基于截斷歷史注意力的商品評論屬性詞抽取框架
2022-03-21 09:45:24張順香朱廣麗張鎮江孫爭艷
太原理工大學學報 2022年2期
張順香,趙 彤,朱廣麗,張鎮江,孫爭艷
(安徽理工大學 計算機科學與工程學院,安徽 淮南 232001)
商品評論不僅為用戶的購買決策提供了參考,商家同樣通過對商品評論進行細粒度的情感分析得到用戶對商品不同屬性(例如:材質、價格、顏色等)的情感傾向[1-2],從而調整商品的制作工藝、銷售策略等,以此獲取更大的商業利潤。從商品評論中抽取屬性詞是后續針對屬性詞所屬方面進行細粒度情感分析的必要步驟。但由于商品評論具有基數大、表達口語化等特點,故為商品屬性詞的完整抽取帶來了一定的挑戰,使其成為當前的研究熱點之一。
屬性詞分為顯式屬性詞和隱式屬性詞,例如:“顏色好看!”中“顏色”是顯式屬性詞,“有點小貴!”中隱藏了“價格”這個隱式屬性詞,現有的主流屬性詞抽取方法是2016年提出的BiLSTM-CRF模型[3],該模型通過BiLSTM(bidirectional short and long term memory network,BiLSTM)自動學習上下文語義信息,一定程度上克服了對人工選取特征的依賴,并通過CRF(conditional random field)計算輸出標簽序列的全局概率,提高了顯式屬性詞抽取的準確率,但是該模型無法抽取隱式屬性詞,導致了屬性詞抽取的不完整。為了解決該問題,屬性詞的抽取方法有待深入研究。一種完整的屬性詞抽取方法應該考慮以下兩個方面:1)如何有效地挖掘單詞間的隱式關系,抽取評論中的隱式屬性詞;2)如何同時抽取顯式、隱式屬性詞,使屬性詞抽取過程更加高效。
基于上述兩個問題,本文提出了一種基于截斷歷史注意力機制(truncated history-attention,THA)[4]的商品評論屬性詞抽取框架,如圖1所示。該框架在對商品評論語料進行預處理后,通過BiLSTM-CRF模型抽取評論文本中的顯式屬性詞,引入截斷歷史注意力機制,建立包含屬性詞和詞間映射關系的詞庫,獲取單詞間的隱式關系,抽取評論中的隱式屬性詞。框架主要包括以下3部分:
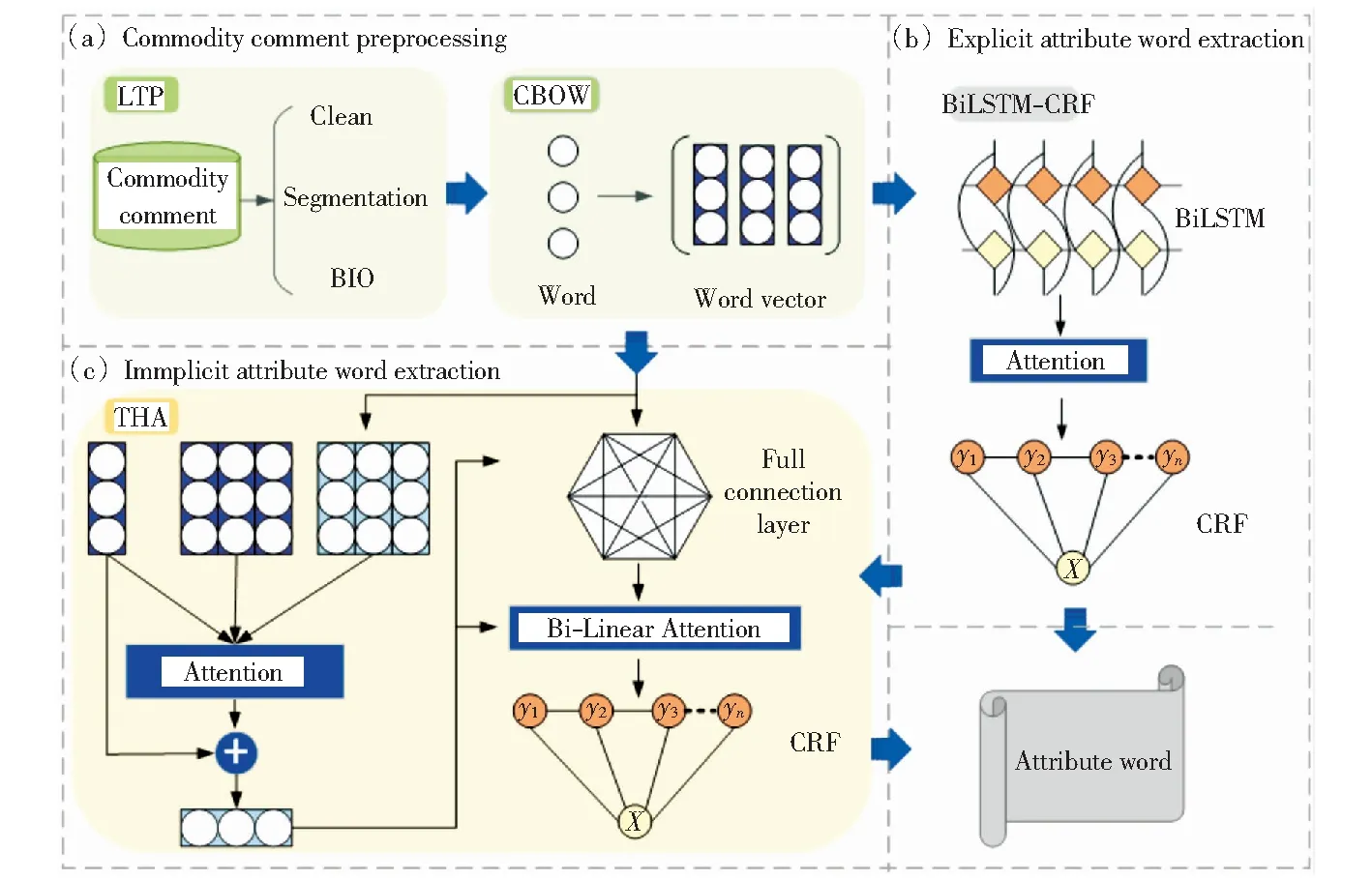
