結合對抗網絡與條件均值的多源適應分類方法
2022-03-21 10:33:24譚茜成鄒俊穎
計算機工程與設計 2022年3期
夏 青,郭 濤,譚茜成,鄒俊穎
(四川師范大學 計算機科學學院,四川 成都 610101)
0 引 言
深度神經網絡在各種機器學習問題和應用方面取得了重大進展。然而這一重大進展歸功于大規模標記數據的可用性[1]。但人工標注數據耗時費力、代價昂貴。相比于傳統的監督學習,無監督學習[2]利用沒有標注的數據進行模型訓練,以解決機器學習中標注數據缺乏的問題。此外,傳統機器學習通常假設訓練數據和測試數據來自于同一概率分布[3]。而在實際中,由于訓練數據和測試數據往往來源于不同的數據分布,這就導致了在很多實用場景中不能正常使用傳統機器學習算法下訓練出來的模型,學習到的模型在新領域使用時性能會大幅度衰減[4]。與機器學習不同,遷移學習[5,6](transfer learning,TL)借助于源域數據訓練過程中學到的知識,完成對目標域的識別[7]。但是不同域之間存在的間隙使得源域訓練的模型在目標域進行識別的時候學習效果會受到影響,域適應[8]學習作為遷移學習中的一種代表性方法,通過建立從有標簽源域到無標簽目標域的知識遷移,學習域間共享信息,實現模型在目標域上的正確分類[9]。針對域適應的研究,SankaraNara-yanan等[10]提出的生成適應網絡(generate-to-adapt,GTA),通過學習單個源和單個目標之間的共享特征嵌入和生成對抗網絡[11](generative adversarial network,GAN)之間的共生關系來減小域差異,進一步利用源域中學習到的知識對目標域進行預測,但僅使用單源域學習提取到的數據特征有限,且對抗機制不足以減少域差異,當樣本來自于多個不同概率分布的時候,模型會出現負遷移,使得模型的分類性能受到影響。目前大多數域適應算法和理論假設源樣本僅從單個源域進行采樣。而在實際應用中,會在多個不同設備上采集到源樣本數據用于訓練,但是這些數據不但和目標域概率分布不同,而且互相之間概率分布也不同[12]。基于此,楊強等提出了多源遷移學習[13],將一個源域擴展為多個源域,利用多個源域中豐富的監督信息能夠更有效輔助目標域的學習[14]。近來,朱勇椿等研究學者提出了多特征空間適應網絡[15](multiple feature spaces adaptation network,MFSAN),通過提取多個源域和目標域之間的共享特征,使用最大均值差異[16]優化每一對源和目標的距離。受MFSAN思想啟發,并針對GTA模型的不足,本文提出一種結合對抗網絡與條件均值的多源適應分類方法,該方法通過對特征提取網絡的訓練,提取多個源域和目標域之間的域不變信息。將學習到的源域和目標域特征信息送入特定域的生成對抗網絡,同時使用條件最大均值差異[17]最小化域間距離,利用無監督對抗訓練輔助分類網絡對目標域特征進行識別。由于不同源訓練的分類器具有差異性,因此使用差異度量準則對每一個分類器的輸出進行約束,并回傳各個類別的梯度信號,以提高網絡的分類性能。在具有4個源域和一個目標域的實驗環境中的實驗結果表明了MSDACG模型利用多源域的監督信息來提高目標域學習的有效性,且分類精度有明顯提升。
