異構大數據環境中高效率知識融合方法的研究
2022-03-22 03:42:30張淑娟鄭國強鄭高峰
計算機工程與應用 2022年6期
汪 玉,王 鑫,張淑娟,鄭國強,趙 龍,鄭高峰
1.國網安徽省電力有限公司 電力科學研究院,合肥 230601
2.國網安徽省電力有限公司,合肥 230022
Web 3.0與大數據時代的到來證實了多種前期技術理論的實踐與應用可行性,谷歌公司在2012年提出的“知識圖譜”就是其代表性實例之一[1]。大數據環境中,知識圖譜通過結合不同個體的關系、屬性可視化模型與語義網技術,可使復雜的異構應用實現便捷、高效的人機信息交互。作為多種現代技術的結合,知識圖譜的核心技術包含智能語義[2]、知識提取[3]、知識關聯[4]、知識融合[5]、知識加工[6]等。其中,知識融合通過利用知識推理[7]、實體/本體匹配[8]等技術途徑,從不同數據源、不同數據結構的大數據環境中提取、關聯、合并同義或近義知識,從而實現異構知識圖譜的信息交互及協作應用。
知識融合是知識圖譜的關鍵環節,也是支撐知識圖譜可用性的重要要素,其核心為實體的消歧[9]與對齊[10]。實體的消歧指大量數據中同義實體的抽取及分類,一般用于海量異構數據的知識提取及知識分類;實體的對齊指同義、近義的實體或屬性間相互關系的分析,一般用于復雜異構實體的知識映射。實現實體的消歧與對齊通常采用基于機器學習技術的自然語言處理,從大量的半結構化數據中分析、提取近義實體,對齊、映射相關屬性。機器學習算法主要分為監督學習算法和無監督學習算法。監督學習算法(如貝葉斯估計、支持向量機等)使用歷史數據樣本訓練數據分析模型,通過數據預測、數據聚類等途徑進行實體對齊及屬性融合,具有較高的實時性,但較依賴于歷史數據樣本;無監督學習算法(如主成分分析、人工神經網絡等)無需樣本訓練成本,但一般復雜度較高,尤其在多維、異構的大數據環境中較難滿足知識融合的實時性。
據此,本文面向多維、異構的復雜大數據環境,提出一種結合監督學習、概念漂移檢測以及無監督反向驗證的高可靠、低復雜度知識融合方法。一方面,在監督學習過程中,該方法采用貝葉斯估計算法訓練歷史數據模型,預測待對齊實體,并周期性利用孤立深林算法檢測、修正概念漂移數據樣本,提高歷史數據模型的可靠性;另一方面,在反向驗證過程中,該方法采用一種低復雜度自組織映射(self-organizing map,SOM)神經網絡算法,分析實體歧義并根據評估結果實時調整監督學習的權重系數,進一步提煉數據模型,加強知識融合的準確性。
