云環(huán)境下面向數據密集型應用的容錯性資源配置研究
2022-03-25 01:09:04李宏梅楊天國張磊莫瑞超許小龍徐占洋
云南電力技術 2022年1期
李宏梅,楊天國,張磊,莫瑞超,許小龍,3,徐占洋,3
(1.云南電網有限責任公司德宏供電局,云南 德宏 678400; 2.南京信息工程大學計算機軟件學院,江蘇 南京 210044; 3.南京信息工程大學江蘇省網絡監(jiān)控中心,江蘇 南京 210044)
0 前言
隨著近些年來互聯網行業(yè)的快速發(fā)展,互聯網應用所產生的數據規(guī)模在不斷擴大的同時,數據的復雜性也在逐漸增加[1]。為了給用戶提供豐富且良好的互聯網服務,如何及時有效地處理這些應用數據是現在互聯網行業(yè)所面臨的巨大難題[2-3]。
云計算作為一種分布式計算模式,通過將計算任務部署在擁有超強計算能力的資源池中,各計算任務能夠根據自身需求獲取計算資源,從而使得計算任務能夠得到高效的執(zhí)行[4]。隨著近些年來云計算技術的快速發(fā)展,云計算的相關技術日漸成熟,通過構建大型云平臺以滿足用戶的計算資源需求,使得互聯網應用所產生的數據能夠得到有效的處理,已經成為目前的一種趨勢[5]。
數據密集型應用作為一種對數據的訪問頻率十分密集且數據量大的特殊應用,其要求產生的數據需要在極短的時間內得到有效處理。相比與非數據密集型的應用,數據密集型應用對數據處理時延極其敏感。當應用所產生的數據不能夠得到及時的處理將會帶來較差的用戶體驗。云計算技術雖然為應對數據密集型應用的計算需求提供了充足的計算資源,但在云平臺中部署數據密集型應用時仍有一些問題需要解決[6-7]。在云平臺中有許多因素可能導致計算結點死機,例如計算結點過載,操作系統(tǒng)的故障等等[8-9]。當任意托管應用的計算節(jié)點發(fā)生故障時,部署在該故障結點的計算任務不能夠及時的在正常運行的計算結點得到恢復將會引發(fā)各種后果(例如,數據丟失,數據密集型應用完成時間延長等),而這些后果將會給用戶(比如:電力行業(yè))帶來巨大損失[10-12]。總的來說,在云平臺出現故障后,如何為故障結點上部署的任務選擇合適的資源配置策略依舊面臨著巨大挑戰(zhàn)。一方面,為宕機結點上部署的計算任務選擇出最優(yōu)的資源配置策略需要使得數據密集型應用的完成時間盡可能的短,另一方面,云平臺計算結點的負載均衡也需要被考慮,通過優(yōu)化負載平衡,云平臺所有計算節(jié)點都工作在穩(wěn)定狀態(tài),這有利于提高云平臺的資源利用率。此外,保證云平臺的負載均衡能夠降低了數據密集型應用執(zhí)行過程中出現問題的可能性,從而進一步提高了云平臺的容錯能力。
針對現存的故障任務遷移問題上,國內外學術界和工業(yè)界都開展了廣泛的研究:Zhu等設計了一個隨意的工作流容錯框架,并提出了一種動態(tài)容錯調度算法,用于對虛擬化云中的實時工作流進行資源配置[13];文獻[14]中,Asvija等結合實際的氣象工作流建立了MM5模型作為計算網格工作流程的支持框架以解決故障任務的遷移問題;Chen等提出了一種普通任務失效建模模型,該模型采用基于最大似然估計的參數估計過程來模擬工作流工作的性能,該模型的提出在一定程度上解決了故障任務恢復的問題[15];文獻[16]中,Ding等從云平臺的角度提出了一種容錯彈性調度算法,可以應用于云平臺來執(zhí)行工作流;而在文獻[17]中,Yao等設計了一種獨特的容錯工作流調度算法,該算法結合了基于復制和基于重新提交的策略,以實現其容錯功能。
