系,能夠體現出當今世界各國對于歷史文化資源保存與利用的重視程度。
5.2 ?平臺特點分析
5.2.1 ?跨界合作突出
國內外先進的數字人文關聯數據平臺一個突出的特點就是跨界合作,這是數字人文的跨學科屬性所要求的。合作方式主要可以分為以下兩種:
一方面是國內外機構的廣泛合作。S. Wong[48]指出,數字人文學科的合作性是該領域的核心價值之一,采用合作的方法可以利用各種機構的優勢和專業知識,從而產生深遠影響。比如歐洲數字圖書館Europeana,有超過15個國家的200多個文化機構為該數字圖書館的開放數據集提供了貢獻,包括倫敦的大英圖書館、阿姆斯特丹的里杰克斯博物館和巴黎的盧浮宮等著名機構以及歐洲其他地方較小的文化遺產組織和圖書館[49]。此外,由北京大學中國古代史研究中心與哈佛大學費正清東亞研究中心合作開發的中國歷代人物傳記資料庫項目(CBDB),同樣是國內外研究中心合作建立資料庫的經典實踐,該平臺能夠展現歷史人物之間的各類關系,并形成特有的社會關系網絡,實現人物之間隱性關系的挖掘與呈現[50],在研究中國歷史的同時,能夠促進西方國家對中國傳統文化的理解。
另一方面是校外機構與高校的合作。大多數字人文機構隸屬于大學,以高校圖書館依托進行平臺建設,由高校圖書館、檔案館提供數據資源和人才,企業、基金會提供資金等。比如伊利諾伊大學香檳分校人文、藝術和社會科學計算所與亞伯拉罕·林肯博物館合作開發的林肯著作數據庫,該數據庫由伊利伊諾大學香檳分校主導開發,投入人才資源支持與后續平臺管理和服務,亞伯拉罕·林肯博物館提供相關歷史資源,形成人才資源與歷史資源的相互支撐[51]。學術機構、圖書館、檔案館、博物館以及企業、基金會等之間建立廣泛的聯系,再加上人文、社科、理工等多學科參與,有利于資源的整合與創新利用。
5.2.2 ?實踐導向性強
首先,較多數字人文關聯數據平臺為包括人文學科在內的一系列學科提供服務,例如提供數字化成像、數字保存、元數據創建、數據策展與管理、GIS和數字映射、數字出版等多種數字學術功能。例如,由德國的柏林洪堡大學圖書館信息學院、曼海姆大學、開放知識基金會等多個機構合作研發的歐洲數字手稿項目,該項目構建了DM2E數據集,提供元數據和鏈接以及展示、處理、整合數據的相關工具,以便數字人文研究者和想要了解歐洲歷史文化的群眾直接訪問歐洲各地各種文化遺產機構的數字化內容[52]。這也體現了數字人文關聯數據平臺服務于實踐,服務于解決實際問題的特點。
其次,這些平臺都較為注重成果對大眾的呈現與宣傳。例如敦煌壁畫敘詞表關聯數據服務平臺通過敘詞表可視化,降低了敘詞表的認知難度,實現了專業化敘詞表向適用于大眾利用的過渡[53]。上海圖書館研發的中國家譜知識服務平臺[54],基于大量數據,采用時空結合對姓氏、人物及人物間的相互關系進行全景式的可視化展示和統計分析。由此可知,數字人文關聯數據平臺進行成果呈現一方面有助于數字人文研究的推廣,提升數字人文學科影響力,另一方面有助于促進文化從現實世界向數字空間延伸拓展,豐富人類的數字文明內涵。
5.2.3 ?數據孤島現象突出
數字人文關聯數據平臺數據資源的智慧性主要體現在及時性、可獲取性以及可利用性3個方面。因此需要形成動態的、開放關聯的數據資源,不斷豐富其內容與形式。近年來,國內外對于數字人文關聯數據平臺建設越來越重視。但與此同時,新的隱患也在形成。王曉光提出了數字人文研究中的數據失秩現象,尤其在中國大陸,這種現象更為嚴重,他指出:數字資源建設的主體走向多元化,圖書館、博物館、檔案館等相關研究機構都投入了相當多的資金與人力支持,卻導致了無數個更大的“數據孤島”出現,比紙質文獻時代更嚴重[55]。這種現象淡化了領域學者為平臺建設所付出的相關努力,甚至可能給人留下一種數字人文研究的生命周期很短暫的印象。
