面向建設期鐵路大數據的分級存儲方法研究
2022-03-30 03:45:06廉小親程智博王萬齊吳艷華
鐵路計算機應用 2022年2期
廉小親,楊 凱,程智博,王萬齊,3,吳艷華
(1. 北京工商大學 人工智能學院,北京 100048;2. 中國鐵道科學研究院集團有限公司 電子計算技術研究所,北京 100081;3. 國家鐵路智能運輸系統工程技術研究中心,北京 100081)
我國鐵路正快步邁入大數據時代[1],鐵路系統的數據總量己達到10 PB數量級[2],其中,包含大量鐵路路段建設期的數據[3]。然而,在傳統的單節點數據存儲模式下,數據訪問效率和存儲介質性能較低[4],因此,需要搭建一種分布式的數據分級存儲系統[5],并建立相應的數據評價體系[6],來實現業務層面的數據高效分級存儲。
鐵路大數據的分級存儲問題是當前的研究熱點[7]之一。郭歌等人[8]以鐵路基礎設施各階段用例為中心,通過對鐵路基礎設施數據進行層次化分析,形成一個可支撐鐵路全生命周期應用的數據共享模型體系;王沛然等人[9]設計了一種鐵路大數據服務平臺存儲架構,針對不同業務、不同類型的數據采用不同的數據庫進行存儲,并根據數據的訪問頻次將數據分為冷數據和熱數據;彭劍峰等人[10]從鐵路大數據的敏感度特點出發,從多個維度對鐵路大數據進行分類分級。
本文分析了鐵路建設期大數據的存儲與管理需求[11],以海量建設期數據為研究對象,設計面向多源、異域、跨系統、多類型數據的分級存儲架構及策略,有效提高數據的訪問效率及數據庫的利用率,增強平臺存儲性能、降低存儲成本。
1 分級存儲架構設計
1.1 主流大數據分級存儲架構
目前主流的大數據分級存儲系統通常以數據的生命周期為依據,將數據庫劃分為在線存儲數據庫、近線存儲數據庫及離線存儲數據庫,其存儲架構如圖1所示。

圖1 主流大數據分級存儲架構