1 理論基礎
1.1 單源無監督域適應
域適應由著名學者楊強提出,能夠有效地解決訓練樣本和測試樣本概率分布不一致的學習問題[18],是當前機器學習的熱點研究領域。以下給出相關的定義:
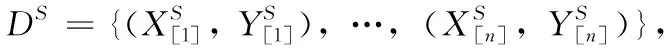
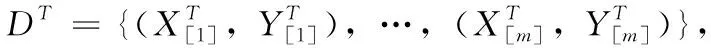
定義3 單源無監督域適應[19]:首先給定一個有標記的源域數據DS=(XS,YS) 和一個無標記的目標域數據集DT=(XT), 定義源域輸出函數FS:XS→YS, 即兩者構成源域(DS,FS),目標域即為(DT,FT),單源域適應的目標則是通過解決單個源域和單個目標域之間分布不同的問題,將在源域中學習到的知識對目標域的輸出函數FT進行學習[20]。圖1顯示了單個源和目標域之間的學習過程。

圖1 單源->目標域
1.2 多源無監督域適應
單源無監督域適應關注的是一個域的場景,而多源無監督域適應[21]作為單源無監督域適應的一種擴展,首先給定DS={DS1,DS2,…,DSN}, 即多源無監督域適應方法假定樣本是從N個不同的源域 {DS1,DS2,…,DSN} 中進行收集的,給定XS1,XS2,…,XSN是分別來自N個源域DS1,DS2,…,DSN的樣本,目標域數據記為DT。多源域適應的目標旨在解決多個源域和目標域之間分布差異的問題。利用在多個源域中學習到的知識對目標域進行預測。圖2顯示了多個源域和目標域之間的學習過程。
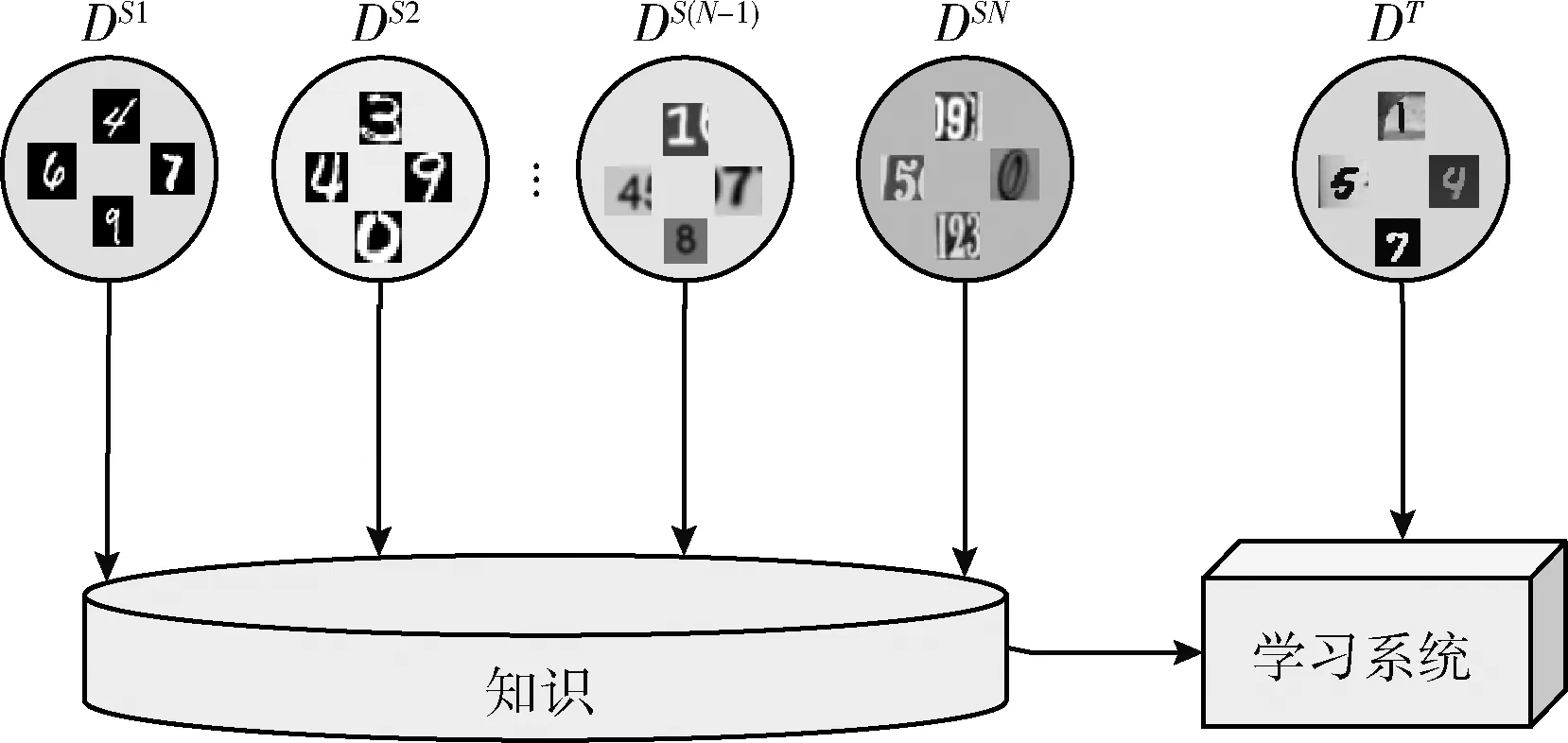
圖2 多源->目標域
1.3 GTA模型
GTA模型的學習過程分為兩個階段:①第一個階段:學習一個特征提取網絡并提取單個源和目標之間的共享特征嵌入作為生成器的輸入,以生成類似源域的數據,而判別器作為二分類器通過分辨真實的數據和生成數據之間的真假信息,并將學到的信息進行回傳;同時判別器作為多分類器僅使用源域的標簽信息進行監督學習。②第二個階段:學習一個分類器,利用源域的共享特征嵌入作為分類器的輸入并且實現在目標域上的預測。圖3是GTA模型的結構。

圖3 GTA模型結構
2 MSDACG模型
2.1 問題描述
通過對GTA模型的結構進行深入研究發現存在以下問題:一是特征提取器作為學習源和目標的共享特征嵌入,其僅使用對抗訓練的方式不足以拉近域間距離,缺少距離度量準則來約束域間距離,使得域適應效果受到影響。二是使用單源學習到的知識有限,導致難以識別來自分布不同的判別特征。三是如果特征提取器學習來自多個不同概率分布的源集合和目標域的共享嵌入特征,會使得模型產生負面影響,從而影響模型的分類效果。
2.2 結構描述
受GTA模型框架的啟發,并針對其存在的不足,本文提出結合條件均值與對抗機制的多源適應分類方法。其流程如圖4所示。模型首先利用特征提取器(F)提取所有域的共享嵌入表示,進而通過特定域的生成器分支(G)和特定域的判別器分支(D)學習不同源域和目標域間的特征,使用CMMD減小不同域間的條件分布差異,以輔助利用多個源域的監督信息對無標記的目標域數據進行識別。由于特定域的分類器(C)之間可能會出現差異,因此采用差異損失來約束不同分類器的輸出,以使得分類器的預測盡可能一致。下面分別對MSDACG模型的4個網絡結構流程及特點分別進行詳細介紹:
首先設定size為多個源域和目標域輸入數據的尺寸大小,N為源域的個數。
(1)共享特征提取網絡(F):
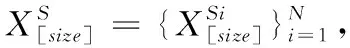
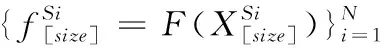
3)嵌入空間E服從于標準的高斯分布,并隨機產生一定維度的噪聲數據Z[size]。

(2)特定域的生成器網絡(G):
1)G使用反卷積神經網絡結構,并且G是由 {G1,G2,…,GN}N個特定域的生成器組成。
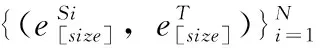
(3)特定域的判別器網絡(D):
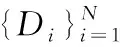
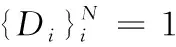
(4)特定域的分類器網絡(C):
1)C使用全連接層結構,并且C是由 {C1,C2,…,CN}N個特定域的分類器組成。
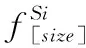
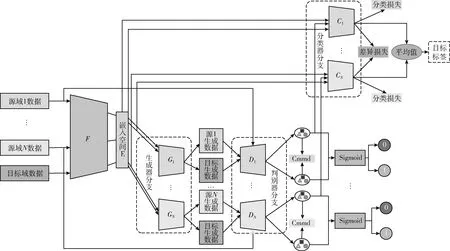
圖4 MSDACG模型總體結構
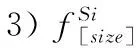
2.3 評估方法
本實驗采用CMMD距離度量、交叉熵損失函數,對抗性損失函數以及差異損失函數作為評估MSDACG模型的方法。
CMMD距離度量:CMMD是MMD的延伸概念。MMD是被用于計算不同數據的邊緣概率分布之間的差異,而CMMD是用于計算不同數據的條件概率分布P(XS|YS=C) 和Q(XT|YT=C) 之間的差異,其中C表示樣本的類別數量。由于在無監督學習中,目標域數據是沒有標簽的。因此,需要使用深度神經網絡的輸出y′=f(XT) 作為目標域上的偽標簽。則CMMD的計算公式可以表示為
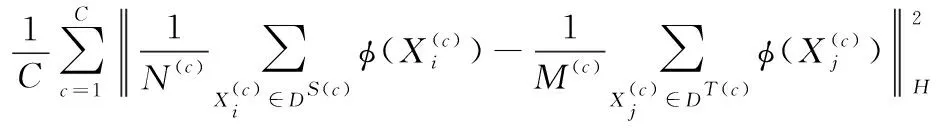
(1)
依據式(1),可得知CMMD在D上的損失函數Lcmmd的表達式見式(2),其中μ為動態平衡因子,用于對CMMD減小條件分布距離的程度作出衡量

(2)
通過最小化等式(2)可以有效拉近源域和目標域之間的條件概率分布。
(3)
(4)


(5)
(6)
(7)
D輸出兩個分布,來辨別輸入圖像的真偽性。根據GAN算法原理,對抗性損失函數的目的在于G利用D回傳的對抗性特征信息,在不斷地迭代優化過程中,G能夠生產出越來越類似源域類別空間的圖像,從而使得D難以分辯圖像的真假,最后達到一個納什均衡狀態。
差異損失函數:差異損失函數Ldisc的作用是為了解決引入多源時產生的各分類器差異的問題。在訓練過程中,分類器是由不同的源域監督信息進行訓練的,因此導致在對目標域預測的時候會出現分歧,特別是類邊界附近的目標樣本。正確的方式是不同分類器預測相同的目標樣本應該得到相同的預測。因此通過最小化所有分類器之間的距離以解決樣本觀測不平衡的問題。本文利用目標域數據的所有分類器的概率輸出之間差異的絕對值作為差異損失,計算表達式如式(8)所示
