基于局部密度信息熵均值的密度峰值聚類算法
2022-03-30 07:13:14唐風揚覃仁超
計算機測量與控制 2022年3期
唐風揚,覃仁超,熊 健
(西南科技大學 計算機科學與技術學院,四川 綿陽 621010)
0 引言
近幾年,隨著全球存儲信息量與數據量的爆炸式增長,在給各行業帶來機遇的同時也帶來了巨大的挑戰,即如何高效地處理這些信息與數據。聚類算法作為數據處理的關鍵技術,本質是將一組數據劃分為不重疊的子集的過程,每個子集都是一個聚類,所以同一聚類中的點彼此相似,而與其他聚類中的點不相似。聚類算法不僅是數據挖掘的一種重要手段,還是機器學習理論與技術中的重要數據預測和分析方法之一,在模式識別[1]、圖像處理[2]、文獻計量學,生物信息學等領域得到了廣泛應用。
1 研究現狀
聚類算法常用在無監督學習中,算法通過學習未作標記的樣本以此來揭示數據的內在規律,完成數據的分類。隨著近年來不斷的深入研究,通常將其分為以下幾類,基于劃分的聚類如K-MEANS[3]算法,然而該算法聚類效果的好壞取決于人工選擇的聚類中心且有著對樣本中的異常點敏感的缺點。為此衍生出了利用聚類中心相互間隔距離較遠思想的K-MEANS++算法,雖然方法簡單,但非常有效;而改變中心點選取策略的K-MEDOIDS算法在小樣本的數據中有著更好的噪聲魯棒性;利用遺傳算法,粒子群等優化算法進行初始值尋優的多種改進方法都有著良好效果。其他經典算法中有將空間劃分為矩陣,基于網絡多分辨率聚類技術的STING[4]算法和利用層次方法進行聚類和規約數據的BRICH[5]算法。DBSCAN[6]算法作為具有代表性的密度聚類算法,提出了密度可接近性與密度可連性的概念,將具有足夠密度大小的區域劃分成簇,在帶噪聲的空間中能識別形狀各異的簇,但參數的人工選擇限制了算法的效果。而為了解決這個問題,OPTICS[7]算法應運而生,算法為聚類的分析生成簇的排序,從這個排序中可以得到DBSCAN算法的多種聚類結果。這些算法在性能上有很大差異,如K-MEANS只能識別凸球形簇,STING算法具有很快的速度,但是準確度不高,而BRICH算法可以簡單對數據進行預處理并識別噪聲點,但在數據是非超球體的分布簇的情況下效果一般。DBSCAN在不規則簇的識別上效果顯著,也有不錯的抗噪聲能力,但在面對數據維度升高時效果明顯下降[8]。
2014年6月,Rodriguez等人在Science上發表了DPC[9]算法,這是一種基于距離和密度的算法,能夠找到任意形狀的聚類中心,與傳統算法相比,該算法無需迭代目標函數就能找到高密度點,并且實現簡單。然而該算法需要通過經驗設置距離閾值dc完成密度的計算。目前為止許多學者對算法進行了改進,其中一部分改進算法根據數據集自身數據情況自適應求得最佳距離閾值dc[10-14],這種做法一定程度上優化了距離閾值dc的選擇,但各方法的適用數據集不同。文獻[15]通過構建Ball-Tree 縮小樣本局部密度和距離的計算范圍減少了計算量,文獻[16]基于塊的不相似性度量計算樣本間的相似度,引入樣本的 K近鄰度量,定義新的局部密度。文獻[17]等通過改變聚類中心的定義,并將鄰域中的密度極值點確定為聚類中心,然后會選擇到超過簇數目的聚類中心,文獻[18]等引入K近鄰的思想來計算距離閾值dc和每個點的局部密度,文獻[19]等定義了從屬的概念來描述相對密度關系,并使用從屬的數量作為識別聚類中心的標準。文獻[20]等利用網絡劃分的方法,解決計算歐氏距離時花費過多時間的問題。文獻[21]等不僅引入KNN思想解決局部密度的計算,并且運用PCA對高維數據降維。
本文針對距離閾值dc選擇存在的問題,定義局部密度捕獲范圍并利用局部密度信息熵均值進行優化,通過設置距離閾值一定倍數的參數確定局部密度捕獲范圍,使得在分類錯誤的情況下通過對相對距離進行密度的加權重新獲得正確的分類數量和分類中心。通過DPC算法與信息熵的結合使用,即使在不規則圖形中也能夠排除異常點的干擾,準確快速地找到正確的分類中心和分類數量,實驗證明在不同的數據集中均取得了良好的效果。
2 密度峰值聚類算法
2.1 算法原理
DPC算法認為簇中心擁有如下特征:(1)數據點與其他密度大的點有相對遠的距離[22];(2)數據點本身密度大于包圍它周圍的點。通過定義ρi和δi來表示數據點的密度與相對距離,然后選取兩者中雙方值都相對較大的點作為簇中心,最后將其他非中心點歸到其最近的更高密度點完成聚類。
2.2 算法過程
首先通過計算得到對于數據集S={x1,x2,x3,...,xn}中,數據點xi與xj的歐氏距離dij,計算公式如式(1):
(1)
計算數據點xi的局部密度ρi。
截斷核計算公式如式(2):
(2)
dij為數據點xi與xj的歐式距離,dc為能囊括總數據量1%至2%的距離閾值,其中函數X如式(3)所示:
(3)
高斯核計算公式如式(4):
(4)
截斷核以離散值估計出的密度全為整數,有重復值,而高斯核以連續值估計出的密度因此不會產生重復值,因此當不同點擁有相同局部密度的情況下使用高斯核進行計算會取得更好的效果,故本文中采取高斯核密度計算公式。
