基于爬蟲技術的醫療行業輿情監控系統的設計與實現
2022-03-30 15:04:00孟慶昊李青君
科技創新與應用 2022年8期
孟慶昊,沈 妍,李青君,蘇 波
(首都師范大學 物理系,北京 100037)
以互聯網為媒介的網絡輿情信息是網民在特定事件中的態度、意見和看法,具有強烈的情感表達色彩[1]。在21世紀這個信息化的時代背景下,數以億計的用戶在微博上圍繞國家政策、民計民生、娛樂八卦等話題不斷產生出海量的體現著個人意志的輿情數據,若不加以引導,任由其肆意發展那么謠言重傷、惡語相向將會充斥著整個社會,由此可見建立一個完善的輿情監控體系顯得尤為重要[2]。
2020年新冠肺炎席卷全球,醫療行業受到社會廣泛關注,隨之而來的便是海量輿情信息的爆發,針對這一社會現狀,本課題以Python作為開發語言,設計實現一套基于爬蟲技術的醫療行業輿情監控系統。摒棄以往數據獲取方式,為解決數據信息獲取困難等問題。本系統使用通用爬蟲作為數據源獲取手段進行系統開發,并以CSV文件的形式存儲數據。系統以自然語言處理作為工作核心,使用Sonw模型、樸素貝葉斯算法、Jieba分詞、LDA聚類以及關鍵詞提取等技術對初始數據集進行處理和分析,使用PyEcharts、Tkinter工具將處理結果和輿情信息以可視化界面的方式向用戶展示出來。
1 網絡爬蟲簡介
網絡爬蟲(Web Crawler)又稱為網絡蜘蛛(Web Spider),是一個智能抓取網頁的程序,網絡爬蟲最初設計用于搜索引擎中,成為搜索引擎不可缺少的組成部分。首先給定一些種子鏈接放到爬蟲隊列中,網絡爬蟲通過鏈接對應的頁面抓取新鏈接放到隊列中,繼續抓取更多的鏈接,重復這一周而復始的過程,直到滿足爬蟲設定的終止條件為止[3]。按照爬蟲的功能、結構、爬行策略以及實現技術的不同,網絡爬蟲可以劃分為3大類:通用爬蟲(General Crawler)、聚焦爬蟲(Focused Crawler)和深度爬蟲(Deep Crawler)。
2 輿情監控系統的設計與實現
2.1 技術可行性分析
本輿情監控系統使用Anaconda進行開發,用到了一些Python自帶的庫文件:包括Pyecharts可視化庫、CVS存儲爬取數據、Tkinter庫搭建操作界面等。本系統所用技術如下:
(1)Anaconda是主流的Python IDE之一,擁有很多方便高效的工具,是Python開發人員的得力助手。另外還支持基于Django框架的專業Web開發,是一款開源的Python開發平臺。
(2)本系統主要借助了一些Python內置的庫文件,如re、selenium、pandas、requests、os、pickle等模塊。這些模塊拿之即用,免去了繁瑣的開發過程,極大地提高了開發效率。
(3)Ui界面采用Python內置的Tkinter,相較于Pyqt5小巧,并且高效,完全能勝任本系統的功能需求。
2.2 功能需求分析
2.2.1 輿情采集模塊
輿情采集利用網絡爬蟲技術來完成微博上關于醫療衛生行業熱點話題的信息采集。
2.2.2 數據處理模塊與輿情應用模塊對爬取到的數據進一步篩選統計處理,需完成下述功能:輿情信息查詢即實現對醫療輿情信息的基于關鍵詞的數據查詢功能;
統計分析即對醫療輿情信息進行歸類匯總,通過自然語言處理,根據不同條件形成可視化數據;
輿情預警是整個系統的核心功能之一,通過文本的情感傾向性分析,進行輿情信息正負面情緒識別,并對負面醫療輿情進行預警。
2.2.3 系統管理模塊
