煙草文獻數據知識檢索服務平臺的設計與實現
2022-03-25 13:26:48王永勝劉亞麗宗國浩鄭新章馮偉華
煙草科技 2022年3期
王永勝,劉亞麗,賈 楠,宗國浩,王 銳,王 迪,鄭新章,馮偉華
中國煙草總公司鄭州煙草研究院,鄭州高新技術產業開發區楓楊街2 號 450001
科技文獻資源是重要的科技基礎條件[1],國家中長期科學和技術發展規劃綱要(2006—2020)指出,科技投入和科技基礎條件平臺是科技創新的物質基礎,是科技持續發展的重要前提和根本保障。國家煙草專賣局在行業中長期科技發展規劃綱要(2006—2020)中也提出,要充分利用現代信息技術手段,加強煙草科學數據平臺、科技文獻平臺、科技資源平臺和網絡科技環境平臺建設。而信息資源的有效利用是推動行業自主創新的重要基礎[2],積極推進信息化與煙草產業的深度融合,構筑以“用戶為中心”的煙草文獻數據知識檢索服務平臺是推動煙草文獻數據共享服務向智能化、精準化、知識化轉型的重要舉措[3-4]。2000 年張曉林[5]提出知識服務的概念,即知識服務是用戶目標驅動的服務,是面向知識內容的服務,是提出解決方案的服務,是貫穿用戶解決問題過程的服務,也是能夠增值的服務。知識服務和信息服務雖本質相同,但在服務程度上存在差別。信息服務是一種檢索和傳遞顯性知識的服務,而知識服務是提供解決方案的智力服務,可同時提供顯性和隱性知識。信息服務是知識服務的基礎,知識服務是信息服務的深層次服務,是信息服務的升華[6]。中國知網、萬方數據知識服務平臺、維普、超星等機構的數據庫均擁有海量的文獻數據資源,面向互聯網用戶提供各類文獻數據資源的信息檢索和知識服務[6]。煙草文獻數據是煙草行業重要的數據資源,包含中外文煙草期刊論文、會議論文、學位論文、科技成果、國內外專利、標準、科技信息、科技圖書、法律法規和設備樣本等數據。近年來,隨著信息技術的發展,煙草行業對科技信息資源的需求已從單純的資源獲取演變為數據知識服務[7-9],滿足行業科技人員資源檢索和知識服務的需求已成為亟待解決的問題。為此,通過對煙草文獻數據資源進行結構化和碎片化處理,利用大數據分析和自然語言處理(Natural Language Processing,NLP)技術構建了煙草文獻數據知識檢索服務平臺,以期促進煙草文獻的知識化整合,滿足行業科技人員對文獻信息資源更深層次的知識需求,為推動煙草行業科技創新提供支持。
1 系統設計
1.1 體系架構
煙草文獻數據知識服務平臺基于B/S 架構進行設計,遵循J2EE開發標準規范并采用前后端分離的開發模式。前端主要采用LayUI、JQuery 等框架,數據檢索采 用 SolrCloud 構 建索引[10];后 端采用RESTFUL API 接口技術,通過JSON 實現與前臺的數據交互。結構化數據采用Oracle 數據庫存儲,非結構化數據采用FastDFS分布式文件系統存儲。
系統體系架構主要分為數據層、服務層和應用層,見圖1。數據層為上層應用提供數據支撐,包括煙草學科領域的中外文期刊、會議論文、學位論文、科技成果、國內外專利、煙草標準、科技信息、科技圖書、法律法規和設備樣本等文獻數據資源庫;服務層包括數據處理和知識加工兩個模塊,數據處理模塊完成采集、清洗、融合、加工等功能,知識加工模塊完成索引構建、文本提取、語義識別、統計分析、可視化展示等功能;根據服務層提供的知識資源整合服務,應用層實現煙草文獻數據資源的智能檢索、智能推薦、智能分析、科技評價以及查新查重等功能,并設置熱點專題和個人中心模塊。此外,系統公共組件還包括爬蟲服務、資源加工、檢索服務、賬戶管理、日志監控、權限控制以及規則庫管理等模塊。