在線存儲數據庫用來存儲當前訪問頻率最高的熱數據,以便數據申請者得到快捷、及時的響應。為保證更好的數據訪問性能,在線存儲數據庫多采用性能較高的存儲設備[12],例如固態硬盤等。近線存儲數據庫主要用來存儲訪問頻次相對較低的溫數據,且對訪問速度要求較低,因此,近線存儲設備往往具有較高的存儲容量,同時,在可接受的時間范圍內向用戶反饋數據,主要采用磁帶庫或低端磁盤設備。離線數據主要用來存儲訪問頻率最低的冷數據,這部分數據很少再被訪問到,主要采用光盤、磁帶庫等設備[13]。
1.2 鐵路建設期大數據分級存儲架構
鐵路建設期業務繁多,數據種類復雜[14],從數據類型角度看,包含結構化數據、半結構化數據和非結構化數據,且數據量日漸龐大,原有的大型計算機基于此類存儲任務的負荷也越來越重,目前,將計算機組成集群對海量多源異構數據進行分級存儲是一種可行、可靠、高效的模式[15]。本文在圖1所示的分級存儲架構基礎上,結合鐵路建設期系統的業務特征,搭建了一種基于非關系型數據庫、關系型數據庫及分布式文件系統的鐵路建設期大數據分級存儲架構,并在中間件判定該數據對應的存儲級別,使得數據能夠合理的存放在指定數據庫中,存儲架構如圖2所示。
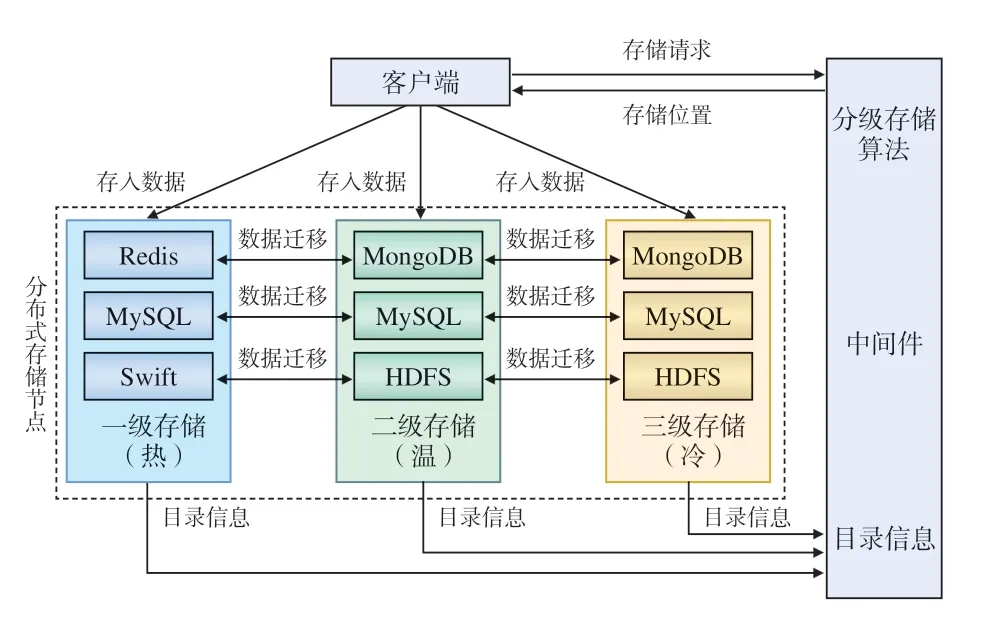
圖2 鐵路大數據分級存儲架構
鐵路大數據分級存儲系統架構包括客戶端、中間件及分布式存儲節點3部分。其中,分布式存儲節點包含三級存儲,一級存儲節點中包含Redis數據庫、MySQL數據庫和Swift分布式文件系統,以存儲鐵路建設期的熱數據;二級和三級存儲節點中包含MongoDB、MySQL數據庫和HDFS,分別存儲鐵路建設期的溫數據和冷數據。
當客戶端產生的數據需要進行存儲時,向中間件提交存儲請求,該存儲請求包含數據格式、數據大小、數據所屬業務系統等基本信息,中間件中的鐵路大數據分級存儲算法會根據上述基本信息和當前存儲系統中各級存儲的目錄信息計算數據價值,判定該數據對應的存儲級別,并反饋至客戶端,客戶端即可根據存儲級別確定存儲位置,將數據存放至指定的數據庫中,從而實現數據的分級存儲。