本文提出方法在公開數據集及國網安徽省配電網知識圖譜系統中進行了多項對比實驗。實驗結果表明,提出方法在歷史模型訓練、知識融合效率、算法復雜度等方面均優于常規機器學習算法。
1 知識融合技術相關研究
隨著知識圖譜在各行各業的迅速普及,跨業、跨界數據的知識融合技術已然引起了學術界的廣泛關注。國內方面,劉嶠等[11]詳細解釋了知識融合的概念、意義及知識融合在知識圖譜應用中的重要性;于夢月等[12]分析了現代知識融合的支撐理論架構,在知識融合的各階段列舉了多種知識融合理論模型;高國偉等[13]具體分析了先網絡環境的碎片化知識特征,提出了一種結合非線性融合模型的知識超網絡的融合框架;侯位昭等[14]針對解決推薦服務的信息爆炸問題,通過在推薦服務提出了一種基于貝葉斯網絡模型的知識圖譜融合技術;程秀峰等[15]面向用戶行為數據的采集與共享應用,在科研數據管理系統中通過知識融合技術分析了科研工作者的行為數據共享機制,并通過開發、應用移動行為數據采集APP開展了實證研究。異構數據的知識融合是現代知識圖譜技術的關鍵應用,常用于多語言知識鏈接、融合等,余圓圓等[16]面向跨語言百科文章之間的知識融合應用,提出了一種結合雙語主題模型及雙語詞向量的候選集排序模型,實現了中英文維基百科間的知識鏈接;余傳明等[17]提出了一種基于機器學習,融合雙語詞嵌入的主題對齊模型,通過提出雙語主題相似度、雙語對齊相似度等新對齊指標,改進了傳統雙語主題模型的語義共享;趙生輝[18]針對建模藏漢雙語融合型知識圖譜,通過從邏輯框架、知識模板和數據實例等三個層面解析建模原理,實現了多語言知識圖譜的創建及跨語言知識檢索。
國際方面,Ruta等[19]針對車載自組織網絡的上下文信息共享問題,提出了一種基于非標準、非單調推理服務的知識融合算法,實現了車載網絡節點不一致上下文注釋的自動協調及合并;Huang等[20]針對多源區間值(Interval-Valued)數據的動態融合,提出了一種將多源區間值數據轉換為梯形模糊顆粒的模糊信息融合方法及增量分析算法;Sultana等[21]面向基于社交行為提示的生物識別應用,通過融合個人知識、社交行為知識和獨有生物特征,增強了傳統生物識別系統的性能;Liu等[22]分析了基于知識圖譜的專家系統、搜索引擎及知識問答系統在害蟲及作物病害的應用,介紹了知識圖譜的知識融合技術在智慧農業的應用現狀;Han等[23]針對電力設備電源質量問題的多樣性及復雜性問題,提出了一種基于知識-數據融合的神經網絡模型,在常規信息、質量信息、過程信息等異構數據中有效提高了電源質量問題的分析效率;Li等[24]面向異構知識圖譜的融合應用,提出了一種基于圖結構數據、圖神經網絡,用于融合知識圖譜實體子圖結構的知識融合機制,實現了知識圖譜中實體的融合嵌入。