縱觀形成數據孤島現象的原因,首先是隨著研究的開展,資源數據量與研究資料的范圍也在拓展。除了傳統的文獻資源以外,其他實物、圖像、音視頻等資料都會被列入數字人文學者的研究范圍內。數字人文領域基礎資料種類的繁雜容易造成相關研究的彼此孤立。其次,較多平臺管理者傾向于將重點放在規劃和啟動新項目上,從而容易忽略對舊項目的后續管理、維護[56]。隨著時間的推移,原有的數據資源格式可能會與現有的技術存在不相兼容的情況,舊的數據資源將無法與新的目標用戶需求匹配。若不能及時更新現有的技術方法及操作環境,反而一味開展新項目,平臺資源便很難保持鮮活。如何改善數據孤島現象,實現對數字人文智慧數據資源的統一表示,已經成為數字人文智慧化知識服務平臺發展道路上的重要議題。
6 ?數字人文領域知識圖譜研究的未來趨勢
綜合近年來的數字人文領域知識圖譜的研究成果,結合目前數字化技術的智慧化趨勢,我們可以觀察到如下發展趨勢:
(1)多元數據集成。數據的長期保存是數字人文領域知識圖譜平臺非常重要的基礎職能之一。與其他領域相比,數字人文領域中的數據相對來說比較特殊,包含了語言、文獻、繪畫、音樂等多種形式,它們的維度超越了可被物理上測量的范圍,更加依賴于語義和語法[57]。對數字人文領域的研究離不開人文文獻資料的數字化,龐大的數據資源在數字人文領域具有非凡的價值,而如何處理好這些數據,將其轉換為機器可理解、可處理的資源至關重要。而數字人文研究只使用以往的數據資源是遠遠不夠的,還需要大量鮮活的、正在被創造出來的數據。因此,可以利用社會性網絡和開放存取的信息作為信息來源,將跨地域、跨學科、跨國別的聯系變得更加緊密,在經過深度語義標注、結構化、形式化和可視化處理后,將數據轉變為高級形式的智慧數據,并推進到更細化的分支領域。
(2)多模態知識融合。早期數字人文領域的多模態知識融合更多地針對不同知識源的各類知識,強調知識來源的多樣性。未來,多模態知識融合將進一步突破傳統的時間和空間限制,對于不同知識源的多樣化特征進行涵蓋與擴展,依托知識圖譜智能平臺的數據整合能力,打通文本、影像、實體(人物、地點、年代、地域、事件)等多維度語義資源,為體系化、語義化、系統化的數字人文資源整理、研究提供能力支撐。此外,對于同一知識源的不同解讀也構成了數字人文資源的不同維度與層次,從而能夠更好地滿足數字人文領域研究中深層次的信息需求,并實現大數據環境下智能知識服務的不斷創新。
(3)多學科交叉應用。數字人文領域關聯數據平臺構建的創新性研究應用于多種學科領域,有助于形成相互補充、相互驗證的有機整體成果,能夠將不同學科之間的距離縮小,促進學科的融合。一方面,學科的專業化程度不斷提高,內部發展逐漸精細化,能夠更具體、更深入地涵蓋數字人文領域內容;另一方面,學科交融產生新的學科,如數字藝術、數字史學等。梁晨等[58]指出,數字技術或數據庫平臺還可以是微觀信息的加速器或對撞機,并在數據的交叉和對撞過程中呈現出各種特征、趨勢和規律。這些變化都在逐漸要求領域內研究人員不斷突破不同專業之間的界限,為數字人文研究帶來新的獨有的研究范式,進一步推動交叉學科的穩固發展。
7 ?結論
從構建到為數字人文研究提供基礎設施支持,數字人文領域的知識圖譜研究經歷了不斷的發展與變革,以適應“數智時代”傳統文獻資源向智慧數據資源的轉型。目前,數字人文領域知識圖譜已經能夠較好地提供知識發現和推理功能,支持多種類型的數字人文資源描述與融合,并能夠滿足文化的長期保存和共建共享的需求。本文以數字人文領域國內外會議、期刊發表的相關文獻為研究對象,對數字人文領域的數據資源建設、知識圖譜構建、智能服務平臺3個方面進行調研,認識到數字人文領域知識圖譜研究能夠為該領域資源的數字化建設制定統一規范的方法參考,并為數字人文研究提供基礎設施,更好地實現智慧數據資源的轉型與升級。在這個過程中,新的機遇、新的挑戰都在不斷發生,而知識圖譜作為人工智能時代一種先進的知識組織方式,能夠充分發揮其知識融合中介的作用,為“數智時代”的發展提供源源不斷的動力,并為我國未來的數字人文發展道路提供指引與方向。
參考文獻:
李啟虎, 尹力, 張全.信息時代的人文計算[J].科學, 2015, 67(1):35-39, 4.