但是當前的研究工作忽略了在任務恢復過程中任務的執(zhí)行完成時間問題,而且也忽略了任務故障恢復對數據中心負載均衡所造成的影響。因此,本文針對性提出了一種云計算環(huán)境下面向數據密集型應用的容錯性資源配置方法,以實現任務故障恢復,并能夠保證故障恢復后的任務的完成時間與云平臺所有計算結點的負載均衡需求。
1 基于VL2網絡拓撲結構的云平臺
虛擬層2(Virtual layer 2,VL2)[18]是一種實用的網絡拓撲結構,分為中繼交換機層(Intermediate Switches Layer)、匯聚交換機層(Aggregate Switches Layer)和TOR交換機層(Top of Rack Switches Layer)[15]。通過部署大量的網絡設備和網絡鏈接,VL2網絡拓撲結構實現了網絡的全二等分帶寬,為建立高性能的云平臺提供了良好的基礎[18]。
如圖1所示,在根據VL2網絡拓撲結構搭建的云平臺中,不同的區(qū)域根據實際的計算需要部署任務備份節(jié)點和計算節(jié)點。在同一區(qū)域的所有計算節(jié)點和備份節(jié)點都被連接相同的TOR層交換機。此外,為了保證兩個區(qū)域之間的數據通信,兩個相鄰區(qū)域的TOR層交換機被連接到同一個匯聚層交換機上。同時,匯聚層的所有交換機都被連接到中繼交換機上以保證網絡中所有區(qū)域之間的數據通信。因此,在VL2網絡拓撲結構所搭建的云平臺中每一個終端計算節(jié)點到中繼交換機的最長距離為3跳,這使得在云平臺部分結點發(fā)生錯誤的時候,宕機任務能夠得到有效的恢復。

圖1 基于VL2網絡拓撲結構的云平臺
2 系統(tǒng)模型
2.1 數據密集型應用模型
為了簡化數據密集型應用的工作流程,在本文中將數據密集型應用被定義為有向無環(huán)圖(Directed Acyclic Graph, DAG),用D={T,R}來表示,其中T={t1,t2,...,tn}代表著完成該數據密集型應用做需要執(zhí)行的任務集合,而R用來表示任務之間數據依賴集合。兩個任務之間的數據依賴可以用ri,j=(ti,tj)的形式來表示,在這種 情 況 下,任 務ti(1≤i≤n)表 示 為tj(1≤j≤n)的前驅任務,相應的tj則作為ti的后繼任務。一般來說,一個任務的開始需要傳入來自前驅任務完成得到的數據。此外,tstart和tend這兩個虛擬任務分別作為應用的開始任務和結束任務被引入,使得應用中只包含一個入口和出口。
在數據密集型應用模型中,從開始結點到結束結點花費時間最長的路徑被稱為關鍵路徑,為了找出關鍵路徑,應用中的每一個任務的最早開始時間(Earliest Start Time, EST)、最早完成時間(Earliest Finish Time, EFT)、最晚開始時間(Last Start Time, LST)和最晚結束時間(Last Finish Time, LFT)需要被計算出來以便判斷該任務是否處于關鍵路徑。任務ti的最早開始時間可以通過下面的公式計算出來:

其中,p(ti)代表的是任務ti的所有前驅任務集合;αjexe是任務完成所需要的執(zhí)行時間;ctfi,j代表的是任務ti獲取其前驅任務數據所需要花費的時間。
2)迭代:在NSGA-III的迭代過程中,父代種群Ho經過選擇和突變產生子種群Qo,然后將來自父代種群Ho和子種群Qo的所有個體融合到Ro中,然后通過非優(yōu)勢排序從Ro中選擇合適的個體,然后通過參考點法從N個個體形成新的種群N個個體選取新的個體以構建新的種群Ht+1。當數據密集型應用的完成時間和云平臺的負載均衡的結果收斂后,NSGA-III的迭代過程將會停止,而此時種群中的個體將形成一個解集,稱為帕雷托(Pareto)最優(yōu)解。
粗選磁場強度110 kA/m,精選磁場強度110 kA/m,掃選磁場強度110 kA/m。磨礦細度80.00%-0.074 mm,給礦濃度35.00%。試驗結果見表9,試驗原則流程圖及數質量流程分別見圖3、圖4。

任務ti的最晚開始時間通過下式可以計算出來:

其中,c(ti)代表的是任務ti的后繼任務集合。此外,應用的最晚開始時間表示為:
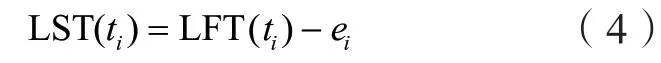
通過上述分析,可以得到應用上每一個任務的最早開始時間和最晚開始時間,而后根據關鍵路徑的定義可知,當一個任務的最早開始時間和最晚開始時間相等,則該任務是關鍵路徑上的任務,稱該任務為關鍵任務。根據關鍵任務可以找出應用的關鍵路徑,從而計算出該數據密集型應用的最大完成時間D。
2.2 宕機任務恢復時間計算模型
在數據密集型應用模型基礎上,假設由于計算結點發(fā)生故障導致工作流產生的宕機任務集合為FT={ft1,ft2,...,ftn},為了恢復ftz(1≤z≤n),該任務的備份鏡像數據和前驅任務完成所產生的數據需要被發(fā)送到恢復該任務的計算結點,從而使得ftz能夠繼續(xù)執(zhí)行。然而,恢復任務的計算結點接收宕機任務的鏡像數據和其前驅任務所產生的數據并且重啟ftz需要花費一定的時間云計算平臺是不能夠被忽略的。假設恢復任務ftz所需要的時間為HFSz,則HFSz表示為:
扶貧資源濫用,扶貧資金被截留和貪污,扶貧政策監(jiān)管和執(zhí)行中出現偏差,一個重要的原因就是缺乏有效的跟蹤反饋[4]。由于觀念原因,有些脫貧人口仍死死扣留“貧困帽子”,不愿退出。由于上級下達的貧困戶指標有限,真正需要幫助的貧困戶無法進入。部分地區(qū)返貧率高,沒有返貧人口再入機制,貧困人口退出機制和再入機制不健全,一些人甚至出現“被脫貧”、“假脫貧”現象。由此可以看出,缺乏動態(tài)管理和監(jiān)管,對黑龍江省精準脫貧產生了巨大的束縛。

本文提出了一種容錯性資源配置方法(Fault- tolerant Resource Provisioning Method,FRPM)使得在云平臺發(fā)生錯誤之后,宕機任務能夠找到最優(yōu)的恢復策略,保證部署在云平臺上的數據密集型應用的完成時間最短的同時,云平臺的負載均衡也能夠得到保證。本文所提出的FRPM是基于參考點的非支配排序算法(Non-dominated Sorting Genetic Algorithm III, NSGA-III)[19],該算法是一種能夠針對目標進行同時優(yōu)化的遺傳算法,FRPM在實現過程中將數據密集型應用的完成時間和云平臺的負載均衡作為算法優(yōu)化的目標,借助NSGA-III為宕機任務找到能夠同時滿足數據密集型應用的完成時間最短和云計算平臺的負載均衡這兩個目標的資源配置策略。