圖1 系統體系架構Fig.1 System architecture diagram
1.2 業務流程
系統業務流程包括文獻數據采集、整合、加工、審核發布、知識庫構建、知識分析應用等部分,見圖2。數據來源主要有互聯網上離散的煙草文獻數據、行業內非結構化文本數據、已有業務系統存儲的文獻數據以及其他文獻數據。這些海量的煙草文獻數據經過采集、碎片化處理、自動化導入和手動錄入等方式實現了異構文獻資源的集成,再經過融合、去重、清洗、標引等知識加工處理后由相應人員審核并發布到緩存庫。索引管理中心針對緩存庫中的元數據和全文數據構建主題索引和專題索引。文獻檢索分析引擎通過檢索與分析接口對檢索結果進行合并、排序、分類和分析等處理,為用戶提供文獻檢索、知識展示、智能分析、科技評價等服務。
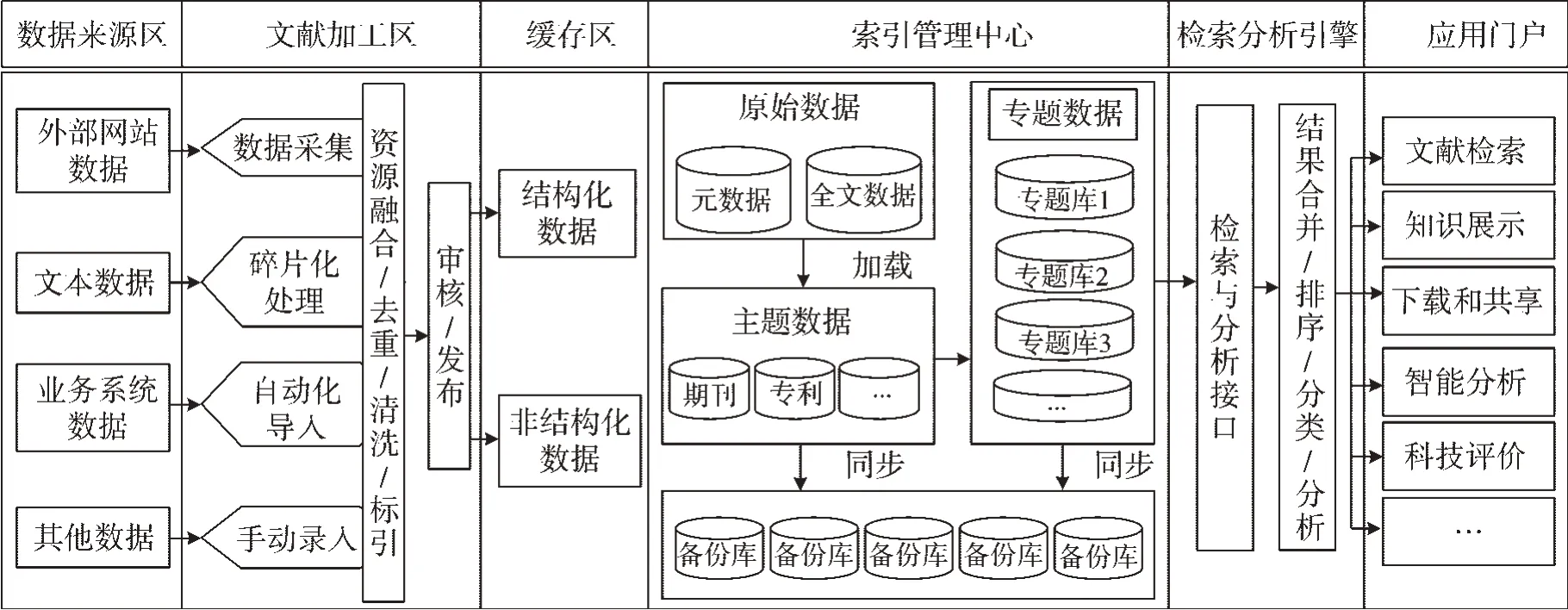
圖2 系統業務流程Fig.2 System process diagram
2 功能實現
系統以煙草文獻數據為基礎,采用數據融合、文本分析、知識挖掘、文獻計量等技術,對煙草文獻資源進行知識挖掘和知識關聯分析,從廣度和深度上揭示文獻資源的隱性信息。系統核心功能模塊見圖3。

圖3 系統核心功能模塊Fig.3 System core function modules
2.1 文獻智能檢索服務
針對期刊、科技成果、專利、標準等煙草文獻資源,采用先進的檢索技術和知識發現算法,實現了模糊檢索、語義檢索、意圖識別、以圖搜索等多種智能檢索服務。此外,采用精準的知識聚類和篩選機制,開展學科分布、收錄分布、機構篩選等自動聚類服務,實現了文獻檢索結果的細化和分層顯示,幫助用戶在海量資源中快速、精準地定位到最佳匹配結果,提升用戶獲取和利用知識的能力。文獻智能檢索服務功能頁面見圖4。

圖4 文獻智能檢索服務頁面Fig.4 Intelligent retrieval of literature resources
2.2 科技分析與評價服務
為幫助用戶把握國內外研究主題的分布趨勢,探究研究主題滲透的學科領域,發現研究主題的相關學者和代表機構等內容,從學術產出、學術影響、發文趨勢、學科分布、期刊分布、代表學者、基金資助、代表機構以及最新文獻等方面對檢索主題詞進行多維度、全方位分析,并借助數據可視化技術展示研究主題的知識脈絡。針對煙草科研活動的特點和規律,結合煙草行業科技創新評價原則,研究制定了涵蓋科技項目、科技成果、科技獎勵、學術論文、專利、標準、著作等評價指標的煙草機構和科研人員綜合性評價指標體系,實現了煙草機構和人員科研能力的綜合評價功能。科技分析與評價服務功能頁面見圖5。
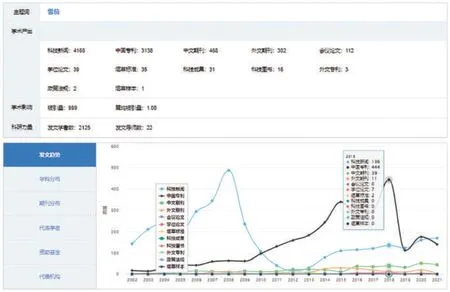
圖5 科技分析與評價服務頁面Fig.5 Scientific and technological analysis and evaluation
2.3 知識智能擴展服務
基于細粒度、碎片化、結構化的煙草文獻知識元,圍繞作者、機構、期刊、參考文獻、關鍵詞等內容構建煙草知識脈絡,實現了煙草知識多維度、全方位的知識智能擴展服務,包括概念擴展、同義詞擴展、相關熱詞、相關文獻、合作網絡、學者知識脈絡等功能。其中,學者知識脈絡可以提供學者文獻引用情況、學術關鍵詞、學術成果趨勢分析、代表性合作學者及科研產出詳細列表等服務。學者知識脈絡功能頁面見圖6。

圖6 學者知識脈絡服務頁面Fig.6 Scholar knowledge vein
3 關鍵技術
3.1 統一檢索技術