劉煒, 葉鷹.數字人文的技術體系與理論結構探討[J].中國圖書館學報, 2017, 43(5):32-41.
HASLHOFER B, ISAAC A, SIMON R. Knowledge graphs in the libraries and digital humanities domain[J]. arXiv preprint, 2018, arXiv:1803.03198.
周莉娜, 洪亮, 高子陽.唐詩知識圖譜的構建及其智能知識服務設計[J].圖書情報工作, 2019, 63(2):24-33.
KAPLAN F. A map for big data research in digital humanities[J]. Frontiers in digital humanities, 2015, 2(1): 1-7.
董政娥, 陳惠蘭.數字人文資源調查與發展對策探討[J].情報資料工作, 2015(5):103-109.
陳濤, 劉煒, 朱慶華.中文百科概念術語服務平臺SinoPedia的構建研究[J].中國圖書館學報, 2018, 44(4):4-18.
HOEKSTRA R, MERO?O-PE?UELA A, DENTLER K, et al. An ecosystem for linked humanities data[C]//European semantic Web conference. Cham: Springer, 2016: 425-440.
Zeng M L. Smart data for digital humanities[J]. Journal of data and information science, 2017, 2(1): 1-12.
王軍, 張力元.國際數字人文進展研究[J].數字人文, 2020(1):1-23.
KESTEMONT M, STUTZMANN D. Script identification in medieval Latin manuscripts using convolutional neural networks[C]// Premiere annual conference of the International Alliance of Digital Humanities Organizations. Montreal: McGill University, 2017.
OLIVEIRA S A, KAPLAN F, DI LENARDO I. Machine vision algorithms on cadaster plans[C]// Premiere annual conference of the International Alliance of Digital Humanities Organizations. Montreal: McGill University, 2017.
張輝, 王冬梅.基于三維掃描技術的唐陵雕塑數字化保護研究[J].藝術與設計(理論), 2016, 2(4):91-93.
劉江霞.模擬音視頻檔案數字化質量控制研究[J].檔案學研究, 2018(1):101-106.
錢萬里.傳統聲像檔案的數字化處理[J].檔案與建設, 2007(8):22-24.
羅永俊, 畢曉然, 郝陽.內蒙古民族文化珍貴音像檔案搶救技術研究[J].黑龍江檔案, 2020(5):43-45.
R2RML: RDB to RDF Mapping Language [EB/OL]. [2021-07-23]. https: //www.w3.org/2001/sw/rdb2rdf/r2rml/.
熊順, 劉平芝, 蘇宗義, 等. 基于語義匹配映射的地理信息本體融合方法研究[J]. 測繪科學與工程, 2017 (1): 51-58.
NOY N F, MUSEN M A. The PROMPT suite: interactive tools for ontology merging and mapping[J]. International journal of human-computer studies, 2003, 59(6): 983-1024.