2 本體模型
本文提出的算法針對大數據環境中異構、半結構化數據的知識融合,因而采用了基于實體對齊的本體映射方法。本體(Ontology)在信息學科中,是一種對于數據的抽象概念模型,是人類與智能設備間存在的概念模式以及互交模式的形式化描述[25]。本體的建模以及匹配是大數據環境中實現知識共享、知識重用的關鍵要素。
本文采用了較為通用的本體模型,由實體、關系、屬性三元組組成,如式(1)定義:

其中,O為本體,E為實體(Entity),R為關系(Relation),A為屬性(Attribute)。實體、關系為結構化數據。其中,實體是本體的固有識別名,可以是物體、狀態、現象等對象的名稱,相同實體在異構數據庫中可對應不同本體;關系是本體中實體所對應屬性的關聯規則的集合。實體、關系在同構數據集中具有同等的定義,但在異構數據集間存在潛在的歧義。屬性為非結構化數據,包含實體由關聯規則對應的其他實體與對應關系的集合,由式(2)描述:
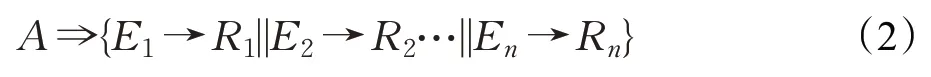
總之,本體模型中各元組的相互關系如圖1所示。
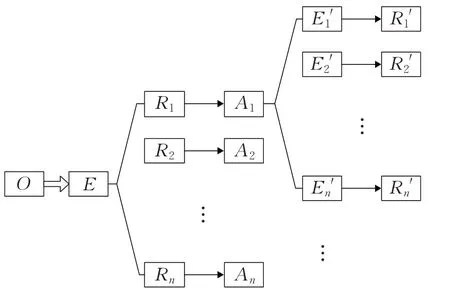
圖1 本體模型關系圖示例Fig.1 Example of relationship diagram of ontology model
即本體中唯一的E通過R關聯A,而A為非結構化自然文本數據,可包含多項其他E′及R′的關聯。該模型為二維本體,可根據應用需求及數據的信息量進一步擴展多維本體。
3 基于概念漂移檢測的監督式知識融合
根據上述本體模型,分析本體的相關度,進行基于貝葉斯估計法的實體對齊,通過映射相關屬性,實現知識融合。該過程的輸入為一個待融合本體;分析對象為目標數據庫中具備相同或近義實體的本體,近義實體則通過常規的文本相似度分析法進行判斷;輸出為目標數據庫中相關度最高的本體集。目標本體與待融合本體的相關度F(O)的計算方法有如式(3)所示:
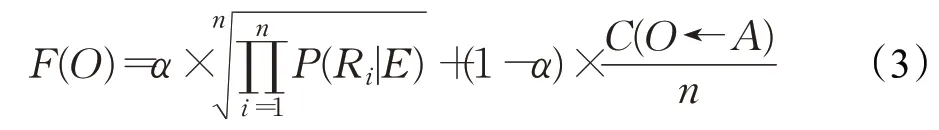
其中,O為異構數據庫中與待融合本體存在相同或近義實體的本體,取決于實體名稱的文本相似度;α為權重系數,默認值為0.5,根據反向驗證結果持續更新,在后續章節詳細敘述;n為相同或近義實體的數量;C(O←A)為目標本體與待融合本體的屬性相關度,有如式(4)所示:
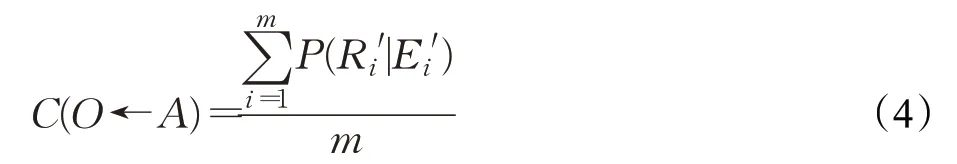