圖1 THA-BiLSTM-CRF框架圖Fig.1 THA-BiLSTM-CRF frame diagram
1)商品評論語料預處理。首先對商品評論語料進行清洗,去除重復、空值和與商品評論無關的語句,然后使用哈工大信息檢索實驗室開發的LTP工具對商品評論進行分詞、詞性標注和實體標注,最后通過word2vec中的CBOW模型,將單詞轉化成包含語義信息的詞向量。
2)基于BiLSTM-CRF模型抽取顯式屬性詞。將預處理后的詞向量傳入BiLSTM層獲取文本特征的前向向量和后向向量,拼接后作為當前單詞的隱藏狀態向量,通過CRF進行解碼,計算出序列文本每個單詞的標簽得分,得分最高的標簽序列為顯式屬性詞。
3)基于THA模型抽取隱式屬性詞。將預處理后的詞向量傳入截斷歷史注意力機制(THA)模型,將每個時間步得到的摘要輸入到注意力機制中,建立包含屬性詞和詞間映射關系的詞庫,獲取單詞間的隱式關系,通過注意力機制抽取隱式屬性詞。
本文研究工作的主要貢獻可概括為以下兩點:
1)在BiLSTM-CRF模型基礎上引入截斷歷史注意力機制(THA),有效挖掘了商品評論中的隱式屬性詞。
2)使用BiLSTM-CRF模型抽取顯式屬性詞,為后續挖掘評論文本詞間隱式關系提供顯式屬性詞詞庫,此種設計可以共享數據,同時抽取顯式和隱式屬性詞,使屬性詞的抽取工作更加高效。
1 相關工作
屬性詞抽取是命名實體識別的三大子任務之一,現主要使用的抽取方法是基于統計概率和基于神經網絡的方法。基于統計概率的方法是通過分類統計模型將屬性詞抽取問題轉化為一個分類問題進行求解。基于神經網絡的方法在統計概率模型的基礎上通過自學習樣本特征,在不需要提供大量的特征工程的情況下訓練抽取模型。
1.1 基于統計概率的方法
在基于統計概率方法的屬性詞抽取任務中,隱馬爾可夫模型(hidden markov model,HMM)[5]和條件隨機場[6]是最常用的兩種模型。1991年BIKEL et al[7]首次提出將隱馬爾可夫模型用于命名實體識別任務中,通過馬爾可夫鏈生成狀態序列和與其對應的觀測序列,使用聯合概率模型訓練參數,得出聯合似然最大值。LIU et al[8]通過最大熵模型構造了屬性詞與標簽之間的映射關系,利用HMM進行屬性詞的命名實體識別。