DOAN A H, MADHAVAN J, DHAMANKAR R, et al. Learning to match ontologies on the semantic Web[J]. The VLDB journal, 2003, 12(4): 303-319.
LAMé M, PITTET P, PONCHIO F, et al. Heterotoki: non-structured and heterogeneous terminology alignment for digital humanities data producers[C]//Open data and ontologies for cultural heritage. Rome: Antonella Poggi, 2019.
任飛亮, 沈繼坤, 孫賓賓, 等.從文本中構建領域本體技術綜述[J].計算機學報, 2019, 42(3):654-676.
尚新麗.國外本體構建方法比較分析[J].圖書情報工作, 2012, 56(4):116-119.
岳麗欣, 劉文云.國內外領域本體構建方法的比較研究[J].情報理論與實踐, 2016, 39(8):119-125.
WIMALASURIYA D C, DOU D. Ontology-based information extraction: an introduction and a survey of current approaches[J]. Journal of information science, 2010, 36(3): 306-323.
何琳, 陳雅玲, 孫珂迪.面向先秦典籍的知識本體構建技術研究[J].圖書情報工作, 2020, 64(7):13-19.
王穎, 張智雄, 孫輝, 等.國史知識的語義揭示與組織方法研究[J].中國圖書館學報, 2015, 41(4):55-64.
THAKKER D, KARANASIOS S, BLANCHARD E, et al. Ontology for cultural variations in interpersonal communication: building on theoretical models and crowdsourced knowledge[J]. Journal of the Association for Information Science and Technology, 2017, 68(6): 1411-1428.
鄧君, 王阮.口述歷史檔案資源知識組織與關聯分析[J].情報資料工作, 2021, 42(5):58-67.
周耀林, 趙躍, 孫晶瓊.非物質文化遺產信息資源組織與檢索研究路徑——基于本體方法的考察與設計[J].情報雜志, 2017, 36(8):166-174.
劉悠然, 龍丹. 一種基于規則的上古漢語句型統計方法的設計與實現[C]//澳門大學人文學院、中國中文信息學會、澳門語言學會.第十五屆漢語詞匯語義學國際研討會論文集.北京: 外語教學與研究出版社, 2014:428-433.
謝明鴻, 冉強, 王紅斌.基于同義詞林和規則的中文人物關系抽取方法[J/OL].計算機工程與科學, 2021, 43(9):1660-1667.
LIU C L, HUANG C K, WANG H, et al. Mining local gazetteers of literary Chinese with CRF and pattern based methods for biographical information in Chinese history[C]//Proceedings of 2015 IEEE international conference on big data (Big Data), Santa Clark, 2015: 1629-1638.
秦賀然, 王東波.數字人文下的先秦古漢語關鍵詞抽取應用——以《春秋經傳》為例[J].圖書館雜志, 2020, 39(11):97-105.
唐曉波, 朱娟.大數據環境下知識融合的關鍵問題研究綜述[J].圖書館雜志, 2017, 36(7):10-16.
周芳, 劉玉戰, 韓立巖.基于模糊集理論的知識融合方法研究[J].北京理工大學學報(社會科學版), 2013, 15(3):67-73.
高勁松, 梁艷琪.關聯數據環境下知識融合模型研究[J].情報科學, 2016, 34(2):50-54.
陳濤, 劉煒, 單蓉蓉, 等.知識圖譜在數字人文中的應用研究[J].中國圖書館學報, 2019, 45(6):34-49.
FRONTINI F, BRANDO C, GANASCIA J G. Semantic Web based named entity linking for digital humanities and heritage texts[C]// Proceedings of first international workshop semantic Web for scientific heritage at the 12th ESWC 2015 Conference. Portoro?: Fabien Gandon, 2015:77-88.
劉嶠, 韓明皓, 江瀏祎, 等.基于雙層隨機游走的關系推理算法[J].計算機學報, 2017, 40(6):1275-1290.
周莉娜. 面向領域知識服務的唐詩本體構建與智能應用研究[D].武漢:武漢大學, 2020.