計算數據點xi的相對距離δi,公式如式(5)~(6):
(5)
(6)
公式(5)中δi表示對于數據點xi,到有高于它局部密度點的最近距離,(6)中δi是當其數據點xi在數據集S中局部密度最大時的距離。一般密度大的數據點的距離參數δi要比其它鄰近點大。
在計算完每個點的局部密度ρi和相對距離δi之后,以密度為橫坐標,相對距離為縱坐標畫出相對距離/密度圖在其中選取密度和距離值相對大的點作為聚類中心。不過文獻[4]中提到通過設置決策函數:
γi=ρi×δi
(7)
來繪制決策圖賦值確定聚類中心。其中具有更大γi的點xi會具有更高成為聚類中心點的可能性。為此,將γi降序排序,在二維平面圖中畫出決策圖,找到γi較大的點xi作為聚類中心,DPC算法將非中心點歸并到密度比當前點高且距離最近點以完成聚類。
2.3 算法的不足
DPC極其依賴參數距離閾值dc的選擇,相同的數據集在不同的距離閾值dc下有非常大的差別,在Rodriguez等人的文章中指出dc選擇能囊括總數據的1%~2%數量(下文簡稱dc=n%)的數值,這種局限性突出在一些特殊的數據集中,并且對不同的數據集難以進行距離閾值dc的選擇。
目前普遍認為距離閾值dc選擇過小時,可能會在同一簇內找出多個密度峰值,從而得到過多的聚類中心導致聚類失敗,極端情況下距離閾值dc小于數據集中各個點的最小歐氏距離,這時每個數據點都將單獨成為一個類別;如果距離閾值dc選擇過大,會使得區分度過低,從而不同的簇往往會被分到同一聚類中心,導致簇中心的少選從而聚類失敗,極端情況是距離閾值dc超過了數據點中各個點的最大歐式距離,這會把所有數據歸為一個類別。
3 基于局部密度信息熵均值優化的聚類算法
3.1 信息熵
假設X為隨機型離散變量,那么它在有限范圍內的取值R={x1,x2,x3,...,xn},而其中xi出現的概率為Pi,同時設Pi=P{X=xi},則對于x信息熵的公式定義為式(8)所示:
(8)
信息熵作為一種計算屬性權重的經典算法一般用來計算數據的離散度。熵值一般與離散程度成反比,即數據某指標越小的熵值說明該指標離散程度越大,同時該指標也有更大的信息量。
3.2 局部密度捕獲范圍
針對DPC算法在計算相對距離和密度時并未考慮數據點空間分布特性的影響,而是從全局的角度出發通過使鄰近樣本數占比達到全部樣本的一定數量,計算距離閾值來確定密度進而算出相對距離的時候數據密度和相對距離分布不均勻,多個密度峰值被劃分至同一個聚類中心和一個簇中心存在多個密度峰值的問題。
本文提出一種局部密度捕獲范圍,用來捕獲數據點附近一定范圍內的點以供后續計算使用,通過設置參數w來確定某點的局部密度捕獲范圍。
定義1:局部密度捕獲范圍。局部密度捕獲范圍表示能包含某一區域內全部數據點的范圍,記作w如式(9)所示:
w=c×dc
(9)
其中:參數c在多次實驗中顯示取距離閾值dc的0.5~5倍時有最佳效果。
3.3 局部密度信息熵均值的計算
本文中將信息熵與局部密度相結合,通過計算某點的局部密度信息熵均值,確定該點相對于周圍點的密度分布情況。相對距離相近但局部密度不同的點,在決策圖上通常難以區分,但可以通過以其相對距離乘以局部密度信息熵均值來解決,在相對距離相近的情況下,局部密度相差小的點相對局部密度相差大的點擁有更大的局部密度信息熵均值,從而讓局部密度相差大的點的相對距離變小,進而使決策圖中的相應的值變小,以此來區別出數據密度點中可能被誤分為聚類中心的點。
定義2:局部密度信息熵均值。局部密度信息熵均值表示局部范圍內數據點的分布情況,某一點的局部密度信息熵的值與該點附近密度分布離散程度成反比,記作H(X)。
局部密度信息熵均值的計算公式如式 (10)所示:
(10)
其中:
(11)
N為點xi半徑小于局部密度捕獲范圍w內的所有點的數量。
在加權之后由于權數值較小,故為使加權效果更加顯著,在反復實驗中類比sigmoid,log等函數之后發現log一類的對數函數由于沒有明確上界會將密度較大的點的相對距離過于放大,從而難以產生效果,而sigmoid函數無法產生有效的區分度,但使用反正切函數acrtan能夠更好地將正確簇中心與錯誤簇中心區別,故選用使用反正切公式來處理H(X)得出全新加權系數H′(X)如式(12)所示:
(12)
3.4 加權后相對距離
使用原相對聚類δ新加權系數H′(X)相乘得到加權后相對距離δe如式(13)所示。
δe=H′(X)×δ
(13)
3.5 新的決策函數γe
使用新的加權相對距離δe與密度ρ相乘得到γe如式(14),從而繪制新的決策圖。
γe=ρ×δe
(14)
3.6 聚類中心的選取
如圖1所示,點A和點B屬同一簇,但點B具有較高的局部密度和距離δ,在DPC中在距離閾值dc取值較小時會把A,B點看作兩個聚類中心點,而LDDPC算法通過對相對距離δe進行加權,使得B的相對距離δe變小,從而將A,B點歸為同一簇中完成正確的聚類。