其中,m為本體O所包含屬性的數量;P(R|E)為貝葉斯后驗概率,由下式得出:

其中,P(R,E)、P(E)為先驗概率,從數據庫中統計得出;考慮到R之間無直接相關性,式(3)由后驗概率的平均值估算屬性相關度。
據此,通過計算本體間相關度,提取與待融合本體得出較高相關度的本體集合,對齊實體并連接相關屬性,實現異構數據庫的知識融合。如上公式,基于貝葉斯估計的相關度分析需充分利用歷史數據模型,統計實體與關系的先驗概率。而實際應用中,異常、突發事件的發生(如因突發事件,特定實體、關系的出現頻度驟增)可導致歷史數據的偏移,觸發概念漂移[26],從而降低貝葉斯數據模型的可靠性,如圖2。
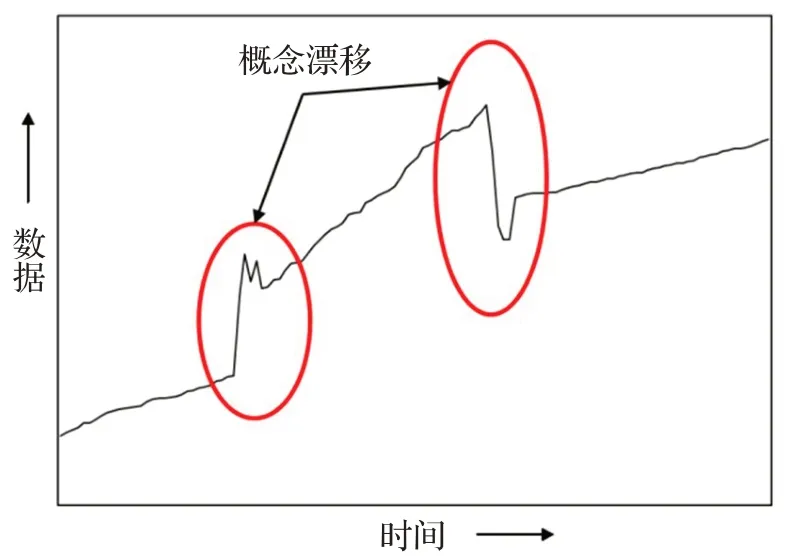
圖2 概念漂移示意圖Fig.2 Example of concept drifting
據此,采用基于孤立森林(iForest)的異常點檢測算法,進行概念漂移的檢測及數據模型的修復。該過程的具體目標為檢測、聚類非預期數據,并將其擬合至常規數據模型,提高整體歷史數據模型的可靠性,具體如下。
首先,在歷史數據中選擇定量樣本,構建決策樹(iTree);隨后,按均勻分布提取少量檢測點,計算檢測點在每棵iTree的平均高度h;最終,遍歷所有iTree,計算檢測點的異常概率分值,如式(6):

其中,E為0~1之間的異常概率分值;m為樣本個數;ξ為歐拉常數。
由上式,設定異常閾值,將異常概率分值大于異常閾值的數據判斷為異常數據。該過程中,離散的異常數據僅視為異常事件,從數據庫隔離;而連續的異常數據則判斷為概念漂移,將第一個異常數據的位置設定為概念漂移的起點,最后一個為終點,對范圍內的所有數據(包括非檢測點數據)進行歷史模型的擬合,如式(7)所示:
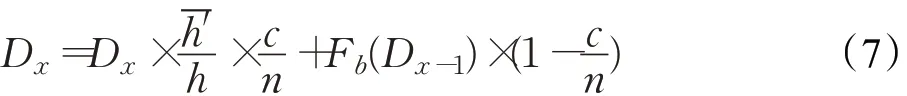
其中,Dx為第x個概念漂移數據;′為概念漂移數據在iTree的平均高度;c為概念漂移范圍的異常數據總量;n為發生概念漂移前歷史數據的總量;Fb為概念漂移前貝葉斯模型的預測函數。由上式,概念漂移的修正取決于異常數據的數據量及偏移量,異常數據量較多,其擬合過程偏向于數據偏移量的大小,反之,則偏向于貝葉斯歷史數據模型。
4 基于自組織映射的無監督式反向驗證
多維、異構的數據庫中,實體名稱的歧義可導致歷史數據模型的分析誤差,而反向驗證是進行實體消歧,提煉數據模型的有效手段。本文提出一種基于自組織映射(SOM)神經網絡的反向驗證算法,分析已對齊實體的歧義,輔助提高知識融合過程的知識融合準確率。該算法通過逆向匹配由貝葉斯數據模型對齊的實體集,進行實體的歧義補正,進一步提煉歷史數據模型的可靠性。