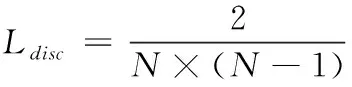
(8)
通過最小化方程(8),所有分類器的概率輸出是相似的。最后,預測目標樣本的標簽為計算所有分類器輸出的平均值。
2.4 算法流程
MSDACG模型的整體算法流程如算法1所示。
算法1: MSDACG模型訓練
Input:N個源域數據集DS={DS1=(XS1,YS1),DS2=(XS2,YS2),…,DSN=(XSN,YSN)}, 目標域數據集DT=(XT,YT), 訓練迭代次數T, 批量大小size, 權衡系數λ。
Output: MSDACG模型∑
(1) 隨機初始化模型∑中所有的網絡層參數。
(2)fortin 1:Tdo
(5) 隨機產生size個噪聲數據, 記為z[size];

(7) 根據式(3)、 式(4)及式(8)計算分類器上的損失函數
LC=Lcls+Lcls,d+λLdisc;
(8) 根據式(2)和式(4)~式(7)計算判別器上的損失函數
LD=Lsrc+Lcls,d+Ladv,src+Ladv,tgt+Lcmmd;
(9) 根據式(2)、 式(4)、 式(6)計算生成器上的損失函數
LG=Lcls,d+Ladv,src+Lcmmd;
(10) 根據式(3)、 式(4)、 式(7)、 式(8)計算共享特征提取網絡的損失函數
LF=Lcls+Lcls,d+Ladv,tgt+λLdisc;
(11) 使用梯度下降法進行反向傳播各個網絡的梯度信號;
(12)endfor
(13)輸出模型∑, 算法終止。
3 實驗結果與分析
3.1 數據集
實驗中使用的5個數據集分別是從以下的公開數據集中進行采樣,即:mt(MNIST)、mm(MNIST-M)[22]、sv(SVHN)、up(USPS)和sy(Synthetic Digits)。使用與文獻[23]相同設置,實驗從訓練集中采樣25 000幅圖像用于訓練,從MNIST、MINST-M、SVHN和Synthetic Digits中的測試集中采樣9000幅圖像用于測試。而對于USPS數據集總共僅包含9298幅圖像,所以選擇整個數據集作為一個域。實驗中輪流選擇一個域作為目標域,記為DT,其余的分別作為源域D1,D2,D3,D4。
3.2 實驗配置
實驗環境配置為:NVIDIA TESLA SXM2 V100 32 GB GPU服務器,Ubuntu16.04操作系統,Intel至強E5-2698v4處理器20核心,40線程。32 GB DDR4 LRDIMM 2133 MHz內存,480G Intel S3610 6 Gb/s SATA 3.0 SSD系統硬盤,平臺為pytorch。模型采用小批量Adam優化器進行訓練,學習率統一設置為0.0005,學習率衰減參數為0.0001,指數參數設置為β1為0.8,β2為0.999,批量大小統一設置為100。
3.3 分類精度對比實驗
實驗過程:
(1)根據3.1節描述選取一個數據集的訓練數據作為目標域數據集DT,其余數據集中的訓練數據分別作為源域數據集 {D1,D2,D3,D4}。