圖1 錯誤聚類示例
經過反正切公式(11)和相對距離加權公式(12)的運算之后,在γe上決策圖的聚類中心變得清晰可分。在決策圖中很容易看到非聚類中心點之間排列緊密,且相互之間的差值非常小,這時只需選取決策函數γe較大且相互差距大的點作為聚類中心即可。經LDDPC算法處理后相比DPC算法能夠更快速更直接地選取正確的聚類中心。
4 算法流程
算法處理流程如下。
步驟1:輸入待檢測的數據集S={x1,x2,x3,...,xn}和dc以及參數w;
步驟2:將數據集按照公式(1)求出歐氏距離;
步驟3:分別代入公式(4)~(6)求出每個數據點xi的ρi與δi;
步驟4:按照公式(10)~(12)算出每個數據點的局部密度信息熵均值H(X)和加權后的系數H′(X);
步驟5:根據公式(13)和公式(14)算出加權后每個點xi的相對距離δei以及γei;
步驟6:根據γe的決策圖計算出聚類中心;
步驟7:將每個數據按照最近距離數據點的類別分類;
步驟8:輸出實驗結果。
5 實驗與分析
5.1 實驗環境
LDDPC算法通過python3.7.9實現與處理。實驗環境:操作系統為win10 64位,CPU為I5-7300HQ,主頻2.5 GHz,內存為16 G。為了驗證算法性能,將在下文的實驗中把DPC算法與LDDPC算法效果相比較。
5.2 實驗說明
實驗一與實驗二數據集詳見表1,為了驗證算法的有效性和適應性,故實驗中選取的dc值中即有小于1%,大于2%也有1%~2%正常取值區間內DPC算法無法正常發揮效果的值,通過實驗驗證錯誤聚類中的聚類過多和過少的情況下LDDPC算法仍能發揮的效果。