SOM是一種競爭型、無監督式神經網絡,常用于數據聚類[27]、協同控制[28]等。該神經網絡中,各神經元通過競爭、聚類、加權過程的多次迭代,實現復雜的信息處理。本文的反向驗證過程中,輸出神經元對應異構數據庫的所有實體,輸入神經元對應待匹配實體,而競爭過程則對應神經元在異構數據庫間的匹配度比較過程。
提出的反向驗證算法通過SOM的無監督式迭代匹配,評估已融合本體中各實體相似度,進行監督式本體融合的權值更新。首先,以首個數據庫的已對齊實體為輸出神經元,待匹配數據庫的所有實體為輸入神經元,進行匹配度比較并選擇獲勝神經元,如圖3。
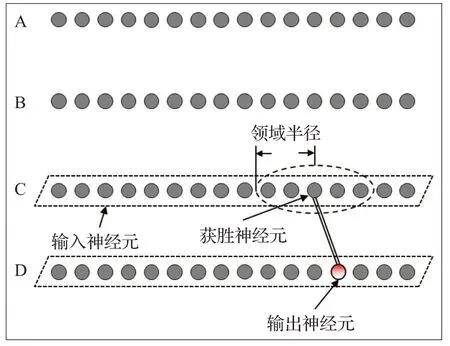
圖3 基于SOM的反向驗證算法(首次迭代)Fig.3 SOM-based reversing verification algorithm(first iteration)
圖3中,數據庫的迭代順序由已融合本體的相關度F(O)(式(1))排序而定。獲勝神經元選擇過程如式(8):
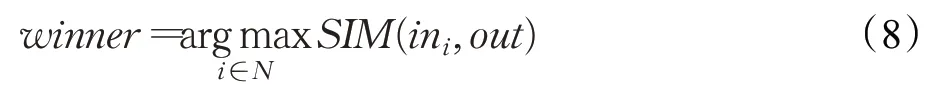
其中,winner為獲勝神經元,i為輸入神經元編號;N為輸入神經元集合;in為輸入神經元;out為輸出神經元;SIM為實體匹配度,由式(9)得出:
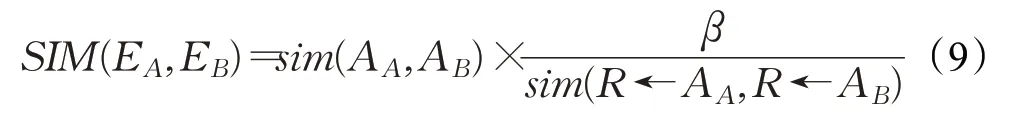
其中,E為比較本體所對應的實體;sim為文本相似度;AA、AB為兩個比較實體所對應的屬性中,具備最高文本相似度的屬性;R為關系,R對應該屬性與相關實體;β為匹配度權值,取決于已融合本體與獲勝神經元的本體相關度F(O)。
下一步為基于SOM規則的近義實體聚類過程。以上一次獲勝神經元為中心,計算SOM領域函數,如式(10):
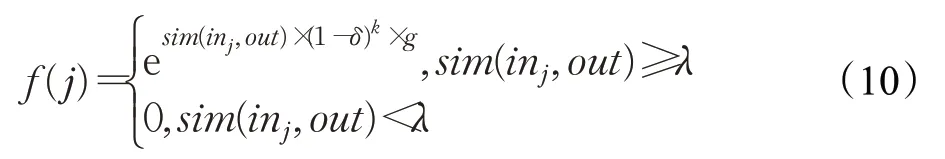
其中,j為輸入神經元編號;δ為0到1的常數,根據數據庫間的相關性設定;k為迭代次數;g為最高匹配值;λ為領域半徑。由此,下一輪迭代的輸出神經元為獲勝神經元的領域半徑(λ)內的所有本體,輸入神經元為數據庫C的所有本體,而領域值(f)則決定各輸出神經元的匹配權值,獲勝神經元獲得最高權值,其他神經元與獲勝神經元越近,則獲取更高的權值,首次迭代結束。
再次進行迭代競爭,與首次迭代不同,此時的輸出神經元為所有領域半徑內的神經元,匹配度比較公式更新如下:
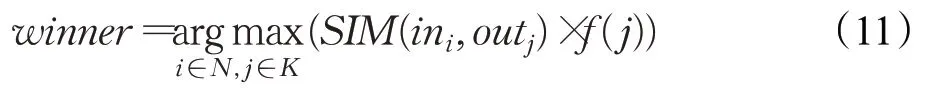
其中,j為輸出神經元編號;K為輸出神經元集合;f為匹配權值。
由式(11),選擇該輪迭代的獲勝神經元,如圖4。圖中,上輪的獲勝神經元具備最高的匹配優先度,但在數據庫B中找出最高匹配度本體的神經元是領域內其他神經元。因而,本輪獲勝神經元為數據庫B中與該最高匹配度本體所對應的神經元。
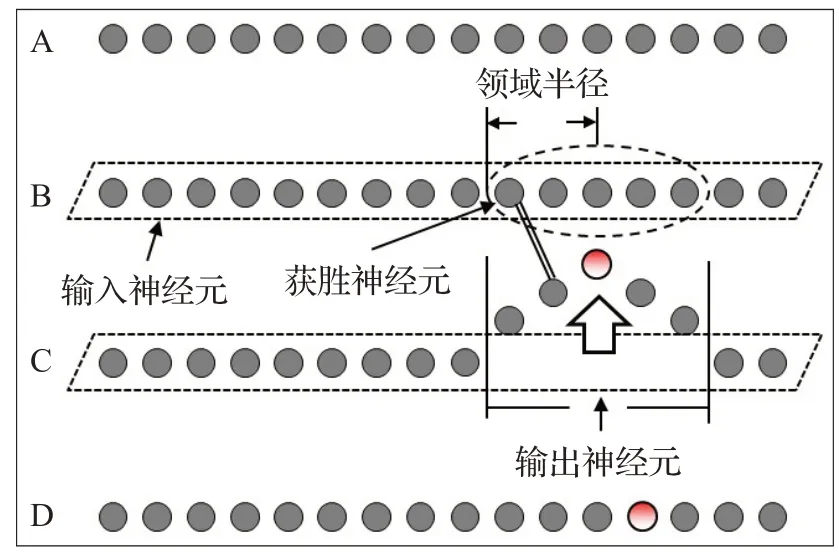
圖4 基于SOM的反向驗證算法(二次迭代)Fig.4 SOM-based reversing verification algorithm(second iteration)
持續迭代該過程,直到在所有異構數據庫中選出獲勝神經元,如圖5、圖6。
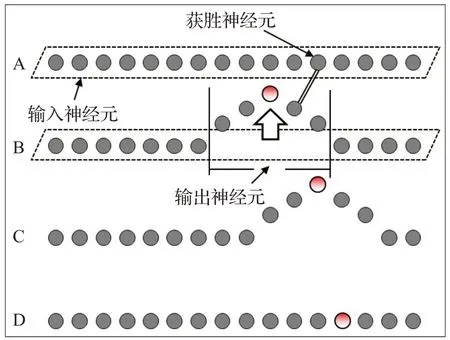
圖5 基于SOM的反向驗證算法(最終迭代)Fig.5 SOM-based reversing verification algorithm(last iteration)
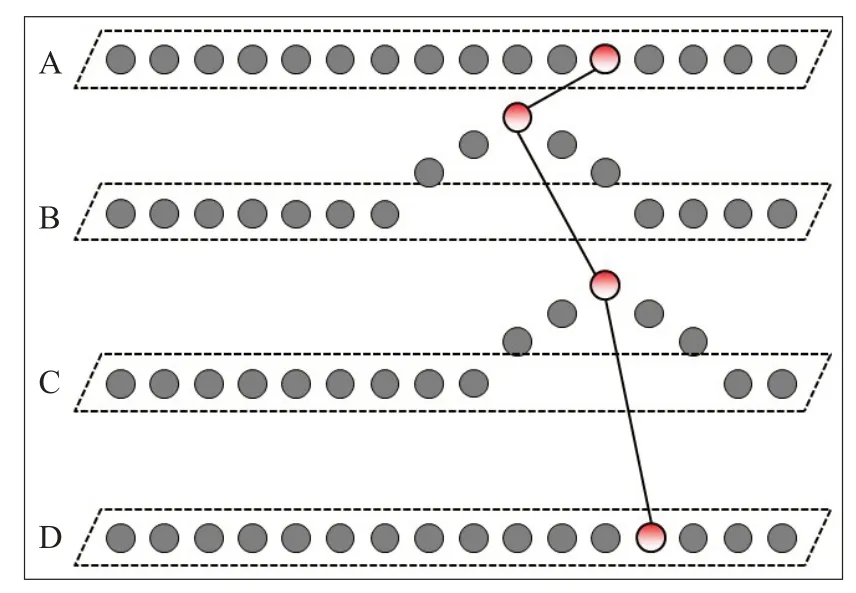
圖6 提取獲勝神經元Fig.6 Extracting winner neurons
最終,通過已融合本體與獲勝神經元的相似度比較,更新監督式知識融合的權重系數α(式(3)),如式(12)所示:
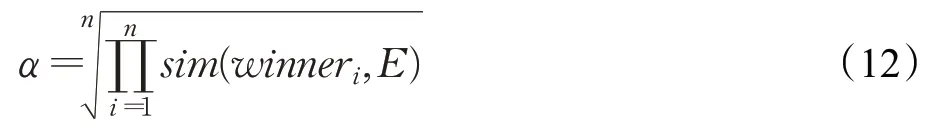
其中,n為SOM神經網絡的迭代次數。
基于SOM神經網絡的反向驗證算法無需在數據庫中獲取先驗知識,且相比常規的無監督式神經網絡算法,在每輪迭代過程中僅在獲勝神經元領域半徑內進行神經元比較,從而大幅度降低了神經網絡的拓撲結構復雜度,并保證了算法的收斂性。
5 性能分析與評價
通過在多維、異構數據環境中進行對比實驗,分析了提出方法的知識融合效率以及應用可行性。
首先,利用加利福尼亞大學機器學習與智能系統中心的公開數據集[29],對監督學習、概念漂移檢測、無監督反向驗證等提出方法的三階段運作過程進行了比較分析。該數據集包含了2014—2017年北京市天壇、奧體中心、萬柳、昌平等12個區域的空氣質量、溫度/露點溫度、風向/風速、空氣壓強、降雨量等時序性環境數據。