該模塊實現用戶注冊、用戶登錄、醫療關鍵字設定等主要系統功能。
2.3 系統設計
2.3.1 系統總體結構設計
通過對醫療行業輿情監控系統的整體分析,將系統功能劃分為4大功能模塊,其體系結構如圖1所示。
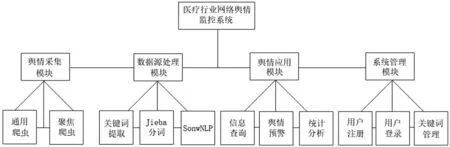
圖1 系統總體結構圖
2.3.2 數據處理流程設計
系統數據處理模塊主要完成對微博上公開的醫療行業輿情信息的清洗、處理和存儲,為接下來實現數據可視化展示打下基礎。系統數據處理流程圖如圖2所示。
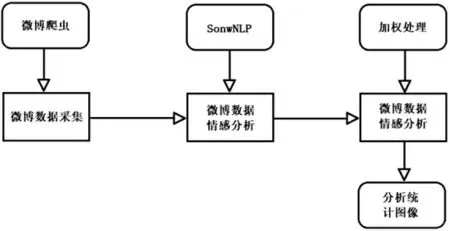
圖2 數據處理流程圖
2.4 系統實現
2.4.1 情感分析功能
輿情信息的情感分析處理是基于Python的SonwNLP模型作為情感分析的模型,該模型原理是機器學習中的Naive-Bayes分類方法,對數據文本利用Jieba分詞工具進行分詞并使用哈工大停用詞表去除停用詞[4]。在此基礎處理后,提取單句的關鍵詞信息,將單句評論的詞匯作為模型特征:(ω1,ω2,...,ωn),再利用樸素貝葉斯公式進行打分:
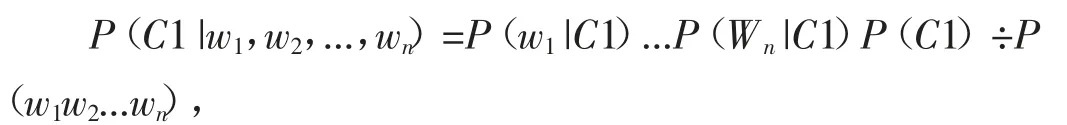
其中:C1代表積極類情緒,等式右邊的計算基于訓練好的模型,分數越高代表語句情感越積極。情感分析功能實現如圖3所示。
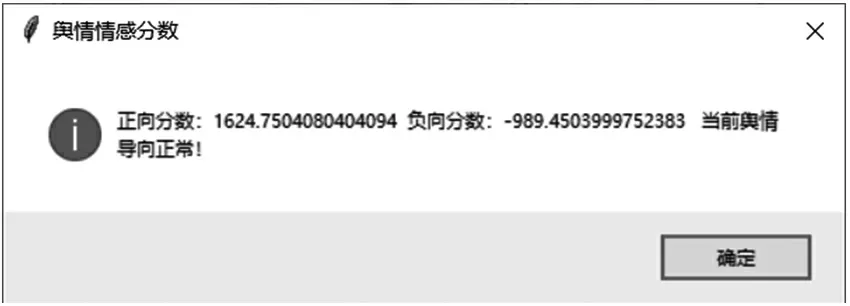
圖3 情感分析結果圖
2.4.2 關鍵詞搜索功能
輿情信息關鍵詞搜索功能涉及的核心算法有LDA聚類、關鍵詞提取技術等。首先根據關鍵詞信息對整個數據源LDA聚類,篩選出符合要求的微博數據。作為一個主題生成模型,同時也是一個三層貝葉斯概率模型,用于基于關鍵詞的數據篩選效果良好[5]。接著使用NLP技術中的關鍵詞提取技術,對符合條件的微博數據進行關鍵詞提取整合。最后交付可視化系統進行展示。如圖4所示為搜索關鍵詞為“醫療”時用戶關注的輿情信息詞云生成圖。

圖4 關鍵詞搜索詞云生成圖
2.4.3 可視化功能實現
通過對輿情信息獲取模塊爬到的數據源經過上述處理后,利用Python可視化包庫進行數據統計、畫出數據分析結果柱狀圖、餅狀圖、關鍵詞詞云等可視化圖像。醫療行業網絡輿情監控系統主界面如圖5所示。
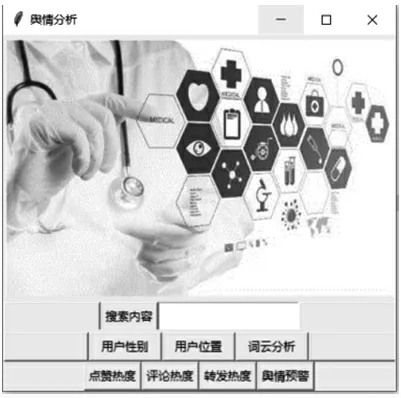
圖5 系統界面圖
3 結論
本課題選取通用爬蟲作為數據獲取工具,以自然語言處理技術作為核心工作,成功設計出一套基于爬蟲技術的醫療行業輿情監控系統,對時下熱點話題——新冠肺炎的輿論監控和導向起到了一定的作用。
猜你喜歡
中華詩詞(2022年6期)2022-12-31 06:41:24
世界科學技術-中醫藥現代化(2022年3期)2022-08-22 00:32:50
云南化工(2021年8期)2021-12-21 06:37:54
海洋信息技術與應用(2020年1期)2020-06-11 12:43:56
傳媒評論(2019年4期)2019-07-13 05:49:14
中國科技論壇(2017年7期)2017-07-25 08:49:53
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
中國中醫藥現代遠程教育(2014年22期)2014-03-01 04:32:55
中國中醫藥現代遠程教育(2014年16期)2014-03-01 04:28:54