CRF在HMM的基礎上進行了改進,不再要求獨立性假設,支持了豐富的語言特征。MCCALLUM et al[9]在CONLL-2003測評中將CRF用于命名實體識別,獲得了良好的效果。JAKOB et al[10]首次將CRF用于商品評論中商品屬性詞的抽取任務,證明了基于CRF的抽取方法在商品評論領域的可行性。在屬性詞抽取任務中,雖然基于統計概率的傳統機器學習方法取得了較好的性能,但由于機器學習的方法需要對數據集進行人工特征的選擇與處理,所以耗費了大量的人力和時間成本。
1.2 基于深度學習的方法
隨著近年來以神經網絡為核心的深度學習理論快速發展,使用深度學習去解決屬性詞抽取問題成為目前的一種趨勢。在屬性詞抽取任務中,常用的神經網絡有循環神經網絡(recurrent neural network,RNN)[11]和長短期記憶網絡(short and long term memory network,LSTM)[12]。2003年,BENGIO et al[13]在論文中首次將深度學習的思想融入到語言模型中。但由于文本數據中各個字詞之間相互關聯,單向結構的神經網絡模型并不適用于屬性詞抽取,而RNN存在梯度消失問題,因此又引入了LSTM模型。LSTM則通過引入“門”來控制信息的累計速度,有選擇地增加和遺忘信息,更加適合處理命名實體識別問題[14]。LAMPLE et al[15]使用的LSTM-CRF模型在英文命名實體識別中獲得良好的效果。2017年,TAN et al[16]首次將自注意力機制應用在序列標注問題中。在不同的領域中,PENG et al[17]利用詞向量提升社交領域中命名實體識別的性能,ZENG et al[18]將LSTM-CRF 模型應用在醫藥實體名的識別任務中,CAO et al[19]利用對抗遷移學習和自注意力機制對微博文本進行命名實體識別,CHEN et al[20]提出一種半監督的深度學習框架系統對政府文件中的實體信息進行識別。而在商品評論領域,LIU et al[21]利用循環圖和開關遞歸神經網絡模型對屬性詞進行識別。
綜上,在屬性詞抽取任務中,基于統計概率的方法需要滿足一定規模的特征工程,會耗費大量的人工和時間成本,而基于深度學習的抽取方法通過自學習樣本特征,無需過多的人工特征,更具有研究價值。因此,本文在BiLSTM-CRF模型的基礎上加入截斷歷史注意力機制(THA)用于隱式屬性詞抽取的研究,進一步提高屬性詞抽取的完整度。