2 分級存儲算法
2.1 分級存儲需求
鐵路大數據中的建設期數據包含進度、質量、統計匯總、評估預測等多方面數據,具有數據量大、涵蓋范圍廣、業務類別多、數據類型雜及產生頻率高的特點,僅從單一維度對數據進行級別劃分存在一定的局限性。因此,亟需針對建設期鐵路數據的業務特點,建立一種多維度、綜合性的鐵路建設期大數據分級體系和價值評價體系,以實現鐵路大數據分級存儲算法。
2.2 數據價值評價體系
本文以建設期結構化數據中的數據表為評價對象,根據鐵路建設期大數據特有的業務價值特點,提出以下評價指標,構建數據價值評價體系,如圖3所示。一級指標為數據表的數據價值;二級指標在一級指標的基礎上劃分為數據表業務特征指標和數據庫/數據表的自身屬性特征指標;三級指標既包含定性評價指標,也包含定量評價指標,定量評價指標為數據庫數據量大小指標、數據庫“增”行為操作量指標、數據庫“刪”行為操作量指標、數據庫“改”行為操作量指標和數據庫“查”行為操作量指標,此類指標數值定期通過日志文件進行更新。其余的三級指標均為定性評價指標,本文采用專家評價法對其進行價值判定[16],基本操作流程為:(1)對三級定性評價指標下的四級指標進行打分;(2)對四級指標的權重值進行打分;(3)以加權求和方式得到三級指標中定性指標的結果。
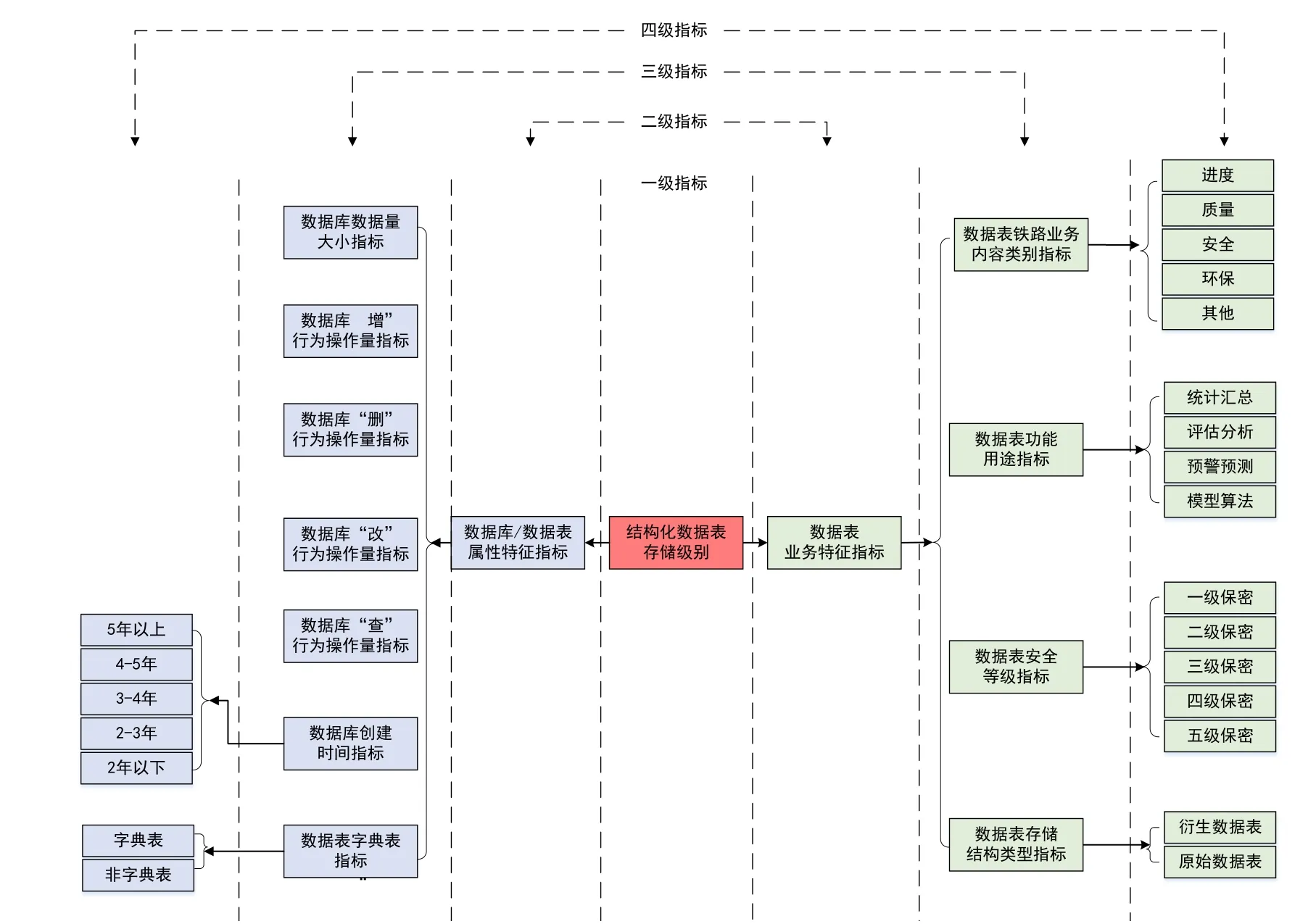
圖3 建設期鐵路大數據價值評價體系
2.3 基于K-means的數據價值判定算法
由2.2節可知,在數據價值評價體系中,每一張數據表均通過專家評價法和日志文件統計分析得到一組三級指標打分結果,而數據價值評價體系的一級指標為數據表的價值,因此需要建立數據表的價值與存儲級別之間的非線性映射關系,并根據數據表一級指標的統計信息決定數據表所在的存儲級別。