假設云計算中心當前未發(fā)生故障的計算結點的集合為Ps={ps1,ps2,...,psl},且每一個計算結點所剩余的計算資源表示為cd(1≤d≤l)。此外,鏡像服務器集合為Pm={pm1,pm2,...,pmk}。假設ftz會在psd(1≤d≤k)上重啟,則psd需要從不同的結點獲取ftz的鏡像數據和其前驅任務所產生的數據。假設恢復ftz所需要的鏡像數據和前驅任務所產生的數據分別存放在pam(1≤a≤k)和psb(1≤b≤l)上面。
根據VL2的網絡拓撲結構特點,不同的結點之間的位置關系存在3種情況,為了便于表示恢復任務計算結點與前驅任務數據所在結點以及任務的備份數據所在結點之間的關系,使用ξ來表示這三種情況:
1)ξ=0代表著兩個計算結點連接到了同一個TOR;
2)ξ=1代表著兩個計算結點未連接到同一個TOR交換機,但是連接到了同一個匯聚層交換機;
3)ξ=2代表著兩個計算結點未連接到同一個TOR交換機或匯聚層交換機,但是兩個結點連接到了同一個中繼層交換機。同理,計算結點和任務鏡像結點之間的關系也可以用ξ來表示。
與傳統(tǒng)的遺傳算法相比,NSGA-III通過采用精英策略,能夠很迅速找到多目標優(yōu)化問題的全局最優(yōu)解,所以在本文中采用NSGA-III來解決多目標的宕機任務恢復問題[20]。在遺傳算法中,染色體的基因型表示多目標優(yōu)化問題的解。在本文中為了找到宕機任務恢復策略,對云平臺中未發(fā)生錯誤的計算結點進行編碼,將每個計算節(jié)點的編號作為基因,這些基因被組合在一起形成一條染色體,染色體通過不斷的變異和進化從而為宕機任務找到最優(yōu)的資源配置策略。此外,由于宕機任務不能夠在出現問題的計算結點恢復,也不能在計算容量不能夠滿足運行該任務的計算結點上執(zhí)行,所以對每一條染色體,式(13)和式(14)給出了適應度函數。
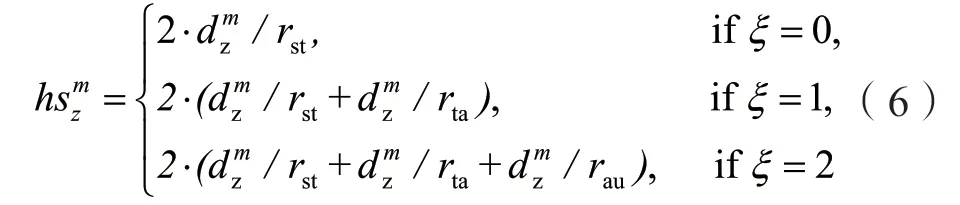
for 關鍵任務 do
當psd在得到了ftz的鏡像數據之后,需要獲取來自該任務的前驅任務的數據,假設前驅任務的數據大小為dmz,則獲取前驅任務所產生數據需要的傳輸時間hssz表示為:

此外,由于ftz的前驅任務可能會是一個或多個,所以需要從多個計算結點獲取數據,但是psd在獲取這些前驅任務的數據是同時進行的,所以將在這個過程中需要的最長時間作為hssz。
2.3 負載均衡模型
在對宕機任務進行恢復的過程中,需要考慮到這些任務都屬于數據密集型的任務,對計算結點所處的狀態(tài)有一定的要求。具體來說,如果宕機任務在過載或者即將過載狀態(tài)的計算結點進行恢復,將會引發(fā)云平臺的計算結點再次出現宕機的情況。因此,在對宕機任務進行恢復時一定要考慮到云平臺所有計算結點的負載均衡狀態(tài),降低由于恢復宕機任務而導致計算結點負載不均衡的可能。在本文中,云平臺所有計算節(jié)點平均利用率的方差被用來表示云的總體負載平衡。云計算中心所有計算結點的負載均衡方差的值越小,就表明云中各計算節(jié)點的整體負載越均衡。假設完成任務td(1≤d≤n)所需的虛擬機容量是vmd,且每個計算節(jié)點的平均利用率由ρd來表示,可以表示為:
①系統(tǒng)覆蓋范圍和用戶較廣。在管理內容上覆蓋了水利、供水、排水、水文四大行業(yè);在管理范圍上覆蓋了國家、直轄市、區(qū)(縣)三級管理;在建設范圍上覆蓋了自動化和信息化等方面集成;在用戶使用上覆蓋了水行政主管部門、企業(yè)、科研規(guī)劃部門、社會公眾等。

其中,ω(ti)表示的是判斷任務ti是否運行在計算結點psw(1≤w≤l)上,表示為:

此外,ρ被用來表示云平臺中所有計算結點的平均資源率,表示為:

最后,通過以上計算得出了云平臺各計算結點的平均資源利用率和云平臺總體的平均資源利用率,由此可以的得到云平臺的負載均衡,可以表示為:

2.4 目標函數
在云平臺的計算結點發(fā)生錯誤時,需要盡快對部署在這些計算結點上的計算任務在其他正常計算結點重新啟動,以確保數據密集型應用的完成時間D最短的同時,也要保證云平臺各計算結點的負載均衡U。本文所需要實現的目標和約束具體表示為:

3 本文方法
其中hsmz代表的是下載ftz鏡像數據所需要的時間,hsfz是獲取該任務的前驅任務執(zhí)行產生數據所花費的時間,hssz是在計算結點上重啟ftz所需要的時間。
基于前文分析,從深層原則與基礎理念看,近代以來西方社會管理的基本要素或基本原則主要有兩個:一是個人主義,二是理性主義。
3.1 數據密集型應用完成時間計算方法
數據密集型應用的完成時間是指從開始任務到結束任務所需要的最長執(zhí)行時間,也就是關鍵路徑上所有任務完成所花費的時間的總和。為了計算出數據密集型應用的完成時間,在算法1中,首先需要找出數據密集型應用中的關鍵路徑,然后對關鍵路徑上面的關鍵任務所需要的時間進行求和,從而得到數據密集型應用的完成時間。
算法1 數據密集型應用的完成時間
輸入 數據密集型應用
輸出 數據密集型應用的完成時間D
2、外部信息溝通不順暢。電力企業(yè)為更好地實現往來賬款信息的及時清理,建立了有關往來款核對的第三方平臺,用于信息的及時核對。但現實操作中,往往會出現一家供應商與多個業(yè)務部門之間的往來業(yè)務,導致最終的詢證函發(fā)放工作還在財務部門。這種一對多的往來信息核對無法依靠第三方平臺實現,很容易因財務的人工核對造成錯誤。
初始化關鍵任務集合V
for 所有的宕機任務結點 do
根據式(1)、(2)計算任務的最早開始時間和最早結束時間
根據式(3)、(4)計算任務的最晚開始時間和最晚結束時間
if 該任務的最早開始時間和最晚開始時間相等 do
將該任務放置到關鍵任務集合V中
end if
end for
其中,計算結點和TOR層交換機之間的帶寬表示為rst,TOR層交換機與匯聚層交換機之間的帶寬表示為rta,匯聚層交換機與中繼層交換機的之間帶寬表示為rau。
if 該任務是tstart
首先討論超級人工智能。超人無比強大。對于人類與超人的關系,不是人類面對超人人類該怎么辦,因為人類根本沒有應對能力,根本無法控制超人,而是超人會如何對待人類。
fortstart的后繼任務
選擇tstart需要花費時間最長的后繼任務ti
D+ti完成所需要的時間+數據傳輸時間
end for
要做到“兩個過程”的合理性,即從數學知識發(fā)生發(fā)展過程的合理性、學生認知過程的合理性上加強思考,這是落實數學核心素養(yǎng)的關鍵點.前一個是數學的學科思想問題,后一個是學生的思維規(guī)律、認知特點問題.