2 基于BiLSTM-CRF的顯式屬性詞抽取
2.1 文本預處理
原始的商品評論文本中含有許多空值、與商品評論無關和重復的語句等噪聲,首先對語料庫中的文本進行數據清洗;然后使用哈工大信息檢索實驗室開發的LTP工具對處理后文本進行分詞、詞性標注等預處理,例如,“襯衫顏色很好看,喜歡!”標注結果為“襯衫/n 顏色/n 很/d 好看/a,/wp喜歡/v !/wp”;最后利用BIO標簽進行命名實體的詞庫標注。在屬性詞抽取任務中BIO標簽輸入一個單詞序列X={x1,x2,…,xT},輸出預測方面標簽序列Y={y1,y2,…,yT},其中每個yi來自一個有限的標簽集Y={B,I,O},它描述了可能的方面標簽,B、I和O分別表示相位跨度的開始、內部和外部。
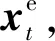
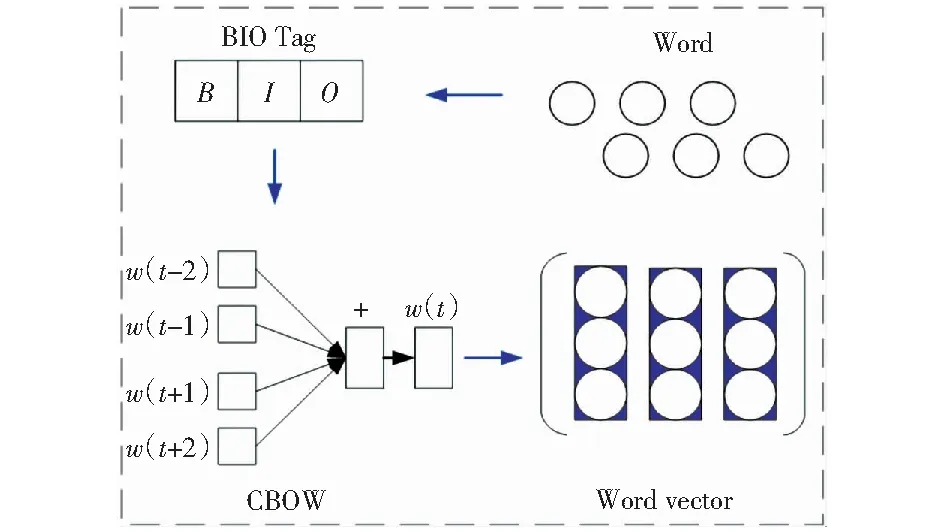
圖2 文本向量化過程Fig.2 Text vectorization process
2.2 BiLSTM-CRF模型介紹
BiLSTM-CRF模型結合了長短時記憶網絡(LSTM)和條件隨機場算法(CRF),主要用于解決命名實體識別的有效性問題,是現有的主流顯式屬性詞抽取模型,其模型框架如圖3所示。
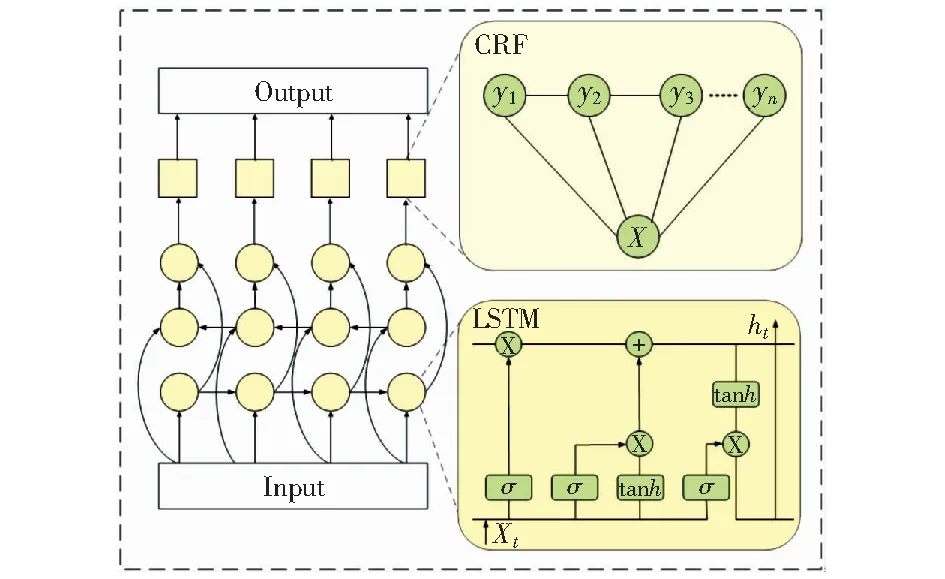
圖3 BiLSTM-CRF模型Fig.3 BiLSTM-CRF model
2.2.1BiLSTM層
相比循環神經網絡(RNN),長短時記憶網絡(LSTM)利用數據中的長期依賴關系,解決了序列訓練過程中的梯度消失和梯度爆炸問題。LSTM是一個記憶單元通過輸出門、輸入門和遺忘門來控制其內部狀態的讀、寫和重置操作,其內部結構如圖3中的LSTM模塊。
在某一時刻,使用當前輸入和前一狀態的輸出,遺忘門將決定保留哪些信息和丟棄哪些信息,隨后更新記憶單元。當輸入的文本詞向量矩陣為X=[x1,x2,…,xK]時,LSTM的傳遞過程如式(1)-式(6)所示。
it=σ(Wi·[Ht-1,xt]+bi).