采用SolrCloud 分布式搜索技術,構建了煙草文獻統一檢索引擎,實現了中文期刊資源庫、外文期刊資源庫、中國專利資源庫、國外專利資源庫、科技成果資源庫、煙草標準資源庫等12 種文獻資源庫的統一檢索。SolrCloud 是一種基于Solr 和Zookeeper 的分布式搜索方法,具有中心化集群配置、自動容錯、近實時搜索、查詢時自動負載均衡等特點[11]。在進行檢索時,SolrCloud 先將索引數據進行Shard 分片,每個分片均由多臺服務器共同完成;當接收到索引或搜索請求時分別在不同Shard服務器中操作,提供檢索服務。采用SolrCloud 分布式搜索技術可使全文檢索準確度達到97%以上。
3.2 文獻碎片化處理技術
按照已制定的標準格式或規則,采用中文分詞、自動標引等文獻碎片化處理技術對煙草科技文獻的PDF 文件進行處理。依據文獻標注模型,根據中文文本版面的特征規律,自動完成文檔的碎片化和結構化,主要包括元數據標引,文章的篇、章、節結構分析和拆分,自動提取文本中的段落、圖片、表格、公式等內容,實現PDF 文檔版面的自動識別和結構化解析,并生成具有統一格式、統一命名規范和組織規范的結構化數據[12]。此外,利用文獻碎片化工具還可生成XML結構及附圖,方便與其他業務系統進行交互及數據的二次加工。
3.3 關鍵詞提取算法
文本關鍵詞是指能夠表達文檔中心內容的詞語[13-14]。在信息檢索中,準確提取關鍵詞可以大幅度提升檢索效率;在知識推薦中,關鍵詞的發現有助于獲取主題思想。在煙草文獻數據的文本預處理階段,采用詞向量聚類加權的TextRank 算法、LDA(Latent Dirichlet Allocation)算法等關鍵詞提取技術,通過提取文本中的學者、機構等信息以及文獻相關主題詞,可以為合作關系網絡的發現、文獻標簽體系的構建、學術關鍵詞的提取以及研究熱點主題詞分析等提供技術保障。
3.4 文獻共引聚類算法
文獻共引是指兩篇文獻同時被另外一篇或多篇論文引用的關系[15]。采用共引加權算法從文獻的標題、摘要、作者、關鍵詞等內容中提取特征詞構建特征向量,利用共引加權的相似度計算函數計算特征向量間的相似度,得到文獻相似度矩陣,進而實現共引文獻的聚類分析。該技術可以揭示學科內部的相互關系以及研究熱點的發展脈絡[16]。
4 結論
基于大數據和自然語言處理等技術,采用先進的檢索技術和知識發現算法,結合知識圖譜可視化分析技術,對煙草文獻數據資源進行了深度融合與分析,研究構建了煙草文獻數據知識檢索服務平臺,可實現煙草科技文獻的智能檢索、科技分析與評價、知識智能擴展等功能,提高了煙草學科領域文獻資源的整合能力、信息檢索能力、知識精準定位能力以及領域知識分析能力。該平臺目前還處于發展和完善中,在知識服務方面仍存在許多有待研究和改進之處,未來將圍繞煙草行業科技創新發展布局和科研工作知識服務需求,從科研項目選題定題、煙草百科、領域專家智能推薦等方面入手,進一步開展相關研究,推動煙草文獻數據共享服務向全面的知識服務轉型。
猜你喜歡
奧秘(創新大賽)(2023年3期)2023-05-06 01:48:20
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
少兒科學周刊·兒童版(2017年9期)2018-03-15 15:00:11
兒童故事畫報·發現號趣味百科(2017年4期)2017-06-30 12:41:53
資源再生(2017年3期)2017-06-01 12:20:59
浙江中西醫結合雜志(2017年2期)2017-01-12 18:23:59
兒童故事畫報·發現號趣味百科(2016年6期)2016-08-19 06:35:19
當代化工研究(2016年9期)2016-03-20 16:22:08