K-means聚類分析[17]是數據挖掘[18]中重要的無監督學習算法之一。與監督學習不同的是,該算法待處理的樣本數據集中沒有包含樣本分類相關信息。聚類是把數據集中的對象劃分成多個簇的過程,被廣泛應用于模式分類等領域。K-means算法簡單便捷、收斂速度快,在大數據分級存儲中使用能有效減少計算時間、提高存儲效率。故本文采用K-means聚類算法建立上述映射關系。
設定原始數據表三級指標矩陣V為:

其中,vji為第j(j=0,1,···,m?1)個數據表中第i(i=0,1,···,n?1)個三級指標的分值;m為數據表數量;n為三級指標數量。由于三級指標評價結果包含定性評價結果和定量評價結果,需要在同一評價指標維度下對各維度的數據進行歸一化處理,以消除數據量綱,同時,也可減小由于數據量級差導致的聚類誤差。三級指標歸一化矩陣K如公式(2)所示。
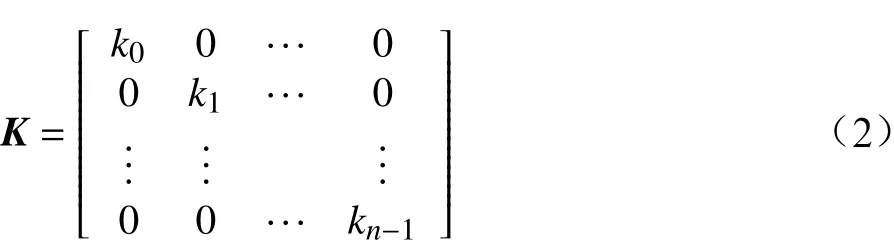
其中,ki表示第i+1個評價維度的歸一化尺度因子。歸一化后的三級指標矩陣X為:
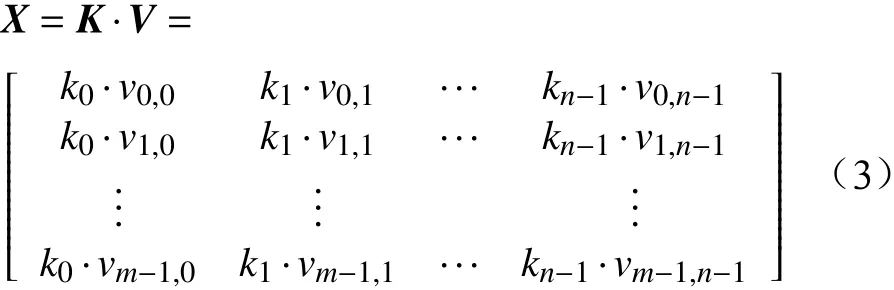
對矩陣X進行K-means聚類。由于本文搭建的數據分級存儲系統中包含三級存儲節點,因此,設聚類中心數量為3,聚類標簽集合為{“0”,“1”,“2”},設聚類后輸出結果向量為Y,K-means聚類模型為F(·),第j個數據表聚類結果為yj,則有:
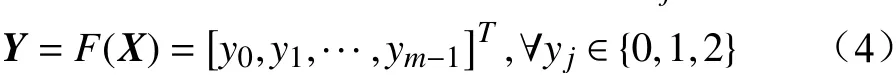
分別統計每一組聚類空間內所有樣本歸一化后三級指標各維度值的加權平均值Vp,如公式(5)所示。
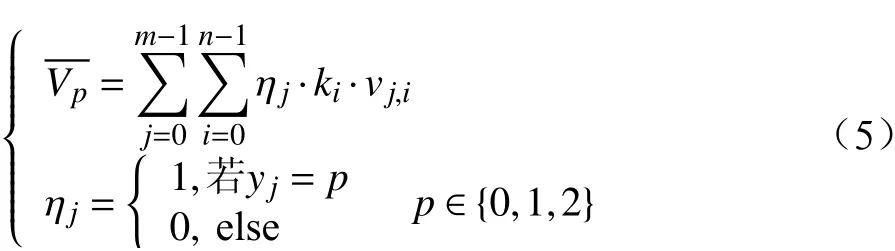
3 實驗驗證