(1)
ft=σ(Wxf·xt+Whf·ht-1+bf).
(2)
ot=σ(Wxo·xt+Who·ht-1+bo).
(3)
zt=tanh(Wxz·xt+Whz·ht-1+bz).
(4)
ct=zt·it+ct-1·ft).
(5)
Ht=tanh(ct)·ot.
(6)
式中:W為權重矩陣;b為偏置向量;σ為sigmoid函數,sigmoid層輸出0或1,當輸出為0時代表不能通過,1代表能夠通過。zt是待增加內容,ct是t時刻的更新狀態,it、ft、ot分別是輸入門、遺忘門和輸出門的輸出結果,Ht則是整個LSTM單元t時刻的輸出H={h1,…,hi,…,ht}.

(7)
(8)
(9)
式中:wt是t時刻向量層的輸出向量,即BiLSTM層t時刻的輸入向量;ct-1是t-1時刻記憶細胞的狀態;ht-1是t-1時刻LSTM層輸出向量;ct是t時刻的記憶細胞狀態;ht是t時刻BiLSTM層的輸出向量,該層的輸出向量序列構成的矩陣記為[h1,…,ht].
2.2.2CRF層
CRF是一種統計建模方法,結合了最大熵模型和隱馬爾可夫模型的優點形成了無向圖模型,并且可以考慮上下文信息。隨機場的主體思想是若干個位置組成的整體,當給每一個位置中按照某種分布隨機賦予一個值之后,該全體就叫做隨機場。CRF是隱馬爾可夫模型的特例,CRF假設隱馬爾可夫模型中只有x和y兩種變量,其中x一般是給定的,而y是在給定x的條件下模型的輸出。當CRF中x和y具有相同的結構,就構成了線性鏈條件隨機場,如圖3中的CRF模塊。
通過將CRF從訓練數據中自動學習得到的標簽序列之間的約束條件添加到最終的命名實體標簽,保證了預測標簽的有效性。CRF層通過引入狀態轉移矩陣獲得實體標簽之間的依賴關系,以提高屬性詞的抽取效果。首先,計算其所有的實體標簽序列(y1,…,yi,…,yn)的概率;然后,計算規范化因子Z(X);最后,使用Viterbi算法判斷最有可能出現的標簽序列,并將其作為屬性詞抽取結果,其計算過程如公式(10)-(11)所示。
(10)
(11)

2.3 顯式屬性詞抽取過程
BiLSTM-CRF模型中,對于輸入的商品評論,經過預處理后將包含語義的詞向量傳入BiLSTM層,獲得句子的前向向量和后向向量;接著將前向向量和后向向量進行拼接作為當前詞匯或字符的隱藏狀態向量;最后將包含上下文信息的語義向量輸入到CRF中進行解碼,通過CRF計算出序列文本每個詞語或字符的標簽,將具有最高得分的標簽序列作為模型預測的最好結果,即商品顯式屬性詞輸出,具體過程如算法1所示。
算法1 基于BiLSTM-CRF的顯式屬性詞抽取算法。
輸入:商品評論詞向量S={s1,s2,…,sn},注意力機制層矩陣元素M;
輸出:商品顯式屬性詞輸出y.