(2)參照算法1對多個源域與目標域進行訓練,獲得相應的4個模型Φ1,Φ2,Φ3,Φ4。
(3)凍結Φ1模型中的F網絡和C1網絡,并且記為測試模型Ω1,對Φ2,Φ3,Φ4采用一致的步驟處理,獲得相應的測試模型Ω2,Ω3,Ω4。
(4)采用Ω1,Ω2,Ω3,Ω4分別對DT進行預測,計算出在每個測試模型下的分類準確率。
(5)最后取這4個分類精度的平均值作為最終分類精度。在5種不同的域適應情況下進行驗證,并重復以上過程,計算出每種域適應情況下的分類精度。
結果分析:如表1所示,在5種多源域適應任務下,將MSDACG方法與當前多源域適應方法進行分類精度的比較。其中,粗體表示分類精度最高的值。可以看出MSDACG方法平均值達到了90.56%,相較于M3SDA的平均分類精度提高了2.91%。在目標域數據集為MNIST-M的遷移任務上,其精度可以達到80.86%,與M3SDA相比,其分類精度提高了8.04%;相較于DCTN提高了10.33%。而在其它多源域適應任務下,其分類精度也提高了0.35%~3.16%左右。圖5展示了在MSDACG模型下, mm,mt,sv,sy→up這一組遷移任務的分類損失比較,橫軸代表模型訓練的迭代次數,而豎軸代表訓練過程中產生的分類損失函數值。可以看出隨著迭代次數的增加其分類損失呈現不斷遞減的趨勢,且越來越接近于x坐標軸,驗證了學習來自不同域的信息對分類器效果有一定的提升。

表1 MSDACG與當前主流的多源域適應方法的分類精度比較
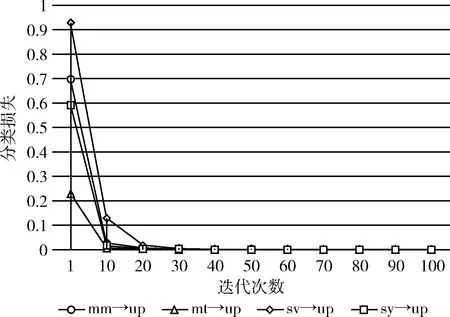
圖5 mm,mt,sv,sy→up分類損失折線
3.4 圖像生成對比實驗
實驗過程:
(1)對4個源域 {D1,D2,D3,D4} 分別隨機選取100幅圖像作為測試數據集D1*,D2*,D3*,D4*。
(2)按照算法1的步驟,固定F網絡以及G1,G2,G3,G4。 產生對應的模型Ψ1,Ψ2,Ψ3,Ψ4分別作為測試模型。
(3)使用測試數據D1*,D2*,D3*,D4*經過對應的模型Ψ1,Ψ2,Ψ3,Ψ4分別生成對應的生成數據。
結果分析:圖6展示了在MSDACG模型下, mm,mt,sv,sy→up遷移任務的圖像效果。將每一組生成圖像和真實圖像進行可視化對比分析,模型根據來自不同概率分布的源域樣本生成了類似源域效果的圖像,對于像MNIST-M、SVHN、Synthetic Digits這樣具有彩色數字的圖像,模型也能夠根據其特點生成紋理以及邊緣構造清晰的數字。而對于Synthetic Digits生成圖像的效果相較于MNIST-M、SVHN不是特別好的原因可能是與原先真實圖像的清晰度有關。而對于具有黑白手寫數字樣式的MNIST數據集來說,生成的數字圖像邊緣以及輪廓也具有良好的可視化效果。因此能夠驗證生成器是可以學習到來自不同源域的數據特征進而生成類似源域分布的生成圖像,并且對于學習彩色圖像也具有相對優秀的能力。圖7展示了MSDACG模型在訓練過程中CMMD值隨迭代次數變化的趨勢圖,這里縱軸代表CMMD的值,表示源域特征與目標域特征的像素矩陣經過RKHS空間中使用具有衡量條件概率分布的CMMD進行計算所得出的值。即隨著迭代次數的增加CMMD值在不斷減小,該結果驗證了隨著模型的不斷迭代,每一組源域和目標域之間的條件概率差異在不斷地減小。