陸泉, 劉婷, 張良韜, 等.面向知識發現的模糊本體融合與推理模型研究[J].情報學報, 2021, 40(4):333-344.
周知, 蔣琳.數字人文圖像資源知識組織模型構建研究[J].圖書館學研究, 2021(8):66-72, 65.
王曉光, 江彥彧, 張璐.敦煌壁畫圖像語義描述層次模型實證研究[J].圖書情報工作, 2015, 59(19):122-129.
田玲, 張謹川, 張晉豪, 等.知識圖譜綜述——表示、構建、推理與知識超圖理論[J].計算機應用, 2021, 41(8):2161-2186.
陳濤, 劉煒, 單蓉蓉, 等.知識圖譜在數字人文中的應用研究[J].中國圖書館學報, 2019, 45(6):34-49.
HOEKSTRA R, MERONO-PENUELA A, DENTLER K, et al. An ecosystem for linked humanities data[C]// Proceedings of European semantic Web conference. Cham: Springer, 2016: 425-440.
SHUN HAN REBEKAH W. Digital humanities: what can libraries offer?[J]. Libraries and the academy, 2016, 16(4):669- 690.
ISAAC A, HASLHOFER B. Europeana linked open data–data.europeana.eu[J]. Semantic Web, 2013, 4(3): 291-297.
TSUI L H, WANG H. Harvesting big biographical data for Chinese history: the China Biographical Database (CBDB)[J]. Journal of Chinese history, 2020, 4(2): 505-511.
Institute for Computing in Humanities, Arts, and Social Sciences[EB/OL].[2021-12-15].http://chass.illinois.edu/.
BAIERER K, DR?GE E, ECKERT K, et al. DM2E: a linked data source of digitised manuscripts for the digital humanities[J]. Semantic Web, 2017, 8(5): 733-745.
王曉光, 侯西龍, 程航航, 等.敦煌壁畫敘詞表構建與關聯數據發布[J].中國圖書館學報, 2020, 46(4):69-84.
夏翠娟, 劉煒, 陳濤, 等.家譜關聯數據服務平臺的開發實踐[J].中國圖書館學報, 2016, 42(3):27-38.
王曉光.數字人文與智慧數據[J].上海高校圖書情報工作研究, 2018, 28(2):25, 24.
REED A. Managing an established digital humanities project: principles and practices from the twentieth year of the William Blake archive[J]. Virginia Tech, 2014, 8(1):1-17.
SCH?CH C. Big? smart? clean? messy? data in the humanities[J]. Journal of digital humanities, 2013, 2(3): 2-13.
梁晨, 李中清.從微觀數據到宏觀歷史:作為橋梁的數字史學[J].中國社會科學評價, 2021(2):84-92, 159.
作者貢獻說明:
朱麗雅:參與框架制定,收集整理資料,撰寫并修改論文;
張 ?珺:收集整理資料,撰寫并修改論文;
洪 ?亮:提出論文主題和研究框架,指導論文寫作;
羅紹輝:提出論文部分章節的寫作思路;
蘭 ?度:提出論文部分章節的寫作思路。
Abstract: [Purpose/significance] This paper conducts a systematic review of the knowledge graph research in the field of digital humanities, aiming to provide possible future research directions and open research topics. [Method/process] By taking relevant paper published in domestic and foreign conferences and journals as the research objects and using the comprehensive induction method, the theoretical and practical development of the knowledge graph in the field of digital humanities was systematically combed. Then it explained the related concepts of the knowledge graph in the field of digital humanities. And according to the current research hot spots, this paper revealed its research trends from three aspects of the data resource construction, key construction technologies and intelligent application platforms. Finally, it showed the prospects for future research trends. [Result/conclusion] This paper summarized the future trends of the knowledge graph research in the field of digital humanities. In the future, it will show the development trends of multi-source data integration, multi-modal knowledge fusion and multi-disciplinary cross-application.
Keywords: digital humanities ? ?knowledge graph ? ?smart data; data resource construction ? ?semantic mining
3144500589268