for each epoch until Δ for each batch do BiLSTMCRF.Insert(sentence); CRF.Forward(); CRF.Backward(); UpdateModel(); end for end for T←Gettransferscore(y);/*計算屬性轉移分數*/ Z←Exceptionsum(T,M);/*計算規范化因子Z(X)*/ PY←Calprobabilityof(y);/*計算標簽序列概率*/ y←Viterbi(s);/*計算屬性詞抽取結果*/ 由于商品評論具有表達口語化的特點,例如“有點小貴!”中“價格”這樣的隱式屬性詞無法通過BiLSTM-CRF等現有模型被有效抽取。針對該問題,本文提出一種基于截斷歷史注意力機制(truncated history-attention,THA)的隱式屬性詞抽取方法。THA算法通過挖掘整個商品評論語料庫中觀點詞與屬性詞的詞間隱藏關系,在語料庫中抽取單條評論中被隱藏的屬性詞,即完成隱式屬性詞的抽取。 THA模型分為兩個模塊,如圖4所示,分別是截斷歷史注意模塊和二次計算模塊,分別用于捕獲方面檢測歷史和觀點摘要。 圖4 THA模型Fig.4 THA Model 截斷歷史注意模塊通過遍歷所有評論首先抽取每條評論內所包含的觀點詞、顯式屬性詞,接著將顯式屬性詞與其對應觀點詞的關系進行記錄(例如,“昂貴—價格”、“好吃—味道”),最后將顯式屬性詞和對應關系一同輸入注意力機制模型中,如果發現注意力機制的詞庫中有匹配當前評論觀點詞的屬性詞,則抽取隱式屬性詞。 在算法上,截斷歷史注意模塊主要由BiLSTM模塊處理后的詞向量和注意力機制模塊組成,如圖4(a)所示。由于遞歸神經網絡可以記錄上下文的序列信息,故使用LSTM模型來構建和組織向量化的評論語句。具體構建如式(12)所示。t表示當前處理語句的位置指示,st來表示當前處理的語句,使用BiLSTM來產生初始化的狀態信息ht. (12) 截斷歷史注意模塊的另一個組成部分是注意力機制模塊。注意機制的基本思想是從每一個較低的層次提取一個注意權值,然后將這些權值集合起來,得到較高層次的表示。使用BiLSTM可以記憶預測的整個歷史,但是沒有辦法記憶先前已有的經驗和當前經驗之間的關系,所以引入注意力模塊建模當前時間步和歷史時間步的關系,即在注意力模塊中存儲屬性關系。對于每一個預測步驟t,注意力模塊會記住每一對單詞間的關系,并予以計算相關性,再將得到的相關性使用softmax函數進行處理,其計算過程如式(13)-(14)所示。 (13) (14) 算法2 基于THA的初步隱式屬性詞抽取算法。 輸入:向量化的評論信息S={s1,s2,…,sn}; 輸出:每條商品評論的屬性詞。 S←data_cleaning(S);/*進行數據的預處理,包括去除過短、重復、主題不同的評論*/ VS←word2vec(S);/*向量化評論信息*/ for each sentence inVS [sentence,feature]←BiLSTM(sentence);/*利用BiLSTM對評論進行處理,得到初步的屬性詞*/ Attention.Insert(feature);/*將屬性詞寫入注意力機制*/ [sentence,feature]← Attention.Deal(sentence); /*利用注意力機制提取特征詞,得到評論語句與對應的屬性詞*/ ST.Insert(sentence,feature); end for 由于詞庫的建立是動態的,即一邊遍歷商品評論一邊進行詞庫的建立,所以前后不同時間順序處理的評論屬性詞的抽取質量不同。雖然使用BiLSTM模型一定程度上可以弱化此種問題,但還是有大量評論語句的屬性詞抽取沒有達到抽取要求。為解決這個問題,文本通過加入二次計算來進一步完善隱式屬性詞的抽取。 在截斷歷史注意模塊中,評論語句的屬性詞和對應關系的抽取是動態的,隨著處理過程的進行,抽取的準確性會越來越好,所以最初抽取的隱式屬性詞和靠后時間抽取的隱式屬性詞的質量參差不齊。為了提高隱式屬性詞抽取的整體效果,本文引入了二次計算。 二次計算部分的組成主要包括了全連接層和雙線性注意力機制兩部分,如圖4(b)所示。首先,將原始評論預處理后的詞向量與截斷歷史注意模塊抽取出的隱式屬性詞共同輸入到全連接層。