為實現建設期鐵路大數據的分級存儲,本文搭建了基于NoSQL、RDB和DFS的分布式存儲系統,以建設期鐵路大數據中的結構化數據為主要研究對象,建立一套鐵路大數據價值評價體系,通過Kmeans聚類算法判定各類數據相應的存儲級別。其中,價值評價體系的可靠性和K-means聚類算法結果的準確性決定了本文提出方法的可行性和可靠性。
本節以脫敏后的鐵路建設期數據表和相應的訪問日志為實驗樣本,確定數據表在數據價值評價體系中各指標的專家評價結果及指標分值,利用Kmeans聚類算法判定數據表的分級存儲結果。
3.1 數據價值評價體系四級指標打分結果
本文以四級指標為評價維度,721張數據表的專家評價結果(部分)如表1所示,評價結果為“1”表明該數據表具有該項四級指標特征,評價結果為“0”表示該數據表不具有該項四級指標特征。

表1 四級指標專家評價結果(部分)
3.2 數據價值評價體系四級指標權重打分結果
通過專家評價法對數據價值評價體系中的四級指標分值進行打分,打分結果如表2所示。

表2 四級指標分值專家打分結果
3.3 數據價值評價體系三級指標數值計算結果
對表1和表2的評價結果進行加權求和,并對日志數據進行統計分析,計算所有實驗樣本的三級指標結果,如表3所示。表3中的指標1、2、3、4、9、10、11分別指代二級指標下差異較大的各項三級指標。
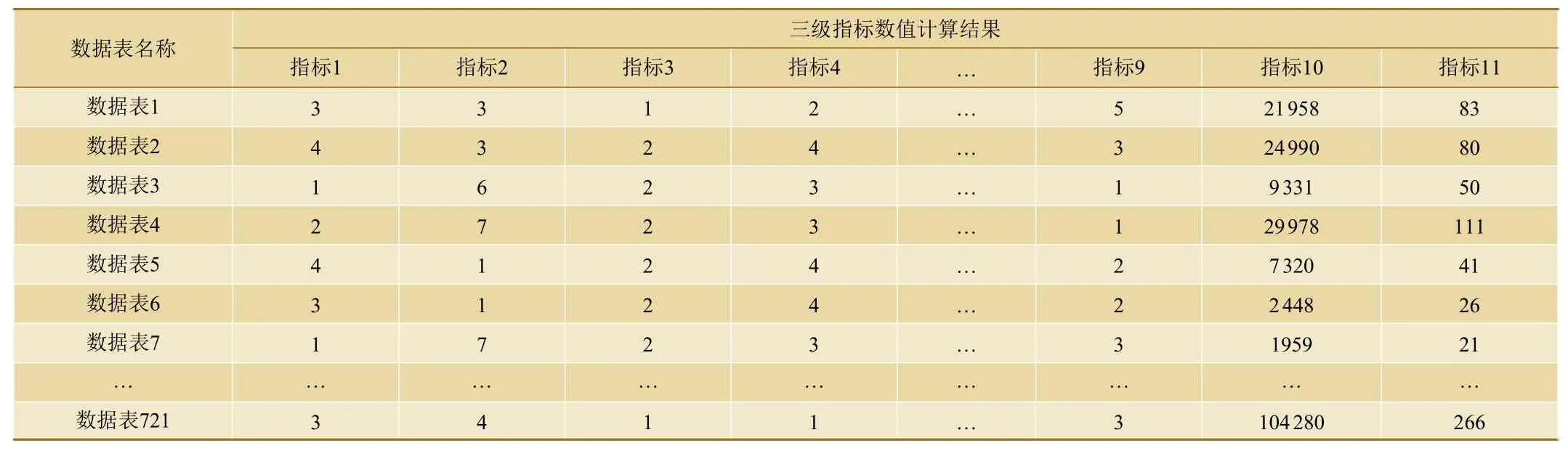
表3 三級指標數值計算結果
3.4 K-means聚類結果及分析
對表3中的三級指標數值計算結果進行歸一化處理,以{“0”, “1”, “2”}作為聚類結果標簽進行K-means聚類。聚類結果分布如圖4所示,將數據表三級指標各指標值求和即可得到各數據表的數據價值,數據價值分布如圖5所示。

圖4 數據聚類結果分布情況
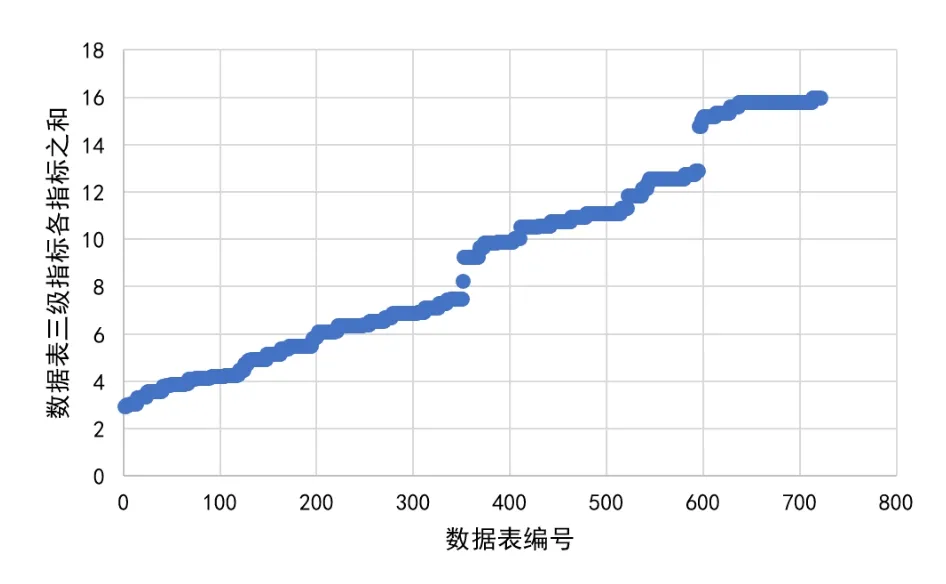
圖5 數據價值分布情況
由圖4和圖5可知,標簽“0”的數據價值相對分布明顯高于標簽“2”,標簽“2”的數據價值相對分布明顯高于標簽“1”,未出現明顯誤差,驗證了K-means聚類結果的準確性。