end if
end for
返回數據密集型應用的完成時間D
3.2 基于NSGA-III容錯性資源配置方法
基于以上的分析,恢復任務的計算結點需要獲取宕機任務的鏡像數據和該任務前驅任務所產生的數據,首先假設宕機任務ftz的鏡像數據大小為dmz,則在psd上獲取該任務的鏡像數據所需要的時間hsmz可以表示為:
1)基因操作:在遺傳算法中,基因操作分別是交叉和變異。其中交叉(Crossover)是指通過將兩條父母染色體經過交換部分基因的方式產生兩個新的后代,這樣產生的子代染色體會繼承優(yōu)良基因從父母,并且可以形成子代染色體自身獨特的基因型,方便找到最優(yōu)解。此外,突變(Mutation)作為另一種基因操作,染色體通過小概率的基因突變會使得該染色體上的一個基因型被該染色體上的另一個等位基因所取代,從而形成一個新的個體。通過多次基因操作有效提高了種群的多樣性,加快了目標解的結果收斂。
根據公式(1)計算出來的最早開始時間和完成任務所需要花費的時間ei,任務的最早結束時間可以由下式計算出來:
3)選擇優(yōu)化:事實上,由于NSGA-III可以生成多個表示故障任務資源供應策略的解決方案。因此,為了得到最優(yōu)解,實現了簡單加權法(Simple Weighting Method, SAW)和多準則決策(Multiple Criteria Decision Making, MCDM)從多種策略進行歸一化處理,從而選出最優(yōu)資源配置策略。使用SAW和MCDM計算每個解決方案的效用值,并選擇效用值最大的解決方案作為最終的資源配置策略。假設EiD和FiD分別表示兩個目標的值,EDmax、EDmin、FDmax和FDmin分別表示兩個目標函數的最大和最小值。此外,ε1和ε2作為數據密集型應用完成時間和負載平衡的權重指標,兩者之和為1。
FFD:該方法的核心思想是首先將云平臺中還在正常運行的計算結點按照剩余容量進行升序排序,然后每一個宕機任務將在剩余容量可以滿足該任務的計算結點重啟,該方法最大的特點就是一旦找到能夠滿足該任務的計算結點就不再繼續(xù)找其他更合適的計算結點了。
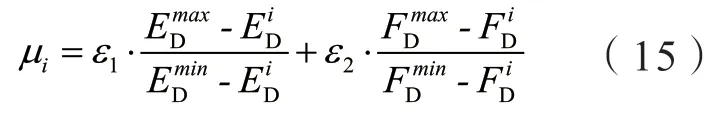
4 實驗評估
4.1 實驗環(huán)境
本實驗是在一臺配有Intel Core i7-5500U 處理器和8GB 內存的電腦上完成的。本文使用云平臺發(fā)生錯誤后數據密集型應用的完成時間、云平臺的負載均衡這兩個評估標準來展示FRPM的在動態(tài)資源分配的優(yōu)越性。此外,實驗中使用的VL2網絡拓撲結構搭建的云平臺的具體參數如表1所示,網絡的具體參數配置是根據文獻[18]而來。
在我國,小麥的面積和總產僅次于水稻和玉米,為第三大糧食作物,在國民經濟中占有重要地位。面粉顏色是小麥品質評價的重要指標,而籽粒黃色素含量是影響面粉顏色的主要因素。因此,研究小麥籽粒黃色素含量形成機制及其相關基因,對我國小麥面粉顏色品質改良具有重要意義。

表1 參數設置
4.2 對比方法
為了充分展示出FRPM的性能,在本文實驗過程中選擇了Benchmark、FFD和BFD[5,9]進行比較,三種方法的基本原理如下:
非線性偏微分方程有很多的應用,尤其是非線性方程的孤子解,在工程、光纖和物理等領域都起著很重要的作用。因此求解非線性偏微分方程的孤子解變得越來越重要了,但是它的求解是非常困難的,尤其是高階非線性偏微分方程。直到最近幾十年,隨著計算機軟件的發(fā)展,如MATLAB、Mathematica等,許多的求解非線性偏微分方程孤子解的方法被提出,非線性方程求解方向獲得很大發(fā)展[1-16]。
Benchmark:該方法的核心思想是為每一個宕機任務隨機選取一個正常運行的計算結點進行恢復。
鄂麥398田間綜合抗病性較好,但抗性鑒定結果表明該品種高感條銹病和紋枯病、中感赤霉病和白粉病,生產中應注意防治條銹病、紋枯病、赤霉病和白粉病,搞好“一噴三防”。
5.統(tǒng)一規(guī)范,把好項目資料關。規(guī)范基礎工作是審計項目順利開展的前提和保障,審計組長在強化審計項目質量的同時,要擯棄“重成果、輕基礎”的錯誤導向,按照“規(guī)范、全面、標準”的要求,實行審計基礎工作標準化管理,保證審計資料歸檔的及時性、準確性、完整性,促進審計質量和工作效率的提高。
BFD:該方法的核心思想是首先將云平臺中還在正常運行的計算結點按照剩余容量進行升序排序,然后每一個宕機任務將在剩余容量剛好滿足該任務的計算結點重啟,該方法最大的特點就是宕機任務找到的重啟任務的計算結點的剩余容量是所有正常運行計算結點中最小的。
4.3 實驗結果與分析
4.3.1 應用完成時間對比
數據密集型應用的完成時間是評價宕機任務恢復方法的關鍵標準。在云平臺的計算節(jié)點發(fā)生故障后,宕機任務需要得到有效的恢復以使得數據密集型應用的完成時間盡可能短。在本實驗過程中,首先隨機選取五個宕機任務,而后每次向宕機任務集合中添加兩個宕機任務。在數據密集型應用的完成時間這一指標中,Benchmark、BFD、FFD和FRPM的實驗結果如表2所示。其中,Benchmark、BFD和FFD算法所為宕機任務找到資源配置策略雖然能夠使得任務得到恢復并繼續(xù)執(zhí)行,但是算法在執(zhí)行過程中未考慮到數據密集型應用的整體的完成時間,而FRPM方法在迭代尋找資源配置的過程中始終將數據密集型應用的完成時間作為考量指標,所以也就導致使用Benchmark、BFD和FFD對宕機任務進行恢復后的完成時間明顯長于FRPM。此外,在實驗過程中為了避免FRPM所找出的資源配置策略出現局部最優(yōu)解,所以對FRPM所得出的解借助SAW和MCDM進行了歸一化處理,從而避免出現局部最優(yōu)解的問題。
“當然有啊,”陸教授說,“古代又沒有電腦制圖,也沒有現代化的造幣機,那么第一批樣錢,也就是我們說的雕母,當然是純手工造的啊。而且肯定比別的錢造得精細。要是樣品都造得隨隨便便,成品錢就不象樣了。”

表2 數據密集型應用完成時間對比 (單位:秒/s)
4.3.2 平均資源使用率對比