在全連接層上,由于在截斷歷史注意模塊中已經將所有顯式屬性詞、詞間關系抽取,所以將所有顯式屬性詞作為節點,建立全連接關系。當某個觀點詞輸入全連接層后,在全連接層上進行詞間關系挖掘,找到觀點詞對應的隱式屬性詞。然后,將全連接層的輸出與截斷歷史注意模塊抽取出的隱式屬性詞再次共同輸入到雙線性注意力機制中。全連接層通過直接映射的方式,得到更加準確的隱式屬性詞,但當{觀點詞,屬性詞}中存在一對多的情況時(例如,“好看”可能對應的屬性詞是“顏色”或“樣式”)部分詞會出現偏差,所以此時需要更高維度的關系挖掘,即雙線性注意力機制,它可以構建注意力模型,以挖掘更深層的關系,完成隱式屬性詞進一步的抽取。基于THA的二次隱式屬性詞抽取過程如算法3所示。 算法3 基于THA的二次隱式屬性詞抽取算法。 輸入:向量化的評論信息S={s1,s2,…,sn},THA計算后每條評論語句的屬性詞集合ST; 輸出:每條商品評論的屬性詞. for eachifrom 1 toS.Count Sentence←S[i]; Feature←ST[i].Feature; FCLayer.Insert(feature); Abstract←FCLayer.Deal(sentence,feature); BiLinearAttention.Insert(abstract); end for For eachiform 1 toS.Count Sentence←S[i]; feature←ST[i].Feature; Abstract←BiLinearAttention.Deal(feature);/*將屬性詞輸入雙線性注意力機制進行計算*/ Feature←FCLayer.Deal(feature,abstract); SA.Insert(sentence,feature); end for end 綜上所述,通過上述兩部分基于THA的抽取算法,最終可以實現完整的隱式屬性詞的抽取。 本文采用京東平臺2011年1月1日到2014年3月31日的消費者的部分購買評論作為實驗的數據集,該數據集由ChallengeHub提供。數據集主要包含5個表關系,分別是商品編號與商品名的映射、商品類別與類別編號的映射、商品編號與類別編號的映射、商品編號與評論信息的映射,商品評論與屬性詞的映射。其中,商品編號與商品類別存在著多對多的映射關系,例如商品“鼠標”可同時被分類為“電腦配件”類和“電子產品”類,而“電腦配件”類也可以包含多種商品。 數據集包含了525 620種商品,1 175種類別,71 865條商品評論(數據集中很多商品沒有評論),每件商品都擁有關鍵字標注。本文從原始數據集中選取5 000條高質量評論作為實驗數據集。將數據集以隨機分配的方式,以70%的數據作為訓練集,30%的數據作為測試集。 對于商品評論屬性詞抽取,本實驗將商品的評論信息作為原始輸入,將商品的屬性詞作為標簽,通過本文提出的商品評論命名實體識別方法對原始輸入進行計算,將得到的預測標簽,與真實標簽相比較。 采用召回率R、精確率P和F1值來評測模型的性能,各評價指標的計算方法如式(15)-式(17)所示。 (15) (16) (17) 式中:a為識別正確的實體數,A是總實體數,B為識別出來的實體數。 本實驗的軟硬件環境如表1所示。 表1 訓練環境參數配置Table 1 Training environment parameter configuration 本文提出了一種商品評論屬性詞的抽取框架THA-BiLSTM-CRF.首先,在商品評論信息的基礎上進行人工標注,計算本模型對人工標注信息的召回率、準確率以及F1值作為實驗的評價指標;然后,對本模型中的重要參數進行提取,使用訓練集對模型的參數進行訓練;最后,將本文的模型與傳統屬性詞抽取模型進行比較,評測本文提出的屬性詞抽取模型相對于其他模型的進步性。具體實驗步驟如下: 1)實驗數據獲取。本文實驗所需數據集來自電商平臺對外提供的商品評論數據。 2)實驗數據預處理。結合商品評論的特點,將過短、重復、空值和與商品評論無關的語句進行過濾,并使用哈工大信息檢索實驗室開發的LTP分詞工具進行分詞,然后利用CBOW模型將數據集轉換成詞向量的形式進行存儲。 3)抽取顯式屬性詞和其對應的觀點詞。