圖6 mm,mt,sv,sy→up生成圖像可視化
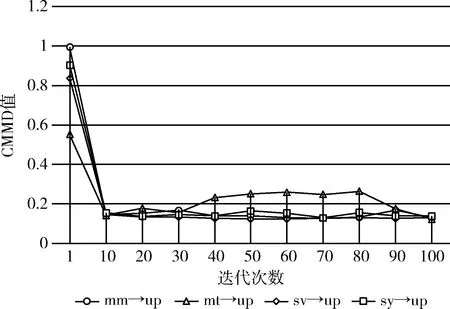
圖7 mm,mt,sv,sy→up CMMD值折線
3.5 t-SNE特征嵌入可視化分析實驗
實驗過程:
(1)分別從3.1節中D1,D2,D3,D4,DT的每個類別里隨機選取50個數據及相應的標簽,分別組成總大小為500的測試數據D1**,D2**,D3**,D4**,DT**。
(2)將D1**和DT**進行數據歸一化操作,且計算出對應tsne值tsneS1和tsneT。
(3)使用tsneS1和tsneT以及D1**和DT**和對應的標簽繪制適應前的tsne可視化特征。其次通過固定3.3節中模型Φ1的F網絡、G1網絡和D1網絡作為特征可視化的測試模型Γ1,在模型上使用D1**和DT**產生適應后的源域特征數據featureS1和目標域特征數據featureT。
(4)同理,D2**,D3**,D4**重復以上過程,即可得到適應后的tsne嵌入判別器最后一層卷積且經過CMMD度量方法適應后的特征可視化效果。
結果分析:圖8中(a)~(d)分別展示了MSDACG模型在mm,mt,sv,sy→up這一組遷移任務情況下多個源域和目標域之間的適應前后的效果。在MNIST-M→USPS這一組遷移任務的tsne圖中,左邊表示的未適應前的可視化分布圖,可以看出未適應前的特征分布散亂,且隨機分布在空間中,域間隙較大,分類信息難以識別。而在使用MSDACG模型進行域適應之后,域間距離開始聚攏,且分類信息更加明顯。在其它3組任務中,源域為SVHN的這一組任務中,適應相對較弱,通過對左圖SVHN的真實數據分布進行分析,初步推斷是由于真實數據分布過于散亂,且類別難以區分使得聚攏效果相比其它3組較弱。源域為MNIST和Synthetic Digits的這兩組任務中,可以看出未適應前同一種顏色的數據中,域間距離較大,且存在多數類別錯分的情況,在適應后之后,同一種顏色和數字標簽從不同的位置開始朝著與自己具有相同的特征方向靠近。從而驗證了條件概率度量準則以及對抗訓練的加入對模型的域適應能力以及分類性能都有一定的提升。

圖8 mm,mt,sv,sy→up下適應前后tsne可視化對比
4 結束語
為解決當前大多數域適應方法僅假設樣本來自單個域的情況而未考慮到多源任務的遷移,并且針對GTA模型僅使用單源學習到的特征有限以及使用對抗訓練拉近域間隙能力較弱的問題,本文提出一種結合對抗網絡與條件均值的多源適應分類方法MSDACG,該方法學習多個源域和目標域之間的共享特征嵌入,并且考慮到每個源域之間不同的決策邊界,使用特定域的生成器和判別器之間的對抗訓練聯合條件最大均值差異來減小每一組源域和目標域之間的間隙,加強類與類間的約束。同時,該模型還利用特定域的分類器網絡訓練來自不同源域的數據,并且對不同分類器的預測輸出進行約束,從而以更優的預測能力來識別目標域中的數據。在4種源域下的實驗結果表明MSDACG模型在多源域適應分類中具有良好的效果。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