表1 實驗一與實驗二所用數據集
5.3 實驗一:DPC算法分類錯誤時通過LDDPC算法獲得正確分類
圖2至圖4為在Aggregation數據集中,當dc=1.3%時的效果圖,決策圖和聚類結果圖,圖2為密度ρ和相對距離δ的原始分布,圖(a)為原始算法得出的分布情況而圖(b)為LDDPC算法處理后(即密度ρ和加權后相對距離距離δe)的分布,圖3和圖4中可以看到圖(a)DPC算法中簇數過多而導致分類的失敗,決策圖中能看到超過簇數7個的相對大的γ值,而圖(b)LDDPC算法處理后,在決策圖上能夠明顯分辨出7個相對大的γe值,從而成功分為7個類。在圖5至圖7為數據集Flame中,為dc取值為3.6%時的對比圖,從圖5(a),圖6(a),圖7(a)中可以明顯看出距離閾值取值的失敗導致出現4個簇中心的多分類情況,此時同一個簇中擁有多個聚類峰值,而在圖5(b),圖6(b),圖7(b)中在LDDPC算法的處理下決策圖中僅出現2個相對較大的γe值,說明同一簇中多余的聚類峰值的消失,于是數據成功分成2個類別。

圖2 在Aggregation數據集下的相對距離/密度圖對比圖

圖3 在Aggregation數據集下的決策圖對比圖

圖4 在Aggregation數據集下的聚類結果對比圖
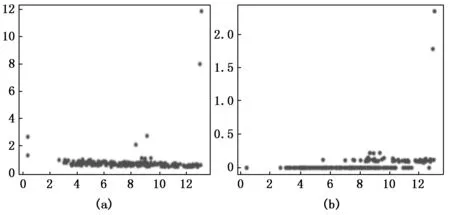
圖5 在Flame數據集下的相對距離/密度對比圖

圖6 在Flame數據集下的決策圖對比圖

圖7 在Flame數據集下的聚類結果對比圖
通過實驗可以看到以上數據集均被錯誤地分成了多個類別,并且從決策圖可以看出分布并不明顯,稍有不慎就會誤選,將密度ρ和相對距離δ乘積γ較大的點選為聚類中心,導致同一簇中存在多個聚類峰值的情況,而在LDDPC算法下通過γe構建決策圖從而被正確的分類,并且新決策圖中γe值顯示非中心點與中心點具有更大的差值,相比原決策圖更加清晰可分,不會因不慎而錯選多選而導致出現不正確的簇數的情況出現。
5.4 實驗二:DPC算法分類正確時獲得更加清晰的決策圖
圖8至圖10展示了R15數據集在dc=2%時正確聚類情況,通過圖8和圖9的對比可以看出,在LDDPC算法的處理下,相比DPC算法中原來的相對距離δ,經局部密度信息熵加權后的加權相對距離δe具有更大的值,聚類中心點和非中心點在新決策圖中的γe值與原決策圖中的γ值相比差值變大,這使在決策圖中尋找聚類中心時更加容易。同理圖11至圖13是數據集D31在dc=2%時,經過LDDPC算法處理前后的對比,圖11(a)與圖11(b)相比DPC算法區分度更明顯,相對距離δ整體上移,在決策圖中同樣體現為γe值的整體上移,與R15中同樣在處理后增加了決策圖的辨識度,能夠更好地把真實簇中心從其他高密度峰值的虛假簇中心中分離,從而能夠更加精確快速地完成31個類別的數據集的分類。

圖8 在R15數據集下的相對距離/密度對比圖

圖9 在R15數據集下的決策圖對比圖

圖10 在R15數據集下的聚類結果對比圖

圖11 在D31數據集下的相對距離/密度對比圖

圖12 在D31數據集下的決策圖對比圖

圖13 在D31數據集下的聚類結果對比圖
以上實驗說明數據集在LDDPC算法處理過相對距離δ之后在不影響DPC算法本身效果的同時還使得在決策圖上尋找聚類中心時更加容易。
5.5 實驗三:高維數據集測試
為了進一步驗證算法的有效性,實驗三中選取了UCI數據集中的3個高維數據集分別為Iris,Wine,Seed進行測試,實驗選用的數據集詳細信息如表2,DPC與LDDPC算法實驗結果的對比如表3。

表2 實驗三所用數據集

表3 實驗三實驗結果
實驗三在dc值的選擇上仍然選擇了一個小于1%,一個大于2%,一個介于1%~2%之間且分類錯誤的3個具有代表性的dc值。在圖14中可以看到(a)圖被誤分成了2類,而(b)圖中決策圖上出現了3個γe值相對大的點,通過對相對距離進行的加權找到了隱藏的真實聚類中心,即一共3個正確的聚類中心;而圖15(a),圖16(a)圖中被多分成了4類的情況下,經過LDDPC算法處理之后明顯看到決策圖上γe值相對大的點由4個變為3個,即通過對相對距離的加權使同一簇中原有的兩個密度峰值減少為一個,排除了錯誤的聚類中心,數據集成功地被重新分成了正確的3類,測試效果表明算法在DPC分類錯誤時能夠使分類正確,且可以明顯提升算法的準確率。

圖14 在Iris數據集下的決策圖對比圖

圖15 在Wine數據集下的決策圖對比圖

圖16 在Seed數據集下的決策圖對比圖
6 結束語
針對傳統的DPC算法在距離閾值選取不當時無法正確分類的情況,本文提出了局部密度捕獲范圍和利用局部密度信息熵均值的加權算法(LDDPC),成功在距離閾值使分類錯誤的情況下通過對數據點的相對距離進行其局部密度信息熵均值的加權使分類正確。該算法克服了DPC算法對距離閾值取值敏感的缺點,在數據集上的實驗結果可以證明,通過LDDPC算法在DPC算法的距離閾值取值不當導致分類錯誤時,得以正確分類,并且提高準確率。