大量的計算資源被部署在云平臺以滿足用戶對計算能力的需求,一般情況下,云平臺的計算資源是希望被充分利用,所以云平臺的計算資源是否被充分利用也是衡量資源配置策略有效性的重要因素。在本文中,通過計算每個計算節(jié)點所占用的虛擬機數量來評估云平臺的平均資源利用率。如表3所示,對比了Benchmark、BFD、FFD和FRPM在 不 同宕機任務情況下的云平臺的平均資源利用率。可以看出:由于FRPM在為宕機任務進行資源配置時對當前云平臺所有計算結點的資源使用率進行了充分考量,所以隨著宕機任務數量的增加,云平臺的資源利用率也隨之增大;而Benchmark、BFD和FFD在進行資源配置的時候僅考慮單一計算結點的資源使用率,并沒有考慮云平臺整體的資源使用率,所以不能為宕機任務進行均衡的資源配置。
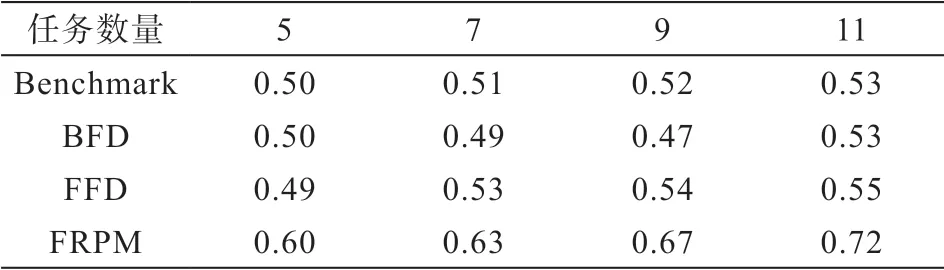
表3 平均資源使用率對比(*102%)
4.3.3 負載均衡對比
負載均衡作為宕機任務恢復方法的一個重要評價指標,一方面,當云平臺總體保持負載均衡時可以在最大程度上發(fā)揮各計算結點的性能。另一方面,當云中的所有計算節(jié)點都保持負載平衡狀態(tài)時,所有的計算結點都處在較為穩(wěn)定的狀態(tài),降低了計算節(jié)點出現問題的風險,在一定程度上提升了云計算中心的容錯性。一般情況下,負載平衡方差的值越小,就表示云計算中心所有計算節(jié)點的負載平衡越好。如表4所示,隨著宕機任務數量的增加,在Benchmark、BFD、FFD和FRPM對宕機任務進行資源配置之后,云計算中心計算結點的負載均衡方差都在隨之增加。其中,FRPM所得到的負載均衡方差值最小,BFD的負載均衡方差比FRPM大,而Benchmark和FFD得到的負載均衡方差值最大。主要原因時由于Benchmark和FFD在為宕機任務進行資源配置的過程中不考慮各計算節(jié)點的負載而直接進行資源配置,所以導致兩種算法在為宕機任務進行資源配置的時候云計算平臺的負載均衡方差值相差無幾;BFD在為宕機任務進行資源配置的時候,首先會考慮最所剩容量適合宕機任務的計算結點,所以使得云計算中心的負載較好;而FRPM在尋找宕機任務資源配置策略時會綜合考量云計算中心所有計算結點當前所處的負載狀態(tài),因此得到的資源配置策略使得云計算中心處于更好的負載均衡狀態(tài)。
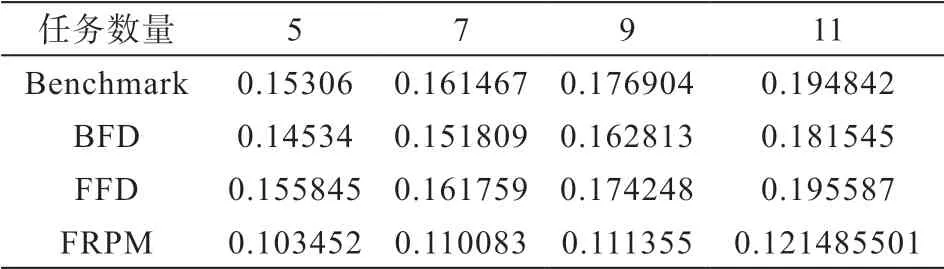
表4 負載均衡對比
5 結束語
在本文中,為了保證在云平臺發(fā)生故障時,部署在云平臺的數據密集型應用的完成時間最短的同時,云平臺的負載均衡也能得到有效的保證,本文提出了一種基于NSGA-III的FRPM方法。該方法為云平臺中發(fā)生錯誤的數據密集型應用進行有效的資源配置以保證數據密集型應用在云平臺發(fā)生宕機時的完成時間最短的同時,也能夠保證云中所有計算節(jié)點的負載均衡。最后,通過大量的實驗對FRPM的有效性進行了驗證。在未來的工作中,在恢復宕機任務過程中,應用數據的隱私問題需要被考慮。
大數據時代下,企業(yè)的發(fā)展依賴于信息化平臺的建設,資源共享平臺建設是會計信息化的重要發(fā)展趨勢和前進方向。資源共享平臺的構建會為管理者決策行為提供可靠保障,為了避免會計信息化發(fā)展過程中信息孤島的出現,資源共享平臺的開拓有著十分重要的意義。