將預處理后的詞向量傳入BiLSTM-CRF模型進行處理,得到評論的顯式屬性詞和其對應的觀點詞,顯式屬性詞和觀點詞之間的詞間關系通過共享內存的方式將數據傳給THA模塊,在此過程中不斷訓練BiLSTM-CRF模型中的參數。 4)抽取隱式屬性詞。THA接收BiLSTM-CRF模型共享的顯式屬性詞和觀點詞之間的詞間關系并處理,得到所有屬性詞與對應觀點詞之間的聯系,即全聯接層,然后遍歷所有評論,根據全聯接層的信息得到隱式屬性詞,在此過程中不斷訓練THA模型中的參數。 5)設計本模型與其他模型的對比實驗。比較屬性詞抽取結果對人工標注的召回率、準確率以及F1值,證明本文所提出的屬性詞抽取框架的進步性。 4.5.1隱式屬性詞抽取結果舉例 本文提出的模型可以將原本商品評論中不直接出現的屬性詞同樣抽取出,改善了已有的BiLSTM-CRF模型只能抽取顯式屬性詞的局限性,增加屬性詞抽取的完整度,表2為隱式屬性詞抽取的示例。 表2 隱式屬性詞抽取示例Table 2 Implicit attribute word extraction example 4.5.2模型性能對比 為了驗證本文所提出模型的有效性,現將模型與BiLSTM-CRF、Attention-BiLSTM-CRF兩種主流的屬性詞抽取模型進行比較實驗。由于本文模型考慮了隱式屬性詞的抽取,因此模型的準確率、召回率和F1值較對比模型都有了明顯提高,具體實驗結果如表3所示。 表3 模型性能對比Table 3 Model performance comparison % 實驗驗證了3種模型在同一數據集下對商品屬性詞的抽取能力,通過數據測試的P、R和F1值作為評測標準。本文所提出的THA-BiLSTM-CRF屬性詞抽取模型在屬性詞抽取任務中的F1值達到80.88%,領先于其他模型6.44%~9.56%,驗證了通過引入THA提取隱式屬性詞,很大程度地提高了商品屬性詞抽取的完整性。 商品屬性詞的完整抽取,是提高商品評論細粒度情感分析準確性的重要工作之一。傳統的屬性詞抽取模型難以有效抽取隱式屬性詞,故本文提出了一種基于截斷歷史注意力機制的商品評論屬性詞抽取框架THA-BiLSTM-CRF.該模型在BiLSTM-CRF模型的基礎上引入截斷歷史注意力機制(THA),充分利用歷史時間步信息,建立包含屬性詞和單詞間映射關系的詞庫,挖掘商品評論中的隱式屬性詞。研究工作的主要貢獻包括: 1)通過在BiLSTM-CRF模型中引入THA模型有效挖掘了隱式屬性詞。傳統的屬性詞抽取多是針對顯式屬性詞,但由于商品評論表達的口語化,很多評論中并沒有顯式屬性詞,故本文提出的隱式屬性詞抽取方法提高了屬性詞抽取的完整度。 2)通過BiLSTM-CRF模型與THA模型的數據共享,將BiLSTM-CRF模型抽取的觀點詞、顯式屬性詞作為THA模型挖掘詞間關系的詞庫,實現了同時抽取顯式、隱式屬性詞,使抽取步驟更加簡潔高效。 實驗結果表明,本文提出的框架不僅可以抽取顯式屬性詞也可以抽取隱式屬性詞,提高了屬性詞抽取的完整度。本文提出的抽取方法需要遍歷每一條評論,具有一定的計算復雜度,未來我們會繼續改進屬性詞抽取算法并進一步研究細粒度情感分析的相關工作,例如更準確地抽取商品屬性詞和與之對應的觀點詞等。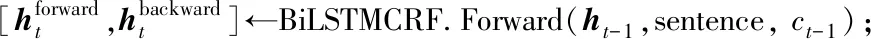
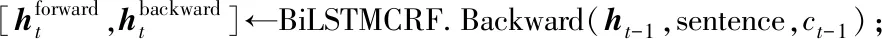
3 基于THA的隱式屬性詞抽取

3.1 截斷歷史注意模塊

3.2 二次計算模塊
4 實驗及結果分析
4.1 實驗數據集
4.2 評價指標
4.3 實驗環境

4.4 實驗方法
4.5 實驗結果


5 總結
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
四川勞動保障(2021年9期)2022-01-18 05:11:08
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
文苑(2018年21期)2018-11-09 01:23:06
中國衛生(2016年9期)2016-11-12 13:28:08
光學精密工程(2016年6期)2016-11-07 09:07:19
中國衛生(2015年9期)2015-11-10 03:11:12
核科學與工程(2015年4期)2015-09-26 11:59:03
中國衛生(2014年3期)2014-11-12 13:18:12