按照公式(5)分別統計每一組聚類空間內所有樣本歸一化后三級指標各維度值的加權平均值經計算,可知,標簽為“0”的數據表應存放至一級存儲節點,標簽為“2”的數據表應存放至二級存儲節點,標簽為“1”的數據表應存放至三級存儲節點。
4 結束語
本文結合了計算機領域數據分級存儲的思想,設計了一種面向建設期數據的鐵路分布式大數據分級存儲架構和分級存儲算法,實現建設期鐵路大數據分級存儲,提高數據的訪問效率及數據庫的利用效率,增強平臺存儲性能,降低存儲成本。實驗結果表明,本文提出的數據價值評價體系和分級存儲算法能夠有效的對建設期鐵路大數據進行存儲級別判定,為后續理論內容的工程化應用提供技術基礎。
本文也存在一定的不足之處,例如,本文提出的數據價值評價體系中,采用專家評價法進行打分,最終的計算結果很大程度上與打分人對指標的主觀判斷有關聯。因此,在后續研究過程中,可考慮采用主觀判斷和客觀分析相結合的方式,共同決定評價指標的最終取值,以此提高評價體系的可靠性。
猜你喜歡
云南畫報(2021年12期)2021-03-08 00:50:54
鐵道通信信號(2018年7期)2018-08-29 01:17:04
財經(2017年2期)2017-03-10 14:35:35
文理導航·科普童話(2016年7期)2017-02-04 15:09:20
小天使·四年級語數英綜合(2016年11期)2016-11-29 22:37:30
財經(2016年15期)2016-06-03 07:38:02
通信電源技術(2016年4期)2016-04-04 02:58:04
財經(2016年3期)2016-03-07 07:44:46
工程建設與設計(2016年3期)2016-02-27 10:50:46
財經(2016年6期)2016-02-24 07:41:51