第一階段實驗的分析對象為提出方法的概念漂移檢測算法在貝葉斯歷史數據模型的數據預測效率。預測對象為基于PM2.5值的某區域空氣質量。實驗中,使用30%的數據構建了貝葉斯歷史數據模型,隨后在剩余70%數據種隨機刪減30%的數據,對刪除的數據進行了基于貝葉斯估計的數據預測,實驗結果如圖7所示。可以看出,基于概念漂移檢測算法預測的數據分布與實際歷史數據分布的吻合度相比于傳統貝葉斯監督學習顯著高,由此說明結合概念漂移監測算法,可以通過檢測、修正概念漂移數據提高數據預測的準確率,進而提高歷史數據模型的可靠性。
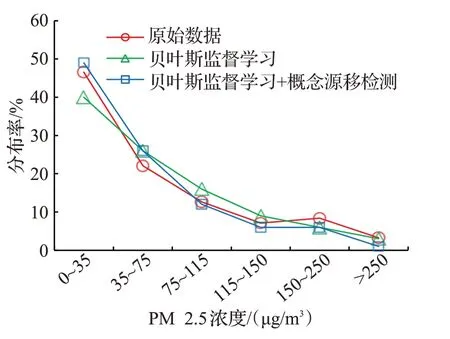
圖7 原始樣本分布與預測數據分布的比較Fig.7 Comparison of distributions of original samples and predicted data
第二階段實驗為整體方法的實體對齊效率。該階段將17種風向與10類風速組合文本設定為“實體”,溫度的特定區間設定為“關系”,其他對應數據(不包含時序數據)為“屬性”,以對齊實體的時間相關度差值為融合指標,進行了12個數據集的本體融合。實驗結果如圖8。
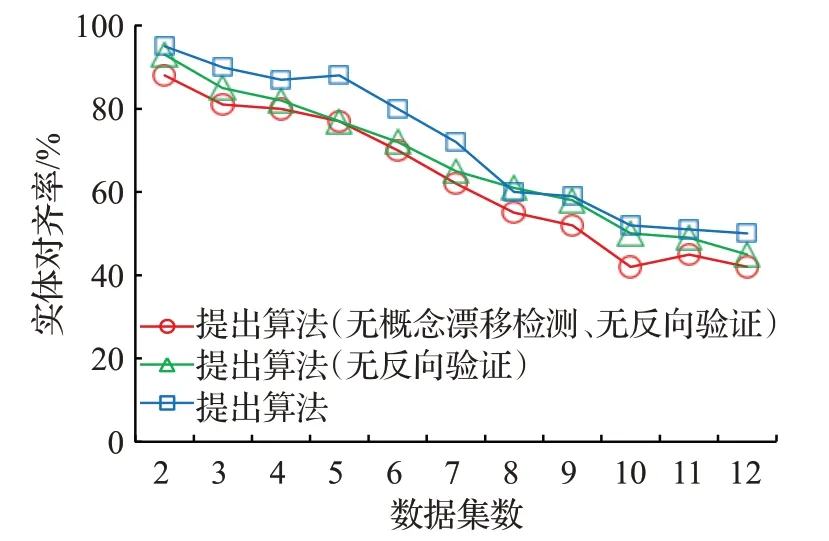
圖8 融合率比較Fig.8 Comparison of fusion rate
實驗比較了提出算法三種模式的實體對齊率,實體對齊率的定義為:已融合樣本與目標實體(第一個數據集實體)的時間相關度差值小于一定閾值的樣本所占比值。實驗結果可以看出,相比常規的無監督學習,提出算法的概念漂移檢測及無監督反向驗證過程均在一定程度上提高了實體對齊能力。
以上實驗使用了公開數據集的同構數據。隨后,為證實提出方法在異構數據集的應用可行性,使用國網安徽省電力公司的實際業務數據進行了實驗分析。該數據庫包括營銷業務應用系統、生產管理系統以及地理信息系統。實驗中,將該三類數據庫拆分為9個數據集,并通過在同類數據集間設置較高的數據相關度δ(式(10)),構建了多維異構數據環境。本實驗選擇了基于極大似然估計與K近鄰算法(K=10)的實體對齊方法進行了比對分析。
實驗方式如下:首先,根據預定義的語料庫,對所有異構數據庫進行本體關聯,定義實體對齊指標。例如,異構數據中實體為“電纜”“纜線”,關系為“故障”“停役”等本體屬于互映射本體,其屬性為實體及關系所對應的事件(如:發生***區域大規模停電、安排***維修員進行現場搶修等)。之后,在一個數據庫中隨機提取一個本體,進行實體對齊、實體消歧義及屬性融合。最終,根據實體對齊指標,計算已融合本體的TP(True Positive)、FP(False Positive)及FN(False Negative)指標,通過計算準確率(Precision)與召回率(Recall),比較分析F1分數,如式(13)~(15)所示:

圖9為F1分數的實驗結果比較。本文提出算法的兩種模式均得出了較高分數。實驗中,K近鄰算法根據輸入屬性,在全局數據庫間進行本體的聚類,選擇數據庫間離聚類中心最為接近的本體。這種方式在低維數據中可得出較好的融合效果,但在高緯度異構數據中,因持續累積的匹配誤差,最終得出較差的F1分數。極大似然估計法采用了比較所有實體→屬性→關系似然值的全局搜索方式,得出了近似提出算法(無反向驗證)的F1分值,但其全局搜索方式需要較高的時間復雜度。
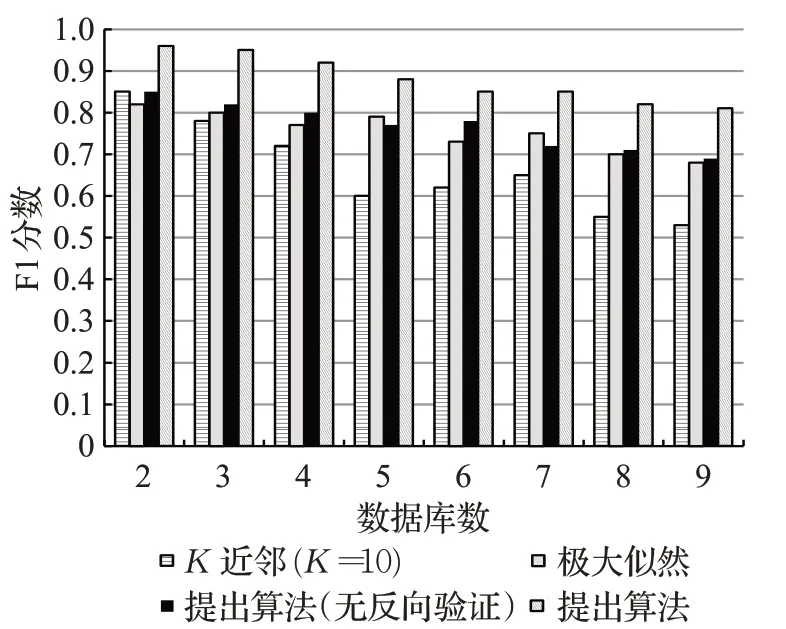
圖9 F1分數的比較Fig.9 Comparison of F1 scores
K近鄰與極大似然估計法均屬于無監督學習算法,在多維數據庫中具有較高的時間復雜度。圖10中,該類算法的運行時間按數據的維度指數級增長,因而較難應用于高緯度數據集。提出算法的運行時間是線性增長,其中,反向驗證過程占用了約20%的算法運行時間。實驗中,概念漂移檢測的進程與本體融合相互獨立,因而未納入運行時間的比較。
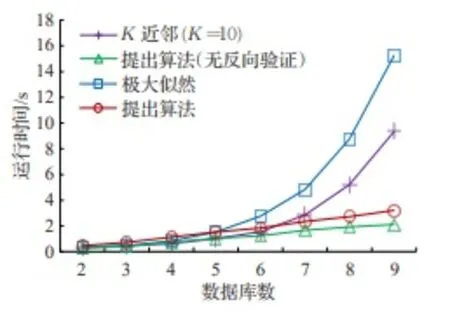
圖10 算法運行時間的比較Fig.10 Comparison of run time
總之,提出算法在F1分數和運行時間上均得出了較好的數值。相比K近鄰算法,得出了顯著提高的F1分數;極大似然估計法與提出算法(無反向驗證)得出了類似的F1分數,但提出算法具有較低的時間復雜度,因此體現了良好的算法收斂時間。上述實驗證明了提出算法在多維、異構大數據環境的知識融合可行性。
6 結束語
本文面向大數據環境的復雜信息融合應用,提出了一種結合監督學習、概念漂移檢測及無監督反向驗證的知識融合方法。該方法通過在監督學習中引入周期性概念漂移檢測,提高數據模型的可靠性及實體對其效率,并在異構數據集間利用無監督式反向驗證算法,有效、高速地進行實體消歧義。目前,提出算法在國網安徽省電力公司知識圖譜系統中進行著試點應用,未來工作為選擇、比較及優化符合監督學習-概念漂移檢測-無監督反向驗證的先進算法,進一步提升知識圖譜系統在異構大數據環境的應用可行性。
猜你喜歡
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
無線電工程(2020年11期)2020-10-29 01:25:46
現代出版(2020年3期)2020-06-20 07:10:34
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
